卒業論文
Convolutional Neural Network
の
特徴抽出過程における不変性獲得の調査
福井 宏
2014
年
3
月
指導教授 藤吉弘亘
A Graduation Thesis of College of Engineering, Chubu University
Investigation of feature extraction by Convolutional Neural Network
はじめに
文字認識をはじめとする物体検出法の一つとして,ニューラルネットワークがある.ニュー ラルネットワークとは,人間の脳の神経回路の仕組みを模したモデルである.ニューラ ルネットワークの研究は 1940 年代から研究が進められており,現在までに何度か研究の ブームと終焉を繰り返してきた.まず,1980 年にニューラルネットワークの学習方法で ある誤差逆伝播法 [1] が提案されたことによりブームが起きた.誤差逆伝播法は,パーセ プトロンの出力と教師信号から誤差を求め,パラメータを更新する学習手法である.しか し,このブームは 90 年代半ばに次の 3 つの理由から終焉を迎えた.1 つ目の理由として, 誤差逆伝播法によるパーセプトロンの学習は,3 層程のパーセプトロンなら十分な精度を 得ることができるが,層を増すに連れて学習はできるが識別で十分な精度が出ない状態 (このような状態を過学習と呼ぶ) に陥いる.2 つ目の理由は,パーセプトロンの学習時の パラメータ調節が非常に難しいことである.3 つ目の理由は,90 年代の計算機の処理能力 が現実的な問題を扱えないからである. 2012 年頃から Deep Learning という新しいアプローチが提案され改めてニューラルネッ トワークが注目されている.Deep Learning とは,複数の中間層を持つ多層パーセプトロ ンである.従来の多層パーセプトロンでは,中間層が複数の層では十分な学習ができな かったが,プレトレーニング [2] や Drop out[3] などの提案によって複数の中間層を持った パーセプトロンでも十分な学習ができるようになった.また,Deep Learning が注目され る大きな理由は,識別に有効な特徴量を学習により自動で獲得することである.従来の機 械学習には,Histgram of Oriented Gradients(HOG) 特徴量 [4] や Scale Invariant Feature Transform(SIFT) 特徴量 [5] などの認識に有効な特徴量を試行錯誤して選択する必要があ る.Deep Learning の先駆けとなる手法として Convolutional Neural Network(CNN) があ る [6].CNN とは,各層でフィルタの畳み込みとプーリングの処理をするパーセプトロン である.各層間で畳み込みとプーリングをすることで各層間の結合が疎になり誤差が拡 散するのを防いでくれるため,多層にしても過学習が起きづらくなる.実際に,1989 年ている. そこで,本研究では Deep Learning における,特徴量の学習が識別器にどのような影響 を与えているのかを CNN を対象として調査する.また,CNN の畳み込みとプーリング により自動生成された特徴量が,微小な幾何変化に対してどの程度不変性を持っているの かを調査する.そして,従来のニューラルネットワークの学習方法であるランダム学習を 導入することで,CNN が幾何変化に対する不変性を向上できるのかを調査し,ランダム 学習を導入することで自動生成される特徴が変化するのかを実験する.
目 次
第 1 章 ニューラルネットワーク 1 1.1 ニューロンモデル . . . . 1 1.1.1 活性化関数 . . . . 2 1.2 単純パーセプトロン . . . . 4 1.3 多層パーセプトロン . . . . 5 1.3.1 勾配降下最適化 . . . . 6 1.3.2 誤差逆伝播法 . . . . 9 1.3.3 ロジスティック回帰 . . . 12 第 2 章 Deep Learning 14 2.1 Convolutional Neural Network . . . . 152.1.1 特徴抽出部 . . . 16 2.1.2 識別部 . . . 18 2.1.3 ユニットの構成 . . . 19 第 3 章 評価実験 21 3.1 データセット . . . 21 3.2 学習パラメータ . . . 23 3.3 可視化実験 . . . . 23 3.3.1 実験概要 . . . 23 3.4 CNN の幾何変換に対する不変性の実験 . . . . 28 3.4.1 実験概要 . . . 28 3.4.2 実験結果 . . . 29 おわりに 38
図 目 次
1.1 ユニットの構造 . . . . 2 1.2 シグモイド関数の例 . . . . 3 1.3 単純パーセプトロンの例 . . . . 4 1.4 単純パーセプトロンが学習できないデータ分布の例 . . . . 6 1.5 多層パーセプトロンの例 . . . . 7 1.6 多層パーセプトロンの例 . . . . 9 2.1 誤差の勾配が拡散している例 . . . . 14 2.2 CNN の基となった技術.文献 [7][8] より引用 . . . . 15 2.3 CNN の処理の流れ . . . . 16 2.4 プーリングの処理の流れ . . . 18 2.5 識別部の処理の流れ . . . . 19 2.6 CNN のユニットの構成 . . . . 20 3.1 MNIST Dataset の例 . . . . 22 3.2 重みフィルタの可視化結果 . . . 24 3.3 特徴マップの可視化結果 . . . 25 3.4 誤差の推移 . . . . 26 3.5 学習による重みフィルタと特徴マップの変化 . . . 27 3.6 学習誤差の推移と重みフィルタの変化 . . . . 28 3.7 幾何変換を与えた識別サンプルの例 . . . 29 3.8 幾何変化に対する誤識別率の変化 . . . 31 3.9 幾何変化を与えたときの特徴マップ . . . 32 3.10 ランダム学習を導入したときの重みフィルタ . . . . 33 3.11 ランダム学習を導入したときの特徴マップ . . . . 34表 目 次
3.1 実験で識別サンプルに与えた幾何変化 . . . . 30
ニューラルネットワークとは,人の神経細胞の学習のメカニズムをモデルに作られたア ルゴリズムである.ニューラルネットワークはユニットと呼ばれる 1 つの神経細胞を重み で繋げていきネットワークを作る.中でも,ユニットを階層型のネットワーク構造にした パーセプトロンは現在でも使われている手法である.本章では,パーセプトロンの基礎的 な構造について述べる.
1.1
ニューロンモデル
脳には,何種類ものニューロン (神経細胞) が存在している.中には,内部で高度な機能 を持っているニューロンも存在している.このニューロンの人工的なモデルをユニットと 呼ぶ.ユニットの構造は図 1.1 のように多入力 1 出力の素子が用いられる.実際のニュー ロン間は神経繊維に対応する線で結ばれている.それに対し,図 1.1 のようにユニット間 はシナプス結合と同様で,信号は一方向に伝わり,重み w を付加し,結合されたユニット に入力される.1.1. ニューロンモデル f 入力信号 重み 活性化関数 出力 図 1.1: ユニットの構造 重みをつけられたそれぞれの入力信号 xi,wiの総和を求めて活性化関数 f により出力 y を求める.ここで,入力信号 x と重み w は特徴次元数 d だけ用いる.重み wiはパーセプ トロンの学習により変化させることが出来る.出力 y は式 (1.1) のように表される. y = f ( d ∑ i=1 wixi ) (1.1)
1.1.1
活性化関数
ユニットの出力 y は,活性化関数 f に入力信号 xiと重み wiの総和を入力することで求 まる.活性化関数には様々な種類があり,ネットワークの構造や問題設定により使う活性 化関数が異なる.本項では,従来使われている活性化関数について述べる.また,本項で は入力信号と重みの総和を X とする. ■ マカロック・ピッツモデル マカロック・ピッツモデルは,式 (1.2) のように X に応じて 2 通りの値を出力する活性 化関数である.例えば,式 (1.2) では,X が 0 よりも大きい場合は 1 を出力し,X が 0 以 下の場合は-1 を出力する関数である.この活性化関数は,初期のニューラルネットワークで用いられていた活性化関数である. f (X) = 1 (X > 0) −1 (X ≤ 0) (1.2) ■ シグモイド関数 シグモイド関数とは,図 1.2 に示すような関数であり,式 (1.3) のように示すことがで きる.シグモイド関数は,どのような入力に対しても 0 から 1 の値が出力される. Gain 2.0 0.2 1.0 図 1.2: シグモイド関数の例 f (X) = 1 1 + exp (−gX) (1.3) ここで,式 (1.3) の g はゲインを示している.ゲイン g は,シグモイド関数の曲線の緩 急を制御する係数である.図 1.2 では,赤い線ほどゲインの係数が大きく,青い線ほどゲ インの係数が小さいことを示している.図 1.2 より,ゲインが大きいほどシグモイド関数 の曲線が急になり,最終的にはステップ関数に近い曲線になる.また,ゲインが小さいほ ど,シグモイド関数の曲線が緩やかになり,最終的には直線に近い曲線になる.
1.2. 単純パーセプトロン このシグモイド関数を用いることによってパーセプトロンの識別性能は格段に向上す る.その理由は,シグモイド関数は微分でき,1.3.2 章で説明する誤差逆伝播法に適用す ることが出来る.また,シグモイド関数 f (X) を微分した場合に式 (1.4) のように簡単に 求めることができるため,計算しやすいというメリットがある. f0(X) = gf (X) (1− f (X)) (1.4)
1.2
単純パーセプトロン
単純パーセプトロンは 1957 年に提案されたパーセプトロンモデル [9] である.図 1.3 の ように入力層,中間層,出力層の 3 層で構成された 2 クラス識別器である. バイアス 入力層 中間層 出力層s
1s
2s
3s
ds
ia
1a
2a
Ja
jθ
w
ijw
jO
A
S
図 1.3: 単純パーセプトロンの例 ここで,○はユニットを表しており,→はユニット間の重みを示している.入力層のユ ニット数は特徴次元数 d であり,中間層のユニット数は任意の数 J であり,出力層のユ ニット数は 1 つである.単純パーセプトロンでは,入力層と中間層の重み wij は初期値で 固定する.そして,中間層と出力層の重み wjを学習により更新する.出力層の出力は-1 か 1 の 2 値が出力される.単純パーセプトロンでは通常のユニットと重みに加えてバイア ス θ を設定する必要があり,バイアス θ も学習により更新する.中間層のユニットの出力を A = [a1, a2, . . . , aj, . . . , aJ]T を求める.中間層と出力層の重みを w = [w1, w2, . . . , wj] と したとき,単純パーセプトロンの出力 O は式 (1.5) のように示す. O = f ∑J j=1 wj1aj − θ (1.5) この出力 O と教師信号 T を用いて式 (1.6),式 (1.7) で重みとバイアスをそれぞれ更新する. wt+1 = wt+ η (T − O) A (1.6) θt+1= θt+ η (T − O) (1.7) 式 (1.6) と式 (1.7) の t は,更新回数を示している.また,η は学習係数と呼ばれ,重みの更 新量を制御する係数であり,η > 0 である.単純パーセプトロンでは,式 (1.6) と式 (1.7) の更新をすべてのサンプルに対し行う.単純パーセプトロンの学習は,学習の終了条件を 満たすまで繰り返し更新する.学習の終了条件は,一般的に学習回数が指定した回数まで 達した場合や,誤識別率が 0% になるまでに設定される.
1.3
多層パーセプトロン
2 次元のデータ x1,x2で,赤と青の 2 クラスが図 1.4(a) のように配置してあるとする. 赤と青のクラスのデータの配置は排他的論理和の関係である.排他的論理和のデータ分 布は,線形識別ができないため,単純パーセプトロンでは識別できない.また,2 次元の データ x1,x2で図 1.4(b) のように赤と青と黄色の 3 クラスのデータ分布の場合も識別で きない. そこで,図 1.4 のようなデータ分布に対して問題を解決する手法で多層パーセプトロン がある.多層パーセプトロンは,非線形の多クラス識別器であり,図 1.5 のように入力層, 中間層,出力層の 3 種類の層で構成されているパーセプトロンである. 多層パーセプトロンと単純パーセプトロンの大きな違いは 2 点ある.まず,単純パーセ プトロンは中間層と出力層の重みのみ更新していたが,多層パーセプトロンではすべて の重みに対して学習で更新を行う.次に,多層パーセプトロンでは,多クラス識別を行う ため出力層のユニット数はクラス数 c だけ用意する.入力層のユニット数は特徴次元数 d と同じであり,中間層のユニット数は任意の数 J である.多層パーセプトロンの学習方法 は,教師付き学習による誤差逆伝播法を用いた勾配降下最適化法により学習する.1.3. 多層パーセプトロン 0 1 1 0 0 (a) 排他的論理和のデータ分布 (b) 多クラスのデータ分布の例
x
1
x
2
x
1
x
2
(1,0) (1,1) (0,0) (0,1) 図 1.4: 単純パーセプトロンが学習できないデータ分布の例1.3.1
勾配降下最適化
パーセプトロンを学習するとき,パーセプトロンの各パラメータの更新量を適切に求め る必要がある.このとき,更新するパラメータは各層の重みとバイアスである.パーセプ トロンの学習では,学習誤差を用いて各パラメータの更新量を求める.この各パラメータ の更新量を求める方法として誤差逆伝播法を用いる.そして,誤差逆伝播法により求めた 更新量を勾配降下最適化を使いパラメータを更新する.以下の項では勾配降下最適化法に ついて説明する. ■ 最急降下法 勾配降下最適化法の 1 つとして最急降下法という手法がある.最急降下法とは,すべて の学習サンプルを一度に用いてパーセプトロンの各パラメータを更新する手法である.ま ず,すべての学習サンプルの学習誤差を式 (1.9) で求める.今回は誤差関数として,二乗 誤差を用いて説明する. EN = 1 2 N ∑ n=1 c ∑ k=1 (Tk− Ok) 2 (1.8)入力層
S
中間層A
出力層O
s
1
s
i
s
d
s
3
a
1
a
j
a
J
o
1
o
2
o
c
o
k
w
ij
w
ij
γ
θ
図 1.5: 多層パーセプトロンの例 最急降下法では,この誤差関数 EN を用いて式 (1.9) に示すように,パーセプトロンの各 パラメータを更新する.重みの更新量は,誤差関数 EN の勾配を算出して学習係数 η をか けたものを重みの更新量とする.すべての学習サンプルを一度に用いるため,誤差関数の 減少率が最大となる方向にパラメータが更新される. wt+1 = wt− η∂EN ∂wt (1.9) このとき,バイアスも最急降下法によって学習させるが 1.3.2 章の誤差逆伝播法で説明す る.また,すべての学習サンプルを一度に用いて学習するテクニックをバッチ学習法と 呼ぶ.1.3. 多層パーセプトロン ■ 確率的勾配降下法 確率的勾配降下法とは,1 つの学習サンプルを用いてパーセプトロンの各パラメータを 更新する手法である.最急降下法では,学習サンプルが増えるにつれて誤差関数の総和を 求めないといけないため計算量が増加してしまう.しかし,1 つの学習サンプルを用いて パラメータの更新を行う確率的勾配降下法では,学習サンプル数が大量に増えたとしても 計算量は変化しないため,ニューラルネットワークのように大量の学習サンプルを用いて 学習を行う識別器には有効な手法である.確率的勾配降下法では,1 つの学習サンプルの 誤差を用いてパラメータ更新を行うため,式 (1.10) の誤差関数を用いる. En = 1 2 c ∑ k=1 (Tk− Ok)2 (1.10) 確率的勾配降下法では,式 (1.10) の誤差関数 Enを用いてパーセプトロンの各パラメータ を更新する.重みの更新量は,最急降下法と同じように誤差関数 Enの勾配を算出して学 習係数 η をかけたものを重みの更新量とする.確率的勾配降下法による各パラメータの更 新式は式 (1.11) のように表せる. wt+1 = wt− η∂En ∂wt (1.11) 最急降下法と同様に,バイアスも確率的勾配降下法によって学習されるが 1.3.2 章の誤差 逆伝播法で説明する.また,1 つの学習サンプルを用いて誤差を求めパラメータを更新す るテクニックをオンライン学習法と呼ぶ. ■ mini batch 学習法 バッチ学習とオンライン学習の中間の位置に属する学習法として,mini batch 学習法が ある.mini batch 学習法は,1 度に複数の学習サンプルを用いて学習を行う手法である. mini batch 学習法は,確率的勾配降下法と比べてパラメータの更新回数を削減すること ができ,最急降下法と比べて計算量を削減することができるメリットがある.そのため, 計算を効率よく行うことができる.バッチサイズを M として,パラメータを更新する場 合に確率的勾配降下法や最急降下法と同じように式 (1.12) で誤差関数 Emを設計し,式 (1.13) のパラメータの更新式を設計して学習を行う. EM = 1 2 M ∑ m=1 c ∑ k=1 (Tk− Ok) 2 (1.12)
wt+1 = wt− η∂EM ∂wt (1.13)
1.3.2
誤差逆伝播法
誤差逆伝播法とは,入力層,中間層,出力層からなるパーセプトロンに対し,出力層か ら入力層にかけて誤差の勾配を逆伝播させることで各パラメータを修正する教師付き学 習アルゴリズムである.この学習方法は通常,勾配降下最適化法と組み合わせて使われ る.まず図 1.6 のような構造の多層パーセプトロンで考える.誤差逆伝播法のアルゴリズ ムは,初めに順伝播することで出力を求める.そして,図 1.6 のように求めた出力と教師 信号を使い,誤差を求める.算出した誤差から各パラメータの更新量を求め,勾配降下最 適化法により各パラメータを更新する. 入力層 中間層 出力層 バイアス バイアス 教師信号 二乗誤差γ
θ
i
j
k
O
A
c
d
S
T
k
c
図 1.6: 多層パーセプトロンの例 パーセプトロンに入力される特徴次元数を d とし,識別するクラスを c とする.入力層 のユニットを Si,中間層のユニットを Aj,出力層のユニットを Ok,教師信号を Tkとし, 中間層と出力層の活性化関数 f はシグモイド関数を使う.また,入力層と中間層の重みを wij,中間層と出力層の重みを wjkとしたとき,中間層のユニット j の出力は,式 (1.14) の ように重み wijと入力 Sjの総和とバイアス θjを使って求めることができる.1.3. 多層パーセプトロン Aj = f ∑d i=1 wijSi+ θj (1.14) 今回の例では,確率的勾配降下法により各パラメータを更新するとする.この例の場 合,誤差関数は式 (1.10) を用いる.まず,式 (1.10) の誤差関数を出力 Okについて微分す る.出力 Okについて微分することで,式 (1.15) のような出力層における教師信号 T との 誤差 δkを得ることができる. ∂En ∂Ok = (Ok− Tk) = δk (1.15) ここで,出力層のユニット Okの内部ポテンシャルを Pk = ∑ jwjkAj+ γkとするとき, 出力層のユニットの出力 Okは式 (1.16) のように求めることが出来る. Ok = f (Pk) (1.16) 式 (1.16) で k > 2 の場合,式 (1.17) のように式変形される.式 (1.17) は,ソフトマッ クス関数と呼ばれておりシグモイド関数を多クラス問題に対応させた活性化関数である. ソフトマックス関数は,すべてのクラスに関する内部ポテンシャル Pkの和が 1 になるよ うに,内部ポテンシャル Pjを用いて正規化し,確率値に変換する. Ok = exp (Pk) ∑ jexp (Pj) (1.17) ここで,誤差関数 Enの勾配である∇Enを求める.∇Enは式 (1.18) のように求めるこ とが出来る. ∇En = ∂Enjk ∂wjk (1.18)
まず,出力層と中間層への誤差の勾配∇Enjkについて求める.∇Enjkは式 (1.18) を偏 微分の連鎖法則を用いることで求めることが出来る.偏微分の連鎖法則を用いることで, 最終的に式 (1.19) のように求めることができる. ∇Enjk = ∂En ∂wjk = ∂En ∂Ok ・∂Ok ∂wjk = ∂En ∂Ok ・∂Ok ∂Pk ・∂Pk ∂wjk (1.19) 式 (1.19) より,最終的な出力層と中間層の誤差の勾配∇Enjkは式 (1.20) のように表さ れる. ∇Enjk = ∂En ∂wjk = δk・Ok・(1− Ok)・Aj (1.20) また,中間層から入力層の誤差の勾配∇Enijも同様に,偏微分の連鎖法則を用いて求め ることができる.中間層から入力層の誤差の勾配∇Enij は,最終的に式 (1.21) のように 求めることができる. ∇Enij = ∂En ∂wij = ∂En ∂Aj ・∂Aj ∂Pj ・∂Pj ∂Wij = ∂En ∂Ok ・∂Ok ∂Pk ・∂Pk ∂Aj ・∂Aj ∂Pj ・∂Pj ∂wij = ( ∑ k δk・Ok・(1− Ok)・Wjk ) ・Aj・(1− Aj)・Si (1.21) そして,式 (1.20) と式 (1.21) を用いて各層間のパラメータの更新式を,確率的勾配降下 法を用いて設計する.まずはじめに,式 (1.20) を用いて出力層と中間層の重みとバイアス の更新式をそれぞれ設計する.式 (1.20) を確率的勾配降下法の更新式 (1.11) に代入する ことで重みの更新式 (1.22) を作成する.またバイアスの更新式は,式 (1.23) のように求 めることができる. wjkt+1 = wjkt − η・δk・Ok・(1− Ok)・Aj (1.22) γjt+1 = γjt− η・δk・Ok・(1− Ok) (1.23)
1.3. 多層パーセプトロン 同じようにして,中間層と入力層の重みとバイアスの更新式を確率的勾配降下法を用いて それぞれ設計する.中間層と入力層の重みの更新式を式 (1.24) に示し,バイアスの更新式 を式 (1.25) に示す. wt+1ij = wtij − η・ ( ∑ k δk・Ok・(1− Ok)・Wjk ) ・Aj・(1− Aj)・Si (1.24) θt+1j = θjt− η・ ( ∑ k δk・Ok・(1− Ok)・Wjk ) ・Aj・(1− Aj) (1.25) 多層パーセプトロンの学習では,各パラメータの更新をすべての学習サンプルに対して行 う.そして,すべての学習サンプルに対して各パラメータを更新したとき,学習の終了条 件を満たしている場合は学習を終了する.もし,終了条件を満たしていない場合は,初め から学習サンプルを学習させる.終了条件として,指定した epoch 数に達したときが一般 的である.このとき,1epoch はすべての学習サンプルに対してパラメータを 1 回更新し たことを示す.このようにして,多層パーセプトロンの学習は行われる.
1.3.3
ロジスティック回帰
ロジスティック回帰とは,教師あり学習の一種で教師信号が離散値の場合の問題を解決 するための線形モデルである.出力される予測値は事後確率を出力するため 0 から 1 の値 の間を取る.多層パーセプトロンの場合,出力層のユニットの活性化関数はシグモイド関 数であるため出力の値は 0 から 1 の確率値である.そして,教師信号も離散値のため多層 パーセプトロンはロジスティック回帰と見なすことが出来る.ロジスティック回帰は,2 ク ラス分類問題における一般線形モデルとして用いる.2 クラス問題の場合,1 つの目的変 数 t で,t = 1 がクラス C1,t = 0 が C2を表す.ネットワークの出力 y は,シグモイド関 数を使っているため式 (1.3) を用いる.出力 y(x, w) は条件付き確率 p(C1|x) と解釈でき, このとき p(C2|x) は 1 − y(x, w) で与えられる.従って,入力が与えられた時の目標の条件 付き分布は式 (1.26) のように表せる. p (t|x, w) = y (x, w)t{1 − y (x, w)}1−t (1.26) 式 (1.26) の分布は,ベルヌーイ分布になる.学習サンプルが独立な観測値の場合には,式 (1.27) の負の対数尤度で表されるクロスエントロピー誤差関数が用いられる. E =− N ∑ n=1 {tnln yn+ (1− tn) ln (1− yn)} (1.27)Simard らは,二乗誤差の代わりにクロスエントロピー誤差関数を用いたほうが,学習がよ り早くなると共に汎化能力が向上したことが示している [10].多クラスの場合,式 (1.28) のクロスエントロピー誤差関数が用いられる.多クラスのロジスティック回帰の場合,多 クラスロジスティック回帰と呼ばれる. E =− N ∑ n=1 C ∑ c=1 tncln yc (1.28)
第
2
章
Deep Learning
パーセプトロンの層数を増やして学習する Deep Learning という手法がある.従来の多層 パーセプトロンでは,各層間で重みが全結合しているため中間層を増やすことで,誤差の 勾配が拡散してしまうというデメリットがある.図 2.1 では,多層パーセプトロンで誤差 の勾配が拡散する例を示したものである.初めに,多層パーセプトロンの出力 O と教師 信号 T を用いて各クラスの誤差を求める.そのとき,出力層のあるユニット Okに着目し た場合に,青の矢印に沿って誤差の勾配が逆伝播される. 誤差c
d
i
j
k
k
c
j
j
入力層 出力層 中間層A S O 教師信号 T 図 2.1: 誤差の勾配が拡散している例 図 2.1 のように,途中の層からすべての重みに対して誤差の勾配が逆伝播されるため,入力層に近づくにつれて誤差の勾配がうまく逆伝播されない.そこで,Convolutional Neural Network(CNN) という手法が提案された.CNN は,各層間の重みに過疎性を持たせるこ とで,中間層の層数を複数用いても学習できるような構造である.本章では,CNN の概 要について述べる.
2.1
Convolutional Neural Network
CNN とは,多層パーセプトロンの一つで中間層で畳み込みとプーリングの処理を複数 回繰り返し行い,特徴量を自動で取得するニューラルネットワークである.CNN は Hubel と Wisel の研究にルーツがある [11].この研究で Hubel らは,図 2.2(a) のように猫の初期 視覚野に特定の傾きを持つ線分に選択的に反応する単純細胞と,特定の傾きを持つ線分を 移動させても反応する複雑細胞の存在を確認した.その後,Fukushima らは,図 2.2(b) の ような数理モデルとなる Neocognitron という視覚パターン認識に関する階層型神経回路 モデルを発表した [8].Neocognitron は,同一の結合重みを持つユニットを複数並べ,出 力をさらに上位層で集積するプーリングを行い幾何学的変化に対する不変性を実現して いる.CNN は,Neocognitron に誤差逆伝播法を用いた勾配降下最適化法を取り入れた手 法である. (a) 特定の傾きに反応する細胞 (b)Neocognitron 図 2.2: CNN の基となった技術.文献 [7][8] より引用 CNN の学習は,教師付き学習を前提とし,誤差逆伝播法を用いた勾配降下最適化法で 学習する.CNN では入力層で画素値を入力し,入力した画素値から畳み込みとプーリン
2.1. Convolutional Neural Network グの処理を繰り返して特徴抽出をし,識別する.図 2.3 は CNN の処理の流れを示す.ま ず,入力画像に対して重みフィルタを畳み込み処理する.この畳み込み処理の出力はマッ プ状に出力される.この出力されたマップを特徴マップと呼ぶ.次に,出力された特徴 マップを入力としてプーリング処理を行う.プーリングの処理により新たな特徴マップを 得ることができる.この処理を繰り返すことにより,特徴量を自動生成できる.最後に, 得られた特徴マップを入力として識別部に入力されて識別する. 畳み込み層 プーリング層 重みフィルタ 重みフィルタ 特徴マップ 畳み込み層 プーリング層 Full-Connect層 出力層 (事後確率) 教師信号 中間層第1層目 中間層第2層目 特徴抽出部 識別部 0.01 0.00 0.96 0.02 0 1 8 9 図 2.3: CNN の処理の流れ
2.1.1
特徴抽出部
特徴抽出部では,中間層の畳み込みとプーリングの処理を繰り返すことで特徴量を自動 生成している.本項では,CNN の特徴抽出部で処理されている畳み込みとプーリングの 処理について述べる.■ 畳み込み処理 CNN での畳み込み処理は,重みフィルタと入力画像,または重みフィルタと特徴マッ プで内積をとり,ラスタスキャンにより繰り返し畳み込みを行うことで特徴マップを得る. 重みフィルタは,誤差逆伝播法による勾配降下最適化法により学習される.また,この畳 み込みの処理は Hubel らの研究の単純細胞の働きをしている.畳み込み処理で,画像と 重みフィルタのサイズをそれぞれ nx× ny,nw× nwとしたとき,出力される特徴マップ のサイズ n0x, n0yは式 (2.1) のようになる. n0x = nx− nw+ 1 n0y = ny − nw+ 1 (2.1) ■ プーリング処理 プーリングとは,入力される特徴マップの小領域から値を出力して新たな特徴マップに 変換する処理である.プーリングを行う目的は 2 つある.まず,プーリングによりユニッ ト数を減らすため,調整するパラメータを減らすことが出来る.2 つ目は,ある小領域か ら応答値を出力するため,幾何変化などに対する不変性を獲得することが出来る.この 2 つ目の性質は Hubel らの複雑細胞の働きをしている.CNN でよく使われているのはマッ クスプーリングである.マックスプーリングは,図 2.4 のようにある小領域 P 内の値 hi から最大値を出力するプーリングである.マックスプーリングの出力 h0は式 (2.2) から求 めることができる.ここで,i は小領域 P の位置を示す. h0 = max i∈P hi (2.2) マックスプーリングは畳み込み層の出力の隣接している 2 × 2 のユニットの最大値を出 力するため,出力される特徴マップのサイズは式 (2.3) のように示すことができる. n0x = nx/2 n0y = ny/2 (2.3)
2.1. Convolutional Neural Network 小領域 43 53 41 132 134 87 129 90 91 147 13 70 63 198 73 82 132 134 147 198 入力マップ 出力マップ
P
P1 P2 P3 P4 図 2.4: プーリングの処理の流れ2.1.2
識別部
CNN の識別部では,従来の多層パーセプトロンと同じような構造をしており,特徴抽出 部で生成された特徴マップを入力して識別を行う.図 2.5 に識別の流れを示す.特徴抽出部 の畳み込みとプーリングの処理により自動生成された特徴マップを,識別部の Full-Connect 層のユニットに入力する.このとき,最終的に生成された特徴マップと Full-Connect 層 のユニットの層間の重みは全結合されている.その後,従来の多層パーセプトロンと同じ ように出力層のユニットに応答値が入力して識別する.最終的に出力された特徴マップ
畳み込み
プーリング
Full-Connect 層 出力層 出力値 ( 事後確率 ) 教師信号 0.01 0.95 0.00 0.02 0 1 2 9 図 2.5: 識別部の処理の流れ2.1.3
ユニットの構成
1 CNN のユニットの構成について説明する.まず,入力層と出力層のユニット数は多 層パーセプトロンと同じである.中間層では,畳み込みとプーリングによってユニット数 がそれぞれ式 (2.1) と式 (2.3) のように変化する.畳み込みでは nw× nwの重みフィルタ で畳み込み処理をするため,nw× nwの範囲のユニットから一つのユニットに応答値を出 力する.その後,2 × 2 の小領域でプーリングをして 1 つのユニットに応答値を出力する. 識別部では,特徴抽出部で抽出した特徴から識別部の Full-Connect 層のユニットと全結 合し識別する.この一連の処理からユニットの構成は図 2.6 のようになっていることがわ かる.このような構造から,CNN の層間は結合が疎であると言える.2.1. Convolutional Neural Network 特徴マップ 特徴マップ 入力層 畳み込み層 プーリング層 第一中間層 特徴マップ 特徴マップ 畳み込み層 プーリング層 第二中間層 Full-Connect 層 出力層 図 2.6: CNN のユニットの構成
本章では,CNN が自動生成した特徴量の有効性を調査するために,CNN の特徴量の可 視化と CNN の幾何変換に対する不変性の 2 つの実験を行う.また,この 2 つの実験は MNIST Dataset を使い,同じ CNN のパラメータで実験する.
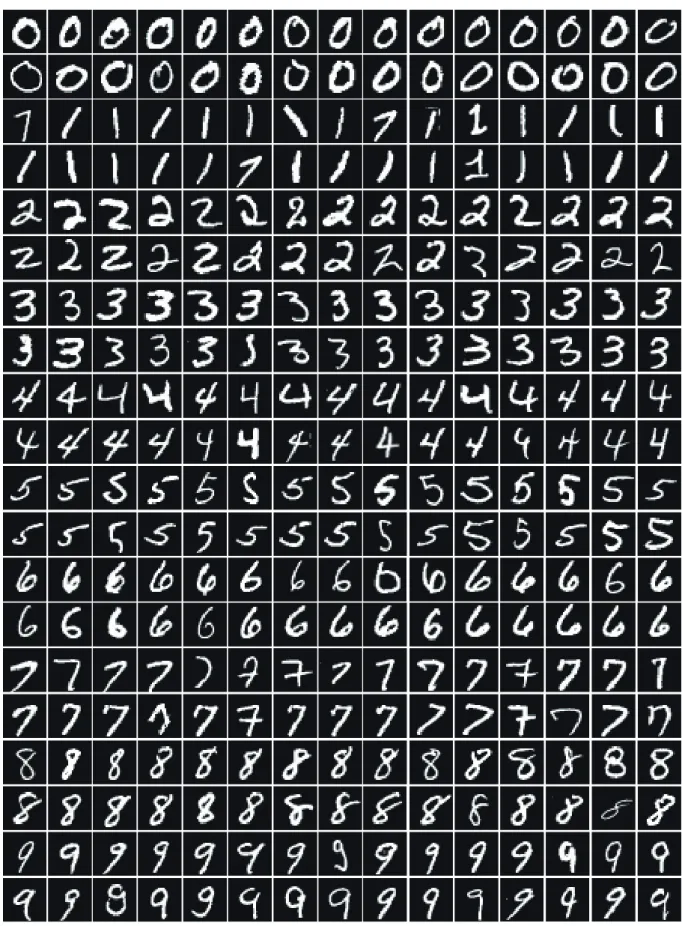
3.1
データセット
実験では,ある領域で切り出された手書き文字のデータセットを用いる.データセッ トには,手書き文字認識実験で広く用いられている MNIST Dataset を使用する.図 3.1 に MNIST Dataset の例を示す.MNIST Dataset は数字の 0 から 9 までの手書き文字の画 像により作成されたデータセットである.学習サンプルには 50,000 枚,検証サンプルは 10,000 枚,評価サンプルは 10,000 枚を使用する.画像サイズは 28 × 28pixel で使用する.3.1. データセット
3.2
学習パラメータ
本実験で使用した CNN の重みフィルタは,サイズが 5 × 5 で 1 層目は 6 枚,2 層目は 14 枚用いる.プーリングは,2 × 2 の小領域から最大値を出力するマックスプーリングを 用いる.識別部の Full-Connect 層のユニット数は 400 個使用いる.学習係数は 0.1 で設定 し,バッチサイズが 10 のミニバッチ学習を行う.学習誤差の算出は交差エントロピー誤 差関数を用いて,出力層のユニットの活性化関数はソフトマックス関数を用いる.また, 各実験の比較実験で用いる多層パーセプトロンは,中間層が 1 層でユニット数が 1000 個 の多層パーセプトロンを用いる.学習係数とバッチサイズは CNN と同じで,それぞれ 0.1 と 10 で設定する.epoch 数は 100 で実験を行う.3.3
可視化実験
3.3.1
実験概要
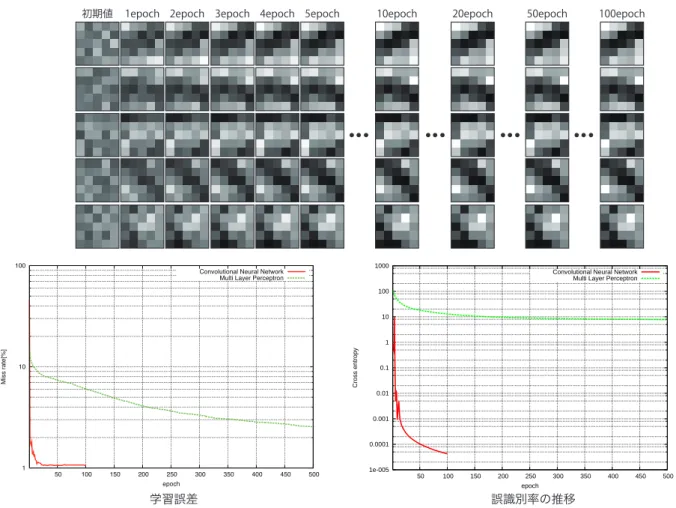
CNN がどのような特徴量を自動生成しているのかを確認するために,各層の重みフィ ルタと特徴マップを可視化する.このとき,学習誤差と識別誤差に対すると重みフィルタ と特徴マップの関連性を確認するために,学習誤差と誤識別率の推移を確認し,重みフィ ルタと特徴マップが学習によってどのように変化するのかを実験により調査する. ■ 実験結果 CNN で生成された重みフィルタを可視化した結果を図 3.2 に示す.図 3.2 では,上半分 が学習前の重みフィルタを示しており,下半分が学習後の重みフィルタを示している.図 3.2 より,学習によって重みフィルタの濃淡が変化していることがわかる.3.3. 可視化実験
1 層目
2層目
1 層目
2層目
初期状態
100epoch
図 3.2: 重みフィルタの可視化結果図 3.3 に,1 層目と 2 層目の畳み込みとプーリングより出力された特徴マップを示す.図 3.3 より,epoch が増えるにつれて入力画像のエッジが強調されていることがわかる.特 に,2 層目の特徴マップでは epoch が増えるにつれて局所的なエッジが大きく強調されて いることが確認できる. Conv1 Conv2 Pool1 Pool2 Conv1 Conv2 Pool1 Pool2 Conv1 Conv2 Pool1 Pool2 Conv1 Conv2 Pool1 Pool2 Conv1 Conv2 Pool1 Pool2 Conv1 Conv2 Pool1 Pool2 Conv1 Conv2 Pool1 Pool2 Conv1 Conv2 Pool1 Pool2 初期状態 100epoch 図 3.3: 特徴マップの可視化結果 図 3.4(a) に学習誤差の推移,図 3.4(b) に識別誤差の推移を示す.このとき,比較対象と して多層パーセプトロンの学習誤差と識別誤差も示す.図 3.4(a) と図 3.4(b) より,学習誤 差と識別誤差ともに多層パーセプトロンよりも誤差の収束が早いことがわかる.
3.3. 可視化実験 (a) 学習誤差の推移 (a) 誤識別率の推移 1e-005 0.0001 0.001 0.01 0.1 1 10 100 1000 50 100 150 200 250 300 350 400 450 500 Cross entropy epoch
Convolutional Neural Network Multi Layer Perceptron
1 10 100 50 100 150 200 250 300 350 400 450 500 Mi ss ra te [% ] epoch
Convolutional Neural Network Multi Layer Perceptron
■ 考察
重みフィルタと畳み込み層の特徴マップの各 epoch に対する変化を図 3.5 に示す.図 3.5 では,上半分が 1 層目の畳み込み層の特徴マップ,下半分が 2 層目の畳み込み層の特徴 マップを示している.図 3.5 より,重みフィルタの濃淡の差が大きく出るほど特徴マップ のエッジが強調されていることがわかる.
初期状態 1epoch 2epoch 3epoch 4epoch 5epoch 100epoch
初期状態 1epoch 2epoch 3epoch 4epoch 5epoch 100epoch
1 層目
2 層目
図 3.5: 学習による重みフィルタと特徴マップの変化 図 3.4(a) の学習誤差と誤識別率の推移と可視化をした各 epoch の重みフィルタの変化 をまとめたものを図 3.6 に示す.図 3.6 より,学習誤差が大きい場合は重みフィルタの各 係数の更新量が大きいことが確認できる.また,重みフィルタの濃淡の差が大きく変化す ることで誤識別率も大きく減少していることが確認できる.これらの結果より,学習誤差 と誤識別率と重みフィルタの変化は密接な関係であることが確認できた.3.4. CNNの幾何変換に対する不変性の実験
1epoch 2epoch 3epoch 4epoch 5epoch
初期値 10epoch 20epoch 50epoch 100epoch
学習誤差 誤識別率の推移 1e-005 0.0001 0.001 0.01 0.1 1 10 100 1000 50 100 150 200 250 300 350 400 450 500 Cross entropy epoch
Convolutional Neural Network Multi Layer Perceptron
1 10 100 50 100 150 200 250 300 350 400 450 500 Mi s s ra te [% ] epoch
Convolutional Neural Network Multi Layer Perceptron
図 3.6: 学習誤差の推移と重みフィルタの変化
3.4
CNN
の幾何変換に対する不変性の実験
3.4.1
実験概要
CNN の幾何変化に対する不変性の実験について述べる.識別サンプルに平行移動,回 転,スケール変化の幾何変化を与え,識別精度がどのように変化をするのかを実験する. このとき,CNN がどのような特徴マップを生成しているのかを確認し,プーリング処理 によって不変性を獲得できているのかを実験する.その際に,識別精度を比較するために 従来の多層パーセプトロンを用いて,同様に幾何変化を施した識別サンプルを入力して識 別精度を比較する.この実験により,CNN が特徴量を自動生成することで不変性を獲得 できているのかを調査する.また,ニューラルネットワークの従来の学習方法であるランダム学習を CNN に取り入れることで,CNN で自動生成される特徴量にどのような変化 が生じるのかを実験する.ランダム学習とは,ニューラルネットワークの学習サンプルに ランダム性を持たせて学習し,汎化性能を向上させる手法である.入力する学習サンプル は,図 3.7 のようにランダムに平行移動,回転の幾何変化をそれぞれ与えて学習する.ま た,ランダム学習なしの実験結果とランダム学習ありの実験結果を比較し,各幾何変化に 対する汎化性能が向上するのかを比較実験する. 平行移動 回転 図 3.7: 幾何変換を与えた識別サンプルの例
3.4.2
実験結果
学習した CNN に対して,平行移動や回転,スケール変化を与えたときの実験結果につ いて述べる.まず,本実験で行った幾何変化についてまとめたものを表 3.1 に示す.ここ で,平行移動の“ - ”が左方向,“ + ”が右方向を示す.3.4. CNNの幾何変換に対する不変性の実験 表 3.1: 実験で識別サンプルに与えた幾何変化 与えた幾何変化 平行移動 -5 ∼ +5 回転 0∼5,10,15,20,25,30 拡大 × 1.1 ∼ × 1.5 縮小 × 0.5 ∼ × 0.9 まず,それぞれの幾何変化を与えたときの誤識別率を図 3.8(a)∼図 3.8(c) に示す.ここ で,CNN の幾何変化に対する不変性を比較するため,多層パーセプトロン (MLP) を用い て比較実験する.図 3.8(a)∼図 3.8(c) より,多層パーセプトロンより CNN のほうが幾何 変化に対する不変性が高い結果となった. ここで,識別サンプルに幾何変化を与えたときの特徴マップを図 3.9 に示す.図 3.9 で は,図 3.8(a)∼図 3.8(c) の誤識別率が 10% 未満のときの特徴マップを可視化結果を示し ている.また,図 3.9 では 1 層目と 2 層目の各プーリング層の特徴マップの可視化結果を 示している.図 3.9 より,1 層目のプーリング処理では微小な変化を吸収し,2 層目のプー リング処理では 1 層目で吸収できなかった変化を吸収し,不変性を獲得していることがわ かる.
0 10 20 30 40 50 60 70 80 90 100 -10 -5 -4 -3 -2 -1 0 +1 +2 +3 +4 +5 +10 [%] [pixel] MLP CNN 0 5 10 15 20 25 30 0 1 2 3 4 5 10 15 20 25 30 [%] [°] MLP CNN 0 10 20 30 40 50 60 70 80 0.6 0.7 0.8 0.9 1.0 1.1 1.2 1.3 1.4 1.5 [%] スケールの変化率 MLP CNN (a) 平行移動に対する誤識別率の変化 (b) 回転に対する誤識別率の変化 (c) スケール変化に対する誤識別率の変化 図 3.8: 幾何変化に対する誤識別率の変化
3.4. CNNの幾何変換に対する不変性の実験 2 3 1 10 15 20 1.2 1.1 0.9 0.8 1.3 スケール変化 Pool1 Pool2 Pool1 Pool2 回転 Pool1 Pool2 Pool1 Pool2 幾何変化無し Pool1 Pool2 平行移動 +1 +2 -1 -2 Pool1 Pool2 Pool1 Pool2 図 3.9: 幾何変化を与えたときの特徴マップ
次に,学習サンプルにランダムな平行移動をしたときの CNN の重みフィルタを図 3.10 に示す.図 3.10 では,1 段目にランダム学習無しの場合の CNN の重みフィルタを示し, 2 段目にランダムな平行移動を与えた場合と,ランダムな回転を与えた場合の重みフィル タをそれぞれ示している.図 3.10 より,ランダム学習無しの CNN のほうがフィルタの濃 淡の差が大きい結果となった. 1 層目 2層目 1 層目 2層目 ランダム学習無し 平行移動のランダム学習あり 回転のランダム学習あり 図 3.10: ランダム学習を導入したときの重みフィルタ 次に,図 3.11 にランダム学習した CNN の各層の特徴マップの可視化結果を示す.図 3.11 では,1 段目では,平行移動のランダム学習をした CNN に,5pixel 左に平行移動さ
3.4. CNNの幾何変換に対する不変性の実験 せた識別サンプルを入力した場合に得られた特徴マップを示している.また,図 3.11 の 2 段目では回転のランダム学習をした CNN に,20◦回転させた識別サンプルを入力した場 合に得られた特徴マップを示している. (c) 回転無しの特徴マップ (d) 回転ありの特徴マップ (a) 平行移動無しの特徴マップ (b) 平行移動ありの特徴マップ Conv Pool Conv Pool Conv Pool Conv Pool 1 層目 1 層目 2 層目 2 層目 図 3.11: ランダム学習を導入したときの特徴マップ 図 3.13(a) にランダム学習をした CNN の学習誤差の推移を示し,図 3.13(b) に誤識別率 の推移を示す.ここで,図 3.13(b) の誤識別率では,識別サンプルに幾何変化を与えてい ないものとする.図 3.13(a) と図 3.13(b) より,回転のランダム学習をした CNN は学習誤 差,誤識別率ともに誤差が振動しつつ減少していることが確認できる.しかし,平行移動 のランダム学習の場合,誤識別率は振動しつつ減少はしているが,誤識別率はランダム学 習していない CNN よりも高い結果となった.学習誤差に関しては,誤差の減少が見られ なかった.
表 3.2 に,各幾何変化に対する最小誤識別率を示す.比較する手法は,多層パーセプト ロン,ランダム学習無しの CNN,ランダム学習ありの CNN で比較を行う.表 3.2 より, CNN にランダム学習を導入することによって幾何変化により頑健な特徴抽出が可能であ ることがわかった. 表 3.2: 実験で識別サンプルに与えた幾何変化 比較する手法 左に 2pixel 右に 2pixel 20◦回転 MLP 25.79 23.63 11.41 ランダム学習無しの CNN 3.98 4.80 6.27 ランダム学習ありの CNN 2.11 1.80 4.38 ■ 考察 ランダム学習により得られた重みフィルタは,濃淡の差が少なく従来の CNN よりもラ ンダムなパターンのフィルターが得られた.そこで,各 epoch の重みフィルタの変化を 確認し,ランダム学習について考察する.図 3.13 に,ランダム学習によって重みフィル タを各 epoch で表したものを示す.図 3.13 より,ランダム学習ありの CNN はランダム学 習なしの CNN に比べてフィルタの更新のペースが遅いことがわかる.そのため,ランダ ム学習の場合は epoch 数を増やして重みフィルタの傾向を調査する必要がある.しかし, 表 3.2 でランダム学習無しの CNN よりも幾何変化に対して不変性を向上できたことから, epoch 数の増加により更なる不変性の獲得に期待できると思われる.
3.4. CNNの幾何変換に対する不変性の実験 1e-006 1e-005 0.0001 0.001 0.01 0.1 1 10 100 20 40 60 80 100 Cross entropy epoch
Parallel Shift Learning CNN Rotation Learning CNN No Random Learning CNN 0.1 1 10 100 10 20 30 40 50 60 70 80 90 100 Miss rate[%] epoch
Parallel Shift Learning CNN Rotation Learning CNN No Random Learning CNN
(a) ランダム学習による CNN の学習誤差の推移
初期状態 1epoch 2epoch 3epoch 4epoch 5epoch 100epoch ランダム学習無し 50epoch 平行移動ランダム学習 回転ランダム学習 図 3.13: 各 epoch の重みフィルタの推移
おわりに
本論文では,Convolutional Neural Network における特徴抽出の不変性の調査を行った. 各章について以下にまとめる. 1 章では,従来のパーセプトロンモデルである単純パーセプトロンと多層パーセプトロ ンについて述べた.また,多層パーセプトロンの学習方法である誤差逆伝播法を用いた勾 配降下最適化法について述べた.多層パーセプトロンは多クラスの非線形識別が可能であ り,パーセプトロンの構造次第では大きな性能を出すことが可能なため,今現在でも研究 が進められている.
2 章では,Deep Learning の一種である,Convolutional Neural Network について述べ た.Convolutional Neural Network をはじめとする Deep Learning では,機械学習により 特徴量を自動生成するという新しいアプローチを持つ手法である.Convolutional Neural Network では,中間層の畳み込み処理とプーリング処理の繰り返しにより特徴量を自動生 成している.また,従来の多層パーセプトロンは中間層の層数を複数用いて学習をするの が難しいが,Convolutional Neural Network ではユニット間の重みの過疎性を利用して, 中間層を複数用いて学習できるために高い性能を出すことができる.
3 章では,Convolutional Neural Network を対象として,特徴量の学習が識別に対して 有効性を調査するために,特徴量の自動生成の過程を調査し,自動生成された特徴量の有 効性を調査した.実験の結果,自動生成された特徴量は,学習によって識別に有効な特徴 量に変化しており,自動生成された特徴量は微小な変化に対して不変性を獲得しているこ とが確認できた.Convolutional Neural Network の場合,学習過程にプーリング処理が行 われているため,不変性が獲得できたと考えられる.また,従来の学習方法であるランダ ム学習を Convolutional Neural Network に取り入れた場合に,自動生成される特徴量が幾 何変化に対する不変性を向上できる特徴に変化していることが確認できた.
Convolutional Neural Network が,従来の多層パーセプトロンと比べて高い精度と不変 性を持っていることを確認できた.しかし,特徴量の自動取得することで識別時間が多
謝 辞
本研究を行うにあたり,終始懇切なるご指導を頂きました中部大学藤吉弘亘教授に謹んで 感謝します.次に本論文の作成にあたり,有意義な御助言,御指導頂いたオムロン株式会 社山下隆義氏,中部大学博士研究員 山内悠嗣氏,中部大学大学院工学研究科情報工学専 攻 三品陽平氏,に心から厚く御礼申し上げます.最後に,本研究において,アドバイス や相談等に協力していただいた藤吉研究室の皆様に感謝致します.[1] D. Rumelhart, G. Hintont, and R. Williams, “Learning representations by back-propagating errors”, Nature, pp.533-536, 1986.
[2] G. E. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov, “Im-proving neural networks by preventing co-adaptation of feature detectors”, CoRR, vol.abs/1207.0580, 2012.
[3] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks”, Advances in Neural Information Processing Systems 25, pp.1106–1114, 2012.
[4] N. Dalal, and B. Triggs, “Histograms of oriented gradients for human detection”, International Conference on Computer Vision & Pattern Recognition, vol.2, pp.886-893, 2005.
[5] D. G. Lowe, “Object recognition from local scale-invariant features”, Proceedings of the International Conference on Computer Vision-Volume 2 - Volume 2, pp.1150–, IEEE Computer Society, 1999.
[6] Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, and L. D. Jackel, “Backpropagation applied to handwritten zip code recognition”, Neural Computation, vol.1, pp.541-551, 1989.
[7] J. W. Kimball, “Kimball’s biology pages”, , 2000, http://www.dls.ym.edu.tw/ol biology2/ultranet/visualprocessing.html.
[8] K. Fukushima, and S. Miyake, “Neocognitron: A new algorithm for pattern recog-nition tolerant of deformations and shifts in position”, Pattern Recogrecog-nition, vol.15, no.6, pp.455–469, 1982.
[9] F. Rosenblatt, “The perceptron: A probabilistic model for information storage and organization in the brain”, Psychological Review, vol.65, no.6, pp.386-408, 1958. [10] S. Patrice, V. Bernard, L. Yann, and D. John S, “Tangent Prop: a formalism for
specifying selected invariances in adaptive networks”, NIPS, pp.895–903, 1991. [11] B. Y. D. H. Hubel, and A. D. T. N. Wiesel, “Receptive fields, binocular interaction
and functional architecture in the cats visual cortex”, The Journal of physiology, vol.160, pp.106–154, 1962.