低レイテンシ1対1結合マルチポート・インターリーブ・キャッシュの評価
21
0
0
全文
(2) 2. 情報処理学会論文誌:ハイパフォーマンスコンピューティングシステム. 本論文では,データ・キャッシュの低レ イテンシ,お よび,高バンド 幅を実現する機構について検討する.. Nov. 2001. 本研究の目的は,マルチポート・インターリーブ・ キャッシュのレ イテンシの改善にある.この目的のた. キャッシュのレ イテンシを削減するには,ヒット率. めに,我々は文献 6) で提案されているロード /スト. を向上させ,アクセス時間を短くすることが必要であ. ア・ユニットとインターリーブ・キャッシュの各バン. る.ヒット率は,連想度を上げ容量を増加させること. クを 1 対 1 で結合する構成に着目した7),8) .本構成の. で改善できるが,連想度の増加は複雑さを急速に増加. キャッシュを搭載するプロセッサでは,命令を命令ウィ. させるので,大きな改善のためには容量を増加させる. ンド ウへ書き込む前に,何らかの方法によりアクセス. ことが必要である.しかし一方で,容量を増加させる. するバンクを求める.命令ウィンド ウからは,決定さ. とアクセス時間が増加するので,トレードオフが存在. れたバンクに結合されたロード /ストア・ユニットに. する.特に,近年のディープ・サブミクロン半導体技. 発行され,目的のバンクにアクセスする.本方式は,. 術においては,ゲート遅延に比べて配線遅延が大きく. インターリーブ・キャッシュから複雑な相互結合網を. なっているため,アクセス時間の増大は深刻化してい. 削除することにより,レイテンシを低減することがで. る.このため,容量を大きくすることでレイテンシを. きる.また,アクセス時間はバンクを構成する小さな. SRAM のアクセス時間で決まるため,これによって. 削減することが困難になってきている. 一方,キャッシュのバンド 幅拡大については,同時. もレ イテンシを低減することができる.以上 2 つの. に複数のアクセス要求に応える必要があるため,通常,. 効果により,スケーラビリティの高い大容量,マルチ. マルチポート化により対応している.マルチポート化. ポートのキャッシュを構成することができると考えら. には,一般には次の 4 つの方法がある.1 つは,メモ. れる.本方式の有効性について,文献 6) では,2 バ. リ・セルをマルチポートにすることである.この方法. ンクの場合に限定し,簡単な評価が行われている.し. は,各ポートから独立にキャッシュをアクセスすること. かし,バンク数が 2 より大きな場合の評価や,キャッ. ができるという点で理想的であるが,実現に高いコス. シュのアクセス時間やスーパスカラ・プロセッサの動. トを要する.また,バンド 幅に対しスケーラビリティ. 的スケジューリングの効果を考慮した詳細な評価は行. がない.2 つめの方法は,空間的多重化である.この方. われておらず,有効性の定量的確認が不足している.. 法は,キャッシュのコピーを必要なポート数だけ用意. 本論文では,これらの点を考慮した詳細な評価を行う.. することにより,マルチポート化するものである(た. 以下,ポート数分のロード /ストア・ユニットを用意. とえば,Compaq Alpha 211641) ) .この方法は,読み. し,インターリーブ・キャッシュの各バンクと 1 対 1. 出しに関しては,単一ポートのキャッシュのアクセス. で結合する構成のキャッシュのことを,PPC キャッ. 時間を維持したまま,バンド 幅拡大を実現できるとい. シュ( point-to-point connected cache )と呼ぶ.. う点で優れている.しかし書き込みについては,複数. 2 章ではキャッシュのアクセス時間について概説す. のコピーの内容を同一にするために,データのストア. る.3 章では提案の構成と機構について説明する.4. はすべてのコピーに行わなければならないため,バン. 章では提案機構を評価する.5 章で関連研究について. ド 幅は拡大しないという欠点がある.また,複数のコ. 述べ,6 章で本研究をまとめる.. ピーが必要なので高コストである.3 つめの方法は,時 間的多重化である.単一ポートのキャッシュを 1 サイク. 2. キャッシュのアクセス時間. ルに複数回アクセスすることにより,マルチポートを. 本章では,キャッシュのアクセス時間について概説す. .この 実現する(たとえば Compaq Alpha 212642) ). る.最初に単一ポートの場合について,次にインター. 方法は低コストであるが,多くのポートを必要とする. リーブによるマルチポートの場合について説明する.. 将来のプロセッサでは使えない.最後の方法は,キャッ. 2.1 単一ポート ・キャッシュ. シュを複数のバンクに分割してインターリーブする方. キャッシュはデータ・アレ イとタグ・アレ イの 2 つ. 法である.この方法では,前述の 3 つの方法に比べ,. の部分よりなる.アクセス時間は,それぞれの信号. バンクにおけるアクセス競合によるバンド 幅低下や,. パスの長い方で決まる.データ・アレ イおよびタグ・. ロード /ストア・ユニットとバンクを結合する相互結. アレ イそれぞれの信号パスの遅延時間 Taccess (data),. 合網によるアクセス時間増大という問題があるが,コ. Taccess (tag) は,以下の式で表される. Taccess (data) = Taddr (data) + Tdecode (data). ストとスケーラビリティの点で優れている.このため, 多くのプロセッサで採用されている(たとえば,Intel 3). 4). 5). Pentium ,MIPS R10000 ,AMD Athlon ) .. + Twordline (data) + Tbitline (data).
(3) Vol. 42. No. SIG 12(HPS 4). 低レ イテンシ 1 対 1 結合マルチポート・インターリーブ・キャッシュの評価. 3. でサブアレ イを選択する.選択されたサブアレ イか. 8BA. らの出力は,トライステート・バッファを介して出力 8BA S. 8BA. バスに出力される.アドレス・デコーダは,サブアレ イに多く分割するほどその複雑さが低減されるので,. Data Array Data Array. S/2. Data Array. Tdecode (array) が短くなる.また,ビット線が短くな るので Tbitline (data) が短くなる.しかし一方で,ア ドレスは複数のアレイに分配されなければならないの. Output Bus. Output Bus. で,Taddr (array) が長くなる.また,出力バスに結 合されるトライステート・バッファ数の増加と出力バ. (a) 元の構成. (b) ビット方向に分割した構成. 図 1 アクセス時間を削減するためのキャッシュの構成例 Fig. 1 Cache organization example to reduce the access time.. ス長の増加により Toutput (array) が長くなる.さら に,タグ・アレイとデータ・アレ イの距離が増加する ので,Tselect (tag) が長くなる.これらは,アレ イや 出力マルチプレ クサの配置を工夫10) することにより. + Tsense (data) + Tselect (data) + Toutput (data). 改善されるが,依然としてアクセス時間に大きな影響 を与え,アレ イ分割とトレード オフの関係にある. 分割にはこのほかワード 方向の分割がある.この分. Taccess (tag) = Taddr (tag) + Tdecode (tag) + Twordline (tag) + Tbitline (tag) + Tsense (tag) + Tcmp (tag) + Tselect (tag) + Toutput (data) ここで,Taddr (array),Tdecode (array) ,. 割では,ワード 線が短くなるので Twordline (array) が 短くなる.一方でアドレス・デコーダの数が増えるの で,Taddr (array) が長くなる. 以上述べたように,分割にはトレード オフが存在す るが,一般には,容量が大きいほど最適なサブアレイ. Twordline (array),Tbitline (array),Tsense (array) は. 数は多くなる.. それぞれ,array ∈ data, tag 側のアドレス駆動遅延, 遅延,センス・アンプ 遅延である.Tselect (data) は. 2.2 インターリーブ・キャッシュ マルチポート・インターリーブ・キャッシュの遅延 時間は,単一ポート・キャッシュの場合に比べて増加. アレ イから読み出されたデータから要求されている. する.これは,インターリーブ・キャッシュにはバン. アド レ ス・デコード 遅延,ワード 線遅延,ビット 線. データを選択する出力マルチプレ クサを通過する遅. クとポートとの相互結合網(通常クロスバー)が必要. 延,Tselect (tag) はその出力マルチプレクサを制御す. なためである.しかし前節で述べたように,高速化の. る遅延, Tcmp (tag) はタグ比較の遅延,Toutput (data). ために一般にキャッシュは,物理的にすでに複数のサ. は出力バスの遅延である.. ブアレイに分割され,それらはバスで結合されている. キャッシュの各アレ イは,論理的には 1 つのアレ イ であるが,アクセス時間を短縮するために,物理的に. ので,これを拡張してクロスバーを形成すれば,遅延 が大きく増加することはない.. は通常複数に分割されている9) .図 1 に,1 つのデー. 図 2 に,データ・アレイから読み出されたデータを. タ・アレイをビット方向に 2 つに分割した例を示す.図. 出力バスに出力する論理回路を示す.この図は,デー. において,A は連想度,B はブロック・サイズ(単位. タ・アレ イが 2 つに分割された場合の例である.同. :バイト ) ,S はセット数である.同図 (a) に示した単. 図 (a) は文献 11) に示されている単一ポートの場合の. 一のアレイの場合,log2 S ビットのアドレスをデコー. 回路であり,(b) は 2 ポートのインターリーブに対応. ド するデコーダにより,S 本のワード 線の中の 1 本を. するように拡張した回路である(実際の回路は,大き. 駆動する.ワード 線により選択されたセルは,ビット. な負荷を駆動するド ライバが挿入されているなど高速. 線を駆動し,センス・アンプにより信号は増幅される.. 化のための工夫がある.ここでは図を簡単化するため. タグ比較結果から得られる選択信号(図では省略)に よってデータが選択され,バスに出力される. 同図 (b) は,ビット方向に 2 つに分割した場合で. に論理のみ示す) .単一ポートの場合,タグ比較結果 ( tag match0/1 )とアドレスから生成されるアレ イを 指定する信号( array0/1 )の論理積をとった信号を,. ある.各アレ イをサブアレイと呼ぶ.log2 S − 1 ビッ. トライステート・バッファの制御ピンに与え,アレイ. トのアドレスが両方のサブアレイに与えられ,データ. の出力を選択し,データ・バスを介してデータ・ポー. が読み出される.アドレスの第 log2 S 番目のビット. トに出力する.これに対して 2 ポートの場合,まず,.
(4) 4. Nov. 2001. 情報処理学会論文誌:ハイパフォーマンスコンピューティングシステム. Data Array1. tag match0. L/S. Register File. array0 tag match1. N-ported D-cache. ALU. array1 L/S. Interconnection Network. data port. Instruction Window. ALU Reorder Buffer. Data Array0. Bank. Bank. (a) 単一ポート Fig. 3 Data Array0. 図 3 基本スーパスカラ・プロセッサの構成 Baseline superscalar processor organization.. Data Array1. これに対して,網のスイッチは単一ポート・キャッ シュには必要ないので,つねに遅延増加を引き起こす. data port0. スイッチに要する時間の多くは,どのアレイの出力を どの出力バスに出力するかの選択肢が増えることによ. data port1 tag match0 array0&port0. るものである.図 2 に示した回路では,タグ比較結果 を出力するゲートのファンアウトが増加することによ り遅延が増加する.. array0&port1 tag match1 array1&port0. 3. 1 対 1 結合インターリーブ・キャッシュ. array1&port1. 本章ではまず最初に,本論文で仮定するスーパスカ (b) 2 ポート 図 2 出力回路 Fig. 2 Output circuit.. ラ・プ ロセッサの基本構成を述べる.その後,PPC キャッシュを組み込んだ構成を示す.次に,命令発行 前にバンク番号を求める機構について述べる.さらに,. 2 つのポートに出力する 2 つのバスを用意し,各アレ イの出力を 2 つのバスにトライステート・バッファで. ロード /ストア命令が使用できるアドレシング・モー. 結合する.選択は,タグ比較結果とアレイを指定する. ドとして,最も一般的なベース相対のみの場合を考え. 信号に加え,どのポートに出力するかを指定する信号. るが,このほかによくサポートされているアドレシン. ( port0/1 )の論理積とする. クロスバーによる遅延について詳し く考えてみる.. 本機構を強化する方式について説明する.本論文では,. グ・モードとして,インデクス修飾の場合について議 論する.最後に,PPC キャッシュをプロセッサに組み. クロスバーによる遅延は,網をデータが通過する時間. 込むには,アドレス計算とキャッシュ・アクセスを別々. と網のスイッチを制御(図 2 では,トライステート・. にスケジューリングする分離ロード /スト アと呼ばれ. バッファの選択)する時間の 2 つに分けられる.ま. る方式が必要であるが,その長所と短所について議論. ず,データ通過時間について考える.キャッシュの容. する.. 量が小さい場合,アクセス時間を最小とするサブアレ イ数は少ない.インターリーブ・キャッシュに必要な. 3.1 基 本 構 成 図 3 に,本論文で仮定するスーパスカラ・プロセッ. バンク数が,最適なサブアレイ数より多い場合,必要. サの基本構成を示す.図 4 には,ロード /ストア命令. 以上に分割されることとなる.これによりアクセス時. のパイプライン構成を示す.フロントエンドは,本研. 間が増加する.一方,容量が大きい場合,アクセス時. 究には無関係なので省略している.. 間最小の構成では,多くのアレイに分割される.必要. 命令はデコード 後,レジスタ・ファイルとリオーダ・. なバンク数より最適なサブアレイ数が多くなれば,こ. バッファを参照しオペランドを得,命令ウィンドウに書. のようなペナルティを課せられることがないため,イ. き込まれる.命令ウィンド ウより命令は各機能ユニッ. ンターリーブによる遅延増加は小さい.明らかなこと. トに発行され実行される.ロード /ストア命令につい. であるが,ポート数が多いほどこのペナルティを被ら. ては,さらにデータ・キャッシュをアクセスする.デー. ないキャッシュ容量の下限が上がる.. タ・キャッシュの長いアクセス時間がクロック・サイ.
(5) No. SIG 12(HPS 4). 1. 2. 3. 4. 5. 6. Reg Read. Dispatch. Issue. Addr Gen. D-Cache1. D-Cache2. Reg Write. Fig. 4. Select. Win Read. 図 5 Dispatch と Issue ステージでの処理内容 Fig. 5 Breakdown of Dispatch and Issue stages.. クル時間に与える悪影響を避けるため,最近の高速な プロセッサでは,アクセス動作はパイプライン化され ている場合が多い.この例では 2 段にパイプライン化 されている.. 3.3 節での説明を容易にするために,命令ウィンド. ALU. Instruction Window. Wakeup. Issue. option. Dispatch Win Write. 5. 図 4 基本プロセッサにおけるロード /ストア命令のパイプライン Pipeline for load/store instructions in the baseline processor.. Reorder Buffer. Load/Store Instruction. 0. Register File. Cycle. 低レ イテンシ 1 対 1 結合マルチポート・インターリーブ・キャッシュの評価. Bank Number Calc/Pred. Vol. 42. ALU. N-ported PPC D-Cache. L/S. Bank. L/S. Bank. 図 6 PPC を搭載するスーパスカラ・プロセッサの構成 Fig. 6 Superscalar processor organization with the PPC cache.. ウへの書き込みから発行までの処理をより細かく分解 して説明する.図 5 に,Dispatch と Issue の 2 つの. ンクを構成する小さな SRAM のアクセス時間で決ま. パイプライン・ステージの処理内容とタイミングを示. るため,これによってもレイテンシを低減することが. す.Dispatch ステージの前半で,命令は命令ウィンド. できる.一方,欠点としては,通常のインターリーブ・. .後半では,次のサ ウに書き込まれる( Win Write ). キャッシュと比べ,データパスが大きくなる場合があ. イクルに実行が終了する命令の結果タグが命令ウィン. ることである.バンク数と同数のロード /ストア・ユ. ド ウにブロードキャストされ,タグ比較の結果,参照. ニットが必要なため,バンク数を多くしバンク競合を. オペランドが利用可能かど うかを表すフラグが更新さ. 削減しようとした場合,従来構成よりも多くのロード /. .次に Issue ステージの前半で,参照 れる( Wakeup ). ストア・ユニットが必要になる.このようなことは通. オペランドがそろっている命令の中から,発行する命. 常のインターリーブ・キャッシュでは必要ない.ロー. ,後半で,選択された命令が命 令が選択され( Select ). ド /ストア・ユニットの増加によりコスト増加,バイ. 令ウィンド ウより読み出され,機能ユニットに送り出. パス遅延の増加などが生じる.. . される( Win Read ). 3.3 バンク番号の計算と予測 BNU はバンク番号を得るユニットである.バンク 番号を得るには,計算による方法や予測による方法が. 3.2 PPC キャッシュを組み込んだ構成 図 6 に PPC キャッシュを組み込んだスーパスカラ・ プロセッサの構成を示す.基本構成との大きな違いは 次の 2 点である.第 1 に,バンク数と同数のロード /. 考えられる.本節ではそれらの方法について説明する.. 3.3.1 バンク番号の計算. ストア・ユニットを用意し,それらとバンクを 1 対 1. バンク番号を計算により求める場合,レジスタ・ファ. で結合する.第 2 に,命令ウィンド ウに命令を書き. イルあるいはリオーダ・バッファよりベース・レジスタ. 込む前に,アクセスするバンクの番号を計算あるい. を得た後,アドレスの下位よりバンク番号が得られる. は予測により求めるユニット( BNU: bank number. 桁までオフセットを加算して求める.この方法はレジ. calculation/prediction unit )を設ける.得られたバ. スタ参照時にベース・レジスタがすでに利用可能な場. ンク番号を命令とともに命令ウィンド ウに書き込む.. 合にのみ可能である.計算はアドレスの下位のみなの. 発行時に参照し目的のロード /ストア・ユニットに命. で,計算時間は短い.たとえば,ワードによる 4 ウェ. 令を発行する.ロード /ストア・ユニットで実効アド. イ・インターリーブの場合,4 ビットの計算ですむ.. レスを計算し,結合されたバンクにアクセスする.. PPC キャッシュは,インターリーブ・キャッシュか ら複雑な相互結合網を削除することにより,レイテン シを低減することができる.また,アクセス時間はバ. 計算によってバンク番号を得る場合のロード /スト ア命令のパイプラインを,図 7 に示す.PPC キャッ シュのアクセス時間は従来のキャッシュより短いので, ˙ に,BNU 1 サイクルでアクセスできるとする.図 7(a).
(6) 6. Nov. 2001. 情報処理学会論文誌:ハイパフォーマンスコンピューティングシステム Cycle Load/Store Instruction. 0. 1. Dispatch Reg Read (Bank Calc). 2. 3. 4. 5. Issue. Addr Gen. D-Cache. Reg Write. (a) ベース・レジスタが利用可能な場合. Cycle Load/Store Instruction. 0. 1. Dispatch Reg Read (Bank Calc). 2. 3. 4. 5. Issue. Addr Gen. D-Cache. Reg Write. (b) ベース・レジスタが利用可能でない場合 Fig. 7. 図 7 BNU でバンク番号を計算して得る場合のパイプライン Pipeline when bank numbers are obtained by calculation in BNU.. においてバンク番号が得られる場合のパイプライン構. るが,本方式では 2 度目の発行サイクルを隠蔽できな. 成を示す.Dispatch ステージの前半でバンク番号を 計算し,後半で命令ウィンド ウに書き込む.書き込ま れたバンク番号は,命令がどの資源を要求するかを示. い点が異なる.図 8 に命令の発行タイミングの詳細 を示す.図の上方にあるサイクル番号は,図 7 (b) の. すフラグの 1 つであり,Issue ステージの Select 時に. トアの場合である.アドレス計算とオーバラップして. 参照される.バンク番号の書き込みタイミングは,命. キャッシュ・アクセス操作の発行動作を行うことがで. 令ウィンド ウへの命令の書き込みタイミングより半サ. きるため,オーバヘッドは生じない.同図 (b) に PPC. それと対応している.図 8 (a) は通常の分離ロード /ス. イクル後ろとなるが,参照は Issue ステージなので問. キャッシュにおける場合を示す.アドレス計算の前半. 題ない.この仕様に合わせて,命令が要求するその他. にバンク番号が得られ( Bank Calc ) ,そのサイクル. の資源についても,要求資源フラグをセットするタイ. の後半に命令ウィンド ウの当該エントリの要求資源フ. ミングを Dispatch の後半に変更する.. .次のサイクルに選 ラグを更新する( Update R-flag ). 一方,ベース・レジスタが利用可能でないために,. 択,命令ウィンド ウの読み出しが行われ,再発行を完. BNU でバンク番号が得られない場合,利用可能にな. 了する.以上のように,PPC キャッシュの場合,ロー. るのを待つのではなく,通常どおり命令ウィンド ウに. ド /ストア・ユニットはキャッシュのバンクと 1 対 1 で. 書き込む.その後,分離ロード /ストアと同様の動作. 結合されているため,資源要求の調停のためにバンク. で,アドレス計算の後,目的のロード /ストア・ユニッ. 番号が必要である.このため,バンク番号が命令ウィ. トに発行する.ここで,分離ロード /ストアとは,1 つ. ンド ウに書き込まれなければ,発行する命令の選択を. のロード /ストア命令を,アドレス計算とキャッシュ・. 開始することができない.このようなことは通常の分. アクセスの 2 つの操作に分解し,それらを別々にスケ. 離ロード /ストアは生じない.このため,再発行に余. ジュールし実行する方式をいう.図 7 (b) にパイプラ. 分に 1 サイクルを要する.つまり,再発行のサイクル. イン示す.サイクル 2 に,ベース・レジスタが利用可. が,BNU でバンク番号を得られなかったことによる. 能になるとする.命令は,実効アドレスを計算するた. ペナルティということができる.. め ALU に発行される.このとき,通常の命令発行と. 計算によりバンク番号を得る方法では,数ビットの. 異なり,当該命令が格納されている命令ウィンド ウの. 加算器が必要なだけなので,3.3.2 項で述べるストラ. エントリを削除しない.サイクル 3 で実効アドレスを. イド 予測による方式より低コストであるという利点が. 計算する.このサイクルの早期にバンク番号を得るこ. ある.一方,欠点としては,4 章で評価を行うが,ベー. とができるので,命令ウィンド ウ内の当該命令のエン. ス・レジスタが計算時点で利用可能である確率があま. トリに,得られたバンク番号を書き込む.サイクル 4. り高くないという点である.このため,PPC キャッ. では,命令ウィンド ウの当該命令のエントリに実効ア. シュの恩恵を得る機会が減少する.もう 1 つの欠点. ドレスが書き込まれ,再スケジューリングされて目的. は,実装によってはクロック速度に悪影響を与える可. のロード /ストア・ユニットに再発行される.サイク. 能性があることである.本説明では,命令の Dispatch. ル 5 では,ロード /ストア・ユニットのアドレス計算. と Issue を 2 サイクルで行うプロセッサを仮定したた. 回路をバイパスし,データ・キャッシュをアクセスす. め,バンク番号の計算を Dispatch ステージの前半に. る.サイクル 6 で得られたデータを書き込む.. 組み込むことができ,クロック速度に影響を与える可. 以上の動作は,分離ロード /ストアとほぼ同一であ. 能性を少なくすることができた.しかし,Dispatch と.
(7) Vol. 42. No. SIG 12(HPS 4). 低レ イテンシ 1 対 1 結合マルチポート・インターリーブ・キャッシュの評価 2. Cycle. 3. Issue Address Calc. 7. 4. Addr Gen Win Read. Select. Issue Select. Cache Access. D-Cache Win Read. (a) 通常の分離ロード /ストアの場合. (b) PPC キャッシュにおいて BNU でベース・レジスタが利用可能でない場合 図 8 通常の分離ロード /ストアと PPC キャッシュにおける命令発行のタイミング Fig. 8 Timing of instruction issue in usual split load/stores and PPC cache.. Issue を 1 サイクルで行うようなプロセッサでは,ク. い,それに従って投機的にロード /ストア・ユニット. ロック速度に影響を与えてしまう.レジスタ読み出し. に発行すれば,レ イテンシ削減に効果がある.. のステージで行うように変更しても,レジスタ読み出. バンク予測として,大きく分けて 2 つの方法を示. しはクリティカル・パスの 1 つであるから,やはりク. す.1 つは,最新のベース・レジスタが利用できない. ロック速度に影響を与える可能性がある.この問題は,. 場合,その以前の値を予測値とし,計算により求める. 計算するビット数を減らすことができれば低減するこ. 方法を提案する.以下これを古いレジスタ予測方式と. とができる.もし 桁上げを予測することができれば,. 呼ぶ.ベース・レジスタの更新によってバンク番号が. バンク番号指定に使用する桁のみの加算ですませるこ. 影響を受けないなら,予測は正しいものとなる.たと. とができる.我々は文献 8) において,論理積 1 ゲー. えば,ワードによる 4 ウェイ・インターリーブの場合,. トを用いた予測方法を提案した.この方法では,たと. 4 ワード の整数倍のストライドで変化するならば,ア. えばライン・インターリーブでは,ベース・レジスタ. クセスするバンクは変化しないので 100%正しく予測. とオフセット値におけるライン内オフセット部( LO:. できる.また,ベースが 1 バイトのストライドで変化. line offset )の最上位ビットの論理積をとったものと. する場合,ベース・アドレスの変化がワード 境界を超. する.LO の最上位桁のレジスタ値とオフセット値が. えるときのみ予測を誤るので,75%の予測精度を得る. (1,1) のときに桁上がりがあり,(0,0) のときには桁上. ことができる.この方法は,予測に要するコストが非. がりがないことを利用するものである.(1,0) あるい. 常に小さいという利点がある.一方,バンク番号を得. は (0,1) のときは LO の最上位より下位のビットに依. るためには計算が必要なため,実装によっては前述の. 存するが,これらのビットがランダムでも 50%の確率. ようにクロック速度に影響を与える可能性がある.. で予測は成功する.したがって,この予測手法は,最. 2 つめの方法は,一般的なアドレス予測方式を修正. 終的には 75%程度の確率で成功すると考えられる.ま. して用いる方法である6),12) .バンク予測は,アドレ. た,オフセット値は 0 である確率は高く(文献 8) での. ス予測13)∼17) のサブセットと考えられる.予測器の修. ,このときは桁上がりはないので,予 測定では 24% ). 正には,バンク予測に特化するいくつかの方法が考え. 測成功の確率はさらに高いと期待できる.. られる.まず,バンク番号はアドレ スの一部なので,. 3.3.2 バンク予測と予測失敗からの回復動作 3.3.1 項で述べた方法では,バンク番号計算時にベー. 値履歴表にはバンク番号を指定する部分を含むアドレ. ス・レジスタが利用可能でない場合,1 サイクルのペ. 幅に削減できる.また,後述するが予測誤りによるペ. ナルティを被る.これに対し,バンク番号の予測を行. ナルティは小さい.加えて,少ないバンクを予測する. スの下位のみ保持すればよい.これによりコストを大.
(8) 8. 情報処理学会論文誌:ハイパフォーマンスコンピューティングシステム. Nov. 2001. ことは比較的容易である.以上を考慮すると,タグ・. ンク番号を求める計算時間は変わらない.2 つのレジ. チェックや信頼性推定機構を省略する選択肢がある.こ. スタが利用可能な確率は,1 つのレジスタが利用可能. れらは予測率( 全ロード /ストア命令に対し正し くバ. な確率より低いので,計算可能な確率は下がり,BNU. ンクを予測できた割合)の向上とコスト削減の効果が. としてのこの方式の有効性は低下する.古いレジスタ. ある.古いレジスタ予測方式と異なり,レジスタ読み. の予測でも同様に,2 つのレジスタの参照が必要なた. 出しと並行して予測を行うことができるので,クロッ. め,予測精度は低下する.ストライド 予測については,. ク速度への影響はほとんどない.. アドレスをどのようにして生成するかは,アドレスの. 予測により命令が発行される場合,その検証はアド レス計算時に行う.発行後も予測誤りに備えて,命令 ウィンド ウのエントリを削除せず,予測が正しいこと. 履歴とは無関係なので,予測精度は変わらないと思わ れる.. 3.6 分離ロード /スト ア. が分かった時点で削除する.予測が誤りと分かった場. PPC キャッシュでは,前述のように,分離ロード /. 合,3.3.1 項で説明した方法と同様の手順で,命令を. ストア方式を使用しなければならない.本節では,分. 再発行する.再発行のための 1 サイクルが,予測誤り. 離ロード /ストアの長所/短所について議論する.. のペナルティである.また,命令ウィンド ウのエント. 短所としては,まず命令発行バンド 幅をより多く消. リの削除が遅れるので,命令ウィンド ウがより頻繁に. 費するということがあげられる.また,アドレス計算. 一杯になるという問題がある.これも実装によっては,. に ALU を用いるので,ALU がより多く消費される.. ペナルティとして課せられる.. これらにより IPC( instruction per clock cycle )が低. 3.4 性能向上のための強化 予測により命令を発行する場合,使用されないすべ てのロード /ストア・ユニットに対しブロード キャス. 下する可能性がある.回路上の短所としては,通常の. トすれば,たとえ予測を誤ってもペナルティを被る確. れの遅延が設計目標を満たさなければならないという. 場合,アドレス計算とキャッシュ・アクセスの遅延の合 計が設計目標を満たせばよいが,分離すると,それぞ. 率を下げることができる6) .ブロード キャストを行う. ことがあげられる.アドレス計算のサイクルにキャッ. 命令の選択方法としては,たとえば,予測により発行. シュ・アクセスの一部の回路を移動させることが可能. する命令のうち,プログラム順で最も古いものとする. な通常の場合に対し,そのようなことは分離の場合で. 方法や,予測の信頼性が低いものとする方法が考えら. きない.. れる.. 長所としては,メモリ依存を考慮した正確なスケ. 命令ウィンド ウとすべての機能ユニットの間にはす. ジューリングが可能な点である.メモリ依存を知るた. でに相互結合網が形成されているので,ブロード キャ. めには,データ・アドレスが必要である.分離ロード /. ストによる通信の複雑さの増加はほとんどない.予測. ストアでは,データ・アドレスが命令ウィンド ウの中. ミスを知らせる信号は,ブロードキャストされた各ユ. で参照できるので,アドレスを比較することにより依. ニットからの予測ミス信号の論理積をとる必要がある. 存が判明し,それに基づいた正確なスケジューリング. が,予測の正誤はサイクルの早期に判明するので問題. が可能となる.これに対し ,通常のロード /ストアで. ない.. は,スケジューリング時にアドレスが判明していない. 3.5 インデクス修飾アドレシングの場合. ので,先行するストアがすべて発行されなければロー. 本論文では,ロード /ストア命令が使用できるアド. ドは発行できない.これは偽の依存を発生させること. レシング・モードとして,ベース相対のみの場合を仮 定しているが,このほかによくサポートされているア ドレシング・モード として,インデクス修飾がある.. になり,IPC が低下する. 分離ロード /ストアで,メモリ依存を解析してスケ ジューリングする場合,命令ウィンド ウにアドレスを. たとえば,SPARC では,ベース相対とインデクス修. 格納するサイクルが必要となる.このサイクルを必要. 飾の両方をサポートしている.本節では,インデクス. なときのみ挿入する最適化は容易である.つまり,先. 修飾アドレシングの場合について議論する.. 行するすべてのストアが発行されているなら,ロード. アドレシング方式が異なるだけなので,これまで説. はアドレス計算に続いてキャッシュをアクセスすると. 明した PPC キャッシュの方式において変更しなけれ. いう方法がとれる.このタイミングでの動作を図 8 (a). ばならない点は,BNU のみである.まず,計算によ. で説明した.. りバンクを求める機構においては,当然であるが,2. 本章の説明では,分離ロード /ストアを 1 つの命. つのレジスタを加えてバンクを求める必要がある.バ. 令ウィンド ウで実装したが,実装の容易さの点から,.
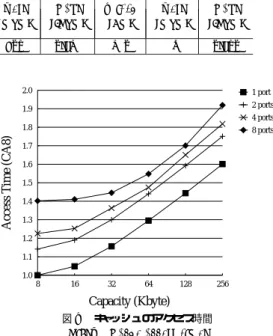
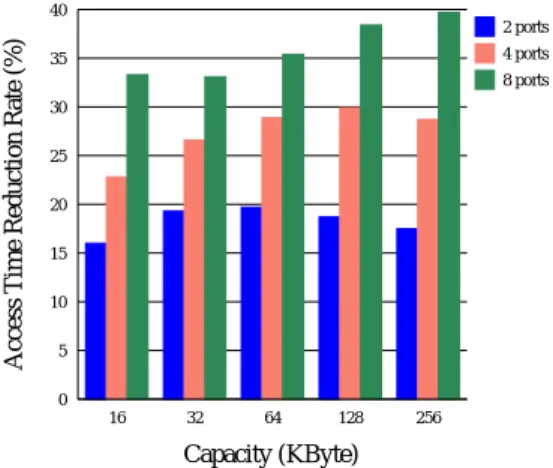
(9) Vol. 42. No. SIG 12(HPS 4). Table 1. Gate Cap. (fF/µm) 1.56. 低レ イテンシ 1 対 1 結合マルチポート・インターリーブ・キャッシュの評価. 9. 表 1 仮定した 0.18 µm プロセス技術におけるトランジスタと配線の特性 Features of transistors and wires in the assumed 0.18 µm process technology.. Transistor Junction Transistor Cap. Res. (fF/µm) (K-µm) 1.51 3.6. Mid-Level Metal Supply Voltage (V) 1.8. Top-Level Metal. Width (nm). Res. (m/m). Cap. (fF/m). Width (nm). Res. (m/m). Cap. (fF/m). 320. 107. 0.253. 530. 36. 0.270. キャッシュ・アクセス操作を別のウィンドウで保持する. 2.0. 方が有利である.一般に,この命令ウィンド ウのこと. 1.9. を LSQ( load/store queue )と呼ぶ.メモリ依存を考. 1.8. う必要があるが,これは別のバッファにする方が実装 が容易である.また,ロードが LSQ 内にとど まって いる先行ストアに依存していた場合,LSQ 内でデータ を受け取るよう回路を構成する必要がある.このフォ ワーディング機構を実装するためにも,別バッファに する方が有利である.ただし,これは実装上の問題で あり,論理的には 1 つのウィンド ウで構成する方法と. 2 ports 4 ports. Access Time (CA8). 慮したスケジューリングのために,アドレス比較を行. 1 port. 8 ports. 1.7 1.6 1.5 1.4 1.3 1.2 1.1 1.0 8. 16. 32. 64. 128. 256. Capacity (Kbyte). エントリ数の違いを除いて等価である.また,3.1 節. 図 9 キャッシュのアクセス時間 Fig. 9 Cache access time.. の基本構成の説明では,一般性を欠かないために,分 離しない通常のロード /ストア方式を仮定したが,分 離ロード /ストアの方が正確なスケジューリングによ. 間を測定できるよう,相互結合網に関わる回路を加え. り高い IPC が得られるので,以下の評価においては,. た.第 2 に,最近のプロセス技術に適応できるように,. 比較対象の基本プロセッサも分離ロード /ストアを仮. トランジスタと配線のパラメータについて次のことを. 定している.. 4. 評 価 結 果. 行った.トランジスタの特性に関し CACTI で仮定さ れているパラメータを,最小加工寸法と電源電圧に対 してスケーリングできるようようにした(たとえば文. 本章では,最初にインターリーブ・キャッシュのア. .配線に関するパラメータは,文献 19) 献 18) 参照). クセス時間の評価を行い,PPC キャッシュによるア. に示されているのものを用いた.表 1 に,測定に用. クセス時間の削減について評価する.次に,BNU の. いた 0.18 µm プロセス・パラメータを示す.我々が仮. 性能によって,PPC キャッシュの実効的なアクセス時. 定したトランジスタ特性は,半導体回路の論文誌に掲. 間が変化するので,それについて評価する.さらに,. 載されている文献,たとえば,文献 20) のものとほぼ. BNU に用いるストライド ・バンク予測器について評. 一致しており,妥当なものと考える.第 3 に,配線遅. 価する.最後に,PPC キャッシュをプロセッサに搭載. 延の影響を小さくするために,サブアレイ配置の最適. した場合の性能を評価する.. 化,負荷の大きなトランジスタのサイジング,長い配. 4.1 キャッシュ・アクセス時間の評価 アクセス時間の評価方法について述べた後,評価結 果を示す.. 4.1.1 評 価 方 法. 線へのリピータの挿入,配線層の使い分け(アレ イ内 部に中層メタル,アレ イ間に高層メタル )を行った. 修正の詳細については,本論文の範囲を超えるので省 略する.. CACTI10),11)を修正し,キャッシュのアクセス時間 を求めた.CACTI は,与えられたキャッシュ容量,ブ ロック・サイズ,連想度の下で,アクセス時間を最小. 4.1.2 アクセス時間 図 9 に,32 バイト・ブロック,2 ウェイ連想で,容 量を 8 K∼256 K バイトで変化させたときのアクセス. にするアレイの分割数と,そのときのアクセス時間を. 時間の測定結果を示す.縦軸は,8 K バイトのキャッ. 求めるプログラムである.我々は,CACTI に対し次. シュのアクセス時間 959 ps で規格化した遅延である.. のような修正を加えた.. 以下では,8 K バイトのキャッシュのアクセス時間の. 第 1 に,インターリーブ・キャッシュのアクセス時. r 倍の遅延のことを,r CA8 と表すこととする.8 KB.
(10) 10. Nov. 2001. 情報処理学会論文誌:ハイパフォーマンスコンピューティングシステム. バイトのキャッシュを基準としているのは,この 10 年 るキャッシュ容量は 8 K∼64 K バイトの範囲で変動し ている.また,キャッシュ・アクセスはプロセッサの クリティカル・パスの 1 つであるため,これがクロッ ク・サイクル時間を決定することがよくある(このた め,プロセッサの世代が新しくなるときに容量が小さ くなることもある) .キャッシュ容量の変動の範囲での 最小値である 8 K バイトでの遅延を基準とすれば,ク ロック・サイクル時間との関係が直感的に分かる.. 40 2 ports. Access Time Reduction Rate (%). 間のハイエンド の多くのプロセッサにおいて,搭載す. 図 9 から分かるように,単一ポートでは,32 K バイ. さい.. 8 ports 30 25 20 15 10 5 0 16. ト以上では,容量を倍にするごとにおよそ 0.14 CA8 で増加していく.16 K バイト以下では,その量は小. 4 ports. 35. 32. 64. 128. 256. Capacity (KByte) 図 10 PPC キャッシュによるアクセス時間の削減 Fig. 10 Access time reduction with the PPC cache.. ポートを増やすと,2.2 節で述べたように,アレ イ の必要以上の分割と相互結合網の遅延でアクセス時 間が増加する.容量が大きい場合( 32 K バイト以上). 4.2 PPC キャッシュの実効アクセス時間 PPC キャッシュを使用することにより,前節で示し. は,遅延増加は相互結合網によるもののみである.1. たアクセス時間削減の利益を享受するためには,BNU. ポートから 2 ポートにすると,網のスイッチ論理が. でアクセスするバンクが正しく得られることが必要で. 必要となり,遅延が大きく増加する.この量はおよそ. ある.3.3 節で述べたように,BNU で正しいバンク. 0.14 CA8 である.ポートをそれ以上にしても,選択 論理のファンアウトが増加するだけなので増加量は小. 番号が得られなければ,1 サイクルのペナルティを被 る.これを考慮に入れたアクセス時間が,PPC キャッ. さく,2 から 4 ポートにするとおよそ 0.05 CA8,4 か. シュの実効的なアクセス時間( effective access time ). ら 8 ポートにするとおよそ 0.07 CA8 増加する.一方,. である.実効アクセス時間は,キャッシュ・アクセス. 容量が小さい場合,アレ イの分割が大きく作用する.. 時間の期待値であり,PPC キャッシュの性能を知るた. この影響は大きく,たとえば,容量 128 K バイトでは. めの指標となる.本節では,実効アクセス時間を評価. 単一ポートから 8 ポートにすると,0.25 CA8 の遅延. する.なお,実効アクセス時間に対し,4.1 節で求め. 増加であるが,容量 8 K バイトでは 0.40 CA8 も増加. たキャッシュそのもののアクセス時間のことを,物理. する.. アクセス時間( physical access time )と呼ぶことと. 図 10 に,PPC キャッシュによるアクセス時間の削. する.. 多くのバンクに分割されるため,PPC キャッシュによ. 4.2.1 評 価 方 法 BNU で正しいバンク番号が得られる確率を CBR. るアクセス時間削減率は大きい.たとえば ,64 K バ. ( correctly bank number obtained rate ) ,正しいバ. イトのキャッシュでは,8 ポートで 35%,2 ポートで. ンク番号が得られなかった場合のペナルティを PPC. 減の割合を示す.一般に,ポート数が多いほど ,より. も 20%ほどアクセス時間を削減できる. また,前述のように単一ポート・キャッシュの遅延 時間は,容量を増加させると,緩やかな増加から急な. ペナルティと呼ぶこととする.PPC キャッシュの実効 アクセス時間は,次の式で求められる. Ef f ectiveaccesstime = P P Cphysicalaccesstime + P CCpenalty × (1 − CBR). 増加傾向を示すので,キャッシュ容量を大きくすれば PPC キャッシュによるアクセス時間削減量も大きくな. ここで,PPC ペナルティは命令の再発行に必要な 1 ク. る.しかし,単一ポート・キャッシュの遅延時間の容. ロック・サイクルに相当する時間であるが,これを以. 量に対する増加量は一定なので(増加率が一定という. 下の計算では PPC の物理アクセス時間とする.キャッ. わけではない) ,PPC キャッシュの効果は容量増加に. シュ・アクセスがプロセッサのクリティカル・パスの. 対し低減の傾向を示す.図 10 より,2 ポートと 4 ポー トの場合でこの現象が見られる.8 ポートの場合は測. 1 つであることはよく知られている.ここでは,PPC キャッシュを導入したプロセッサでも PPC キャッシュ. 定の範囲でこの現象は見られないが,さらに大きな容. のアクセス時間がクロック・サイクル時間を決定する. 量に対して測定すれば観測されると思われる.. と仮定する.この仮定は,キャッシュ以外のクリティ.
(11) Vol. 42. No. SIG 12(HPS 4). 低レ イテンシ 1 対 1 結合マルチポート・インターリーブ・キャッシュの評価. 11. 表 2 ベンチマーク・プログラム Table 2 Benchmark programs.. program compress95 gcc go ijpeg li m88ksim perl vortex. input bigtest.in genoutput.i 2stone9.in specmun.ppm train.lsp ctl.in scrabbl.in vortex.in. カル・パスがクロック・サイクル時間を決定すること があるので,つねに正しいわけではない.特に,1 つ. instructions 95M 84M 75M 450M 183M 420M 80M 80M. % loads 20.8% 26.2% 21.3% 19.1% 25.7% 20.2% 27.5% 30.0%. % stores 13.7% 14.3% 6.7% 7.8% 16.4% 9.8% 18.8% 25.0%. れぞれ 2 倍,4 倍持つ. 命令ウィンドウに RUU を用いているので,命令ウィ. のバンクが小さいほど ,他のパスがクロック・サイク. ンドウのエントリはコミットされるまで削除されない.. ル時間を決定する可能性が大きい.したがって,この. したがって,3.3.2 項で述べた発行後のエントリの削. 仮定の下での PPC キャッシュの実効アクセス時間は. 除の遅れにより命令ウィンド ウ占有時間が長くなるこ. 下限を示すこととなる.このように,以下の測定結果. とによるペナルティは課せられない.ただしコミット. を見るには注意を要するが,BNU を考慮した PPC. も遅れるならば,そのペナルティは課せられたことに. キャッシュの実効アクセス時間を知るうえではよい指. なる.また,従来のキャッシュを用いるプロセッサに. 標と考える.. BNU の CBR は,プロセッサの動的な振る舞いに関 係するため,プロセッサの実行シミュレーションが必. おいてもロード /ストア命令は,LSQ を用い分離方式 で,メモリ依存を考慮した正確なスケジューリングが 行われる.. 要である.シミュレーションには,SimpleScalar Tool. L1 データ・キャッシュは,ポート数以外は全モデル. Set21) 中の out-of-order 実行シミュレータを基に,我々 の機構を組み込んだシミュレータを用いた.命令セッ トは MIPS R10000 である.ベンチマーク・プログ. で同一であり,容量 32 K バイト,32 バイト・ブロッ. ラムには SPECint95 を用い,そのバイナリは GCC. 合 1 サイクルとした.L1 命令キャッシュは完全,L2. ver.2.7.2.3,オプション -O6 -funroll-loops でコンパイ. キャッシュは,単一ポート,容量 2M バイト,統合,64. ク,2 ウェイ連想である.ヒット・レイテンシは,従来 のキャッシュの場合 2 サイクル,PPC キャッシュの場. ルして得た.表 2 に各ベンチマーク・プログラムに. バイト・ブロック,4 ウェイ連想で,6 サイクルのヒッ. 対する入力セット,実行命令数,ロードとストアの占. ト・レイテンシ,36 サイクルのミス・レイテンシとし. める割合を示す.入力は,測定時間が過大にならない. た.分岐予測器には,13 ビットのインデクス,6 ビッ. ように,関数の出現頻度をほぼ維持しつつ調整してい. トの履歴の gshare22)と,2 K エントリ,4 ウェイ連想. る.また,プログラムの特定の部分を繰り返すプログ. の BTB,および,16 エントリのリターン・アドレス・. ラムについては,その部分を抜き出し繰返し回数を調. スタックを用いた.分岐予測ミス・ペナルティは 5 サ. 整している.. イクルとした.なお,4.4 節ではキャッシュのヒット・. データ・キャッシュのポート数が,2,4,8 である 3. レ イテンシと分岐予測ミス・ペナルティを種々変えて. つのプロセッサ・モデル P2,P4,P8 を仮定した.デー. 測定を行うが,これらが CBR に与える影響は,測定. タ・キャッシュは,ポート数と等しいバンクに分割され. の結果,非常に小さい.このため,上述のパラメータ. ているとする.P2 モデルは,4 命令発行で,命令ウィ. での測定結果のみ示す.. ンド ウとして 32 エントリの RUU( register update. unit )と 16 エントリの LSQ( load/store queue )を 持つ.機能ユニットには,2 つの ALU,2 つのロード / ストア・ユニット,1 つの整数乗除算ユニット,2 つの 浮動小数点 ALU,1 つの浮動小数点乗除算ユニットを. BNU と命令発行に組み込む機構として,以下の 5 つの機構を仮定した.. C. : ベース・アドレスが利用可能なと. O. : 古いレジスタ予測によってバン. S. : ストライド 予測によってバンク. き,バンクを計算により求める.. 持つ.これらの機能ユニットのレ イテンシは R10000 とほぼ同じである.P4, P8 モデルは P2 モデルに対 し,上記資源(命令ウィンド ウと機能ユニット )をそ. クを予測する. を予測する..
(12) 12. Nov. 2001. 情報処理学会論文誌:ハイパフォーマンスコンピューティングシステム. S+B. : ストライド 予測によってバンク を予測し,発行の際,プログラ ム順で最も早い命令を使用され ないロード /ストア・ユニット に ブロード キャストする.. S+B+C. : 計算可能な場合は計算により, そうでないときは,ストライド 予測によってバンク番号を得る. 予測により発行する場合 は,前 述のポリシーでブロード キャス. 表3. C 機構を持つ PPC キャッシュによる実効アクセス時間の増 加率 (%) Table 3 Increase of the effective access time in PPC cache with C mechanism (%). program compress95 gcc go ijpeg li m88ksim perl vortex. P2 9.1 20.6 31.0 16.8 25.2 20.0 18.4 16.2. P4 0.5 15.4 21.3 11.7 20.2 13.4 15.7 14.2. P8 -8.8 7.8 11.8 10.0 12.5 4.4 8.6 7.8. トする. なお,ストライド ・バンク予測器は 4 K エント リ の表より構成される.この表は,ロード /ストア命令 の命令アドレスでインデクスされ,各エントリは対応 する命令が最後にアクセスしたアドレスの下位よりバ ンク番号までのビット(最終値)と,その前にアクセ スしたアドレスとの差分の下位よりバンク番号までの ビット( ストライド )を保持する.最終値とストライ ド( 初期値はいずれも 0 )を加えて予測値とする.タ グはない.また,ストライドが検出されたかど うかを. 表 4 BNU でベース・レジスタが利用可能な割合 Table 4 Availability rate of base registers at BNU (%).. program compress95 gcc go ijpeg li m88ksim perl vortex. P2 64.8 50.5 37.6 55.2 44.7 51.3 53.2 55.9. P4 62.9 42.6 34.6 47.7 36.1 45.3 42.2 44.3. P8 63.5 38.7 32.7 35.4 31.6 43.7 37.4 38.7. 表す状態も存在しない.この方式は,文献 16) で示さ れた 3 状態の予測器より単純であるが,バンク予測と. 率を図 11 に示す.正の数は減少したことを意味し,負. しては本方式の方が有効である.このことについては,. の数は増加したことを意味する.また,図 12 に CBR. 4.3 節で述べる. 4.2.2 実効アクセス時間. を示す.評価結果より次のことが分かる.. まず最初に,BNU に C 機構のみを実装した場合の. • 予測を用いることで CBR は大きく向上する.た とえば P4 において,O 機構では 59∼78%,S 機. 評価結果を示す.C 機構のみでは,ほとんど場合で実. 構では 71∼86%まで向上する.当然ながら,ポー. 効アクセス時間を削減することはできなかった.表 3. ト数が少ないほど CBR は高い.S 機構の CBR は. に,従来のキャッシュに対する PPC キャッシュの実効. ベンチマーク平均で,P2 で 90%なのに対し,P8. アクセス時間の増加率を示す.正の数は増加したこと. では 72%である. • 予測にブロードキャストを導入すれば,ポートが 多い場合において大きく CBR を向上できる.S. を意味し,負の数は減少したことを意味する.同表か ら分かるように,ほとんどの場合で実効アクセス時間 は増加している.特に,ポート数が少ないプロセッサ. から S+B 機構にすることにより,平均で P2 で. ほど物理アクセス時間の削減量が小さいため,実効ア. は 5%ポイントしか改善しないが,P8 では 7%ポ. クセス時間の増加率が大きく,P2,P4 では,すべて. イント改善する.特に,ストライド 予測で CBR. のベンチマークで増加した.. の低い gcc,go,li において効果が大きい.. このように実効アクセス時間を削減できなかった理. • さらに,ベース・レジスタ利用可能時に計算を行. 由は,BNU でバンク番号を計算する際に,ベース・. うことを加えれば,P8 において CBR は 2∼6%ポ. レジスタが利用可能な割合が小さいことである.表 4 に,BNU でベース・レジスタが利用可能であった割 合を示す.同表より分かるように,平均で 40∼50%程 度しか利用可能でない.このため,頻繁にペナルティ が課せられ実効アクセス時間が増加した.以上より,. イント改善する.. • ポート数が多いほど高度な BNU/発行機構を使う 利点が現れてくる.その結果,ポート数が増加し ても CBR が大きく低下することはない.ベンチ マーク平均で P2 から P8 の CBR の減少量は,O. C 機構より高い確率で正しくバンクを指定できる機構. 機構では 21%ポイントもあるが,S+B+C 機構で. が必要であることが分かる.. は 13%ポイントと小さくなる.. 次に,C 機構以外の場合の実効アクセス時間の削減. • CBR はポート数が多い場合の方が低いが,物理.
(13) 5. 0. -5. (b) P4. 30 O. 25 S+B. 20 S+B+C. 10. 5. 0. -5. 図 11 実効アクセス時間の削減率 Fig. 11 Effective access time reduction rate.. (c) P8. 図 12 Fig. 12. (c) P8. CBR CBR. vortex. 10. vortex. S+B+C. perl. 20. perl. S+B. m88ksim. 25. m88ksim. O. li. 30. li. (a) P2. ijpeg. -5. ijpeg. vortex. perl. m88ksim. li. ijpeg. 0. go. 5. go. 10. go. S+B+C. gcc. S+B. gcc. 20. compress95. 15. CBR (%). 25. compress95. 15. CBR (%). vortex. O. gcc. 15. CBR (%). vortex. perl. m88ksim. li. ijpeg. go. gcc. compress95. Effective Access Time Reduction Rate (%) 30. compress95. vortex. perl. m88ksim. li. ijpeg. go. gcc. compress95. Effective Access Time Reduction Rate (%). No. SIG 12(HPS 4). perl. m88k.. li. ijpeg. go. gcc. compress95. Effective Access Time Reduction Rate (%). Vol. 42 低レ イテンシ 1 対 1 結合マルチポート・インターリーブ・キャッシュの評価. S. S. S. 70. 60. 50. 40. 30. 20. 10. 0. 13. 100 90 O. S. 80 S+B. 70 S+B+C. 60. 50. 40. 30. 20. 10 0. 100. (a) P2. 90 O. S. 80 S+B. 70 S+B+C. 60. 50. 40. 30. 20. 10. 0. (b) P4. 100. 90 O. S. 80 S+B. S+B+C.
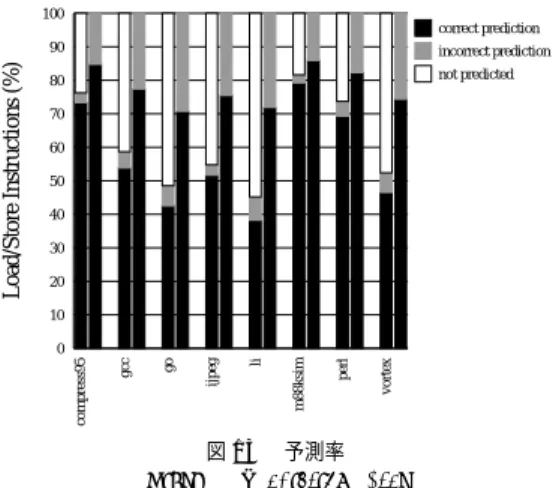
(14) 14. 情報処理学会論文誌:ハイパフォーマンスコンピューティングシステム 100. Load/Store Instructions (%). correct prediction 90. incorrect prediction. 80. not predicted. 70 60. 表5. ストライド ・アドレス予測器とストライド ・バンク予測器の コスト Table 5 Cost of stride address predictor and stride bank predictors (bits).. scheme ADR BANK OUR. 50 40 30. Nov. 2001. tag 18 18 0. state 2 2 0. last value 32 4 4. stride 32 4 4. total 84 28 8. 20 10. vortex. perl. li. m88ksim. go. ijpeg. gcc. compress95. 0. 図 13 予測率 Fig. 13 Prediction rate.. し,PPC キャッシュを持つプロセッサがどれほど性能 を改善するかを評価する.本評価では,クロック・サ イクル時間と実行サイクル数の両方を考慮し,性能を 比較する.クロック・サイクル時間について以下の仮 定を置く.. アクセス時間の削減率が大きいので,実効アクセ ス時間の削減率はポート数が多いほど大きい.削. • クロック・サイクル時間の下限として,控えめな 仮定と積極的な仮定の 2 つの場合を想定する.各. 減率は S+B+C 機構の場合で,P2 で平均 16%,. 仮定におけるクロック・サイクル時間は,文献 19). P8 では 22%もある.. より,それぞれ 1.08 CA8,0.54 CA8 とする.こ. 4.3 スト ライド ・バンク予測器の評価 前節で述べたように,我々はストライド・バンク予 測器として,通常のストライド・アドレス予測器とは. • クロック・サイクル時間を決定するクリティカル・ パスの遅延は,キャッシュ・アクセス以外につい. 異なり,ストライド 検出を表す状態とタグの両方を持. ては,与えられたクロック・サイクル時間の下限. たない構成とした.PPC キャッシュでは,バンク予測. になっているとする.したがって,クロック・サ. を誤ってもバンク予測を行わなくても,ともに 1 サイ. イクル時間は,次の式で与えられる:. クルのペナルティを被るので,全ロード /ストア命令 に対する予測精度(予測率と呼ぶ)が高い方が有利で ある. 図 13 に,P4 モデルにおける予測率の測定結果を示 す( 他のモデルでも同様の傾向) .各ベンチマークに. 2 本の棒グラフがある.左がタグと状態を持つ通常の. れらの数字については後で説明する.. clockcycletime = max(givenlowerbound, cacheaccesstime/n) ここで,n はキャッシュ・アクセスのパイプライ ン段数である.. • 積極的な仮定の場合は,控えめな仮定の場合に比 べパイプライン段数が倍であるとする.この効果. ストライド 予測器の場合であり,右がこれらを削除し. を分岐予測ミスペナルティに反映する.本測定で. た簡易予測器の場合である.同図より分かるように,. は,控えめな仮定で 5 サイクル,積極的な仮定で. 予測率はどのベンチマークでも簡易予測器の方がかな. 10 サイクルとする.. り大きい.予測率は平均で,通常の予測器で 57%であ るのに対して,簡易予測器では 78%ある. 表 5 に,キャッシュを 4 ポートのワード・インター. クロック・サイクル時間の下限の 2 つの仮定につい て説明する.文献 19) によると,クロック・サイクル時. す.32 ビット・アーキテクチャで,4 K エントリの表. 間の下限は,トレンド,SIA( Semiconductor Industry Association )の予測23) ,ISSCC( International Solid-State Circuits Conference )掲載の回路24)など. を仮定している.ADR は通常のストライド ・アドレ. から,今後,8∼16 FO4 の間で推移すると予測して. ス予測器,BAN K は最終値とストライド ・フィール. いる.ここで FO4 とは,半導体技術に独立な遅延の. ドにバンクに関係する下位 4 ビットを保持する予測器,. 単位であり,360*Ldrawn (ps) という時間の定数であ. OUR は我々の提案するストライド ・バンク予測器に. る.ここで,Ldrawn (*m) は,与えられた半導体技. リーブとした場合の 1 エントリに必要なビット数を示. 対応する.同表から分かるように,我々の予測器のコ. 術における最小ゲート長である.n FO4 とは 1 FO4. ストは,通常の予測器の 10%ほどしか要しない.4 K. の n 倍の時間を意味する.ゲート遅延は Ldrawn にほ. エントリの表のコストは,わずか 4 K バイトである.. ぼ比例して短縮されるので,FO4 を単位とする遅延. 4.4 プロセッサ性能評価 本章では,従来のキャッシュを持つプロセッサに対. は,半導体技術に対し 独立な数となる.4.1.2 項で書 いたように 1 CA8 は 959 ps なので,クロック・サイ.
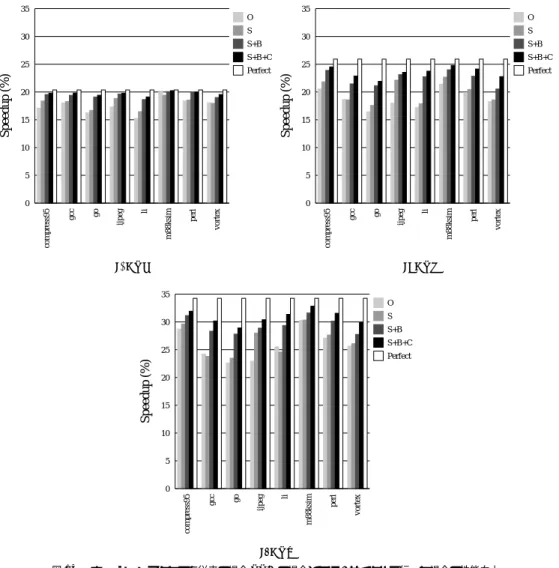
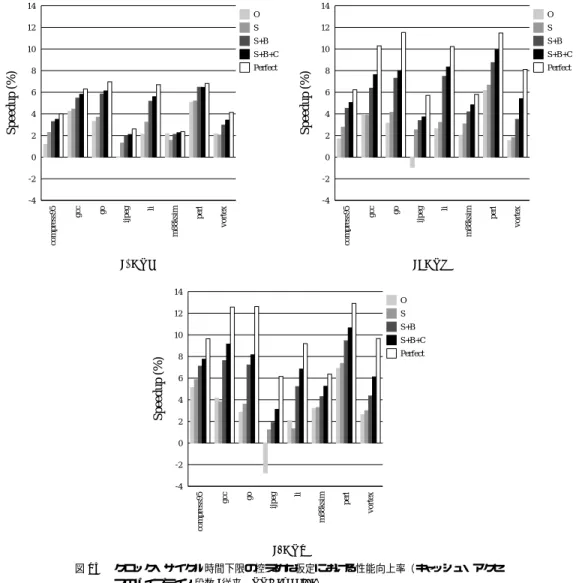
(15) Vol. 42. No. SIG 12(HPS 4). 低レ イテンシ 1 対 1 結合マルチポート・インターリーブ・キャッシュの評価. 表6. クロック・サイクル時間下限の控えめな仮定におけるキャッ シュ・アクセスのパイプライン段数とクロックサイクル時間 ( CA8 )の関係 Table 6 Relationship between the number of pipeline stages and clock cycle time (CA8) under the conservative assumption of the lower bound of the clock cycle time.. モデル. P2 P4 P8. パイプライン段数 従来 PPC 1 2 1. 1.30 1.36 1.45. 1.08 1.08 1.08. 1.08 1.08 1.08. 15. シュの場合で IPC は変わらないので,性能差はクロッ ク速度のみから生じ る.表 6 に示したように,ポー ト数の多いキャッシュほど クロック・サイクル時間の 削減は大きいので,より大きな性能向上率を達成して いる.クロック・サイクル時間の改善が少ない P2 に おいても,19.1∼20.2%( S+B+C 機構)の大きな性 能向上を示す.一方で,ポート数が多いほど CBR は 低いので,Perfect から実際の BNU にした場合の性 能低下は大きい.それでもなお P8 においては,28.9 ∼32.8%( S+B+C 機構)の大きな性能向上を示して いる.. クル時間の下限は CA8 で表すと 0.54∼1.08 CA8 と なる.本章では,下限の最小値と最大値の 2 つの場合 を想定して評価を行う.以下では,最初に控えめな仮 定の場合について,次に積極的な仮定の場合について 評価する.. 4.4.1 クロック・サイクル時間下限の控えめな仮 定の場合 従来のキャッシュの場合,P2,P4,P8 の各プロセッ. パイプライン段数 (2,1) の場合 従来キャッシュのパイプライン化によりクロック・ サイクル時間に違いがなくなり,性能差は IPC の違 いより生じる.図 15 に測定結果を示す. ど のプロセッサ・モデルでも,(1,1) の場合に比べ 性能向上率は小さくなっている.一般に,ポート数の 少ないプロセッサでは,狭いキャッシュ・バンド 幅に よりメモリ・アクセスのスループットが低く抑えられ,. サ・モデルにおけるキャッシュ・アクセス時間は,図 9. ロード /ストア命令の長いレ イテンシが他の命令の実. よりそれぞれ,1.30 CA8,1.36 CA8,1.45 CA8 で. 行によって隠蔽される.このため,図 15 から分かる. ある.これに対し ,PPC キャッシュの場合,それぞ. ように,P2 では完全な BNU の場合で得られる性能向. れ,1.05 CA8,1.00 CA8,0.97 CA8 である.クロッ. 上率は最高で 7.0%,平均で 5.0%と大きくない.実際. ク・サイクル時間の控えめな仮定における下限は 1.08 CA8 であるから,従来のキャッシュの場合,どのプロ. の BNU においては CBR が高いため,これに近い性. セッサ・モデルにおいても,2 段までのパイプライン. 改善にとど まっている.. 能を達成しているが,2.1∼6.5%( S+B+C 機構)の. 化ならばクロック・サイクル時間を低減できる.一方,. 逆に,多くのポートを持つプロセッサでは,長いレイ. PPC キャッシュの場合,キャッシュ・アクセス時間は どのプロセッサ・モデルにおいても下限より短いので,. テンシが露出され,性能に大きな影響を与える.完全な. BNU において,P8 では最高 12.9%,平均 9.9%性能が. キャッシュ・アクセスは最も長いクリティカル・パスで. 向上する.しかし一方で,ポート数が多けれれば CBR. はない.よって,パイプライン化の必要はなく,どの. が減少するので,完全な BNU からの損失量は大きい.. モデルにおいても,クロック・サイクル時間は下限値. それでも P8 では最高 10.7%,平均 7.1%( S+B+C 機. である.表 6 にキャッシュ・アクセスのパイプライン. 構)の性能向上を達成している.. 段数とクロック・サイクル時間の関係をまとめる.表. 同一のプロセッサ・モデルにおいて,各 BNU の機. において,下線を引いた数字は下限によって抑えられ. 構に対する性能は,当然ながら,CBR が高い順となっ. たクロック・サイクル時間である.以下では,キャッ. ている.また,正の性能向上を得るには,CBR には. シュ・アクセスのパイプライン段数(従来,PPC )が,. かなり高い値が要求されることが分かる.ijpeg にお. (1,1) および (2,1) の場合について評価を行う.なお,. いては,O 機構ではどのプロセッサ・モデルでも性能. バンクを求める機構として,O,S,S+B,S+B+C. 向上を得ることができていない.O 機構の CBR は. の 4 つの機構に加え,バンクを完全に予測できる場合. 図 12 より,47∼78%であるが,この程度では不十分. ( Perfect )について測定した.. であることが分かる.S 機構を用いれば,すべてのベ. パイプライン段数 (1,1) の場合. ンチマークで性能向上を得ることができるが,P8 に. 図 14 に性能測定結果を示す.どのプロセッサ・モ. おいても最高 7.4%,平均 3.7%にとどまる.これに発. デルにおいても,クロック・サイクル時間の削減が大. 行時ブロードキャストを加えれば,性能は最高 9.5%,. きく作用し ,PPC キャッシュを用いた場合性能が大. 平均 5.9%にまで向上する.さらに C 機構を加えれば. きく向上する.Perfect の場合では従来と PPC キャッ. 性能は前述の値,最高 10.7%,平均 7.1%にまで向上.
(16) 16. Nov. 2001. 情報処理学会論文誌:ハイパフォーマンスコンピューティングシステム 35. 35 O S+B S+B+C. 20. (a) P2. vortex. perl. compress95. vortex. perl. m88ksim. 0 li. 0 ijpeg. 5. go. 5. gcc. 10. compress95. 10. m88ksim. 15. li. 15. Perfect. ijpeg. 20. S+B+C. go. Perfect. S+B. 25. Speedup (%). 25. S. 30. gcc. 30. Speedup (%). O. S. (b) P4 35 O S. 30. S+B S+B+C. Speedup (%). 25. Perfect. 20 15 10 5. vortex. perl. m88ksim. li. ijpeg. go. gcc. compress95. 0. (c) P8 図 14. キャッシュ・アクセスを従来の場合 PPC の場合ともに 1 サイクルで行った場合の性能向上 Fig. 14 Speedup with a single-cycle cache access in both cases of the conventional and the PPC cache.. する.3.3 節で述べたように,BNU に C 機構を組み 込む場合は,クロック速度に悪影響を及ぼす可能性が ある.この場合は,S+B 機構を組み込むのが最善と いえる.. 4.4.2 クロック・サイクル時間下限の積極的な仮 定の場合 クロック・サイクル時間の下限は 0.54 CA8 と低い ため,キャッシュのパイプラインを控えめな仮定の場 合より深くし,クロック・サイクル時間を低減するこ とができる.表 7 にキャッシュ・アクセスのパイプラ. 表7. クロック・サイクル時間下限の積極的な仮定におけるキャッ シュ・アクセスのパイプライン段数とクロックサイクル時間 (CA8) の関係 Table 7 Average performance normalized by the performance of the processor with non-pipelined conventional cache.. モデル. P2 P4 P8. 1 1.30 1.36 1.45. パイプライン段数 従来 PPC 2 3 1 2. 0.65 0.68 0.72. 0.54 0.54 0.54. 1.05 1.00 0.97. 0.54 0.54 0.54. イン段数とクロック・サイクル時間の関係をまとめる. 下線を引いた数字は下限によって抑えられたクロック・ サイクル時間である.. おけるベンチマークの平均性能を示し,その後に,平 均性能が最も高いパイプライン段数のときの比較をベ. ここでは誌面の節約のため,まず,従来と PPC の. ンチマークごとに示す.表 8 に平均性能の測定結果を. 両キャッシュの場合について,各パイプライン段数に. 示す.最も性能の低い場合であるパイプライン化して.
図



+7

関連したドキュメント
Let X be a smooth projective variety defined over an algebraically closed field k of positive characteristic.. By our assumption the image of f contains
(4) The basin of attraction for each exponential attractor is the entire phase space, and in demonstrating this result we see that the semigroup of solution operators also admits
We present sufficient conditions for the existence of solutions to Neu- mann and periodic boundary-value problems for some class of quasilinear ordinary differential equations.. We
Then it follows immediately from a suitable version of “Hensel’s Lemma” [cf., e.g., the argument of [4], Lemma 2.1] that S may be obtained, as the notation suggests, as the m A
Applications of msets in Logic Programming languages is found to over- come “computational inefficiency” inherent in otherwise situation, especially in solving a sweep of
Our method of proof can also be used to recover the rational homotopy of L K(2) S 0 as well as the chromatic splitting conjecture at primes p > 3 [16]; we only need to use the
Shi, “The essential norm of a composition operator on the Bloch space in polydiscs,” Chinese Journal of Contemporary Mathematics, vol. Chen, “Weighted composition operators from Fp,
[2])) and will not be repeated here. As had been mentioned there, the only feasible way in which the problem of a system of charged particles and, in particular, of ionic solutions
