363 頁∼ 379 頁
統計的因果推論の視点による重回帰分析
岩崎 学
∗Multiple Regression Viewed from Causal Inference Perspective
Manabu Iwasaki∗ 重回帰分析は疑いなく統計的データ解析手法の中で最も多く応用されるきわめて有用な手法で ある.しかしそれ故に誤用も多く見られることも事実である.本論文では,重回帰分析につき, その教科書的な記述に対し,実際問題への応用を意識した場合に重要と思われるいくつかの論点 を統計的因果推論の観点から吟味し,それらに関する筆者の考えを述べる.また,重回帰分析の 教育において,受講者の興味を引くであろういくつかのパラドクス的な例を紹介する.
Multiple regression analysis is, without doubt, the most important and extremely useful method of statistical data analysis. It is also a fact, however, that there are many misuses in practical applications of the method. In the present paper, in addition to the textbook description of multiple regression analysis, some issues that seem important in applying the methodology to various practical problems are examined from the viewpoint of statistical causal inference. Some paradoxical examples will be also shown that may be of interest to students attending the class of multiple regression analysis.
キーワード: データサイエンス,回帰関係,観察研究,パラドクス 1. はじめに 重回帰分析は,疑いなく統計的データ解析の中で最も重要かつ多用されている統計手法 である.表計算ソフトの MS Excel をはじめ,SAS や SPSS などの商用ソフトウェアはも とより,R や Python などの無償のソフトウェアのほぼすべてに搭載され,きわめて多く の人々がそれを使える環境にあることから,その適用に関するすそ野は大いに広がりを見 せている.ソフトウェアのおかげで,データさえあれば誰もがいとも簡単にそれなりの結 果を出すことが可能になっている.大学の授業でも,モデルを形式的に説明して演習用の データセットを用意して結果を出し,通り一遍の解釈をするだけであれば1コマの授業だ けで事足りてしまう.これは,社会人向けの統計セミナーでも同様であろう.このすそ野 ∗ 統計数理研究所:〒 190-8562 東京都立川市緑町 10-3 (E-mail: [email protected]).
の広がりは当然歓迎すべきことであるが,反面,実際問題への適用で,その解釈には首を かしげざるを得ないこともこれまた多く見られる.
一方で近年,統計的因果推論が,その理論の整備とソフトウェアの提供により身近な ものとなりつつある.実際,Imbens and Rubin (2015),Morgan and Winship (2015), Rosenbaum (2002, 2017, 2020), Hern´an and Robins (2020) をはじめとする専門の書籍が 刊行されている.そして重回帰分析に対しても,因果推論的な視点からのアプローチを含ん だ著作が増えつつある.例えば Angrist and Pischke (2009),Berk (2004),Best and Wolf (2015),Gelman and Hill (2007),Gelman et al. (2021) などを参照されたい.
筆者は近年,授業やセミナーなどで重回帰分析を取り上げる際,この因果推論的な視点 を重視したアプローチを積極的に取り入れている.ビッグデータやデータサイエンスが喧 伝され,あたかも多量のデータと適当なソフトウェアさえあれば事足りるという風潮は, もちろん統計家から見て望ましくない. 本論文は,筆者のこれまでの経験に基づき,重回帰分析を統計的因果推論の立場から見 直すとともに,過去に議論を巻き起こしたいくつかの例を示し,今後の重回帰分析の健全 な発展に少しでも寄与しようとするものである.特に,現在あるいは今後,重回帰分析を 教える立場の方々を念頭に置いている. 以下では,第 2 節で統計的因果推論から見た研究の種類分けおよび変数の分類について 述べ,第 3 節で重回帰モデルにまつわる種々の側面について議論する.第 4 節では,重回 帰分析の教育において興味深いと考えられるいくつかのパラドクス的な話題を紹介する. これらは,第 2 節での論点の具現化でもある.そして最後の第 5 節で簡単なまとめを行う. 本論文の内容は,統計の専門家にとっては釈迦に説法的なものかもしれない.とはいえ, いくつかの例に対しては興味を持たれるであろうし,また,実際に統計教育に携わってい るか,もしくはこれから関ろうとする教員に対して資するところがあれば幸いである.な お本論文には,筆者の個人的な見解であって広く受け入れられたものではないかもしれな い事柄も含んでいる.読者各自の常識に照らし合わせて読んでいただきたい.その種の判 断も「教える立場」としては必要不可欠なものであろう. 本論文は,筆者の 2020 年度日本統計学会賞受賞の記念論文である.また,筆者の日本統 計学会会長の就任にかかる記念論文である岩崎 (2016) も併せてお読みいただければと考 える. 2. 研究の種類と変量間の関係 重回帰分析の議論に入る前に,簡単に研究の種類と変量間の関係に触れておく.これら は重回帰分析の理解には欠かせないものである.データを用いた研究には,新たにデータ をとる場合と既存のデータを活用する場合がある.ここでは前者の新たにデータをとる場
合を念頭に置いて話を進める.新たにデータをとる場合の研究としては, 実験研究,観察研究,調査研究 の 3 種がある.「実験研究」と「観察研究」が何らかの処置の効果の評価をその研究目的と するのに対し,「調査研究」は必ずしもそれを目的とはしない (cf. Rosenbaum (2002)).実 験研究と観察研究の相違は,前者が研究の計画が研究者の手に委ねられ,被験者への処置 の割当てのランダム化が可能である一方,後者は処置の割当てが被験者の選択によるもの である点にある.第 1 節で述べた統計的因果推論の書物は,主として観察研究に軸足を置 いたものである.そして重回帰分析は,それらのすべての種類の研究で重要な役割を果た す手法であるといえる. 次に,分析に供される変量について,それら変量間の関係をここでは 因果関係,回帰関係,相関関係 の 3 種類に分ける.これまでの統計学のテキストでは,『因果と相関は異なる』として「因 果関係」と「相関関係」を対峙させることが多いが,ここではその中間として「回帰関係」 を想定する.その定義は『必ずしも因果関係ではないが予測には有用な関係』である.回 帰分析の用語を援用している. これらの分類に関連して,重回帰分析の目的は次の3つである: 記述,予測,制御・介入 これらのうちの「記述」は,文字通り目的変数と説明変数間の記述であり,そこからさま ざまな仮説を見出したりすることになろう.研究の種類のうち観察研究と調査研究が関係 する.ただし,実際問題では記述だけでは不足で,予測あるいは制御・介入に資するので なければ,単に分析をやっただけになりかねない.「予測」は,重回帰分析の目的の一つで あり,そこでの変量間の関係は回帰関係である.ただし,それが因果関係となるかどうか には注意深い考察が必要となる.例えば,得られた回帰式 y = a + bx において,b > 0 の とき『x が 1 単位大きければ y が平均的に b だけ大きい』という解釈は妥当であるが,そ れは『x を 1 単位 大きくすればy は平均的に b だけ 大きくなる』ことを一般に意味しない. その解釈が成立するためには因果関係が必要となる.3 番目のカテゴリーのうちの「制御」 は品質管理を念頭に置いた用語で,説明変数の値を人為的に変化させることで目的変数の 値をコントロールすることを意味する.また「介入」は主として医療分野で用いられる用 語であり,薬剤の投与などの人為的な処置を意味する. 実際のところ,回帰分析の本来の目的は「制御・介入」の妥当性評価であることが少な くないであろう.Evidence Based Policy Making (EBPM) の目的もそこにある.そのた
めには変量間の関係として因果関係を必要とし,研究形態は実験研究もしくは観察研究と なる. 3. 重回帰分析モデル再考 ここではまず 3.1 節で通常の重回帰分析モデルを示し,3.2 節でそこに潜む論点について 議論する.3.3 節では,重回帰分析の実際問題への適用において重要な回帰係数の解釈につ いて,変数選択の問題を含めつつ論じる. 3.1 重回帰モデルの定式化 全部で n 個の個体において,第 i 個体の目的変数を表す確率変数を Yiとし,p 個の説明 変数の値を xi1, ..., xipとして,重回帰モデルを Yi= β0+ β1xi1+ L + βpxip+ εi (i = 1, ..., n) (3.1) とする.誤差項の確率変数 εiには通常
(i) E[εi] = 0, (ii) V [εi] = σ2, (iii) Cov[εi, εi0] = 0 (i6= i0) の仮定が置かれる.また, (iv) εiは正規分布に従う とされることも多い.モデル (3.1) とそれに伴うこれらの仮定は,Y1, ..., Ynからなる n 次 ベクトルをY とし,定数項および p 個の説明変数からなる n× (p + 1) 行列を X,定数項 と p 個の回帰係数からなる (p + 1) 次ベクトルをβ,誤差項を表す n 次ベクトルをεとした とき, Y = Xβ + ε, ε∼ Nn(0, σ2In) (3.2) と表される.E[Y ] = Xβ であり,重回帰分析は Y の値そのものに関する分析法であると 同時に,Y の期待値に関する分析法であるとも言える.この後者の役割も,手法の理解あ るいは結果の解釈において重要である.以降,(3.2) を重回帰モデルとして話を進め,(3.1) の和の表現は必要な場合に限って言及することとする.なお以下では rank(X) = p + 1 と し,rank(X) < p + 1 のときは,逆行列 (X0X)−1を適当な一般逆行列 (X0X)−に置き換え る(プライムは行列の転置の記号). 回帰係数ベクトル β の最小二乗推定量は b = (X0X)−1X0Y (3.3) で与えられ, E[b] = β, V [b] = σ2(X0X) (3.4)
が成り立つ.また,Y の予測値を ˆ Y = Xb = X(X0X)−1X0Y = PXY (3.5) とすると, E[ ˆY ] = Xβ, V [ ˆY ] = σ2X(X0X)−1X0= σ2PX (3.6) となる.ここで PX = X(X0X)−1X0は n 次ユークリッド空間 Rnにおいて X の列ベクト ルの生成する部分空間 S(X) への直交射影行列である.X0X のスペクトル分解および X の特異値分解を X0X = HDH0, X = L∆H0 (3.7) とする.ここで,D は対角要素に X0X の固有値 λ1≥ · · · ≥ λp> 0 を持つ対角行列,∆ は 対角要素に特異値 δ1≥ · · · ≥ δp> 0 を持つ対角行列で,H0H = Ip,L0L = Ipである.こ のとき,PX= LL0と書けることに注意する. また,第 j 回帰係数 βjに関する検定 H0: βj = 0 vs. H1: βj6= 0 (j = 1, ..., p) (3.8) は,(X0X)−1の第 (j, j) 要素を cjj とし,残差平方和 A に基づく σ2 の推定量を S2 = A/(n− p − 1) としたとき, 統計量 Tj= bj/ √ cjjS2/n が自由度 n− p − 1 の t 分布に従う ことを用いて行われる.検定の統計量の値や P 値は,重相関係数や決定係数などに加え, 重回帰分析のソフトウェアで標準的に出力されるので,それらを利用すればよい. 重回帰分析における理論的な結果はほぼ以上のみであり,モデル (3.2) から始めて (3.3)∼ (3.8) の結果を導くのに何ら困難はなく,線形代数の知識を前提とすればほんの数回の授業 で事足りるであろう.しかし問題は,モデル (3.1) あるいは (3.2) は出発点でなくある意 味でゴールであり,さらに (3.3)∼(3.8) もゴールではなく,現実問題ではそこから議論が 始まる出発点と言っても過言ではない. 3.2 重回帰モデルにおける論点 3.1 節の重回帰モデル (3.2) では,誤差の正規性を想定している.回帰係数の最小二乗 推定のような線形代数学的な扱いでは誤差の正規性は必ずしも必要ではないが,この正規 性の想定はきわめて重要であると考える.その理由はモデル (3.2) の構築に関わっている. 3.1 節の終わりにモデル (3.2) はある意味でゴールであると述べた.モデル (3.2) は天から 降ってきたものではなく,研究者が自ら構築するものである.どの変量をモデルに取り込 むか,取り込んだ変量と目的変数との関数関係として何を想定するかといったあらゆる可 能性を試した上でモデル (3.2) に到達するのであり,それは現象のモデル化に関するゴー ルである.
正規分布は別名誤差分布 (error distribution) とも言われ,何ら構造を持たない分布であ るとされる.モデル化において,構造があるとすればそれは説明変数として明示的にモデ ルに取り込むべきである.また,実際の現象は複雑なものであり,目的変数 Y に影響を与 える変量はかなり多いに違いない.しかしそれらすべてをモデルに取り込もうとするのは 現実的ではなく得策でもない.重要な変量はモデルに取り込み,あまり重要ではない変量 はまとめて誤差として扱うのが現実的な方策である.その際の指針が誤差の正規性に他な らない.“All models are wrong, but some are useful.” とは Box et al. (1978) にもある George Box の金言であるが,useful なモデルの構築こそが統計家・データサイエンティス トに課せられた使命である. 関連して,誤差項 ε と説明変数 X との独立性にも言及したい.通常 X は与えられた定 数と見なされ,回帰分析は X が与えられときの条件付き分析法とも解釈される.X が定 数であれば,式の上ではそれらの共分散については Cov[X, ε] = O が成り立つことになる. しかし,この X と ε の独立性は,回帰係数の推定の上で重要な仮定である.もし重要な変 量をモデルに取り損ねてしまうと,X と ε の独立性が損なわれかねない.計量経済学の分 野では omitted variable の問題として取り扱われることが多いが,計量経済学に限らずす べての分野で注意すべき点である. 3.3 回帰係数の解釈 重回帰分析では,計算によって得られた回帰係数 b1, ..., bpの解釈が問題とされることが 多い.教科書的に言えば,「bjは他の変量の値を一定にしたときに,xjを 1 単位変化させ たときの y の平均的な変化量」であるが,誤解を与えかねない表現である.品質管理にお ける直交計画のように X の各列が直交していれば bjは他の変量とは無関係に xjの与える 影響と見なすことができるが,X の各列に相関関係がある場合にはその限りではない. そもそも,回帰係数の解釈が必要であるか,という点から話を始める必要がある.もち ろん,研究の目的が第 2 節で分類した中の「記述」あるいは「制御・介入」であればそれは 重要であるが,分析の目的が「予測」の場合はどうであろうか.回帰係数 β の推定値 (3.3) と Y の予測値 (3.5) は,ともに (3.4) と (3.6) から分かるようにともに不偏性を有してい て,それらの間の統計学的な相違は分散共分散行列 V [b] および V [ ˆY ] に表れている.後者 は,X の列空間 S(X) の関数であり,そこでの基底(X の個々の列ベクトル)には依存せ ず,X の特異値にも依存しない.一方,前者は S(X) の基底である X の個々の列ベクトル そのものに依存し,かつ X0X の固有値(X の特異値の 2 乗)に依存する. 目的変数 Y の予測値が,S(X) にのみ依存して個々のベクトルに依存しないのであれば, 同じ S(X) を与える基底ベクトルの取り方は任意であって,極論すればそれらが一次独立 である必要もない(多重共線性があってもよい).すなわち,与えられた列ベクトルの任意
の一次結合は許容され,当然それらの変量の係数は異なるのであるが,そのことが主成分 回帰 (principal component regression) の一つの動機付けにもなる.ただし,主成分回帰 では選択された主成分が目的変数と高い相関を持つことが吟味されなくてはならない.す なわち,適切な S(X) を与えるベクトルの選択は重要であるが,与えられた個々のベクト ルの係数はさほど重要でないともいえる.したがって,個々の回帰係数にそうこだわる必 要はない.実際,予測を目的とする機械学習の多くの手法は,その計算法がブラックボッ クスで,その善悪はともかくとして,ここでいう回帰係数の解釈に無関係に予測が当たれ ばよいという価値判断がなされている. 結論的には,分析の目的が予測である場合には,個々の回帰係数の解釈は,すべきでな いとまでは言わないが,その重要性は高くない.また,変数選択も,S(X) がほぼ同じであ るならば,変数は多すぎてもさほどマイナスにはならない(多重共線性は恐れなくてもよ い).逆に重要な変数をモデルに取り入れ損なうことで適切な S(X) を構築できないマイナ スは大きいので,候補となる変量は多めにモデルに入れておくという戦略が考えられる. 一方,分析の目的が制御あるいは介入である場合には,そもそも制御可能な変量は少数 個に限られるであろうから,変数選択が必要となるであろうし,個々の変量に関する回帰 係数の値は,その変量の目的変数への寄与度を表すことから,実質上きわめて重要な意味 を持つ.しかしその場合は常に,各説明変数間の相関を考慮しなくてはいけない.実験計 画法のように X の各列を人為的に想定することができて,それらを直交させるあるいは相 関を小さくすることが可能な場合には,その解釈にさしたる困難はない. しかし,目的が記述の場合には,X の選択ができないことが多く,変量間の相関を考慮す る必要がある.回帰係数の解釈としては,この節の最初に述べた教科書的なものではなく, 『bjは,目的変量 Y を xj以外の変量が説明した残りの中で xjが説明できる度合い』とすべ きである.線形代数的に言えば,Sj(X) を X の中で xj以外の変量の生成する部分空間と し,その直交補空間を Sj(X)⊥としたとき,Y の Sj(X)⊥上への直交射影と xjの Sj(X)⊥ 上への直交射影との間の単回帰式の回帰係数が bjである.すなわち,bjは xj以外の変量 の影響を強く受けている.その意味で,(3.8) の回帰係数の検定の帰無仮説 H0: βj= 0 は 誤解を生む表現である.それが目的変数 Y に対する xj単独の影響度を与えるものと解釈 される危険性がある.正確な理解のためには,xj以外の変量に依存するという意味で H0: βj = 0| x1, ..., xj−1, xj+1, ..., xp とすべきなのかもしれない. また,モデル (3.1) における x1, ..., xpの役割を考える必要がある.統計的因果推論では, 研究の目的が処置の効果の評価であるが故に,目的変数(アウトカム)を表す Y と処置の 割当てを表す Z,そしてそれ以外の第三の変量 X に分けて考える(第三の変量は複数ある
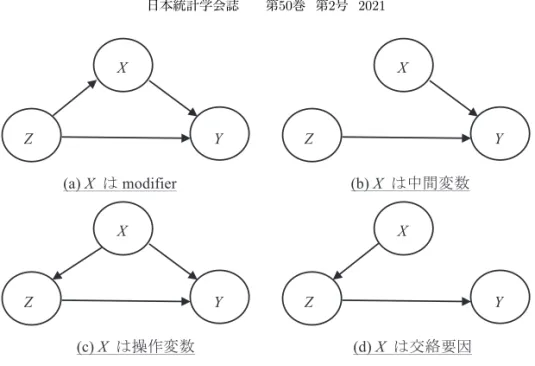
図 1 変数間の関係の因果ダイアグラム. のが普通で,その場合はベクトルとなる).最初に,共変量 (covariate) とは,処置の影響 を受けない変量であることを確認しておく.これらの間に考えられる関係は図 1 のようで ある.(a),(c),(d) では X は共変量であるとする((b) の X は処置の影響を受ける変量 で,共変量ではなく中間変数).詳細は因果推論の書物に譲るが,(a) では,X はモデル に入れなくてもいいが入れると多くの場合有利,(b) では X はモデルに入れるべきでない (cf. Rosenbaum (1984)),(c) では X は解析で対応する(Angrist et al. (1996), Rosenbaum
(2017) などを参照),そして (d) の場合は X は交絡要因であって,モデルに入れなくては いけない,となる.変量の性格を知ることがモデル作りではきわめて重要である.これら の違いについては第 4 節で例を用いて述べる. 4. Regression paradox の例 分割表解析における Simpson のパラドクス (Simpson (1951)) は,その見た目の単純さ と不思議さにより,分割表の解析は一筋縄でいかないことを例証すると同時に,受講者の 興味を引くことになるという教育的にも価値の高いものである.ここでは,重回帰分析と 統計的因果推論に関わる一見パラドクス的で興味深いいくつかの例を示す.これらは,当 該分野での分析結果の解釈の上で議論を巻き起こした,あるいは巻き起こす可能性がある ものであると同時に,筆者のこれまでの授業やセミナーでも,実際に学生あるいは受講者 の興味を引いたものであった.なお,示した数値例は議論を分かりやすくするためのもの であり,元の論文とは異なることを注意しておく. ここに挙げたもの以外にも,筆者のこれまでの授業などで用いて,受講者の興味を引い たいくつかの例が岩崎 (2019) に掲載されている.参考にしていただければ幸いである.
4.1 回帰と逆回帰 (reverse regression) 次の問題を考える.非正規雇用者の労働時間と賃金の関係を調べるため男女別にデータ が取られ,その結果は表1のように与えられたとする.x が 1 日当たりの労働時間(単位: 時間),y が 1 日当たりの賃金(単位:千円)である. 表 1 男女別の 1 日当たりの労働時間と賃金. 女性 統計量 時間 (x) 賃金 (y) 平均 6.0 6.0 分散 0.32 0.32 相関 時間 (x) 賃金 (y) 時間 (x) 1 0.5 賃金 (y) 0.5 1 男性 時間 (x) 賃金 (y) 7.0 7.0 0.32 0.32 時間 (x) 賃金 (y) 1 0.5 0.5 1 男性の平均賃金が 7 千円で女性の平均賃金が 6 千円であるが,これをもって男女格差が あるとは言えないであろう.男性のほうが平均労働時間が長いためである.両方とも平均 時給 1 千円となっている.次に,x から y を予測する回帰式を求めると,簡単な計算により 女性:y = 3.0 + 0.5x,男性:y = 3.5 + 0.5x となる.ここで x = 6.4 を代入すると,女性では y = 6.2 となり,男性では y = 6.7 とな る.すなわち,同じ 6.4 時間働いた場合,女性での平均賃金は 6.2 千円であるのに対し,男 性では 6.7 千円となる.これは性差別ではなかろうか.
次に逆に,y から x を予測する回帰(逆回帰 reverse regression)を求めると,同様の計 算により 女性:x = 3.0 + 0.5y,男性:x = 3.5 + 0.5y が得られる.ここで,y = 6.4 を代入すると,女性では x = 6.2 となり,男性では x = 6.7 となる.同じ 6.4 千円得るためには,女性は平均 6.2 時間働けばよいが,男性は平均 6.7 時 間働く必要があることになる.これは性差別ではなかろうか(ただし逆方向の). この問題は,ある時期に経済関係の学術誌をにぎわして論争となった.詳細は,Conway and Roberts (1983) に始まる一連の discussion 論文である Ferber and Green (1984),Goldberger (1984),Greene (1984),Michelson and Blattenberger (1984),Miller (1984) および rejoinder の Conway and Roberts (1984),ならびに Whiteside and Narayanan (1989),Racine and Rilstone (1995) を参照されたい.統計学分野では Dempster (1988) の興味深い discussion 付き論文がある.
ここでのロジックは,次の Load のパラドクスに関係したものであり,単なる比較と条 件付き比較の違いを論じたものとなっている.詳細は上述の参考文献を見ていただきたい が,最も説得力のある解釈は,最初に述べた,平均的な時給は男女間で同じというもので あろう. 4.2 Lord のパラドクス ある大学の学生食堂のメニューが学生の体重に影響をもたらすかどうかが問題となり, 男女別に学期開始時 (x) と学期終了時 (y) の体重のデータが得られた(単位:kg).表 2 は その概要である. 表 2 男女別の学期開始時と終了時の体重. 女子学生 統計量 学期開始 (x) 学期終了 (y) 平均 60 60 標準偏差 8.0 8.0 相関 学期開始 (x) 学期終了 (y) 学期開始 (x) 1 0.5 学期終了 (y) 0.5 1 男子学生 学期開始 (x) 学期終了 (y) 70 70 8.0 8.0 学期開始 (x) 学期終了 (y) 1 0.5 0.5 1 分析を依頼された統計家 A は,学期終了時と学期開始時との差 y− x を取り,男女とも 平均の差は 0 であることから,食堂のメニューが学生の体重に与える影響は男女間で差が ないと結論した.それに対し統計家 B は,学期開始時の体重 (x) を共変量に取り,性別を 分類変数 z を(z = 1:男子学生,z = 0:女子学生)とした共分散分析を適用し,以下の 式を得た. y = 30 + 5z + 0.5x ここで x = 64 を代入したところ,女子学生では y = 62,男子学生では y = 67 を得たこと から,女子では学期開始時に 64 kg であった学生は学期終了時には平均 62 kg と体重が減 少したのに対し,男子で同じ 64 kg であった学生は学期終了時に平均 67 kg に増加してい て,食堂のメニューは男女間で異なる影響を与えたと結論付けた.ここで回帰係数は両群 で平行であるので,x としていかなる値を与えようとも男女間の平均の差は 5 kg となる, どちらの統計家の結論が正しいのであろうか. この「パラドクス」は,当初 Lord (1967, 1969) で提示され,後に統計的因果推論から の考察が Holland and Rubin (1983) によって行われた.さらに,Wainer (1991),Wainer and Brown (2004),Chen et al. (2009) なども参照されたい.実はこれらの論文でも指摘 されているように,このパラドクスは,Simpson のパラドクスや前節の逆回帰の問題とも
深くかかわっている.Chen et al. (2009) 225 頁では “some caution should be maintained when applying a well-established statistical methodology to open-ended contexts, such as mining observational data without a predefined hypothesis.” と述べているが,まさに その通りである. ここで述べた「前後差」と「共分散分析」の選択は,現在においても現実的な問題であ る.新薬開発の臨床試験では,処置群 (z = 1) と対照群 (z = 0) のそれぞれで,薬剤の投 与前 (X) と投与後 (Y ) のデータが取られることが多い.処置前後差を分析対象とした場 合には,モデルとして Y − X = α + γz + ε (4.1) を想定し,帰無仮説 H0: γ = 0 を検定することになる.対応のある t 検定が標準的に用い られるであろう.一方,処置前値を共変量に取った共分散分析では,モデルは Y = α + γz + βx + ε (4.2) であり,ここでも H0 : γ = 0 の検定が問題となる.モデル (4.1) の X の実現値を x とし て右辺に移項すると Y = α + γz + x + ε となることから,処置前後差の検定は,モデル式 における x の係数 β を強制的に 1 と置いた共分散分析に相当するとの解釈が可能である. 処置前値は処置後値に大きな影響を与える共変量であることから,処置の割付け (Z) がラ ンダムであるとすれば,Z は X のみならずすべての変量と独立であるので,因果ダイアグ ラムは図 1 のようになり,この場合には X = x を共変量に取った解析のほうが効率が良 い,すなわち検定が有意になりやすいことが示される(少なくとも悪くはならない).その ためか,臨床試験の解析では共分散分析モデル (4.2) が用いられることが多いが,その解 釈は,Lord のパラドクス同様,やや分かりにくいと言えるかもしれない.臨床試験では, 処置前値に基づくスクリーニングが行われるのが普通であるので,処置前値を所与とした 条件付き解析である共分散分析が妥当な選択であるとも言えよう. 4.3 Birth weight(中間変数の影響) 新生児の出生時体重 (birth weight) がその子供の成長後にどのような影響を及ぼすかは, 疫学における研究テーマの一つとして多くの研究がなされてきている.実験研究は不可能 であることから,それらの多くは既存の,ときとしてきわめて大規模なデータベースを用 いた観察研究であり,それゆえに因果推論的な結論の導出には注意が必要となる. 出生時体重が,成長後における高血圧,糖尿病,動脈硬化症,喘息あるいは過度の肥満な どに影響を及ぼすとの仮説は “fetal origins of adult disease (FOAD) hypothesis” と呼ば れることもある(Barker (1995),Barker et al. (2002) などを参照).未熟児として生まれ た子供がその後の成長において何らかのリスクを抱え得ることは容易に想像できるが,正
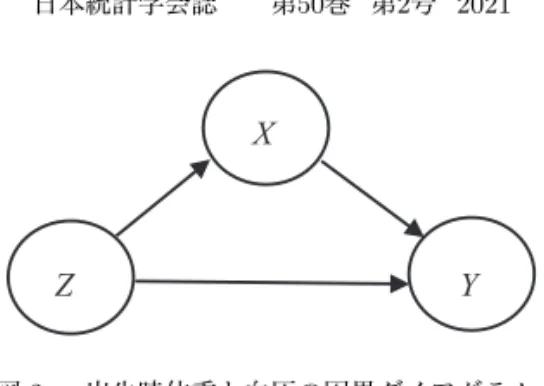
図 2 出生時体重と血圧の因果ダイアグラム. 常な分娩による新生児の体重がその後の成長にどのような影響をもたらすのかについては 諸説あり,FOAD 仮説がどの程度成り立ち得るのかについては議論の的となっている. 上述のように出生時体重はその後の慢性疾患などに影響を与え得るとされるが,ここで は特に,血圧に与える影響を評価する.Barker らは,出生時体重 (Z) が成人の血圧 (Y ) に与える影響を評価する際に,成人の体重 (X) が影響を与え得るということで,X を交絡 因子に取り,Y を説明するモデルに Z と X を取り込んだモデルに基づく分析の結果,Z の係数は負であり,出生時体重が低い子供は,成人後に血圧が高い傾向にあるという結論 を得た.それに対し Tu et al. (2005) は,成人の体重は出生時体重の影響を受け,出生時 体重から成人の血圧に至る因果ダイヤグラム(図 2)の中間に位置することから,成人の 体重をモデルに取り込むのは適切でないとした.これは 3.3 節の図 1(b) に示した状況であ り,因果推論においては,Rosenbaum (1984) で示されたように中間変数をモデルに取り 込んではならないのである. Tu et al. (2005) は,シミュレーション研究によりいくつかのパターンの結果を導いてい るが,そのうちの一つは,各変量間の相関が R[Z, Y ] = 0,R[Z, X] = 0.35,R[X, Y ] = 0.25 とした場合において,Z から Y への単回帰モデルにおける回帰係数は 0.01 で 95%信頼区 間は (−1.76, 1.82) であるが,Z と X を説明変数に取った重回帰モデルにおける Z の係数 は−1.96 で,95%信頼区間は (−3.69, −0.11) になったと報告している.すなわち,出生時 体重と成人後の血圧間の関係はない R[Z, Y ] = 0 にもかかわらず,成人体重を説明変数に 加えることで,あたかも出生時体重が成人後の血圧に影響を及ぼしてるように見える,と 結論付けている.もちろん,出生時体重が成人後の慢性疾患などに与える影響については, このような単純なモデルがそのまま当てはまるとは言い切れないが,因果関係において因 果のパスの中間に位置する変量をモデルに加えるべきではなく,Tu et al. (2005) は,この 種の(誤った)統計解析が与える影響については,研究者はその種の統計学上の知識を身 に付けたうえで,十分考慮する必要があるとしている. 4.4 Suppression と enhancement ならびに多重共線性 重回帰分析では,重相関係数 R と個々の変量 x1, ..., xpと目的変量 y 間の単相関係数 r1, ..., rpとの間には様々なことが起こり得る.特に,ある変量 x2が,x1とは相関を持つが
y との相関は 0 であるにもかかわらず,x2を説明変数に取り込んだ重回帰分析における決 定係数 R2を増加させるとき,suppression(抑制)が生じたと言い,x2を suppressor と呼 ぶ.すなわち,x1と y との関係のうち,x1における y に関係ない部分を x2が抑制してい るという解釈に基づく用語である. Suppression の定義には種々のものが提案されている が,いずれにせよ,単相関と重相関の奇妙な関係の各分野における解釈のようである.ま た,x1と x2を説明変数に持つ重回帰式の決定係数 R2が,x1単独および x2単独での単回 帰分析における相関係数 r1および r2の 2 乗和よりも大きいときに enhancement が生じた とも言う.Suppression と enhancement はそれぞれ関係した概念である.
詳しくは例えば Lewis and Escobar (1986),Lynn (2003),Friedman and Wall (2005)
などを参照されたい.Friedman and Wall (2005) では,x1と y の相関が 0.8 であり,x2
と y の相関は 0 であるが,x1と x2を説明変数とする重回帰分析における x1の係数は 0.95 で,重相関係数が R2= 0.76 となる数値例を紹介している.さらに一般に,特に社会科学 分野では,本来は正であるべき回帰係数が負になったりする多重共線性 (multicollinearity) が問題とされる. これらの現象については,当該分野においてその意味を解釈する前に,線形代数学もし くは幾何学的な構造,すなわち X の生成する空間 S(X) の性質を吟味すべきである.その 理解により,得られた回帰式に対し,当該分野における知識をもとに,無理に意味付けす る類の愚を犯す可能性が低くなるであろう.Lewis and Escobar (1986) は,幾何学的な扱 いの重要性を説いた教育的な論文であり,Margolis (1979) もその種の幾何学的な扱いのメ リットを主張している.また,Herr (1980) は線形モデルの幾何学的な議論の歴史をまと めた興味深い内容を含んでいる. 4.5 単回帰か重回帰か これは筆者が実際に経験した例である.大学の授業では,「出席」,「課題」,「試験」間の 関係は,学生のみならず教員にとっても興味の的である.表 3 は,ある授業における 33 名 の学生に関するデータの要約統計量である.すべての相関は正であり,これは教育上首肯 できる結果である. このデータをもとに,z から x,z から y,および x から y の各単回帰式を求めると以下 のようになる. x =−97.8 + 14.6z y =−38.9 + 8.4z y = 17.1 + 0.58x いずれの回帰係数もすべて正であり,表 3 の正の相関を反映した教育上からも納得のいく 妥当な結果であるといえよう.各回帰係数が 0 であるという帰無仮説の検定の P 値もきわ
表 3 ある授業における要約統計量. 統計量 出席 (z) 課題 (x) テスト (y) 平均 11.94 76.61 61.26 標準偏差 1.01 19.38 13.89 相関 出席 (z) 課題 (x) テスト (y) 出席 (z) 1 0.77 0.61 課題 (x) 0.77 1 0.80 テスト (y) 0.61 0.80 1 めて小さく,統計的にも高度に有意である. それに対し,試験の点数 y を目的変数,z と x を説明変数に取った重回帰式を求めると y = 18.0− 0.10z + 0.58x となる.出席 (z) の係数はわずかながらも負となっている.ちなみにその P 値は 0.966 で あり,統計的に有意ではない.これはどう解釈したらよいのであろうか.出席が多い方が 試験の点数は悪い,あるいは検定の結果を踏まえて,出席は試験の点数に影響がない,とす べきであろうか.いずれにせよ教育上望ましくない結論であることは疑いない.この例は, 4.3 節とは逆に,本来関係があるのに関係がないように見えてしまうものとなっている. この問題の因果ダイアグラムは図 3 のようであり,図 2 と同じ構造を持っていて,3.3 節 で示した図 1(b) の状況である.図 3 から分かることは,z から y への因果のパスにおいて は x は中間変数であること,x から y への因果のパスでは,z は交絡要因となることであ る.3.3 節での考察を踏まえると,出席 (z) が試験 (y) に与える影響を評価する場合には, 課題 (x) をモデルに取り込んではならないこと,および,課題 (x) が試験 (y) に与える影 響を評価する場合には出席 (z) をモデルに取り入れなければならないこととなる.3.3 節 の図 1(d) に相当する状況である.これより,出席と試験との関係では単回帰式,課題と試 験の関係では重回帰式における係数が評価の対象となる.重回帰式での出席の係数は,何 ら意味を持たない値であり,解釈の対象とすべきではないことになる. 図 3 授業データの因果ダイアグラム. この種の数値例は人工的に容易に作ることができる.しかしここでの例は実際に生じた
ものであり,その意味で(少なくとも筆者には)大いに有用なものである. 5. おわりに 近年,データサイエンスの名のもとに,統計的データ分析のすそ野が広がりを見せ,デー タを活用した予測や意思決定への社会の期待は大きい.それらは AI と称されもするが,そ の理論的根拠は統計学である.統計的データ解析の諸手法の中でも重回帰分析は,最も頻 繁に用いられるものであり,その手法に関する正しい理解は,データサイエンス時代にあっ てもきわめて重要なものとなっている (cf. Iwasaki (2020)). 本論文では,特に現在および今後のデータサイエンス・統計教育を見据え,重回帰分析 に関する著者の意見を述べるとともに,教育上有用であると思われるパラドクスをいくつ か紹介した.統計的因果推論では,データの取り方に特に重きを置く.その意味で,「デー タ+ソフトウェア=結果」という単純な関係ではなく,「良質のデータ+ソフトウェア+正 しい知識=有用な結果」となることを期待したい. 謝辞 筆者の 2020 年度日本統計学会賞の授賞に関係された各位に感謝いたします.また,第 4 節で取り上げた例の多くは,筆者がサバティカルで 2014 年度前期に統計数理研究所に滞在 した折に,自らの知識獲得のインプットのために読んだ論文に基づいています.静謐な研 究環境を提供いただいた当時の統計数理研究所の皆さんに御礼申し上げます.インプット なきところにアウトプットはないことが再認識された貴重な機会でした. なお,本論文に関して適切かつ有益なコメントを頂いた査読者および本誌の編集委員の 方々に感謝します.最後になりますが,筆者のこれまでの統計学関連の活動に対しご支援 ご理解をいただいたすべての方々に御礼申し上げます.有難うございました. 参 考 文 献
Angrist, J. D. and Pischke, J.-S. (2009). Mostly Harmless Econometrics, An Empiricist’s Companion, Princeton University Press.
Angrist, J. D., Imbens, G. W. and Rubin, D. B. (1996). Identification of causal effects using instrumental variables (with discussion), Journal of the American Statistical Association, 91, 444–472.
Barker, D. J. P. (1995). Fetal origins of coronary heart disease, BMJ, 311, 171–174.
Barker, D. J. P., Eriksson, J. G., Fors´en, T. and Osmond, C. (2002). Fetal origins of adult disease: strength of effects and biological basis, International Journal of Epidemiology, 31, 1235–1239.
Berk, R. A. (2004). Regression Analysis. A Constructive Critique, Sage Publications.
Best, H. and Wolf, C. (eds.) (2015). Regression Analysis and Causal Inference, Sage Publications. Box, G. E. P., Hunter, J. S. and Hunter, W. G. (1978). Statistics for Experimenters, John Wiley & Sons. Chen, A., Bengtsson, T. and Ho, T. K. (2009). A regression paradox for linear models: Sufficient conditions
and relation to Simpson’s paradox, American Statistician, 63, 218–225.
Conway, D. A. and Roberts, H. V. (1983). Reverse regression, fairness, and employment discrimination, Journal
Conway, D. A. and Roberts, H. V. (1984). Rejoinder to comments on “reverse regression, fairness, and employ-ment discrimination,” Journal of Business & Economic Statistics, 2, 126–139.
Dempster, A. P. (1988). Employment discrimination and statistical science (with discussion), Statistical Science,
3, 149–195.
Ferber, M. A. and Green, C. A. (1984). What kind if fairness is fair? A comment on Conway and Roberts,
Journal of Business & Economic Statistics, 2, 111–113.
Friedman, L. and Wall, M. (2005). Graphical views of suppression and multicollinearity in multiple regression,
American Statistician, 59, 127–136.
Gelman, A. and Hill, J. (2007). Data Analysis Using Regression and Multilevel/Hierarchical Models, Cambridge University Press.
Gelman, A., Hill, J. and Vehtari, A. (2021). Regression and Other Stories, Cambridge University Press. Goldberger, A. S. (1984). Redirecting reverse regression, Journal of Business & Economic Statistics, 2, 114–116. Greene, W. H. (1984). Reverse regression: the algebra of discrimination, Journal of Business & Economic
Statistics, 2, 117–120.
Hern´an, M. A. and Robins, J. M. (2020). Causal Inference: What If, Chapman & Hall.
Herr, D. G. (1980). On the history of the use of geometry in the general linear model, American Statistician,
34, 43–47.
Holland, P. W. and Rubin, D. B. (1983). On Lord’s paradox, Principals of Modern Psychological Measurement:
A Festschrift for Frederic M. Lord (eds. H. Wainer and S. Messick), Routledge, 3–25.
Imbens, G. W. and Rubin, D. B. (2015). Causal Inference for Statistics, Social, and Biomedical Sciences. An
Introduction, Cambridge University Press.
岩崎学 (2016). 「統計家の役割:これまでとこれから」『日本統計学会誌』 45, 217–230. 岩崎学 (2019). 『事例で学ぶ!あたらしいデータサイエンスの教科書』翔泳社.
Iwasaki, M. (2020). Multiple regression analysis from data-science perspective, Advanced Studies in
Behav-iormetrics and Data Science, Essays in Honor of Akinori Okada (eds. Y. Imaizumi, A. Nakayama and S.
Yokoyama), Springer Nature, 131–140.
Lewis, J. W. and Escobar, L. A. (1986). Suppression and enhancement in bivariate regression, The Statistician,
35, 17–26.
Lord, F. M. (1967). A paradox in the interpretation of group comparisons, Psychological Bulletin, 68, 304–305. Lord, F. M. (1969). Statistical adjustments when comparing preexisting groups, Psychological Bulletin, 72,
336–337.
Lynn, H. S. (2003). Suppression and confounding in action, American Statistician, 57, 58–61.
Margolis, M. S. (1979). Perpendicular projections and elementary statistics, American Statistician, 33, 131–135. Michelson, S. and Blattenberger, G. (1984). Reverse regression and employment discrimination, Journal of
Business & Economic Statistics, 2, 121–122.
Miller, J. J. (1984). Some observations, a suggestion, and some comments on the Conway-Roberts article,
Journal of Business & Economic Statistics, 2, 123–125.
Morgan, S. L. and Winship, C. (2015). Counterfactuals and Causal Inference. Methods and Principles for Social
Research. Second Edition, Cambridge University Press.
Racine, J. and Rilstone, P. (1995). The reverse regression problems: statistical paradox or artefact of misspec-ification? Canadian Journal of Economics, 28, 502–531.
Rosenbaum, P. R. (1984). The consequences of adjustment for a concomitant variable that has been affected by the treatment, Journal of the Royal Statistical Society, Series A, 147, 656–666.
Rosenbaum, P. R. (2002). Observational Studies, Second Edition, Springer-Verlag.
Rosenbaum, P. R. (2017). Observation & Experiment. An Introduction to Causal Inference, Harvard University Press.
Rosenbaum, P. R. (2020). Design of Observational Studies, Second Edition, Springer Nature.
Simpson, E. H. (1951). The interpretation of interaction in contingency tables, Journal of the Royal Statistical
Tu, Y.-K., West, R., Ellison, G. T. H. and Gilthorpe, M. S. (2005). Why evidence for the fetal origins of adult disease might be a statistical artifact: the “reversal paradox” for the relation between birth weight and blood pressure in later life (with comments), American Journal of Epidemiology, 161, 27–37.
Wainer, H. (1991). Adjusting for differential base rates: Lord’s paradox again, Psychological Bulletin, 109, 147–151.
Wainer, H. and Brown, L. M. (2004). Two statistical paradoxes in the interpretation of group differences: Illustrated with medical school admission and licensing data, American Statistician, 58, 117–123.
Whiteside, M. M. and Narayanan, A. (1989). Reverse regression, collinearity, and employment discrimination,