2011 年度 修士論文
ブログにおけるコメントスパムの収集と分析
提出日: 2012 年 1 月 31 日
指導:後藤滋樹教授
早稲田大学 大学院基幹理工学研究科 情報理工学専攻 学籍番号: 5110B076-4
高野弘子
目次
1 序論 5
1.1 研究の背景 . . . 5
1.2 研究の目的 . . . 6
1.3 本論文の構成. . . 7
2 ブログ 8 2.1 ブログ . . . 8
2.1.1 ブログとは . . . 8
2.1.2 ブログにおける双方向交流 . . . 8
2.1.3 アフェリエイト . . . 9
2.2 ブログに対するスパム行為 . . . 10
2.3 巡回ツール . . . 10
2.4 関連研究 . . . 12
3 提案手法 13 3.1 提案手法 . . . 13
3.1.1 スパムコメントのカテゴリ . . . 13
3.1.2 提案手法 . . . 14
4 実証実験 16 4.1 HTMLファイルの分析要素 . . . 16
4.2 実験1 . . . 16
4.2.1 実験の手順 . . . 16
4.2.2 実験の結果 . . . 17
4.3 実験2 . . . 19
4.3.1 実験の手順 . . . 19
目次
4.4 実験3 . . . 20 4.4.1 実験の手順 . . . 20 4.4.2 実験の結果 . . . 21
5 まとめ 23
5.1 まとめ . . . 23 5.2 今後の課題 . . . 23
図一覧
1.1 インターネット利用時間における各サービスの占める時間 . . . 6
2.1 巡回ツールと正規ユーザーのコメントの違い . . . 11
4.1 データAのコメント構成 . . . 18
4.2 データBのコメント構成 . . . 18
4.3 URL件数による比較 . . . 21
4.4 コメント件数による比較. . . 22
表一覧
4.1 データA・データBから得られた情報 . . . 17
4.2 データCから得られた情報 . . . 19
4.3 URL件数による比較 . . . 20
4.4 コメント件数による比較. . . 21
第 1 章 序論
1.1 研究の背景
2010年度の流行語大賞に「〜なう」が選ばれたり、企業がリクルート活動にFacebookを使用 することがニュースになったりするなど、日本では手軽に情報を発信できるSNS(ソーシャル ネットワーキングサービス)が人気を集めている。一方こうした動きの中で影が薄くなってしまっ た印象のあるブログサービスだが、図1.1によればインターネットの利用時間ではSNSやマイク ロブログと比べ同程度であり、ブログサービスの利用も衰えていない。。ブログは現在では一般 化した情報発信ツールである。
ブログには運営者が書いた記事に対する感想などのコメントを利用者が入力することができ、
コメントを入力する際に任意のURLを記載することができる。これは本来、ブログの運営者同 士が交流を行うことを目的に付けられている機能である。しかしこれを悪用し、自身のブログへ 誘導する目的でURL付きのコメントを残す行為が多く存在する。投稿されたコメントは「荒ら しコメント」や「スパムコメント」と呼ばれ、交流や運営の障害となっている。また、このスパ ムコメントによって誘導されるサイトはアダルトサイトやマルチ商法の勧誘サイト等の有害サイ トであることも多く、そちらの面でも問題が多い。
このようなスパムコメントを防ぐ方法として、特定の単語を含むコメントを禁止したり悪質な コメントを行うもののIPアドレスをアクセス禁止にする等の対策がされてきた。しかしツール の高度化やコメントの文章を一見無害なものへ変えたりすることなどの抜け道が存在し、根絶 するまでには至っていない。2006年にはブログ運営会社の一つであるライブドアが短時間に多 くのコメントを残すユーザーを規制するスパムコメントの対策を行ったが、現在でも後を絶たな い。
第 1 章 序論
図 1.1: インターネット利用時間における各サービスの占める時間
1.2 研究の目的
現在スパムコメント対策として主に禁止ワードによるフィルタリングやコメント文字列に対す る特徴解析が研究されてきた。しかし以下の例のように、フィルタリングされそうな単語や自分 のサイトへの誘導がない、一見スパムコメントには見えないものも存在する。
• こんにちは^^。クリックしてたら、来ちゃいました。これも何かのご縁でしょう。ヨロ シクお願いします。^^
• とっても立派なブログですね。参考にさせて頂きますね。また、お伺いしま〜す。
• いつも面白楽しく拝見させて頂いております。今回初コメです。 これからのご活躍も楽し みに、もちろん拝読させていただきますよっ!頑張ってくださいね。
これらのコメントに付いているURLをたどると、資料請求をすすめるブログや運営会社から悪 質だとして凍結されているブログへ接続される。しかしこれらのコメントにはフィルタリングさ れそうな単語もなく、似通った単語の傾向も見られないため、上記の対策ではスパムコメントと 判定することは難しい。今回はこれらのコメントでもスパムと判定できるように、ほぼすべての スパムコメントが何らかのプログラムを使用し、自動的に書き込まれていることを利用する。
前述したスパムコメントはよく知られるスパムメールと同じく、自動的にブログを巡回しなが らコメントを残すプログラムを使用していると考えられる。そのため、記事の内容に即した正常
第 1 章 序論
なコメントよりもコメント本文のバリエーションはが少なく、複数のブログに全く同一の文章が 書きこまれると考えられる。そこで、複数のブログに残された同一の書き込みがあるコメントを 調べることで、スパムコメント、特に既存の研究では判定が難しい「フィルタリングされやすい 単語や自身のブログへの誘導も含まないスパムコメント」を発見し収集することを目的とする。
1.3 本論文の構成
本論文は以下の章により構成される。
第1章 序論
本研究の概要について述べる。
第2章 ブログ
ブログの基本構造やそれに関するスパム行為について述べる。
第3章 提案手法
今回行ったスパムコメントの収集方法やその評価について述べる。
第4章 実証実験
提案手法を行った結果について述べる。
第5章 まとめ
本論文のまとめを述べる。
第 2 章 ブログ
本章ではブログやそれに関係するスパム行為について説明する。
2.1 ブログ
2.1.1 ブログとは
文献[3]によれば、ブログとは以下のように定義される。
ブログとは、個人やグループなどにより運営され、時系列的に更新されるウェブペー ジの総称である。「Web」と「Log」(日誌)を一語に綴った「weblog」(ウェブログ) という言葉が誕生し、それを略して「blog」(ブログ)と呼ばれている。
ブログは自分でWebサイトを作る際には必要となるHTMLやCSSなどの専門知識を必要とせ ず、また無料でサービスを受けられることから 2004年から2005年にかけて爆発的に広まった。
文献[4]によると、平成20年1月において日本のアクティブブログ(一ヶ月以内に更新があった ブログ)数は約308万件であり、Webにおける主要な情報発信の場の一つとなっている。主な ブログサービスとしてはFC2ブログ、livedoor Blog、アメーバブログ、Yahoo! Japanブロ グなどが挙げられる。
2.1.2 ブログにおける双方向交流
ブログでの閲覧者と運営者を結ぶ機能としては、コメントとトラックバックの2つがあげられ る。
トラックバックとは相手のブログへ自分が内容を引用したことを知らせる仕組みである。ただ し単にリンクさせる場合とは異なり、引用先のURLが引用元へ送られるため相互リンクがつき、
そこから交流を持つことができる。
第 2 章 ブログ
またコメント機能とは、ブログの運営者が書いた記事に対しての感想等を書き込める、それぞ れの記事に固有の掲示板のことである。コメントには本文の他に投稿者の名前とURLを任意で 入力することができる。URLを入力した場合は名前の部分にリンクが張られ、運営者はそこか らコメントの投稿者と交流を持つことができる。
しかし「リンクが作成される」という特性のため、自身のブログへの誘導や検索エンジンでの 掲載順位を上げる目的で行うスパム行為が後を絶たない。そのためブログサービス提供業者は主 に以下のような対策機能を提供している。
フィルタリング 一定の条件を設け、その条件に触れた投稿を禁止する方式である。代表的なの は特定の複数の単語を「禁止ワード」として登録し、その単語が含まれるトラックバック やコメントを投稿できなくするものである。スパムに頻出するアダルト系の単語や金銭に 関する単語をこれに登録することで、かなりのスパムを防ぐことができる。
また、特定のIPアドレスからの投稿を禁止したり、投稿される言語を日本語のみに制限す ることにより、英語圏からのスパムを防ぐこともできる。
画像認証 投稿する際に表示された画像に則って文字入力を求めることで、プログラムによる投 稿を防止する認証方式。表示される画像はノイズがかかっていたり、入力すべき数字を日 本語で表現するなど、画像認識プログラムによる読取を難しくしている。
しかし、画像認証を破るプログラムによるスパム行為も近年確認されている。
またスパム行為を発見した場合にはサービス提供会社に訴えることができるが善意と悪意の境 界線が難しく、個人の基準の違いや私怨によってスパムではない投稿も報告される場合があるた め、選別が難しい。
2.1.3 アフェリエイト
アフェリエイトとはオンライン書店 Amazonが始めたWeb広告の一種である。成果報酬型と もいわれ、ブログ運営者が広告会社からWeb広告を自分のブログに貼り付け、閲覧者がそのWeb 広告から商品を買った時点で広告料を得ることができる。
広告を企業ではなく個人に掲載させることで個人は気軽に収入を得ることができ、企業側にも ブログという趣味・嗜好が同じ不特定多数が閲覧する場に掲載することでターゲットを絞って効 果的に訴えられるというメリットがある。しかしアフェリエイトが広まったことで、金銭を得る 目的で業者やスパマー以外にも一般人がスパム行為に加担することも増えてしまったという悪影 響も存在する。
第 2 章 ブログ
2.2 ブログに対するスパム行為
ブログの運営者や他の閲覧者にリンクを辿らせ、自分のサイトへ誘導することも目的の一つで あるが、大きな理由としてはSEOがある。
SEOとはサーチ・エンジン・オプティマイゼーションの頭文字をとったものでGoogleやYa- hoo!などの検索エンジンにおいて検索結果の上位に入ることを目的とした行為のことである。上 位に掲載されるよう、自身のサイトに対する検索エンジンからの価値を上げるには様々な方法が あるが、他のサイトからのリンクの数は重要な要素だと言われている。そのため実際にスパマー が運営するWebサイトへ訪問をしなくとも、リンクが付属するトラックバックスパムやコメン トスパムが残っていればスパマーの目的は達成されたことになる。
現在ブログに関するスパム行為としては以下のものがある。
トラックバックスパム 前述したトラックバック機能を使用し、自分の記事とは関係なくトラッ クバックを送る行為のこと。トラックバックが消されなければ、トラックバック元に対し て相互リンクを増やすことができ、自身の検索結果順位向上につながる。
コメントスパム 前述したコメント機能を使用し、自分のブログのURLをつけたコメントを投稿 する行為のこと。トラックバックスパムと同様にリンクが付いているため、投稿するだけ でリンクを増やすことができ自身の検索結果順位を上げることができる。
リファラスパム ブログにはアクセス解析機能がついており、自分のブログに訪問者がどのよう な検索結果から来ているのか、このページにはどのサイトからリンクをたどってきたのか がわかるようになっている。それを逆手に取り、リファラを偽造して訪問元をたどろうと するブログ運営者を誘導する行為がリファラスパムである。ブログの種類によってはブロ グ内に訪問元へのリンクが貼られるため、上記の2つのスパムよりも手軽にリンクを増や すことができる。
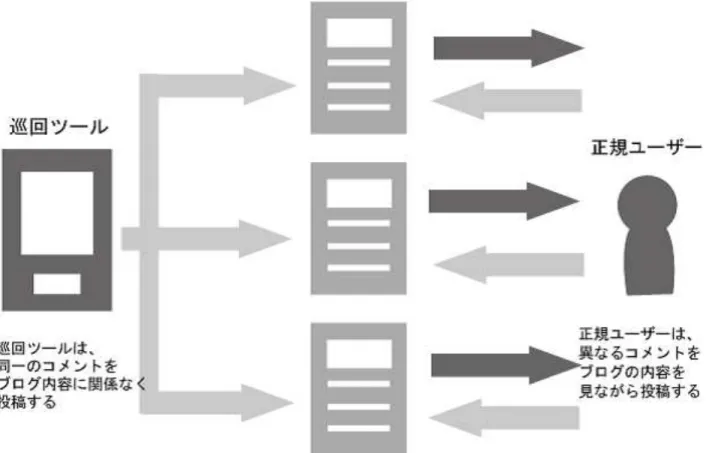
2.3 巡回ツール
スパムメールと同じく、トラックバックスパムやコメントスパムにおいても自動ツールが使用 されている。Googleで「巡回ツール コメント」を検索すると276,000もの検索結果が返って くることから、現在進行形でスパムが広がっていることが確認できる。また、このようなツール の価格も五千円程度から無料のフリーソフトまであるなどとても敷居が低い。スパムメールより も技術は必要がないが、「所有するブログを宣伝する行為」がどこからスパムになるかは曖昧で ある。このため一般のブログ運営者の多くが意識せずにスパム行為をしている可能性がある。
第 2 章 ブログ
図 2.1: 巡回ツールと正規ユーザーのコメントの違い
第 2 章 ブログ
これらのツールでは投稿者が投稿したいコメントを予め登録しておき、その中からツールがブ ログへコメントを投稿する。そのため、記事の内容やブログの運営者のコメントを踏まえてコメ ントを投稿する一般のユーザーよりも、投稿するコメントは登録したものの中しか選べない巡回 ツールを使った迷惑ユーザーの方がコメントの種類が少ないと思われる。そこで、複数のブログ からコメントのみを収集し、同一のコメントを見つけることで、迷惑ユーザーや同じツールの使 用者、迷惑ユーザーが運営する複数のブログを発見できるのではないかと考えた。
また、巡回ツールは無差別に行動するため長期間更新がないブログや、古い記事にもコメント を投稿する。ブログの運営者はスパムコメントを見つけた場合、すぐに消してしてしまうことが 多いが、このような放置されたサイトにはコメントが残りやすい。そのため今回はスパムコメン ト自体を検索することで、このようなスパムコメントが残っているブログから集中的にコメント を収集した。
2.4 関連研究
コメントスパムに対しての対策を行なっている研究は[5]がある。これはベイジアンフィルタ を使用し、スパムメール対策に使用される統計的フィルタリング手法をトラックバックスパムや コメントスパムに適用する研究をさらに発展させたものである。本研究とは、ブログ空間すべて からデータを収集するのではなくスパムが集まっているところへ絞る点で共通点がある。
第 3 章 提案手法
本章では、今回提案するスパムコメントのデータを効率的に集める方法について述べる。
3.1 提案手法
3.1.1 スパムコメントのカテゴリ
まず複数のブログに対して同一のコメントを送る行為のことをコメントスパム、そのコメント をスパムコメントと定義する。ただこの定義を使用すると、自動巡回ツールを使った場合と個人 が自分のコメントをコピーして投稿している場合が区別がつかないが、後者も前者と同じくブロ グの内容を踏まえていないためにコメントスパムとして扱う。また誘導される先が有害なサイト でなく個人のブログであっても複数のブログに同一のコメントを送っていればコメントスパムと する。
また集まったスパムコメントを以下の3つのカテゴリに分ける。
1. カテゴリ1
アダルト系や金銭に関する単語などを含む、一見してスパムコメントとわかるものをここ におく。このカテゴリに属すものはフィルタリングで大半を防ぐことができる。コメント スパムもこの形で送られるものが一番多い。
例「ホームビジネスに興味はありませんか。お金を稼ぎたい方、必見です。」
2. カテゴリ2
カテゴリ1のようなフィルタリングされやすい単語を含まないが、自分のサイトへ誘導す るものをここにおく。例「はじめまして、素敵なブログですね。私もブログを始めたので 是非参考にさせてください。よろしければ遊びに来て頂けると嬉しいです。」
第 3章 提案手法
いがその分運営者に消されにくく、リンクを保つことができる。例「いつも楽しく拝見し ております。これからもがんばってくださいね。応援しています!」
3.1.2 提案手法
スパムコメント、特にフィルタリングによって判別するのが難しいカテゴリ3のスパムコメン トを収集するために以下の点を踏まえ実験を行った。
• コメントスパムは主に巡回ツールを使用しているため、全く同じ文面のコメントが複数の ブログに存在する
• 同じサービス提供会社のブログでも運営者により対策に差がある。例えば活発に活動して いるブログでは運営者がスパム対策をしていたりこまめにコメントのチェックをするため スパムコメントが残りにくい。一方、放置されたブログでは多く残されていることが多い。
スパムコメントの収集を行うには幾つかの課題がある。まず、コメント数全体の分母が膨大であ ることである。人気のあるブログであれば記事一件につきスパムコメントを除いても200件以 上の正常なコメントが付くことがある。前述のとおりスパムコメントが残っている量はブログに よってかなりの開きがあるため、無作為にコメントを抽出しても無駄にリソースを消費すること になりかねない。
次に、記事内容への関連性からコメントスパムと判断するのが難しい、という点がある。「ブ ログの内容について引用を行う」ことが本来の目的であるトラックバックには、トラックバック 先の記事とトラックバック元の文章との関連性からスパム判定を行う研究[7]がある。しかしコ メントにはそのような具体的な役割が存在しないため、記事ではなくブログの運営者に対するコ メントや記事の題材のリクエスト等本文とは関連のないものもある。よってフィルタリングされ やすい単語をもつカテゴリ1以外のコメントを自動判別することは困難である。
以上のような理由により、コメントスパムを収集することは他のスパムと比べて難しい。しか しメールでのスパムとは異なり他人に送られたスパムの文章を見ることができることはスパム判 別において大きな利点である。これを利用し、以下の手順で進めた。
1. スパムコメントの本文を適当な長さで区切り、キーとして設定する。キーとして設定する 本文には、あいさつなどの使用頻度が高い部分はできるだけ除き、ある程度の長さを残す。
これは検索結果にこのコメント以外がヒットするのを防ぐためである 2. 設定したキーワードで対象をブログに限定して検索する
3. 検索結果として出てきたブログの情報をwgetコマンドにより取得し、そこからスパムコ メントを抽出する
第 3章 提案手法
4. 得られたコメントをキーに設定し、最初から繰り返す
第 4 章 実証実験
第3章で説明した実験を行った。その結果と考察を述べる。
4.1 HTML ファイルの分析要素
今回はwgetで得られたHTMLファイルから記事本文などを除いてコメントを操作しやすい CSVファイルに成形する。その際、コメントを含めて以下の要素を抽出した。
ファイル名 wgetにより得られた、ブログ記事が記載されているHTMLファイルの名前 記事作成日時 ブログ記事が作成され、公開された日付と時間
コメント本文 投稿されたコメント本文
コメント投稿日時 コメントが投稿された日付と時間
投稿者名 コメント投稿者の名前。コメントを投稿する際に任意で自由に入力できるもの
URL 原則はコメント投稿者の持つブログやサイト等のURL。コメントスパムはこれを利用し てSEO対策や自身のサイトへの誘導を行なっている
4.2 実験1
実験1では提案手法の評価実験を行う。
4.2.1 実験の手順
1. 検索エンジンにキーワード「文章を書くのがお得意のようですね」を入れ、上位100件の ブログからwgetでコメントを収集する。ここでは-Aオプションを使用し、ブログ全体の エントリー記事をすべて取得する。ここで得られたコメントデータをAとおく。このキー
第 4章 実証実験
ワードは一般的にスパムコメントとして認知度が高いものである。
2. 検索エンジンに急上昇ワードランキング[8]から2012年1月29日における上位のキーワー ド「2Dバッグ」を入れ、検索結果上位100件のブログからコメントを収集する。ここで 得られたデータをBとおく。急上昇ワードをキーワードとして設定する理由はスプログを 除き人間によって書かれているブログのコメントを取得したいためである
3. AとBにおける正規のコメントも含めた総取得数、その中に含まれるコメントスパムの数 と割合、得られたコメントスパムのカテゴリ構成をそれぞれ調べる。
4.2.2 実験の結果
データA・データBは表4.1のような結果となった。また、データA・データBのスパムコメ ントを含む割合と、そのカテゴリ構成を図4.2.2と図4.2.2へ表す。データAはスパムコメントを 検索キーワードとしているため放置されたブログを多く含み、全体のコメント数は少ない。一方、
データBは最近の話題に関連した単語を検索キーワードとしているため、頻繁にブログを更新す る運営者のブログが含まれている。アクティブな運営者のブログは固定の訪問者も多く投稿され たコメントに対して返信を行うことも多いため、ファイル数や総コメント数は多い。
表 4.1: データA・データBから得られた情報 データ名 総コメント数 総スパムコメント数
A 4,788 288
B 106,721 46
「スパムコメントが元から存在する場所に絞ったほうが効率よく収集することができる」とい うことがこれで実証できた。
また正規のコメントの投稿者やスパムコメントとその投稿者とは以下のような傾向が見られ た。
• 得られたデータの中で複数回名前が登場した投稿者は、正規の場合はほぼ1つのブログで しか確認できない。一方でスパムの投稿者の場合は1つのブログではほぼ1度しか投稿し ない
第 4章 実証実験
図 4.1: データAのコメント構成
図 4.2: データBのコメント構成
第 4章 実証実験
4.3 実験2
実験2では実験1で得られたデータAを使用してコメントスパムに付いているURL件数の増 減に対する実験を行った。
SEO対策の一環として衛星サイトの作成がある。衛星サイトとはメインのサイトの他に立ち 上げる関連サイトのことである。メインのブログでの話題と関連した内容でブログを立ち上げ、
リンクさせることで衛星サイトが入り口の役割を果たしメインのサイトの価値が上がる。悪質な サイトの場合は衛星サイトに人気のあるキーワードを検索用に複数置き、メインのサイトにリダ イレクトさせることで強制的に訪問させることもある。ここではこのようなスパマーが持つ衛星 サイトを発見することを目的として実験を行った。
4.3.1 実験の手順
1. 実験1において得られたスパムコメントについているURLの件数を調べる。スパムコメ ントを検索キーワードとしてそれぞれ検索にかけ、上位 20件のページを収集する。これを データCとおく
2. 新たに得られた20件のページの集合であるデータCとデータAをあわせ、定義された手 順に従いスパムコメントを新たに抽出する
3. 抽出されたスパムコメントについているURLの件数とデータAでのURLの件数を比較 する
4.3.2 実験の結果
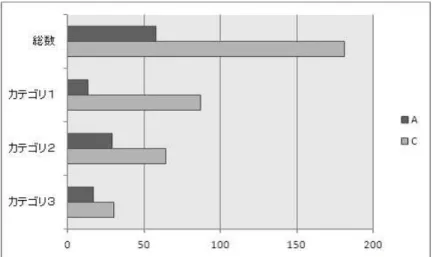
データCは表4.2のような結果となった。また実験2の結果は表4.4のようになった。グラフ
表 4.2: データCから得られた情報 データ名 総コメント数 総スパムコメント数
C 8,547 1,257
にしたものを図4.4.2に示す。総数から見れば15倍のURLを取得できたが、その多くがカテゴ リ1のものであった。以下のような低レベルのドメイン名とファイルの場所が一致している URL がよく見られた。
第 4章 実証実験
http://1k6Z6qD3.monju.me/1k6Z6qD3/
whoisを用いて調べると、両者とも同じIPアドレスを指した。また、コメント本文はほぼ同一
である。推測であるが、URLを対象にしたフィルタリングからの防衛策であると考える。CNAME を使用し、複数の別名を用意することで規制されたURLを集めたブラックリストとの一致を困 難にしている。
一方、カテゴリ2・3でのURL件数は微増となった。完全一致での検索では多くの新規 URL を見つけることができなかったが、同じ投稿者名をもつコメント本文では似通っているものが散 見した。一例をあげる。
心の隙間を埋めてくれるブログです。よかったら見てください。
心の隙間を埋めてくれるホームページです。よかったら見てください。
また、これ以外にも新たな文章が末尾に書きこまれているものや記号の差異(♪から☆に変える など)等の細かな変更が施されているものもあった。検索する際にある程度の曖昧さを許容する などの手法の改善が考えられる。
表 4.3: URL件数による比較
カテゴリ データA データC
1 16 936
2 34 38
3 13 21
合計 63 991
4.4 実験 3
実験3では提案手法における「発見できたスパムコメントを検索キーワードとして利用し、検 索を繰り返すことでどれだけスパムコメントを新たに取得できるか」を評価する。繰り返した データは実験2において得られた、データCを使用する。
4.4.1 実験の手順
1. データAで得られたスパムコメントの件数を調べる。今回においてはコメント本文は同一 で本文に書かれているURLのみ異なる場合は重複したコメントとして数えない
第 4章 実証実験
図 4.3: URL件数による比較
2. データCにおいても同様に重複したスパムコメントを削除する
3. データAのスパムコメントの件数とデータCでのスパムコメントの件数を比較する
4.4.2 実験の結果
結果は表4.4のようになった。それをグラフにしたものを図4.4.2に示す。実験2で得たデータ Cのファイル数は894個である。一つのキーワードで実験1では 100件のサイトを巡り820個の ファイル数を得たデータAと比べると1つのキーワードにつき20個しか取得していないものの、
得られたデータは約3倍となった。
表 4.4: コメント件数による比較 カテゴリ データA データC
1 13 87
2 29 64
3 17 30
合計 58 181
第 4章 実証実験
図 4.4: コメント件数による比較
第 5 章 まとめ
本研究のまとめと今後の課題について述べる。
5.1 まとめ
本論文ではスパムの中で正規のコメントと識別するのが難しい、フィルタリングされやすい単 語や自分のサイトへの誘導を含まないコメントも発見することを主目的とし、効率的にコメント スパムを収集する方法を提案した。
実験を行った結果、スパムコメントが消されずに残っているブログを中心にコメントを収集し たほうが効率よくスパムコメントを集めることができることが実証できた。
今後の発展としてはこの一連の流れを自動化しツール化することや、識別困難なコメントスパ ムに対するベイジアンフィルタの作成等があげられる。
5.2 今後の課題
今後の課題として挙げられるものを以下に挙げる。
データ容量の問題 無作為にコメントを抽出するよりも今回提案した方法の方が、全体に対する スパムコメントの割合が大きかったことは証明できた。しかし、スパムをある程度の量取 得するためには取得コメント全体のデータ量が大きくなってしまい、ソーティングに悪影 響を及ぼす。これ以上のスパムを調査するためにはアルゴリズムの改良が必要となる。
HTMLテンプレートの問題 今回の実験ではwgetコマンドで得られたHTMLファイルからコ メント等のデータを取り出す際に「公式で配布されているブログテンプレートのHTMLタ グの名称や構造が同じであること」を前提にしている。しかしブログサービス提供会社に
第 5 章 まとめ
態が発生する。サービス提供会社によらずコメントのみを抽出する研究も存在する[9]が今 回は実装には至らなかった。同様の仕様を実装することが今後の課題である。
謝辞
本学士論文の作成にあたり日頃より御指導を頂いた早稲田大学情報理工学研究科の後藤滋樹教 授に深く感謝致します。
また、研究を進めるにあたって多くの助言を頂いた後藤研究室の戸部和洋氏、同期に深く感謝い たします。
参考文献
[1] 財団法人インターネット協会 監修/インプレスRD インターネットメディア総合研究所 編, インプレスジャパン, 「インターネット白書2011」, 2011.
[2] 総務省|統計情報
http://www.soumu.go.jp/menu_seisaku/toukei/index.html
[3] 佐伯千種, 岩間 健宏,「ブログの実態に関する調査研究〜 ブログコンテンツ量の推計とブロ グの開設要因等の分析 〜」,2009, 総務省.
[4] 「平成23年度版 情報通信白書」
http://www.soumu.go.jp/johotsusintokei/whitepaper/h23.html
[5] 中村健二, 田中成典,「カテゴリ分類と時系列情報に基づくブログスパム判定手法の提案」, 情報処理学会論文誌 49(3), pp.1119-1130, 2008.
[6] IT用語辞典 e-Words http://e-words.jp/
[7] 藤村浩太, 西出隆志,「内容の類似性を用いたトラックバックスパム判別法の評価と考察」, 情報処理学会研究報告. CSEC, [コンピュータセキュリティ] 2009-CSEC-47(1), pp.1-6, 2009.
[8] Yahoo! 検索ランキング
http://searchranking.yahoo.co.jp/
[9] 吉田光男, 乾孝司,「ブログ記事集合を用いたポストとコメントとの自動分離抽出手法の提 案」, 情報処理学会研究報告. データベース・システム研究会報告 2009-DBS-149(20), pp.1- 8, 2009.
[10] whois 情報検索
http://www.cman.jp/network/support/ip.html