論 文
GPU による 2 次元アンサンブル経験的モード分解の高速実行 *
堀部 拓也
†a)清水 郁子
†b)中條 拓伯
†c)Fast Bidimensional Ensemble Empirical Mode Decomposition with a GPU
∗ Takuya HORIBE†a), Ikuko SHIMIZU†b), and Hironori NAKAJO†c)あらまし 本論文では,2次元アンサンブル経験的モード分解を並列化し,GPU上に実装して高速化を図っ た結果について報告する.入力画像のブロック分割境界における不連続なエンベロープの生成に対しては,ブ ロック分割境界にデータを余分に保持するオーバラップ領域を設け,精度低下に対処した.また,処理進行に伴 う曲面補間処理の精度低下に対しては,画像のブロック分割サイズを動的に変更し対処した.これらにより,解 析精度低下の抑制と高速化を両立させることが可能となる.またブロック内部の処理を並列化することにより,
GPUの搭載する大量の演算コアを有効利用する.従来手法による解析結果と比較した場合のPSNRの平均は 39.06dBとなり,提案手法の解析精度への影響が小さいことが確認できた.また512×512 pixelの画像に対し て,汎用CPUに比べ,GPU上に実装した提案手法は,最大422.7倍の速度向上率が得られた.
キーワード GPU,経験的モード分解,画像処理,並列処理
1.
ま え が き信号解析の分野において画像の特徴解析手法は高い 注目を集めており,特にマルチスケール特徴のAM- FM解析や多重解像度解析について多くの研究が行 われてきた.1次元信号に対するマルチスケール解析 手法の一つに,経験的モード分解(Empirical Mode Decomposition: EMD)がある[1].これは,入力信号 を固有モード関数(Intrinsic Mode Function: IMF) と呼ばれる狭帯域な信号の和に分解する手法である.
入力信号を周波数帯域ごとのIMFへと分解し,IMF を入力として瞬時振幅,瞬時周波数の解析手法である ヒルベルト変換に適用することで,1次元信号の時間– 周波数成分の解析が可能となる.
EMDのもつ高い解析性能に着目し,2次元信号 (画像)を対象としてEMDを拡張した手法に,2004 年 に Nunes ら が 考 案 し た2次 元 経 験 的 モ ー ド 分 解(Bidimensional Empirical Mode Decomposition:
†東京農工大学,小金井市
Tokyo University of Agriculture and Technology, 2–24–16 Naka-cho, Koganei-shi, 184–8588 Japan
a) E-mail: [email protected] b) E-mail: [email protected] c) E-mail: [email protected]
*本論文は学生論文特集秀逸論文である.
BEMD)があり[2],医療画像解析や,画像の局所特 徴の解析やフラクタル解析といった様々な応用研究が 行われている.しかしながら,EMD及びBEMDは,
Mode Mixingと呼ばれる,本来は異なるIMFとして 分解されるべき周波数成分が,一つのIMFとして出 力されてしまう問題点がある.
この問題の解決のための一手法に,2009年に考 案されたアンサンブル経験的モード分解(Ensemble Empirical Mode Decomposition: EEMD)がある[3]. EEMDはEMDの発展手法として,高い解析性能と Mode Mixing問題を回避するという利点をもつことか ら,EMDに置き換わる手法として期待されている.同 様に,EEMDの手法をBEMDに適用した2次元アン サンブル経験的モード分解(Bidimensional Ensemble Empirical Mode Decomposition: BEEMD)が考案 されているが[4],計算量が膨大となる点が問題視され ている.
そこで本研究では,大量の演算コアを搭載したプロ セッサであるGraphics Processing Units (GPU)上に おいて,BEEMDを並列化する手法を提案する.本研 究の目的は,従来の逐次処理との解析結果の精度差を 最小にとどめ,GPUに適した並列化によりBEEMD を大幅に高速化することである.本研究で提案する並 列化手法により,BEEMDの実行時間の大幅な短縮が
可能となり,画像処理時間の制約がある分野において も詳細な解析が容易となることから,画像解析の応用 分野が広がることが期待できる.
本論文の構成は,2.で関連研究を紹介し,3.にお いて2次元アンサンブル経験的モード分解の理論につ いて解説する.4.では,提案する2次元アンサンブル 経験的モード分解のGPUによる並列化手法について 示す.5.では,提案手法を実際のマルチコア(CPU), メニーコア(GPU)環境において実装し,評価した結 果を示す.最後に6.でまとめる.
2.
関 連 研 究本研究に関わりのある高速化手法として,ブロック分 割を用いることで2次元経験的モード分解を高速化し たAdaptive Lapped Block Bidimensional Empirical Mode Decomposition (ALBBEMD) [5]がある.
ALBBEMDは,Sabriらが入力画像をブロック分 割して,2次元経験的モード分解を実行することで高 速化を試みた手法である.その基本的なアイデアは,
4. 1で示す静的ブロック分割方式に近いものである.
これは,入力画像を複数ブロックに分割し,分割境界 をある程度オーバラップさせることで不連続な中間処 理結果(エンベロープ)の生成を抑制しており,更にブ ロック分割境界のエッジによってオーバラップサイズ を決定することで,解析精度の維持と高速化の両立を 実現している.
しかしながら,ALBBEMDでは,ブロック分割方 式における分割数は四つに固定されており,[5]におい ても適用例はシンプルな画像に対してのみである.ま た,オーバラップサイズを拡張することで不連続なエ ンベロープ生成を抑制できるが,入力画像を4分割以 上してしまうと低周波成分解析時に解析精度が著しく 低下してしまう.このことから,ALBBEMDのオー バラップサイズ拡張手法は,本来BEMDが効果を発 揮するような,複雑に周波数が混ざり合った画像にお いて効果を発揮するとは限らないと考えられる.
ブロック分割数の制限は大きな画像に適用した場合 に期待できる速度向上率が低下することを意味するた め,GPUのような大量の演算コアをもつプロセッサ を用いた実装には向いていない.
3. 2
次元アンサンブル経験的モード分解 本章では,提案する並列化手法の理論的な背景とし て,2次元経験的モード分解(BEMD)の理論と問題点を示す.次に,その発展手法であるアンサンブル経験 的モード分解(EEMD)について述べた後に,BEMD とEEMDを組み合わせた手法として2次元アンサン ブル経験的モード分解(BEEMD)について示す.
3. 1 2次元経験的モード分解
2次元経験的モード分解は,以下に示すEMDの適 用対象を1次元信号から2次元信号(画像)に拡張し た手法であり,そのアルゴリズムによって幾つかの種 類が存在する.本論文では,解析性能において優位性 を示し,なおかつ多くの応用研究が行われている事か ら,Bidimensional Empirical Mode Decomposition (BEMD)を今後2次元経験的モード分解として扱う こととする.
経験的モード分解(EMD)のアルゴリズム
(1) 入力In(t)をprotoIMFpn(t)に代入: pn(t) =In(t),初期値は原信号
(2) protoIMFpn(t)にふるい処理を適用 a) protoIMFpn(t)より極大,極小値を検出.
b) 三次スプライン補間を用いて,全ての極大 値を繋いだ上側エンベロープemax(t)と極小値 を繋いだ下側エンベロープemin(t)の抽出
c) 上側・下側エンベロープの平均である中間 エンベロープm(t)の抽出:m(t) = (emax(t) + emin(t))/2.
d) protoIMFpn(t)より中間エンベロープを 引き,値を更新:pn+1(t) =pn(t)−m(t).
e) protoIMFpn+1(t)がIMFの条件を満た すならばsn(t) = pn+1(t)としてIMFを出力.
そうでない場合はa)∼e)の処理を繰り返し
(3) 入力In(t)からIMFsn(t)引いて更新:
In+1(t) =In(t)−sn(t)
(4) In+1(t)に含まれる極値数が3未満の場 合,In+1(t)を残余信号r(t)として出力.そうで ない場合,In+1を新たな入力として(1)から繰 り返し
既存の画像のマルチスケール解析手法であるウェー ブレット変換やウィグナー分布,ガボール関数等と比 較してBEMDが優れている点として,完全データ駆 動型手法である事が挙げられる.既存手法では解析に 用いるマザーウェーブレットやPredeterminedフィル タによって解析結果が異なってくるため,画像ごとに最 適なフィルタ等を選択する必要がある.一方,BEMD
図1 極大値検出とパディング Fig. 1 Detecting the maximums and padding.
では,画像ごとにそういったフィルタを用いることな く,高精度な解析結果を得ることができる.
3. 1. 1 BEMDのふるい処理
BEMDは,入力信号を狭帯域な信号である2次元 IMFの和として分解する手法であり,以下にBEMD のふるい処理における各処理の詳細を示す.
a ) 極 値 検 出
2次元信号に対する極値検出では,信号に含まれる 極値(極大値及び極小値)を検出するために,入力信 号I(x, y)の各点(x, y)の値を隣接ウィンドウを用い て隣接8点と比較することで極値を決定する.隣接8 点より値が大きい(小さい)場合その点は極大値(極小 値)となる.極値検出の次の処理であるエンベロープ 計算において極値の値I(x, y)及び座標(x, y)を用い るため,それぞれの情報を異なる配列に格納する必要 がある.この処理をパディングと呼ぶ.
図1に5×5の入力信号を用いた場合の極値検出 の結果とパディング後の配列を示す.ここでは,極値 の検出を座標(0,0)よりx方向に順に行い,x= 4に なった段階で次の行(y= 1)に移動して同様に処理を 継続する.パディングに用いる配列のうち,max x及 びmax yは極値の座標を格納する配列であり,max h は極値の値(画素値)を格納する配列である.パディ ング後の配列のインデックスを参照することにより,
入力信号の極値の座標と値を得ることができる.隣 接ウィンドウ方式を用いる場合に極値が連続して検出 されることがないため,極値の最大数は入力画像の height×width/4となる.そのためパディングに用い る配列として入力画像のheight×width/4に相当す るメモリを確保すればよい.
BEMDの極値検出を逐次処理で計算する場合には,
画像の全ての座標に対して極値検出を行うため,入力 サイズをN×Nとした場合,計算量はO(N2)となる.
また隣接ウィンドウ方式以外の極値検出手法として,
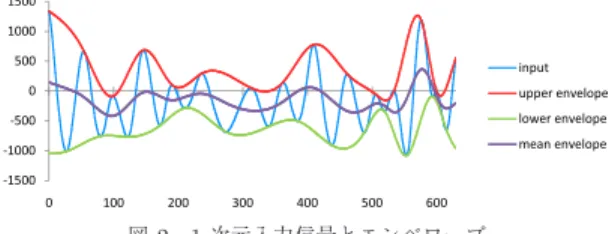
図2 1次元入力信号とエンベロープ Fig. 2 Single dimensional signal and its envelopes.
モルフォロジカル再構成を用いる方法やwatershedを 用いる方法が存在する[6].
b ) エンベロープ計算(曲面補間)
2次元経験的モード分解におけるエンベロープ計算 には一般に極値間を補間する曲面補間手法を用いる.
1次元の場合を例に,図2をもとに説明する.エンベ ロープとは,信号に含まれる極大値(極小値)間を滑ら かに繋いだ曲線であり,極大値を繋いだものを上側エ ンベロープ(upper envelope),極小値を繋いだものを 下側エンベロープ(lower envelope)と呼ぶ.図2に,
ある入力信号における上側及び下側エンベロープと,
その平均値である中間エンベロープ(mean envelope) を示す.曲面補間はこの処理を2次元に拡張したもの である.
BEMDでは,高い精度で散逸点を曲面補間できる 手法であるRadial Basis Function (RBF)を用いて エンベロープ計算を行う[7].曲面補間にRBFを用い る利点として,高精度な曲面補間が可能であるため,
画像をより細かく意義のある2次元IMFに分割でき る点が挙げられる[8], [9].
極値数をMとした場合,RBFの関数は以下のよう に表される.
s(x) =pm(x) + M i=1
λiφ(x−xi), x∈Rd, λi∈R
(1)
pmは低次多項式であり, · はユークリッドノルム を表している.またλiはRBFの係数であり,φは基 底関数と呼ばれる実関数である.xiはRBFの中心を 表している.
pm(x)及びλi,φは以下の式を解くことで求められ る.式(2), (3)におけるxi及びyiは極値の座標を,
fiは極値の値を示している.
⎡
⎢⎢
⎢⎢
⎢⎢
⎢⎢
⎢⎢
⎢⎣
φ1,1· · ·φ1,M x1 y1 1 ..
. .. .
.. .
.. .
.. . φM,1· · ·φM,M xM yM 1
x1 · · ·xM 0 0 0
y1 · · ·yM 0 0 0
1 · · · 1 0 0 0
⎤
⎥⎥
⎥⎥
⎥⎥
⎥⎥
⎥⎥
⎥⎦
⎡
⎢⎢
⎢⎢
⎢⎢
⎢⎢
⎢⎢
⎢⎣ λ1
.. . λM
ax ay a0
⎤
⎥⎥
⎥⎥
⎥⎥
⎥⎥
⎥⎥
⎥⎦
=
⎡
⎢⎢
⎢⎢
⎢⎢
⎢⎢
⎢⎢
⎢⎣ f1
.. . fM
0 0 0
⎤
⎥⎥
⎥⎥
⎥⎥
⎥⎥
⎥⎥
⎥⎦
(2)
pm(x) =axxi+ayyi+a0 (3) φ(r) = 0 (r= 0)
r2log(r) (r= 0) (4) RBFの係数λiを求めるための式(2)は,一般に Ax=bの形で表すことができ,連立一次方程式の解 法により解くことが可能である.本研究では式(2)の 求解に数値解析ソフトウェアライブラリであるLA- PACK [10]を用い,実際の関数としてはdgesv()を 利用する.関数dgesv()は倍精度の連立一次方程式の 解を求める関数であり,その内部計算としてLU分解 と前進代入及び後退代入を行っている.極値数をM とした場合の計算量は,LU分解がO(M3),前進代入 及び後退代入がO(M2)であるため,RBFの計算量は O(M3) +O(M2)となる.また計算に必要なメモリ量 は式(2)の行列が密行列であるためO(M2)となる.
前述したようにRBFは高精度な曲面補間が可能で あるが,一方で計算量と必要メモリ量が非常に大きい という欠点をもつ.RBFの計算量はO(M3)である ため,極値数の増加とともに計算時間は急激に増大す る.大きな画像サイズに対しては膨大な計算時間と必 要メモリ量の増大を招き,512×512pixelの画像を倍 精度浮動小数点数を用いてBEMDにより解析した場 合,必要最大メモリ量は約32GBといったものとなる.
c ) protoIMF算出
BEMDにおけるprotoIMF計算は,EMDのpro- toIMF計算を単純に2次元に拡張することで実現で きる.入力画像の各点(x,y)において,エンベロー プ計算で求めた上側エンベロープEnvmax と下側エ ンベロープ Envmin の平均を計算し,前ステップの protoIMF pnから引くことで算出できる.したがっ て,protoIMFpn+1の算出式は以下のようになる.
pn+1=pn−(Envmax+Envmin)/2 (5) protoIMF計算を逐次処理で行う場合には,画像の 全ての画素に対し計算するため,入力画像サイズを N×N とした場合の計算量はO(N2)となる.
d ) IMF判 定
BEMDにおけるIMFの判定条件にはEMDと同じ
く標準偏差(Standard Deviation: SD)を用いる.前 ステップのprotoIMFをpn(x, y),求めたprotoIMF をpn+1(x, y)とすると,標準偏差は以下の式により求 めることができる.
SD= 1 M N
M x=1
N y=1
|pn+1(x, y)−pn(x, y)|2
|pn(x, y)|2 (6) 式(6)で求められる標準偏差がしきい値以下になった 場合にprotoIMFを2次元IMFとして出力する.
3. 1. 2 BEMDの問題点
EMD及びBEMDは優れた解析性能をもつが,その 一方で前述のMode Mixingに加え,Boundary Effect が発生するといった問題点が指摘されている.
Boudary Effectとは,信号の端点付近における誤 差の問題である.EMD及びBEMDのふるい処理で は,入力信号の極値を用いてエンベロープ計算を行う ため,極値情報が乏しい信号の端点付近において誤差 が発生してしまう.特に2次元画像では画像の端が全 て端点となるため,1次元信号と比較してBoundary Effectの影響が大きい.
3. 2 アンサンブル経験的モード分解(EEMD) EMDにおけるMode MixingやBoundary Effect の問題を解決するための手法として,WuとHuangら は2008年にアンサンブル経験的モード分解(Ensem- ble Empirical Mode Decomposition: EEMD)を考 案した[3].その原理は,まず入力信号にホワイトノイ ズを加算した信号を複数パターン生成し,全てのノイ ズ加算信号に対してEMDを適用してノイズ加算IMF を求め,最後に全てのノイズ加算IMFの平均である アンサンブルIMFを出力するというものである.
EEMDにおいて,アンサンブルIMFを求めるため のノイズ加算信号の数をアンサンブル数と呼ぶ.加算 したノイズが結果に与える影響を抑えるためには,ア ンサンブル数は数十〜100程度必要とされている[3]. EEMDの計算では,アンサンブル数分のノイズ加算 信号に対してEMDを適用する必要があるため,計 算時間はEMDの数十〜100倍以上になる.EEMD はEMDと比較して高い計算コストを伴うが,Mode MixingやBoundary Effectといった問題を解決して いることから,EMDに置き換わる手法として期待さ れている.
3. 3 2次元アンサンブル経験的モード分解の概略
BEMDを適用した際に発生するMode Mixingや Boundary Effect問題の解決法として,BEMDにア
ンサンブル経験的モード分解(EEMD)の手法を組 み合わせた,2次元アンサンブル経験的モード分解 (Bidimensional Ensemble Empirical Mode Decom- position: BEEMD)が考案されている[4].なお[4]の 論文ではAssisted signal-based BEMDという名称が 用いられているが,実際にはBEMDとEEMDを組 み合わせた手法であるため,本論文ではBEEMDと 呼ぶこととする.
BEEMDの基本的なアルゴリズムはアンサンブル
経験的モード分解と同じであり,適用対象が1次元信 号から2次元画像に変わっただけである.そのため EEMDの内部処理を2次元経験的モード分解の処理 に変更したものがBEEMDとなる.
BEEMDでは,入力画像に対して複数パターンのホ ワイトノイズ画像を加算した画像を生成し,各ノイズ 加算画像に対してBEMDを適用してノイズ加算2次 元IMFを求める.得られたノイズ加算2次元IMFの 全体平均を求め,これを2次元アンサンブルIMFと して出力する.このときの各ノイズ加算画像の処理は 独立であるため,並列に計算することが可能である.
BEEMDの計算におけるアンサンブル数は経験的
に30〜50程度必要であるため,BEEMDの計算時間 はBEMDの30〜50倍になる.実際にはノイズを加 算することにより極値数が増加するため,更に計算時 間が必要となる場合が多い.BEEMDはBEMDのも つMode MixingやBoundary Effectといった問題を 解決しているが,極めて長い計算時間を必要とするた め,実際の応用は簡単ではない.
4. 2
次元アンサンブル経験的モード分解の 並列化ここでは,2次元経験的モード分解(BEMD)及び 2次元アンサンブル経験的モード分解(BEEMD)の 並列化の提案手法について述べる.まず画像の静的 なブロック分割によるBEMDの並列実装において生 じる問題点について示し,その後,前述の問題を解 決するために我々が考案した動的なブロック分割によ るBEMD及びBEEMDの並列化手法について解説 する.
4. 1 静的ブロック分割による並列化
GPUの開発環境であるCUDAを用いた実装では 一般的に入力データを複数のブロックに分割し,GPU 内部のStreaming Multiprocessor (SM)単位で処理 を割り付ける.そのためBEMDを並列化するために
入力画像のブロック分割を行うが,単純に入力画像を ブロック分割をしてBEMDを適用すると,以下に述 べる二つの問題が生じる.
• ブロック分割境界における不連続なエンベロー プの生成
一つ目の問題は,エンベロープ計算における極値間 の曲面補間処理によって発生する問題である.3. 1. 1 のb)で述べたエンベロープ計算に用いるRBFでは,
入力信号全ての極値を参照して各々のλiを算出する (式(2)).そのため入力画像を単純に分割し,各ブロッ クが独立してエンベロープを算出すると,各ブロック は隣接ブロックの極値情報をもたない状態で曲面補間 することになるため,ブロック境界において不連続な エンベロープが生成されてしまう.図3に単純な分割 による不連続なエンベロープの生成例を示す.図3は,
x軸とy軸の中心127においてブロック分割を行った 場合のエンベロープであり,特に二つのブロック境界 が重なる(x= 127,y= 127)付近において不連続な エンベロープが生成されていることが確認できる.
この問題に対しては,画像のブロック分割境界に オーバラップ(重ね合わせ)領域を設けることにより対 処が可能である[5].ブロック分割にオーバラップを組 み合わせた場合の処理の概念図を図4に示す.隣接ブ ロックのデータを余分にもつように入力画像を分割し,
各ブロックで独立してIMFを求める.解析結果とし
図3 領域境界におけるエンベロープの不連続性 Fig. 3 Discontinuous envelopes at boundaries.
図4 オーバラップ領域を適用したBEMD Fig. 4 BEMD with overlapped area.
て得たIMFはオーバラップ領域を切り捨てた状態で 結合する.このような処理を行うことにより,分割境 界においても連続なエンベロープを生成することが可 能となる.このように入力画像を処理の最初にブロッ ク分割した状態で全ての処理を行う手法では,処理の 最後までブロック分割サイズを変更しないため,この 方式を今後静的ブロック分割方式と呼ぶ.
• BEMDの処理進行に伴うブロック内極値数減 少による曲面補間精度の低下
これは,BEMDが入力画像を高周波成分で構成さ れるIMFから順に分解することに起因する問題であ る.高周波成分を含む入力画像では,ブロック内に含 まれる極値数も多くなるため,オーバラップ領域を設 けることによって不連続なエンベロープ生成を防ぐこ とができる.しかしながら,高周波成分のIMF分解 の後に入力となる低周波成分主体の入力信号は,分割 後のブロックに含まれる極値数が減少するため,曲面 補間を行うために十分な極値数を確保できずに不連続 なエンベロープを生成してしまう.
ブロックサイズとオーバラップ領域(BlockSize = 64, OverlapSize = 24)を固定してBEEMDを適用した 場合,高周波成分で構成されるIMFではブロック分割 の影響が見られないが,低周波成分で構成されるIMF ではブロック分割が解析結果に影響を与える.
この問題に対しては,最初の分割時に低周波成分画 像の解析に問題ない範囲でオーバラップ領域を広げる 方式が考えられるが,分割ブロックとオーバラップ領 域を合わせたサイズが大きくなるうえ,細かくブロッ ク分割することが不可能である.そのため静的ブロッ ク分割方式による高速化には限界があり,多数のプロ セッサコアを用いた並列化には不向きである.そこで 我々は,解析性能の低下とブロック分割による高速化 を両立する手法として,次節で述べる動的ブロック分 割に基づいた並列化方式を提案する.
4. 2 動的ブロック分割による並列化
動的ブロック分割方式は,入力信号に含まれる極値 数の変化に伴い,ブロック分割サイズとオーバラップ 領域サイズを動的に変更することにより,高速化と解 析精度の維持を両立させる手法である.本方式は静的 ブロック分割方式のようにオーバラップ領域を無駄に 広くとる必要が無く,画像を細かく分割することがで きるため,GPUを用いた並列化にも適している.
しかしながら,各SM内のスレッドは分割ブロック にオーバラップ領域を含めた領域に対して処理を行う
ため,オーバラップ領域を増やし過ぎることは,並列 化の恩恵を捨てることとなる恐れがあり,慎重に選定 する必要がある.
また入力画像が大きくなった場合においても有効に 機能するため,画像サイズの増加にも対応することが 可能となる.以下では動的ブロック分割方式に基づい たBEMD及びBEEMDの並列化手法について,それ ぞれの処理の流れと特徴を述べる.なお以下で述べる 手法は,GPUのStreamingMultiprocessorをCPU のコアに置き換えることでマルチコアCPUにも適用 可能である.
4. 2. 1 動的ブロック分割に基づくBEMD
動的ブロック分割による2次元経験的モード分解(Bi- dimensional Empirical Mode Decomposition based on Dynamic Block Partitioning: DBPBEMD)は,
動的ブロック分割方式をBEMDに適用した手法で ある.
実際に画像に対してDBPBEMDを適用する場合を 考える.まずIMF1を求める際には入力画像に含まれ る極値数が多く,入力画像を細かくブロック分割する.
GPUのStreamingMultiprocessor (SM)は,その各 ブロックに対し,独立に2次元経験的モード分解を 行い,ブロックごとのIMF1を求める.全ブロックの IMF1が求まった段階でSM間で同期を取り,IMF1 を結合した後に入力とIMF1の残余を求める.次に IMF2を求める場合の極値数の減少がそれほど大きく なく,ブロックサイズとオーバラップ領域はそのまま で処理する.IMF3を求める場合,その入力画像に含 まれる極値数が減少しているため,ブロックの分割サ イズを1段階大きくすることで,ブロック内に十分な 極値数を確保する.その後はIMF1の場合と同様に,
各ブロックのIMF3を求めた後にSM間で同期を取 り,IMF3を結合する.IMF4についても,そのまま で処理し,最後にIMF5を求める場合は,入力画像に 含まれる極値数が少ないためブロック分割せずに処理 を行う.この際GPUのSMは協調して入力画像全体 を処理する.
4. 2. 2 動的ブロック分割に基づくBEEMD
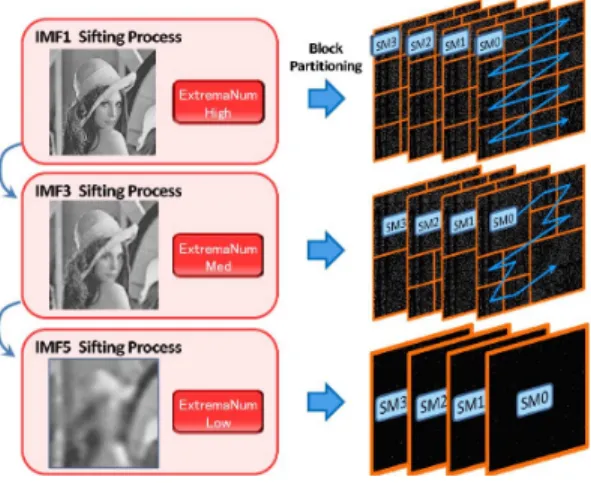
動的ブロック分割による2次元アンサンブル経験 的モード分解(Bi-dimensional Ensemble Empirical Mode Decomposition based on Dynamic Block Par- titioning: DBPBEEMD)は,動的ブロック分割方式 をBEEMDに適用した手法である.DBPBEMDの 概念を図示したものを図5に,フローチャートを図6
図5 動的ブロック分割によるBEEMD Fig. 5 BEEMD with dynamically partitioned blocks.
図6 動的ブロック分割によるBEEMDのフローチャート Fig. 6 Flowchart BEEMD with dynamically partitioned
blocks.
に示す.
このフローチャートの処理は,ノイズ加算を除き,
全てGPU内のSM (Streaming Multiprocessor)に おいて実行しており,処理結果の表示等については,
PC内のCPUが行っている.
図5において,高周波成分の多い,つまり極値数の
多いノイズ付加画像ごとにSMを割り当て,画像内の 分割ブロックに対しては,SM内のマルチスレッドに より処理を行う.図6において,Iは原画像,gmは ホワイトノイズを示し,Imはノイズが加わった画像 として各SMが処理する.
実際に画像に対してDBPBEEMDを適用する場合 を考える.まず入力信号にSM数分のホワイトノイズ を加算してノイズ加算信号を生成する.次にSMは担 当するノイズ加算信号をブロック分割し,ノイズ加算 信号ごとにIMF1を求める処理を行う.SMはIMF1 を求め終わった段階で同期を取らずに次のIMFを求 める処理に移る.IMF2も同様に求めた後,IMF3を 求める場合を考えると,この例ではIMF3の入力画像 に含まれる極値数が減少しているため,SMはブロッ クサイズを適度なサイズに変更し,ブロック内に十分 な極値数を確保した状態でIMF3を求め,IMF3を分 解した段階で同期を取らずに次のIMFを求める処理 に移る.IMF4も求めた後に,最後にIMF5を求める 場合には,IMF5の入力画像に含まれる極値数が少な いためブロック分割せずに処理を行う.この処理を全 てのアンサンブル数分行い,最後にアンサンブルIMF を求めて処理を終了する.
上記のようにDBPBEEMDは,SMが担当するノ イズ加算信号の全てのIMFを求める処理を行うため,
アンサンブルIMFの計算時以外にはSM間同期を取 る必要がない.そのためSMがバリア同期待ちでアイ ドル状態に入ることが少なくなり,GPUの演算コア を効率的に活用することができる.
4. 3 分割ブロック内処理の並列化
本節では,動的ブロック分割方式により分割したブ ロック内の処理の並列化について述べる.分割ブロッ ク内の処理はGPUのSMを用いて処理する必要があ るため,並列実装することで高速化が可能である.以 下では分割ブロック内の処理のうち,BEMDの極値 検出,エンベロープ計算の並列化について述べる.
4. 3. 1 極 値 検 出
極値検出では,画像の各点が極値であるかどうか,
GPUの各スレッドが判定を行い,その後エンベロー プ計算の前処理として,図1で示すパディング処理を 行う.極値判定については判定する点の周囲8点の情 報があれば判定が可能であるため,スレッドは独立し て並列に処理可能である.しかし,極値検出後の配列 のパディング処理を並列化するには,配列のどの位置 に極値情報を格納するか,各スレッドは知る必要性が
図7 Prefix Sumによる極値パディング処理 Fig. 7 Padding the maximums with Prefix Sum.
ある.
本提案手法では,極値情報のパディング処理には,
図7に示すPrefix sumと呼ばれる手法を用いる.こ の処理は,GPU内のSMが並列に行う[11].図7よ り,まず入力画像の各点に対して極値の座標に1を,
非極値の座標に0を格納し,極値をマッピングした配 列を生成する.次に極値のマッピング配列を1次元の 配列とみなしてPrefix sumを適用する.Prefix sum により得られた配列は,極値の座標と何番目の極値で あるかを示しているため,元の入力画像の該当座標を 参照することにより,極値の値を知ることができる.
上記処理の計算量について,入力画像をN×N,プ ロセッサ数をPとした場合,画像の各座標について 極値判定するため,計算量はO(NP2)となる.Prefix sumのアルゴリズムは,ステップ数がlogN2回であ り,各ステップにおいてNP2 回の演算が必要となるた め,パディング処理全体の計算量はO(NP2logN2)と なる.Prefix sumの計算量はO(N2)よりも大きいが,
GPUのようにPが大きい場合には,大きな性能向上 が期待できる.
4. 3. 2 エンベロープ計算(曲面補間)
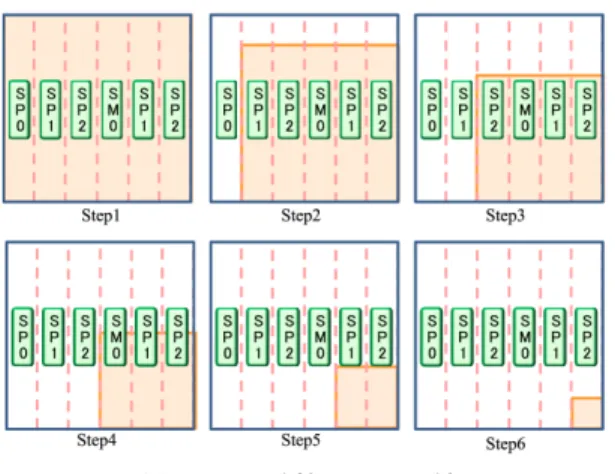
エンベロープ計算では,3. 1. 1のb)で述べたよう にRadial Basis Functionの内部処理として連立一次 方程式を解く必要があり,それには,LU分解の並列化 を行う.本研究では,LU分解の並列化においてcyclic 分割方式を採用している.
cyclic分割によるLU分解の動作を表したものを 図8に示す.図8のSPはGPUのSMが搭載して いるStreaming Processorを指している.まず入力と なる行列に対して列方向にSPを割り当てる(Step1). Step2では,SP0が1列目の枢軸要素を全て0にし,
次のStep3ではSP1が枢軸要素を全て0にし,Step4
図8 cyclic分割によるLU分解 Fig. 8 LU decomposition with cyclic partitioning.
においてSP2が同様の処理を行う.この処理を繰り返 すことにより,最終的に行列全体をLU分解できる.
上記の処理では,枢軸要素を担当するSPが枢軸列に ついて計算を行った段階で,別のSPへとデータの転 送を行う.
上記の処理では,入力行列をM×M,プロセッサ 数をPとした場合,全体の計算量はO(MP2)となり,
高速に演算することができる.
5.
評 価本章では,我々の提案する手法の評価について,評 価環境,動的ブロック分割方式を用いる際のブロック サイズ変更しきい値,動的ブロック分割方式による解 析精度への影響を評価し,速度向上率の評価結果を 示す.
5. 1 評 価 環 境
今回用いるCPUとGPUの評価環境を表1に示す.
CPUにはIntel Core i5 3.4GHzを用いる.GPUには Streaming Multiprocessor (SM)を14基,Streaming Processor (SP)を448基搭載しているTesla C2050 を用いる.CUDAのコンパイルオプションにある- use fast mathは,計算精度を若干落とす代わりに三 角関数や除算の計算速度を向上させるオプションであ る.またCPUを用いた並列実装の評価では,OpenMP を用いて4スレッドで実行する.
入力画像として,まず図 9 (a)に示す合成画像を 用いる.図 9 (a)は,図9 (b), (c), (d)の三つの周波 数帯域の画像によって構成されおり,BEEMD及び DBPBEEMDにより得られたIMFとの比較を行い評
表1 評 価 環 境 Table 1 Evaluation environment.
CPU GPU
Processor Core i5 750 Tesla C2050
Cores 4 448
Frequency 3.4GHz 1.15GHz
Cache 256KB (L2), 8MB (L3) 48KB (L1), 768KB (L2)
Dev Env. OpenMP CUDA SDK 4.0
Compiler gcc-4.1.2 nvcc
Compiler Option -O3 -fopenmp -use fast math
図9 合成画像(構成要素) Fig. 9 Compound image (components).
価する.
また自然画像にはLennaなど,幾つかの特徴的な 実画像を用い,ブロックを分割せずにBEMDによ りあらかじめ求めておいたIMFと,BEEMD及び DBPBEEMDにより得られたIMFとの比較により評 価する.
2次元アンサンブル経験的モード分解に関わるパラ メータとして,IMFの判定条件である標準偏差(SD) を0.05,アンサンブル数を30とする.動的ブロック 分割に関わるパラメータとして,分割ブロックの最小 サイズを64pixel,オーバラップ領域を16pixelとし,
以後オーバラップ領域を含めたブロック内極値数が一 定値以下になるごとに分割ブロックサイズ及びオーバ ラップ領域を2倍ずつ増加させるものとする.この増 加を行うきっかけとなるブロック内極値の数をブロッ クサイズ変更しきい値と定義する.またBEEMDに おけるノイズ加算画像はあらかじめ生成したものを用 いた.
5. 2 評 価 結 果
まず分割を行わない従来手法(BEMD)と,提案 手法である動的ブロック分割に基づいたBEEMDと DBPBEEMDによる解析結果の比較評価を行う.
図 10は256×256pixelの図 9 (a)の画像に対し て,BEEMDとDBPBEEMDを適用した場合の解析 結果である.図10 (a), (b)より,BEEMDとDBP- BEEMDの解析結果の間に目視で確認できるレベルの 差は見られない.
表2は,図9 (a)の各構成要素に対する解析結果と のPSNR (Peak Signal-to-Noise Ratio)を比較した ものである.PSNRは画像圧縮時の画質評価において
図10 合成画像の解析結果の比較(a) BEEMD (b) DBPBEEMD
Fig. 10 Comparison of analyzed results for Compound image (a) BEEMD (b) DBPBEEMD.
表2 合成画像に対するBEEMDとDBPBEEMDの解 析結果のPSNR
Table 2 PSNR of analysis of BEEMD and DBPBEEMD with compound images.
IMF1 IMF2 Residue Average BEEMD 34.915 27.977 31.416 31.436 DBPBEEMD 34.636 26.636 32.071 31.114
用いられる指標であり,以下の式によって求められる.
P SN R= 10 log10 2552
M SE
(7)
M SE= 1 N M
N i=1
M j=1
X(i, j)−X(i, j)2 (8)
これはM×Nサイズの画像に対するもので,X(i,j) は原画像の画素,X’(i,j)は何らかの変換を施した画素 を表す.
PSNRは値が高いほど二つの画像の差異が小さいこ とを表し,一般的にPSNRが35dB以上であると原 画像に忠実であるとされている.
表 2 よ り,DBPBEEMDで は IMF2に お け る PSNRが低いが,残余画像ではBEEMDに比べて PSNRが高くなっている.またPSNRの平均値も大 きく変わらないため,図9 (a)のような周波数特性が 単純な合成画像に対しては,動的ブロック分割が有効 に働いているものと考えられる.
次に画像Lennaに対する解析精度の評価を行う.
図11は,BEEMDとDBPBEEMDの対応するIMF 及び残余画像のPSNRを表している.縦軸はPSNR を示し,各項目はブロックサイズ変更しきい値が50,
図11 ブロックサイズ変更しきい値による解析精度の評 価(Lenna)
Fig. 11 Annalyzing accuracy by threshold in changing sizes of blocks (Lenna).
図12 LennaのBEEMDによる解析結果 Fig. 12 Analyzed results for Lenna with BEEMD.
100, 200, 400の場合のPSNRを示している.高周波 成分IMFであるIMF1, 2ではPSNRがブロックサ イズ変更しきい値によらず非常に高い結果となってい る.これはブロック内に十分な極値が含まれており,
分割サイズの変更が行われなかったためである.低周 波成分IMFであるIMF3〜5ではブロックサイズ変更 しきい値によってPSNRが変化しており,しきい値が 200, 400の場合に高いPSNRが得られているが,し きい値が50, 100の場合には全体的にPSNRの低下 が見られる.PSNRの平均値(Average)より,しきい 値が200, 400の場合に解析精度が高いことが分かる.
そのため,実行時間の点においても有利なブロックサ イズ変更しきい値200を,今後の評価のパラメータと して用いる.
図12及び図 13は,Lennaに対するBEEMD及
図13 LennaのDBPBEEMDによる解析結果 Fig. 13 Analyzed results for Lenna with DBPBEEMD.
図14 評価に用いる画像 Fig. 14 Images in evaluation.
びDBPBEEMDの解析結果を図示したものである.
図13は,ブロックサイズ変更しきい値を200とした 場合のDBPBEEMDによる解析結果である.図12 及び図13より,高周波成分で構成されるIMF1, 2で は解析結果にほとんど差が無く,低周波成分で構成さ れるIMF3, 4, 5では若干の濃淡の差はあるものの,輪 郭に大きな違いは見られない.またブロック分割境界 における誤差が発生しやすい低周波成分IMF4, 5及 び残余画像においても,ブロック分割境界におけるズ レは見られず,動的ブロック分割方式が有効に機能し ていることが確認できる.
次に複数の画像に対する解析精度の評価を行う.評 価に用いた画像を図14に示す.図14 (a)はCTスキャ ンによる画像,(b)はフローリングの木目テクスチャ,
(c)はヒヒの画像である.ブロックサイズ変更しきい値 を200とした場合のBEEMDとDBPBEEMDの解析 結果のPSNRを表したものを図15に示す.図14 (a) の解析結果のPSNRが非常に高いことが確認できる が,これは画像内の暗色領域が広いことに起因すると 考えられる.図14 (b)の解析結果のPSNRは高周波 成分で低く,低周波成分では逆に高くなっているが,
図15 解析精度の評価(CT, WOOD, BABOON) Fig. 15 Analyzing accuracy (CT, WOOD, BABOON).
表3 BEEMDに対するDBPBEEMDの速度向上率 Table 3 Speedup of DBPBEEMD against BEEMD.
128×128 256×256 512×512 DBPBEEMD CPU1core 1.036 3.932 20.364 DBPBEEMD CPU4core 3.279 10.819 67.222 DBPBEEMD GPU 17.438 71.587 422.726
これは画像の端付近においてオーバラップ領域の影響 が出ているものと考えられる.最後に図14 (c)の解析 結果のPSNRはCTの結果には及ばないものの,高 い数値となっている.これらより,提案手法は解析精 度の低下が非常に小さいことが確認できた.
次に提案手法による速度向上率の評価結果を示す.
表3は,入力画像としてLennaを用いた場合の速度 向上率の結果である.BEEMDをCPU上に逐次実装 した場合を1として速度向上率を計算している.評価 項目として,DBPBEEMDをCPU上に逐次実装し た場合と,OpenMPを用いて4スレッドで実行した 場合,及びDBPBEEMDをGPU上に実装した場合 の三つを評価した.
DBPBEEMDをCPUのシングルコアで実行した 結果からは,動的ブロック分割方式自体による速度向 上が得られている.DBPBEEMDのCPUシングル コア評価より,入力画像のサイズが小さい場合にはブ ロック分割による計算量の削減効果は小さいが,入力 画像のサイズが大きい(512×512pixel)場合には約20 倍と高い速度向上率を得ている.
したがって入力画像サイズが大きい場合には,ブ ロック分割により大幅に実行時間を短縮できることが 分かる.これはBEEMDのエンベロープ計算におけ るO(M3)の曲面補間処理や,その他の計算量の大き い処理が入力画像のサイズによって,計算コストが大 きく増加するためであり,動的ブロック分割により一 度に処理するブロックサイズを小さくすることで実行
表4 DBPBEEMDの実行時間(sec) Table 4 Execution time of DBPBEEMD.
128×128 256×256 512×512 DBPBEEMD CPU1core 483.5 2821.4 20914 DBPBEEMD CPU4core 152.79 1025.6 6335.6
DBPBEEMD GPU 28.73 155 1007.5
時間を大幅に短縮できた.CPUの4コア全てを用い てDBPBEEMDを処理した場合には,1コアで処理 する場合と比較して約2.8倍〜3.2倍の速度向上率を 得られた.このことから,マルチコアCPUにおいて も提案手法が有効であることが確認できた.
最後にDBPBEEMDをGPUを用いて処理した場 合には,CPUの4コアを用いた場合に比べて7倍前 後の速度向上率が得られた.そのため,入力画像が 512×512pixelの場合において,CPUの従来手法と 比較して400倍以上の大幅な速度向上となった.表4 は,入力画像にLennaを用いた場合の実行時間を示し ている.これより,GPUを用いてDBPBEEMDを 実行した場合には,512×512pixelに適用した場合で も,17分程度で解析を完了している.これは従来手法 による解析の場合に数日かかっていたことを考慮する と,実用的な時間で解析が可能であることを表し,本 提案手法の有効性を示している.
6.
む す び本論文では,2次元アンサンブル経験的モード分解 (BEEMD)を,GPUを用いて並列処理するために,
入力画像において,ある程度のオーバラップ領域を設 けて複数のブロックに分割することで,解析精度を維 持したまま並列処理できる手法を提案した.更に,処 理進行に伴いブロック分割サイズを動的に変更するこ とで,低周波成分解析時の解析精度維持,高速化を高 いレベルで両立でき,更に,ブロック内部の処理に並 列アルゴリズムを用いることで,GPUが搭載する多 数のプロセッサを有効に活用できる並列処理手法方式 を提案し,実現した.
評価の結果,提案手法のPSNRの全体平均は31.3dB であり,解析精度への影響を抑制していることが確認 できた.また実際にCPUにCore i5,GPUにTesla C2050を搭載した環境において提案手法を実装するこ とにより,CPUによる従来逐次手法と比較して,最 大422.7倍の速度向上率が得られた.動的ブロック分 割方式は入力画像が大きいほど高速化の効果が高く,
より大きな画像に対して適用した場合には更なる高速
化が期待できる.
本研究で提案した手法により,BEEMDを高速に実 行することが可能になるため,BEEMDの画像解析に おける応用が広がることが期待できる.今後の展望と して,小さな画像を解析する際においても高い速度向 上率を実現する並列化手法の提案や,極値数が激しく 変動するようなサイズが大きい画像に適用した場合に,
より適切にブロック分割を行う手法の考案などが考え られる.
小さな画像に対しては,GPUの並列性が発揮でき ず,逆に速度低下を招く恐れがあり,そういった場合 には,CPUのマルチスレッド処理とのハイブリッド 方式も有効となると考えられる.
また,今回エンベロープ計算において,数値解析ラ イブラリであるLAPACKを用いたため,全体の処理 を倍精度で計算したが,単精度で行う独自関数を開発 して組み込めば,誤差がそれほど問題とならない場合 には,更に速度向上が見込める.
謝辞 本研究の一部は,文部科学省特別経費「持続 可能社会にむけた知的情報空間技術の創出」及びJSPS 科研費 基盤研究(C) 25330067による支援を得た.こ こに記して感謝する.
文 献
[1] N.E. Huang, Z. Shen, S.R. Long, M.C. Wu, H.H.
Shih, Q. Zheng, N. Yen, C. Tung, and H.H. Liu,
“The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis,” Proc. of the Royal Society of London, Se- ries A: Mathematical, Physical and Engineering Sci- ences, vol.454, no.1971, pp.903–995, 1998.
[2] J.C. Nunes, Y. Bouaoune, E. Delechelle, O. Niang, and Ph. Bunel, “Image analysis by bidimensional em- pirical mode decomposition,” Image and Vision Com- puting, vol.21, no.12, pp.1019–1026, 2003.
[3] Z. Wu and N.E. Huang, “Ensemble empirical mode decomposition: A noise-assisted data analy- sis method,” Advances in Adaptive Data Analysis, vol.01, no.01, pp.1–41, 2009.
[4] G.L. Xu, X.T. Wang, and X.G. Xu, “Improved bi- dimensional empirical mode decomposition based on 2D-assisted signals: Analysis and application, image processing,” IET, vol.5, no.3, pp.205–221, 2011.
[5] A. Sabri, M. Karoud, H. Tairi, and A. Aarab, “Fast bidimensional empirical mode decomposition based on an adaptive block partitioning,” International Journal of Computer Science and Network Security, vol.8 no.11, pp.357–363, 2008.
[6] J.C. Nunes and E. Delechelle, “Empirical mode decomposition: Applications on signal and image
processing,” Advances in Adaptive Data Analysis, vol.01, no.01, pp.125–175, 2009.
[7] J.C. Carr, W.R. Fright, and R.K. Beatson, “Surface interpolation with radial basis functions for medical imaging,” IEEE Trans. Med. Imaging, vol.16, no.1, pp.96–107, 1997.
[8] S.M.A. Bhuiyan, N.O. Attoh-Okine, K.E. Barner, A.Y. Ayenu-Prah, and R.R. Adhami, “Bidimensional empirical mode decomposition using various interpo- lation techniques,” Advances in Adaptive Data Anal- ysis, vol.01, no.02, pp.309–338, 2009.
[9] J.C. Nunes, S. Guyot, and E. Delechelle, “Texture analysis based on local analysis of the bidimensional empirical mode decomposition,” Machine Vision and Applications, vol.16, pp.177–188, 2005.
[10] Lapack – Linear Algebra Package, http://www.netlib.
org/lapack/
[11] http://http.developer.nvidia.com/GPUGems3/
gpugems3 ch39.html
(平成25年6月3日受付,10月7日再受付)
堀部 拓也
2011東京農工大・工・情報工卒.2013 同大大学院工学研究科情報工学専攻修了 2013 (株)日本電気勤務.
清水 郁子 (正員)
1994東大・工・計数卒.1999同大大学院 工学系研究科計数工学専攻博士課程了.博 士(工学).同年埼玉大学工学部助手,2004 東京農工大学大学院講師,現在に至る.コ ンピュータビジョンの研究に従事.計測自 動制御学会,IEEE-CS等会員.
中條 拓伯 (正員)
1985神戸大・工・電気工卒.1987同 大大学院工学研究科電子工学専攻修了.
1989同大学工学部助手の後,1998より 1年間Illinois大学Urbana-Champaign 校Center for Supercomputing Research and Development(CSRD)にてVisit- ing Research Assistant Professorを経て,1999より東京農 工大学大学院准教授.プロセッサアーキテクチャ,並列処理に 関する研究に従事.電子情報通信学会,IEEE-CS,ACM各会 員.博士(工学).