TSUBAME2.0上でのHadoopの性能評価
8
0
0
全文
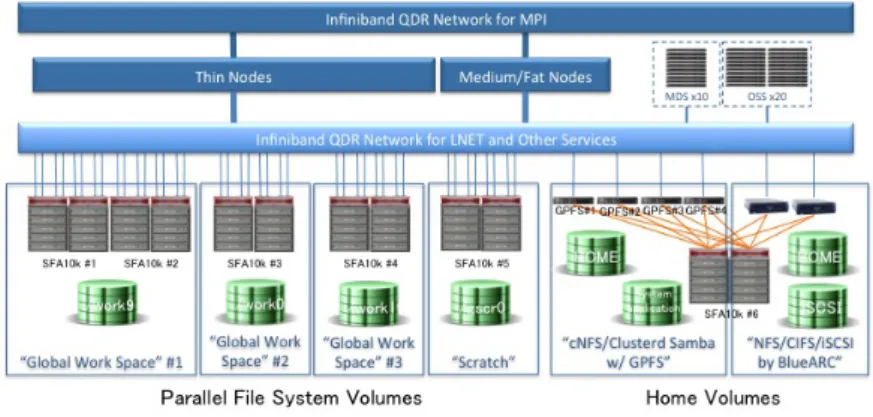
(2) Vol.2011-HPC-129 No.16 2011/3/16. 情報処理学会研究報告 IPSJ SIG Technical Report. 主に Lustre 並列ファイルシステムを利用していたのに対し,TSUBAME2.0 ではロー. 2.1 HDFS. カルストレージとして SSD 利用可能であり,また,並列ファイルシステムも Lustre. HDFS は,コモディティなハードウェアで構成されたクラスタ計算機上で大規模データ. ?1. と GPFS が利用できる.従って,Lustre などの並列ファイルシステムだけでなく,. を扱うことに特化した並列共有分散ファイルシステムである.典型的なマスタ・ワーカの構. Hadoop に付属するローカルストレージを活用した分散ファイルシステムである HDFS. 成をしており,NameNode と呼ばれるマスタがファイルシステムのディレクトリツリーや. など,複数の並列ファイルシステムが利用可能になる.. ファイルのメタデータなどファイルシステムの名前空間に関する情報を管理し,DataNode. また,TSUBAME2.0 は,GPU だけでなく CPU の演算性能,計算ノードのメモリバンド. と呼ばれる複数のワーカが実際のファイルのデータを管理する.ファイルは 1 つ以上の一定. 幅,ストレージ性能,計算ノード間及びストレージへのネットワークバンド幅の点において. のサイズ (デフォルトでは 64MB) の断片に分割され,各計算ノードのローカルストレージ. 大幅な性能向上が図られ,大規模データ処理に適した環境である一方で,利用ユーザの多い. へ分散されて格納されるが,実際には統合した一つのイメージとしてみえる.また,データ. Hadoop ベースの MapReduce アプリケーションの性能特性などは明らかではない.. の耐故障性を実現するために,ファイル断片は異なる DataNode へ一定数複製される.. そこで,我々は,これらの相違点を解消するための改良を加えることで Tsudoop を TSUB-. 3. TSUBAME2.0. AME2.0 に対応させ,このツールを用いて MapReduce アプリケーションを実行して基本 的な性能を調査した.改良版 Tsudoop では,TSUBAME2.0 上のジョブスケジューラで ある PBS Pro や,Lustre などの並列ファイルシステム, ノード上の複数の SSD からなる. 東工大 GSIC では,2010 年 11 月からスーパーコンピュータ「TSUBAME2.0」の運用を. ローカルストレージなどの既存のシステムと協調動作して,オンデマンドで TSUBAME2.0. 開始した.2010 年 11 月の地点では,ピーク性能 2.4PFlops,Linpack 性能 1.192PFlops,. に Hadoop 環境を構築し,ユーザーの MapReduce アプリケーションを実行する.TSUB-. 80TB を超えるメモリ容量,190TB の SSD,7.1PB のストレージ領域,フルバイセクショ. AME2.0 上の 24 ノード,264 コアで Hadoop 付属の RandomWriter, Sort アプリケーショ. ン構成な QDR InfiniBand ネットワークと,データインテンシブアプリケーションを実行. ンを実行したところ,HDFS では 1 ノードでの実行と比較して高々1.1 倍の実行の増加に留. するのに適した大規模計算システムである.ここでは,まず,Hadoop を TSUBAME2.0 上. まり良好な weak scaling 性能を示すのに対して,Lustre においては 1.6∼1.8 倍の実行時間. で実行する上で関連する部分についての概要を述べる.. の増加を示した.. 3.1 構. 成. TSUBAME2.0 は,1442 台の計算ノードが合計 7.1PB のストレージと QDR InfiniBand. 2. Hadoop. で接続された構成になっている.TSUBAME2.0 上でのジョブの実行は,PBS Pro により. Hadoop8) は,Apache Software Foundation にてオープンソースで開発が進められてい. バッチジョブスケジューラを介して行う.図 1 に TSUBAME2.0 全体の構成図を示す. 以. る,並列分散環境で MapReduce による大規模データ処理を行うためのソフトウェアコレク. 下では,各構成要素の概要について述べる.. ションである.Hadoop での MapReduce 処理は,分散ファイルシステムである HDFS 上で. 計算ノード. Hadoop MapReduce という MapReduce 処理システムが動作することで行われる.Google. TSUBAME2.0 の計算ノードは,1408 台の Thin ノード,24 台の Medium ノード, 10 台. の MapReduce システムにインスパイアされているため類似した部分1),7) が多く含まれる. の Fat ノードから構成される.本稿の実験では,Thin ノードをメインに使用するので,ここ. が,ここでは構成要素の中心である HDFS と Hadoop MapReduse の概要について述べる.. ではその詳細について説明する.各 Thin ノードは HP Proliant SL390s G7 からなり,6 コ. 詳細については,Hadoop のホームページ8) を参照されたい.. アの Intel Xeon X5670 2.93GHz プロセッサを 2 つ,NVIDIA Tesla M2050 GPU を 3 つ搭 載する.メインメモリとしては計 54GB(一部 96GB) の DDR3 メモリを搭載し,60GB(一 部 120GB) の SLC SSD2 台により RAID0(ソフトウェア RAID) でローカルストレージ が構成されている.また,40Gbps の QDR InfiniBand の host channel adapter(HCA) を. ?1 2011 年 4 月運用開始予定. 2. c 2011 Information Processing Society of Japan.
(3) Vol.2011-HPC-129 No.16 2011/3/16. 情報処理学会研究報告 IPSJ SIG Technical Report. 図2. TSUBAME2.0 のストレージ構成. (サーバ) に接続された Object Storage Target(OST) が実際のファイルのデータを格納す る.work0 では,MDS は 2 台,OSS は 4 台で冗長構成され,SFA 10k 上の HDD が OST を担う.SFA 10k は,計 600 台の HDD(600GB の SAS 10 台,2TB の SATA 590 台) を 図 1 TSUBAME2.0 の構成図. 搭載し,10 台の SAS ディスクにより RAID6 で MDT を構成し,560 台の SATA ディス クにより OST を構成する.1 台の OST は 10 台の SATA ディスクを RAID6 にして構成. 2 つ持ち,各計算ノード,ストレージへ接続されている.OS は 64bit 対応 SuSE Linux. され,1 台の SFA 10k あたり 56 の OST が存在する.ファイルは 1 つ以上の一定サイズの. Enterprise Server 11 および Windows HPC server 2008 R2 が動作する.. 断片に分割され,OST 上に分散されて格納されが,デフォルトの設定では,ストライピン. 3.2 ストレージ. グされずに,1MB 単位で格納される.各 MDS, OSS, SFA 10k 間は,図 3 のように QDR. 図 2 に TSUBAME2.0 のストレージ構成を示す.TSUBAME2.0 のストレージの主要部. InfiniBand に接続されている. 3.3 ネットワーク. 分は,5.1PB のホーム領域と 1.2PB の並列ファイルシステム領域の計 7.1PB のストレー ジ領域から構成される. ここでは,本稿の実験で関連する並列ファイルシステム領域につ. 各計算ノードとストレージの間は QDR Infiniband ベースのインターコネクトにより接. いて説明する.並列ファイルシステム領域は,5 台の DDN SFA10k ストレージシステム. 続される.このインターコネクトは,2 段のスイッチからなるファットツリー・フルバイセ. を中心に構成され,使用用途に応じて分割して運用されている.本稿の実験ではそのうち. クション構成で, Dual rail により,各 rail がファットツリーを構成する.エッジスイッ チと. の 1 つの領域である work0 を利用している.図 3 にその構成を示す. work0 上では,並. して 36 ポートの Voltaire GridDirector 4036 を 185 台持ち,各エッジスイッチのポート. 列ファイルシステムとして Lustre(version 1.8.5) が動作している.Lustre は典型的なマス. のうち 18 は上 流のコアスイッチに接続され,残り 18 は下流のノードに接続される.コア. タ・ワーカの構成をした並列ファイルシステムで,Meta Data Server(MDS) と呼ばれるマ. スイッチは 324 ポートの GridDirector 4700 で,各 rail につき 6 台,計 12 台存在する.. スタがファイルシステムのディレクトリツリーやファイルのメタデータなどファイルシス. 各ノードは 2 本の 40Gbps QDR InfiniBand により エッジスイッチに接続され,2 本は. テムの名前空間に関する情報を管理し (実際には Meta Data Target (MDT) と呼ばれるス. Dual rail のそ れぞれに接続される.各ストレージは,5 台の Voltaire GridDirector 4036. トレージ上にメタデータが格納される),Object Storage Server(OSS) と呼ばれるワーカ. からなるエッジスイッチに接続され,これらのエッジスイッチは Dual rail の片方の各コア. 3. c 2011 Information Processing Society of Japan.
(4) Vol.2011-HPC-129 No.16 2011/3/16. 情報処理学会研究報告 IPSJ SIG Technical Report. きない.. • Hadoop MapReduce では JobTracker が MapReduce ジョブのスケジューリングを行う のに対し,TSUBAME1 ではスパコン全体のジョブスケジューリングを司るスケジュー ラ (n1ge) が存在する.. • HDFS の NameNode, DataNode,及び, Hadoop MapReduce の JobTracker, TaskTracker は ssh を介してデーモン化され起動するが,TSUBAME1 ではゾンビジョブが 残る可能性があることから計算ノードへの ssh は推奨されていなかった. 一方,TSUBAME2.0 では構成や運用面において次のような変更がされた.. • 各計算ノードに SSD が導入されローカルストレージとして使用可能になり,HDFS を 構成することができるようになった.. • スケジューラが PBS Pro になり,スパコンへのジョブ投入方法が変更された. • 占有して使用できるノードに対しては,ssh を許可するようにした. このため,これまでの Tsudoop の実装の基本的なアイデアは変更せず,TSUBAME2.0 の 仕様,構成変更に合わせて対応した.また,TSUBAME2.0 では,上述のような技術的課題 だけでなく,新たに以下のような問題も挙げられる. 図3. work0(Lustre) の構成. • HDFS,Lustre など複数のファイルシステムが利用可能になったが,MapReduce アプ リケーションのワークロードに応じたファイルシステムの選択の基準が不明である.. • ユーザの課金や資源のプロビジョニングの観点からなるべく少ないノード占有により. スイッチと 2 本の QDR InfiniBand によりファットツリーで接続される.. 3.4 バッチジョブスケジューリングシステム. MapReduce アプリケーションを実行することが望ましいが,資源選択の基準が不明で. TSUBAME2.0 では,一部,インタラクティブによるジョブの実行も可能であるが,他の. ある.. ジョブの影響を受けることなく,計算資源を大規模に効率良く利用するために,バッチジョ. 1 点目に関しては,Lustre ではレイテンシが小さくコンカレントな並列 I/O を対象とし. ブスケジューラ (PBS Pro) を介したジョブの実行が推奨されている.通常の PBS Pro の. ているのに対し,HDFS では read スループット重視の I/O を対象にしており,ファイル. 大きく仕様は異なっていないものの,ジョブの投入,状況確認,削除などのコマンドが,そ. システムに応じた使い分けが必要になるが,その選択の基準が明らかではない.さらに,. れぞれ,t2sub(qsub),t2stat(qstat),t2del(qdel) のように変更されている. TSUBAME2.0 では,Lustre では全ての計算ノードから共有されているため直接計算ノー ドからアクセスできるのに対し,HDFS は Tsudoop によりオンデマンドにユーザが確保. 4. TSUBAME2.0 への Hadoop の適用 4.1 課. した計算ノードのローカルストレージを集約して構築するので構築した HDFS に対してス. 題. テージングが必要になるなど,両ストレージの利用には,性能,利便性の点でのトレードオ. 我々は,これまで,TSUBAME1 上で Hadoop 環境をオンデマンドに構築するツール. フの関係がある.2 点目に関しては,ユーザの立場では占有するノード数が増加するにつれ. 「Tsudoop」の研究開発を通じて,TSUBAME1 上に Hadoop を適用する際の問題点を指摘. 課金が増え,運用の立場ではユーザが占有するノード数が増加するにつれ他のユーザに対し. 6). してきた .具体的には以下のとおりである.. て割り当てられる資源が減少し利用率が下がるため,可能であれば空間的にも時間的にもな. • 計算ノード上のローカルストレージを使用できないため,HDFS を構成することがで. るべく少ないノード占有になるような MapReduce アプリケーションの実行が望ましいが,. 4. c 2011 Information Processing Society of Japan.
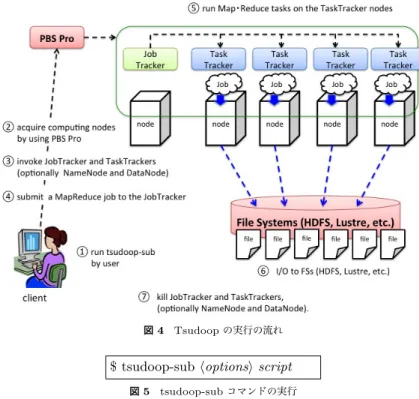
(5) Vol.2011-HPC-129 No.16 2011/3/16. 情報処理学会研究報告 IPSJ SIG Technical Report. #!/bin/bash . $TSUDOOP HOME/conf/tsudoop.sh hadoop. jar. hadoop-mapred-examples-*.jar 図6. sort. input. output. シェルスクリプトファイル (script) の内容の例. アプリケーションの実行,Hadoop 環境の破棄などを行う.具体的には,PBS Pro に対し て t2sub を行うことでノード (複数) を確保すると,確保したノードの 1 つで上述の script が実行され,Hadoop 環境の構築が開始される.PBS NODELIST 環境変数にこのとき確 保されたノードが記述されているファイルへの path が代入されるので,このノードのリス トから JobTracker, NameNode となるノード,TaskTracker, DataNode となるノードを選 択する.その後,start-mapred.sh,start-dfs.sh を呼び出すことで Hadoop MapReduce や. HDFS を起動し,その後,ユーザの記述したコードを実行し,終了シグナルを受け取った後, 図4. stop-mapred.sh, stop-dfs により Hadoop MapReduce や HDFS を終了する.start-*.sh,. Tsudoop の実行の流れ. stop-*.sh の内部では,ssh により他のノードへのプログラムの起動を行っている.Lustre を利用する場合は,HDFS の起動は行わず,直接ファイルシステムへ I/O を行う,. $ tsudoop-sub hoptionsi script 図 5 tsudoop-sub コマンドの実行. 5. 実. 験. 資源選択の基準が不明である.特に,TSUBAME2.0 では CPU 演算資源が少ないため問題. 5.1 概. 要. となる.. Hadoop に付属している RandomWriter, Sort アプリケーション用いて TSUBAME2.0. 4.2 TSUBAME2.0 での Hadoop の実行. 上で weak scaling を検証する実験を行った.まず,RandomWriter により TaskTracker が. 図 4 に TSUBAME2.0 版の Tsudoop の全体の実行の流れを記す. Tsudoop は図 5 のよ. 動作するワーカノード 1 台あたり 10GB のデータを生成した後,Sort により生成データに対. うにコマンドラインから tsudoop-sub コマンドに script を与えることで実行する.script に. するソートを行った.このとき,RandomWriter では map タスクの実行のみが行われるが,. は,Hadoop に対して実行したいコマンドを記述する. この tsudoop-sub は,TSUBAME2.0. Sort では reduce タスクによるノード間のデータ転送が発生する.実験には TSUBAME2.0. で動作する PBS Pro の qsub コマンド (t2sub) へのラッパーである.現在の実装では,オプ. の S96 キューの計算ノードを使用した.実験環境やこの計算ノード 1 台の詳細については. ションとして,投入するキュー (-q),ユーザが属するグループ (-g), 使用するファイルシステ. 3 節に記述されているが,注意点として,S96 キュー上の計算ノードは通常の Thin ノード. ム (-f) などが設定できる.例えば,Hadoop に付属する Sort プログラムを実行したい場合. よりも多くのメモリ容量 (96GB),SSD 容量 (240B) を搭載する.また,この計算ノード上. は図 6 のように記述する. このシェルスクリプトのファイルの上部で,tsudoop.sh が読み. では,Hyper-Threading が動作している.ワーカノード (TaskTracker, DataNode が動作. 込まれている.この tsudoop.sh が,実際には,Hadoop 環境の構築,ユーザの MapReduce. するノード) の数は 1 ∼24 ノードとし,マスタノード 1 ノード (JobTracker, NameNode). 5. c 2011 Information Processing Society of Japan.
(6) Vol.2011-HPC-129 No.16 2011/3/16. 情報処理学会研究報告 IPSJ SIG Technical Report. は別途用意した.ワーカノードで 1 台で実行する map タスク (m),reduce タスク (r) は,. m : r = 8 : 3, 16 : 6 の 2 種類とし,ストレージも HDFS(hdfs), Lustre(lfs) の 2 種類とした.. 8:3-lfs 16:6-lfs 8:3-hdfs 16:6-hdfs. 100. m : r = 8 : 3 の場合では 1 ノード 12 コア中の全てのコアを使用せずそのうちの 11 コアを使 用するのに対し,m : r = 16 : 6 は Hyper Threading でみえるコアの数より若干多くのタス 80. クを実行する.一方,アプリケーション側の map タスク数,reduce タスク数の設定は,そ Elapsed time [sec]. れぞれ,16 × n, 6 × n とした.ここで,n はワーカノード数とする.各ストレージの設定と しては,Luster についてはストライプサイズを 16MB とし,ストライピングしない構成と した.HDFS についてはブロックサイズを 256MB とした.各 I/O 性能は,Thin ノード上 で,256MB のファイルを 16MB のバッファで read, write したときの性能は,SSD で read. 3206MB/s,write 823MB/s,Lustre で read 3020MB/s,281MB/s であった. ?1. 60. 40. .Hadoop. についてはバージョンは 0.21.0 を使用し,デフォルトの圧縮 (zlib) を使用して Map 出力の圧. 20. 縮をする設定とした.また,map タスクあたり 2048MB,reduce タスクあたり 4098MB(以 上) の Java Heap Size を割り当て,map 出力のバッファ(mapreduce.task.io.sort.mb) を 0. 1024MB とした.. 0. 5. 10. 15. 20. 25. # of nodes. 5.2 実 験 結 果. 図7. RandomWriter の実行時間. まず,図 7 に Random Writer の結果を示す. x 軸は Tsudoop により構築した Hadoop 環境のワーカノード (TaskTracker が動作するノード) の台数を表し,y 軸は MapReduce. た点などが要因として挙げられる.また,Lustre の領域はすべての TSUBAME2.0 の計算. ジョブが実行しはじめてから終了するまでの経過時間 (実行時間) を表す.図中,8 : 3-hdfs,. ノードから共有されているため他のユーザのプロセスからの I/O の影響を受けた可能性が. 8 : 3-lfs, 16 : 6-hdfs, 16 : 6-lfs などの凡例はそれぞれ,1 ノードあたりに MapReduce ジョ. 考えられるが,確認はできていない.後者の現象については,Lustre の OSS,OST の数を. ブが使用する map 数,reduce 数,及び,ファイルシステムを表す.図より 8 ノードまでは. 増やすことにより解消されると考えられる.一方,HDFS ではノード数を 16,24 ノードの. HDFS も Lustre も良好な weak scaling 性能を示すものの,Lustre ではノード数が 16,24. ときにおいても良好な weak scaling 性能を示す.例えば,8:3-hdfs, 16:6-lfs の場合におい. ノードになったあたりでオーバーヘッドがみられる.具体的には,8:3-hdfs, 8:3-lfs では,8. ても高々1.1 倍の実行時間の増加に留まった.これは,HDFS の場合は map タスクが実行. ノードにおいては 1 ノードの場合と比較してそれぞれ 1.20 倍, 1.08 倍の実行時間の増加に. されているノード上のローカルストレージへ write を行うため,I/O の並列度を上げても. 留まるのに対し,24 ノードにおいては 8:3-hdfs では 1.18 倍の実行時間の増加であるのに対. SSD レベルでの競合が発生が少ないためである.また,Tsudoop ではオンデマンドに計算. し,8:3-lfs では 1.82 倍の実行時間の増加を示した.これは,RandomWriter の map フェー. ノードのローカルストレージを束ねて HDFS として構築するので,他のユーザからの I/O. ズにおいて多数の map タスクによる write I/O(例えば,24 ノードのときは 384 map タス. の干渉も発生しない.. クにより 240GB の write I/O が行われる) が集中して発生したため MDS でのメタデータ. 次に, 図 8 に Sort の結果を示す. x 軸はワーカノードの台数を表し,y 軸は MapReduce. アクセスの応答性能の低下を引き起こした点や,実験に使用した Lustre の OST が 56 台. ジョブの経過時間 (実行時間) を表す.また,図中の凡例は,MapReduce ジョブの使用する. で構成されているため複数の map タスクの同時アクセスによりスループット性能が飽和し. map 数,reduce 数,及び,ファイルシステムを表す.Sort の場合においても,ノード数の 増加に対して HDFS では良好なスケーラビリティを示すのに対し Lustre では大幅な性能低 下を示し,RandomWriter のときにみられた傾向がさらに顕著に現れた.例えば,24 ノー. ?1 キャッシュの効果を含む. 6. c 2011 Information Processing Society of Japan.
(7) Vol.2011-HPC-129 No.16 2011/3/16. 情報処理学会研究報告 IPSJ SIG Technical Report. ノード間データ転送量も増加により 1 タスクあたりに扱うデータ量が増加するため,weak. 1600 8:3-lfs 16:6-lfs 8:3-hdfs 16:6-hdfs. 1400. scaling 性能が低下し,ボトルネックが顕在化することを示している.. 6. お わ り に 1200. Elapsed time [sec]. TSUBAME2.0 上のジョブスケジューラである PBS Pro や,Lustre などの並列ファイル 1000. システム, ノード上の複数の SSD からなるローカルストレージなどの既存のシステムと協調 動作して,オンデマンドで TSUBAME2.0 に Hadoop 環境を構築し,ユーザーの MapRe-. 800. duce アプリケーションを実行するツール「Tsudoop」による Hadoop の TSUBAME2.0 への適用事例を示した. また,このツールを用いて,TSUBAME2.0 上で Hadoop 付属の. 600. RandomWriter, Sort による MapReduce アプリケーションを実行し,weak scaling 性能. 400. を調査した結果,HDFS では 24 ノード, 264 コアの実行では 1 ノードでの実行と比較して 高々1.1 倍の実行の増加に留まり良好な weak scaling 性能を示すのに対して,Lustre にお. 200. いては 1.6∼1.8 倍の実行時間の増加を示した. 0 0. 5. 10. 15. 20. 今後の課題としては,Tsudoop の TSUBAME2.0 上での公開をはじめとして,MapRe-. 25. # of nodes. 図8. duce ジョブの I/O 性能の詳細な解析やメモリ使用量の挙動の解析,MapReduce ジョブ実. Sort の実行時間. 行環境の資源選択手法の開発,大規模なデータを用いた実アプリケーションへの適用などが ドの場合において,8:3-hdfs では実行時間が 1 ノードの場合と比較して 0.95 倍の実行時間. 挙げられる.. となり若干の性能向上がみられるのに対し,8:3-lfs では 1.6 倍近い実行時間の増加がみられ. 謝辞 本研究の一部は科学研究費補助金特定領域研究 (18049028) の補助による.. た.これは,Sort の場合では map,reduce フェーズでのファイルシステムへの I/O だけで. 参. なく,Shuffle フェーズにおいて計算ノード間のデータ転送が発生するためである.HDFS. 考. 文. 献. 1) Dean,J. and Ghemawat,S.: MapReduce: simplified data processing on large clusters, Communications of the ACM, Vol.51, No.1, pp. 107 – 113 (2008). 2) Scaling Hadoop to 4000 nodes at Yahoo!, http://developer.yahoo.net/blogs/ hadoop/2008/09/scaling hadoop to 4000 nodes a.html (2008). 3) Chu,C.-T., Kim,S.K., Lin,Y.-A., Yu,Y.Y., Bradski,G., Ng,A.Y. and Olukotun,K.: Map-Reduce for Machine Learning on Multicore, in Advances in Neural Information Processing System 19, pp. 281 – 288 (2006). 4) Mahout, http://mahout.apache.org. 5) PEGASUS Peta-Scale Graph Mining System, http://www.cs.cmu.edu/∼pegasus. 6) 佐藤仁, 小西史一, 山本泰智, 高木利久, 松岡聡:スーパーコンピュータ TSUBAME 上での MapReduce の実現, 情報処理学会研究報告 2009-HPC-123 (HOKKE-17), pp. 1–7 (2009). 7) Hadoop, http://hadoop.apache.org.. の場合はローカルストレージに対して I/O が行われ,ネットワークは計算ノード間のデー タ転送のみに利用されるのに対して,Lustre の場合は,RandomWriter のときにみられた. I/O 競合に加えて,ネットワークが I/O だけでなく計算ノード間のデータ転送にも利用さ れるのでネットワーク競合が発生しためである.また,1 ノードあたりの map, reduce の タスクを増加させた場合 (m : r = 8 : 3, 16 : 6 の比較),ワーカがが 1∼4 ノードと少ない 場合は,HDFS,Lustre の場合ともに良好な結果を示した.一方で,ノード数を増加させ るにつれ,HDFS では Map 及び Reduce タスクの Out of Memorry エラーが多くなりジョ ブの実行が継続できなくなり,Lustre においてはジョブの継続はされるものの線形に大幅 な実行時間の増加を示した.これは,1 ノードあたりに実行可能な map・reduce のタスク 数を増やすと,I/O 律速にならないタスクでは処理の高速化が見込める反面,I/O の多い タスクである場合は 1 タスクあたりに利用可能なメモリ容量が不足や Shuffle フェーズでの. 7. c 2011 Information Processing Society of Japan.
(8) Vol.2011-HPC-129 No.16 2011/3/16. 情報処理学会研究報告 IPSJ SIG Technical Report. 8) Ghemawat,S., Gobioff,H. and Leung,S.-T.: The Google File System, in Proceedings of the 19th ACM Symposium on Operating Systems Principles, pp. 96–108, Bolton Landing, NewYork (2003).. 8. c 2011 Information Processing Society of Japan.
(9)
図

関連したドキュメント
(ページ 3)3 ページ目をご覧ください。これまでの委員会における河川環境への影響予測、評
事前調査を行う者の要件の新設 ■
船舶の航行に伴う生物の越境移動による海洋環境への影響を抑制するための国際的規則に関して
環境影響評価の項目及び調査等の手法を選定するに当たっては、条例第 47
環境への影響を最小にし、持続可能な発展に貢
第2章 環境影響評価の実施手順等 第1
本稿で取り上げる関西社会経済研究所の自治 体評価では、 以上のような観点を踏まえて評価 を試みている。 関西社会経済研究所は、 年
事象発生から 7 時間後の崩壊熱,ポロシティ及び格納容器圧力への依存性を考慮し た上面熱流束を用いた評価を行う。上面熱流束は,図 4-4 の
