学習済仮想環境行動の人の指示による実環境適応の考察
A consideration of virtual learned action fitting in real world using person navigation
笠置みちこ, 大城英裕,行天啓二
Michiko Kasagi, Hidehiro Ohki and Gyohten Keiji 大分大学工学部{v14e3005,ohki,gyohten}@oita-u.ac.jp
Abstract:Reinforcement learning is well known with respect to acquisition of action for autonomous robot control. However, it is required much trial for its convergence. In our research, we have proposed the method of reinforcement learning addition of semi-supervised learning. The method yielded that autonomous robot learning in real environment quickly corresponds to environmental changes to goal achievement. The effecitiveness was shown in the results in the simulation. In this paper, we verify the learned action in the simulation to the real environment.
Keywords: 強化学習, 半教師あり学習, Fuzzy Sarsa(λ),状態行動空間
1
はじめに
今日,人間が活動できない場における自律ロボットの 活躍が期待される.そこでは素早く環境の変化に対応 し,目標を達成することが求められる.自律ロボット制 御の行動知識の獲得には強化学習が用いられるが,収束 のために多大な試行が必要となることが課題である. 解決策として,学習方式の改善という方法が多くみ られ,シミュレーションによる成果が報告されている. しかし,実際のロボットではシミュレーションの結果が 正しく動作しない場合がある. 先行研究[1]ではそこに着目し,実環境における自律 ロボットの効率良い目標達成のために,通常の強化学習 機構に半教師あり学習を付加することを提案した.こ の手法は強化学習を行っているロボットに,必要に応じ て目標達成のための人が教示を行う.未知環境(動的環 境)における自律学習を行い,従来よりも収束速度およ び獲得知識の精度向上が期待できる. 先行研究ではシミュレーションにおいて学習の収束 状態が実現できたが,実環境では収束状態を得られな かった.そこで,本研究では自律学習と人の教示による 学習によって,仮想環境で得た行動知識が実環境に適応 していくのかを検証した. 実環境は,絶えず変化している.特に照明や太陽光に よるセンサへの影響や,ロボットが持つモータの個体差 等はロボットの動作に大きな影響を与える.本研究で は仮想環境に実環境を完全再現するのは難しいと仮定 し,仮想環境と実環境間の誤差も,提案手法による再学 習によって改善されると考えた. 実験では,仮想環境でのシミュレーション実験によっ て獲得した行動知識をもとに,実際の環境において提案 手法による再学習でロボットの学習が収束し,Goalま での行動数がどれほど減少するかを確認した. 結果として,仮想環境のシミュレーションで得たロ ボットの挙動が,実環境での教示によるロボットの挙動 に有用であるデータを得ることができなかった.2
関連研究
半教師ありの強化学習に関連する研究について以下 に述べる. 2.1 教師あり学習(Supervised Learning) 教師あり学習には,パターン認識やニューラルネット ワークなどがある.これらはある入力に対し正しい出 力を与える教師が必ず存在しているため,強化学習より も速く確実な収束を得られる. しかし,学習によって得た知識はその教師データに依 存したものになってしまう.また,特にロボットの動作 学習においては,全ての入力に対する教師データを作る のが難しいという課題がある. 2.2 教師なし学習 教師なし学習では,教師の代わりに環境などから得ら れる報酬にしたがって学習を行う.未知環境において 試行錯誤的に総報酬値が高くなるような行動を学習し ていくという特徴から,ロボットの行動学習に向いて いる. 2.2.1 強化学習(Reinforcement Learning) 強化学習は,教師なし学習であり,ロボットの自律学 習のために一般的に使われる手法である. 人工知能学会研究会資料 SIG-ALST-B502-06 − 27 −!"#$ %&'( )'( *+,-.*/0 123456 789 :; !"#$ 123456 <=>? @ABC 図1 方式の概要 ロボット自身が現在置かれている状況を観測し,行動 選択を行う際,環境から報酬が得られ,状態と行動を学 習する.これを繰り返し試行し,報酬が最大となる最適 方策を獲得する. 学習収束のために多大な試行が必要であることが課 題であり,特にタスクが複雑であるほど試行数は膨大に なる[2].これは実環境において,ロボットがスムーズ に動作できない一因となっている. これを解決するための従来アプローチとして,より 高速な学習方式の開発があり,よく知られるものには Q(λ)やSarsa(λ)がある.また,Sarsa(λ)に状態空間 の連続性を考慮したFuzzy Sarsa(λ)[3]もある. 2.3 半教師あり学習(Semi-Supervised Learning) 半教師あり学習とは,強化学習中のロボットに必要 に応じて人の教示を与えるようにしている.そのため, 必要箇所では教師による正しい出力を学習でき,教師 データが全くない場合よりも速く確実な収束を得られ る.また,強化学習も行っていることで未知環境に対応 が可能となる.したがって未知環境での学習知識の精 度向上とそれに伴う収束速度の向上につながる.
3
提案手法
仮想環境において高速に学習することができても,実 環境では学習に時間がかかることが多い.実環境での より高速な学習の実現のため,先行研究[1]では,通常 の強化学習機構に半教師あり学習を付加することを提 案した.この手法では,強化学習中のロボットに,教師 データを与えることで学習の効率化を狙っている.本 研究では,仮想環境でのシミュレーション実験によって 獲得した行動知識をもとに,実際の環境において強化学 習を行い,必要に応じて人の教示が行えるようにした. 状態空間の連続性と定性的な人の教示を考慮して,学習 方式はFuzzy Sarsa(λ)を用いる.図3に提案手法の概 要を示す. 点線:ゴールに向かう動作 直線:ゴールから遠ざかる動作 図2 ゴールから遠ざかる動作 3.1 教師信号の与え方 次に,人の教示の与え方について述べる.図2の実 線のようにロボットは,Goalから明らかに遠ざかって いく動きを行うことがある.そのような場合に,Goal の方角を向くようなアクセル値とステアリング値を教 示として与える.これによって,目標達成までの時間の 短縮,かつ精度の高い知識の獲得により,学習収束の向 上,ひいては,実環境での自律ロボットの動作の柔軟さ につながると考えている. 3.2 Fuzzy Sarsa(λ) Fuzzy Sarsa(λ) は ,フ ァ ジ ィ 推 論 と 強 化 学 習 の Sarsa(λ)を組み合わせたものである.連続的な状態 行動空間を扱うために量子化にファジィ推論を用いて いる.強化学習にSarsa(λ)を用いることで,環境との 相互作用を通じて,方策改善も同時に改良しながら,学習する.Proc. 1にFuzzy Sarsa(λ)のアルゴリズムを
示す[3]. 状態st の時に行動at をとることで,将来的にどれ だけの報酬が期待できるかを,価値関数Q(st, at)を用 いてQ値で表す. e(si, aj) = 0は状態行動対(si, aj)の適格度トレー ス,ˆatは行動価値である.Fuzzy Sarsa(λ)のアルゴリ ズムが特徴的なのは,(7)の適格度トレースの部分で, 今までのステップにおいて実際に適用された状態行動 対の値の系列をメンバーシップ関数µi(ˆst)を用いて学 習するところである.各状態siと直前までに選択した 行動に注目して,最適なひとつの行動を決定する.これ によってQ値更新の際の学習速度が向上する.また, (12)のベルマンエラー(Bellman error)値をそのまま 方策に結びつけている. 本手法では (4) の行動選択の部分を変更した. ϵ-greedyによって行動を選択,すなわち,アクセル値と
− 28 −
Proc. 1 Fuzzy Sarsa(λ)
1: t = 0, ∀(si, aj) ∈ S × A e(si, aj) = 0 and initialize Q(si, aj) arbitrarily.
2: repeat for each episode
3: Initialize ˆstand evaluate µi(st)∀si∈ S
4: ∀si∈ S, choose atji∈ A using ϵ-greedy policy.
5: ˆat=∑hi=1µˆst× a
t ji
6: repeat for each step in episode
7: Compute eligibility traces∀(si, aj)∈ S × A et+1(si,aj)= µi(ˆst) if µi(ˆst)̸= 0 and aj= atji 0 if µi(ˆst)̸= 0 and aj̸= atji γλet(si, aj) Otherwise
8: Apply ˆat, observe reward rtand new state ˆst+1
9: ∀si∈ S, evaluate µi(ˆst+1)
10: ∀si∈ S, choose at+1(ji)∈ A using ϵ-greedy policy.
11: ˆat+1=∑ni=1µ(st+1)× ˆat+1ji
12: Compute the Bellman error:
δt= rt+γ∑ni=1µi(ˆst+1)×Qt(si, at+1ji )− ∑n i=1µi(ˆst)× Qt(si, atji) 13: ∀(si, aj) ∈ S × A, update Q(si, aj): Qt+1(si, aj) ← Qt(si, aj) + α× δt× et+1(si, aj) 14: ∀si S µi(ˆst) ←µi(ˆst+1) a t ji← a t+1 ji , t ← t + 1.
15: until ˆstis terminal ▷ end episode
16: until a satisfactory condition ▷ end learning
ステアリング値を選択している部分に,直接値を代入す ることで人の教示を強化学習の中に取り入れた.
4
実験
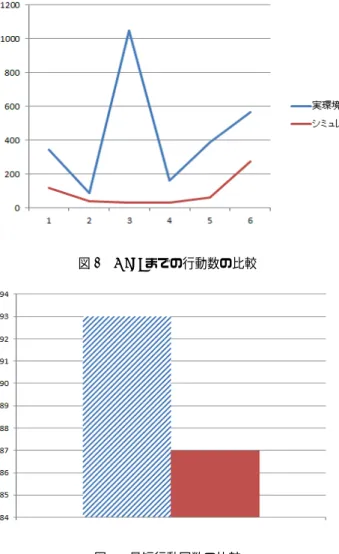
仮想環境で学習済みの行動知識を用いて,実境を再学 習中のロボットに教示を与えることによる学習効率に ついて考察するための実験である. 4.1 実環境におけるロボット制御 実環境におけるロボット制御について詳しく述べる. 先行研究[1]では,仮想環境内での本手法の有効性を 確認した.このときに獲得した状態行動空間を用い,実 環境上でロボットが経路探索を行う.ロボットは,実環 境に配置したカメラから送られた画像データから,自分 の位置情報を得る.この位置座標と行動知識を基に推論 し行動決定を行い,実際に行動する. 4.2 人の教示データ ロボットがゴールから遠ざかる動きを行う場合,コマ ンド入力によって教示を与える.コマンド入力の指示 は,表1のようになっている.数字の1∼2を入力する ことでアクセル値(速度)とステアリング値(旋回速度) による制御が行われる.数字の3∼4を入力するとアク セル値(速度)を制御できる.教示による強制的な行動 制御が行われると.ロボットは副報酬値を獲得できる. 得た副報酬値は,それまでの総報酬値に加算される. 4.3 課題設定 実験環境について図3に示す. また使用するロボット を図4に示す. 実験タスクとしては,ロボットがGoalエリアへ入る 表1 コマンド対応表 入力記号 コマンド 1 右にゆっくり旋回 2 左にゆっくり旋回 3 小さく前進 4 大きく前進 フィールド:縦120cm×横120cm連続平面 スタート地点:座標(90,90) ゴール地点:座標(0,0),(30,0),(30,30),(0,30)を結んだエリア 内 フィールドの四方に高さ30cmの壁 図3 実験環境 LEGO社MINDSTORMSを1体を使用 倒立制御,行動制御,障害物検知を行う(オープンソース) 図4 実環境で用いたロボット ことが目標である.ロボットは各ステップ毎に環境か ら-1の報酬を受け取る.ロボットが壁に衝突した場合 は,-200の報酬,目標達成した場合は +5000の報酬 を受け取る.次ステップまでの行動出力間隔を 1000ms としている.ステップ数が1000を超えたら終了として いる. 4.4 実験結果 実験の結果,仮想環境で得たロボットの挙動に対し て,実環境のロボットの挙動には再現性がないことがわ かった.図5にロボットがStartからGoalするまでの− 29 −
図5 Goalまでの行動数の比較 図6 最短行動回数の比較 仮想環境,実環境の行動数を示す.仮想環境で得られた 行動知識を用いて,実環境で動作実験を行ったものの, 実環境での提案手法の有用性を示せるまでに至っては いない.ロボットのセンサやモータの誤差による影響 が大きいと考えている. 実環境における行動数は1000回を超える時があり, 教示を与えているにも関わらず,シミュレーション結果 を大きく超えた行動数となっている.しかし,教示を与 える行為自体は有効と思われる結果も出ている.教示 を与えた場合と教示を一切与えていない場合の最小行 動回数の比較グラフを図6に示す.図6を見ると,教 示を与えた場合の方がより少ない行動回数でGoalして いることがわかる. 4.5 考察 実環境において実際にロボットを動作させていると き,教示を割り込ませても教示内容がこちらの思った 通りに反映されていない場面が多々あった.それは図5 の結果にも現れた通りである. しかし,ロボットのアクセル値やステアリング値を調 べてみたところ,教示を与えた瞬間は教示がロボット の動きに反映されていた.ロボットは過去の経験から 行動を決定している.つまり,最終的な総報酬値が高く なった過去の経験を優先しているので,教示通りに動作 した時に得る副報酬値がいくら高くてもあまり意味が ないと考えられる. このことから,仮想環境で学習済みの行動知識を用い て,実環境でロボットの再学習をさせたことが行動回数 のばらつきを与えたのではないかと仮定し,行動知識も 一から実環境で作っていく際のロボットの挙動を確認 してみた.学習初期段階ではあるが,教示を割り込ませ た時のロボットの動きは今までとは違うため,収束まで 検証していく必要がある.
5
おわりに
今回は,通常の強化学習機構に半教師あり学習を付加 した学習機構を用いて仮想環境で学習済みの行動知識 が,実環境でのさらなる自律学習と教示による学習に よってどのように環境に適応していくのかを検証した. 仮想環境で学習済みの行動知識に,確実にロボットに 教示内容を反映させたいのであれば,実環境での学習結 果と仮想環境での学習結果をお互いにフィードバック しあうような工夫が必要であることがわかった. 提案した学習機構自体には,最小行動数の比較から可 能性が示唆されるため,行動知識も一から実環境で作っ ていく際の収束結果には現段階では期待できる.参考文献
[1] 笠置みちこ,濱口佑希,大城英裕,末田直道,ロ ボット制御知識獲得のための半教師あり学習を付 加した強化学習機構,第19回 知能メカトロニク スワークショップ講演論文集,E1-1, pp. 161-166, 2014.[2] Richard S.Sutton and Andrew G.Barto 三上貞 芳,皆川雅章 共訳:Reinforcement Learning 強
化学習:森北出版株式会社(2000)
[3] Sylvain Kamdem , 末 田 直 道, 大 城 英 裕: Fuzzy Sarsa with Focussed Replac-ing Eligibility Traces for Robust and Accurate Control:IEEJ Trans.EIS,Vil.130 , No1 , 2010
[4] Xiaojin Zhu:Semi-Supervised Learning Litera-ture Survey,Computer Sciences TR 1530, Uni-versity of Wisconsin - Madison, Last modified on July 19, 2008