学位論文 博士 (情報科学)
視線情報と美的評価則に基づく
画像系列要約に関する研究
Image Sequence Summarization Based on Visual Attention and Aesthetic Measure
2015 年 3 月
山梨大学大学院医学工学総合教育部
澤田 友哉
Tomoya Sawada
指導教官 茅 暁陽
要旨
要旨
要旨
要旨
近年,スマートフォンに代表されるディジタルデバイスの普及とソフトウェアの充実に よって,エンドユーザが多量のデータを使用する場面が増えている.例えば,インターネ ット上の映像コンテンツの視聴や日常的に撮影する写真を考えてみても,解像度はますま す上がり,利便性が日増しに高まってきている.一方で,高解像度のデータを利用する環 境が整いこれが広まったことは,社会におけるデータ量が爆発することを意味する.すな わち,今後も増加し続ける映像や写真などのマルチメディアコンテンツに対して,重要な 情報を要約する手段が求められている.特に,近年のインターネットショッピングにおけ る利用者の購買履歴に基づく購買予測・促進に代表されるように,利用者個々の興味・嗜 好を把握し,利用者の感性を反映させるような要約技術を創造できれば,個々のニーズに 即した多岐に渡るサービスが実現される. 動画に対しては,映像内の情報を時間的・空間的に解析し特徴を得て重要なシーンのみ を検出しまとめる動画要約の研究が行われている.応用例として,動画におけるインデキ シングやダイジェスト,圧縮などがある.また,静止画に対しては画像内の情報を空間的 に解析することで重要箇所を推定し,重要な箇所のみを残して加工することで静止画にお ける要約を行う研究もなされている.これらの研究では対象とするコンテンツが異なって おり,例えば動画要約に関してはニュース・ホームビデオ・監視カメラ・CG やアニメー ション・スポーツ・映画などがある.また,静止画における研究ではスナップショットや 自然画像をターゲットとしている. 本研究では,映像や画像などのコンテンツにおける要約のための手法を提案する.要約 技術は,データ中のどこが重要かを定める“情報の抽出”という意味合いだけでなく,そ れを適切に加工して利用者に提供する“要約結果の提示”という意味合いまで含めること ができる.これを踏まえて,重要情報の抽出から加工結果の提示までを一貫して行うシス テムを提案する. 特に,本研究において着目したのは人の興味を要約結果にいかにして反映させるかとい う点である.本研究では,映像コンテンツの要約に関しては鑑賞者と映像内のシーンとの インタラクションに着目し,鑑賞者の視線情報から特異なパターンを抽出しこれを鑑賞者 の興味の変化ととらえて自動でコミック調の編集を行う.また,静止画の要約に関しては 写真撮影を対象として,構図を決める際の撮影者と撮影シーンとのインタラクションに注 目し,その過程から撮影者の意図を推定することにより自動でベストショットを撮影する. こうした人の自然な振る舞いから意味のある情報を抽出し,またそれを適切に整形して提示することで,情報の抽出から要約結果の提示まで一貫して提供するシステムの開発を目 指す. はじめに,映像コンテンツから鑑賞者の視線情報を利用して自動でコミック調画像に合 成する技術を提案する.フィルムコミックとは,映像コンテンツをコミック調画像に変換 したものである.従来,フィルムコミックの作成のためには,専門家が人手で以下の処理 を行っていた.すなわち,映像内に含まれる膨大な数のフレーム画像の中から重要なもの を選出し,シーンの内容に応じたレイアウトを設計し,レイアウトの形状に沿って選択し たフレーム画像を加工し,セリフのあるシーンではセリフを配置して完成する.以上の工 程において,重要フレームの選出は絵コンテに示されることが多いようにシーンの内容を よく描画するように選ばなくてはならず,またフレーム画像の加工やセリフの配置は画像 内における重要箇所を切り取ったり隠したりしてしまわないようにして実現しなくては ならない.さらに,レイアウト設計はシーンの内容をよりわかりやすく整形する必要があ る.しかし,重要フレームや重要箇所の検出には,映像作品そのものの理解が不可欠であ り,画像処理技術のみからこれを実現することは難しい.そこで本研究では,人の興味を 時空間的に抽出することで,以下の処理の自動化を実現した.1)映像コンテンツから人の 興味を引くような,重要なフレーム画像の選出.2)見栄えの良さだけでなく,内容が把握 しやすいレイアウト設計.3)重要箇所を切り取らず,元の構図を維持したトリミング.4) 重要箇所を隠さず,読みやすく加工したセリフ配置.人の興味を捉えるための手段として, 本研究では視線情報を利用した.これによって,実際の人の興味を直接反映するようなコ ミックの自動生成を実現した. 次に,撮影時におけるユーザのカメラ移動から最適構図を探索し,オートフレーミング を実現する手法を提案する.オートフレーミングとは,被写体を発見し被写体位置が最適 な位置となる構図を求めて自動で撮影する技術のことを指す.一般的に写真の構図を体得 するには,長い経験とセンスが必要であり素人にとっては構図の良い写真を撮ることは難 しい.本研究ではシステム側が自動で良い構図で切り取ることで素人でも構図の良い写真 が撮れることを目指し,オートフレーミングの実現に際して以下の手法を提案する.まず, 予備実験の結果,撮影者は写真を撮る前に構図を決めかねてカメラを移動させることがわ かった.そこで,1)このときのカメラ移動から,撮影者が何を撮ろうとしているのか,そ の主観的な被写体の推定を行う.そして,2)被写体位置が構図として良いかを調べるため に三分割法というカメラ撮影におけるヒューリスティックなルールを用いて客観的に美 観評価を行う.撮影者が何を撮りたいのかを知るには撮影者の興味の推定に踏み込む必要 がある.撮影者の興味を捉えるための手段として,本研究ではユーザのカメラ移動を利用 した.これによって,撮影者の意図を反映した被写体が美しい構図でオートフレーミング されるようにした. 最後に,静止画や動画において人の目を引く箇所を画像処理的に求める顕著性マップの 要素として,特に写真工学で用いられるリーディングライン効果を付与した顕著性マップ の作成技術を提案する.リーディングライン効果とは,空間上に直線成分や線群が一点に 収束するように構成された場面では,人の目はリーディングラインの収束先に引かれやす いという経験則である.本研究では,検証実験により視線はリーディングラインの収束先 に誘導されることが示されたため,リーディングラインを含む画像において既存の顕著性 マップとリーディングラインの重みとを視線情報を用いて学習して求め,リーディングラ インを付与した顕著性マップの実現に成功した.これを基にして最適構図を求める問題を
解決することで,より実際の人の興味を反映した構図結果が得られることが期待できる. 以上のように,本研究では映像コンテンツおよび写真における要約技術に関するプロセ スを確立し,人の興味を反映した要約技法を提案した.人の興味の推定は,実際のコンテ ンツを視聴中の鑑賞者の視線や,撮影中のユーザのカメラ移動に基づくものであり,こう した人の自然な振る舞いからユーザに負荷なく,意味のある情報を抽出でき,かつそれを 整形して提示することで,情報の抽出から要約結果の提示まで一貫して提供するシステム の開発に成功した.今後もますます増大するコンテンツに対して,人の興味や意図を反映 した要約技術は近い将来必ず必要となってくる.その時,本研究で提案した人の自然な振 る舞いから内容理解に踏み込む研究が大きく貢献するものであると確信する.
ABSTRUCT
The popularization of digital devices such as smartphones together with the enhancement of software environments has recently calls for the necessity to deal with massive amount of image and video contents. A large amount of video contents are now conveniently available on the Internet. On the other hand, the rapid improvement of camera performance makes it possible to take photographs of very high resolution. Many people have established the style of sharing their own lives with others by using Social Networking Service (SNS). Since photographs and videos are the major contents of lifelog, many applications for sharing high quality Image/Video contents have been provided. All of these imply that tremendous amount of data is in flood, and the methods for extracting real valuable information from Image/Video contents are becoming more and more important.
Considering such background, some researchers have been working on Video Summarization which is a technology for extracting important scenes from a video by analyzing the video spatially and temporally. Image Retargeting is another technology related to the information extraction from a large image. It analyzes an image spatially and detects the informative areas so as to keep those areas not changed as possible when change the size or aspect ratio of the image. Various video summarization and image retargeting techniques have been developed for dealing with different contents. For example, in case of video summarization, the major types of contents include news, home videos, surveillance videos, CG/animation, sport TV programs, movies and so on. The contents of image retargeting can be divided into two major types: snapshots and natural images.
This thesis proposes the novel techniques for summarizing Image/Video contents. Summarization technique means not only “information extraction” which is to detect the important area or frames from Image/Video contents but also “information presentation” which is to edit the extracted information and present it to users in an easy to understand and aesthetically pleasing way. The proposed technology deals with the whole process of Image/Video summarization from extracting key information to the presentation of extracted information
intention in the summarization. For summarizing video contents, eye tracking data is used to predict the users’ interest. By analyzing the relationship between viewer’s eye movement patterns and the contents of the video, it is found that some particular eye movement patterns can be used to infer the shift of viewer’s interests. By detecting the moment when such eye movements occur, it is possible to extract important frames from a video. As an image summarization problem, how to take a best shot reflecting users’ intentions was studied. When taking a photograph, the user usually tries to take a shot with best composition by moving his/her camera around. Such camera movement can be used to predict the user’s intention. In other words, meaningful information can be extracted based on users’ natural gestures/behaviors. The thesis presents 3 main contributions.
First, I propose a novel way to generate film comic from video automatically by using viewer’s eye-tracking data. A film comic is generated from the frame images of a movie. Automatic generation of film comic requires solving several challenging problems such as selecting important frames well conveying the whole story, creating comic layout attracting readers, trimming frames to fit into panels in pages, and arranging speech balloons without hiding important objects. These problems are story dependent, and even user dependent, and hence cannot be solved with naive Image/Video processing. The key idea of the proposed technique is to employ eye-tracking data of multiple viewers. Specific eye movement patterns provide clues for understanding the whole story. The best frame selection and the best layout of panels/balloons are obtained by analyzing the eye movement patterns. Computational Heat map, which combines eye position information and image features, is computed to indicate the importance of frames and regions in a frame. The speech balloon arrangement and image trimming are realized as the result of optimizing an energy function defined with the Heat map. The effectiveness of the proposed method was confirmed through subject studies.
Next, I propose an Auto-Framing technique for automatically generating a photograph with the best composition based on the camera motion right before a user release the shutter. The proposed method solves the issue of how to determine the best composition by detecting the user intended object and considering the aesthetic measure. Generally, taking photos of good composition requires rich experience and good aesthetic sense, and therefore, it’s usually a difficult for naive users. Through a preliminary study observing how users take photos, it is found that almost all users move camera around before releasing shutter due to the hesitation in deciding the composition, and the object of interest is likely being included in most candidate shots during the whole process for finding best composition. Such founding suggests the possibility of using such camera motion to predict the user’s subjective intention. Auto-Framing technique is implemented in the following steps. First, the user’s subjective intention is predicted with an Importance map by combining Saliency map and Master map computed by accumulating all the local image features captured during the camera movement. Then the position of the user intended object is decided
based on Rule of Thirds, which is known as a typical heuristics rule for deciding a balanced composition. The experiment result demonstrates that the proposed approach succeeded in generating aesthetically pleasing photos reflecting the subjective intention of users.
Finally, I propose a new kind of Saliency map taking account of leading line effect. Saliency map is known as the computation model for predicting human’s visual attention. It is know that in photographs and paintings, lines converging to a point attract viewer's attention. Those lines are called as leading lines. Such phenomenon was confirmed in the primary study. During the experiment, the eye positions of subjects are recorded and used as the training data to learn the weight for combining existing Saliency map and the Saliency map based on leading lines. Through evaluation experiment, it is confirmed that the new Saliency map generated with the proposed technique provides a better prediction to the visual attention than the traditional method based on center-surrounding difference of major visual features. In the future, I plan to incorporate the new Saliency map into the Auto-Framing technique so as to generate photos reflecting users’ attention more accurately.
To summarize, this thesis proposes novel summarization methods for Image/Video contents by considering the user’s interest or intention as well as the aesthetic measure. For predicting users’ interests, eye-tracking data or camera motion is used. By using these natural gestures/behaviors, meaningful information can be extracted and edited properly without adding extra load to users. The implemented prototype system provides consist supports to the whole process of Image/Video content summarization, from extracting key information to the presentation of the edited result. Such technique is sure to be needed for solving the massive data problem in the future.
目次
目次
目次
目次
概要 概要 概要 概要 ... エラーエラーエラーエラー! ブックマークが定義されていません。ブックマークが定義されていません。ブックマークが定義されていません。ブックマークが定義されていません。 ABSTRUCT ... 6 第1章 第1章 第1章 第1章 序論序論 序論序論 画像系列要約の目的と実現方法画像系列要約の目的と実現方法画像系列要約の目的と実現方法画像系列要約の目的と実現方法 ... 14 1.1 研究背景 ... 14 1.2 研究概要 ... 23 1.2.1 フィルムコミックの自動生成... 23 1.2.2 オートフレーミングカメラ ... 24 1.2.3 リーディングライン効果を付与した顕著性マップ ... 25 1.3 論文構成 ... 26 第2章 第2章 第2章 第2章 視線パターンに基づく視線パターンに基づく視線パターンに基づく視線パターンに基づく映像コンテンツからの映像コンテンツからの映像コンテンツからのフィルムコミックの自動生成映像コンテンツからのフィルムコミックの自動生成フィルムコミックの自動生成フィルムコミックの自動生成..27 2.1 はじめに ... 27 2.2 関連研究 ... 29 2.3 提案手法概要 ... 32 2.4 フレーム選出 ... 33 2.4.1 鑑賞者の視線移動に基づく重要シーン検出のための予備実験 ... 33 1. 視線の分散値の急変 ... 33 2. まとまった状態での集団の視線の大きな移動 ... 37 2.4.2 予備実験に基づくアルゴリズムの開発 ... 39 2.5 レイアウト設計 ... 40 2.5.1 コマの初期形状 ... 42 2.5.2 ページ生成 ... 43 2.6 コマ編集 ... 44 2.6.1 Heat Map の作成 ... 44 2.6.2 画像のトリミング ... 46 2.6.3 セリフ配置 ... 47 2.7 実験と結果 ... 48 2.7.1 フレーム選出に対する評価 ... 49 2.7.2 レイアウト設計に対する評価... 54 2.7.3 コマ編集に対する評価 ... 55 2.7.4 追加実験 ... 58 2.8 おわりに ... 59 第3章 第3章 第3章 第3章 カメラ移動に基づくカメラ移動に基づくカメラ移動に基づくカメラ移動に基づくオートフレーミングの実現オートフレーミングの実現オートフレーミングの実現オートフレーミングの実現 ... 61 3.1 はじめに ... 61 3.2 関連研究 ... 62 3.3 システム概要 ... 65 3.4 主観的興味の抽出による被写体発見 ... 66 3.4.1 画像合成手法 ... 68 3.4.2 Master Map の作成 ... 693.5 客観的美観評価による最適構図の自動決定 ... 72 3.5.1 三分割法 ... 72 3.5.2 評価関数の作成 ... 73 3.6 実験と結果 ... 76 3.7 おわりに ... 84 第4章 第4章 第4章 第4章 リーディングライン効果を付与したリーディングライン効果を付与したリーディングライン効果を付与したリーディングライン効果を付与した顕著性マップの開発顕著性マップの開発顕著性マップの開発顕著性マップの開発 ... 86 4.1 はじめに ... 86 4.2 関連研究 ... 87 4.3 リーディングラインを含む画像における視覚注意に関する検証実験 .... 88 4.4 提案手法 ... 90 4.4.1 リーディングライン顕著性マップと 中心周辺差分顕著性マップの統合 ... 90 4.4.2 リーディングラインの検出 ... 90 4.4.3 学習用視線データの収集 ... 91 1. 視線データの収集 ... 91 2. 使用する視線データの決定 ... 92 4.4.4 マップの作成 ... 93 4.5 結果と評価 ... 94 4.6 おわりに ... 98 第5章 第5章 第5章 第5章 結論結論結論結論 画像系列要約のまとめと今後の課題画像系列要約のまとめと今後の課題画像系列要約のまとめと今後の課題画像系列要約のまとめと今後の課題 ... 100 5.1 本研究のまとめ ... 100 5.2 本研究におけるアプローチ ... 100 5.3 今後の課題および展望 ... 102 謝辞 謝辞 謝辞 謝辞 ... 105 参考文献 参考文献 参考文献 参考文献 第1章 第1章第1章 第1章 ... 106 第2章 第2章第2章 第2章 ... 109 第3章 第3章第3章 第3章 ... 111 第4章 第4章第4章 第4章 ... 113
図目次
図目次
図目次
図目次
1.1 フィルムコミックの自動生成の概念図… ……… 23 1.2 オートフレーミングの概念図… ……… 24 1.3 リーディングライン効果を付与した顕著性マップの概念図……… 25 2.1 提案手法概要… ……… 32 2.2 シーン A における視線の振る舞い… ……… 34 2.3 シーン B における視線の振る舞い ……… 34 2.4 シーン C における視線の振る舞い ……… 34 2.5 シーン D における視線の振る舞い… ……… 35 2.6 シーン E における視線の振る舞い ……… 35 2.7 シーン F における視線の振る舞い ……… 36 2.8 シーン G における視線の振る舞い……… 36 2.9 シーン H における視線の振る舞い……… 37 2.10 シーン I における視線の振る舞い ……… 37 2.11 シーン J における視線の振る舞い……… 38 2.12 シーン K における視線の振る舞い… ……… 38 2.13 シーン L における視線の振る舞い……… 38 2.14 オートレイアウトシステム概要… ……… 41 2.15 カメラワークを反映したレイアウト例… ……… 42 2.16 レイアウトの整形例… ……… 43 2.17 Heat Map の作成… ……… 45 2.18 Heat Map に基づく画像のトリミング… ……… 472.19 The Wacky Wabbit における既存手法との比較……… 50
2.20 My Artistical Temperature における既存手法との比較……… 51
2.21 シーン M における視線の振る舞い……… 51
2.22 My Artistical Temperature における各手法のフレーム選出の違い…… 52
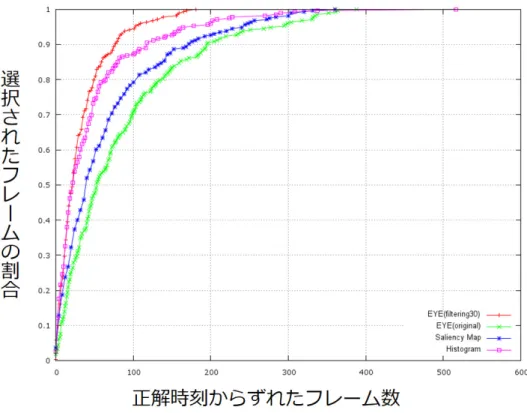
2.23 The Wacky Wabbit における各手法のフレーム選出の違い……… 54
2.24 提案手法により作成したフィルムコミック例 ……… 55
2.25 Walther らによる Saliency Map と提案手法による Heat Map の比較 … 56 2.26 Heat Map に基づくトリミング例 ……… 57 2.27 Heat Map に基づくセリフ配置例 ……… 57 2.28 選出フレームと Heat Map の透過画像……… … 58 2.29 パラメータ調整後のフィルムコミック例 ……… 60 3.1 提案手法概要 ……… 65 3.2 シーン A におけるカメラの予備動作 ……… 67 3.3 シーン B におけるカメラの予備動作……… 67 3.4 シーン C におけるカメラの予備動作……… 67 3.5 Stitching 技術による画像合成の概要及び実行例……… 69 3.6 Structure Map 作成方法 ……… 71 3.7 提案手法における各マップの要素の違いと Master Map の結果…….. 72 3.8 三分割法に則る写真例 ……… 73 3.9 Hou ら[13]による周波数解析アプローチに基づく顕著性マップ……... 74
3.10 トリミング後の顕著性マップの違い………. 74 3.11 重要箇所とそうでない箇所の比率… ……… 76 3.12 異なるアスペクト比における最適構図の探索結果 (シーン A) ……… 77 3.13 異なるアスペクト比における最適構図の探索結果 (シーン B) ……… 77 3.14 異なるアスペクト比における最適構図の探索結果 (シーン C) ……… 78 3.15 異なるアスペクト比における最適構図の探索結果 (シーン D) ……… 78 3.16 異なるアスペクト比における最適構図の探索結果 (シーン E) ……… 79 3.17 異なるアスペクト比における最適構図の探索結果 (シーン F) ……… 80 3.18 異なるアスペクト比における最適構図の探索結果 (シーン G)……… 81 3.19 異なるアスペクト比における最適構図の探索結果 (シーン H)……… 82 3.20 アスペクト比の違いと正解との一致率……… 82 3.21 アスペクト比 1:1 における各マップの正解との近さ……… 83 3.22 アスペクト比 3:2 における各マップの正解との近さ……… 83 3.23 アスペクト比 16:9 における各マップの正解との近さ……… 84 4.1 提案手法によるリーディングラインを含む顕著性マップ………. 87 4.2 実験環境………. 88
4.3 Heat Map と Itti らの顕著性マップ………. 89
4.4 リーディングライン収束先の検出………. 91 4.5 収集した画像例………. 92 4.6 刺激の提示方法………. 92 4.7 被験者の順番付視線データ………. 93 4.8 画像番号 4 の顕著性マップ………. 93 4.9 画像番号 6 の顕著性マップ………. 93 4.10 画像番号 7 の顕著性マップ………. 94 4.11 顕著性マップと視線マップの差分………. 94 4.12 提案手法と既存手法[10]の比較 (シーン A) … ……… 95 4.13 提案手法と既存手法[10]の比較 (シーン B) … ……… 96 4.14 提案手法と既存手法[10]の比較 (シーン C) … ……… 96 4.15 提案手法と既存手法の性能評価(AUC) ……… 97 4.16 提案手法と既存手法の性能評価(SIM) ……… 97 4.17 提案手法と既存手法の性能評価(EMD) ……… 98 4.18 畠ら[9]の鉛筆画生成手法における顕著性マップの違い……… 98 4.19 学習用画像例……….…… 99 4.20 評価用画像……….… 99
表目次
表目次
表目次
表目次
1.1 重要箇所の推定要素と本研究の位置づけ……….……… 22 4.1 提案手法と既存手法の TC 値(%)の比較……….……… 95 4.2 式(2)により求めた各画像セットの重み k の最適値……….……… 96第1
第1
第1
第1章
章
章
章 序論
序論
序論
序論
画像系列要約の
画像系列要約の
画像系列要約の
画像系列要約の目的と
目的と
目的と
目的と実現
実現
実現方法
実現
方法
方法
方法
1.1
研究
研究
研究
研究背景
背景
背景
背景
近年,エンドユーザにもスマートフォンに代表されるディジタルデバイスが普及し,日 常生活において必需品となっている.また,こうした市場の拡大に伴ってソフトウェアの 充実もなされており,生活を豊かにするようなアプリケーションも開発されている.この ような情報化社会の著しい発展に伴って,我々の日常において多量のデータを使用する機 会が増えている.例えば,インターネット上の映像コンテンツの視聴や日常的に撮影する 写真を考えてみても,解像度はますます上がり,利便性は日増しに高まってきている.ま た,最近では SNS 等を活用して自分の生活を他人と共有するスタイルが確立されつつあ り,ライフログと化して大きな人気を博している.こうしたニーズを受け,高解像度の静 止画・動画を共有するためのサービスも充実してきている. 一方で,高解像度のデータを利用する環境が整いこれが広まったことは,社会における データ量が爆発することを意味する.こうしたデータの氾濫は,生活の利便性を高めるが, データを包括的に管理することは困難である.すなわち,今後も増加し続ける映像コンテ ンツや写真を含む多量のデータに対して,重要な情報を要約する手段が必要である. 多量のデータを簡易に利用できる昨今,データを要約し利活用することは現代の情報化 社会にとって大きな意義がある.要約技術は,データ中のどこが重要かを定める“情報の 抽出”という意味合いだけでなく,アプリケーションにおける応用面では,それを加工し て利用者に提供する“要約結果の提示”という意味合いまで含めることができる.近年の トレンドワードであるビッグデータにおいては,多量かつ複雑な情報の集合に対して,重 要情報の抽出から結果の可視化までを一貫して解決することが望まれている[35].このこ とからも,要約に対する要求が情報の抽出だけでなく,その結果の提示手段にまで及んで いることがわかる. 多量のデータに対して統計的手法を適用し,情報の抽出を試みる手法はデータマイニン グと呼ばれ,古くから研究が進められてきており概念とそのアプローチに関して Han ら[1] の文献で調査されておりこれを参照されたい.現代社会においては,ソーシャルメディアは日常生活で必須の存在となっており,写真や動画の共有,ウェブブログやナレッジコミ ュニティなど多彩なジャンルが存在する.増え続ける膨大な情報に対して重要なものを知 的に判断し自動で抽出するニーズは,今後もますます必要となってくる.特に,マルチメ ディア(言語,音声,映像,画像など)に対するマイニングは必要性を増している.例えば, 言語処理の分野では多量のテキストに対して重要な情報の収集を行うテキストマイニン グが知られている[2].近年のインターネットの普及に伴って,爆発的に増え続けている ウェブページや,多くのユーザが利用している SNS サービスに対してテキストマイニン グを行うウェブマイニングが,その重要性を増している.また,音声処理の分野において は,大量に用意された音声データを利用して音声合成を行い,応用として自動テキスト読 み上げ(Text To Speech)技術の提案が古くからなされており[3],現在においてカーナビゲー ションシステムや公共交通機関の案内板など,至るところで利用する機会がある.テキス ト読み上げ技術(Text To Speech)は,Dutoit[4]の文献を参照されたい.また,画像処理の分 野において,映像コンテンツの要約技術は動画要約(Video Summarization)と呼ばれ,膨大 な映像中のシーンの中から重要な所だけを抽出する技術として用いられている[11]-[13]. さらに,近年のメディアの発展とデバイスの普及によってコンテンツを楽しむための機器 が身近にあふれている背景を受け,異なるデバイス間で画像の見た目が変わらないように コンテンツサイズを動的に変更させる研究は Image Retargeting と呼ばれ,静止画における 要約技術として知られる[5, 6].また,これを拡張して動画における空間リサイジングを 実現させる技術は,Video Retargeting と呼ばれる[7]-[10].Setlur ら[5]は Image Retargeting において,領域分割の結果と顕著性マップ(Saliency Map)を統合して重要物体を検出して 背景と分離し,背景のみをユーザ任意のサイズにリサイズした後,重要物体を再度貼り付 けることで重要物体の配置や形状が変化しないリサイジング方法を提案した.顕著性マッ プ(Saliency Map)は,動画や静止画において人の興味を引く箇所を推定する技術として知 られている.Lin ら[6]は,領域分割した結果と顕著性マップを複合して重要領域を定義し, 入力画像にメッシュを張って重要箇所ほど変化しにくいようにリサイズする手法を提案 した.彼らの手法では,画像の直線成分のような構造情報も考慮することで,編集箇所が 人目に付きにくいような自然なリサイジング結果を得ている.さらに,彼らはこの手法を 動画へ拡張し,Video Retargeting においても時空間的に重要箇所を求めることでこれを解 決している[7].また,Kang ら[8]は,時空間的に顕著な箇所を求め顕著でない箇所を省略 して時空間的に合成することで,動画における時空間的なモンタージュ技法を提案してい る.Zhang ら[9]は,動画に対してカット検出を行った後に各ショットに対して顕著性・動 き・テクスチャの 3 要素からなる重要度マップを作成し,重要な所が残るようにクロッピ ングを行って大雑把に画面サイズを縮小し,列方向のみのメッシュ変形を用いたリサイジ ングを行うことで,重要箇所の変形が少なく人目に編集痕が分かりにくい Video Retargeting 技術を提案している.また,Li ら[10]は,グリッドベースで毎フレームトラッ キングを行うことでグリッドの流れからキーフレームを選出し,キーフレームに対してリ サイジングをしてそれ以外のフレームをリサイジング結果に合わせて補間することで Video Retargeting を行う手法を提案した.この手法では,フレーム間の対応がとれている ためフレーム毎に重要箇所のリサイジング結果が異なることが少ない. 既存研究[5]-[10]では,映像や画像においてリサイジングを実現するために重要箇所を 求め,空間的に要約を行うアプローチがなされていたが,要約技術はデータ中のどこが重 要かを定める“情報の抽出”という意味合いだけでなく,それを適切に加工して利用者に 提供する“要約結果の提示”という意味合いまで含めることができる.これを踏まえて,
本研究では重要情報の抽出から加工結果の提示までを一貫して行う要約技術を提案する. 特に,本研究において着目したのは人の興味を要約結果にいかにして反映させるかという 点である.要約技術の実現のためには時間的・空間的・時空間的な重要箇所を推定するこ とが必要であるが,本研究では“視線”を用いてこの解決を図る.すなわち,人の自然な 振る舞いから意味のある情報を抽出し,またそれを適切に整形して提示することで,情報 の抽出から要約結果の提示まで一貫して提供する手法の開発を目指す.システムの実現に 際し,フィルムコミックの自動生成フィルムコミックの自動生成フィルムコミックの自動生成フィルムコミックの自動生成・オートフレーミングカメラオートフレーミングカメラオートフレーミングカメラ・リーディングラインオートフレーミングカメラ リーディングラインリーディングラインリーディングライン を付与した顕著性マップの を付与した顕著性マップの を付与した顕著性マップの を付与した顕著性マップの作成作成作成という 3 つの応用アプリケーションを提案する.これに先作成 立って,関連する要素技術を以下に述べる. フィルムコミックの自動生成 フィルムコミックの自動生成 フィルムコミックの自動生成 フィルムコミックの自動生成. 本研究では,映像コンテンツを見る際の鑑賞者とシー ンとのインタラクションに注目し,その間の視線移動から鑑賞者の興味を推定し,鑑賞者 の興味を反映させながら読みやすく最適化されたコミック編集を自動で行う手法を提案 する.フィルムコミックとは,CG やアニメーションなどの映像コンテンツをコミックに したものであり,映像中からシーンを代表するような画像を抽出する必要がある.映像の 中から重要なシーンを選んでくる手法は動画要約(Video Summarization)技術と呼ばれよく 研究されている.例えば,Fiss ら[11]は,ビデオチャットのように人の顔が写っている動 画を対象として,顔の動き(瞬き・目線の動き・口の動き・顔の表情の動き)と顔のテクス チャ解析の結果を特徴とし評価関数を定め,人手で評価させた良い顔のフレーム画像にお けるパラメータを学習することで重要フレームの選出手法に成功している.また,You ら [12]は,鑑賞者の興味を集める,映像内の動き・コントラストの変化・顔やセリフなどの 高次の情報・分割したシーンの時間的長さの 4 つを時系列的な特徴として利用し,これら を組み合わせて映像コンテンツからキーフレームを選出する動画要約技術を提案してい る.Geetha[13]らは,人の視覚特性を利用した静的な特徴量と動作検出を利用した動的な 特徴量によって重要度を算出し,映像から重要シーンを検出する手法を提案している.動 画要約(Video Summarization)は,本研究と密接に関連するため,特に第 2 章において詳述 している.また,本研究では人の興味を反映した動画要約を行うため,鑑賞者の視線情報 を利用する.映像と鑑賞者の視線に関する研究として,Hillaire ら[14]は,ウェブカメラを 使った安価な視線追跡技術を実現し,顕著性マップ(Saliency Map)を用いることによって 視線位置の取得精度を飛躍的に高めている.Häkkinen ら[15]は,立体視を利用した 3D 映 像において 2D の映像よりも鑑賞者の興味箇所が散漫してしまい,視線位置がより広範囲 に分布することを調べた.また,Jain ら[16]は,コミック作品における製作者の意図が鑑 賞者の視線を誘導すると考え,検証実験により以下を示した.すなわち,ロボットや素人 の撮った写真が人の視線を誘導する効果に欠け,鑑賞者の視線がばらついてしまうのに対 して,コミック製作者の描くシーンはどの鑑賞者に見せても見るべきところが一致する傾 向にあることが示されている.DeCarlo ら[36]は,静止画において鑑賞者の視線を利用し た抽象画作成手法を提案している.鑑賞者の視線は興味領域(Region of Interest)を含み,顕 著箇所を容易に推定できる.彼らの手法では,領域分割結果と視線位置を利用して視線が 多く存在する箇所を詳細に,それ以外を抽象的に描くことで鑑賞者の興味を反映した抽象 画作成手法を提案した.彼らの抽象画は現実世界をコミック調にした画像にも利用できる. フィルムコミックの自動生成においては,セリフ情報を適切に配置する必要があるがこれ に関連して,Vollick ら[17]は,図に各部の説明をする注釈をつける際,最適な位置に注釈 をつける方法を提案している.本研究における研究チームはこれまでに,鑑賞者の視線と 映像コンテンツのインタラクションを利用し,視線移動のパターンから重要シーンを検出
し,コミック調に合成して要約する技術を提案している[18]-[20]. オートフレーミングカメラ オートフレーミングカメラ オートフレーミングカメラ オートフレーミングカメラ. 本研究では,構図を決める際の撮影者とシーンとのイ ンタラクションに注目し,その過程から撮影者の意図を推定し,ルールベースの美的尺度 と合わせて最適化を行う新たな Computational Photography 技術を提案する.まず,写真に おける構図に関する著書としては Krages[21]で調査されており,これを参照されたい.本 研究では,ユーザのカメラ移動を動画として捉え,その移動課程を Stitching 技術により合 成することでユーザの見ている世界を再現するが,複数枚の画像の合成技術に関して以下 の関連研究を挙げる.Hays ら[22]は,入力画像において編集したい箇所を選択し,似てい る箇所を多量の画像から検索し,選択した候補をシームレスにつなぎ合わせる技術を提案 した.また,Chen ら[23]は,ユーザのスケッチと描いたものを説明するテキストから,現 実世界の写真を作成する技術を提案した.彼らの手法では,入力のシーンに最も類似した 背景画像を検索し,またユーザの意図を汲んだ物体検索を行う.そして,背景と物体の組 み合わせを最適化することでより自然な合成画像を得ている.Bae ら[24]は,歴史的な建 物などで過去に撮られた画像を参照画像とし,同じ場所でユーザを誘導しながら位置合わ せをして写真を撮らせることで,過去の写真と現在の写真を融合させる Re-Photography 技術を提案した.He ら[25]は,三脚を使わずに撮影した写真が傾いてしまうことを考慮し, 撮影後の写真をシステムが自動で傾きを補正する技術を提案した.彼らの手法では,エッ ジ・物体形状・境界線が保たれるようにメッシュを利用した画像変形によって,写真の内 容が変化しないような傾き補正を実現した. リーディングラインを付与した顕著性マップの リーディングラインを付与した顕著性マップの リーディングラインを付与した顕著性マップの リーディングラインを付与した顕著性マップの作成作成作成作成. 本研究では,リーディング ラインと呼ばれる,一点に収束する直線成分が人の視線を誘導する効果があることを利用 し,静止画や動画から人の視線を集める箇所を推定する技術として知られる顕著性マップ にこれを付与することで,より正確な顕著性マップの作成技術を提案する.近年の顕著性 マップのアプローチについて以下にまとめる.まず,画像内の特徴のみを利用した低次の 特徴量を用いた顕著性マップを以下に挙げる[26]-[32].Klein ら[26]は,画像の色・彩度・ 方向性の各特徴に対し,周辺と中央がどれ程異なるかを情報量の差異を求める尺度である KLD(Kullback Leibler Divergence)を用いて計算し,それらを統合して顕著性マップを作成 した.Achanta ら[27]は,入力画像を代表する色を抽出し入力画像にガウシアンフィルタ かけたものからこれを引くことで,簡易的な手法でありながら高解像度な顕著性マップが 得られることを示した.Liu ら[28]は,多重解像度のコントラスト,ヒストグラムの中心 周辺差分値,色の空間分布を特徴量として各特徴の重みを学習によって求め,前景と背景 を分離しやすい顕著性マップを提案した.Cheng ら[29]は,画像内のすべてのピクセルに 対して色の差分を求め,ヒストグラムを平滑化することで領域分割のような効果を付与し てこれを顕著性マップとして提案した.Perazzi ら[30]は,画像を抽象化してコントラスト の特異性と空間的分布を特徴量として抽出し,これを統合して前景と背景を完全に分離す るような顕著性マップを提案した.Chang ら[31]は,物体推定と顕著箇所推定の両方を兼 ね備えた顕著性マップを提案している.彼らの手法では,物体らしさと顕著らしさをエネ ルギーとしこれをピクセルベースで最小化問題として解くことで,どちらの性質も持ち合 わせた顕著性マップを作成した.一方,Wei ら[32]は,物体らしさや前景ではなく背景に 着目し,境界付近では色差が大きくなることを期待し,グラフの枝の重みを隣接パッチの 色の差分として枝の重みが最小になるようなパスを探索することでグラフ理論を利用し た顕著性マップを提案した.さらに,これらの低次の特徴だけではなく,人の認知レベル
の高次の特徴を含んだ顕著性マップが提案されている[33, 34, 37].Borji[33]は,色・輝度・ 方向性等を使って求められる低次の特徴量を基に求められる顕著性マップと,人・顔・車 等の認知的な要素を含む高次の特徴を基に求められる顕著性マップとを,人の視線を学習 して統合することで,より精度の高い顕著性マップを提案した.また,Goferman ら[34] は,コントラストや色などの低次の特徴,画像全体に対する標準からのずれ特徴,見かけ の構成ルール,人の顔などの高次の特徴を複合した顕著性マップを提案した.彼らの手法 では,顕著な領域は局所的に存在し,そうでないものは広域に存在するとして,エッジや 前景物体によく反応する顕著性マップを提案した.また,Judd ら[37]は多量の自然画像を 被験者に見せてその間の視線を記録し,視線を学習して顕著性マップを作成する方法を提 案した.彼らの手法では,画像特徴を輝度・色・方向性などの Low level,垂直・水平成 分の Middle level,顔や人物といった認識レベルを表す High level,画像の中心に被写体が ある場合が多いことを考慮した中央バイアスである Center prior に分け,各要素に対する 識別器を鑑賞者の視線から学習して統合している. 以上のように,本研究では複数の研究要素が関連する.表 1.1 に関連する研究分野と本 研究の位置づけを示す.まず,本研究で明らかにするのは時間・空間・時空間における重 要箇所の推定手法に関する研究分野である.時間における重要箇所の推定は,研究分野と して動画要約が挙げられる.空間における重要箇所の推定は,Image Retargeting,Saliency Map,コミック作成要素技術,Image Synthesis・Stitching,最適構図探索などの研究分野が 挙げられる.時空間における重要箇所の推定は,Video Retargeting,動画要約,コミック 作成などの研究分野が挙げられる.また,それぞれの研究分野に対するアプローチとして 画像処理技術によるアプローチと人の生体情報を取得して興味の推定を図るアプローチ に分けられる.画像処理によるアプローチはさらに,画像特徴だけを利用するアプローチ と人の視覚特性を考慮した画像処理技術に分類できる.各研究分野とアプローチの違いを 以下に示す. 動画要約. 動画要約. 動画要約. 動画要約. 動画は一秒間に 30~60 枚以上の画像群からなっており,こう した膨大な画像群の中から重要な瞬間を手動で検出することは困難である.動画の中から 重要なシーンを検出し,一覧や短い動画クリップなどの形式で提示する研究を動画要約 (Video Summarization)という.応用として,Video Indexing やイベント検知,映像のダイジ ェスト作成などが挙げられる.まず,時間要素に対する重要箇所の推定手法について述べ る.画像特徴を利用したアプローチでは主にモーション解析に基づくものが多く,ヒスト グラム・輝度の差分を用いて変化の大きい所を抽出する方法や,人物・物体の動作などか ら重要なシーンを検出する手法がある(第 2 章[15]-[18]).視覚特性を考慮したアプローチ では,これに加えて人物の顔・唇を検出して各フレームの重要度を決定する(第 1 章 [11]-[13],第 2 章[12, 20]).生体情報を利用するアプローチでは,人の興味を正確に推定す るために fMRI を用いて脳血流を計測し血流の変化と脳内の反応箇所から重要フレームを 抽出したり,人の視線情報の注視時間を利用して時系列で重要度の推定を行ったりする (第 2 章[6, 7, 19, 21]).時空間要素における重要箇所の推定方法では,視覚特性を利用した アプローチによるものが多く,顕著性マップ(Saliency Map)を用いて空間的な重要度を推 定したのち,これを時系列に拡張して時空間的な重要度を求め動画要約を行う(第 2 章 [1]-[5]).画像処理を用いる手法が重要なシーンを客観的に選ぶのに対して,生体情報を利 用する手法はユーザの興味を反映した主観的なシーン検出手法だといえる. Image Retargeting.... メディアの発展とデバイスの普及により,コンテンツを楽しむ
ための機器が身近に多く存在する.異なるデバイスに共通のコンテンツを配信する際,デ バイス間で画面サイズや操作方法が違うことを考慮して,アスペクト比の変更やレイアウ トの変更をしてコンテンツの再配信を行うことを Contents Retargeting という.画像コンテ ンツに対して,特にコンテンツ内容が変わらないようにしながらサイズを動的に変更させ る技術を Image Retargeting や Image Summarization という.サイズを自在に変化させるた めには,画像における空間的重要箇所を推定する必要がある.すなわち,重要箇所ほどサ イズ変更による変化の影響を受けにくくする.画像特徴を用いたアプローチでは,画像の 勾配情報を利用して重要箇所を推定し,人目に付きにくい一行・一列を探索して削除・挿 入を繰り返すことで動的なサイズ変更を可能にする(第 3 章[8]).視覚特徴を利用した手法 では,空間上の重要箇所の推定を顕著性マップ(Saliency Map)を利用して求め,領域分割 やメッシュ変形手法を組み合わせて重要箇所ほど変化が少ないようにサイズを変更する (第 1 章[5, 6],第 3 章[6]). Saliency Map.... 画像上における人の興味を引く箇所を推定する画像処理技術 を顕著性マップ(Saliency Map)と呼び,空間における重要度の定義に用いられることが多 い.人の視線は,画像上で選択的に重要箇所を探索して重要箇所を見る.こうした人の生 理学的な視覚刺激の探索過程を計算機的にシュミレーションしたモデルとして顕著性マ ップが定義された.視覚特性を模したアプローチであり,低レベルの特徴量として色・輝 度・エッジ方向性・動き特性に基づく統合モデルや周波数解析に基づくもの,局所的な情 報量を周辺と比較するものなど様々な手法がある(第 1 章[26]-[32],第 2 章[23, 24],第 3 章[13],第 4 章[1, 3, 10]).これに加えて,人の顔や車などの認知的な要素を物体検出技術 により検出して顕著性マップに統合する,高次の特徴レベルを持った顕著性マップも研究 されている(第 1 章[33, 34],第 4 章[4]-[6]).低レベル特徴量を基にした顕著性マップを bottom up アプローチといい,高次の特徴レベルを付与した顕著性マップを top down アプ ローチという.さらに,生体情報を用いたアプローチとして実際の視線から低レベル特徴 の重みを求める手法もある(第 1 章[37]).本研究では,リーディングラインという特殊な 構造を持つ画像に対して,実際の人の視線が構造に導かれる空間バイアスを有することか ら,これを視線情報を利用して学習し統合する手法を提案する.リーディングラインのよ うな構造が視線を誘導するという認知心理学的に知られる知見を利用している(第 4 章[2]). なお,画像の構造情報を空間バイアスとして顕著性マップに付与する試みは,既存手法で は用いられていない. コミック作成. コミック作成. コミック作成. コミック作成. コミック作成においては,コミックらしいレイアウトを作成す る技術や話者を推定しセリフを配置する技術が必要になる.こうした工程では,各フレー ム画像における重要箇所の推定のほか,フレーム毎の重要度を定義し 1 ページのコミック におけるコマの大きさを決める必要がある.画像特徴を利用したアプローチでは,背景に コミックらしい効果線を付与して話者方向に吹き出しを向けてセリフを配置したり,多量 のマンガレイアウトデータベースから現在のシーンに最も適したレイアウトを検索して マッピングしたりするものがある(第 2 章[9, 10, 14]).生体情報を利用したものには,鑑賞 者の視線を学習して読みやすい位置にセリフを配置し視線の誘導効果を考慮したレイア ウトを作成するものや,視線が向けられている箇所ほど詳細に描きそれ以外を抽象的に描 くことで写真をコミック調に抽象化するものがある(第 1 章[36],第 2 章[26]).また,これ に関連し視線情報が内容理解(Scene Understanding)にどれ程迫れるかを検証する研究もな されている(第 1 章[16],第 2 章[27]).さらに,これに動画要約の効果を合わせて時空間的
に重要箇所を求めることで,自動でコミックを作成する研究もなされている.画像特徴を 利用した研究では,カメラワークを検出してそれを代表的なテンプレートレイアウトへマ ッピングする手法や,映画の脚本情報を利用して吹き出し形状にシーンに適した変形を付 けながら自動でコミック生成する手法,動画要約結果の時系列における重要度をコマのサ イズへマッピングしてコミック調にする手法などがある(第 2 章[11, 13, 22]).また,視覚 特性を用いたものには顔・唇認識技術と字幕情報を利用して話者を推定しセリフを配置し 動画要約技術によりシーン検出を行ってテンプレートレイアウトにマッピングすること により自動でコミック生成を行うものがある(第 2 章[12]).本研究では,人の興味を正確 にかつ簡易的に取得するために生体情報として視線を利用し,複数の鑑賞者の視線の振る 舞いの変化から動画要約を実現し,この振る舞いの変化をレイアウトへ反映させて,視線 位置により話者推定を行ってセリフ配置やトリミングを行う.すなわち,視線情報を時間 的・空間的・時空間的において活用することで,コミック作成における種々の問題を一貫 して解決する(第 2 章[18]-[20]).
Image Synthesis・・・Stitching.・ ... 静止画における画像処理の需要として,複数枚のシー
ムレスな画像合成技術が挙げられる.手法としては,局所的な小さなパッチの自己複製に よるテクスチャ合成技術や,画像の欠損部分に対する補間技術,また近年のカメラに搭載 されているようなパノラマ撮影技術などがある.シームレスな画像合成とは,すなわち人 の目に付きにくい箇所を見つけて複数枚の画像の合成面であるつなぎ目を目立たなくさ せることである.この実現のためには,空間的な重要度を求める必要があり,ピクセル値 の近傍との差分やエッジ情報がよく使われる.パノラマ撮影技術に代表される Stitching 手法では,各画像における位置合わせの自動化が求められる.これまでの研究では,局所 特徴量を算出し画像間の全特徴量の差分が最小となる位置を求めることで位置合わせを 行う(第 3 章[5, 10],[14]-[17],[19]-[21]).一方,人の意図を反映させた手法として,ユー ザのスケッチからユーザの意図を反映させたシーンを作り出す研究もある(第 1 章[23]). 最適構図探索. 最適構図探索. 最適構図探索. 最適構図探索. 写真を撮った後の画像は,構図や被写体位置に不満が残っても 再度撮り直したところでうまく撮れないものである.そこで,撮影後の画像における被写 体位置を自動で最適位置へ移動させる画像再構成技術がある.また,入力画像内における 構図が最適となる位置を検出しトリミングして再撮影する研究もなされている.こうした 研究では,画像空間上で被写体となる重要箇所を検出し構図位置の評価を行うことで最適 構図を計算する.画像特徴を用いた手法では,領域分割を繰り返すことで被写体を推定し, また直線成分となる領域分離線を求めて,これらの要素が構図として良い位置を計算する (第 3 章[4]).視覚特性を用いた手法では,被写体推定に顕著性マップ(Saliency Map)を利用 している(第 3 章[3, 7, 9]).また,人の意図を反映させた研究としては,視線を利用して被 写体推定を行い最適位置でトリミングを行う研究や,多量に用意した写真データベースに 対し人手で評価値を与え,写真に対する評価の与え方を学習する手法などがある(第 3 章 [1, 2]).本研究における Auto Framing 技術は,Stitching 技術と最適構図探索技術の両方を 必要とする.人の意図を反映させるため,ユーザのカメラ移動を利用し局所画像特徴量の 時系列合成によって被写体を推定し,画像特徴の分布形状からなる構造情報と顕著性マッ プ(Saliency Map)を利用して構図の美的な評価を行う.これまでの研究と違い,重要度の 推定の要素として時空間情報を利用することで,ユーザの意図の反映を実現している.
Video Retargeting.... Image Retargeting 技 術 を 動 画 へ 拡 張 し た 研 究 を Video Retargeting という.Image Retargeting と同様,コンテンツの中身が変わらないようにして 動画サイズを自在に変更することを目的としている.この実現には,コンテンツにおける 時空間的な重要箇所の類推が必須である.例えば,あるフレーム画像における顕著なオブ ジェクトや構造情報を空間的に推定し,それが前後のフレームにおいてシームレスにつな がるように時間方向に対しても補正を掛ける.こうして時空間的な重要度を推定したのち, 大きく分けて Cropping・Seam Carving・Warping という 3 つのアプローチによって Video Retargeting を実現する.まず,Cropping 技術を利用した手法では,重要箇所を避けて動画 を望ましいサイズへ切り取ることで Video Retargeting を行う.Seam Carving を利用した手 法では,人の目に付きにくいような行・列を探索し,削除・挿入をしながらサイズを変更 させることで Retargeting を実現する.Warping を利用した手法では,画面にメッシュを張 り,重要でない所を大きく変化させてサイズを変えることで重要箇所ほど変化しないよう な Video Retargeting が実現できる(第 1 章[7]-[10]).
1.2
研究概要
研究概要
研究概要
研究概要
本研究では対象を画像系列とし,情報の抽出と要約結果の提示という要約技術の満たす べき要素に対して,人の自然な振る舞いという新しい概念を取り込むことで情報の抽出を 行い,また要約結果の提示にあたり美的に整形が取れているかを考慮してユーザに提示す るシステムを提案する.要約技術の実現には関連要素技術で述べたように,時間・空間・ 時空間における重要度の推定が必要である.本研究では,視線という共通の解決法を利用 し,簡易的でありながら正確な人の興味を反映した要約技術の実現を目指す.1.2.1 フィルムコミックの自動生成
フィルムコミックの自動生成
フィルムコミックの自動生成
フィルムコミックの自動生成
はじめに,映像コンテンツから鑑賞者の視線情報を利用して自動でコミック調に合成す る技術を提案する(図 1.1 参照).フィルムコミックとは,主に CG やアニメーションなど の映像コンテンツをコミック調画像に変換したものである.従来,フィルムコミックの作 成は専門家が人手で以下の処理を行っていた.すなわち,映像内に含まれる膨大な数のフ レーム画像の中からシーンを代表するような重要なものを選出し,シーンの内容に応じた レイアウトを設計し,レイアウトの形状に合わせて選択したフレーム画像を加工し,セリ フのあるシーンではセリフを配置して完成する.以上の工程において,重要フレームの選 出は絵コンテに示されることが多いようにシーンの内容をよく描画するように選ばなく てはならず,またフレーム画像の加工やセリフの配置は画像内における重要箇所を切り取 ったり隠したりしてしまわないようにして実現しなくてはならない.さらに,レイアウト 設計はシーンの内容をよりわかりやすく内容が把握しやすいように整形する必要がある. しかし,重要フレームや画像空間内の重要箇所の検出には,映像作品そのものの理解が不 可欠であり,画像処理技術のみからこれを実現することは難しい.そこで本研究では,人 の興味を時空間的に抽出することで,以下の処理の自動化を実現した.1)映像コンテンツ から人の興味を引くような,重要なフレーム画像の選出.2)見栄えの良さだけでなく,内 容が把握しやすいレイアウト設計.3)重要箇所を切り取らず,元の構図を維持したトリミ ング.4)重要箇所を隠さず,読みやすく加工したセリフ配置. 図 1.1 フィルムコミックの自動生成の概念図鑑賞者の興味を捉えるための手段として,本研究では視線情報を利用している.まず, 1)に関して複数人の鑑賞者の視線位置を視線追跡装置によって取得し,視線移動における 特異なパターンを抽出する.このパターンが生じるシーンは,映像コンテンツ内に変化を 持つ箇所であることが予備実験の結果わかった.そこで,鑑賞者の視線移動のパターンか ら重要フレームの選出を行うことで,鑑賞者の興味を反映した動画要約を実現する.2) に関して,鑑賞者の視線情報は時間的な移動情報と空間的な分布情報を持つ.そこで,実 際のコミックにみられるレイアウト作成法を視線の時空間情報と対応付け,鑑賞者の興味 を反映するような内容が把握しやすいレイアウトを自動生成する.3),4)に関して,視線 情報の時空間分布と映像コンテンツの持つ局所画像特徴を統合することで,画像空間にお ける情報を持つ領域を確率分布として表現し,これを利用して自動で最適な画像の編集を 行う.これにより,視線移動という人の自然な振る舞いから重要情報の抽出を行いかつこ れを最適に加工して提示する,フィルムコミックの自動生成技術を実現した.
1.2.2 オートフレーミングカメラ
オートフレーミングカメラ
オートフレーミングカメラ
オートフレーミングカメラ
次に,撮影時におけるユーザのカメラ移動から被写体を発見し,最適構図を探索して自 動撮影をするオートフレーミングを実現する手法を提案する(図 1.2 参照).オートフレー ミングとは,被写体を発見し被写体位置が最適な位置となる構図を求めて自動で撮影する 技術のことを指す.本研究では,オートフレーミングの実現に際して以下の手法を提案す る.まず,予備実験の結果,撮影者は写真を撮る前に構図を決めかねてカメラを移動させ ることがわかった.そこで,1)このときのカメラ移動から,撮影者が何を撮ろうとしてい るのか,その主観的な被写体を推定する.そして,2)被写体位置が構図として良いかを調 べるために三分割法というカメラ撮影におけるヒューリスティックなルールを用いて客 観的に美観評価を行う. 図 1.2 オートフレーミングの概念図 撮影者の興味を捉えるための手段として,本研究では撮影者のカメラ移動を利用してい る.1)に関して,カメラ移動から被写体を推定するために,まずカメラ移動を動画として とらえ一定間隔でサンプリングしてくることによって,ユーザのカメラ移動の経緯に関す る情報を得る.そして,取得したサンプリングフレームに対して局所画像特徴を求め各フ レーム間における画像の相対的な位置の対応を取り,すべてのサンプリングフレームを合成する.重要な被写体はカメラ移動に対してどのフレームにも入っていると仮定し,時系 列に沿って局所画像特徴の出現頻度を求めることで撮影者の主観的な被写体推定を試み る.また,構図を決めるために被写体の構造情報も重要な要素として考えらえるため,局 所画像特徴の空間的な分布を求めて被写体構造を抽出する.これらを統合して被写体情報 の確率分布を得る.2)に関して,求めた被写体情報の確率分布を基に最適なトリミング位 置とスケールを探索する.ここで,重要な被写体ほど三分割法の線上・交点上によく乗る ように評価することで,写真工学における一般的な構図が満たされる.これにより,カメ ラ移動という撮影者にとって自然な振る舞いから重要な被写体情報の抽出を行いかつこ れを最適に加工して提示する,オートフレーミング技術を実現した.
1.2.3 リーディングライン効果を付与した顕著性マップ
リーディングライン効果を付与した顕著性マップ
リーディングライン効果を付与した顕著性マップ
リーディングライン効果を付与した顕著性マップ
最後に,静止画や動画において人の目を引く箇所を画像処理的に求める顕著性マップの 要素として,特に写真工学で用いられるリーディングライン効果を付与した顕著性マップ の作成技術を提案する(図 1.3 参照).リーディングライン効果とは,空間上に直線成分や 線群が一点に収束するように構成された場面では,人の目はリーディングラインの収束先 に引かれやすいという経験則である.本研究では,検証実験により視線はリーディングラ インの収束先に誘導されることを示した.そこで,リーディングラインを含む画像におい て既存の顕著性マップとリーディングラインの重みとを被験者の視線情報を用いて学習 して求め,リーディングラインを付与した顕著性マップを実現した. 図 1.3 リーディングライン効果を付与した顕著性マップの概念図顕著性マップにリーディングラインを考慮する試みはこれまでになされておらず [26]-[34],既存手法を用いたところ,実際の視線位置とは程遠い顕著箇所を推定した.提 案手法では,様々なリーディングラインを含む画像について被験者の視線位置を用いて, リーディングラインの収束先を示す箇所と既存手法の顕著箇所の重みを学習した.これに よって,未知の画像に対してもリーディングラインの収束箇所とそれ以外の顕著箇所を考 慮して,より実際の視線を引く領域に近い顕著箇所を空間的に推定することが可能となる. また,これを基にして最適構図を求める問題を解決することで,より人の興味を反映した 構図結果が得られることが期待できる.