ISSN -
0258-2724 DOI
:10.35741/issn.0258-2724.54.3.22
Research article
A
N
EW
T
RAINING
M
ETHOD BASED ON
B
LACK
H
OLE
A
LGORITHM
FOR
C
ONVOLUTIONAL
N
EURAL
N
ETWORK
Sinan Q. Salih 1
Applied Computational Civil and Structural Engineering Research Group, Ton Duc Thang University, Ho Chi Minh City, Vietnam, [email protected]
2 Computer Science Department, College of Computer Science and Information Technology, University of
Anbar, Ramadi, Iraq
Abstract
One of the commonly used neural networks currently is the Convolutional Neural Networks (CNN). They have different applications but have recently been proven useful in deep learning. With its continued growth in the more convoluted domains, the difficulty of its training process is equally increasing. As such, several hybrid algorithms have been developed and implemented to solve this problem. This paper proposes the use of the Black Hole (BH) algorithm to train CNN in a bid to improve its performance by avoiding local minima entrapment. The performance of the new training algorithm was compared to the currently used training algorithms in terms of the convergence analysis, computational accuracy and cost using a benchmark problem specific to Optical Character Recognition (OCR) applications.
Keywords: Training Algorithm, Convolutional Neural Network (CNN), Black Hole Algorithm, Optimization,
Computational Intelligence. 摘要 : 目前常用的神經網絡之一是卷積神經網絡(CNN)。 它們有不同的應用,但最近被證明在深度學習 中很有用。 隨著其在更複雜的領域的持續增長,其培訓過程的難度也同樣增加。 因此,已經開發並實現 了幾種混合算法來解決該問題。 本文提出使用黑洞(BH)算法來訓練 CNN,以通過避免局部最小捕獲來改 善其性能。 使用光學字符識別(OCR)應用特有的基準問題,在收斂分析,計算精度和成本方面將新訓練 算法的性能與當前使用的訓練算法進行比較。 关键词: 訓練算法,卷積神經網絡(CNN),黑洞算法,優化,計算智能。
I. I
NTRODUCTIONThe framework of a simple Artificial Neural Network (ANN) is made up of an input layer and an output layer of neurons [1]. The concept of deep learning (DL) was introduced owing to the need for more intermediate hidden layers in the ANN [2]. As a complex form of ANN, DL uses several layers with nonlinear processing units and depends on the concept of supervised or
unsupervised learning of several feature levels or data representations [3]. The first idea of a working algorithm for deep feedforward multilayer perceptrons was introduced in 1965 [4] but with time, DL has undergone several improvements and has been useful in several fields.
The CNN has been recently presented as the perfect solution towards achieving a better
recognition accuracy. There are different areas of DL, including Neural Networks, Pattern Recognition, Artificial Intelligence, Optimization, Graphical Modeling, and Signal Processing [5], [6], [27], [28]. However, it is computationally complicated to design a perfect CNN architecture for specific tasks as evidenced in the previous research efforts. Thus, there are different architectures for CNN implement, for instance, the LeNet architecture which was originally developed in 1998 by LecCun et al [7], [8] but later implemented for OCR and character recognition in documents. Similarly, the CNN can be implemented using the ConvNet architecture which uses 7 layers, with each layer having a specific role which will be described later. Additionally, an optimal performance may not be achievable if the same architecture is applied on several tasks; hence, the CNN architecture must be specified for specific tasks, and this will require serious research effort as several types of machine learning tasks exists in the industries [9].
Despite the robustness of the CNNs, some of its parameters still need to be optimized; such parameters can be roughly categorized into those for learning and those for network configurations. The network configuration has been reported to influence the recognition performance of CNNs [10], [11]. Several studies have strived to provide the theoretical basis for the better performance of CNNs, but yet to provide the strategies for optimizing its parameters. This implies a shift in the concepts from visual features extraction to network structure configuration and parameters optimization [11].
The Black Hole algorithm was recently invented by [12] as one of the meta-heuristic optimization frameworks which was inspired by the behavior of the black hole while pulling its surrounding stars. The BH algorithm was inspired by the nature and interaction of the BH with its surrounding solar bodies. Assume a set of stars toepresent the total number of solutions in a given iteration and each star is susceptible to the pulling force of the BH ( represents the best solution). In the next iteration, the new set of solutions can be generated by moving the surrounding stars toward the BH. As the star gets closer to the BH at a pre-determined aistance, it will be engulfed by the BH and the other stars randomly be generated immediately. This enable the algorithm to launch an exploration task in the unsearched areas within the solution space instead of wasting the optimization time in the solution space that has already been explored.
The BH algorithm has proven successful in solving data clustering problems even though the evaluation performance showed this approach to perform better than the other meta-heuristics in optimization processes [13].
In this paper, the major contribution is the proposal of a novel training algorithm called BH-CNN for the training of the BH-CNN model based on the BH algorithm. Here, the BH algorithm is used to establish the optimal CNN parameters. The optimization performance of these algorithms was compared using several criteria such as their calculated errors and accuracy. This study used the Mixed National Institute of Standards and Technology (MNIST) dataset which is a dataset of handwritten digital images. In this dataset, the digital size of the images is 28 x 28 pixels; it consists of 70,000 images out of which 60,000 are used to train the model while 10,000 are for the model testing.
The arrangement of this paper is as follows: Section 2 provides the basics of the CNN and BH models while Section 3 explained the proposed BH-CNN algorithm. Section 4 presents the results of the analysis of the proposed BH-CNN algorithm while section 5 and presents the limitations of the proposed work, and concludes the paper.
II. P
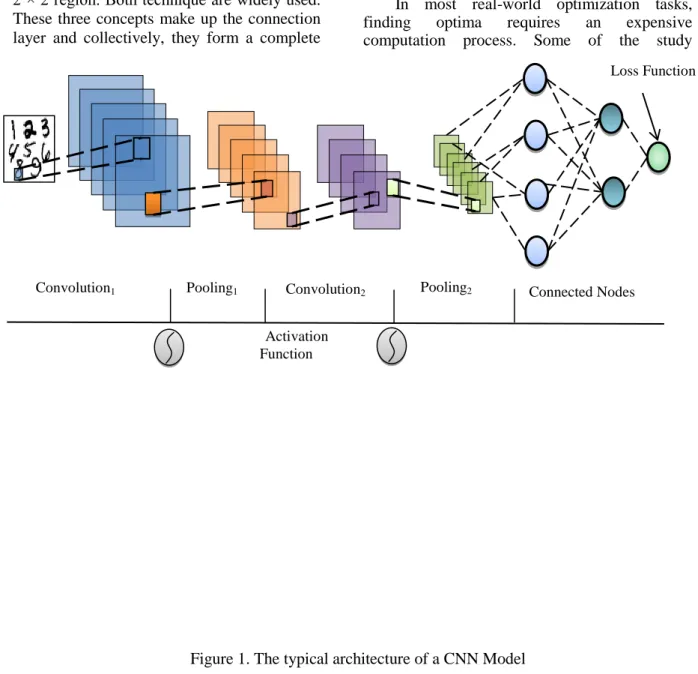
RELIMINARIESA. Convolutional Neural Networks (CNN) Kelley [14] introduced DL in 1960 based on the concept of an output becoming the input in the next iteration. The CNN is a type of DL network which is basically comprised of several convolution layers, followed by the pooling layers for the reduction of the size of the received input. The pooling layers are followed by the ReLU layers which enhances the outputs‟ non-linearity. The last layer is the Fully Connected Layer which uses the Softmax activation function for the control of the output range. The CNN can combine the advantage of the correlation between the adjacent neurons; it has 3 basic concepts which are local receptive fields, shared weights, and pooling [15], [16]. The typical architecture of a CNN is depicted in Figure 1.
a. Local receptive fields (LRF): This is a small sized input region for composing one neuron in the first hidden layer. When the LRF is slid across all the input image, a different hidden neuron which contains the overall first hidden layer is made.
b. Shared weights and biases: This feature detects similar features from different input image location. Therefore, the feature map is designated to the map between the input and hidden layers while the weights are called the shared weights and biases, the shared biases. The filter or kernel are also defined by the shared weights and biases. Image recognition requires more than one feature map to detect several features, so, several different feature maps can compromise the convolutional layer. c. Pooling layers: The pooling layer follows the convolutional layers; it analyzes the information received from the convolution layer. Max – pooling is among the pooling procedures which involves maximum neuron activation. L2 pooling takes the square root of the sum of the squares of the activations in the 2 × 2 region. Both technique are widely used. These three concepts make up the connection layer and collectively, they form a complete
CNN architecture
Several convolution, activation function, and pooling stages are first combined before introducing one or more fully connected layers. A loss function is adopted in the model output to measure the performance in terms of the difference between the CNN‟s output and a true image label (i.e., the loss). The CNN is mainly trained to minimize the loss function and this is usually done using stochastic gradient descent which is an optimization technique that first estimates the loss function gradient based on the weight of each edge in the network before updating the weights based on the computed gradient [15].
B. Black Hole Algorithm (BH)
In most real-world optimization tasks, finding optima requires an expensive computation process. Some of the study
Figure 1. The typical architecture of a CNN Model
Convolution1 Pooling1 Convolution2 Pooling2 Connected Nodes
Activation Function
limitations such as computation resource constraints and project time requirements have necessitated the need to make the optimization process less complicated and rapid [17]–[19]. Most of the standard optimization frameworks require several function evaluations and usually produce satisfactory results due to their inherent special information transfer mechanism of using several first-choice solutions in a range of fitness evaluations[20]. The need to evaluate each candidate resolution makes these processes to demand much computing resources and execution time. Consequently, efforts have been devoted to the development of efficient optimization algorithms for the evaluation of several functions. Several novel approaches have been proposed in recent times with some satisfactory performances with fewer function evaluations [21]–[23].
The BH algorithm was developed based on the inspiration from the BH phenomenon. The basic concept of the BH algorithm is simply a region of space with much mass focused on it such that nothing near it can escapes its gravitational pull. Once anything is pulled into the BH, it is forever eliminated from existence. The BH algorithm is made up of two parts, namely, the migration of the stars and the re-initialization of stars that had crossed the event horizon around the BH. The working principle of the BH algorithm is as follows: First, the + 1
stars, (where =
population size), are initialized randomly in the solution space before evaluating their fitness. The one with the best evaluation function is called the black hole . Being that the BH is static, it
cannot move until the other stars finds a better solution. The number of individuals that search for the optimum is equal to . Every star, in each generation, moves towards the BH based on the following equation:
(1) where rand = a random number in the range [0,1]. In the BH algorithm, any star that its distance to the BH is less than the event horizon will disappear. The radius (R) of the event horizon (R) is given by:
(2)
where and represent the fitness values of the BH and the ith star. represent the number of stars (individual solutions). Whenever R is greater than the distance between a BH (best solution) and an individual solution, that individual solution will collapsed, giving way for the creation of a new individual which will be randomly distributed in the search space. The structure of BH is simple and easy to implement; it is also a parameter-less algorithm. In all the runs, the BH can converge to the global optimum where other heuristics can be trapped in local optimum [12], [13], [24]. The CNN was trained in this study using BH algorithm for two reasons, first is its simple structure and ease of implementation, and second is its parameter-less nature.
III. T
HEP
ROPOSEDA
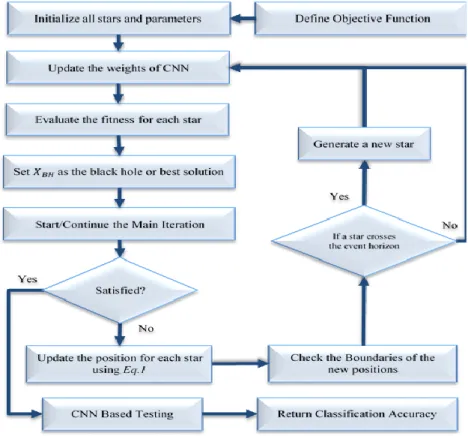
LGORITHMAs mentioned earlier, the main contribution of this paper is to develop a training algorithm for CNN, meaning that finding the best values for the parameters of CNN. In this paper, Black Hole algorithm is used as the training algorithm, for two reasons: first, it has a simple structure, while the second reason, it does not have any controlling parameters. The proposed training algorithm is called “BH-CNN”, the flowchart of BH-CNN is given in figure 2 below.
The flowchart illustrated the main steps of the BH-CNN, however, there are three main steps need to be explained in details. These steps are explained in the next subsections.
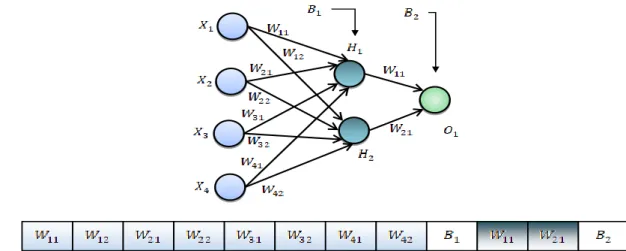
A. The Encoding of the Stars
A CNN is composed of two basic parts of feature extraction and classification. Feature extraction includes several convolution layers followed by max-pooling and an activation function. The classifier usually consists of fully connected neural network layers. In the proposed method, the weights set of the neural network is considered as the structure of each star. For this purpose, a vector of real values has been used. This vector contains all the weights of the neural network. A schematic representation of a star to train neural network is shown in figure 3.
B. Initialization of the Stars
In terms of the population initialization, after the size of the population is set up, stars are randomly created until reaching the population size. Each star is initialized using the a uniform distribution equation, as follows:
(3) Where represents the positions of a star, while and represent the values of upper bound and lower bound respectively. Finally, represents a
random value in range [0, 1]. C. Fitness Function
General terms and terms in the plural, as well as multivalent concepts should not be used in the keywords. Be careful in the use of abbreviations: only abbreviations that have been well established in the field of research can suit. These keywords will be used for indexing.
(4)
The value of the classification error depends on the correctly classified samples, meaning that, The CNN is used to classify the samples based on the values of each star.
The pseudocode of BH-CNN is given in the following figure.
IV. R
ESULTSThe data set used in this paper is the MNIST (Modified National Institute of Standards and Technology) data which it divided over two parts. First one contains 60,000 images used for training process. These images are collected and scanned from handwriting of 250 people, half of them were US Census Bureau employees, and the other half comes from high school students. All these images are grayscale and 28 x 28 pixels‟ size. Second part of MNIST data set is 10,000 images used in the test process with the same properties. But for performance issue these images come from different 250 people (than those in the training data set) although they still a group split between Census Bureau employees and high school student. This different of samples give us confidence that the system will recognize digit form handwritten of people whose writing didn‟t see in training process of the system [16].
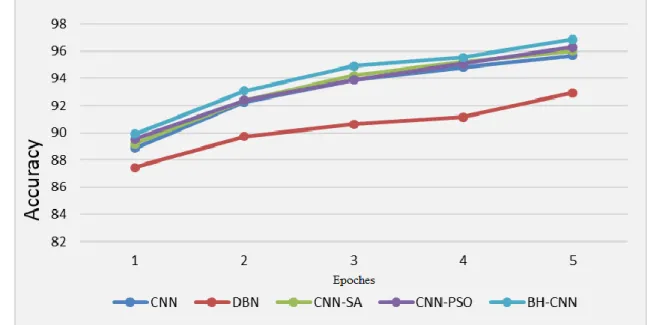
The population size used in this study is equal to 30 stars, while the maximum number of epochs ( is equal to 20. The proposed method is compared against four main deep learning models, such as standard CNN, Deep Belief Network (DBN), Convolutional Neural Network based Simulating Annealing (CNN-SA)[25], and Convolutional Neural Network based Particle Swarm Optimization (CNN-PSO)[26]. Table 1 below displays the results of all models with only four epochs in terms of the classification accuracy.
From Table 1, it is obvious that the performance of the models are almost the same. However, the proposed BH-CNN has showed better performance than the other deep learning models. Although the CNN-PSO algorithm showed a very good performance and ranked in the second place with low difference as compared to the BH-CNN, but the PSO algorithm contains three controlling parameters (i.e., cognitive parameter c1, social parameters c2, and inertia
weight w), these parameters require optimal tuning which is another optimization problem. Therefore, the simple structure of BH algorithm with no tuning problem provides a machine learning model (i.e., classifier) with less complexity than the other models, additionally, the error also exhibit the similar behavior. Figure 5 and Figure 6 illustrate the performance accuracy and the error rate for all models
respectively.
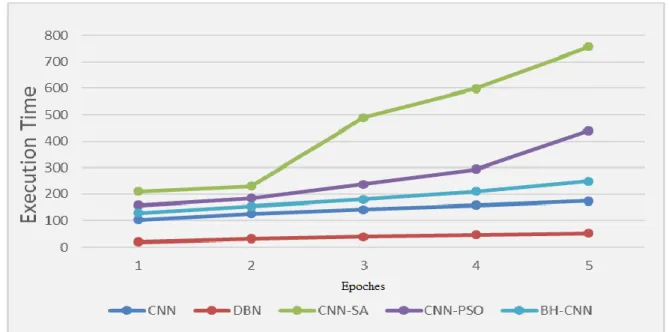
In terms of the execution time, DBN required less time due to the training process in DBN used contrastive divergence which is very fast. It is worth to mention that BH-CNN ranked in the third place after the DBN and the standard CNN, because of the BH algorithm requires addition iterations as well as the event horizon calculations. Figure 7 portrays the execution time comparison.
V. L
IMITATIONS ANDF
UTUREW
ORK This paper proposed a new training algorithm based on Black Hole (BH) algorithm for Convolutional Neural Network (CNN). The proposed classification model has been evaluated based on a well-known hand-written dataset, which is Mixed National Institute of Standards and Technology (MINIST). Despite the good performance and classification accuracy of the proposed mode, there are two main limitations in this work. First, the exploration part of BH algorithm depends mainly on the eliminating of the stars and initialized them again with different values; which leads to increase the chances of falling in the local optima due to the exploitation ability of the algorithm is more than the exploration. The second limitation is that the BH algorithm has been initialized using the equation of uniform distribution; which leads to start from a small range of possible position.In future studies, the exploration ability of
Table 1. The comparison of the proposed BH-CNN with other models Models
Epochs
Epoch = 1 Epoch = 2 Epoch = 3 Epoch = 4 Epoch = 5
CNN 88.87 92.25 93.9 94.81 95.68 DBN 87.46 89.72 90.64 91.14 92.93 CNN-SA 89.18 92.38 94.2 95.19 96.04 CNN-PSO 89.52 92.38 93.91 95.08 96.31 BH-CNN 89.91 93.08 94.91 95.53 96.88 BH-CNN Algorithm
Input: MINIST dataset, #Epoch, #PopSize, Upper, Lower Output: Best Solution XBH
Procedure:
Initialize all the stars X in the population via eq.3
Update the weights and biases of CNN using each star in the population Evaluate the fitness value of each star Xi in the population via eq.4
Set the best star in the population as Black Hole XBH
While itr <= MaxItr
For each star Xi in the population
Update the position of each star Xi via eq.1
Check the boundaries of each star Xi
Update the weights and biases of CNN using star Xi in the population
Evaluate the fitness value of the star Xi in the population via eq.4
For
Calculate the event horizon via eq.2
For each star Xi in the population
If Xi crosses the event horizon Then
Remove the star Xi
Generate a new star via eq.3 End If
End For
Set the best star in the population as Black Hole XBH
Loop
Return XBH
BH algorithm can be enhanced by using different techniques (such as Levy Flight or Chaotic Maps) in the movement of the stars towards the black hole (i.e., the current best solution). Moreover,
The proposed classification model can be used for classifying the data of the cancer disease such as Breast Cancer, Tumor Cancer, etc.
VI. C
ONCLUSIONIn machine learning field, deep learning models have attracted the researchers from different fields due to its ability to recognize the patterns in classification problems. One of the
most well-known deep learning models is the Convolutional Neural Networks (CNNs). The main structure of CNN consists of two parts, the feature extraction part, and the neural network
parts. In this paper, the second part of the CNN (i.e., the neural network) is trained via a recently developed nature-inspired algorithm called Black Hole (BH) algorithm. The proposed model attained a very good results (96.88) as compared to other deep learning models based on MNIST dataset by five epochs only. In conclusion, Black hole algorithm can be used as an alternative Figure 5. The classification accuracy for all models
training algorithm for CNN. Moreover, the proposed model can be applied to different case studies such as classifying the data of cancer disease.
R
EFERENCES[1] W. S. McCulloch and W. Pitts, “A logical calculus of the ideas immanent in nervous activity,” Bull. Math. Biophys., 1943. [2] G. E. Hinton, S. Osindero, and Y.-W. Teh,
“A fast learning algorithm for deep belief nets,” Neural Comput., vol. 18, no. 7, pp. 1527–1554, 2006.
[3] N. B. Karayiannis and G. W. Mi, “Growing radial basis neural networks: Merging supervised and unsupervised learning with network growth techniques,” IEEE Trans. Neural networks, vol. 8, no. 6, pp. 1492–1506, 1997.
[4] A. Ivakhnenko, “Cybernetic predicting devices.”
[5] T. Dhieb, W. Ouarda, H. Boubaker, and A. M. Alimi, “Deep neural network for online writer identification using Beta-elliptic model,” in Proceedings of the International Joint Conference on Neural Networks, 2016.
[6] L. Haddad, T. M. Hamdani, W. Ouarda, A. M. Alimi, and A. Abraham, “An Adaptation Module with Dynamic Radial Basis Function Neural Network Using Significance Concept for Writer Adaptation.,” J. Inf. Assur. Secur., vol. 12, no. 1, 2017.
[7] Y. LeCun, L. Bottou, Y. Bengio, and P.
Haffner, “Gradient-based learning applied
to document recognition,” Proc. IEEE, 1998.
[8] Y. LeCun and M. Ranzato, “Deep learning tutorial,” in Tutorials in International Conference on Machine Learning (ICML’13), 2013, pp. 1–29. [9] B. Wang, Y. Sun, B. Xue, and M. Zhang,
“Evolving Deep Convolutional Neural Networks by Variable-Length Particle Swarm Optimization for Image Classification,” in 2018 IEEE Congress on Evolutionary Computation, CEC 2018 - Proceedings, 2018.
[10] K. Jarrett, K. Kavukcuoglu, M. Ranzato, and Y. LeCun, “What is the best multi-stage architecture for object recognition?,” in Proceedings of the IEEE International Conference on Computer Vision, 2009.
[11] T. Yamasaki, T. Honma, and K. Aizawa, “Efficient Optimization of Convolutional Neural Networks Using Particle Swarm Optimization,” in Proceedings - 2017 IEEE 3rd International Conference on Multimedia Big Data, BigMM 2017, 2017. [12] A. Hatamlou, “Black hole: A new heuristic optimization approach for data clustering,” Inf. Sci. (Ny)., vol. 222, pp. 175–184, 2013.
[13] S. Kumar, D. Datta, S. Kumar Singh, A. T. Azar, and S. Vaidyanathan, “Black hole algorithm and its applications,” Stud. Comput. Intell., 2015.
[14] H. J. Kelley, “Gradient Theory of Optimal Flight Paths,” ARS J., vol. 30, no. 10, pp. 947–954, 1960.
[15] M. Liu, J. Shi, Z. Li, C. Li, J. Zhu, and S. Liu, “Towards Better Analysis of Deep Convolutional Neural Networks,” IEEE Trans. Vis. Comput. Graph., 2017.
[16] J. Yosinski, J. Clune, A. Nguyen, T. Fuchs, and H. Lipson, “Understanding neural networks through deep visualization,” arXiv Prepr. arXiv1506.06579, 2015.
[17] H. A. Ahmed, M. F. Zolkipli, and M. Ahmad, “A novel efficient substitution-box design based on firefly algorithm and discrete chaotic map,” Neural Computing and Applications, 2018.
[18] A. A. Alzaidi, M. Ahmad, H. S. Ahmed, and E. Al Solami, “Sine-Cosine Optimization-Based Bijective Substitution-Boxes Construction Using Enhanced Dynamics of Chaotic Map,” Complexity, vol. 2018, 2018.
[19] A. M. Taha, S.-D. Chen, and A. Mustapha, “Bat Algorithm Based Hybrid Filter-Wrapper Approach,” Adv. Oper. Res., vol. 2015, 2015.
[20] A. M. Taha, S.-D. Chen, and A. Mustapha, “Natural Extensions: Bat Algorithm with Memory.,” J. Theor. Appl. Inf. Technol., vol. 79, no. 1, pp. 1–9, 2015.
[21] Ogudo, K.A.; Muwawa Jean Nestor, D.; Ibrahim Khalaf, O.; Daei Kasmaei, H. A Device Performance and Data Analytics Concept for Smartphones‟ IoT Services and Machine-Type Communication in
Cellular Networks. Symmetry 2019, 11,
593.
[22] S. Q. Salih, A. A. Alsewari, B. Al-Khateeb, and M. F. Zolkipli, “Novel Multi-swarm Approach for Balancing Exploration and Exploitation in Particle Swarm Optimization,” in Recent Trends in Data Science and Soft Computing, 2019, pp. 196–206.
[23] Z. A. Al Sudani, S. Q. Salih, Z. M. Yaseen, and others, “Development of Multivariate Adaptive Regression Spline Integrated with Differential Evolution Model for Streamflow Simulation,” J. Hydrol., pp. 1–15, 2019.
[24] A. P. Piotrowski, J. J. Napiorkowski, and P. M. Rowinski, “How novel is the „novel‟ black hole optimization approach?,” Inf. Sci. (Ny)., 2014.
[25] L. M. R. Rere, M. I. Fanany, and A. M. Arymurthy, “Simulated Annealing
Algorithm for Deep Learning,” in Procedia Computer Science, 2015. [26] A. R. Syulistyo, D. M. J. Purnomo, M. F.
Rachmadi, and A. Wibowo, “Particle swarm optimization (PSO) for training optimization on convolutional neural network (CNN),” J. Ilmu Komput. dan Inf., vol. 9, no. 1, pp. 52–58, 2016.
[27] N. P. Vinogradova, and A. N. Popov, "Methodological Basis of Economic Decision-Making," Entrepreneurship and Sustainability Issues, vol. 6, no. 4, pp. 1798–1806, 2019.
[28] T. V. Pogodina, V. G. Aleksakhina, V. A. Burenin, T. N. Polianova, and L. A. Yunusov, "Towards the Innovation-Focused Industry Development in a Climate of Digitalization: The Case of Russia," Entrepreneurship and Sustainability Issues, vol. 6, no. 4, pp. 1897-1906, 2019.
参考文:
[1] W. S. McCulloch 和 W. Pitts,“神經活動內 在思想的邏輯演算”,Bull。數學。生 物物理學,1943 年。
[2] G. E. Hinton,S。Osindero 和 Y.-W. Teh, “深度信念網的快速學習算法”,神經 計算,第一卷。 18,不。 7,pp.1527-1554, 2006。 [3] N. B. Karayiannis 和 G. W. Mi,“增長徑向 基神經網絡:將監督和無監督學習與 網絡增長技術相結合”,IEEE Trans。 神 經 網 絡 , 第 一 卷 8 , 不 。 6 , pp.1492-1506, 1997。 [4] A. Ivakhnenko,“控制論預測裝置”。 [5] T. Dhieb,W。Ouarda,H。Boubaker 和 A. M. Alimi,“使用 β 橢圓模型進行在 線作家識別的深度神經網絡”,參見 “ 國 際 神 經 網 絡聯 合 會議 論 文 集 ” , 2016 年。 [6] L. Haddad,T。M. Hamdani,W。Ouarda, A。M. Alimi 和 A. Abraham,“具有動 態徑向基函數的適應模塊神經網絡使 用寫作適應的重要性概念。”,J。Inf。 亞述。 Secur。,vol。 12,不。 2017 年1 月 1 日。 [7] Y. LeCun,L。Bottou,Y。Bengio 和 P. Haffner,“基於梯度的學習應用於文檔 識別”,Proc。 IEEE,1998。 [8] Y. LeCun 和 M. Ranzato,“深度學習教程”, “國際機器學習會議教程”(ICML'13), 2013 年,第 1-29 頁。 [9] B. Wang,Y。Sun,B。Xue 和 M. Zhang, “用可變長度粒子群優化進行圖像分類 的深度卷積神經網絡的演化”,2018 年 IEEE 進化計算大會,CEC 2018 年 - 會 議錄,2018 年。 [10] K. Jarrett , K 。 Kavukcuoglu , M 。 Ranzato 和 Y. LeCun,“物體識別的最 佳多階段架構是什麼?”,參見 IEEE 國際計算機視覺會議論文集,2009 年。 [11] T. Yamasaki,T.Honma 和 K. Aizawa, “使用粒子群優化的捲積神經網絡的有 效優化”,在 Proceedings - 2017 IEEE 第 三 屆 多 媒 體 大 數 據 國 際 會 議 上 , BigMM 2017 年,2017 年。 [12] A. Hatamlou,“黑洞:一種新的數據聚類 啟 發 式 優 化 方 法 ” , Inf 。 科 學 。 (Ny ) 。 , vol 。 222 , pp.175-184, 2013。 [13] S. Kumar,D。Datta,S。Kumar Singh, A。T. Azar 和 S. Vaidyanathan,“黑洞
算法及其應用”,Stud。 COMPUT。 Intell。,2015。 [14] H. J. Kelley,“最佳飛行路徑的梯度理論”, ARS J.,vol。 30,不。 10,pp.947-954, 1960。 [15] M. Liu,J。Shi,Z。Li,C。Li,J。Zhu 和 S. Liu,“邁向更好的深度卷積神經 網 絡 分 析” , IEEE Trans 。 可 見 。 COMPUT。圖。,2017。 [16] J. Yosinski,J。Clune,A。Nguyen,T。 Fuchs 和 H. Lipson,“通過深度可視化 理 解 神 經 網 絡 ” , arXiv Prepr 。 arXiv1506.06579, 2015。 [17] H. A. Ahmed , M 。 F. Zolkipli 和 M. Ahmad,“基於螢火蟲算法和離散混沌 映射的新型高效替換盒設計”,神經計 算和應用,2018。 [18] A. A. Alzaidi , M 。 Ahmad , H 。 S. Ahmed 和 E. Al Solami,“使用增強動 力學混沌映射的基於正弦餘弦優化的 雙射置換 - 盒子構造”,複雜性,第一 卷。 2018 年,2018 年。
[19] A. M. Taha,S.-D。 Chen 和 A. Mustapha, “基於蝙蝠算法的混合濾波器 - 包裝器 方法”,Adv。歌劇院。 Res。,vol。 2015 年,2015 年。
[20] A. M. Taha,S.-D。 Chen 和 A. Mustapha, “自然延伸:蝙蝠算法與記憶。”,J。 Theor。申請天道酬勤。 Technol。, vol。 79,不。 1,pp.1-9,2015。 [21] Ogudo,K.A。; Muwawa Jean Nestor,
D 。 ; Ibrahim Khalaf , O 。 ; Daei Kasmaei,H。智能手機在蜂窩網絡中 的物聯網服務和機器類通信的設備性 能和數據分析概念。 Symmetry 2019, 11, 593。 [22] SQ Salih,AA Alsewari,B。Al-Khateeb 和MF Zolkipli,“用於粒子群優化中的 平衡探索和開發的新型多群方法”,最 近的數據科學和軟計算趨勢,2019 年, pp。 196-206。
[23] Z. A. Al Sudani,S。Q. Salih,Z。M. Yaseen 等人,“用於流動模擬的多元自 適應回歸樣條與差分進化模型相結合 的發展”,J。Hydrol。,第 1-15 頁, 2019 年。 [24] A. P. Piotrowski,J。J. Napiorkowski 和 P. M. Rowinski,“小說'黑洞優化方法是 多麼新穎?”,Inf。科學。 (Ny)。, 2014。 [25] L. M. R. Rere,M。I. Fanany 和 A. M. Arymurthy,“用於深度學習的模擬退 火算法”,計算機科學,2015 年。 [26] A. R. Syulistyo,D。M. J. Purnomo,M。 F. Rachmadi 和 A. Wibowo,“粒子群優 化算法(PSO),用於卷積神經網絡 (CNN ) 的 訓 練 優 化 , ”J. Ilmu Komput。 dan Inf。,vol。 9,不。 1, pp.52-58, 2016。 [27] N. P. Vinogradova 和 A. N. Popov,“經濟 決策的方法論基礎”,“企業家精神和 可持續性問題”,第一卷。 6,不。 4, pp.1798-1806, 2019。 [28] T. V. Pogodina,V。G. Aleksakhina,V。 A. Burenin,T。N. Polianova 和 L. A. Yunusov,“邁向數字化氣候中的創新 聚焦產業發展:俄羅斯的案例”,企業 家精神和可持續性問題,第一卷。 6, 不 。 4 , pp.1897-1906, 2019 。