荻田 武史
東京女子大学 現代教養学部 数理科学科
アルゴリズムによる計算科学の融合と発展 筑波大学 計算科学研究センター
概要
目的LU
分解,QR
分解,Cholesky
分解,特異値分解などの行 列分解のための高精度なアルゴリズムを提案する.A: n
× n
実行列. 提案方式はA
が非常に悪条件な場合も取り扱える. 悪条件: A
の条件数が非常に大きい.=
⇒
例えば,IEEE 754
倍精度の範囲で条件数が10
100を超える ような問題も取り扱える.=
⇒
直接的な応用:
連立一次方程式,行列式.その他,様々な 分野に応用可能.条件数
正方行列
A
に対して,A
の条件数を下記のように定義する:κ(A) :=
∥A∥ · ∥A
−1∥.
=
⇒ κ(A)
は問題の難しさの指標となる=
⇒
例えば,連立一次方程式Ax = b
を考える(x
∗:= A
−1b
). 右辺に摂動:Ay = b +
∆b
(y
∗:= A
−1(b + ∆b)
). このとき,解の変化量∆x = y
∗− x
∗は下記をみたす:∥∆x∥
∥x
∗∥
≤
κ(A)
∥∆b∥
∥b∥
IEEE 754
規格の倍精度演算=
⇒ 1
回の演算の相対精度: u
≈ 1.11 × 10
−16=
⇒
条件数が10
16より大きい(κ(A) > u
−1)場合,通常の倍精度 演算によって得られた計算結果は1
桁も合っていない場合がある.=
⇒
基本精度の限界 (基本精度:単精度や倍精度)=
⇒
このような問題を“
悪条件問題”
と呼ぶことにする.=
⇒
悪条件問題に対し,“
結果精度の高い”
行列分解アルゴリズム を提案する.Notation
A = (a
ij), C = (c
ij)
∈ R
n×n• |A|
:A
のすべての要素に絶対値を付けた行列,|A| = (|a
ij|)
.• A ≤ C
:すべての(i, j)
に対して,a
ij≤ c
ijLU
分解(部分軸交換付)
A
∈ R
n×n,P A
≈ LU
:
P
∈ R
n×n:
置換行列L
∈ R
n×n:
単位下三角行列U
∈ R
n×n:
上三角行列 例)連立一次方程式Ax = b
を解く.→
P Ax = P b
→
LU
ex = b
→
Ly = P b
を解く.→
U
ex = y
を解く.LU
分解の精度をどのように推定するか?残差
∥P A − LU∥
で推定?
例えば,LU
分解の残差∥P A − LU∥
あるいは相対残差は?∥P A − LU∥
∥A∥
< ε
=
⇒
これでは不十分(Matlab demo.)
例)標準的なガウスの消去法を用いた場合:メインアイディア
正確なLU
分解P A = b
L b
U
を考えると,通常,A
の悪条件性は上三 角行列U
b
に反映される.κ(A)
∼ κ( b
U )
もし,(1)
を満たすようなU
b
−1の良い近似X
U が得られれば,κ(A)
と比べて,κ(AX
U)
は相対的に小さくなる.例えば,κ(AX
U)
≪
u
−1.∥ b
U X
U− I∥ < 1
(1)
=
⇒
A
に対する前処理となる (Crout
型でも同様)A
をX
U によって前処理した後は∥X
LAX
U− I∥ < 1
(2)
あるいは∥AX
UX
L− I∥ < 1
(3)
を満たすようなbL
の近似逆行列X
Lを計算するのは難しくない.=
⇒
重要かつ難しい点: どのように悪条件なA
の前処理X
U を計算するか?仮定
κ( b
U )
≫ u
−1,X := b
b
U
−1.X
1= fl ( b
X)
とする(基本精度における最良近似).=
⇒
X
1= b
U
−1+ ∆
,|∆
ij| ∼ u| b
U
ij−1|
(丸め誤差) このような場合でも,∥ b
U X
1− I∥ < 1
は必ずしも成立するわけで はない:∥ b
U X
1− I∥ = ∥ b
U ( b
U
−1+ ∆)
− I∥ = ∥ b
U ∆
∥
≈ ∥ b
U
∥∥∆∥ ∼ u · κ( b
U )
> 1
=
⇒
U
b
−1の近似には,なんらかの高精度な形式が必要前処理としての近似逆行列
丸め誤差によって,X
1はU
b
の逆行列としては機能しない.しかし,A
の前処理としては機能する(U
b
の条件数とは無関係に).=
⇒
κ( b
U X
1) =
O(u)
· κ( b
U ),
u
≈ 10
−16=
⇒
条件数を小さくできる!=
⇒
これを利用した積型の反復アルゴリズムを開発:P AX
U= b
L b
U X
1X
2. . . X
k≈ bL ≈ L
(反復停止条件:∥P AX
U− L∥ < ε
tol)“
高精度
”
な逆
LU
分解
A
∈ R
n×n,P A
≈ LU
:
P
∈ R
n×n:
置換行列L
∈ R
n×n:
単位下三角行列U
∈ R
n×n:
上三角行列 許容誤差ε
tol< 1
に対して∥L
−1P AU
−1− I∥ ≤ ε
tol あるいは∥P AU
−1− L∥ ≤ ε
tol提案方式の方針
悪条件問題を取り扱うためには,なんらかの高精度演算が必要.=
⇒
すべての計算を多倍長精度で計算するのは効率が良くない.=
⇒
内積計算や行列乗算に特定すれば,比較的高速なアルゴリ ズムが利用可能.=
⇒
できる限り,高速な通常の浮動小数点演算を利用したい.高精度な内積計算
x, y
∈ F
nに対し,内積x
Ty =
nX
i=1x
iy
i の計算は,数値線形代数の基礎なので,たくさんの高精度なアル ゴリズムが提案されている.高精度な総和計算/内積計算の文献(
一部
)
1965 Møller (BIT)
1970 Nickel (ZAMM) (Kahan-Babuˇska’s algorithm) 1971 Malcolm (Comm. ACM)
1972 Pichat (Numer. Math.)
1973 KieÃlbaszi´nski (Math. Stos.)
1974 Neumaier (ZAMM) (improved Kahan-Babuˇska’s algorithm) 1977 Bohlender (IEEE Trans. Comput.)
1982 Leuprecht, Oberaigner (Computing)
1986 Kulisch, Miranker (SIAM Review, originally 1970’s in Karlsruhe) 1991 Priest (Proc. IEEE Symposium)
1999 Anderson (SIAM J. Sci. Comput.)
2002 Li et al. (ACM Trans. Math. Softw., XBLAS) 2003 Demmel, Hida (SIAM J. Sci. Comput)
高精度な行列乗算
仮定 任意に高精度な内積の計算結果が得られる.F:
(基本精度における)浮動小数点数の集合u:
浮動小数点演算の相対精度(IEEE 754
倍精度:u
≈ 10
−16) できる限り,通常の浮動小数点数/浮動小数点演算を用いたい.=
⇒
A
1:p:=
P
pi=1A
i,B
1:q:=
P
qi=1B
i のように行列を表現す る.ただし,A
i, B
i∈ F
n×nかつ|A
i| ≤ u |A
i−1| ,
|B
i| ≤ u |B
i−1|
のような関係が成り立っているものとする.仮定 行列乗算の汎用的な関数として下記のようなものが利用可 能とする:
C
1:L= [A
1:pB
1:q]
LK,
C
1:L:=
LX
i=1C
i, C
i∈ F
n×n は,下記をみたすとする(c
1, c
2:
O(1)
の定数):|C
1:ℓ− A
1:pB
1:q| ≤ c
1u
L|A
1:pB
1:q| + c
2u
K|A
1:p||B
1:q|.
これは,A
1:pB
1:qをK
倍長精度で計算し,その結果をL
倍長精度に 丸めたものに対応する(K
≥ L
でないと意味がない).関連研究
Rump
は,悪条件な行列の逆行列を高精度に計算するアルゴリズムを開発した
[unpublished, 1980’s], [JJIAM, to appear]
.function R = AccInv(A,m)
% right inverse version
n = dim(A);
I = eye(n);
R = A \ I;
% pure fl-pt (Solve AR = I for R)
for k=2:m
C = AccMM(A,R,1);
% accurate dot product
T = C \ I;
% pure fl-pt (Solve CT = I for T)
R = AccMM(R,T,k+1);
% accurate dot product
end
アルゴリズム:高精度な逆
LU
分解
[
高精度演算が必要な箇所のみ記載.それ以外は,基本精度]
0:
X
1:0= I
,k = 1
とする.1:
B
k← [A · X
1:k−1]
1k.[
高精度に計算/
基本精度に丸める]
2:
B
kのLU
分解(P
kB
k≈ L
kU
k).3:
U
k−1≈ T
kを計算.4:
X
1:k← [X
1:k−1· T
k]
kk.[
高精度に計算/
高精度に格納]
5:
もし,∥U
k∥∥T
k∥ ≤ ε
tol· u
−1ならばL := L
k, X
U:= X
1:kおよびP := P
kを返す.6:
k
← k + 1
として,1
に戻る.アルゴリズム:高精度な逆
QR
分解
[
高精度演算が必要な箇所のみ記載.それ以外は,基本精度]
0:
X
1:0= I
,k = 1
とする.1:
B
k← [A · X
1:k−1]
1k.[
高精度に計算/
基本精度に丸める]
2:
B
kのQR
分解(B
k≈ Q
kR
k).3:
R
−1k≈ T
kを計算.4:
X
1:k← [X
1:k−1· T
k]
kk.[
高精度に計算/
高精度に格納]
5:
もし,∥R
k∥∥T
k∥ ≤ ε
tol· u
−1ならばQ := Q
k, X
R:= X
1:kを返す.6:
k
← k + 1
として,1
に戻る.難しい点
•
アルゴリズムは簡潔だが,解析が難しい•
実際,厳密な解析は不可能(期待値や確率的な話になる)¶ ³
Proposition 1.
A
∈ F
n×nとする.X
1:k を逆LU
分解(逆QR
分解)アルゴリズムによって得られたn
× n
上三角行列とする. このとき,ある仮定の下で,k
≥ 1
に対して下記が成立する:κ(AX
1:k) = 1 +
O(
u
k)
· κ(A)
(4)
µ ´Remark 1.
A =
P
mi=1A
i, A
i∈ F
n×nのような入力でも取り扱え るようにアルゴリズムを拡張するのは難しくない(もし,高精度 な内積計算/行列乗算のアルゴリズムが利用可能なら).∥ b
RX
1:k− I∥ = ∥AX
1:k− b
Q
T∥ < 1
を達成するためには,下記のような
k
で十分.k =
»
log[ε
tol· κ(A)
−1]
log u
¼
.
しかしながら,一般的にκ(A)
は事前にはわからないため,k
をあ らかじめ決めることはできない. そこで,下記のような停止条件を利用:∥R
k∥∥T
k∥ < ε
tol· u
−1(5)
(5)
が成立=
⇒
∥AX
1:k− b
Q
T∥ < ε
tol提案アルゴリズムの特徴
1.
問題の難しさに応じて,必要なだけ反復的に計算精度を増 やすことができる(アダプティブ性).2.
高精度演算は,行列乗算(つまり内積計算)のみ.3.
それ以外の処理は,BLAS
,LAPACK
などを利用可能で,す べて通常の浮動小数点演算で実行(高速性).4.
高精度な内積計算/行列乗算が高速化されると,提案アル ゴリズムも高速化される.2
については,これもLevel-3 BLAS
を利用した高速な方式を開発 中(早大・尾崎氏との共同研究).数値実験
逆
LU
分解/逆QR
分解のふるまいについて数値実験する.•
倍精度を基本精度とする(u = 2
−53≈ 1.1 · 10
−16)•
テスト行列:Rump
の行列(INTLAB
のrandmat(n,cnd)
)• n = 100
,cnd = 10
100(A
∈ F
100×100,κ(A)
≈ 1.75 · 10
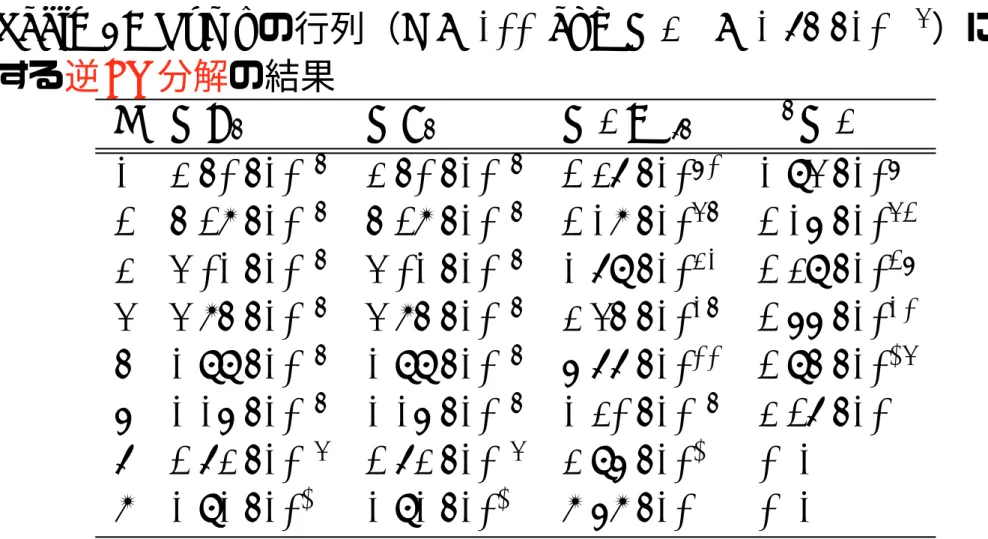
107)Table 1: Rump
の行列(n = 100 and κ(A)
≈ 1.75 · 10
107)に対する逆
LU
分解の結果k
κ(U
k)
κ(T
k)
κ(AX
1:k)
u
kκ(A)
1
3.50
· 10
183.50
· 10
182.37
· 10
931.94
· 10
912
5.28
· 10
185.28
· 10
182.18
· 10
782.16
· 10
753
4.01
· 10
184.01
· 10
181.79
· 10
642.39
· 10
594
4.85
· 10
184.85
· 10
183.45
· 10
482.66
· 10
435
1.99
· 10
181.99
· 10
186.77
· 10
332.95
· 10
276
1.16
· 10
181.16
· 10
181.30
· 10
183.27
· 10
117
2.73
· 10
172.73
· 10
173.96
· 10
2< 1
8
1.91
· 10
21.91
· 10
28.68
· 10
1< 1
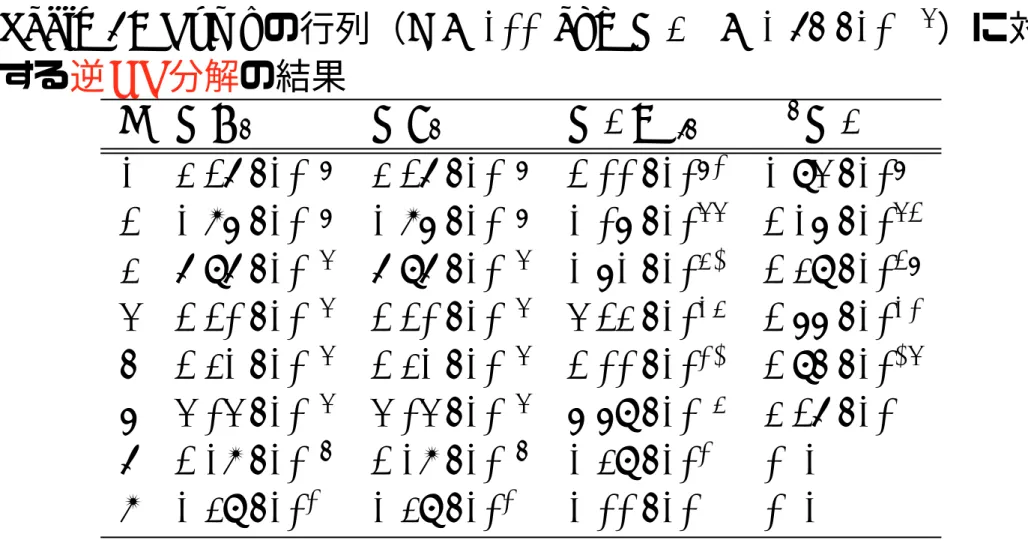
Table 2: Rump
の行列(n = 100 and κ(A)
≈ 1.75 · 10
107)に対 する逆QR
分解の結果k
κ(R
k)
κ(T
k)
κ(AX
1:k)
u
kκ(A)
1
3.27
· 10
193.27
· 10
192.00
· 10
931.94
· 10
912
1.86
· 10
191.86
· 10
191.06
· 10
772.16
· 10
753
7.97
· 10
177.97
· 10
171.61
· 10
622.39
· 10
594
2.20
· 10
172.20
· 10
174.23
· 10
462.66
· 10
435
2.31
· 10
172.31
· 10
172.00
· 10
322.95
· 10
276
4.04
· 10
174.04
· 10
176.69
· 10
163.27
· 10
117
2.18
· 10
182.18
· 10
181.39
· 10
3< 1
8
1.39
· 10
31.39
· 10
31.00
· 10
0< 1
応用
(1):
連立一次方程式
連立一次方程式の近似解の計算に提案アルゴリズムを適用:1. A
T の逆LU
分解(Crout
型ならA
でよい)P A
TX
U≈ L
⇔
X
UTAP
≈ L
T2.
ey = [X
UT· b]
1mを計算3.
三角方程式L
Tz =
ey
を解く(得られた近似解をez
とする)4.
ex = P ez
を計算数値実験
(1): (
スケール化
)Hilbert
行列
H
nH
nは要素が整数の行列(n
≤ 21
のとき,倍精度で正確に表現可能)• n = 15 (κ(H
15)
≈ 6.12 × 10
20)
•
右辺:b = H
15e
∈ F
15,e := (1, . . . , 1)
T• H
15x = b
の真の解:H
15−1b = e = (1, . . . , 1)
T(Matlab demo)
数値実験
(2): Rump
の行列
様々な条件数に対し,提案アルゴリズムを用いて得られた連立一 次方程式の近似解の相対精度(ノルム評価)をみる.• Rump
の行列randmat
(n = 500
,条件数は10
20から10
100)• b = (1, . . . , 1)
T•
提案アルゴリズムの許容誤差:ε
tol= 10
−6•
多倍長精度との速度比較のため,GMP
ベースのガウスの消去法 も実行(真の解は既知とするトライアンドエラー方式)function [p,rel_err] = test_gmp_lin(A,b,xt,tol)
%
xt: given exact solution of Ax = b
% tol: tolerance for relative error
d = 53; norm_xt = norm(double(xt));
while 1
xv = gmp_lin(A,b,d);
% solve Ax=b using GMP
% normwise relative error
rel_err = norm(double(xt-xv))/norm_xt;
if rel_err < tol, break, end
d = 2*d;
% d = 53, 106, 212, ...
end
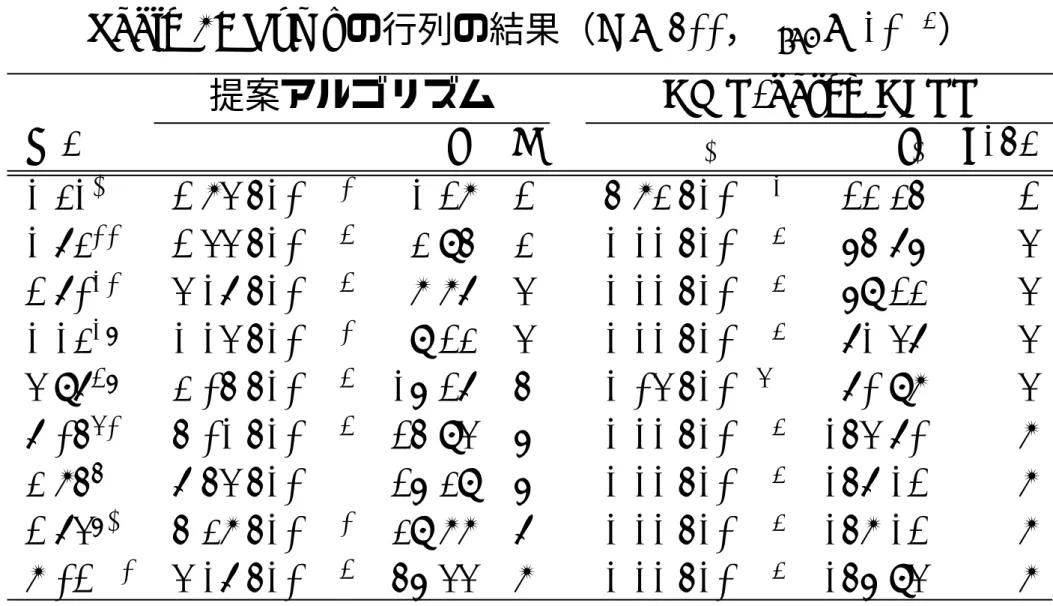
Table 3: Rump
の行列の結果(n = 500
,ε
tol= 10
−6) 提案アルゴリズムGMP-based GEPP
κ(A)
ε
1t
1k
ε
2t
2d/53
1.31
202.84
· 10
−131.28
2
5.83
· 10
−1423.35
2
1.73
332.44
· 10
−153.95
3
1.11
· 10
−1665.76
4
2.70
434.17
· 10
−158.87
4
1.11
· 10
−1669.23
4
1.13
491.14
· 10
−139.23
4
1.11
· 10
−1671.47
4
4.97
593.05
· 10
−1516.27
5
1.04
· 10
−770.98
4
7.05
735.01
· 10
−1525.94
6
1.11
· 10
−16154.70
8
3.85
817.54
· 10
−1126.39
6
1.11
· 10
−16157.12
8
2.74
925.38
· 10
−1339.88
7
1.11
· 10
−16158.12
8
−15 −16応用例
(2):
行列式の計算
良い方法(
Higham in ASNA
)として知られているのは,LU
分解 してU
iiの積を計算:det(A)
≈ det(P
TLU ) = det(P ) det(U ).
(もちろん,これは近似計算なので,結果の保証がない) 行列式は,その符号判定の情報が重要な例が多い.
行列式の精度保証
X
L, X
U: L, U
の近似逆行列.B := X
LP AX
U⇒ det(B) = det(P ) det(A) det(X
U)
⇒
det(A) = det(P )
det(B)
/ det(X
U)
(6)
=
⇒ B:
単位行列(対角行列)に近い, det(B)
≈ 1
=
⇒
Gershgorin
の定理により,B
の固有値の範囲がわかる=
⇒ det(B)
の包含が可能しかしながら,