メニーコアプロセッサ構成の検討を目的とした
高速トレースシミュレータの開発
指導教員
津邑 公暁 准教授
松尾 啓志 教授
名古屋工業大学大学院 工学研究科
修士課程 創成シミュレーション工学専攻
平成
23
年度入学
23413575
番
山田 龍寬
平成
25
年
2
月
5
日
メニーコアプロセッサ構成の検討を目的とした
高速トレースシミュレータの開発
山田 龍寬 内容梗概 ゲート遅延に対する配線遅延の相対的な増大から,動作周波数の向上だけではマイク ロプロセッサの速度向上を見込めなくなってきた.また,集積回路の微細化に伴う消費 電力や発熱量の増大から動作周波数自体の向上も困難になってきている.こうした中で, SIMDやスーパスカラなどの命令レベル並列性(ILP)に基づく高速化手法が注目されてき た.しかし,多くのプログラムは明示的なILPを持たない等の理由から,これらの手法 にも限界がある.現在では,消費電力や発熱量の問題を解決しつつプロセッサあたりの処 理能力を向上させるため,1つのCPUに複数のコアを搭載したマルチコアプロセッサが 広く普及している. 今後は集積度の向上に伴って,搭載するコア数をさらに増大させたメニーコアプロセッ サが一般化すると予想されている.メニーコアプロセッサには高並列な処理性能と低消費 電力化への期待が高まっているが,データ供給面の問題などにより多数のコアを有効活用 することは困難である.こうした理由から並列処理による高速化は様々な研究が行われて いるが,代表的アプリケーションにおける並列化限界はあまり調査されておらず,それら のアプリケーションを効率よく実行できる理想的なプロセッサ構成を検討することが重要 な課題となっている. そこで本論文では,安定したデータ供給が可能なプロセッサ構成の実現可能性を検証す るために,アプリケーションの実行トレースを採取可能なメニーコアトレースシミュレー タを開発する.そのためには,メニーコアプロセッサの実現において重要となる配線遅延 を考慮した構成方式を実現するために,キャッシュ構成やメモリ一貫性プロトコル等の データ供給を効率的に行う方式を構築し検証する必要がある.加えて,コア数の増大に伴 うメモリトラフィックの影響を調べるために,複数のコアやメモリを相互に結合し交信路 を提供する相互結合網の様々な形状を,構築し検証する必要もある.そこで,これらの構 成方式を検討するとともに,性能目標値を導出するための基本となるメニーコアプロセッ サの構成を設計する. 加えて,メニーコア研究において,コア数の増大に伴うシミュレーション時間の増大 が深刻な問題となっている.これを解決し,大規模なアプリケーションを現実的な時間 で実行するために,シミュレータの並列実行による高速シミュレーションを可能にした。これにより,SPLASH-2ベンチマークのシミュレーション時間を4スレッド実行で平均
1 はじめに 1 2 マルチコア/メニーコアプロセッサ 2 2.1 研究背景 . . . 2 2.2 マルチコア/メニーコア間での実装の違い . . . 3 2.2.1 コア数増大とキャッシュ構成の関係 . . . 4 2.2.2 キャッシュコヒーレンシプロトコル . . . 5 2.2.3 結合網形状の検討 . . . 6 3 既存シミュレータの問題点とその解決方針 9 3.1 アーキテクチャシミュレータ . . . 9 3.2 既存シミュレータとその問題点 . . . 10 3.3 研究計画概要 . . . 12 4 メニーコアトレースシミュレータの開発 13 4.1 アーキテクチャ設計 . . . 13 4.2 実行トレースの採取 . . . 15 4.3 動作モデル. . . 16 4.3.1 シミュレータコアの起動と同期処理 . . . 16 4.3.2 キャッシュリクエスト . . . 19 4.3.3 リクエストの衝突と優先順位. . . 20 5 シミュレータの動作検証 23 5.1 動作環境 . . . 23 5.2 動作結果 . . . 23 5.3 考察 . . . 29 5.4 今後のメニーコア研究に向けたシミュレータの改良方針 . . . 31 6 シミュレーションの高速化 33 6.1 ソフトウェアシミュレーションの問題点. . . 33 6.2 既存のシミュレーション高速化手法. . . 34
6.4.2 バリア . . . 39 6.4.3 コアへのバインド . . . 39 7 シミュレーション時間の評価 40 7.1 評価環境 . . . 40 7.2 動作オプションの選択 . . . 40 7.2.1 スレッドの生成 . . . 41 7.2.2 バリア . . . 42 7.2.3 コアへのバインド . . . 44 7.3 評価結果 . . . 46 8 おわりに 50 謝辞 51 著者発表論文 51 参考文献 52
1
はじめに
ゲート遅延が支配的であった2000年代初頭までは,集積回路の微細化による高クロック
化により,マイクロプロセッサの高速化を実現してきた.しかし,それと同じくしてゲー ト遅延に対する配線遅延の相対的な増大や,集積回路の微細化に伴う消費電力および発熱 量の増大といった問題から,マイクロプロセッサの動作周波数の向上は困難になってきて
いる.こうした中で,SIMDやスーパスカラなどの命令レベル並列性(ILP: Instruction
Level Parallelism)に基づく高速化手法が注目されてきた.しかし,多くのプログラムは 明示的なILPを持たないことや,ILPを抽出できる場合でもメモリスループットなどの 資源的制約があることから,これらの手法にも限界がある. このため現在では,消費電力や発熱量の問題を解決しつつプロセッサあたりの処理能力 を向上させるため,1つのCPUに複数のコアを搭載したマルチコアプロセッサが広く普 及している.このため,並列化されていないプログラムを複数のコアを用いて高速化する 一般的な手法として,スレッドレベル並列性(TLP: Thread Level Parallelism)に着目し た様々な手法が研究されている.これらの手法は,プログラムを複数スレッドに割り当て られるよう分割し,それぞれのコアに割り当てることで高速化を図っている場合が多い. 例えば,並列処理ライブラリを用いてプログラマが明示的にプログラムを並列化したり, 自動並列化コンパイラ[1, 2]を用いてコンパイラによりプログラムを複数のコアに対して 自動的に割り当てるような手法が挙げられる.しかし,そもそも並列性を持たずTLPを 抽出することが難しいプログラムも存在することや,プログラマが明示的に並列処理プロ グラムを記述することは困難である場合が多いなど,様々な問題が存在している.このた め,複数のコアを有効に利用してプログラム全体のスループットを向上させる高速化手法 を検討する必要が出てきている. さらに,今後プロセッサあたりのコア数をさらに増大させたメニーコアプロセッサが一 般化すると予想されている[3, 4].超並列処理により実効性能を飛躍的に改善するだけで なく、低速かつ定電圧動作を積極的に導入することにより、性能を担保しつつ大幅に消費 電力を削減することが可能であるため,メニーコアプロセッサへ大きな期待が寄せられて いる.しかし,マルチコアプロセッサに対する既存の高速化手法を利用しても,一部のコ アに処理を割り当てきれないという状況が発生することが想定されることや,データ供給 面の問題なども存在し,多数のコアを有効に利用することは困難である.また,並列処理 による高速化は様々な研究が行われているが,代表的アプリケーションにおける並列化限 界はあまり検討されておらず,それらのアプリケーションを効率よく実行できる理想的な
プロセッサ構成を検討することが重要な課題となっている. そこで本論文では,安定したデータ供給が可能なプロセッサ構成の実現可能性を検証す るために,アプリケーションの実行トレースを採取可能なメニーコアトレースシミュレー タを開発する.そのためには,メニーコアプロセッサの実現において重要となる配線遅延 を考慮した構成方式を実現するために,キャッシュ構成やメモリ一貫性プロトコル等の データ供給を効率的に行う方式を構築し検証する必要がある.加えて,コア数の増大に伴 うメモリトラフィックの影響を調べるために,複数のコアやメモリを相互に結合し交信路 を提供する相互結合網の様々な形状を,構築し検証する必要もある.そこで,これらの構 成方式を検討するとともに,性能目標値を導出するための基本となるメニーコアプロセッ サの構成を設計する. また,マルチコア・メニーコアプロセッサ研究において,コア数の増大に伴うシミュ レーション時間の増加が深刻な問題となっている.これを解決し,大規模なアプリケー ションを現実的な時間でシミュレートするために,シミュレーション自体を高速に行う機 能をメニーコアトレースシミュレータに追加実装する. 以下,2章ではマルチコア/メニーコアプロセッサの現状について述べ,3章では既存 シミュレータの問題点を挙げた上で,その解決方針と研究計画を提案する.そして,4章 でメニーコアトレースシミュレータの開発について述べ,5章で開発したシミュレータの 動作を検証する.その後,6章でシミュレーションの高速化について述べ,7章でシミュ レーション時間の評価結果と,それに対する考察を述べる.最後に,8章で結論を述べる.
2
マルチコア/メニーコアプロセッサ
本章では,マルチコア/メニーコアプロセッサの現状と,複数コアを搭載する一般的な プロセッサ構成方式について述べる. 2.1 研究背景 現在では,消費電力や発熱量の問題を解決しつつプロセッサあたりの処理能力を向上 させるために,1つのCPUに複数のコアを搭載したマルチコアプロセッサが広く普及 している.一般のパソコンやワークステーションに用いられる汎用マルチコアプロセッ サの例として,Intel社のCore i7[5]やIBM社のCell/B.E.[6],Sun Microsystems社のUltraSPARC T4[7]などが挙げられる.さらに,ネットワーク機器等で使用することを
想定し1つのプロセッサに64個のコアを搭載したTILE64[8]などのメニーコアプロセッ
(Digital Signal Processor)などの組み込み向けプロセッサにまでマルチコア技術が幅広 く普及してきた.このようにプロセッサのマルチコア化が進んでおり,複数のコアを利用 してプログラム全体のスループットを向上させる高速化手法を検討する必要が出てきて いる. 今後は半導体のプロセスルールの縮小に伴い,単一プロセッサあたりに搭載されるコア 数がさらに増大していくと予想される.近い将来,コア数は10,100,1000と規模を拡大 していき,メニーコアプロセッサが一般化すると考えられる.このメニーコアプロセッサ は,チップに多数のコアを集積してスレッドレベルの並列性を利用することで高並列な処 理性能と低消費電力化の実現を狙うものである. メニーコアプロセッサの実現方法にはいくつかのアプローチがある.その一つにTILE64 が採用しているタイルアーキテクチャを利用する方法が挙げられる.このようなタイル アーキテクチャでは,タイルと呼ばれる小さいサイズの機能ブロックを規則的に敷き詰め メッシュ状に結合されたネットワーク上で情報通信を行うことで配線遅延を軽減すること ができる.また,コア数を増やし回路規模を大きくしても動作速度を高速に保つことがで きる.しかし,独自のアーキテクチャとなるため既存の命令セットと互換性がないといっ た問題がある.他には,Intel社のCore i7 に代表される汎用のチップマルチプロセッサ で利用されている方法が挙げられる.チップマルチプロセッサでは,シンプルなプロセッ サコアを多数搭載することで従来のプロセッサの設計を再利用し,設計を簡単にしながら スループットを向上させることができる.また,省電力効果を高めることもでき,配線遅 延を考慮した設計にも有効である. このように,どちらの実現方法においても共通して配線遅延を考慮している.配線遅延 の問題は,現在よりさらに配線プロセスの微細化が進むことでより深刻化すると考えられ るため,設計段階から配線遅延を十分に考慮して回路を設計する必要がある.そのため, 高並列実行可能なアーキテクチャの実現に向けたプロセッサ構成の検討が重要になって いる. 2.2 マルチコア/メニーコア間での実装の違い データ供給の転送効率を向上させるキャッシュシステムと,複数のコアやメモリ間の交 信路を提供する相互結合網のトポロジについて,マルチコアとメニーコアプロセッサの構 成間における一般的な違いに着目しながら述べる.
Core Core Core Core L$1 L$1 L$1 L$1 L$2 L$2L$2 L$2 Mem Mem Mem Mem L$1 L$1L$1 L$1 L$2 L$2 L$2 L$2 Mem MemMem Mem Core#0 Core#0Core#0
Core#0 #1#1#1#1 #2#2#2#2 #3#3#3#3 Core#0Core#0 #1Core#0Core#0 #1#1#1 #2#2#2#2 #3#3#3#3 #4#4#4#4 #5#5#5#5
Mem Mem Mem Mem B0 B0B0 B0 L$2 L$2 L$2 L$2 L$1 L$1 L$1 L$1 B1 B1B1 B1 B2B2B2B2 B3B3B3B3 Core#0 Core#0Core#0 Core#0 #1#1#1#1 #2#2#2#2 #3#3#3#3 #4#4#4#4 #5#5#5#5 Mem Mem Mem Mem B0 B0 B0 B0 B1B1B1B1 B2B2B2B2 B3B3B3B3 Core#6 Core#6 Core#6 Core#6 #7#7#7#7 #8#8#8#8 #9#9#9#9 #10#10#10#10 #11#11#11#11 Mem Mem Mem Mem B0 B0B0 B0 L$2 L$2 L$2 L$2 L$1 L$1L$1 L$1 B1 B1 B1 B1 B2B2B2B2 B3B3B3B3 Xbar Cluster#0 Cluster#0 Cluster#0
Cluster#0 Cluster#1Cluster#1Cluster#1Cluster#1
DIRECTORY DIRECTORY DIRECTORY DIRECTORY (1) 単純な構成 (2) L$2 共有 (3) L$2 複数バンク分割 (4) 複数クラスタ構成 Xbar Xbar 図1: コア数の増大に伴うキャッシュの構成の様子 2.2.1 コア数増大とキャッシュ構成の関係 効率的なデータの安定供給のために,一般的なプロセッサではキャッシュシステムが 用いられている.キャッシュシステムでは,プロセッサに搭載されるコア数の増大とその キャッシュ構成に密接な関係性がある.ここで,コア数の増大に伴うキャッシュ構成の変 化の様子を図 1に示す. 図1中の(1)は,シングルコアプロセッサにおける単純なキャッシュ構成を示している. キャッシュメモリは,データを取得・更新する際に主記憶装置やバスなどの低帯域を隠蔽 し,処理装置と記憶装置の性能差を埋める.また,小容量のキャッシュメモリを何階層も 重ねて持つことで,低速な主記憶装置に対するアクセスを削減し処理性能を大きく損なう ことを避けてきた. その後,マルチコアプロセッサが採用されるようになり,複数のコアから主記憶へのア
クセスが発生するようになった.そのため,シングルコア以上にキャッシュシステムによ るメモリ帯域幅の確保が重要となっている.このようなマルチコアプロセッサには,図1 中の(2)で示すように,L2キャッシュの構成を変えず共有するものがある.しかし,並 列実行を目的とした一般的なマルチコアプロセッサでは,2次キャッシュを共有するだけ の単純な構成では,各コアからの参照要求が頻繁に到達するようになるため,リクエスト に対する応答が返ってくるまでの待ち時間が増大してしまい処理性能が低下してしまう. そこで,図1中の(3)で示すように,L2キャッシュを複数のバンクに分割するものがあ る.L2キャッシュをバンク分割しクロスバネットワークで接続することで,参照要求先 のバンクが異なる限り複数コアからの要求を同時に受け付けることが可能になる.しか し,キャッシュのデータ一貫性を保持しなければならないため,データ管理の複雑度が増 大することになる. さらに,搭載されるコア数を増加させたメニーコアプロセッサでは,ハードウェア物量 が増大してしまうため,バンク間でのクロスバネットワークの実現が困難になる.そこ で,ハードウェア物量を抑えつつ,データの転送効率を維持するために図1中の(3)で示 す構成を1つのクラスタとし,図1中の(4)で示すように複数のクラスタを接続するよう な構成をとる傾向がある.また,複数のコアやクラスタが備えるキャッシュでは,先ほど 述べたようにデータの一貫性を管理する必要がある.そのような一貫性の管理には,ス ヌーピングやディレクトリベースの一貫性管理機構がよく用いられている.スヌーピング は各コア間の帯域幅が十分大きければ性能が良くなるが,全てのメモリアクセス要求を全 体にブロードキャストする必要があるため,コア数が増えた場合も高い性能を出すために は,バスの帯域幅をより大きくしなければならなくなる.一方で,ディレクトリベースの 一貫性管理機構はキャッシュとメモリの間にディレクトリ機構が存在することになるため レイテンシが増大する傾向があるが,ブロードキャストが不要となるため帯域幅が小さく ても良いという利点がある.このため,多数のコアを搭載する大規模システムではディレ クトリベースの一貫性管理機構を備えることが多い. 2.2.2 キャッシュコヒーレンシプロトコル 複数のコアやクラスタが備えるキャッシュでは,キャッシュとメモリ間におけるデータ の一貫性を保持するためにキャッシュコヒーレンシプロトコルが採用されている.キャッ シュコヒーレンシプロトコルは,キャッシュの内容に矛盾が生じないように,キャッシュ やメモリへのリクエストを管理する役割を担っている.そのため,状態を管理するプロト コルに応じてトラフィック量が変化し,実際の帯域幅に影響を与えることになる. このプロトコルには様々な種類が存在し,その性能とスケーラビリティは個々のプロト
コルごとに異なる.基本的なプロトコルとして知られるMSIプロトコルは,キャッシュ ライン状態を3つに分けて管理する.これらの状態は,キャッシュラインの内容が無効 であることを示すInvalid,キャッシュラインの内容が有効でメモリと一致していること を示すShared,そして,キャッシュラインの内容が有効であるが当該キャッシュにのみ 存在しメモリ上の値から変更されていることを示すModifiedである.MSIプロトコルで は,データをキャッシュに保持しているのが自分だけであった場合でも,他のキャッシュ が同一アドレスのデータを持っていないことを把握できないため,他の全てのキャッシュ に対してInvalid化の要求を送る必要がある.
そこで,MSIプロトコルを改良したものにMESIプロトコル[9]がある.MSIプロト
コルにおけるSharedの状態を,自分のキャッシュだけが有効のExclusiveの状態と他の キャッシュにも同一アドレスのデータが保持されているSharedの状態に分ける.このよ うな4つの状態を採用することで,書き込もうとするキャッシュラインがExclusive状態 の場合には,他のキャッシュに同一のデータが存在しないので,Invalid化要求を行わず に書き込むことができる. また,MSIプロトコルでは,他のキャッシュからの読み出し要求が,Modified状態の キャッシュラインに届くと,書き換えられたデータの内容をメモリに書き戻す必要があ
る.そこで,MSIプロトコルにMESIとは異なる改良を加えたMOSIプロトコルがある.
先に挙げたMSIプロトコルの3つの状態に,書き戻し責任を負うOwnedの状態を追加し て,書き戻しの頻度を減少させる.具体的には,Modified状態のキャッシュラインに対し て読み出し要求が届いた場合,主記憶への書き込みをせず,他のキャッシュにデータを供 給するとともにキャッシュラインの状態をOwnedに変更することで書き戻しの頻度を減 らす.一方で,データを受け取った側のキャッシュラインはShared状態となる.Owned 状態のキャッシュラインは,キャッシュから追い出される時にはその値をメモリへ書き戻 す必要があるが,他のキャッシュからアクセスされた場合にはメモリへ値を書き戻す必要 はない.そのため,メモリへの書き込み頻度を減少させることができる.
さらに,基本となるMSIプロトコルにExclusiveとOwnedの両方の状態を追加した
MOESIプロトコルがある.マルチコアプロセッサのキャッシュでは,メインメモリへの アクセス時間と比較して,プロセッサ間のキャッシュライン転送時間が非常に短く高速に 実行できるため,このMOESIプロトコルや,MESIプロトコルが採用されることが多い. 2.2.3 結合網形状の検討 コア間結合網では,データ転送性能とハードウェア物量の2つを考慮することが重要に なる.これら2つはトレードオフの関係にあるため,システムに適したトポロジを選択す
Core CoreCore Core #12 #12 #12 #12 Core Core Core Core #13 #13#13 #13 Core CoreCore Core #14 #14 #14 #14 Core Core Core Core #15 #15#15 #15 Core Core Core Core #00 #00#00 #00 Core Core Core Core #01 #01#01 #01 Core Core Core Core #02 #02 #02 #02 Core CoreCore Core #03 #03 #03 #03
Xbar
Xbar
Xbar
Xbar
…
I/O IF I/O IF I/O IF I/O IF…
プロセッサコア プロセッサコア プロセッサコア プロセッサコア プロセッサコアプロセッサコアプロセッサコアプロセッサコア…
…
…
外部 外部外部 外部メモリメモリメモリIFメモリIFIFIF 2 22 2次次次次キャッシュメモリ・ポートキャッシュメモリ・ポートキャッシュメモリ・ポートキャッシュメモリ・ポート 図2: フラット型クロスバ結合網モデル Core CoreCore Core #12 #12 #12 #12 Core Core Core Core #13 #13#13 #13 Core CoreCore Core #14 #14 #14 #14 Core Core Core Core #15 #15#15 #15 Core Core Core Core #00 #00#00 #00 Core Core Core Core #01 #01#01 #01 Core Core Core Core #02 #02 #02 #02 Core CoreCore Core #03 #03 #03 #03…
I/O IF I/O IF I/O IF I/O IF…
プロセッサコア プロセッサコア プロセッサコア プロセッサコア プロセッサコアプロセッサコアプロセッサコアプロセッサコア…
外部メモリ 外部メモリ外部メモリ 外部メモリIFIFIFIF 2 22 2次キャッシュメモリ・ポート次キャッシュメモリ・ポート次キャッシュメモリ・ポート次キャッシュメモリ・ポートRing
Ring
Ring
Ring
図3: フラット型リング結合網モデル る必要がある.このコア間結合網のトポロジとしては,様々な種類の形式が考えられる. この中で,最も転送性能が高くなる反面ハードウェア物量も大きいものの代表的な形式が クロスバ型結合網である.また,単純な構成でハードウェア物量が小さいものの代表的な 形式がリング型結合網である.これら2種類の結合網はマルチコアプロセッサやメニーコ アプロセッサシステムで広く用いられているため,本論文ではクロスバ型結合網とリング 型結合網を基本としたコア間結合網に関して述べる.ここで,クロスバ型結合網,リング 型結合網の両方とも,全てのコアを一つの結合網に繋いだフラット型および結合網を多段 化した階層型の2種類が考えられる.そのため,今回とりあげる結合網形状としてはそれ らを組み合わせた総計4種類の結合網形状が考えられる.Core Core Core Core #00 #00 #00 #00 Core CoreCore Core #01 #01 #01 #01 Core CoreCore Core #03 #03#03 #03 Core CoreCore Core #02 #02 #02 #02
…
Core CoreCore Core #00 #00 #00 #00 Core Core Core Core #01 #01#01 #01 Core CoreCore Core #03 #03 #03 #03 Core Core Core Core #02 #02 #02 #02…
Cluster#0 Cluster#0Cluster#0Cluster#0 Cluster#1Cluster#1Cluster#1Cluster#1
L1Xbar
L1Xbar
L1Xbar
L1Xbar
L1Xbar
L1Xbar
L1Xbar
L1Xbar
I/O IF I/O IFI/O IF I/O IF
L2Xbar
L2Xbar
L2Xbar
L2Xbar
L2Xbar
L2Xbar
L2Xbar
L2Xbar
図4: 階層型クロスバ結合網モデル まず,フラット型クロスバ結合網モデルを図 2に示す.フラット型クロスバ結合網は, 各プロセッサコアや2次キャッシュ,外部メモリインタフェース,I/Oインタフェースな どの全ポートをフラットな完全結合クロスバスイッチで接続したモデルである.このモデ ルでは,全てのポート間で自由にデータが転送できるため,データ転送性能に最も優れる が,ハードウェア物量も最も大きい. 続いて,フラット型リング結合網モデルを図 3に示す.フラット型リング結合網モデ ルは,接続する機器の全てのポートをリンク結合網で接続する.そのため,通信パケット が全てのポートをホップするため,データを転送する際の中継数が増大し転送性能が著し く低下することが予測できる.このモデルでは,データ転送性能が最も低くなってしまう が,ハードウェア物量を最も小さく抑えることができる. 次に,階層型クロスバ結合網モデルを図 4に示す.階層型クロスバ結合網は,各ポート を階層化してクラスタ構成とし,各クラスタ内を完全結合クロスバスイッチで接続する. そして,各クラスタ間をさらに完全結合クロスバスイッチで接続している.このモデルで は,データ転送性能がフラット型クロスバ結合網よりも低くなるが,ハードウェア物量を 抑えることができる. 最後に,階層型リング結合網モデルを図 5に示す.階層型リング結合網は,各ポートを 階層化してクラスタ構成とし,各クラスタ内をリング結合網で接続する.そして,各クラ スタ間をさらにリング結合網で接続している.このモデルでは,データ転送性能がフラッ ト型リング結合の次に低くなってしまうが,ハードウェア物量を小さく抑えることがで きる.Core Core Core Core #00 #00 #00 #00 Core Core Core Core #01 #01 #01 #01 Core CoreCore Core #03 #03#03 #03 Core CoreCore Core #02 #02 #02 #02
…
Core CoreCore Core #00 #00 #00 #00 Core Core Core Core #01 #01#01 #01 Core Core Core Core #03 #03 #03 #03 Core Core Core Core #02 #02#02 #02…
Cluster ClusterClusterCluster#0#0#0#0 Cluster#1Cluster#1Cluster#1Cluster#1
L1Ring
L1Ring
L1Ring
L1Ring
L1Ring
L1Ring
L1Ring
L1Ring
I/O IF I/O IF I/O IF I/O IF
L2Ring
L2Ring
L2Ring
L2Ring
図5: 階層型リング結合網モデル 一般的なマルチコア/メニーコアプロセッサは,以上で述べたキャッシュ構成や相互結 合網形状を組み合わせて構成されている.そして,プロセッサの用途に合わせてこれらの 構成を組み合わせることで,様々な処理に特化したプロセッサが開発されてきた.こうし た理由から,本論文ではこれらのキャッシュ構成や相互結合網形状を基に高並列実行可能 なアーキテクチャ構成を検討する.3
既存シミュレータの問題点とその解決方針
本章では,アーキテクチャシミュレーションの重要性と,既存シミュレータの問題点お よび,それを解決するための方針と研究計画の概要について述べる. 3.1 アーキテクチャシミュレータ マルチコアプロセッサアーキテクチャや,マルチコアプロセッサ時代のソフトウェアに 関する研究・開発を効率的に行うためには,様々なアイディアを迅速に検証できる環境が 必要となる.マルチコアプロセッサを実チップで制作することができれば,リアルな構成 や実験環境を構築でき実際の環境に沿った研究が可能となる.しかし,実チップは非常に 高価である上,制作に時間がかかるため実現が困難であることが多い.さらに,細かい構 成やパラメータの変更を容易に行うことができないという問題もある.特に構成規模が大 きくなるメニーコアプロセッサではこの問題点が顕著となる.そこで,コンピュータアー キテクチャの研究では,シミュレーションによる評価が可能なアーキテクチャシミュレータが重要な役割を担っている.
アーキテクチャシミュレータには大きく分けて2つの種類が存在している.そのひとつ
として,FPGA(Field-Programmable Gate Array)を利用したシミュレータが挙げられ
る.FPGAシミュレータには,実チップによる制作に比べて安価に環境を構築できるだ けでなく,開発期間を短縮できるという利点がある.しかし,配線を含めた基盤が一度組 み上がってしまうと,構成の変更が必要な状況に陥った場合に最初から設計をやり直さざ るを得なくなってしまう.また,シミュレーション中の内部状態の読み出しが難しい.こ うした理由から,アーキテクチャの研究用途としては設計や構成方式を検討する場合,柔 軟性に欠ける部分がある. 一方で,全てソフトウェアでシミュレーションするソフトウェアシミュレータがある. ソフトウェアシミュレータは,C言語などを使って記述した一般的なソフトウェアであ り,汎用コンピュータ上でも稼働させることができる.このシミュレータでは,プロセッ サの設計が未確定の場合にも詳細部分を省略して全体の動作を大まかに模擬できるとい う利点があり,ハードウェア制約のない理想的な構成を手軽に実現できる.そのため,シ ミュレーションに多大な時間を要するという欠点はあるが,様々なパターンのプロセッサ 構成方式を検討する場合には最も適している. 3.2 既存シミュレータとその問題点 マルチコアプロセッサシミュレータは現在までに様々なものが開発されている.FPGA を利用したシミュレータには,日本国内のプロジェクトとしてScalableCore[10]が提案・ 開発されている.FPGAを利用したシミュレータは,メニーコアプロセッサの動作を現実 的な時間でシミュレーションすることを目的としており,プログラムに内在する並列性の 活用によりソフトウェアシミュレータと比較してメニーコアアーキテクチャをより高速に シミュレーションすることを可能としている.ScalableCoreでは,小容量のFPGAで構 成された1つのノードをタイル状に多数配置し,メッシュネットワークで接続するタイル アーキテクチャを採用している.また,ノード数に応じたシミュレーション速度のスケー ラビリティを実現するために,仮想サイクルという概念を導入している.複数のクロック サイクルをかけて1仮想サイクルの動作を進め,1仮想サイクル中に対象アーキテクチャ の動作およびそれに付随するユニット上のSRAMへのアクセスやユニット間通信・同期 などの処理が行われる.このように仮想サイクルを用いることでシミュレーションを高速 化できるが,シミュレート対象となるプロセッサ・ハードウェアの現実性を一部損なって しまっており,複雑なプロセッサモデルのシミュレーションに関しては信頼性が低い.
一方,ソフトウェアシミュレーションのひとつに,HP研究所が開発しているCOTSon[11] がある.COTSonは,コンピューティングシステムを高速かつ正確に評価することを目 的としたフルシステムのシミュレーションフレームワークで,機能シミュレーションとタ イミングシミュレーションを組み合わせたシミュレーション環境となっている.このフ レームワークでは,機能シミュレータが生成するトレースを元に,シングルコア上で動作 するマルチスレッドアプリケーションの各スレッドをシミュレーション対象プロセッサの 各コアにマップ・シミュレーションする.そして,タイミングシミュレータなどで構成さ れるバックエンド側でスレッド間の同期をとるというモデルを用いている.このモデルで は,既存のフルシステムシミュレータで動作するマルチスレッドアプリケーションをマル チコアプロセッサ上で実行した場合の性能を評価することが可能である. また,フルシステムシミュレータの他に,アーキテクチャレベルのシミュレータが存在 する.チップマルチプロセッサでは通信性能の限界がボトルネックとなりつつあり,性能 効率と電力効率の良い相互結合網が求められている.電子機器はこれまでに性能要求に応 えることができていたが,さらなる効率の向上には消費電力の限界値が問題となっている. そこで,ネットワークシミュレーションフレームワークの一つであるOMNeT++を用い たPhoenixSim[12]が開発されている.PhoenixSimは,光通信ネットワークを用いるマ ルチコアプロセッサシステムのモデル化・解析のために,通信ネットワークを統合し実行 するシミュレータである.従来のネットワークシミュレータと対照的に,電子に相当する ものを持たない光通信における相互接続装置とネットワーク素子の測定基準および物理的 な特徴を取得でき,エネルギー効率の良い高帯域な通信環境の構築を目的としている. さらに,アーキテクチャレベルのシミュレータには,ハードウェア記述言語SystemC[13] をベースとしたNIRGAM[14]も存在する.NIRGAMは,ネットワークオンチップの研 究において,様々なトポロジ上のルーティングアルゴリズムやアプリケーションの設計お よび実験の実質的なサポートを目的としている.そのため,拡張可能なモジュールである SystemCをベースとしており,ネットワークオンチップの設計で利用可能な様々なオプ ション機能を備えている.このシミュレータのオプションとしては,トポロジやスイッチ ング機構,ルーティング機構などがあり,新しいルーティングアルゴリズムを容易に実装 できる. 他にも,ある特定のアーキテクチャをシミュレーションするのに特化したシミュレータ として,Shaksham[15]やMC-Sim[16]が存在する.Shakshamは,x86系プロセッサのシ
ミュレーションに特化している.初期世代から最新機まで歴代すべてのx86系のプロセッ
とを目的としている.また,MC-SimはCell/B.E.などに代表されるヘテロジニアスなマ ルチコアプロセッサのシミュレーションを正確に行うことができる.このシミュレータは ヘテロジニアスマルチコア特有の,コプロセッサの構成やプロセッサ間のネットワーク構 成を様々なものに変更し,シミュレーションすることができる. このように,マルチコア/メニーコアを対象としたシミュレーション環境の研究が数 多く行われているが,これら既存のシミュレータはいずれも共有メモリを前提として構築 されている.しかし,メニーコアプロセッサで複数のコアを単一の主記憶装置へ接続して しまうと,メモリアクセスによるボトルネックが顕在化する危険性があるため,全コア共 有のメモリシステムを想定することは現実的ではない.また,メニーコアプロセッサでは メッセージパッシングなどの方式を採用する必要性が増す上,キャッシュシステムなどに よるメモリ帯域幅の確保も重要になると考えられる.こうした理由から,既存のシミュ レータのシミュレーションコア数を増大させるだけでは,メニーコアプロセッサのシミュ レーションを行うことは難しい. そこで本論文では,メニーコアプロセッサの理想的な構成を検討するために,様々な構 成方式を検証可能なメニーコアシミュレータを開発する.プロセッサ構成の検討にあたっ て,2.2節で述べたデータ供給方式と結合網形状に着目することで,配線遅延を考慮した 高並列実行可能なアーキテクチャを模索していく.このような目的の下,プロセッサ構成 の各方式の実現可能性を検証し,さらに各方式を組み合わせた様々な構成パターンを実現 するために,本研究ではソフトウェアによるシミュレーションを採用する. 3.3 研究計画概要 本メニーコアプロセッサ研究の計画は大きく3つのステップに分けることができる.第 1ステップでシミュレータを開発し,第2ステップで,開発したシミュレータを用いてメ ニーコアプロセッサの各構成方式の検証を行う.そして第3ステップで,高並列実行可能 な並列アーキテクチャを模索する.これら3つのステップについて順に説明する. まず第1ステップでは,メニーコアシミュレータを開発する.ハードウェア・アーキ テクチャの検討にあたっては,性能目標値を導出する必要がある.そこで,基本となるメ ニーコアプロセッサの構成を設計し,代表的なアプリケーションを実行可能なシミュレー タを開発する.そして,実行時におけるトレースを採取することで,メニーコアプロセッ サ構成方式の諸検討に利用する.以下,これらの機能を備えたソフトウェアシミュレータ をメニーコアトレースシミュレータ(Manycore Traced Simlator)と呼ぶ.
セッサの実現において重要となる配線遅延を考慮して,キャッシュ構成やメモリ一貫性プ ロトコル等のデータ供給方式および,複数のコアやメモリを相互に結合し交信路を提供す る相互結合網の様々な形状を構築する.また,メニーコアトレースシミュレータの実現の ために基本構成だけでなく,各構成方式を組み合わせることで様々な構成パターンをシ ミュレートすることを目的とし,それらの実行トレースをそれぞれ採取する. 最後に第3ステップで,高並列実行を実現する最適なアーキテクチャを模索する.これ までのステップで得られた実行トレースの結果から,それぞれのメニーコアプロセッサ構 成方式の比較・検討・考察を行う.また,それら構成方式において,単一プログラムを並 列化して実行する場合の並列度の限界を調査する.多くのプログラムは潜在的な並列性を 持っているが,抽出できる並列度は一般に高くない.そのため,多数のコアを有効に利用 するためには単純な並列化のみならず他の高速化技術との組み合わせが必要になると考え られる.そこで,これまで提案されてきた他の高速化技術を組み込むことも視野に入れ, プロセッサ高速化技術の進むべき道筋を示すことが本研究の最終的な目標となる. 以上の3つのステップの中で,本論文では主に1つ目のメニーコアトレースシミュレー タの開発について述べる.まずは,2.2節で述べたプロセッサ構成方式から,基本となる アーキテクチャを設計し,メニーコアトレースシミュレータで動作させるメニーコアプロ セッサの基本構成を実装する.
4
メニーコアトレースシミュレータの開発
性能目標値を導出するためにメニーコアプロセッサの基本構成を設計し,その実行ト レースを採取可能なメニーコアトレースシミュレータを開発する. 4.1 アーキテクチャ設計 データ供給方式および相互結合網の形状において,基本となるプロセッサ構成を検討 する.キャッシュ構成については,プロセッサコア数を増大させることを考慮して,L2 キャッシュを複数のバンクに分割したクラスタを複数備える構成とし,ディレクトリベー スの一貫性管理機構を持たせる.また,最近のプロセッサでは,内蔵キャッシュを3階層 とすることが一般的である.1次キャッシュをプロセッサコアに内蔵し,2次キャッシュ をコアごとに内蔵するもしくは2コア程度で共有し,3次キャッシュを全コアで共有する といった構成をとることが多い.しかし,メニーコアプロセッサでは低消費電力化を目的 とし,プロセッサコアの動作周波数を下げる傾向がある.そのため,高周波数のプロセッ サと異なり,アクセス時間の観点からキャッシュの階層を増大させる必要性は小さい.まCore#00
Core#00 Core#01Core#01 Core#02Core#02 Core#03Core#03 Core#04Core#04 Core#05Core#05 Core#06Core#06 Core#07Core#07
Cluster#0 Cluster#1
I$1 D$1 I$1 D$1 I$1 D$1 I$1 D$1
DDR 物理#0 L$2 #0 L$2 #0 L$2 #1 L$2 #1 L$2 #2 L$2 #2 L$2 #3 L$2 #3 L2-TAG L2-TAG L2-TAG L2-TAG
L2-DIR L2-DIR L2-DIR L2-DIR
I$1 D$1 I$1 D$1 I$1 D$1 I$1 D$1
DDR 物理#1 L$2 #0 L$2 #0 L$2 #1 L$2 #1 L$2 #2 L$2 #2 L$2 #3 L$2 #3 L2-TAG L2-TAG L2-TAG L2-TAG L2-DIR L2-DIR L2-DIR L2-DIR
Core#12
Core#12 Core#13Core#13 Core#14Core#14 Core#15Core#15
I$1 D$1 I$1 D$1 I$1 D$1 I$1 D$1
DDR 物理#3 L$2 #0 L$2 #0 L$2 #1 L$2 #1 L$2 #2 L$2 #2 L$2 #3 L$2 #3 L2-TAG L2-TAG L2-TAG L2-TAG L2-DIR L2-DIR L2-DIR L2-DIR
Core#08
Core#08 Core#09Core#09 Core#10Core#10 Core#11Core#11
I$1 D$1 I$1 D$1 I$1 D$1 I$1 D$1
DDR 物理#2 L$2 #0 L$2 #0 L$2 #1 L$2 #1 L$2 #2 L$2 #2 L$2 #3 L$2 #3 L2-TAG L2-TAG L2-TAG L2-TAG
L2-DIR L2-DIR L2-DIR L2-DIR
L1Xbar L1Xbar L1Xbar L1Xbar L2Xbar Cluster#3 Cluster#2 図6: メニーコアトレースシミュレータのアーキテクチャ構成 た,キャッシュ階層を増大させた場合には,キャッシュミス時のオーバヘッドが大きくな り制御機構も複雑化する.そのため,今回の構成では2階層のキャッシュを採用する. キャッシュコヒーレンシプロトコルは,各階層において別々のものを選択することがで きる.そこで,各クラスタの持つ2次キャッシュには,メインメモリへのアクセス回数を 減少させるために,書き戻し頻度を削減できるMOESIプロトコルを採用する.また,各 コアの持つ1次キャッシュには,一貫性管理の複雑度を抑えつつ効率的なキャッシュアク セスが可能なMESIプロトコルを採用する.一方で,相互結合網の形状には,2.2.3項で 述べた3種類の結合網形状の中で,データ転送性能,ハードウェア物量,消費電力のバラ ンスが最も良いと考えられる階層型クロスバ結合網を選択する. 以上で述べた構成方式をもとに設計したアーキテクチャの構成図を図 6に示す.最小 構成として16コア内蔵の2階層型クロスバ結合のcc-NUMAアーキテクチャを採用した. また,全体で4クラスタ構成となっており,1クラスタに4つのコアが内蔵されるとする. そして,各コアと2次キャッシュ(L$2)がクロスバに接続され,各コアはローカルに命令
Core Core Core Core #00 #00 #00 #00 Core Core Core Core #01 #01#01 #01 Core CoreCore Core #02 #02 #02 #02
‥
メモリI/O
メニーコアトレースシミュレータ time=17304 inc time=17297 mul time=17301 sub time=17283 ld time=17301 st 全コア実行データ(トレースデータ) データ供給方式の検討 結合網形状の検討 メモリ処理系トレースデータ 図7: トレースデータ抽出フロー キャッシュ(I$1)とデータキャッシュ(D$1)を内蔵している.また,主記憶装置DDR はメモリの帯域幅を考慮して各クラスタに均等分割し,クロスバの1 つに接続する. ここで,図中のL2-TAGとは2次キャッシュの各バンクに付属するタグであり,キャッ シュラインの現在の状態をラインごとに保持しており,これを利用してキャッシュのコ ヒーレンシを保証する.また,このタグは1次キャッシュのディレクトリ機構も担ってお り,同じクラスタ内に属するコアが持つ1次キャッシュに格納されている同一アドレスの データの状態も保持している.L2-DIRは,2次キャッシュを管理するディレクトリ機構 であり,2次キャッシュの各バンクに付属する.この機構では,2次キャッシュの各ライ ンが保持するデータと同じデータを持つ,他クラスタの2次キャッシュのライン状態を保 持している. 4.2 実行トレースの採取 メニーコアトレースシミュレータの開発では,代表的なアプリケーションを実行させて プログラム実行中のトレースデータを採取することを目的の一つとしている.そのため, シミュレータの基本的な機能としてシミュレーションのトレース機能を搭載している.ここで,メニーコアプロセッサのように大規模システムのトレースを採取する場合には,膨 大なサイズのトレースデータが生成されてしまうことになる.そのため,今回のメニーコ アトレースシミュレータでは,各コアで採取したトレースデータの中から,特にメモリ処 理(ロード・ストア)だけを抽出する.このトレースデータの抽出フローを図 7に示す. メニーコアトレースシミュレータの各プロセッサコアがベンチマークアプリケーションを 実行した際の全コア実行データを採取し,メモリ処理だけを抽出することでメモリ処理系 のトレースデータを作成する.それを圧縮形式でファイルに書き込み,データ供給方式や 相互結合網の形状における諸検討で統一的に利用する. メモリ処理系のトレースデータにおけるトレースフォーマットは,メモリアクセスの種 別,参照アドレス,アクセス時刻の情報のみを構成要素とする.そして,1回のメモリア クセスを1レコードとし,複数のレコードを時間順にファイルに書き込む.具体的には, メモリアクセスの種別を1ビット,参照アドレスを64ビット,アクセス時刻をそのタイ ミングにおけるサイクル数の64ビットで表す.そのため,1つのレコードを約16バイト で記述することが可能となる.このように,採取するトレースデータを限定することで, 膨大なデータ量を大幅に削減できる. 4.3 動作モデル 次に,メニーコアトレースシミュレータの動作について説明する. 4.3.1 シミュレータコアの起動と同期処理 プログラムを複数のコアで並列実行するために,マルチスレッド化ライブラリが広く利 用されている.マルチスレッド化ライブラリにはいくつかの種類が存在するが,いずれも OSがスレッドの生成からスケジューリングまでを行うという点においては共通している. しかし,現在のメニーコアトレースシミュレータはフルシステムシミュレータではないた め,OSが存在せず,簡単なシステムコールをシミュレートすることしかできない.その ため,一般的に使われているマルチスレッド化ライブラリを使用したプログラムをシミュ レータ上で実行できない. そこで,メニーコアトレースシミュレータ向け専用Pthreadライブラリを実装した.こ のライブラリは,広く利用されているPthreadライブラリと同じAPIを提供することで, シミュレータ上で実行するプログラムの書き換えが必要とならず,ユーザへの負担を増や すことはない.現在,専用Pthreadライブラリが提供している関数を表 1に示し,それ ぞれの動作モデルについて概説する. まず,スレッドを生成するための関数であるpthread create()が呼び出されると,引数
表1: 専用Pthreadライブラリが提供している関数
pthread create() スレッドの生成
pthread join() スレッドが終了するまで待機 pthread mutex init() ロック用変数を初期化 pthread mutex lock() ロックをかける pthread mutex unlock() ロックの解除
pthread barrier init() バリア同期用変数を初期化 pthread barrier wait() 指定したスレッド数でバリア同期する
に指定されたスレッドIDに対応する番号のシミュレーションコアが起動する.その後, 起動したコア上でスレッドのシミュレーションが開始される.なお,現在のメニーコアト レースシミュレータでは1つのシミュレーションコアにつき1つのスレッドを固定して実 行する.その後,スレッドの実行が終了すると,pthread join()が呼び出され,各シミュ レーションコアを停止状態へ移行させる.ただし,シミュレーションコアを停止する前 に,そのコアの1次キャッシュ上に最新の値(Modified)が存在する可能性があるため,1 次キャッシュを2次キャッシュへ書き戻す.また,所属しているクラスタ内のうち最後に 停止状態に移行するシミュレーションコアは,1次キャッシュの書き戻し後に2次キャッ シュもメインメモリへ書き戻す. また,全スレッドはメモリ領域を共有しているため,同じアドレスのデータに対して 競合が発生する場合がある.こうしたスレッド間での競合を回避するためには,一般的 にpthread mutex lock()とpthread mutex unlock()を用いて排他制御を行う.これら を利用してロックした際に,リソースを獲得できなかったコアは待ち状態へと移行す
る.こうしたコアの待ち状態を実現する方法には,スリープ状態に移行しCPUリソー
スを節約するような実装も考えられるが,簡単のためスピンロックで待ち状態を実現 した.排他制御を行うためには,まずロックを管理するための変数であるロック変数を
pthread mutex init()を用いて初期化する必要がある.そして,クリティカルセクションに 入る前にpthread mutex lock()を使用する.ここで,提供しているpthread mutex lock()
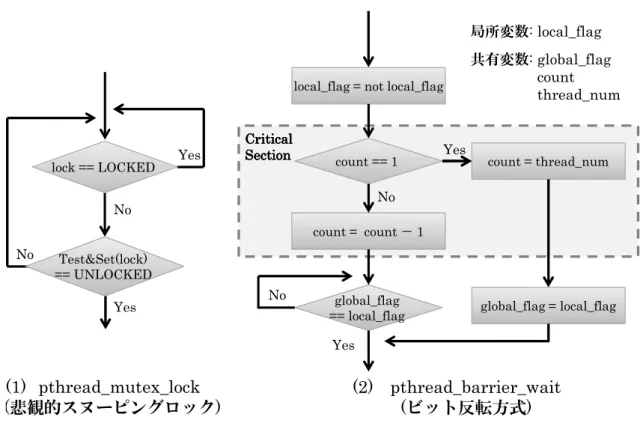
のフローチャートを図 8 の(1)に示す.専用Pthreadライブラリでは,ロックを管理す
るための変数(lock)がロック状態(LOCKED)ではない時だけアトミック命令を実行
する,悲観的スヌーピングロック方式を採用している.これは,アトミック命令を頻繁に 実行するとキャッシュコヒーレンシ要求が頻発し,メモリトラフィック量が爆発的に増加
Yes No No Yes lock == LOCKED Test&Set(lock) == UNLOCKED
local_flag = not local_flag
count == 1 count = count - 1 global_flag == local_flag count = thread_num global_flag = local_flag Yes Critical Critical Critical Critical Section SectionSection Section No Yes No (1) pthread_mutex_lock (悲観的スヌーピングロック) (2) pthread_barrier_wait (ビット反転方式) 局所変数: local_flag 共有変数: global_flag count thread_num
図8: pthread mutex lock()とpthread barrier wait()のフローチャート
してしまうのを回避するためである.その後,クリティカルセクションを抜けるスレッド はpthread mutex unlock()を実行しロックを開放する.
最後に,複数スレッドをあるタスクの完了時に同期させる場合には,pthread barrier wait()
を使用する.提供しているpthread barrier wait()のフローチャートを図8の(2) に示 す.このバリア同期を使用する前に,まずはバリア変数を初期化する必要がある.この
初期化にはpthread barrier init()を使用し,同期させたいスレッドの数を記憶させる
(thread num).その後,pthread barrier wait()に到達したスレッドは,ローカルフラ グ(local flag)を反転させ,バリアに到達したスレッド数をカウンタ(count)で把握する.
もし,自分が同期をとる最後のスレッドではない,つまりカウンタの値が1では無い場合, カウンタをデクリメントする.その後,グローバルフラグ(global flag)がローカルフラ グ(local flag)と一致するまでスピンし続ける.逆に,自分が同期をとる最後のスレッド だった場合,つまりカウンタの値が1の場合,カウンタの値をスレッド数(thread num) で初期化し,グローバルフラグ(global flag)をローカルフラグの値で上書きする.これに より,待機していた他のスレッドはバリアから抜ける事ができる.なお,共有変数count
Core#00
Core#00 Core#01Core#01 Core#02Core#02 Core#03Core#03
I$1 D$1 I$1 D$1 I$1 D$1 I$1 D$1
DDR 物理#0 L$2 #0 L$2 #0 L$2 #2 L$2 #2 L$2 #3 L$2 #3 L2-TAG L2-TAG L2-TAG
L2-DIR L2-DIR L2-DIR L2-DIR
Core#04
Core#04 Core#05Core#05 Core#06Core#06 Core#07Core#07
I$1 D$1 I$1 D$1 I$1 D$1 I$1 D$1
DDR 物理#1 L$2 #0 L$2 #0 L$2 #2 L$2 #2 L$2 #3 L$2 #3 L2-TAG L2-TAG L2-TAG L2-TAG L2-DIR L2-DIR L2-DIR
Core#12
Core#12 Core#13Core#13 Core#14Core#14 Core#15Core#15
I$1 D$1 I$1 D$1 I$1 D$1 I$1 D$1
DDR 物理#3 L$2 #0 L$2 #0 L$2 #2 L$2 #2 L$2 #3 L$2 #3 L2-TAG L2-TAG L2-TAG L2-DIR L2-DIR L2-DIR L2-DIR
Core#08
Core#08 Core#09Core#09 Core#10Core#10 Core#11Core#11
I$1 D$1 I$1 D$1 I$1 D$1 I$1 D$1
DDR 物理#2 L$2 #0 L$2 #0 L$2 #1 L$2 #1 L$2 #2 L$2 #2 L$2 #3 L$2 #3 L2-TAG L2-TAG L2-TAG L2-TAG
L2-DIR L2-DIR L2-DIR L2-DIR
L1Xbar L1Xbar L1Xbar L1Xbar L2Xbar Cluster#0 Cluster#1 Cluster#3 Cluster#2 (a) (a) (a) (a) (b) (b) (b) (b) (c)(c)(c)(c) (c) (c) (c) (c) (d) (d) (d) (d) (d) (d) (d) (d) (e) (e)(e) (e) L$2 #1 L$2 #1 L2-TAG L$2 #1 L$2 #1 L2-DIR L$2 #1 L$2 #1 L2-TAG 図9: リクエストの流れ 他制御を行う. 4.3.2 キャッシュリクエスト キャッシュリクエストが発生するとキャッシュコヒーレンスプロトコルが働き,各コア および各クラスタ間でリクエストが流れる.ここで,リクエストの流れる様子を図 9に示 す.まず,あるコアがロードもしくはストア命令を発行した際,1次キャッシュミスが発 生するとデータを取得するために2次キャッシュに向けてリクエストを送信する必要があ る.そのため,参照アドレスから要求するデータを担当するバンクを割り出し,該当バン クへキャッシュリクエストを送信する(a).そして,2次キャッシュの各バンクに付属さ れるL2-TAGを参照することで,キャッシュラインの状態を知ることができる.また同 時に,クラスタ内に属する他の1次キャッシュの状態を取得でき,必要があればInvalid 化やShared化などのコヒーレンシ要求を該当コアに向けて送信する(b). また,2次キャッシュがInvalid状態の場合には,メモリもしくは他のクラスタが持つ 2次キャッシュからデータを取得する必要があるため,さらにキャッシュリクエストを伝
播させる必要がある.この時,キャッシュリクエストは該当データを保持する主記憶を持 つクラスタへ送信することになる(c).ここで,主記憶にデータを保持するクラスタにお いて,参照すべき同一番号のバンクを管理するL2-DIRは,要求データに対して全クラス タの2次キャッシュのライン状態を保持している.要求元以外のクラスタにもデータが キャッシュされていなければ主記憶アクセスが発生し,メモリからデータを取得できた時 点で要求元クラスタへデータとともにAckを返す.またこの際,L2-DIRにおける要求元
クラスタのライン状態をInvalidからExclusiveに変更する.一方で,Ackを受け取った
クラスタ側では,受け取ったデータを2次キャッシュに格納しL2-TAGの状態を更新す る.そして,データを1次キャッシュに伝搬する. 一方で,要求元以外のクラスタにデータがキャッシュされている場合には,Invalid化 やShared化などのコヒーレンシ要求およびデータの転送要求を該当クラスタへ送信する (d).しかし,要求を受け取ったクラスタ側では,クラスタ内に属する1次キャッシュの状 態を考慮しコヒーレンシ要求を送信しなければならない場合がある(e).もし,要求デー タを持つ1次キャッシュが存在し,キャッシュラインの状態がModifiedであるならばそ のデータを2次キャッシュに書き戻す必要がある.ここで,1次キャッシュはMESIプロ トコルにより管理されているため,データ転送要求を受け取った際にはデータを伝播する 必要が生じる.また,要求元のコアがストア命令を発行していた場合には,該当クラスタ にInvalid化要求が到達する.その際,クラスタに属する1次キャッシュのキャッシュラ インも無効化するために,データをキャッシュしている1次キャッシュにInvalid化要求 を伝搬する必要も出てくる. データ転送要求を受け取ったクラスタは,コヒーレンシ要求に応じてL2-TAGの状態 を更新し要求データとともにAckを返す.そして,Ackを受け取ったクラスタすなわち 該当データを保持する主記憶を持つクラスタでは,変更した他クラスタのL2-TAGの状 態を記憶するためにL2-DIRを更新し,転送されてきたデータとともに要求元クラスタへ Ackを返す.以降は,主記憶アクセスが発生する場合と同様の処理を適用する.このよう に,全ての要求にAckが返ってくると1つのキャッシュリクエストに対する処理が完了 する. 4.3.3 リクエストの衝突と優先順位 各コアからのキャッシュリクエストが頻繁に飛び交うようになると,キャッシュリク エストやメモリリクエスト,コヒーレンシ要求の衝突が発生することになる.ここで,複 数のコアから同時にキャッシュリクエストが発生した様子を図 10に示す.図10中では2 つのコアから2次キャッシュの異なるバンクへ参照リクエストが発生している.この場合
Core#00
Core#00 Core#01Core#01 Core#02Core#02 Core#03Core#03
I$1 D$1 I$1 D$1 I$1 D$1 I$1 D$1
DDR 物理#0
L$2
#0
L$2
#0
L$2
#1
L$2
#1
L$2
#2
L$2
#2
L$2
#3
L$2
#3
L1Xbar
Request Request Request 図10: 異なるバンクへの参照リクエスト Core#00Core#00 Core#01Core#01 Core#02Core#02 Core#03Core#03
I$1 D$1 I$1 D$1 I$1 D$1 I$1 D$1
DDR 物理#0
L$2
#0
L$2
#0
L$2
#1
L$2
#1
L$2
#2
L$2
#2
L$2
#3
L$2
#3
L1Xbar
Request Request 図11: 同一バンクへの参照リクエスト には,2.2.1項で述べたように,複数コアからのリクエストを同時に受け付けることがで き,並列して要求に応じることができる.次に,同時に同一バンクへキャッシュリクエス トが発生した様子を図 11に示す.もし同一バンクへ参照リクエストが同時に発生した場 合には,バンク内でキャッシュリクエストを順位付けし,優先されたリクエストから順に 処理を進める必要がある.この際に,優先されたリクエストすなわちリソースを獲得でき たリクエストは,該当バンクに対してロックを掛けることで他のリクエストを待機させ, キャッシュとメモリ間の一貫性を保持する.そして処理が終わり次第,ロックを解放する ことで次のリクエストに対する処理に移る.その後,待機していたリクエストは再び順序 付けがなされ,リソースを獲得できた順から参照リクエストに対する処理が遂行される. ここで,2次キャッシュへの参照リクエストだけでなく,1次キャッシュへのコヒーレン シ要求やクラスタ間のリクエストの伝播時においても一貫性を保持するためにこうした順 序付けが必要になる.Core#00
Core#00 Core#01Core#01 Core#02Core#02 Core#03Core#03
I$1 D$1 I$1 D$1 I$1 D$1 I$1 D$1
DDR 物理#0 L$2 #0 L$2 #0 L$2 #1 L$2 #1 L$2 #2 L$2 #2 L$2 #3 L$2 #3 L1Xbar Request Request Core#00
Core#00 Core#01Core#01 Core#02Core#02 Core#03Core#03
I$1 D$1 I$1 D$1 I$1 D$1 I$1 D$1
DDR 物理#0 L$2 #0 L$2 #0 L$2 #1 L$2 #1 L$2 #2 L$2 #2 L$2 #3 L$2 #3 L1Xbar Request Request
①
②
③
④
④
①
②
③
(1)Cycle%PENUM=0の時
(2)Cycle%PENUM=1の時
図12: ラウンドロビン方式によるリクエスト優先順位の決定 さて,キャッシュリクエストの順序付けにはいくつかの方法が考えられる.最も簡単な ものに,要求元のコア番号に応じて優先度を変える方法が挙げられる.例えば,2つのコ アから同時に参照リクエストが到達した場合には,コア番号の小さいリクエストを優先す る手法が存在する.この方法では,複雑な機構を必要とせずにハードウェア物量を最小限 に抑えることができるが,優先度の低いコアからの要求にリソースが回りにくくなるとい う欠点がある.そのため,複数のコアが頻繁にキャッシュリクエストを送信するような状 況では,優先度の最も低いコアの参照リクエストはいつまでもリソースを獲得できず一種 の飢餓状態になってしまう恐れがある. 次に,サイクル毎のラウンドロビン・スケジューリング方式により順序付けする方法が 挙げられる.この手法では,処理待ちの参照リクエストに対し,サイクル毎に優先度を変 更することで,コア番号依存の方式におけるリソーススタベーションの問題を解決でき る.またこの手法は比較的実装が容易であるため,追加ハードウェア量も少なくすむとい う利点がある.しかし,各リクエストの転送速度の違いを考慮していないため,必ずしも 最適な処理順序付けができるわけではない. 最後に,参照リクエストの要求順に応じて優先度を変える方法が挙げられる.この方法 では,全てのコアにおけるロード・ストア命令の発行順に応じてリソースが割り与えられ る.そのため,最もリソースを公平に利用することができる.しかし,要求順を記憶する ためにリクエストキューを管理する機構が必要になるなど,追加ハードウェア量が増大し てしまう. 開発するメニーコアトレースシミュレータでは,追加するハードウェア量やキャッシュ リクエストの処理効率の両方を考慮して,サイクル毎のラウンドロビン・スケジューリング方式を採用する.ラウンドロビン方式によるリクエスト優先順位の決定の様子を図 12に示す.この方式では,どのコアからの処理を優先するかサイクル毎に変更する.こ れは,シミュレーション実行開始時からの経過サイクル Cycle をクラスタに属するコア 数P EN U M で割った余りの値を用いて優先度の最も高いコアを決め,そのコアから順 にリクエストの有無を確認することで実現する.例えば,図12(1) で示される状況では, Cycle%P EN U M = 0であるため,コア#00の優先度が最も高い.そのため,同じ時刻 にコア#03が,コア#00と同じバンクへリクエストを送信していたとしても,コア#00 のリクエストが優先的に処理される.図12(2)は,図12(1)の次のサイクルにおけるリク エストの優先順位を表している.前のサイクルで最も優先度の高かったコアからのリクエ ストは,次のサイクルで優先順位が決定する場合には最も優先度が低くなる.
5
シミュレータの動作検証
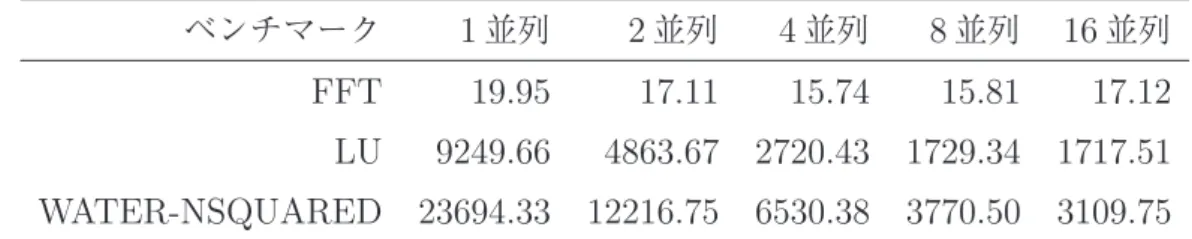
開発したシミュレータ上でベンチマークプログラムを実行し,各プログラムの特徴を調 査することで今後メニーコア研究を進めていくためのシミュレータとして妥当であるかを 検証した. 5.1 動作環境 シミュレータは単命令発行のSPARC V9アーキテクチャをベースとしている.評価に 用いたパラメータを表 2に示す.プロセッサ構成は,4.1節で述べたように,16コア内 蔵の2階層型クロスバ結合のcc-NUMAアーキテクチャとなっている.また,動作検証 の初期段階であることを考慮して,データ管理の複雑度を抑えるために,データキャッ シュの構成としてダイレクトマップ方式を採用している.動作検証対象のプログラムに は,汎用ベンチマークプログラムであるSPLASH-2 ベンチマーク[17]からFFT,LU, WATER-NSQUAREDの3つを用いた.なお,本評価では1サイクル毎に全コアの動作 およびキャッシュシステム,メモリの動作をシミュレートする方法をとっている. 5.2 動作結果 各プログラムを1,2,4,8,16スレッド実行でそれぞれシミュレートした.このとき, 各コアには1スレッドずつ割り当てて実行している.SPLASH-2 FFTの実行結果を表 3 に,LUの実行結果を表 4に,WATER-NSQUAREDの実行結果を表 5に示す.表の各 項目は左から順に,コア番号を示す pid,発行命令数を示す step,命令実行サイクル数 を示す exec,I1キャッシュミスにおける待ちサイクル数を示す I1wait,D1キャッシュ表2: シミュレータ諸元
Processor SPARC V9
number of cores 16 cores
number of clusters 4 clusters
issue width single issue
issue order in-order
register windows 8 sets
I1 cache 16 KBytes
line size 64 Bytes line
ways 4 ways
latency 1 cycle
D1 cache 16 KBytes
line size 64 Bytes line
ways 1 way
latency 1 cycle
D2 cache 16 MBytes
number of banks 4 banks
line size 64 Bytes line
ways 1 way
latency 8 cycles
Memory 256 MBytes
latency 32 cycles
Cache Coherency Protocol
L1 cache MESI
L2 cache MOESI
Interconnect Network 2-Layer Cross Bar Topology
link latency 8 cycles
ミスにおける待ちサイクル数を示すD1wait,総実行サイクル数を示す cycleとなってい
る.また,I1キャッシュとD1キャッシュのキャッシュヒット率を別途算出し,それぞれ
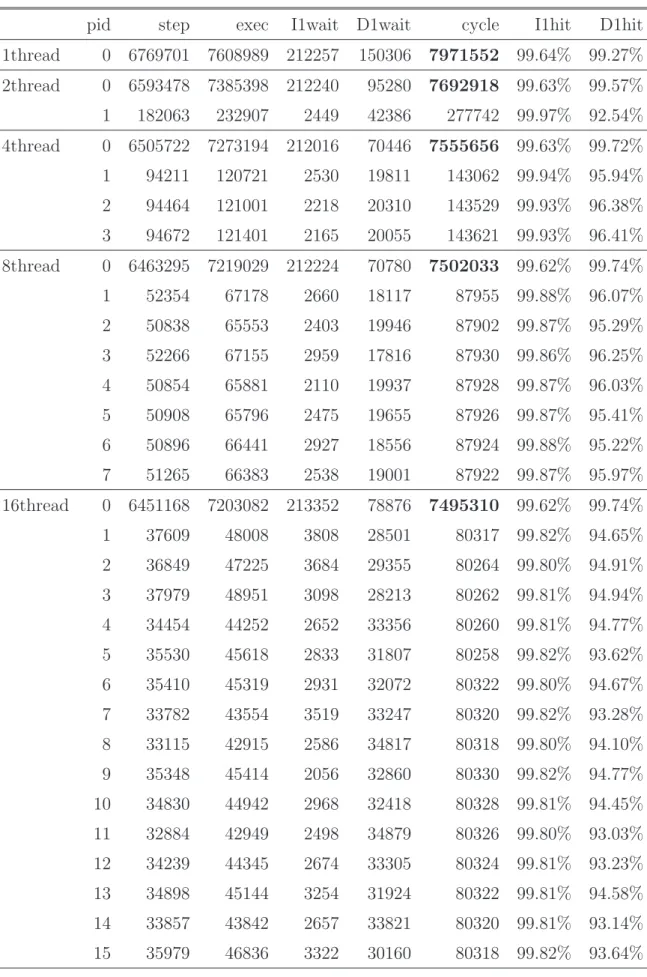
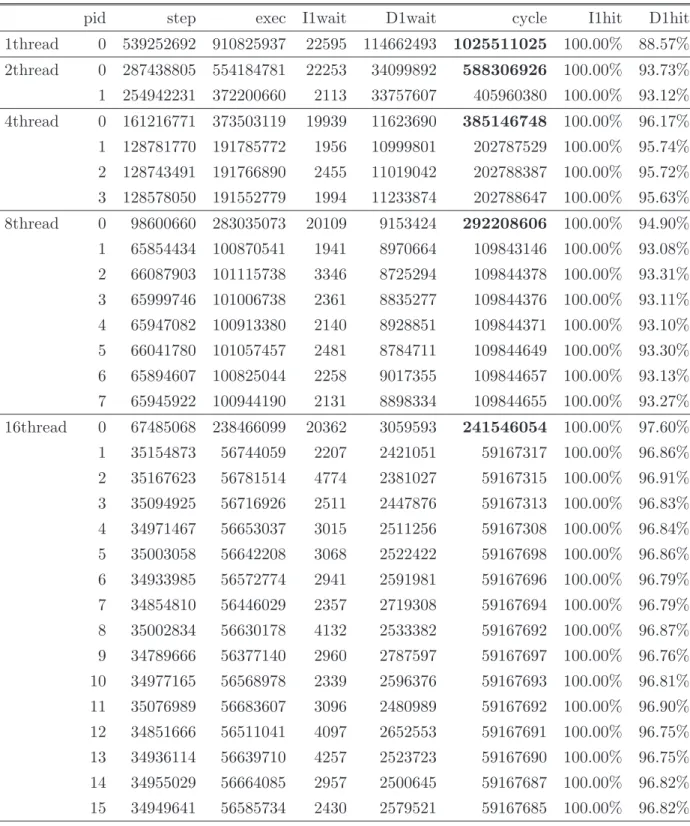
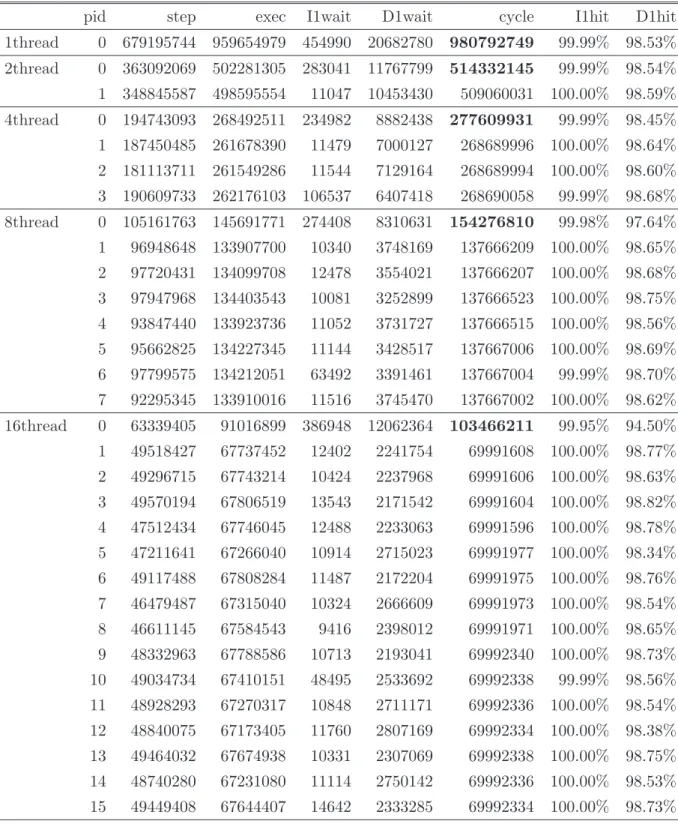
表3: 実行サイクル数(SPLASH-2 FFT)
pid step exec I1wait D1wait cycle I1hit D1hit 1thread 0 6769701 7608989 212257 150306 7971552 99.64% 99.27% 2thread 0 6593478 7385398 212240 95280 7692918 99.63% 99.57% 1 182063 232907 2449 42386 277742 99.97% 92.54% 4thread 0 6505722 7273194 212016 70446 7555656 99.63% 99.72% 1 94211 120721 2530 19811 143062 99.94% 95.94% 2 94464 121001 2218 20310 143529 99.93% 96.38% 3 94672 121401 2165 20055 143621 99.93% 96.41% 8thread 0 6463295 7219029 212224 70780 7502033 99.62% 99.74% 1 52354 67178 2660 18117 87955 99.88% 96.07% 2 50838 65553 2403 19946 87902 99.87% 95.29% 3 52266 67155 2959 17816 87930 99.86% 96.25% 4 50854 65881 2110 19937 87928 99.87% 96.03% 5 50908 65796 2475 19655 87926 99.87% 95.41% 6 50896 66441 2927 18556 87924 99.88% 95.22% 7 51265 66383 2538 19001 87922 99.87% 95.97% 16thread 0 6451168 7203082 213352 78876 7495310 99.62% 99.74% 1 37609 48008 3808 28501 80317 99.82% 94.65% 2 36849 47225 3684 29355 80264 99.80% 94.91% 3 37979 48951 3098 28213 80262 99.81% 94.94% 4 34454 44252 2652 33356 80260 99.81% 94.77% 5 35530 45618 2833 31807 80258 99.82% 93.62% 6 35410 45319 2931 32072 80322 99.80% 94.67% 7 33782 43554 3519 33247 80320 99.82% 93.28% 8 33115 42915 2586 34817 80318 99.80% 94.10% 9 35348 45414 2056 32860 80330 99.82% 94.77% 10 34830 44942 2968 32418 80328 99.81% 94.45% 11 32884 42949 2498 34879 80326 99.80% 93.03% 12 34239 44345 2674 33305 80324 99.81% 93.23% 13 34898 45144 3254 31924 80322 99.81% 94.58% 14 33857 43842 2657 33821 80320 99.81% 93.14% 15 35979 46836 3322 30160 80318 99.82% 93.64%