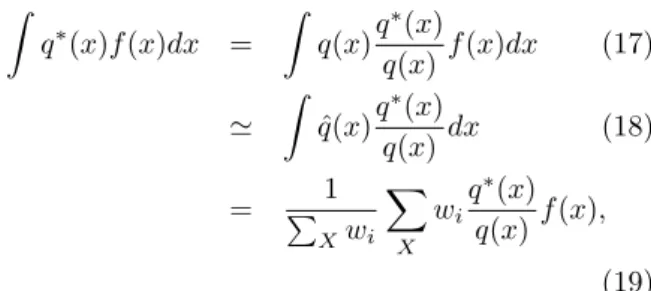リサンプリングを用いたポピュレーションメカニズム:確率モデ
ルを用いた最適化
Maintaining Population with Resampling for Optimization Methods
based on Probability Models
比護 貴之
1∗高玉 圭樹
1Takayuki Higo
1and Keiki Takadama
21
東京工業大学 大学院総合理工学研究科
1
Graduate School of Interdisciplinary Science and Engineering, Tokyo Institute of Technolog
2
電気通信大学 電気通信学部
2
The University of Electro-Communications, Faculty of Electro-communications
Abstract: This paper focuses on Optimization Methods based on Probability Models (OMPM) that statistically estimate the distribution of promising solutions from obtained samples and draw new samples from the estimated distribution, and proposes a novel method for OMPM to improve the accuracy of the statistical estimations by maintaining the previously generated samples more precisely than the conventional methods like Estimation of Distribution Algorithms. The key idea of the proposed method is to update the population (i.e., the set of samples) to follow the target distribution by weighting generated samples and resampling them according to importance sampling. Experimental comparisons between the proposed method and a conventional method have revealed the following two advantages of the proposed method: (1) the proposed method finds better solutions than the conventional method; and (2) the proposed method can control the convergence speed.
1
Introduction
Recently, Optimization Methods based on Probabil-ity Models (OMPM), for example, Estimation of Dis-tribution Algorithms (EDAs) [2] and Cross Entropy method (CE) [8], have been developed quickly. These methods iterate the following two procedures: (1) building a probability model of promising solutions from previously generated samples and (2) generating new samples from the estimated probability model. Since the statistical estimation plays a central role, various machine learning techniques such as Bayesian Networks were introduced so far [6].
The accuracy of the estimation depends on not only the way of building probability models but also both the quality and the quantity of the samples. One feature of OMPM is a population, whose role is to store a part of generated samples. The next popu-lation is generated from both the current popupopu-lation and the newly generated samples so that the popula-tion becomes a set of promising solupopula-tions with a cer-tain diversity. As a result, the population can guide promising areas. This concept comes from Genetic Al-gorithms [1] and some population maintenance tech-niques were proposed[9]. Of course, they are used in some OMPM and one of the most successful method with maintaining the population is hierarchical Baysian
∗連絡先:東京工業大学 大学院総合理工学研究
〒 226-8502 神奈川県横浜市緑区長津田町 4259-J2-53 [email protected]
Optimization Algorithm (hBOA) [5], however the log-likelihood with respect to the target distribution , which is explained in Section 2, is no longer able to be calculated because the distribution of the population is untraceable. On the other hand, basic EDAs and CE can be calculte it because the previous population is completely discarded.
If all generated samples can be stored, actually, there is the optimal method in terms of importance sampling [7]. Therefore, the difficulty in population maintenance is to trece the distribution of the popula-tion. This paper proposes a novel method, which sim-ulate the population to follow the target distribuion by weighting generated samples and resampling them according to importance sampling. The aim of this paper is to investigate the effectiveness of the pro-posed method through experimental comparison with a conventional method, Univariate Marginal Distri-bution Algorithm (UMDA) [4], by applying them to a 2D Ising model.
The outline of the paper is as follows: Section 2 explains OMPM from two different viewpoints, EDAs and CEs. Section 3 describes the proposed method. In Section 4, the proposed method is experimentally compared with a conventional method. Section 5 dis-cusses advantages of the proposed method. Finally, Section 6 concludes our paper.
SIG-DMSM-A701-13 (7/26)
人工知能学会研究会資料
2
Optimization Method based on
Probability Models
The following section provides two viewpoints for Op-timization Method based on Probability Models (OMPM): (1) Estimation of Distribution Algorithm (EDA) and (2) the Cross Entropy method (CE). Both of them are basically the same. While EDA uses a selection oper-ator, CE uses importance sampling instead of using a selection operator.
2.1
Estimation of Distribution
Algo-rithm (EDA)
Estimation of Distribution Algorithms (EDAs) [2] are mainly developed in the area of Evolutionary Com-putation and they can be considered as mathemati-cal representations of Genetic Algorithms. Univariate Marginal Distribution Algorithm (UMDA) [4] is one of basic EDAs. In this paper, EDA is defined as a generalization of UMDA.
A briefe algorithm of EDA is summarized as fol-lows: At the beginning, samples (i.e., candidate so-lutions) are generated randomly as the initial pop-ulation. To update the current population, first, a probability model of the population is built, and then samples are generated form the probability model. Promising solutions in the generated samples are se-lected as the next population by means of a selection operator. Note that the population is completely re-placed by a part of newly generated samples. The pseudo-code of the EDA is shown in Fig. 1.
In general, Maximum likelihood (ML) estimation is used for building a probability model in EDAs. Let p(x) and q(x) be a probability model and a target probability distribution, respectively. ML estimation selects the probability model which maximizes the (expected) log-likelihood defined as follows:
L(p(x)) = ∫
q(x) log p(x)dx. (1) In practice, an empirical log-likelihood is used for an estimator of the log-likelihood. By using given sam-ples X which are generated by q(x), the empirical log-likelihood is calculated as follows:
L(p(x))' 1 N
∑
X
log p(x), (2)
where N is the number of samples X.
In the calculation of building a probability model of a population Xpop, it is assumed that Xpopis
gener-ated from a certain target distribution q(x) . The tar-get distribution is naturally defined by the employed selection operator. For example, employing the trun-cation selection operator, which selects samples whose evaluation f (x) are less than a threshold ˜f in a
mini-mization problem, equals1to defining q(x) as follows: q(x) = 1 Zq(x),˜ (3) ˜ q(x) = I(f (x) < ˜f ) (4) = { 1 f (x) < ˜f 0 else , (5)
where I(·) is an indicator function and Z is a normal-izing constant defined as follows:
Z = ∫
˜
q(x)dx. (6) In this paper, this probability distribution is called partially uniform distribution. Another candidate of the target distribution is the Boltzmann distribution[3].
2.2
Cross Entropy method (CE)
Cross Entropy method (CE) [8] is firstly proposed as a sampling method in the area of rare event simula-tions. The difference from the EDA is that the target distributions described in Section 2.1 are explicitly de-fined instead of using a selection operator. In CE, the empirical log-likelihood is calculated from the previ-ously generated samples Xsamp(t) through importance
sampling [7] as follows: L(pt+1(x))' 1 M ∑ Xsamp(t) qt+1(x) pt(x) log pt+1(x), (7)
where Xsamp(t) is generated from pt(x). Even if we only
know the value ˜qt+1(x) and/or ˜pt(x) which are
propor-tional to qt+1(x) and pt(x), respectively, the empirical
log-likelihood is calculated as follows: L' ∑ 1 X(t)samp ˜ qt+1(x) ˜ pt(x) ∑ Xsamp(t) ˜ qt+1(x) ˜ pt(x) log pt+1(x). (8)
Validity of this calculation is confirmed by the follow-ing equations: 1 = ∫ q(x) p(x)p(x)dx (9) ' 1 M ∑ p(x) q(x) p(x) (10) = 1 M Zp Zq ∑ p(x) ˜ q(x) ˜ p(x), (11) 1 ∑ p(x) ˜ q(x) ˜ p(x) ' 1 M Zp Zq , (12)
1We assume that ML estimation gives perfect probability
EDA
1 Generate samples Xpop(1) ={xi}N1 from the uniform distribution p1(x). t⇐ 1.
2 do{
3 Build a probability model pt(x) of X
(t)
pop.
4 Generate samples Xsamp(t) ={xi}M1 from pt(x).
5 Select promising solutions as the next population Xpop(t+1)={xi}N1 from X (t)
samp.
6 t⇐ t + 1.
7 }until(stopping criterion reached)
Figure 1: The pseudo-code of EDA
where Zpand Zq are the normalizing constants of ˜p(x)
and ˜q(x), respectively,∑p(x)means a summation over samples according to p(x), and M is the number of the samples. Note that the empirical log-likelihood is just an estimator and the accuracy (e.g., the variance) depends on the similarity between pt(x) and qt+1(x).
3
Population Maintenance with
Resampling
In EDA and CE, the population is completely re-placed by a part of the newly generated samples. This is because it becomes difficult to calculate the log-likelihood with respect to the target distribution if the previous population and the generated samples are simply mixed. However, if all generated samples are stored, the log-likelihoods is calculated with im-portance sampling as follows:
L' 1 |X| ∑ X qt+1(x) ∑ i≤tαipi(x) log pt+1(x), (13)
where X is a set of all samples generated from all built probability models and αi is the ratio of the number
of samples generated from pi(x).
This section explains the proposed method named Resampling Population Model (RPM). RPM keeps a finite number of historical samples, with approximat-ing Eq. (13). In RPM, the population is not only a set of histroical samples, but also represents an approxi-mating distribution of the target distribution. For ap-proximating the target distribution, weight is added for each sample in the population.
In the following, firstly, a generalization of impor-tance sampling is explained. By using this, the popu-lation can represent the target distribution. Secondly, the basic framework of RPM is explained. Finlally, for making the details clear, the overall procedure is explained.
3.1
Generalized Importance Sampling
By using a set of samples X and its probability dis-tribution p(x), we can construct ˆq(x) as an approxi-mating distribution of q(x) as follows:
ˆ q(x) = ∑1 Xwi ∑ xi∈X wiδ(x− xi), (14) wi ∝ q(xi) p(xi) f or xi ∈ X, (15)
where δ(·) is the delta function. To determine wi
uniquely, we have to define the normalizing constant ∑
iwi, but the properties described in the following
do not depend on the normalizing constant. ˆq(x) can be described by a set of weighted samples{(wi, xi)}Ki=1,
where K is the number of the samples.
The expectation of any function f (x) with respect to ˆq(x) is exactly given by ∫ ˆ q(x)f (x)dx = ∑1 Xwi ∑ X wif (xi). (16) ∑
Xwi has expected value|X| but nonzero variance,
and if ∑Xwi = |X| then this is reduced to normal
importance sampling. (16) gives a consistent but bi-ased estimator of the expection with respect to q(x). This integration can be extended to calculate the ex-pectation with arbitrary q∗(x) as follows:
∫ q∗(x)f (x)dx = ∫ q(x)q ∗(x) q(x)f (x)dx (17) ' ∫ ˆ q(x)q ∗(x) q(x)dx (18) = ∑1 Xwi ∑ X wi q∗(x) q(x) f (x), (19) where wi is defined by (15). If q(x) = q∗(x), (19) is reduced to (16). If q(x) = p(x), (19) is reduced to normal importance sampling. q(x) has the effect only on the normalizing term. Note that this gives a consistent estimator, and an unified interpretation of normal importance sampling and (16).
3.2
Resampling Population Model
If the probability distribution of the population is given, the log-likelihood can be calculated as follows:
L = ∫ ˆ rt(x) qt+1(x) ˆ rt(x) log pt+1(x)dx (20) = 1 |X(t) m| ∑ Xm(t) qt+1(x) ˆ rt(x) log pt+1(x), (21)
ˆ rt(x) = α(t)qˆt(x) + (1− α(t))pt(x), (22) α(t)= |X (t) pop| |X(t) pop| + |Xsamp(t) | , (23) Xm(t)= Xpop(t) ∪ Xsamp(t) (24) where ˆqt(x) is the probability distributin of the
cur-rent population Xpop(t), and X
(t)
samp is the set of
gen-erated samples which follow pt(x) . For the variance
reduction in (21), ˆq(x) should be similar to or the same as q(x). In terms of this, ˆq(x) = q(x) is optimal case, and thus the objective of RPM is to calculate
L(pt+1(x)) = ∫ rt(x) qt+1(x) rt(x) log pt+1(x)dx, (25) where rt(x) = αtqt(x) + (1− αt)pt(x). (26)
Section 3.1 gives a construction method of ˆqt+1(x)
which approximates qt+1(x) for each t as a set of
weighted samples. RPM regards this set as the pop-ulation. Thus the population at time t is denoted by Xpop(t) = {(w (t) i , x (t) i )} N
i=1, where N is the
num-ber of weighted samples in the population. Here we recursively construct each population. Firstly, it is assumed that the initial population follows the uni-form distribution and the initial target distribution q1(x) is also the uniform distribution. Then X
(1)
pop =
{(1, x(1)
i }Ni=1, where each xiis generated from the
uni-form distribution.
Secondly, we calculate (25) with the population through applying the method (19), and then obtain the following: L(pt+1(x)) ' ∫ ˆ rt(x) qt+1(x) rt(x) log pt+1(x)dx (27) ' 1 |X(t) m| ∑ Xsamp(t) qt+1(xi) rt(xi) log pt+1(xi) + 1 |X(t) m| ∑ Xpop(t) w(t)i qt+1(xi) rt(xi) log pt+1(xi), (28) where |Xpop(t)| = ∑ wi(t) = N is assumed. The first term in (28) can be redefined as follows:
1 |X(t) m| ∑ Xsamp(t) w(t)i qt+1(xi) rt(xi) log pt+1(xi), (29) where Xsamp(t) = {(w (t) i , x (t) i )} and w (t) i = 1. Finally, we obtain L = 1 |X(t) m| ∑ Xm(t) wit qt+1(xi) rt(xi) log pt+1(xi), (30)
and the next population is given by ˆ qt+1(x) = 1 ∑ X(t)m w t+1 i ∑ Xm(t) wit+1δ(x− xi), (31) wit+1= wtiqt+1(xi) rt(xi) . (32) (32) is weight update rule.
Since the number of weighted samples in the pop-ulation becomes large as the procedure is iterated, the part of them have to be discarded with keeping some properties. Fot this purpose, the resampling techniqu, which means generating samples from ˆq(x), can be used. For the resampling, Resampling With-Out Replacement (RWOR) is used in this paper for the reason of stability.
3.3
Numerical Calculation Details
The procedure of the proposed method is described as follows: In initialization, the initial population Xpop(1)
and the initial set of generated samples Xsamp(1) are
generated from uniform distribution, and the target distribution q1(x) and the initial sampler p1(x) are
uniform distribution. Firstly, the next target distri-bution qt+1(x) is defined before generating the next
population Xpop(t+1) and the next samples Xsamp(t+1). In
this work, target distributions are defined by partially uniform distributions, which are defined by (5). The next target distribution qt+1(x) is defined so that the
number of samples which satisfies qt+1(x) 6= 0,
be-comes N0(< N ), which is previously given by the cut-off rate c = NN0.
The marginalized set Xm(t)= X
(t)
pop∪ X
(t)
sampis
gen-erated. The weights of the samples in Xm(t) are
up-dated according to Eq. (32) as follows: wit+1= wti 1 α qt(xi) qt+1(xi)+ (1− α) pt(xi) qt+1(xi) . (33)
Since normalizing constants of qt(x) and qt+1(x) are
unknown, they are estimated from the samples. Let Ztand Zt+1be the normalizing constants of qt(x) and
qt+1(x), respectively. For qt(x) qt+1(x), Zt+1 Zt is estimated by Zt+1 Zt ' 1 N ∑ Xpop(t) wi ˜ qt+1(x) ˜ qt(x) . (34)
On the other hand, for pt(x)
qt+1(x), Zt+1is estimated by Zt+1' 1 M ∑ Xsamp(t) ˜ qt+1(x) pt(x) (35)
Note that both Zt+1of (34) and one of (35) are
The next population Xpop(t+1)is generated by RWOR2
from Xm(t)according to the new weights, and then the
weights are normalized so that the sum becomes N3.
The next sampler pt+1(x) is generated not from
Xpop(t+1)but from Xm(t)because Xpop(t+1)is a part of Xm(t)
and thus Xm(t) contains more information. Note that
the empirical likelihood is given by (30). The proba-bility model maximizing the empirical log-likelihood is selected as the next probability model pt+1(x). Then,
the next set of generated samples Xsamp(t+1) are
gener-ated from pt+1(x). The pseudo-code of the algorithm
is shown in Fig. 2.
4
Experiments
We conduct experiments to compare the proposed method, Resampling Population Model (RPM), and a conventional method, Univariate Marginal Distri-bution Algorithm (UMDA) [4], by applying them to a 2D Ising model [5], which has many local optima.
4.1
2D Ising model
For benchmark function, we employ the problem to minimize the energy of a 2D Ising model with periodic boundary conditions. 20× 20 grids are tested. The cost function is given by
f (x) = − 19 ∑ i=0 19 ∑ j=0 {J(xij, xi+1,j) +J (xij, xi,j+1)}, (36) J (xi, xj) = { 1 xi= xj 0 xi6= xj , (37)
where xij ∈ {0, 1} ,x20,j = x0,j, and xi,20 = xi,0.
This problem has many local optima and two global optima, (0, 0,· · · , 0) and (1, 1, · · · , 1). The optimum cost function value is−800.
Since partially uniform distribution can not pre-cisely control the convergence speed when many solu-tions have the same cost function value , the original cost function f (x) is changed by adding small random number ² as follows:
f0(x) = f (x) + ². (38) In this experiments, ² is u×10−10, where u is a random number uniformly distributed from 0 to 1.
2After applying RWOR, selected samples whose weights are
0 are removed, even if the number of selected samples is less than N . This is because the target distributions are defined according to not the weights of the samples but the number of the samples.
3There is no need that the number of weithted samples and
the sum of their weights are the same value. For the simplicity, we assume this in this paper.
4.2
Experimental Setup
We employ the simplest probability model defined as follows: p(x|w) = 19 ∏ i=0 19 ∏ j=0 p(xij|wij). (39)
This probability model is also used in UMDA. The parameters of RPM are set at combinations of the values described as follows:
• The number of samples in the population N: 50, 100, 200
• The number of generated samples M: 10, 50, 100, 200
• Cutoff rate c: 0.01, 0.05, 0.1, 0.2
The definitions of these parameters are described in Section 3.3.
The parameters of UMDA are set at combinations of the values described as follows:
• The number of samples in the population N = M× c
• The number of generated samples M: 50, 100, 200, 400
• Cutoff rate c: 0.1, 0.3, 0.5, 0.7
The cutoff rate is defined by c = MN and the definitions of the other parameters are described in Section 2.1.
Since the cutoff rates of RPM and UMDA is sim-ilar but it is experimentally known that they have different effect, the cutoff rates are experimentally de-termined. The optimization process is stopped when the variance of the cost function value over samples in the population becomes less than 1× 10−10 or the number of function evaluations becomes more than 2× 106.
5
Results
Tables 1 and 2 show the results of RPM and UMDA, respectively. In both tables, the numbers in the first row represent the values of the cutoff rates. In Ta-ble 1, the numbers in the first column and the second column represent the number of samples in the popu-lation and the number of generated samples, respec-tively. In the first column in Table 2, the numbers of generated samples are shown. The values in the other cell represent the averages with the standard devia-tions between parenthesis of the cost function value of the best obtained solutions over 10 independent runs. The results show that the cases with storing the more samples can find the better solutions for the both methods. Note that the best value in 10 trails can be estimated by the average minus the standard deviation and the numbers of stored samples in RPM and UMDA are N + M and M , respectively. How-ever, the average of RPM with N = 200 are a little
Resampling Population Model 1 Generate the initial population Xpop(1) and the initial samples X
(1)
sampfrom the uniform
distribution. t⇐ 1. 2 do{
3 Generate the target distribution qt+1(x).
4 Reweight each sample (wi, xi)∈ X
(t) m = X (t) pop∪ X (t) sampaccording to (32).
5 Generate the next population Xpop(t+1) ={(1, xi)}Ni=1 by RWOR from X
(t)
m, and
normalize the weights so that∑X(t+1)
pop
wi= N .
6 Build a probability model pt+1(x) from X
(t)
m according to (30).
7 Generate samples Xsamp(t+1)={(1, xi)}Mi=1 from pt+1(x).
8 t⇐ t + 1.
9 }until(stopping criterion reached)
Figure 2: The pseudo-code of the resampled population model
worse than the other cases. This is because the 2D Ising model have the two global optima, and therefore the built probability models tend to be the uniform distribution, which cannot generate promissing solu-tions. For generating promissing solutions, the pop-ulation need to be biased in this problem. Smaller number of samples in the population tend to become biased than larger number of samples. The averages in some cases of RPM are less than −700 while the averages in any cases of UMDA are not. Therefore, we can say that RPM outperforms UMDA in terms of the number of stored samples.
Tables 3 and 4 show the number of the function evaluations in RPM and UMDA, respectively. Since so many cases of RPM are experimented a part of them are shown in Table 3. The numbers in the first column represent the averages of the number of func-tion evaluafunc-tions over 10 independent runs. By com-parison with cases which use roughly the same number of function evaluations, RPM outperforms UMDA ex-cluding a few exceptions. This indicate that RPM can use histrical samples more effectively than UMDA. The results also show that the cutoff rate in RPM controls the convergence speed better than UMDA.
6
Discussions
6.1
Quality of Population
The quality of a population depends on both the aver-age of the cost function value over the samples in the population and the diversity of the population, (e.g., entropy∫ q(x) log q(x)dx). When building a probabil-ity model of a population Xpop and generating
sam-ples Xsamp, samples in Xsamp will be worse in the
cost function value than samples in Xpop because the
statistical estimation is just smoothing method under the smoothing assumption, where xi' xj → f(xi)'
f (xj). The strategies of EDA and CE, where the
cur-rent population is completely discarded, may decrease the average value of the population. In the proposed method, the selected samples are incorporated into the population and a part of the population is dis-carded.
On the other hand, it is also important to keep the diversity of the population for escaping local optima. In the proposed method, a part of samples in the pop-ulation is discarded so that the poppop-ulation follows to the target distribution. In other words, samples in both the population and the generated samples with high p(x), from which the samples are generated, tend to be discarded because there will be many samples in areas with high p(x). As a result, the diversity of the population is kept approximately according to the diversity of the target distribution.
6.2
Control of Convergence Speed
The diversity of a population depends on the thresh-old of the target distribution. Since the threshthresh-old is monotonically decreased in the proposed method, the convergence is guaranteed. However, in UMDA, the threshold depends on the generated samples. Since the generated samples are unstable, the cutoff rate can not control the convergence speed. As the results show, slower convergence is important to find better solutions ,and thus the ability to control the conver-gence speed is an advantage of RPM.
7
Conclusions
This paper proposed Resampling Population Model, where a part of the historical samples are stored as a population to follow the target distribution from the viewpoint of importance sampling. Experimental comparisons between the proposed method and the conventional method (UMDA) have revealed the fol-lowing two advantages of the proposed method: (1) the proposed method finds better solutions than the conventional method and (2) the proposed method can control the convergence speed.
References
[1] David E. Goldberg. Genetic Algorithms in Search, Optimization and Machine Learning. Addison-Wesley Publishing Company, 1989.
Table 1: Average of Best Value for Resampling Population Model Population N Samples M c = 0.01 c = 0.05 c = 0.1 c = 0.2 50 10 -675.6 (12.18) -648.4 (24.96) -589 (25.62) -527.8 (34.1) 50 50 -716.4 (13.72) -706 (12.79) -686.2 (14.98) -636.8 (19.67) 100 10 -722.4 (14.84) -646.6 (20.7) -587.2 (20.03) -521.8 (32.71) 100 50 -749.8 (17.9) -720.6 (10.42) -692.4 (26.29) -622 (38.41) 100 100 -750.4 (9.23) -730 (9.52) -721.6 (19.04) -660.2 (21.78) 200 50 -676.8 (81.84) -700 (32.06) -673.8 (14.8) -594.2 (58.18) 200 100 -719.2 (47.97) -715.2 (36.65) -701.4 (24.66) -651.4 (16.68) 200 200 -729.6 (42.45) -740.2 (13.11) -716.4 (13.82) -664 (32.66)
Table 2: Average of Best Value for UMDA
Samples c = 0.1 c = 0.3 c = 0.5 c = 0.7 50 -528.8 (11.04) -592.4 (10.86) -604.6 (12.4) -596.8 (11.24) 100 -588.8 (11.9) -644.8 (17.44) -644.8 (18.72) -640.4 (14.69) 200 -629.2 (12.69) -661.8 (8.56) -676.2 (13.48) -676.6 (13.33) 400 -657.2 (8.12) -684.2 (14.28) -682.8 (6.27) -695 (16.74)
Table 3: The Number of Function Evaluations for Population Resampling Model Evaluations Best Population N Samples M Cutoff c
1081960 -729.6 200 200 0.01 418330 -750.4 100 100 0.01 224165 -749.8 100 50 0.01 99360 -730 100 100 0.05 94320 -716.4 200 200 0.1 46170 -720.6 100 50 0.05 40610 -701.4 200 100 0.1 36800 -664 200 200 0.2 19385 -692.4 100 50 0.1 17950 -660.2 100 100 0.2 17180 -651.4 200 100 0.2 7720 -636.8 50 50 0.2 7245 -622 100 50 0.2 5542 -646.6 100 10 0.05 2277 -587.2 100 10 0.1 850 -521.8 100 10 0.2
Table 4: The Number of Function Evaluations for UMDA Evaluations Best Samples M Cutoff c
113400 -657.2 400 0.1 51920 -684.2 400 0.3 49660 -629.2 200 0.1 33960 -682.8 400 0.5 ]23120 -695 400 0.7 21760 -661.8 200 0.3 19090 -588.8 100 0.1 14880 -676.2 200 0.5 10460 -676.6 200 0.7 9070 -644.8 100 0.3 7040 -528.8 50 0.1 6130 -644.8 100 0.5 4070 -640.4 100 0.7 3575 -592.4 50 0.3 2425 -604.6 50 0.5 1670 -596.8 50 0.7
[2] Pedro Larranaga and Jose A. Lozano, editors. Es-timation of Distribution Algorithm. Kluwer Aca-demic Publishers, 2002.
[3] Thilo Mahnig and Heinz Muhlenbein. A new adaptive boltzmann selection schedule sds. In Proceedings of the 2001 Congress on Evolutionary Computation, 2001.
[4] Heinz Muhlenbein and Gerd Paass. From recom-bination of genes to the estimation of distributions i. binary parameters. In Parallel Problem Solving from Nature IV, pages 188–197, 1996.
[5] Martin Pelikan and David E. Goldberg. Hierarchi-cal boa solves ising spin glasses and maxsat. In Ge-netic and Evolutionary Computation Conference 2003 (GECCO-2003), pages 1271–1282, 2003. [6] Martin Pelikan, David E. Goldberg, and Erick
Cant´u-Paz. BOA: The Bayesian optimization al-gorithm. In Proceedings of the Genetic and Evolu-tionary Computation Conference GECCO-99, vol-ume I, pages 525–532, 1999.
[7] Reuven Y. Rubinstein. Simulation and the Monte Carlo Method. Wiley-Interscience, 1981.
[8] Reuven Y. Rubinstein and Dirk P. Kroese. The Cross-Entropy Method. Springer, 2004.
[9] Hisashi Shimodaira. An empirical performance comparison of niching methods for genetic algo-rithms. IEICE transactions on information and systems, E85-D(11):1872–1880, 11 2002.