LMNtal による状態空間探索への ヒューリスティック探索の導入
提出日 : 2015 年 1 月 24 日 指導 : 上田 和紀 教授
早稲田大学基幹理工学研究科 情報理工学専攻
学籍番号 : 5113B017-2
小沼 賢
ソフトウェアは社会を構成するシステムにおいて非常に重要な技術となっており,社会 に深く浸透している.同時に,ソフトウェアの信頼性や安全性を高めることが重要となっ ている.そこで近年では,形式手法の一つであるモデル検査が注目を集めている.モデル 検査はシステムを状態遷移系で記述し,網羅的探索を行う検証手法である.
並列モデル検査器SLIMは,階層グラフ書換えに基づく並行言語LMNtalを状態遷移系 記述言語として持つLMNtalの実行時処理系である.LMNtalは階層グラフ書換えに基づ く並行言語モデルであり,アトム,膜,リンクによって構成されるグラフを動的に書き換 えていくことで計算が進行する.LMNtalは並行処理を容易に記述可能であり,高い表現 力を持っていることから,様々なシステムや計算モデルが扱える.SLIMは全実行経路を 出力する非決定実行やモデル検査機能を持ち,これらの機能は状態空間構築機能により実 現している.SLIMにおける状態空間構築機能は,LMNtalの階層グラフ構造を状態,グ ラフ書換えを状態遷移として状態空間の構築と探索を行うことで実現している.状態空間 構築・探索処理は一般にコストの高い処理であり,大規模化と高速化を目指した並列化な どさまざまな最適化が行われている.
現在のSLIMにおける状態空間構築では深さ優先等により機械的にすべての状態の探索 を行っている.しかし,経路探索の問題等ではすべての状態の構築・探索を行う必要はな く,初期状態から目標状態までの最適な経路の取得が目的である.本研究では,LMNtal の状態空間探索にヒューリスティック探索手法であるA*探索を導入することにより,目 標状態までの最適な経路を発見し,また,探索の無駄を減らし実行性能の向上を行った.
これにより,経路探索問題において状態数が大きく非常に実行時間がかかってしまう問題 においても,状態数を大きく削減し,より短い実行時間で最適な経路を求めることができ た.また,グラフ書換え系言語におけるヒューリスティック関数を記述するためのDSL
を,LMNtalを対象言語として設計・実装を行った.このDSLによりLMNtalのグラフ構
造にアクセスすることにより,ヒューリスティック関数の記述を行う.また,A*探索の並 列化を行うことにより,速度向上を行った.
i
LMNtal
Software has become a very important technology in systems that make up the society, and pervades the society deeply. At the same time, to increase the reliability and safety of software is important. Model checking, which is one of the formal methods, has attracted much attention in recent years. Model checking is a method that performs exhaustive search of state transition diagrams expressing the behavior of a system.
The parallel model checker SLIM is a runtime system of LMNtal. SLIM uses the con- current language LMNtal based on hierarchical graph rewriting as a state transition system description language. LMNtal is a concurrent language model based on hierarchical graph rewriting, and its calculation proceeds by rewriting graphs consisting of atoms, membranes, and links dynamically. LMNtal has a high expressive power and allows us to describe concur- rency easily and to express diverse computational models. SLIM features non-deterministic execution and model checking enabled by its state space construction feature. SLIM con- structs and searches state space which consists of hierarchical graphs as states and graph rewriting as state transition. State space construction and search is generally an expensive process, so parallelization and various optimization with the aim of large-scale, efficient pro- cessing has been done.
Currently, SLIM searches all of the states by doing depth-first search mechanically. How- ever, path finding problems do not necessarily construct all states, because its purpose is to obtain an optimal path from the initial state to the goal state.
In this study, we reduced the waste of the state space search and improve the execution per- formance for path finding problems by introducing heuristic search to the state space search of LMNtal. And we designed and implemented a domain-specific language for describing heuristic functions for LMNtal graphs. Moreover, we improved the execution performance by parallelizing A* search.
ii
第1章 序論 1 1.1 研究の背景と目的 . . . 1 1.2 論文構成 . . . 2
第2章 LMNtal言語 3
2.1 LMNtal言語の概要 . . . 3 2.2 LMNtal処理系SLIM . . . 6 2.3 LMNtalの状態空間構築 . . . 8
第3章 A*探索 13
3.1 探索 . . . 13 3.2 A*探索 . . . 15
第4章 LMNtalにおけるA*探索の導入 18
4.1 概要 . . . 18 4.2 LMNtalにおけるA*探索 . . . 19 4.3 LMNtalにおけるA*探索の並列化 . . . 21
第5章 本研究で扱う例題 23
5.1 Nパズル問題 . . . 23 5.2 最短経路問題 . . . 23 第6章 グラフ構造へのアクセスのためのDSLの設計 25 6.1 概要 . . . 25 6.2 グラフ構造へのアクセスのためのDSLの設計 . . . 25 6.3 DSLによるヒューリスティック関数の記述方法 . . . 27
iii
7.1 逐次実行 . . . 32
7.2 並列実行 . . . 36
第8章 まとめと今後の課題 40 8.1 本研究のまとめ . . . 40
8.2 今後の課題 . . . 40
参考文献 43 付録A 使用したベンチマークプログラム 45 A.1 eight-puzzle.lmn . . . 45
A.2 eight-puzzle.hlmn . . . 46
A.3 eight-puzzle.hil . . . 46
A.4 shortestpath.lmn . . . 47
A.5 shortestpath.hlmn . . . 48
付録B ソースコード変更概略 49 付録C 実装した主要部分のソースコード 50 C.1 mc generator.c . . . 50
iv
2.1 LMNtalプログラムの例 . . . 4
2.2 LMNtalの基本構文 . . . 4
2.3 アトム,リンク,膜による階層グラフ . . . 5
2.4 処理系概要 . . . 7
2.5 ルールによる階層グラフ構造の書き換え . . . 8
2.6 非決定実行による状態遷移 . . . 9
2.7 SLIMの状態空間構築処理概要 . . . 10
3.1 A*探索のアルゴリズム . . . 17
4.1 実行時処理系SLIMにおけるA*探索実行の全体の流れ . . . 19
4.2 実行時処理系SLIMにおけるA*探索実行のSLIM部分の概要 . . . 20
4.3 LMNtalにおけるA*探索のアルゴリズム . . . 21
4.4 LMNtalにおけるA*探索の擬似コード . . . 22
5.1 8パズル問題. . . 24
5.2 最短経路問題 ルーマニアの都市の例 . . . 24
6.1 アトム名とリンク名番号によるグラフアクセス . . . 26
6.2 DSLの基本構文 . . . 27
6.3 マンハッタン距離 . . . 28
7.1 各種処理の割合 . . . 35
7.2 各種初期値におけるA*探索の状態数の割合 . . . 36
7.3 各種初期値における11パズルのコア数と実行時間の関係 . . . 38
7.4 初期値3(深さ60)における各種処理の割合 . . . 39
v
表目次
6.1 各都市とBucharestまでの直線距離 . . . 29
7.1 実験環境 . . . 32
7.2 各種初期値における8パズルの実行結果 . . . 35
7.3 各種初期値における11パズルの実行結果 . . . 36
7.4 各種初期値における11パズルのコア数と実行時間の関係 . . . 38
vi
第 1 章
序論
1.1 研究の背景と目的
コンピュータの扱う情報の大規模化に伴い,それを扱うソフトウェアの並行・分散処理 がますます重要となってきている.一方で,そのようなソフトウェアは実行が並列に行わ れ,再現性のない不具合が潜む可能性があり,テストやシミュレーションによる信頼の確 保が難しい.また,ソフトウェアは社会の構成するシステムにおいて非常に重要な技術と なっており,現代社会に深く浸透していることにより,ソフトウェアの信頼性や安全性を 高めることが重要となっている.そこで近年では,形式手法の一つであるモデル検査が注 目を集めている.モデル検査は検査対象のシステムやその振舞いをモデル化したプログラ ムを状態遷移系として管理し,網羅的に実行の探索を行うことにより,入力した性質を違 反するかどうかなどを検証し,システムの正当性の保証を実現するような手法である.こ のようなモデル検査を実現するものとして,LMNtal[1]で記述したモデルの振舞いを検査 するモデル検査器がある.
LMNtalは階層グラフ書き換えに基づく言語モデルであり,並行計算,多重集合書き換え
などの計算モデルを統合を目指している.プログラムの基本構成要素はアトム,膜,リン クによって階層グラフ構造を書き換えていくことによりプログラムが進行する.LMNtal ではグラフ構造を状態,ルール適用によるグラフ書き換えを状態遷移として状態空間の構 築・探索を行う.
現在のLMNtalでは状態遷移に優先度はなく機械的に探索を行っている.しかし,経
路探索の問題等ではすべての状態の構築・探索を行う必要はなく,初期状態から目標状 態までの最適な経路の取得が目的である.経路探索問題はロボットにおける経路探索や 航空会社の運行計画システムなどさまざまな分野で利用される非常に重要な問題である.
経路の探索問題に関して,LMNtalを用いて効率的に最適な経路を求めたい.本研究では
LMNtalの状態空間探索にヒューリスティック探索手法であるA*探索を導入し,最適な
解への経路の取得と展開される状態数の削減を目指す.また,グラフ書き換え系言語にお けるヒューリスティック探索を実現するために,ヒューリスティック関数を記述するため
のDSLを,LMNtalを対象言語として設計・実装を行う.このDSLによりLMNtalのグ
ラフ構造にアクセスすることにより,ヒューリスティック関数の記述を行う.また,A*探 索の並列化により実行時間の向上を目指す.
1.2 論文構成
本章以降の構成は次の通りである.第2章では,LMNtal言語の構文とプログラムの記
述方法,LMNtalの実行時処理系の概要,LMNtalにおける状態空間構築処理について解
説する.第3章では,本研究で扱う例題について解説する.第4章では,一般的な探索問 題と探索手法,ヒューリスティック探索手法であるA*探索について説明する.第5章で
は,LMNtalにおけるA*探索について説明する.第6章では,グラフ構造へのアクセス
のためのDSLの設計と,DSLによるヒューリスティック関数の記述方法について説明す る.第7章では,評価実験を行う.最後に,第8章では,本研究のまとめと今後の課題を 示す.
第 2 章
LMNtal 言語
本章では,階層グラフ書換えに基づくプログラミング言語 LMNtalについて解説する.
LMNtalプログラムを構成する各要素の用語と機能,基本的な構文などを説明する.また,
状態空間構築機能などを持つLMNtalの実行時処理系SLIMについての説明も行う.
2.1 LMNtal 言語の概要
2.1.1 LMNtal 言語の基本構文
LMNtal は,階層グラフ書換えに基づく言語モデルである.アトムを基本構成要素と
し,リンクと膜により構造化することによって階層グラフ構造を表現する.LMNtalプロ グラムはルールによってグラフ構造を動的に書き換えて行くことで進行する.図2.1 は
LMNtal階層グラフ構造をルールにより書き換えられた例を示している.LMNtalのルー
ルは,左辺の構造とマッチする構造がある場合に,右辺の構造に書き換えることを意味 する.
LMNtalプログラム例題
c(X),d(X).
{
a(Y),b(Y).
a(Y),b(Y) :- e } .
LMNtalの基本構文を図2.2に示す.構文に示されているPはプロセス,T はプロセス
テンプレートを表す.
!"#$%&'"#$&()&*+&
図2.1 LMNtalプログラムの例
P ::= 0 (空)
| p(X1, . . . ,Xm) (m≥0) (アトム)
| P, P (分子)
| {P} (セル)
| T:-T (ルール)
T ::= 0 (空)
| p(X1, . . . ,Xm) (m≥0) (アトム)
| T,T (分子)
| {T} (セル)
| T:-T (ルール)
| @p (ルール文脈)
| $p[X1, . . . ,Xm|A] (m≥0) (プロセス文脈)
A ::= [] (空)
| *X (リンク束)
図2.2 LMNtalの基本構文
2.1.2 データ構造
LMNtalの基本構成要素はアトム (atom),リンク(link),膜(membrane)であり,膜に よって構造化することにより階層グラフ構造を表現している.
アトムはグラフ構造のノードに対応する要素である.名前と順序付けられた n 個 (n≧0)以上のリンクを持ち,このときアトムはn価であるという.
図2.3 アトム,リンク,膜による階層グラフ
リンクはグラフ構造におけるエッジであり,アトム同士を一対一に相互に接続すること ができる.アトムの引数(リンク)の個数をそのアトムの価数(arity)と呼ぶ.名前と価数 をアンダースコアで繋いだものをファンクタ(functor)と呼び,アトムの種類を識別する ために用いられる.例として,名前がaで1価のアトムのファンクタは‘a‘ 1となる.ア トムとリンクにより形成されるグラフは,リンクが方向を持たないため無向グラフとな る.アトムはアルファベットの小文字から始まる文字列で,リンクはアルファベットの大 文字から始まる文字列で記述する.
膜は複数のアトム,膜,ルールの多重集合を囲むことができ,膜の中に膜を作ることに より,親膜・子膜・子孫膜といった階層構造が作られる.LMNtalプログラム中で階層構 造の最外部に記述したアトムや膜は,グローバルルート膜と呼ばれる仮想敵な膜に所属し ている.つまりすべての膜はグローバルルート膜の子孫膜となり,グローバルルート膜か ら再帰的にすべての膜とアトムをたどることができるようになっている.
2.1.3 ルール
グラフ構造を書き換える規則をルール(rule)と呼び,次の構文で記述する.
Head: -Body.
ルールの左辺をヘッド部,右辺をボディ部と呼ぶ.グラフ構造のマッチングに付加的な条 件を指定する場合,ガード部に記述する.ガード部を含む構文は次の通りである.
Head: -Guard|Body.
左辺のヘッド部は書き換えるべき階層グラフ構造のテンプレートであり,右辺のボディ部 は書き換え後の階層グラフ構造のテンプレート,右辺のガード部は書き換える際のさらな る条件指定や前処理などを記述することができる.
ヘッド部とボディ部には図2.2の構文規則のプロセステンプレートを記述する.プロセ ステンプレートはプロセスの部分構造を表現する記法であり,プロセスの局所的な文脈を 扱う機能を持つ.
また,各膜はルールを0個以上持つことができ,その多重集合をルールセットと呼ぶ.
プログラムのある時点において,適用可能なルールが同時に複数存在する場合や適用可 能な構造が同時に複数存在するとき,適用の順序は規定されておらず,非決定的にルール による書換えを進める.
また,ルールが適用できなくなるまで階層グラフ構造の書き換えが進み,ルールが適用 できなくなった状態の構造が最終状態となる.
2.2 LMNtal 処理系 SLIM
本章では主にコンパイラと実行時処理系 SLIMから構成されるLMNtalの処理系につ いて説明する.
2.2.1 概要
LMNtalの処理系は,主にコンパイラと実行時処理系SLIMからなる.コンパイラは字
句解析器,構文解析器,ルールコンパイラ,最適化器等で構成され,java言語で実装され ている.コンパイラはLMNtalソースプログラムを入力として受け取り,独自に設計した 中間命令列へと変換を行う.実行時処理系SLIMは,LMNtalコンパイラにより生成され た中間語命令列を入力として実行を行う.SLIMはC言語で実装されており,2008年か ら修正BSDライセンスのオープンソースソフトウェアとしてプロジェクトが発足した.
現在はGitHub(https://github.com/lmntal/slim)上に公開されている. SLIMには検証機能が 実装されており,線形時相論理(LTL)による検証属性の記述をサポートするLTLモデル 検査機能と,可能な全実行経路を出力する非決定実行機能がある.さらに大規模な計算を 考慮して,共有メモリ向けの並列モデル検査が可能になっており,高いスケーラビリティ が達成されている.
!"#$%&'
!"#$%'
!"#$%&&'(
)$'
*+,-./' (!)"' )!!"#$%'
*01234+' *+56'
図2.4 処理系概要
2.2.2 非決定実行
LMNtalのグラフ書き換えルールには非決定性があり,非決定実行を行うことができる.
以下に非決定的に進行するルールによる階層グラフ構造の書き換えの例題を示す.
非決定的なルール適用のプログラム例
num(1),num(2),num(3),num(4),num(5).
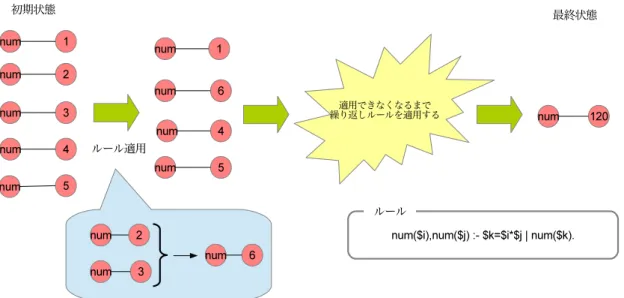
num($i),num($j) :- $k=$i*$j | num($k).
このプログラムはnumアトムと接続された数字のアトムを掛け合わせていくプログラム である.最終状態は1,2,3,4,5が掛け合わされnum(120)となる.図2.5にはルール適用さ れ,階層グラフ構造が書き換えられて行く様子が描かれている.図2.5から最初のルール
適用でnum(2)とnum(3)が乗算されてnum(6)となり,グラフ構造にルールが適用できな
くなるまでルールを適用していき,最終的にnum(120)が生成されているのがわかる.ま た,図2.5では,最初のルール適用でnum(2)とnum(3)に対してルールが適用されている が,ルールの書き換えには非決定性があるので,どの2つを選んでよく,最初のルール適 用では5つの数字から任意の2つをとる組み合わせの数5C2 =10通りある.次に,図2.6 に非決定的に適用されたルールでの書き換えによる状態の遷移図を示す.これから,最初 のルール適用は10通りであるが,2つの内num(1)が含まれる場合の4つはすべて同じ構 造num(2),num(3),num(4),num(5). になるので最初の状態遷移先の個数は7通りとなって いるのがわかる.そして非決定的にルール適用が進み最終的にどの順番で適用していって
もnum(120)となるのが確認できる.
図2.5 ルールによる階層グラフ構造の書き換え
2.2.3 LTL モデル検査
LMNtalにはモデル検査手法の一つであるLTLモデル検査が実装されていて,モデル検
査を行うことができる.モデル検査とはモデル(擬似システム)を作成してテスト・検証 する手法であり,ソフトウェアの仕様を与えることにより,その仕様にバグがないかなど を自動的に検査することができる.またLTLモデル検査はLTL(線形時相論理)を用いた モデル検査手法のことである.モデル検査・LTLについては論文に詳しい記述があり,こ こでは要点を述べるに留める.
2.3 LMNtal の状態空間構築
LMNtalでは非決定実行性により並行してグラフ構造の書き換えが行われ,そのグラフ
構造を一つの状態としていくつもの状態により状態空間が構築される.本章ではLMNtal 処理系SLIMにおける状態空間の管理手法を説明する.
2.3.1 概要
SLIMは,モデルをLMNtalで記述し,そのプログラムについて,階層グラフ構造を状 態,ルールによるグラフ構造の書き換えを遷移とした状態遷移系を探索する非決定実行機
図2.6 非決定実行による状態遷移
能を持つ.状態遷移系を探索し,状態空間を構築する処理の概要を図2.7に示す.
まず,未展開の状態に対して,一回のルール適用を網羅的に行うことにより,遷移元状 態を書き換えた次の状態を生成し状態展開を行う.次に,状態のハッシュ値を計算して,
新規ハッシュ値であれば,新規状態として状態をバイト列に圧縮して状態管理表に登録す る.ハッシュ値が衝突した場合,その2つの状態は同じ状態である可能性があるので,グ ラフの同型性判定によって,等価性判定を行う.同型性判定により2 つの状態が等価で あると判定されたときは,新規状態ではないので状態管理表への登録は行わない.逆に等 価でない場合は,新規状態なので,状態をバイト列に圧縮して状態管理表に登録する.こ のようにハッシュ表形式の状態管理表を用いて,一つの階層グラフ構造を一つの状態とし て,状態空間を一元管理している.
2.3.2 階層グラフのバイト列表現
状態である階層グラフ構造をそのまま構造体などで管理することは,メモリ領域でのコ ストが高く,検証可能な規模を狭めてしまう.そこでSLIMでは階層グラフ構造をバイト 列へ圧縮して管理している.バイト列は再構築可能な形式でエンコードされており,未展 開状態にルールを適用して状態展開する場合など必要に応じて階層グラフ構造の再構築を
!"#$%
&'()!
*+,!
-./01!
23456!
2378!
"#$#%!#$&'%!()"%*#!
'++,!-.!
()"%*#!
239':/01!
/%"!
0+!
/%"!
0+!
*+,!"#$%;<!
23456=>!
?7823@A!
1234!+*!5346!
図2.7 SLIMの状態空間構築処理概要
行っている.
2.3.3 ハッシュ値計算
LMNtalでは階層グラフ構造の状態からハッシュ値を生成する.ハッシュ関数に求めら
れる性質としては
1. 等価な階層グラフ構造に対して異なるハッシュ値を生成してはならない 2. 異なる階層グラフ構造が同じハッシュ値をできるだけ生成しない などが上げられる.
LMNtalでは状態のハッシュ値が衝突した場合,グラフ同型性判定行われるので,ハッ
シュ値はなるべく拡散しハッシュ値の衝突がなるべく少ない方が実行性能が良い.これら を踏まえて,階層グラフ構造のハッシュ値関数は文献[5]で提案されたアルゴリズムによ り実装されている.
LMNtalの階層グラフ構造のハッシュ値計算は,膜を単位として計算される.ある膜の
ハッシュ値はその膜内の分子とその子膜それぞれについてのハッシュ値から計算される.
ここで一つの分子のハッシュ値は,各アトムを基点としてアトムと膜を頂点とする深さD までの木構造として読み出したグラフを計算単位とし,この木構造の集合から計算され
る.そして,最終的に,すべての分子と子膜のハッシュ値の総和と総積の排他的論理和を ハッシュ値とする.
一つの階層グラフ構造のハッシュ値を求めるとき,一番外側の膜(グローバルルート膜) をハッシュ値計算の関数に渡し,前述したように,膜内の分子を計算する.次にその子膜 のハッシュ値を求めるために,同様にその子膜の分子を計算して,子膜から子膜へと再帰 的にハッシュ値計算を行う.
分子の計算単位とする木構造を読み出す深さDは大きいほどハッシュ値が発散するが,
計算時間も多くなる.深さDはハッシュ値の発散により同型性判定の回数が減ることに よる時間と,ハッシュ値の計算時間によるコストとから,実験的に性能が最も良くなるよ うに決定する必要がある.現在のSLIMでは先ほどの内容を含めてプログラムの実行時 間から深さ2までの木構造で実装されている.
2.3.4 同型性判定
LMNtalではハッシュ値が衝突した時,状態の新規性を確かめるためにグラフの同型性
判定を行う.グラフの同型性判定は二つのグラフに対して同型であるかどうかを判定す ることである.つまり,LMNtalではグラフ同型性判定は二つの状態の等価性を検査する (本当に同じ状態であるかどうか検査する)ことであり,二つの状態の階層グラフ構造に存 在するすべてのアトム,リンク,膜,ルールが一対一に対応付け可能であることを深さ優
先探索(DFS)で判定する.
グラフ同型性判定問題は,膜の中に同じ場所にリンクをもつ同名のアトムが存在する場 合など,それらの対応関係すべての可能性を探索する必要がある場合などが存在したりす るので,コストとして高価な処理である.
2.3.5 一意なバイト列
同一のグラフであれば,内部表現が異なっていても同じバイト列を生成する手法がある. バイト列生成時に探索を行い,アトムや膜に一定の並び順を与えることによって,バイト列 の一意性を保証する. この手法を使用した場合,グラフ同型性判定は行われず, バイト列の 比較によって状態の等価性判定を行う. ハッシュ値に関しても,膜のハッシュ値の計算は 行わず,一意なバイト列から計算する.また,膜から計算したハッシュ値を使用していると きに,ハッシュ値の衝突が多く起こった場合,同型性判定の回数が増え実行時間に影響を与 えることがある. そのような場合, SLIMは一意なバイト列にエンコードし, ハッシュ値の
再計算を行う. 再計算が起きた状態に関しては, 専用のハッシュ表に登録することで一貫 性を損なわないようにしている.
2.3.6 差分情報を利用した状態生成
LMNtalでは遷移先の階層グラフを生成する際,遷移元の階層グラフ構造を複製して書
き換えることにより生成している.しかし,遷移の際の階層グラフの書き換えが一部分だ けあることが多いので階層グラフ構造全体を複製するのは非効率的である.この問題を解 消するために遷移先の階層グラフを生成する際,遷移元からの遷移先の差分情報を用いて 状態を生成する手法がある.
未展開状態を展開する際に,遷移先と遷移元の差分情報を作成し,それを元の階層グラ フ構造に適用して書き換える.そして,遷移先の状態の同型性判定やバイト列エンコード などを行い,その後に差分情報を逆適用して元の階層グラフを得る.それをすべての遷移 についても同様にして,網羅的に状態生成を行う.
第 3 章
A* 探索
本章ではヒューリスティック探索手法であるA*探索の説明を行う.
3.1 探索
本節では人工知能の分野であり,さまざまな分野において利用されている探索について の一般的な説明を行う.
3.1.1 探索と探索問題
探索とは特定の条件を満たすような解を見つけ出す行動のことである.ある状態のとき に複数の選択可能な行為をもち,その行為により新しい状態へと遷移することの繰り返し によりゴール状態を発見したとき,それまでの行為列を解とすして見つけ出す.解は初期 状態からゴール状態への経路であり,最適解はすべての解の中で最も経路コストの小さい 解である.
探索問題とは次の4つの要素により定義される.
• 初期状態
• ある状態において選択可能な行為
• ゴール検査
• 経路コスト
初期状態は探索開始時の状態である.ある状態xにおいて選択可能な複数の行為action から,その状態に行為を適用した結果の状態列successorsを取得できる.このとき,後者
関数successor functionとは状態xを入力として,状態列successorsを取得するような関 数である.現在の状態に後者関数を適用し,新しい状態列を取得することを状態を展開す るという.ゴール検査とは,ある状態がゴール状態かどうかを決定する検査である.ゴー ル状態かどうかの検査にはいくつかの方法が考えられるが,簡単な判定方法としてはある 状態がゴールの状態であるか,または,ある状態がゴールの状態集合に含まれるかどうか などで判定を行う.経路コストとは状態xから,行為aを行い,状態yへ行くのにかかる コストであり,c(x, a, y)のように記述できる.初期状態と後者関数によって,初期状態か ら到達可能なすべての状態の集合である問題の状態空間を得ることができる.この状態空 間を用いて解の探索を行う.状態空間における経路とは行為の列でつながった状態の列で ある.
3.1.2 探索問題の達成度の尺度
探索問題解決の達成度の尺度としては以下の4つが挙げられる.
• 完全性
• 最適性
• 時間計算量
• 空間計算量
完全性はそのアルゴリズムは解が存在する場合に解を見つけることを保証しているかど うか.最適性はそのアルゴリズムは最適な解を見つけるかどうか.時間計算量は解を見つ けるためにどの程度の時間が必要か.空間計算量は探索を達成するためにどの程度の記憶 領域が必要か.
3.1.3 探索戦略の分類
探索戦略は大きく知識を用いるかどうかで知識なしの探索 (盲目的探索)と知識ありの 探索(ヒューリスティック探索)に分けられる.
知識なしの探索(盲目的探索)は探索が問題の定義であたえられる以外に状態について のそれ以上の情報を持たず,探索でできることは後者を生成すること,ゴールとゴールで ない状態を判定することのみである.知識なしの探索の例としては幅優先探索,均一コス ト探索,深さ優先探索,深さ制限探索,反復深化深さ優先探索,双方向探索などが挙げら れる.
知識ありの探索(ヒューリスティック探索)はゴールでない状態の一つが別の状態より も見込みがあるかどうかの情報を持ち,それを利用した探索である.知識ありの探索の例 としては最良優先探索,A*探索,IDA*,SMA*,RBFS,分枝限定法などが挙げられる.
また,その他に局所探索として山登り法や焼きなまし法などもある.
3.1.4 ヒューリスティック関数
ヒューリスティック探索では状態の一つが別の状態よりも見込みがあるかどうかの情報 を用いて探索を行うが,この追加の情報を与える方法としてヒューリスティック関数があ る.ヒューリスティック関数はnがゴール状態だとするとh(n)=0となるような制約を 持った任意の問題特有の関数である.ヒューリスティック関数は問題特有の関数であり,
例としてNパズル問題ではマンハッタン距離,最短経路問題ではゴールまでの直線距離 などが挙げられる.
3.2 A* 探索
A*探索はヒューリスティック探索の一つであり,スタートからゴールまでの経路を求め る.このとき特定の条件を満たす場合にA*探索は完全性と最適性を持つ.最良優先探索 の一種であり,評価関数の値が最も低い状態から展開していく探索アルゴリズムである.
A*探索は1968年にPeter E.Hart,Nils J.Nilsson,Bertram Raphaelらによる論文[9]
で発表された.A*探索は最短経路問題に帰着できる問題に対して,効率的なアルゴリズ ムであり,さまざまな分野の問題に利用されている.A*探索を改良したアルゴリズムが 多く考案されており,例としては評価値を深さのカットオフに利用し深さ優先的に探索を 行うた反復深化A*(IDA*)[10],評価値に重み付けを行ったもの,メモリをすべて使うよ うに改良したMA*(memoriy-bounded A*),SMA*(simplified memory-bounded A*)など がある.SMA*はメモリが一杯になるまで最適な葉ノードを展開しながら,A*探索と同じ ように進行し,メモリが一杯になった場合には評価値が大きいノードを捨て,場合により 部分木を再生成する.
また,並 列化を考慮した A*探索も多 く考案されてお り,例としては HDA*(Hash Distributed A*)[12],PRA*[14]等がある.HDA*は分散並列A*アルゴリズムであり,各 プロセッサがオープンリスト・クローズドリストの一部を管理し,全体として一つとなっ ており,ノードの割り当てにはハッシュ関数を用いて行うようなアルゴリズムとなって いる.
3.2.1 A* 探索のアルゴリズム
A*探索は最良優先探索の一種で,ノード nについて,評価関数f(n)が以下の式で定義 される.
f(n) = g(n) + h(n)
評価関数f(n)はn経由の最適解の見積りコスト,g(n)は出発ノードからノードnまでの 経路コスト,ヒューリスティック関数h(n)はnからゴールまでの最短経路の見積りコス トである.nがゴールノードのときにはh(n)=0.A*探索はf(n)の評価関数の値が最も低 いノードから先に展開していく.最適解よりも大きい評価値をもつノードを展開しない.
図3.1にA*探索のアルゴリズムを示す.A*探索は未展開状態のキューopenと展開済 み状態のキューclosedの二つのキューを探索に利用する.まず,openから評価値が最小 の未展開状態を選択する.次に取り出した状態がゴール状態かどうかの判定を行う.ゴー ル状態であれば実行は終了となる.ゴール検査には,ヒューリスティック関数がゴール状 態では0となる性質を利用する場合がある.次にゴール状態でない場合には,状態展開を おこなって,展開された各状態について評価値の計算を行う.また,その状態がすでに生 成された状態であるかを確認し,既出でなければ,openに追加する.既出である場合に は,生成された状態と前の状態との2つの状態の間で評価値の比較を行う.生成された状 態の方が評価値が大きい場合には何もせず,小さい場合には,より良い経路が見つかった ことになるので,closedから削除してopenに追加する.このように状態空間グラフにお けるノードが合流した場合には,評価値の悪い方を捨てることにより,より良い解を探索 する.A*探索はこの操作をopenが空になるかゴール状態となるまで繰り返すことで実現 される.
3.2.2 A* 探索の最適性
A*探索はヒューリスティック関数が特定の条件を満たすときに最適かつ完全となる.
本節ではA*探索の最適性について説明する.Tree-Searchの場合はヒューリスティック 関数が許容的,つまり,ヒューリスティック関数がゴールへ至るまでのコストを過大に見 積もることがないときにA*探索は最適性を持つ.Graph-searchの場合は無矛盾性,つま り,すべてのノードnと行為aで作られたnのすべての後続ノードn’について,nから ゴールへ至る見積りコストの和より大きくないならば,A*探索は最適性を持つ.無矛盾
!"#$"$"%&'"(%
!"#$%&' )()*+,*%
$%-./0% )+,&-"!%#$"$"*%
()*-% 12340%
()*56%
!"#$%&%'"#$%(%)"#$%
"(#$"$"%&'"(%
$%"#%
789:;%
+,&-"!%#$"$"%
&'"(%
'./&./01%#$"$"%
"(#$"$"%+,&-"!%
."2&3"%+,&-"!%
4&%
5"-%
5"-%
4&%
"(#$"$"% !"#$"$"%
図3.1 A*探索のアルゴリズム
であるヒューリスティックスは許容的であり,無矛盾性は許容性よりも難しい条件となっ ているが,許容的であって無矛盾でないようなヒューリスティックスを作るのは難しい.
第 4 章
LMNtal における A* 探索の導入
LMNtalの実行時処理系SLIMは,状態空間を扱う機能である非決定実行やモデル検査
機能を持っている.また,これらの処理は大規模高速化を目指して並列化がなされてい る.現在のLMNtalの状態空間の構築・探索処理では状態遷移に優先度等はなく機械的に 深さ優先探索等により状態空間探索をおこなっている.しかし,経路探索問題などでは効 率的に最適な経路を求めたい場合には,必ずしもすべての状態空間の構築を行う必要がな い.また機械的な探索ではなく,なんらかの指標を元になるべく目的の状態の方向に状態 遷移を行うことが望ましい.
そこで,本研究では LMNtalの状態空間探索にヒューリスティック探索手法であるA*
探索を導入することを目的とする.本章では,LMNtalの実行時処理系SLIMの状態空間 構築・探索処理に導入したA*探索の概要と,その並列化手法について述べる.
4.1 概要
まず初めにLMNtalでどのようにヒューリスティック探索手法であるA*探索を実現す るのかについて,その概要について述べる.図4.1はLMNtalにおけるヒューリスティッ ク探索の全体の流れの概要図となっている.図4.2は実行時処理系SLIMにおけるA*探 索の概要図となっている.ヒューリスティック関数の記述方法については次の章にて述 べる.
LMNtalにおけるヒューリスティック探索の実行には,モデルの動きを記述したLMNtal
プログラムとヒューリスティック関数を記述したヒューリスティックDSLが必要となる.
LMNtalコンパイラはLMNtalプログラムを入力として,中間命令列に翻訳し,ILプログ
ラムを生成する.また,同様にDSLパーサはヒューリスティックDSLを入力として,中
!"#$%&'
!"#$%' !"#$%&&'()$'
*+,-.
/012()!' ()!(,3'
456789' )!*"'
' '
*!!"#$%'
+*!!"#$%'
45:;'
<"'=>'?' @12>'?'
,-AB'
図4.1 実行時処理系SLIMにおけるA*探索実行の全体の流れ
間命令列に翻訳し,HILプログラムを生成する.次に,実行時処理系SLIMは生成された 2つのILプログラムとHILプログラムを入力として受け取り,SLIM内部では,HILプ ログラムを字句解析・構文解析を行いSLIM内部でのHILデータ構造に変換する.次に,
SLIMの状態空間構築を行うが,その際,生成された状態とHILデータ構造からその状態 のヒューリスティック関数とコスト値を計算し,状態の評価値を算出する.状態に付加さ れた評価値を用いて,A*探索を行い,最後に実行結果を出力する.
4.2 LMNtal における A* 探索
LMNtalにおけるA*探索について説明する.LMNtalにおけるA*探索のアルゴリズム
を図4.3に,擬似コードを図4.4に示す.
基本的な流れは通常のA*探索と同様である.オープンキューopenとクローズドキュー
closedの二つのキューを用意する.キューは評価値によりソートする必要があるため,プ
ライオリティキューとする.プライオリティキューは評価値をキーに状態のキューを値と したハッシュ表形式となっている.そのためキューからのenqueue(),dequeue()は共に O(1)の計算時間で処理が可能となっている.
最初に,初期状態をオープンキューに追加する.
!"#$%&!"#$'
%&'()*+' '
' ' ' ' ()()'
' ' '
*+!,-./0' 1234''
%534'
,!+"6*+!' 789%:'
;<='
;<>'
!"'
?@A*+B,!+"'
図4.2 実行時処理系SLIMにおけるA*探索実行のSLIM部分の概要
次に,オープンキューから最も評価値の低い状態を取り出し,ゴール状態であるかどう かゴール検査を行う.ゴール状態である場合にはゴール状態までの経路を出力して探索を 終了する.ゴール状態でない場合には,expand()により状態を展開し,すべての展開され た状態についてcalc heuristic score()でヒューリスティック値とコスト値を計算し,評価 値の計算を行い,求めた評価値を状態に付加する.評価値の算出は次章で説明するDSL を用いて行われる.次に,statespace contain()から,その状態がすでに状態空間に登録 されているかどうかを状態管理表から確認し,状態が登録されていない場合には新規状態
なので,statespace insert()で状態管理票に登録して,オープンキューに状態を追加する.
すでに状態が登録されている場合には,その登録されている状態same stateを取得して,
生成された状態とすでに登録されている状態の評価値を比較を行う.生成された評価値が すでに登録されている状態の評価値よりも小さい場合には,その状態までの経路ですでに 見つかったものよりも最適な経路が見つかったことになるため,すでに登録された状態を 生成された状態に置き換える.状態管理票からstatespace remove()で前の状態を削除し,
statespace insert()で生成された状態を登録する.また,クローズドキューからも前の状
態を削除し,オープンキューにもう一度生成された状態を追加する.
これらの処理をオープンキューが空となるまで行うことでA*探索を行う.
一般的な A*探索と異なる点として,すでに生成した状態であるかどうかの判定をク ローズドキューから行うのではなく,状態管理表から行っているという点がある.これは
!"#$"$"%&'"(%
!"#$%&' )()*+,*%
$%-./0%
)$%123*%
()*-45 670%
()*89%
!"#$%&%'"#$%(%)"#$%
"(#$"$"%&'"(%
+(!%
,-+-"%-+./"%0(,"1-%
$%"#%
:;<=>%
2/&,"!%#$"$"%
&'"(%
'10&10-3%#$"$"%
"(#$"$"%2/&,"!% 1"4&5"%2/&,"!%
+(!%
,-+-"%-+./"%1"4&5"%
$%123%
?@ABCDEF%
GBHI4JKLMN%
$%1230O$%- ./0PQ0RST%
6&%
7",%
7",%
6&%
/&&8%$'%
!"#$"$"%
"(#$"$"%
0(,"1-%
UVWX9:;0O()*9/%
89AY@Z[?@ABC\I]^%
図4.3 LMNtalにおけるA*探索のアルゴリズム
SLIMの状態空間探索では,それまでに構築した状態をすべて保持していて,状態管理表 を用いて管理しているからである.
4.3 LMNtal における A* 探索の並列化
LMNtalにおけるA*探索の並列化について述べる.
基本的な処理の流れは逐次処理の場合と同様である.異なる点としては,グローバルな オープンキューとクローズドキューを用意して,各スレッドが共有を行う点である.共 有したオープンキューとクローズドキューに対して,各スレッドがそれぞれ処理を行う.
また,ヒューリスティック関数を計算するためのレジスタを各スレッド別に持っている.
オープンキューとクローズドキューのプライオリティキューに処理を行う際にはキュー全 体にロックをかけることにより,各スレッドの処理の排他制御を行なっている.現在の並 列化の実装では並列実行における解の最適性は保証しない.これは複数スレッドで状態を 並行して展開していくため,展開される順番が変わるためである.
1: procedureastar search(statespace,init state)
2: open= new PriorityQueue()
3: closed= new PriorityQueue()
4: enqueue(open,init state)
5: while!empty(open)do
6: state=dequeue(open)
7: enqueue(closed,state)
8: if is goal(state)then
9: print path to goal(state)
10: return”success”
11: end if
12: succesors=expand(state)
13: for allnew state∈ succesorsdo
14: calc heuristic score(new state)
15: if statespace contain(new state)then
16: same state= statespace get same state(new state)
17: if get heuristic score(new state)<get heuristic score(same state)then
18: statespace remove(same state)
19: statespace insert(new state)
20: remove(closed,same state)
21: enqueue(open,new state)
22: end if
23: else
24: statespace insert(new state)
25: enqueue(open,new state)
26: end if
27: end for
28: end while
29: return”f ailed”
30: end procedure
31:
32: procedurecalc heuristic score(state)
33: f =g(state)+h(state)
34: state.score= f
35: end procedure
図4.4 LMNtalにおけるA*探索の擬似コード
第 5 章
本研究で扱う例題
本章では本研究で扱う例題について説明する.また,グラフアクセスのDSLを用いた,
これらの例題のヒューリスティック関数の記述例を次章にて示す.
5.1 N パズル問題
Nパズルとはスライドパズルの一種で,m×nのボードの上でN=m×n−1個の番 号付けられたタイルと空白のスペースを利用して動かし目的の形にするパズル問題であ る. 初期状態として,任意の初期位置から,目的の形に至るまでの最短手数を求める.最 短手数を求める問題はNP困難である.ひとつの空白に隣接したタイルをスライドさせる コストは1とする.代表的なNパズルの例としては3×3の8パズル, 4×4の15パズ ル等がある.3×3の8パズルの例を図 5.1に示す.8パズルは任意の可能な配置へ31 手以内に変形可能である.
5.2 最短経路問題
最短経路問題とは,重み付きグラフの与えられた2つのノード間を結ぶ経路の中で,重 みの総和が最小となる経路を求める経路発見問題である.図5.2にルーマニアの都市の例 を示す.経路発見問題は様々な問題に応用され,計算機ネットワークにおけるルーティン グ,航空会社の運行計画システム,ロボットの経路探索,生物の分野では塩基配列の比較 などにも利用されている.
!"
#"
$"
%"
&"
'"
("
)"
("
$"
)"
!"
%"
'"
&"
#"
!"
#"
$"
%"
&"
'"
("
)"
!"
#"
$" %"
&"
'"
("
)"
!!! "
"#$%"
&'$%"
図5.1 8パズル問題
!"#$%&'(&) (*+,-Bucharest).
P
B A
Z
T L
M D O
S R
C F
G
N I
V
U H
E 151
71
75
118
111 70 75
120 140
211 99
80 97
138
146 101
90 85
98
86 142
92 87
図5.2 最短経路問題 ルーマニアの都市の例
第 6 章
グラフ構造へのアクセスのための DSL の設計
本章では,LMNtalにおいてヒューリスティック関数を記述する方法について説明する.
6.1 概要
LMNtalプログラムはグラフ構造で表せるため,グラフ構造からヒューリスティック値
を計算することを考える.そのため,グラフ構造へのアクセスのためのDSLの設計を行 い,このDSLを用いてヒューリスティック関数を記述することを考える.
6.2 グラフ構造へのアクセスのための DSL の設計
グラフ構造へのアクセスのためのDSLの基本構文を図6.2に示す.
設計したDSLの目的としては,状態遷移の際のコスト関数cやヒューリスティック関 数hをDSLによって記述し,処理系内部にてLMNtalの状態 sのグラフ構造を入力とし て,記述した関数を用いてコスト値またはヒューリスティック値を算出することである.
基本的に全体としての式は以下のように記述できる.
h = (ヒューリスティック関数の計算式) c = (コスト関数の計算式)
変数宣言はvariable=Eのような構文になっていて,変数variableの値を式E の計算 結果として定義する.また先ほどのように特別な変数としてh,cがある.また,コスト計
!"
#"
$"
%" &"
!"
#"
'"
!""
""
""
"" !""
""
""
!""
図6.1 アトム名とリンク名番号によるグラフアクセス
算の際などに前の状態が必要な場合にはグラフ構造の中に経路等を保持する必要がある.
条件分岐はif BE then E1 else E2のような構文になっていて,論理式BE の計算結果が trueのとき式E1を,f alseのとき式E2を計算する.
関数は処理系内部で定義されたもののみ使用可能で,ユーザー定義はできないよう になっている.これは実装を軽くするためだけの処置である.関数呼び出しの構文は funcname ( args )のようになっていて,関数 f uncname に可変個の引数argsを適用して 関数呼び出しを行う.現在,処理系内部で実装されている関数としてはabs関数があり,
必要に応じて処理系内部にて追加する予定である.
次にグラフ構造アクセスの構文について説明する.グラフ構造へのアクセス方法として は2種類あり,アトム名とリンク番号から取得する方法と,アトム名と論理式から取得す る方法がある.
まず,アトム名とリンク番号から取得する方法について説明する.アトム名とリ ン ク 番 号 か ら ア ト ム を 取 得 す る 構 文 は atom.n と 記 述 で き て ,ア ト ム 名 atom の リ ン ク 番 号 n の 接 続 先 の ア ト ム を 取 得 す る .図 6.1 の よ う な LMNtal の グ ラ フ 構 造
p(X1, . . . ,Xn, . . . ,Xm), q(Y1, . . . ,Yi, . . . ,Yj) のとき,リンク Xn と Yi が接続されてい
るとすると p.nはqを取得する.また,px.state.1のように”.”が複数続く場合には,後ろ から順に計算される.
次に,アトム名と論理式から取得する方法について説明する.アトム名と論理式からア トムを取得する構文はatom[PE]と記述できて,アトム名atomのアトムの中から論理式 PE の計算結果がtrueとなる最初のアトムを取得する.また,論理式PE 内で条件判定中 のアトムを” ”で参照できる.集合で考えると,atom[PE]は,グラフ構造内部のアトム名 atomの集合と論理式PE を満たす集合の積集合の要素となる.
P ::= P P
| variable = E (変数宣言)
| E (式の計算)
E ::= E iop E (算術演算)
| E bop E (比較演算)
| value (定数)
| variable (変数読み出し)
| i f E then E else E (条件分岐)
| f uncname(E1, . . . , En ) (n∈N) (関数呼び出し)
| atom[E ] (アトム取得1)
| atom.n (n∈N) (アトム取得2) 図6.2 DSLの基本構文
6.3 DSL によるヒューリスティック関数の記述方法
本節では設計したDSLによるヒューリスティック関数の記述方法について具体例を用 いて説明する.
6.3.1 8 パズル - マンハッタン距離
まず,8パズルにおいてのヒューリスティック関数の記述方法を説明する.以下に8パ
ズルのLMNtalプログラムとヒューリスティック関数の例を示す.LMNtalプログラムで
は,8パズルの盤面をstateというアトムに接続する数字のアトムで一次元配列的に表し ている.px,pyはヒューリスティック関数を計算するための補助的なものであり,盤面 の座標を表している.最後に,空白のマスの位置についてそれぞれ,タイルの動きのルー ルを記述している.8パズルのヒューリスティック関数としてはマンハッタン距離を用い ている.マンハッタン距離は図6.3のようにそれぞれのタイルについて各座標の差の絶対 値の総和を2点間の距離としたものである.これはパズルの動きにおいて緩和問題を考え て各タイル目標位置まで他のパネルに関係なく動かせると仮定したときのパネルの移動の 総コストに対応している.DSLによるヒューリスティック関数はそれぞれのパネルにつ いて現在位置と目標位置との2点間の x座標とy座標のそれぞれの差の絶対値を計算し,
!"
!"
!"#$"
%&#$" '()*+,-./0123"
#"$%&%'%&%(%'%&%'"#"&$"
456.7589
#&%)#$"
!"
*"
'"
&"
$"
+"
)"
,"
図6.3 マンハッタン距離
その和を求めヒューリスティック関数hとしている.
LMNtalプログラム
state(6,4,7,8,5,0,3,2,1).
px (1,2,3,1,2,3,1,2,3).
py (1,1,1,2,2,2,3,3,3).
// move rule // (1,1)
state(0,A,B,C,D,E,F,G,H) :- state(A,0,B,C,D,E,F,G,H).
state(0,A,B,C,D,E,F,G,H) :- state(C,A,B,0,D,E,F,G,H).
// (2,1) ...
ヒューリスティック関数
manhattan1 = if state.1 == 0 then 0 else
abs( px.1 - px.state.1) + abs( py.1 - py.state.1 ) ...
h = manhattan1 + manhattan2 + manhattan3 + manhattan4 + manhattan5 + manhattan6 + manhattan7 + manhattan8 + manhattan9
6.3.2 最短経路問題
次に,最短経路問題においてのヒューリスティック関数とコスト関数の記述方法を説明 する.以下に最短経路問題のLMNtalプログラムとヒューリスティック関数の例を示す.
最短経路問題の例としてルーマニアの都市の例について考える.目的地はBucharestであ り,ヒューリスティック関数としてBucharestまでの直線距離を用いる.Bucharestまで の直線距離を表6.1に示す.LMNtalプログラムでは,ヒューリスティック関数を計算す るためにsldというアトムを用いて目的地までの直線距離を表している.グラフのエッ ジをeというアトムで表し,e の第一引数はエッジの始点を,第二引数はエッジの終点 を,第三引数はエッジの重みが表している.stateアトムを用いて,現在の状態を表して いて,第一引数が現在いる都市,第二引数がその一つ前の都市となっている.最後に移動 のルールがあり,このルールは現在いる都市を始点とするエッジを探し,位置を更新する ようなルールとなっている.
表6.1 各都市とBucharestまでの直線距離
都市名 距離(km) 都市名 距離(km)
A - Arad 366 M - Mehadia 241
B - Bucharest 0 N - Neamt 234
C - Craiova 160 O - Oradea 380
D - Dobreta 242 P - Pitesti 100
E - Eforie 161 R - Rimnicu Vilcea 193
F - Fagaras 176 S - Sibiu 253
G - Giurgiu 77 T - Timisoara 329
H - Hirsova 151 U - Urziceni 80
I - Iasi 226 V - Vaslui 199
L - Lugoj 244 Z - Zerind 374
LMNtalプログラム
// Bucharestまでの直線距離(straight line distance) sld(arad, 366),
sld(bucharest, 0), ...
sld(zerind, 374).
// エッジ
e(oradea, zerind, 71), e(zerind, oradea, 71), e(zerind, arad, 75), e(arad, zerind, 75), ...
e(iasi, neamt, 87), e(neamt, iasi, 87).
// 状態
state(arad, nothing).
//移動ルール
e(S, D, C) \ state(A, B) :- A==S, unary(B), unary(D) | state(D, S).
コスト関数・ヒューリスティック関数
// cost function
c = e[_.1 == state.2 & _.2 == state.1].3
// heuristic function h = sld[_.1 == state.1].2
次に最短経路問題におけるDSLを用いたコスト関数とヒューリスティック関数がどの ように計算されるかを説明する.まず,状態遷移時のコストであるコスト関数としては エッジの重みが対応していて,c = e[ .1 == state.2 & .2 == state.1].3と記述 できる.これは e というアトム名のアトム集合の内,論理式[ .1 == state.2 & .2
== state.1]を満たすような eを取得して,その第三引数のエッジの重みを結果として cとするようにしている.論理式の意味としては,stateアトムの第二引数である一つ前 の都市を第一引数に,stateアトムの第一引数である現在の都市を第二引数とするという
条件を表している.従って,e[ .1 == state.2 & .2 == state.1]は一つ前の都市を エッジの始点に,現在の都市をエッジの終点とするようなeというアトムにマッチする.
同様に,h = sld[ .1 == state.1].2は現在の都市を第一引数に持つようなsld とい うアトムを取得して,その第二引数の直線距離をヒューリスティック関数hとしている.
第 7 章
評価実験
本章では,実行時処理系 SLIMにおいて導入したA*探索について,8パズルの問題ま たはその同種の問題についてさまざまな初期状態について評価実験を行う.ヒューリス ティック関数はマンハッタン距離を利用している.表7.1に実験環境を示す.
表7.1 実験環境
OS CentOS 5.10
CPU AMD Opteron(tm) Processor 6176 SE (48CPUs)
Cache Size 512KB
Cache Alignment 64B
Memory 256Gbyte
7.1 逐次実行
本節では,新規機能であるA*探索の実行結果の例を示し,また,逐次実行における測 定結果とその考察を示す.
7.1.1 A* 探索の実行結果
以下にA*探索の8パズルの実行結果を示す.実行結果は初期状態から目標状態までの 経路を表している.逐次実行における結果は初期状態から目標状態までの最適な経路と なっている.
% slim --nd -p3 --benchmark-dump --astar --hil eight.hil eight-puzzle.lmn --- path to goal ---
0 : px(1,2,3,1,2,3,1,2,3). py(1,1,1,2,2,2,3,3,3). state(4,1,3,5,6,0,2,7,8). @5.
1 : px(1,2,3,1,2,3,1,2,3). py(1,1,1,2,2,2,3,3,3). state(4,1,3,5,0,6,2,7,8). @5.
2 : px(1,2,3,1,2,3,1,2,3). py(1,1,1,2,2,2,3,3,3). state(4,1,3,0,5,6,2,7,8). @5.
3 : px(1,2,3,1,2,3,1,2,3). py(1,1,1,2,2,2,3,3,3). state(4,1,3,2,5,6,0,7,8). @5.
4 : px(1,2,3,1,2,3,1,2,3). py(1,1,1,2,2,2,3,3,3). state(4,1,3,2,5,6,7,0,8). @5.
5 : px(1,2,3,1,2,3,1,2,3). py(1,1,1,2,2,2,3,3,3). state(4,1,3,2,0,6,7,5,8). @5.
6 : px(1,2,3,1,2,3,1,2,3). py(1,1,1,2,2,2,3,3,3). state(4,1,3,0,2,6,7,5,8). @5.
7 : px(1,2,3,1,2,3,1,2,3). py(1,1,1,2,2,2,3,3,3). state(0,1,3,4,2,6,7,5,8). @5.
8 : px(1,2,3,1,2,3,1,2,3). py(1,1,1,2,2,2,3,3,3). state(1,0,3,4,2,6,7,5,8). @5.
9 : px(1,2,3,1,2,3,1,2,3). py(1,1,1,2,2,2,3,3,3). state(1,2,3,4,0,6,7,5,8). @5.
10 : px(1,2,3,1,2,3,1,2,3). py(1,1,1,2,2,2,3,3,3). state(1,2,3,4,5,6,7,0,8). @5.
11 : px(1,2,3,1,2,3,1,2,3). py(1,1,1,2,2,2,3,3,3). state(1,2,3,4,5,6,7,8,0). @5.
---
7.1.2 逐次実行における測定結果
表7.2に初期状態を変更したときのA*探索とBFSによる非決定実行の8パズルの実行 結果を示す.図7.1に初期状態を変更したときのA*探索とBFSによる非決定実行の8パ ズルの実行時間の各種割合を示す.図7.2に各種初期値におけるA*探索の状態数の割合 を示す.図7.3に初期状態を変更したときのA*探索とBFSによる非決定実行の11パズ ルの実行結果を示す.
7.1における凡例の説明を以下に示す.
• idle・・・ アイドル状態
• state mhash・・・ グラフ構造のハッシュ値計算
• state mem compare・・・ グラフ同型性判定による状態の等価性判定
• state copy(in COMMIT)・・・ 状態のコピー
• expand rule(ex COMMIT)・・・ ルール適用
• menc dump・・・ 膜からバイト列へのエンコード
• menc restore・・・ バイト列から膜へのデコード
• eval heuristic func・・・ ヒューリスティック関数の計算
• remove updated node・・・ より良い評価値を持つノードをキューから削除する
処理
• other・・・ その他の処理