IoT センサーデータの分析
平成 30 年 3 月
一般社団法人 広島県中小企業診断協会
ニューロビジネス研究会
目次
1. はじめに ... - 1 - 2. センサーと設置場所 ... - 1 - 3. 不要なデータの除去 ... - 1 - 4. データ前処理 ... - 4 - A) 機械学習ための時系列データ前処理 ... - 4 - B) 2 つ部分時系列の距離計算 ... - 5 - 5. クラスタリングでの異常検知 ... - 6 - A) ユークリッド距離ベースでの分類結果 ... - 6 - B) 動的時間伸縮法ベースで分類した結果 ... - 7 -a. Whole Data Scale ... - 7 -
b. Short Time Series Scale ... - 9 -
6. オートエンコーダによる復元データ ... - 10 - A) オートエンコーダモデル ... - 10 - B) 復元データの結果 ... - 11 - C) 復元データの評価 ... - 11 - 7. エンコーダーしたデータの分類 ... - 13 - A) エンコーダーしたデータの取り出し ... - 13 - B) エンコーダーしたデータの分類結果 ... - 14 - 8. LSTM モデルによるデータ予測 ... - 16 - A) LSTM モデルとデータ前処理 ... - 16 - a. モデル ... - 16 - b. データ前処理 ... - 17 - B) 予測結果 ... - 17 - a. 1秒後の予測 ... - 17 - b. 5 秒後の予測結果 ... - 18 - c. 18 秒後の予測結果 ... - 18 - 9. まとめ ... - 19 - A) 統計的なクラスタリングによる分析 ... - 19 - B) オートエンコーダによる復元データ ... - 19 - C) LSTM モデルによるデータ予測 ... - 20 - 参考文献 ... - 20 -
- 1 -
1.
はじめに
近年、センサー機器の性能向上やクラウドプラットフォーム等の発達により、センサ ーデータを様々な産業で活用する環境が急速に整備され、安価なセンサーを用いてデ ータを取得することも出来るようになってきた。 蓄積されたデータは、活用されなければ価値を生み出さないが、目的を明確にしてデ ータ分析を行うことで、データにはその価値を最大にする可能性を秘めている。 企業において、とりわけ中小企業では、センサーから得られたデータを分析すること で何が分かり、どのように事業に活かせるのかが明瞭でないため、センサー導入からデ ータ活用に進んでいないところが多いのではないかと考えられる。 この様な状況から、広島県中小企業診断協会におけるニューロビジネス研究会では、 広島県内の中小企業の協力を得て、安価なセンサーを試験的に取り付け、取得したデー タを用いてデータの分析を実施した。データの分析として、先ずは統計的なクラスタリ ングを用い、更にニューラルネットワークを用いたディープラーニングによるデータ の異常検知と時系列データの予測を行った。2.
センサーと設置場所
センサーは、図 1 に示す ALPS 社製 IoT Smart Module を用い、地磁気と加速度の 6 軸、UV、照度、湿度、温度、気圧を 1 秒間隔で取得した。本センサーの特徴は、低消 費電力通信の Bluetooth で通信を行う、小型かつ安価(税別 9,800 円)なセンサーネッ トワークである。
図 1: ALPS 社製センサー(IoT Smart Module)
本センサーは、広島県大竹市にあるゴム・プラスチックを製造する広合化学株式会社 のブロー成型機の稼動部に取り付けた。
3.
不要なデータの除去
今回取得したデータは、2018 年 1 月 22 日から 2018 年 2 月 8 日までの期間のブロー成 型機の稼動データで、16 個の CSV 形式のファイルに分割されて記録されている。
- 2 -
図 2:IoT データファイル
このデータのサンプリングは1秒で、Time, Index, Battery, Mag_X[uT], Mag_Y[uT], Mag_Z[uT], Acc_X[G], Acc_Y[G], Acc_Z[G], UV-A[mW/cm2], AmbientLight[Lx], Humidity[%RH], Temperature[degC], Pressure[hPa]の 14 個の時系列数値データを含んでいる。
各データファイルには、勤務日(平日)に記録された有効なデータファイルと稼動して いない週末のデータファイルが含まれている。
14 個の時系列データの中には、ブロー成型機の稼動に直接影響がないと考えられるデ ータも含まれており、ime, Index, Battery, UV-A[nW/cm2], AmbientLight[Lx], Humidity[%RH], Temperature[degC], Pressure[hPa]という 8 種類のデータは除去した。
- 3 -
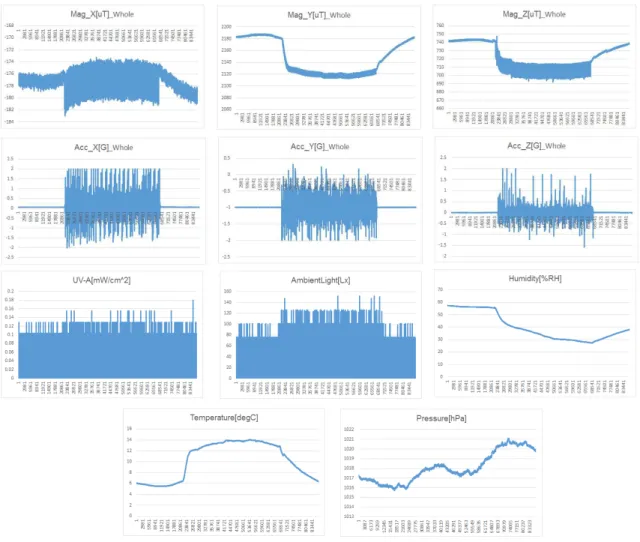
図 2:IoT データの 11 時系列のグラフ
残 り の 6 種類のデータ、Mag_X[uT], Mag_Y[uT], Mag_Z[uT], Acc_X[G], Acc_Y[G], Acc_Z[G]を用いて分析を行った。機械の稼働時間(8AM~7PM、残業ありの日は 8AM~9PM) の間は、データとして有効な情報を持っているが、稼動していない時間は分析データから取 り除いた。
- 4 - 図 3:運行時間と休暇時間にある磁場と加速度のデータ
4.
データ前処理
A) 機械学習ための時系列データ前処理 機械学習アルゴリズムで学習するため、この時系列データをスライディングウィンド ウで分割した。ブロー成型機による製品の作成サイクルが 18 秒なので、スライディングウ ィンドウの分割幅は 18 秒に設定した。- 5 - 図 4 には、時系列データをスライディングウィンドウで小さな部分時系列に分割した 例を示す。 図 4:時系列データの分割例 B) 2 つ部分時系列の距離計算 機械学習では、区分けされた時系列を部分時系列と呼ぶ。機械学習アルゴリズムで学習 する前に部分時系列ごとの互いの距離を計算した。 部分時系列の互い距離を計算するため、ユークリッド距離と動的時間伸縮法(DTW) を使用した。時系列データにある部分時系列の互い距離を計算し、距離行列を算出した。 図 5 は、部分時系列 Q と C のユークリッド距離の計算方法を表す。 図 5:時系列のユークリッド距離の方程式と計算方法 ユークリッド距離は他の複雑なアプローチ[6]に比べて、有利な点が多くある。しかし、 [2]の研究により、ユークリッド距離は「同じ長さの部分時系列でしか利用しない」、「異常と
ノイズは取り扱わない」、「shifting, uniform amplitude scaling, uniform time scaling, uniform bi-scaling, time warping and non-uniform amplitude scaling の 6 つのシグナル変換により影響を受 けやすい[3]」などの欠点もある。一方、動的時間伸縮法(DTW)はユークリッド距離より 適用領域が広いと言われている([2])。参考文献[1]には、DTW について詳しく説明されて
Input: A long time series
Output:
A set of shorter time series
…
- 6 - いる。図 6 は、DTW 距離の方程式と計算方法を表す。 図 6:時系列 Q と C の DTW 距離の計算方法。行列の各 wk = (i, j)k は Q の点 ithと C の点 jthのユークリッド距離である
5.
クラスタリングでの異常検知
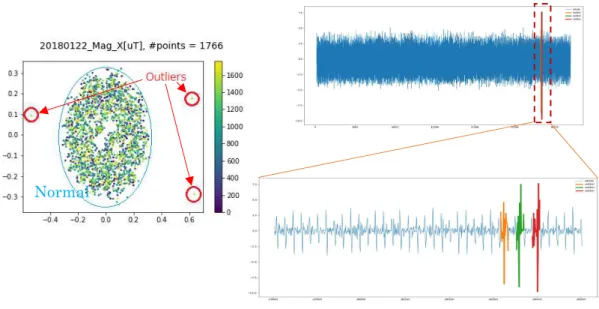
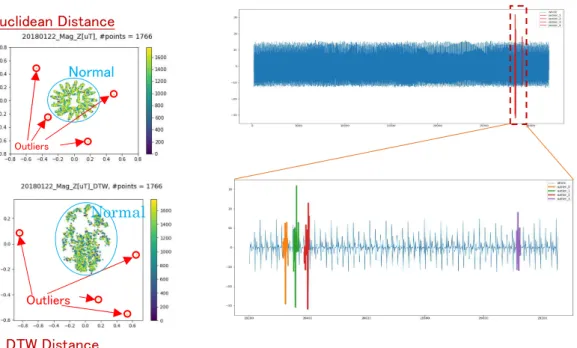
距離行列を計算した後、SVM one-class clustering アルゴリズムを利用し、類以な部分時 系列を 1 つのグループとし、残りの部分時系列は異常としてみなした。 A) ユークリッド距離ベースでの分類結果 図 7 には、ユークリッド距離ベースで 2018 年 01 月 22 日のデータを分類した結果を表 す。 図 7:ユークリッド距離で 2018 年 01 月 22 日のデータを分類した結果 図 8 には、クラスタリングアルゴリズムを利用した異常検知の例を表す。左側はクラス タリングアルゴリズムで異常が 3 ヶ所検知されている。右側はその異常を時系列で表した ものである。- 7 -
図 8:ユークリッド距離で分類して、検知された異常
B) 動的時間伸縮法ベースで分類した結果
ノーマライズされた時系列データは DTW 距離で行列距離を計算した。今回のデータは 「whole-data scale」と「short time series scale」の2つ方法で正規化した。
a. Whole Data Scale
- 図4と同様に、時系列データを各部分時系列に区分ける前に、時系列データは次 の方程式により正規化した。
=max( ) − min ( )X − min (X)
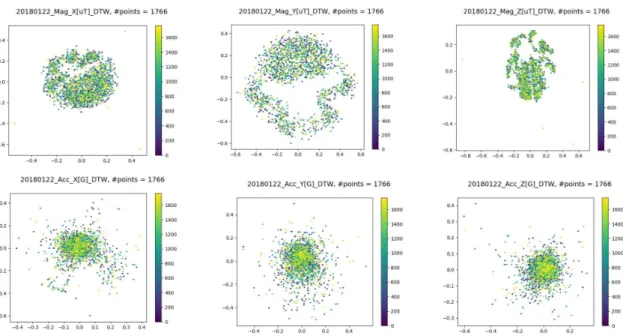
- 図9には、「whole data scale」で正規化されたデータを DTW 距離で分類した結果 を表す。この結果は、DTW ベースで分類した結果と呼ぶ。
- 8 -
図 9:「whole data scale」+ DTW 距離の分類結果
- DTW ベースとユークリッドベースで分類した結果を比べると、双方で検知され た異常(外れ値)は同じになった(図 10)。 Outliers Normal Normal Euclidean Distance DTW Distance
- 9 -
図 10:ユークリッドベースと動的時間伸縮法ベースで検知された異常(外れ値)
b.
Short
TimeSeries Scale
- 標準偏差(standard deviation scale)は次の方程式により正規化する。 =TS − mean(TS)( )
ただし、TS は部分時系列で、時系列データから区分けした。
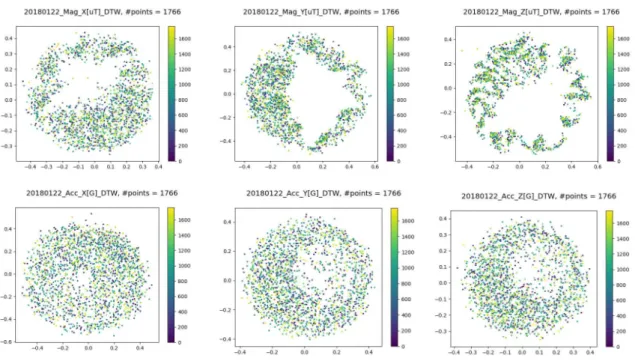
- 「short time series scale」で正規化したデータを用いて、DTW ベースで分類した結 果を図 11 に表す。このアプローチによる分類では、正常と異常(外れ値)の分離 は明確にならなかった。 Outliers Normal Euclidean Distance DTW Distance Outliers Normal
- 10 -
図 11:「short time scale」で正規化されたデータを DTW 距離で分類した結果 (2018 年 01 月 22 日のデータ)
6.
オートエンコーダによる復元データ
A) オートエンコーダモデル
Tensorflow のディープラーニングライブラリを利用して、オートエンコーダモデルを構 成した。このモデルはエンコーダーとデコーダーの 2 つ部分があり、エンコーダーはインプ ット層、128-neuron 層、64-neuron 層、32-neuron 層の 4 層で構成した。デコーダーは 32-neuron 層、64-neuron 層、128-neuron 層、アウトプット層の 4 層で構成した。 オートエンコーダモデルを学習するため、IoT データの時系列をインプットとしてモデ ルに入力して、それからモデルのアウトプットとインプットを比較した。インプットとアウ トプットの差は損失と呼ばれ、オートエンコーダモデルの重みとバイアスを更新するため に利用した。 図 12:時系列データのオートエンコーダモデル
Input
Output
- 11 - B) 復元データの結果
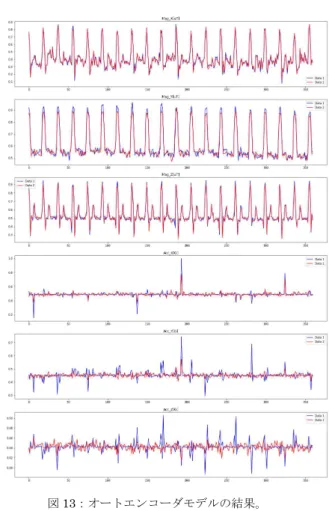
図 13:オートエンコーダモデルの結果。 青い線はインプットで、赤い線はアウトプットである。
オートエンコーダモデルの復元データの結果を図 13 に表す。オートエンコーダモデル は磁場データ(Mag_X[uT], Mag_Y[uT] , Mag_Z[uT])に対して、復元データの再現性が良く、 アウトプットデータ(赤い線)とインプットデータ(青い線)がほぼ重なっている。しかし、 加速度のデータ(Acc_x[G], Acc_y[G] , Acc_z[G])については、モデルの復元性が良くなかった。 その原因は、加速度が変位の2階微分のため、今回のサンプリング間隔では時間変動が大き く、データがランダムになったからと考えられる。 C) 復元データの評価 オートエンコーダモデルのインプットとアウトプットの差を評価するため、Different Average (DA)値を定義する。オートエンコーダのインプット時系列 A とアウトプット時系列 B に対して、A と B の DA 値は次により定義される。 ( , ) = | − | !"#$(%) &'(
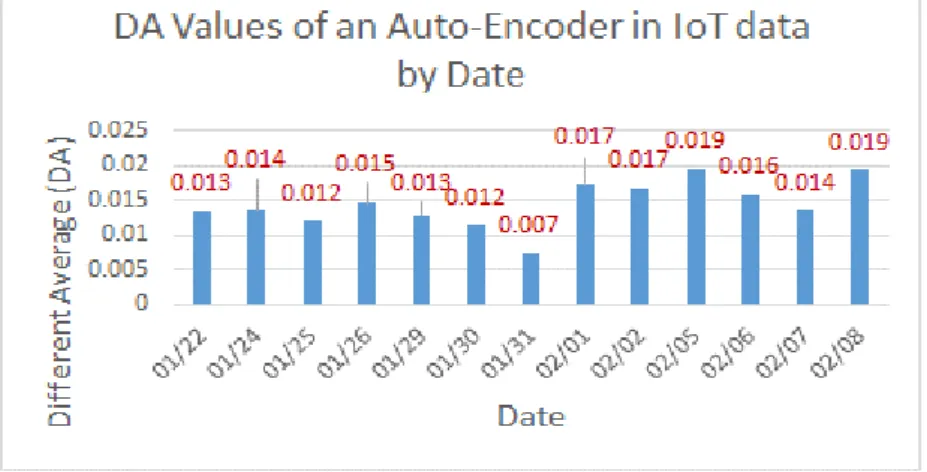
- 12 - ( , ) =-./0 ℎ( )Diff(A, B) オートエンコーダモデルでは、インプットの長さとアウトプットの長さは等しい。IoT データの DA 値は図 14 に表す。ちなみに、オートエンコーダを学習する前、インプットデ ータは[0, 1]範囲に正規化した。図 14 から、2018 年 01 月 31 日の DA 値が最小値である事が わかった。理由は、2018 年 01 月 31 日のデータの中に大幅な変動があり、正規化したデー タの値が小さくなったためと考えられる。その他の日の DA 値は、0.012 から 0.019 の範囲 で推移している。 図 15 は、DA 値が最小値であった 2018 年 01 月 31 日の時系列データを示しており、地 磁気の 3 成分 Mag_X[uT], Mag_Y[uT], Mag_Z[uT]の値が 500,000 で大きく変化している。広 合化学の方にこの状況についてヒアリングしたところ、この日にセンサーの位置を変更し たそうなので、急激に地磁気の取る値が変化したと考えられる。
- 13 - 図 15:2018 年 01 月 31 日のデータグラフにより、大幅な変動があるので、ノーマライズされたデータの値は 小さくなった。そのため、DA 値は他の日より小さい。
7.
エンコーダーしたデータの分類
A) エンコーダーしたデータの取り出し オートエンコーダモデルを学習した後、32-neuron 層からエンコーダーしたデータを取 り出した。それから、そのデータをクラスタリングアルゴリズムで分類した。エンコーダー したデータを分類するため、部分時系列の距離手法としてユークリッド距離を使用した。エ ンコーダーしたデータは時系列データではないため、データ分類時に DTW 距離を使用しな かった。- 14 - 図 16:オートエンコーダモデルの中間層から取り出したデータを分類する。 B) エンコーダーしたデータの分類結果 IoT データの全データでオートエンコーダモデルを学習して、それからエンコーダーし たデータを分類した結果を図 17 と図 18 に示す。各図において、右側にある色づけされた 数値範囲は、図4の時系列の区分けにおける、時系列データ中の指数を表す。部分時系列の 指数 0 は勤務開始時間で、最大値の指数は勤務終わりの時間である。 図 17:1 月のデータをエンコーダーされたデータの分類結果 図 18 に表した 2 月のデータの分類結果は、1 月の結果と異なっていることがわかる。 図 17 では、部分時系列は時間に変化する傾向があるが、図 18 では全体的に分散する傾向 がある。また、2018 年 2 月 2 日と 2018 年 2 月 6 日の結果には、他の時系列から外れた部分
Input
Output
Extract Encoded Data from this Layer
- 15 - 時系列がある事がわかった。外れた部分を拡大して調べると、その部分時系列は 0 に近い指 数のデータであった。 図 19 に 2018 年 02 月 02 日の外れ値付近の地磁気と加速度の 6 軸の時系列データを示 す。横軸の時系列指数が 55,250 から 56,750 の間で、データが変則的であることがわかる。 広合化学のヒアリングによると、この日はインバータの故障で異常温度になったため機械 を一時停止し、試運転を行ったとのことなので、その期間が 2018 年 02 月 02 日の外れ値と して現れたと考えられる。 図 18:2 月のデータをエンコーダーされたデータの分類結果
- 16 - 図 19:2018 年 02 月 02 日の外れ値付近の時系列データ
8.
LSTM モデルによるデータ予測
A) LSTM モデルとデータ前処理 a. モデル モデルを構成するため、Tensorflow のディープランニングライブラリを利用した。まず、 18 個のインプットと 1 個のアウトプットの LSTM モデルを構成した。これは過去のデータか ら1秒後の値を予測するモデルである。 図 20:LSTM モデルOutliers
- 17 - b. データ前処理 全データのうち、8 割を教師用データに、2 割をテスト用データに分割した。LSTM モデ ルによる教師データの前処理ため、時系列データを部分時系列に分割した。分割の方法は、 図 21 に示す。この分割は、LSTM モデルのインプットになる部分時系列の長さ input_len と、 モデルにより予測する部分時系列の長さ pred_len という 2 つのパラメータからなる。図 21 は input_len = 36、pred_len = 18 の場合である。 図 21:LSTM モデルのデータ前処理例 B) 予測結果 a. 1秒後の予測 LSTM モデルでの IoT データの1秒後の予測結果を図 22 に示す。このモデルは図 22 の 右下拡大図に表示されたように、インプットに対しては正しく 1 秒後の値が予測できた。し かし、異常な時系列など、図 22 の左下拡大図に表示された複雑な時系列インプットに対し ては、このモデルでは予測が困難であった。 図 22:LSTM モデルでの1秒後の予測結果
Input: A long time series
Output:
A set of shorter time series
…
- 18 - b. 5 秒後の予測結果 数秒後を予測できる LSTM モデルで、input_len = 18, pred_len = 5 を設定して 5 秒後を予 測した。この LSTM モデルは、図 23 の右下拡大図で示されたように循環性の波形のピーク は時系列に対して捉えることができた。一方、図 23 の左下拡大図に表される複雑なパター ンの時系列に対しては大きな振動波形は捉えられなかった。 図 23:LSTM モデルでの 5 秒後の予測結果 c. 18 秒後の予測結果
pred_len = 18 と予測時間を設定し、インプット時系列の長さ input_len = 36 と input_len = 54 の 2 種類を設定した。それぞれ、予測結果を図 24 と図 25 に示す。しかし、2 つモデ ルの両方は、異常な時系列(外れ)に対して、図 24 と図 25 の左側のように予測ができな かった。 その理由は、訓練データの中に異常な部分時系列が無かったからである。ま た、訓練データの中に異常なデータの個数が少なすぎる場合でも、同様な問題が起こるこ とが多い。これは不均衡データを用いた機械学習の問題と呼ばれている。
- 19 - 図 24:36 秒のインプットで、18 秒後予測する LSTM モデルの予測結果例 図 25:54 秒のインプットで、18 秒後予測する LSTM モデルの予測結果例
9.
まとめ
A) 統計的なクラスタリングによる分析 SVM one-class clustering アルゴリズムを用いた統計的なクラスタリングによる分析で は、地磁気データの外れ値から時系列の異常波形を検知することができた。 B) オートエンコーダによる復元データ ニューラルネットワークを用いたオートエンコーダにより、地磁気と加速度の時系 列データを復元した。地磁気の復元性は高かったが、加速度の復元性は低かった。これ は、加速度が変位の2階微分のため、今回のサンプリング間隔 1 秒では長く、時間変動 が大きく、データがランダムになったからと考えられる。- 20 - C) LSTM モデルによるデータ予測 ニューラルネットワークを用いた LSTM モデルにより、時系列データの予測を行っ た。1 秒先の予測は、正常なデータに対してピークの波形部分を正しく捉えることがで きたが、異常値と検知された複雑な波形は正しく予測できなかった。予測時間を長くし た 5 秒や 18 秒先の予測においても、同様な傾向を示した。 ニューロビジネス研究会では、広島県大竹市にあるゴム・プラスチックを製造する広 合化学株式会社のブロー成型機の稼動部に安価なセンサーを試験的に取り付け、取得 したデータの分析を行った。 試験的に取り付けたセンサーから取得したデータの中で、比較的安定な波形を示す 地磁気データに関しては、異常値の検知が可能で、データの復元性も高く、正常な時系 列データに対するピーク波形を予測することができた。一方で、加速度のようなランダ ムなデータに対しては、復元性と予測は困難であった。動きの激しいブロー成型機で、 復元性と予測精度を高めるためには、サンプリング時間の短縮や、データ取得に最適な センサー位置を探すなどの検討が必要になると考えられる。 今回の結果より、センサーからより多くの異常値を蓄積したデータを分析すること で、機器の故障検知を更に高め、機器の予防保全に活用することが可能と考えられる。 また、異常値を検知し得る相関性の高いデータ種別を更に用いることで、データの復元 性と時系列予測も実用的になり、中小企業において IoT センサーを用いたデータ分析 は、有効な手段になると考えられる。 以上 参考文献
[1] A Description of Dynamic Time Warping (DTW) measurement http://web.science.mq.edu.au/~cassidy/comp449/html/ch11s02.html
[2] Keogh, Ratanamahatana (2002). “Exact indexing of dynamic time warping”. In proceedings of the 26th Int'l Conference on Very Large Data Bases. Hong Kong. pp 406-417.
[3] Perng, Wang, Zhang, Parker (2000). “Landmarks: a newmodel for similarity-based pattern querying in time series databases”. Proc.2000 ICDE, pp. 33–42.
[4] Shieh and Keogh (2008). “iSAX: Indexing and Mining Terabyte Sized Time Series”. SIGKDD, pp 623-631.