2007 年度 修士論文
HMM における
尤度パターンの非対称性を利用した 音声認識に関する研究
指導教授
小林 哲則 教授
早稲田大学大学院 理工学研究科 情報・ネットワーク専攻 知覚情報システム研究室
3606U029-4
加 藤 健 一
i
目 次
第1章 序論 1
1.1 研究背景. . . . 1
1.2 従来研究. . . . 2
1.2.1 SLPを用いた認識法 . . . . 2
1.2.2 LLPを用いた認識法 . . . . 5
1.3 研究目的. . . . 7
1.4 本論文の構成 . . . . 7
第2章 HMMの尤度の非対称性を用いた音声認識 10 2.1 はじめに. . . . 10
2.2 尤度パターンの非対称性 . . . . 10
2.3 尤度パターンを用いた階層型単語音声認識 . . . . 14
2.3.1 概要 . . . . 14
2.3.2 SLPに基づく音声認識 . . . . 15
2.3.3 LLPに基づく音声認識 . . . . 16
2.4 単語音声認識実験 . . . . 17
2.4.1 SLPとLLPの比較 . . . . 17
2.4.2 学習データ量と性能の関連性 . . . . 20
2.5 まとめ . . . . 22
第3章 尤度特徴量次元数削減による頑健性向上に関する検討 27 3.1 はじめに. . . . 27
3.2 次元削減の手法 . . . . 27
3.3 尤度特徴量の次元数削減方式 . . . . 28
3.4 音声認識実験 . . . . 31
3.4.1 実験条件 . . . . 32
3.4.2 実験結果 . . . . 33
3.5 合成音声の利用 . . . . 33
3.5.1 HMM音声合成の概要 . . . . 34
3.5.2 実験条件 . . . . 34
ii
3.6 まとめ . . . . 36
第4章 HMMの非対称性を利用した識別器の統合 37 4.1 はじめに. . . . 37
4.2 相補的な識別器の生成と統合 . . . . 39
4.2.1 提案システムの概要 . . . . 39
4.2.2 相補的な識別器の生成 . . . . 40
4.2.3 相補的な識別器の統合 . . . . 44
4.3 音声認識実験 . . . . 45
4.3.1 実験条件 . . . . 45
4.3.2 実験結果 . . . . 46
4.4 まとめ . . . . 47
第5章 結論 52
謝辞 53
iii
表 目 次
4.1 Evaluation Items. . . . . 46
iv
図 目 次
1.1 MLPによるDPFの抽出および,DPFを利用した認識システムのブ
ロックダイアグラム[7]. . . . . 4
1.2 TANDEMアプローチによる音声認識システムのブロックダイアグ ラム[8]. . . . . 4
1.3 単語単位の尤度パターンとPLRMを用いた認識法[14]. . . . . 6
2.1 同一カテゴリの発話に対するモデルが与える尤度パターン. . . . . 12
2.2 異なるカテゴリの発話に対するモデルが与える尤度パターン. . . . 13
2.3 尤度パターンの非対称性. . . . . 14
2.4 HMMから得られる尤度を特徴量とした階層型音声認識. . . . . . 14
2.5 SLP-SVMの学習手順および評価手順. . . . . 23
2.6 LLP-SVMの学習手順および評価手順.. . . . 24
2.7 各比較項目に対する単語誤り率. . . . . 25
2.8 学習データ量を変化させた時のLLPに基づく手法と単語HMMに 対する単語誤り率. . . . . 26
3.1 各単語における尤度部分空間. . . . . 29
3.2 尤度特徴選択の例.縦軸が実際に認識されやすい単語カテゴリを, 横軸が正解の単語カテゴリを表す.表中の数値はそれぞれの単語カ テゴリにおける順位の平均値である. . . . . 30
3.3 尤度特徴次元削減手順の概要. . . . . 32
3.4 学習データ量を変化させたときのLLPに基づく手法,次元削減を 行ったLLPに基づく手法,および単語HMMに対する単語誤り率. 34 3.5 合成音声から得られる尤度パターンを学習に用いた場合の単語誤り 率.5次元,10次元,20次元の特徴選択を行った場合について実 験を行った. . . . . 36
4.1 提案手法による学習の手順 . . . . 48
4.2 提案手法による認識の手順 . . . . 49
4.3 統合に用いる特徴ベクトル(Nc は識別クラス数を表す) . . . . 50
v 4.4 Word correct for evaluation items. . . . . 51
1
第 1 章 序論
1.1 研究背景
音声認識には,統計的パターン認識の枠組が用いられている.音声認識の応用 アプリケーションとしては,カーナビゲーションシステムや自動会議議事録シス テムが期待されている.また,電話などでの音声対話自動案内システムや,同時 自動翻訳機など,音声認識は幅広い用途に使用されている.音声認識で用いられ る音響モデルなどの確率モデルは,正解カテゴリのデータに対して高い尤度を与 えるように学習されるが,実際に出力される尤度の値は,学習データの量や,確 率モデルの構成によって特徴づけられる.また,不正解のカテゴリであっても音 韻的に類似しているカテゴリのデータであれば,不当に高い尤度を与える可能性 がある.このような認識誤りを削減するために,従来は学習データを増やしたり,
確率モデルの構成を工夫したりすることで対処してきた[1]- [3].しかし,単純化 された確率モデルで複雑な現象を完全に扱うことは難しく,認識誤りを劇的に減 じることは困難であった.
本研究では,確率モデルの精度を上げることで音声認識性能を向上させるとい う立場ではなく,通常用いられているHMMが出力する各カテゴリに対する尤度 のパターンを特徴として捉え,静的に音声認識を行うという階層的な枠組により 音声認識性能を向上させる立場をとる.
確率モデルが与える尤度のパターンを特徴量として識別を行う枠組は次の二つ に大別できる.一つは音素や状態など比較的短い時間構造を持つ確率モデルを用い て,複数フレームの情報を保持したスペクトル特徴ベクトルの尤度パターンを抽出
第1章 序論 2 し,それらの時系列に対してHMMを用いた動的な認識を行う枠組である.そし てもう一つは,単語などの比較的長い時間構造を持つ確率モデルを用いて,単語発 話に対して尤度パターンを抽出し,それらを特徴として静的な認識を行う枠組で ある.ここで,状態などの短い時間構造を持つHMMから得られた尤度パターン をshort-time based likelihood pattern (SLP),単語などの長い時間構造を持つHMM から得られた尤度パターンをlong-time based likelihood pattern (LLP)と呼ぶことに する.我々は後者の,長い時間構造を持つ確率モデルから得られる尤度パターン
(LLP)を特徴として用いる枠組を採用する.HMMの性質上,この尤度パターンは
音韻的に類似する単語カテゴリであっても類似するパターンを与えるとは限らず,
非対称なパターンを示す.それに加えて,この尤度パターンはカテゴリごとに安 定したパターンを示す.このように,尤度パターンはカテゴリごとに識別的なパ ターンを示すので,これをパターン認識の特徴量として利用することで,特に誤 り易い識別カテゴリ同士の識別精度を向上できることが期待できる.
1.2 従来研究
確率モデルから得られる尤度パターンを特徴量として識別を行う枠組のうち,
SLP を特徴量として識別を行う枠組は音素弁別特徴 [5]- [7]や,TANDEM アプ ローチなどが挙げられる.一方,LLPを特徴量とする枠組としては,後段の認識 にdPLRM [14] [15]を用いた手法がこれにあたる.
1.2.1 SLP を用いた認識法
音素弁別特徴の利用
音韻論の分野では,母音性や子音性,連続性といった調音様式や,高舌性,前 方性,舌端性といった調音位置を表す音素弁別特徴(Distinctive Phonetic-Feature
(DPF))による音素分類が古くから提案されている.音声認識においても,DPFの
第1章 序論 3 積極的な利用が近年検討されている.DPFの特徴としては,以下に示すものが挙 げられており,特に悪環境下での高精度な音声認識を可能にする枠組として期待 されている.
• 調音の類似した音素を距離の近いベクトルとして扱える.
• 調音方式や調音位置を陽に表現した特徴量であるため,利用環境の影響を受 け難いと推測される.
• 連続量である音響特徴ベクトルと離散量である音素との中間表現として位置 づけられる.
DPFの抽出法としては,GMM を利用する枠組 [6]が提案されており,これは 各々の弁別素性に対してその弁別素性が音声に存在するか,存在しないか,という 2つのモデルを生成し,それらの尤度を比較することでDPFを抽出している.一 方,Leeらは,複数の多層パーセプトロン(MLP)を用いてDPFの抽出を提案して
いる[7].この手法では,各々のMLPと1つの弁別素性を対応づけて学習し,入
力をMFCC,出力を弁別素性の事後確率としている.そして,認識時には各MLP
の出力,すなわち DPFにKL展開を行い,それを MFCCのパワー成分と結合す ることで MFCCに変わる新たな特徴量とし,HMMによる認識を行う.図1.1に Leeらが提案しているシステムの概要を示す.これらの手法は,DPF単独では高 い性能を得られないため,従来のMFCCと組み合わせて用いられている.それに 対し,福田らは 単一のMLPからDPFを抽出し,それを単独で認識に利用してい
る[5].この手法では,MLPへの入力として局所特徴を用いており,その際,先行
および後続するコンテキストも入力としている.この手法は,クリーン音声に対 して認識を行った場合,従来のMFCCを特徴とするHMMによる認識法と同程度 の性能しか与えていないが,雑音を重畳した音声に対しては従来法よりも誤りを 削減している.
第1章 序論 4
MFCC Extraction
Energy NN 1
NN 60
Concatenation leading to a
60-dimensional vector KL
12MFCC + 1 Energy
61-dimensional vector
HMM
Training data
MFCC Extraction
Energy NN 1
NN 60
Concatenation leading to a
60-dimensional vector KL
12MFCC + 1 Energy 12MFCC + 1 Energy
61-dimensional vector
HMM
Training data
図1.1 MLPによるDPFの抽出および,DPFを利用した認識システムのブロック ダイアグラム[7].
GMM/HMM Viterbi Neural net
(MLP) Feature
calculation
PCA Speech
signal
Post probability
Word/sub word
likelihoods Sequence of words GMM/HMM Viterbi Neural net
(MLP) Feature
calculation
PCA Speech
signal
Post probability
Word/sub word
likelihoods Sequence of words
図1.2 TANDEMアプローチによる音声認識システムのブロックダイアグラム[8].
TANDEMアプローチ
TANDEMアプローチとは,Hermanskyらが提案した手法であり,連続する前後
複数フレームの音響特徴量から,多層パーセプトロン(multi-layer perceptron (MLP)) を用いて音素事後確率を出力し,それを特徴量としてHMMやGMMにより識別 する枠組である.図1.2にTANDEMアプローチによる音声認識のブロックダイア グラムを示す.
TANDEMアプローチでは,MLPを用いているため高い非線形識別性能を利用
することができる.また,少量の学習データで高い認識性能を示している [10].
TANDEMアプローチの派生系としては,NLPの出力を音素の事後確率ではなく,
調音の事後確率を用いたもの[9]や,TempoRAl Patterns (TRAPs) [11] [12]と組み
第1章 序論 5 合わせた手法がある.また,中国語の認識のために音調(Tone)の事後確率を特徴 とし,TANDEMアプローチに利用する枠組も提案されている[13].中国語の認識 において音調の情報は不可欠であり,従来はフレーム単位で音調の情報を抽出し てきた.しかし,音調は音節単位のf0で決定されるため,フレーム単位のf0から は十分な音調の情報を得られない.TANDEMアプローチは,前後複数フレームの 音響特徴から事後確率特徴量を抽出しているため,長い時間単位を考慮しており,
音調の情報を十分に得られるとされている.また,TANDEMアプローチはその高 い認識性能から,会議の議事録支援システムの作成を目的としたAMI Project [16]
にも利用されている.
以上に挙げたSLPを利用する認識の枠組は,認識性能の改善はされているもの の,フレーム単位で尤度パターンを求め,それを特徴量としているため,得られ た特徴量はもとの音響特徴量の単なる座標変換とみなすことができ,劇的に誤り を削減することは困難である.
1.2.2 LLP を用いた認識法
PLRMによる認識
長い時間構造を持つHMMから得られる尤度パターン(LLP)を用いる枠組とし て,Birkenesらが提案している,Penalized Logistic Regression Machine (PLRM)を 後段の認識器に用いる手法[14]が挙げられる.この手法は,HMMが出力する認 識対象語彙全ての尤度の値を特徴量としてPLRMに入力し,各単語カテゴリの事 後確率を推定する手法である.図1.3に,PLRMを用いた認識法の概要を示す.図 1.3のφ(x;λi)は観測データ系列xが与えられた時の,単語iのHMMが与える対 数尤度である.fkはPLRMの識別関数であり,以下の式で表される.
fk =fk(x;θ) =wTkφ(x; Λ) (1.1)
φ(x; Λ) = [1, φ(x;λ1), φ(x;λ2),· · ·, φ(x;λK)]T (1.2)
第1章 序論 6
( )
( )
( x K )
x x
λ φ
λ φ
λ φ
;
;
;
2 1
f
Kf f
2 1
p
Kp p
ˆ ˆ ˆ
2 1
x … … …
1 W
( )
( )
( x K )
x x
λ φ
λ φ
λ φ
;
;
;
2 1
f
Kf f
2 1
p
Kp p
ˆ ˆ ˆ
2 1
x … … …
1 W
図1.3 単語単位の尤度パターンとPLRMを用いた認識法[14].
wk は重みベクトルである.また,最終的な認識に利用される,単語 k の事後確 率は
ˆ
pk= ˆpk(x;θ) = expfk(x;θ) PK
l=1expfl(x;θ) (1.3) で計算される.また,この手法を拡張し,連続数字認識のN −bestのリスコアリ ングにも適用されている[15].このときの尤度特徴量は数字単位で抽出されてお り,やはり音素などに比べて比較的長い時間構造を持つHMMから尤度パターン を得ている.
これらの手法のように,単語などの長い時間構造をHMMから尤度パターンを 得た場合,尤度パターンは非対称性を顕著に表し,これを認識に利用することで,
特に誤り易いカテゴリ同士の認識精度を上げられる可能性がある.しかし,LLP に基づく認識法は,単語のような長い時間長を持つ単位に対する尤度パターンを 用いているため,学習データの収集が困難になる.そのため,大語彙を扱うタス クでは学習データを十分に得ることができず,モデルの信頼性が低下することで,
第1章 序論 7 高い認識性能が得られない可能性がある.また,この手法では,識別対象語彙に 対する尤度を特徴量としているため,大語彙を扱うタスクでは特徴量の次元数が 膨大になり,計算量の観点で問題となる.
1.3 研究目的
本稿では,HMMにおける尤度パターンの非対称性を利用するにおいて,LLPを 特徴量として認識を行うことの妥当性を述べる.
また,LLPを認識に利用するにあたり,以下の2点が問題となる.
• 単語学習データ量の不足
• 語彙数増加に伴う尤度特徴次元数の増大
本研究では,単語HMMから得られた尤度パターンを特徴量として用いた階層的 な音声認識手法において,学習データ量と音声認識性能の関係について調査を行 う.また,LLPに基づく認識法に,特徴選択に基づく尤度特徴ベクトルの次元数 削減を適用した場合についても評価を行う.
1.4 本論文の構成
本論文は5章から構成されており,前節では本研究の背景から始まり,従来研 究,本研究の目的について述べた.
第2章では本論文の主体となる,尤度パターンとその非対称性について述べる.
HMMの出力する尤度パターンは,音韻的に類似するカテゴリ同士であっても非対 称的なパターンを示し,かつカテゴリごとに安定したパターンを持つ.そのため,
これを特徴量とすることで特に誤り易いカテゴリ間の認識精度の向上が期待でき る.この尤度パターンの非対称性は,HMMの一般的な性質から起こりうるもの であり,特に単語などの比較的長い時間構造を持つHMMから与えられる尤度パ
第1章 序論 8
ターン(LLP)は非対称性を顕著に現すと予想される.一方,音素などの比較的短
い時間構造を持つHMMから与えられる尤度パターン(SLP)は,フレームごとに 特徴抽出されているため,単なる音響特徴量の座標変換と同等とみなすことがで き,十分な認識性能の向上が見込めないと思われる.本研究では,SLPとLLPそ れぞれを用いた認識手法の比較を孤立単語音声認識実験によって行う.また,LLP を利用する枠組は単語単位で尤度パターンを求めているため,大語彙を扱うタス クの場合,単語学習データ量が不足し,モデルの精度の低下が予想される.そこ で本研究では,学習データ量と性能の関係について調査を行う.
第3章では尤度特徴量の次元削減について述べる.LLPを利用する認識手法は,
現状では全ての認識対象語彙の尤度を特徴量としている.そのため,語彙数が増 加するに伴い尤度特徴量の次元数も増大し,計算量的に大語彙を扱うタスクに適 用しづらい.そこで尤度特徴量の次元削減について検討する必要がある.本研究 では,PCAやHLDAなどのような次元圧縮ではなく,特徴選択による次元削減を 行う.特徴選択の基準としては,単語ごとに誤認識されやすい単語群を予め求め ておき,その単語群に対する尤度を特徴量とする.すなわち,各単語ごとに固有 の尤度空間を展開することになる.本研究では,尤度特徴量を元々の次元数であ る216次元のわずか4.6%である10次元まで削減した場合において,孤立単語音 声認識実験を行い,少量の尤度特徴次元数においても,高い認識性能を示すこと を確認する.
第4章では尤度パターンの非対称性を利用した識別器の統合について述べる.近 年,識別器の性能を向上させるために,確率モデルや探索アルゴリズムの精密化 に注力するのではなく,複数の識別器から得られる情報を統合する枠組が検討さ れている.このとき,複数の識別器は相補的でなくてはならない.また,識別器 の統合を行うとき,統合対象となる識別器のうち一つあるいは全てが,識別にお いて不適切な特性を持つ場合,統合後もその影響が残り,たとえ相補的であって も認識性能が向上しない可能性がある.以上を考慮し,本研究ではHLDAに基づ
第1章 序論 9 く特徴変換にブースティングの枠組を適用することで相補的な識別器の生成を行 い,生成された複数の識別器から与えられる尤度パターンを統合に利用する.
通常,ブースティングは識別器の設計時(モデルのパラメータ推定時)に適用さ れるため,学習において重要視されるサンプルと軽視されるサンプルが生じる.し たがって,新たに生成される識別器は相補性は得られているものの,識別性能は基 の識別器よりも劣化する.それに対し本手法は,特徴変換の過程において相補性 を得ようとしているため,学習の過程で軽視するサンプルは生じず,結果的に識別 性能劣化の可能性を低く抑えた上で,誤り傾向の異なる識別器が生成されること が期待できる.また,各識別器が出力する尤度パターンは統合対象となる各々の識 別器が有する誤り傾向(相補性)そのものと解釈することができ,これを統合に利 用することで識別器の相補性の情報を有効に使うことが出来る.ここでは,HLDA および HLDA にブースティングの枠組を適用したWHLDA について述べる.ま た,それぞれの座標変換で得られた識別器は相補的であることと,尤度パターン を用いた統合法の有効性を孤立単語音声認識実験で確認する.
第5章では本研究の結論について述べる.本研究ではHMMから得られる尤度 パターンの非対称性に着目し,LLPを特徴量とすることの妥当性を述べた.LLP を認識に利用する際,学習データ量の不足や尤度特徴の次元数増加といった問題 に取り組んだ.その結果,LLPを用いた認識法は少量の学習データ量,および,ご く少数の尤度特徴次元数においても高い認識性能を示し,大語彙タスクへの適用 可能性が示された.
10
第 2 章 HMM の尤度の非対称性を用 いた音声認識
2.1 はじめに
音声認識において一般的に用いられている確率モデルである Hidden Markov
Model (HMM)は,正解カテゴリに対して高い尤度を与えるように学習されるが,
学習データの量や種類,確率モデルの構成などによって,実際に出力される尤度 は特徴付けられ,異なるカテゴリのデータに対しても不当に高い尤度を与える可 能性がある.これから生じる誤りを削減するために,従来は学習データ量を増や したり,HMMの構成を工夫したりといった手段が取られてきたが,認識性能を大 幅に改善するまでには至っていない.
本研究では,HMM の精度を上げることで音声認識性能を上げるのではなく,
HMMの与える尤度パターンの非対称性に着目し,それを利用することで音声認 識性能の向上を図る.
2.2 尤度パターンの非対称性
本研究で扱う尤度パターンについて述べる.尤度パターンとは,音声データに 対して各々のクラスの確率モデルが与える尤度の値である.単語発話に対して識 別対象カテゴリである単語の尤度をHMMを用いて計算し,それらの値をパター ンとして捉え,認識の特徴量として利用する.ここで,音響的に類似する単語同 士では,HMMによって与えられる尤度パターンも類似しており,そのような尤度 パターンを特徴として用いた場合,両者を正しく識別できないことが懸念される.
第2章 HMMの尤度の非対称性を用いた音声認識 11 しかし,実際には尤度パターンは類似する単語同士であっても非対称性を示すた め,互いに誤り易い単語の識別性能を向上できる可能性がある.ここで述べる尤 度パターンの非対称性とは,類似するカテゴリ間での尤度の出方が異なることを 表す.例えば,単語 Aの発話に対して単語BのHMMが与える尤度が高い場合,
必ずしもその逆は成り立たず,単語Bの発話に対して単語AのHMMが低い尤度 を与える場合がある.このような関係を尤度パターンの非対称性と呼ぶ.
次に,尤度パターンの非対称性が生じる理由について述べる.この尤度パター ンの非対称性はHMMの性質上起こり得る.以下,例を用いて非対称性が生じる 理由を述べる.図2.1,図2.2が表すのは,HMMによって与えられる時間アライ メントと,尤度の出方を表している.ここで,“good”は,発話とモデルが適合し,
高い尤度を与えていることを意味し,“bad”は低い尤度が与えられていることを意 味する.図中の/a/,/b/,/c/は単語を構成する音韻に相当し,横軸が時間を,縦軸 が各音韻の分布を表す.図2.1(a)では単語/abc/のHMMに 単語/abc/の発話を入 力した場合を,図2.1(b)では,単語/ac/のHMMに 単語/ac/の発話を入力した場 合を示している.このように,入力発話と同一カテゴリのHMMを用いた場合は,
良好な尤度を与えることが期待される.図2.2(a)では単語 /abc/のHMMに 単語 /ac/ の発話を入力した場合を,図2.2(b)では単語/ac/の HMMに 単語/abc/の発 話を入力した場合を表している.どちらの場合もHMMと入力される単語のカテ ゴリは異なる.図2.2(a)の場合,実際には存在しない/b/という音韻の発話区間に 対して,/b/のHMMの状態にはわずかの時間しか滞留せず,(つまり,/b/の状態 をスキップすることと同等となり),結果的に/ac/という発話に対して/abc/という 単語モデルの尤度が高くなる可能性がある.一方図2.2(b)の場合では,実際に存 在する音韻/b/の発話区間に対し,/a/または/c/の状態が割り当てられるため,そ の区間での尤度は低減し,/abc/という発話に対して/ac/という単語の尤度は低く 出力されることが予想される. 以上のような現象がHMMの性質上起こり得るた め,図2.3に示すような,尤度パターンの非対称性が生じる.ここで,未知発話を
第2章 HMMの尤度の非対称性を用いた音声認識 12
(a) /abc/
!#"/abc/
$#%(b) /ac/
!#"/ac/
&$'%
(a) /abc/
!#"/abc/
$#%(b) /ac/
!#"/ac/
&$'%
図2.1 同一カテゴリの発話に対するモデルが与える尤度パターン.
HMMに入力した際,図2.3の破線のような尤度パターンを示した場合を考える.
従来の最尤基準の識別では,尤度の大小で正解カテゴリを推定するが,図のよう に高い尤度が複数のHMMから出力されている場合に推定された結果の信頼度は 低いと言える.しかし,本研究で採用するLLPに基づく手法では尤度の大小では なく尤度パターンの形で正解カテゴリを推定するため,従来の識別法では認識が 困難なカテゴリ間の識別精度を向上できることを期待できる.
同様に,確率モデルが与える尤度のパターンを特徴量として識別を行う枠組であ る,音素群対における確率比[4]や,音素弁別特徴[5]- [7]を用いる枠組,TANDEM
第2章 HMMの尤度の非対称性を用いた音声認識 13
!
"#
$
(a) /abc/
%'&)(+*-,/ac/
%'.0/(b) /ac/
%1&)('*0,/abc/
%'.-/
!
"#
$
!
"#
$
(a) /abc/
%'&)(+*-,/ac/
%'.0/(b) /ac/
%1&)('*0,/abc/
%'.-/図2.2 異なるカテゴリの発話に対するモデルが与える尤度パターン.
アプローチ[8] [9] [16]では,短い時間構造を持つ確率モデルが与える尤度パター
ン(SLP)を特徴量として用いるため,ここで述べたような尤度パターンの非対称
性が生じにくく,認識性能の向上にあまり貢献しないことが予想される.
第2章 HMMの尤度の非対称性を用いた音声認識 14
X
X
図2.3 尤度パターンの非対称性.
Calculate likelihoods for state templates Spectrum
feature vector sequence
Likelihood pattern vector
sequence
Word Utterance
(a) SLP-based method NS-dim
HMM-based dynamic recognition
result
Category : state
Number of templates:
NS
…
…
a1 a2
z3
Category : word ikioi(15-states) iyoiyo(18-states) omoshiroi(24-states)
…
kakurepyu:ritaN (39-states)
…
Spectrum feature vector
sequence
Word Utterance
(b) LLP-based method NW-dim
Category : word Likelihood
pattern vector (each word)
SVM-based static recognition Calculate likelihoods for
word templates
Number of templates:
NW
…
ikioivs. rest iyoiyovs. rest omoshiroivs. rest
…
kakurepyu:ritaNvs. rest result
Category : word ikioi(15-states) iyoiyo(18-states) omoshiroi(24-states)
…
kakurepyu:ritaN (39-states)
…
Calculate likelihoods for state templates Spectrum
feature vector sequence
Likelihood pattern vector
sequence
Word Utterance
(a) SLP-based method NS-dim
HMM-based dynamic recognition
result
Category : state
Number of templates:
NS
…
…
a1 a2
z3
Category : word ikioi(15-states) iyoiyo(18-states) omoshiroi(24-states)
…
kakurepyu:ritaN (39-states)
…
Calculate likelihoods for state templates Spectrum
feature vector sequence
Likelihood pattern vector
sequence
Word Utterance
(a) SLP-based method NS-dim
HMM-based dynamic recognition
result
Category : state
Number of templates:
NS
…
…
a1 a1 a2 a2
z3 z3
Category : word ikioi(15-states) iyoiyo(18-states) omoshiroi(24-states)
…
kakurepyu:ritaN (39-states)
……
Spectrum feature vector
sequence
Word Utterance
(b) LLP-based method NW-dim
Category : word Likelihood
pattern vector (each word)
SVM-based static recognition Calculate likelihoods for
word templates
Number of templates:
NW
…
ikioivs. rest iyoiyovs. rest omoshiroivs. rest
…
kakurepyu:ritaNvs. rest result
Category : word ikioi(15-states) iyoiyo(18-states) omoshiroi(24-states)
…
kakurepyu:ritaN (39-states)
…
Spectrum feature vector
sequence
Word Utterance
(b) LLP-based method NW-dim
Category : word Likelihood
pattern vector (each word)
SVM-based static recognition Calculate likelihoods for
word templates
Number of templates:
NW
…
ikioivs. rest iyoiyovs. rest omoshiroivs. rest
…
kakurepyu:ritaNvs. rest
…
ikioivs. rest iyoiyovs. rest omoshiroivs. rest
…
kakurepyu:ritaNvs. rest result
Category : word ikioi(15-states) iyoiyo(18-states) omoshiroi(24-states)
…
kakurepyu:ritaN (39-states)
……
図2.4 HMMから得られる尤度を特徴量とした階層型音声認識.
2.3 尤度パターンを用いた階層型単語音声認識
2.3.1 概要
尤度パターンを特徴とした,階層型単語音声認識手法について述べる.まず前 段において,あらかじめ設定したカテゴリ群(本実験では,音素モデルの状態また
第2章 HMMの尤度の非対称性を用いた音声認識 15 は単語)が入力データに対して与える尤度を計算する.後段では,得られた尤度を 特徴ベクトルとして,再度識別対象カテゴリ(本実験では単語)の認識を行う.図 2.4 に,尤度パターンを特徴ベクトルとして用いた,階層型音声認識の概要を示 す.SLPに基づく手法(a)とLLPに基づく手法(b)の本質的な違いは,前段におけ る尤度特徴ベクトル抽出の際に長い時間構造を考慮しているかどうかと,後段に おける最終的な単語カテゴリの識別が動的に行われるか静的に行われるかである.
TANDEMアプローチなどの枠組では,尤度特徴ベクトルは音素や音素モデルの状
態などの短い時間構造を持つHMMに対してフレームごとに抽出され,動的な識 別が行われる.それに対しLLPに基づく手法では,尤度特徴ベクトルは,音素と 比較して長い時間構造を持つ単語単位のHMMを用いて,同様に長い時間構造を 持つ単語発話ごとに抽出され,静的な識別が行われる.
2.3.2 SLP に基づく音声認識
ここではSLPを特徴量として用いた手法について述べる.学習と評価の概要を 図2.5に,手順を以下に示す.
学習手順
1. 該当フレームの前後それぞれN フレームのMFCCを結合した,セグメント
単位(SU-MFCC)を構成する.次にPCAにより次元圧縮を行う.
2. 次元圧縮されたセグメント単位の特徴ベクトルを用いて,各音素ごとにセグ メント単位入力HMM [1]を構成し,これをSU-MFCC-HMMとする.
3. 音素モデルの状態に対する尤度パターン(SLP)をSU-MFCC-HMMを用いて フレーム単位で計算する.これらのパターンは(d1, d2,· · · , dNS)という状態 数 NS を次数として持つベクトルで表される.di は,以下のように算出さ
第2章 HMMの尤度の非対称性を用いた音声認識 16 れる.
di = log p(xt|θi) P
jp(xt|θj) (2.1)
ここで,p(xt|θi)は観測データxtのi番目の状態に対する出力確率である.
4. NS 次元のSLP特徴ベクトルをPCAにより,NS0 次元に圧縮し,フレーム単 位のMFCCと結合したものを新たな特徴ベクトルとしてHMMを構成する.
これをSLP-HMMとする.
評価手順
1. 学習手順と同様に,評価データのSLP 特徴ベクトルをフレームごとに抽出 し,PCAによりNS0 次元に圧縮する.
2. SLP特徴量とフレーム単位のMFCCを結合して新たな特徴ベクトルとし,そ
の時系列とSLP-HMMを用いて動的に認識することで,単語音声認識を行う.
2.3.3 LLP に基づく音声認識
ここではLLPを特徴量として用いた手法について述べる.学習と評価の概要を 図2.6に,手順を以下に示す.
学習手順
1. フレーム単位の MFCCの時系列を用いて音素HMM (MFCC-HMM)を構成 する.
2. MFCCと,音素HMMを連結して構成される単語単位のHMMを用いて,単
語発話の単語カテゴリ群に対する尤度パターン(LLP)を求める.このパター ンは(dL1, dL2,· · · , dLN
W)という単語数NW を次数として持つベクトルとして
第2章 HMMの尤度の非対称性を用いた音声認識 17 表わされる.ここで,dLi は,以下のように算出される.
dLi = log p(x1,· · · ,xT|θiL) P
jp(x1,· · · ,xT|θjL) (2.2) ここで,p(x1,· · · ,xT|θiL)は単語発話の観測データ系列x1,· · · ,xT を入力と したときのi番目の単語 HMMθLi が与える出力確率である.この手順によ り,単語発話特徴量は,全ての単語HMMから得られる尤度で構成された空 間へ写像される.
3. 単語HMMから得られた尤度を特徴量として,各単語カテゴリごとにsupport vector machine (SVM)を構成する(LLP-SVM).
評価手順
1. 学習手順と同様に評価データの尤度パターン(LLP)を各単語ごとに抽出する.
2. 単語発話単位のLLP特徴ベクトルと,LLP-SVMを用いて静的に認識するこ とで単語音声認識を行う.
2.4 単語音声認識実験
LLPに基づく認識法の基本性能を見るため,孤立単語音声認識実験を行なった.
2.4.1 SLP と LLP の比較
実験条件 (a)音声データ
実験に使用した音声データは,接話マイクロホンで収録され,16 kHzでサンプリ ング,16 bitで量子化されている.学習用の連続音声データは,ASJのデータベー スより,男性133話者が発話した新聞記事(ASJ-JNAS)と音素バランス文(ASJ-PB) から構成される 20413 文の読み上げ音声 [20]を用いた.評価用の孤立単語音声
第2章 HMMの尤度の非対称性を用いた音声認識 18 データは,ATRの音素バランス単語216単語を男性20話者がそれぞれ5回発話
した計21600発話[21]を用いた.スペクトルに基づく音響特徴パラメータとして
は,MFCC 12次元とパワー,およびそれらの∆パラメータの計26次元の特徴量 を用いた.このとき,フレーム長は25 ms,フレーム周期は10msである.
(b)評価項目
以下に示す3通りの識別方法を比較した.
• MFCCを用いたHMMによる動的な識別(MFCC-HMM)
• 音素モデルの状態に対する尤度パターンを用いた HMMによる動的な識別 (SLP-HMM)
• 語彙中の全ての単語カテゴリの尤度パターンを用いたSVMによる静的な識 別(LLP-SVM)
(c)SLP-HMMによる識別
前段の尤度特徴ベクトルを抽出するための音響モデルは,ASJのデータベースよ
り20413文を用いて生成されたセグメント単位入力モノフォンHMM (SU-MFCC-
HMM)である.ここで,音素クラス数は43であり,各音素に対して状態数3,混
合数32,分散行列は対角共分散である.セグメント単位に関しては,連続する3
フレームを結合した78次元の特徴量をPCAにより30次元に圧縮した.
学習用の連続発話音声および評価用の孤立単語音声各々に対して,129個の音素 HMMの状態からの尤度パターンをフレームごとに計算し,この129次元の特徴 量をPCAにより5次元に圧縮した.なお,このときの累積寄与率は77.1%である.
後段の,音素HMMの状態に対する尤度特徴ベクトルを用いた認識に用いられ
る SLP-HMMは,SU-MFCC-HMMの学習データと同じ発話からフレームごとに
抽出された 尤度特徴ベクトル(5次元)と,フレームごとのMFCC(26次元)を結合
第2章 HMMの尤度の非対称性を用いた音声認識 19 した31次元の特徴ベクトルを用いて学習される.各音素に対して状態数3,混合
数32,分散行列は対角共分散のモノフォンHMMを構築した.評価には,音素連
鎖バランス単語21600発話を用いた.
(d)LLP-SVMによる識別
MFCC-HMMは2.4.1で述べたSU-MFCC-HMMと同様のデータを用いて学習さ れるが,入力はセグメント単位ではなく,通常のフレーム単位のMFCCである.
HMMは,状態共有型トライフォンHMMであり,HMMの状態数は2000,各状 態の混合数は16,分散行列は対角共分散である.学習データ,評価データ双方に おいて,単語カテゴリ群に対する尤度特徴ベクトル(216次元)を,単語発話ごと に算出する.
後段の認識については,音素連鎖バランス単語21600単語を話者に対して4分 割し,交差検定により評価を行った.そのため,学習には 15 話者が発話した計
16200単語を用い,評価には残りの5話者が発話した計5400単語を用いた.なお,
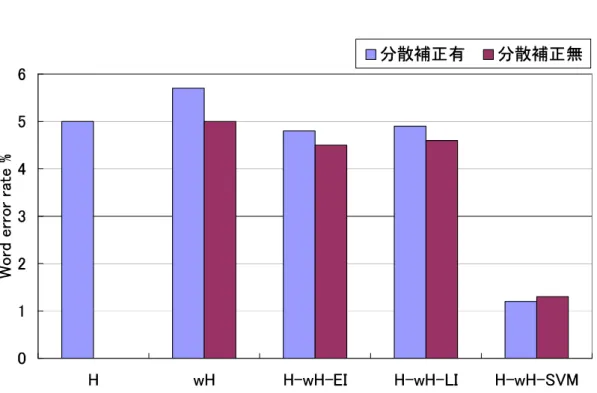
本実験では,前段のHMMによる認識結果の上位nベストの単語カテゴリに対す るSVMを用いて,後段の認識を行う.予備実験で予め最も良い認識性能を示すn を求めた.その結果,HMMの認識結果の内,上位10ベストの単語カテゴリに対 するSVMを用いて後段の認識を行った場合,最も高い認識性能を示し,それ以降 は認識性能は飽和しているため,本実験ではn= 10として後段の認識を行う.
LLP-SVMは”one versus rest”法で学習し,カーネル関数は,線形カーネルを用 いた.このとき,ペナルティ項は10である.
(e)実験結果
図2.7に比較項目に対する単語誤り率を示す.通常の認識手法である,MFCCを 特徴量としたHMMによる認識結果(MFCC-HMM)である96.7%をベースライン とした場合,従来手法の SLP-HMM による動的な認識では認識性能が低下した.
第2章 HMMの尤度の非対称性を用いた音声認識 20 これより,従来のTANDEMアプローチに準ずる手法では,認識性能を大幅に上げ ることは困難であることが分かる.一方, LLP-SVM-fullによる静的な認識では,
認識性能が大きく向上しており,ベースライン(MFCC-HMM)に対する誤り削減 率は79%である.このことから,最尤基準の識別において生じるような誤りを削 減するためには,比較的長い時間構造を持つカテゴリ群の HMMから得られる尤 度パターンを用いて静的な認識を行うことが有効であることがわかった.
2.4.2 学習データ量と性能の関連性
本研究で採用しているLLPに基づく認識法では,単語単位の尤度パターンを用 いるため,学習データに単語発話が必要である.そのため,大語彙を扱うタスク では学習に用いる単語発話を十分に得ることが出来ず,LLPに基づく手法では高 い認識性能が得られない可能性がある.ここでは,LLPを特徴として用いた階層 的な音声認識方式の学習データ量と性能の関連性を調査するため,学習データ量 を変化させた場合の認識性能の変化について調査を行う.
実験条件
(a)LLP-wSVMによる識別
前段の尤度特徴ベクトルを抽出する際に用いた音響モデルは,ASJデータベー
スの20413文を用いて学習した状態共有型トライフォンHMMである.HMMの
状態数は2000,各状態の混合数は16,分散行列は対角共分散である.学習データ,
評価データ双方において,単語カテゴリ群に対する尤度特徴ベクトル(216次元) を,単語発話ごとに算出した.
後段の認識については,学習と評価に用いる音素連鎖バランス単語21600発話 を話者に対して4分割し,交差検定により評価を行った.LLP-wSVMの学習デー タとして,1単語あたり25発話,50発話,75発話の3通りを用い,評価は学習 に含まれていない単語発話に対して行った.このとき,LLP-wSVMは“one versus
第2章 HMMの尤度の非対称性を用いた音声認識 21
rest”法で学習し,カーネル関数は,線形カーネルを用いた.
(b)MFCC-wHMMによる識別
本実験では,単語単位で学習されたHMMを比較対象とする.この単語HMM の構築手順は下記の通りである.まずASJデータベースより20413文を用いて音 素単位のモノフォンHMMを学習した.そして,この音素単位のモノフォンHMM を単語の音素表記に基づいて連結させ,単語単位のHMMを構築した.この単語単 位HMMを初期モデルとして,ATR音素連鎖バランス単語を用いて,単語HMM のパラメータの再推定を行った.このとき,LLP-wSVMと同様,単語データベー スを話者に対して4分割し,交差検定を行った.このように,単語データを用い て再学習された単語HMMをMFCC-wHMMと呼ぶ.このとき,各単語モデルの 状態数は,単語を構成する音素数×3である.
(c)実験結果
図2.8に単語あたりの学習データ数に対する単語誤り率を示す.評価する識別器 は,MFCC-wHMM,LLP-wSVMである.これらの識別器の学習データは同一で ある.これらに加えて,従来一般的に用いられているトライフォンHMM (MFCC-
pHMM)の性能も示した.
これより,75発話のように比較的多くの単語発話を学習に用いた場合は,LLP を用いた手法(LLP-wSVM)は,単語HMM (MFCC-wHMM)と同等の性能しか与え ない.しかし,学習データが25発話のように少量の場合,LLP-wSVMはMFCC- wHMM に比べて64%の誤りを削減した.また,LLP-wSVMは,MFCC-pHMM の誤りも 43%削減した.このように,LLP-wSVMは,少量の学習データを用い た場合,MFCC-pHMM,MFCC-wHMMの誤りを削減していることから,大語彙 を扱うタスクにおいても有効であることが期待できる.
第2章 HMMの尤度の非対称性を用いた音声認識 22
2.5 まとめ
HMMが与える尤度パターンの非対称性に着目し,それを特徴量として利用す る単語音声認識手法について述べた.尤度パターンを利用する枠組としては,短 い時間構造を持つHMMから与えられる尤度パターン(SLP)を特徴とする枠組と,
長い時間構造を持つHMMから与えられる尤度パターン(LLP)を特徴とする枠組 の2つに大別でき,孤立単語音声認識実験を行って,両者の性能を比較した.そ の結果,LLPを利用する枠組の方が,SLPを利用する枠組よりも高い認識性能を 示し,さらに従来のMFCCを音響特徴とするHMMの誤りを79%削減したこと から,尤度パターンの非対称性を利用する上でLLPを特徴とすることの有効性が 示された.また,単語学習データ量と認識性能の関連を調査したところ,LLPを 利用する手法は学習データを十分用いた場合,従来のHMMによる認識法と同等 の性能しか与えないが,学習データ量が少量の場合においても,高い認識性能を 示した.このように少量の学習データ量においても,高い認識性能を維持してい ることから,学習データ量が不足するような,大語彙を扱うタスクにも適用可能 であると思われる.
第2章 HMMの尤度の非対称性を用いた音声認識 23
MFCCs (Continuous speech)
Generate Segmental unit
PCA
EM training
MFCCs (Isolated word)
Generate Segmental unit
PCA
MFCC-HMM Calculate likelihood
for state (each frame)
26
SU-MFCCs
Calculate likelihood for state (each frame)
PCA SLP
Vector concatenation
EM training
SLP-HMM (phoneme)
PCA SLP
Vector concatenation 78
26
30
SU-MFCCs
Dynamic recognition
Result 26 26
129
5
31
Training Evaluation
78
30
129
5
31
SLP-HMM (word)
lexicon Construct word HMM
from phoneme HMM
MFCCs (Continuous speech)
Generate Segmental unit
PCA
EM training
MFCCs (Isolated word)
Generate Segmental unit
PCA
MFCC-HMM Calculate likelihood
for state (each frame)
26
SU-MFCCs
Calculate likelihood for state (each frame)
PCA SLP
Vector concatenation
EM training
SLP-HMM (phoneme)
PCA SLP
Vector concatenation 78
26
30
SU-MFCCs
Dynamic recognition
Result 26 26
129
5
31
Training Evaluation Training Evaluation
78
30
129
5
31
SLP-HMM (word)
lexicon Construct word HMM
from phoneme HMM
図2.5 SLP-SVMの学習手順および評価手順.
第2章 HMMの尤度の非対称性を用いた音声認識 24
EM
MFCC-HMMs (word) Calculate likelihood
for word (each word utterance)
Static recognition LLP-SVMs
Training Evaluation SVM training
MFCCs (Continuous speech) MFCCs
(Isolated word) (for training)
MFCCs (Isolated word) (for evaluation)
Calculate likelihood for word (each word utterance)
Result (LLP-SVMs) 216
26 26
LLP LLP 216
MFCC-HMMs (phoneme) 26
lexicon Construct word HMM
from phoneme HMM EM
MFCC-HMMs (word) Calculate likelihood
for word (each word utterance)
Static recognition LLP-SVMs
Training Evaluation Training Evaluation SVM training
MFCCs (Continuous speech) MFCCs
(Isolated word) (for training)
MFCCs (Isolated word) (for evaluation)
Calculate likelihood for word (each word utterance)
Result (LLP-SVMs) 216
26 26
LLP LLP 216
MFCC-HMMs (phoneme) 26
lexicon Construct word HMM
from phoneme HMM
図2.6 LLP-SVMの学習手順および評価手順.
第2章 HMMの尤度の非対称性を用いた音声認識 25
!
"
#
図2.7 各比較項目に対する単語誤り率.
第2章 HMMの尤度の非対称性を用いた音声認識 26
!"#$$ %
&'(
)*(('((+
,*
-
.0/21315476985.:. ;2;=<>4769?A@. .B/C1D154CEF85.G.
図2.8 学習データ量を変化させた時のLLPに基づく手法と単語HMMに対する 単語誤り率.
27
第 3 章 尤度特徴量次元数削減による 頑健性向上に関する検討
3.1 はじめに
2.3.3で述べたLLPを特徴量として静的に認識する手法では,SLPを特徴量とし
て動的に認識する手法や、従来の音響特徴であるMFCCから生成されるHMMを 用いた認識法と比べ,大幅に誤りを削減している.しかし,この手法は現状では 小語彙のタスクにおいてのみ有効である.なぜならば,このLLPを用いた認識法 は,語彙中の全ての単語カテゴリの尤度から尤度パターンを生成しており,小語 彙のタスクでは後段で行う識別において用いる尤度特徴ベクトルの次元数は小さ いため,比較的容易に適用できるが,大語彙のタスクに適用する場合は尤度特徴 ベクトルの次元数が膨大になるため,計算量の観点から現実的ではないからであ る.そこで,本章では尤度特徴量の次元削減について検討する.
3.2 次元削減の手法
次元削減の手法としては,識別に寄与する情報を座標変換により積極的に抽出す るLinear discriminant analysis (LDA) [30] [31]や,Heteroscedastic LDA (HLDA) [29]
などが挙げられる.しかし,これらの手法は特徴ベクトルの次元数が大きい場合,
計算時間が非常にかかり,大語彙における尤度特徴ベクトルの次元削減は現実的 に不可能であると思われる.
一方,特徴ベクトルの次元を座標変換により削減するという立場ではなく,識 別に寄与する特徴を選択していくという枠組がある [17].Forward Selectionと呼
第3章 尤度特徴量次元数削減による頑健性向上に関する検討 28 ばれる手法がこれにあたる.Forward Selectionは,まず特徴量を1つずつ選択し ていき,学習と評価を行って最も良い認識性能を与える特徴量を選択し,認識性 能が飽和するまでこれを繰り返す.Forward Selection は全ての特徴量から最も良 い認識性能を示す特徴量を選択していくため,比較的識別に寄与する特徴量を得 ることができる.しかし,本研究で用いているLLPを利用する枠組では,語彙の 数だけ尤度特徴次元数は存在するため,Forward Selectionでは計算量的に現実的 ではない.
3.3 尤度特徴量の次元数削減方式
本研究では,LDAやHLDAのような座標変換による次元削減ではなく,特徴選 択に基づき尤度特徴ベクトルの次元削減を行う.その際,Forward Selectionのよ うな枠組では計算量的に現実的ではないため,それに代わる特徴選択法を提案す る.本研究では,単語ごとに誤り易い単語の集合を予め調査し,その集合に含ま れる単語に対してのみ計算される尤度パターンを特徴量として利用することを試 みる.尤度特徴の次元数削減方法,学習手順,および評価手順については以下の 通りである.
尤度特徴量次元削減手順
1. 単語単位のHMM (MFCC-HMM)を用いて,学習データ(単語音声)の認識を 行う.MFCC-HMMについては,2.3.3と同様の手順で構築する.
2. 単語 wi に誤認識され易い(つまり,wiに対して高い尤度が与えられる) 単 語カテゴリの上位n 個のカテゴリから構成される単語カテゴリの部分集合 G(wi) = (w1i,· · · , win)を考え、それらに対する尤度パターンを,単語wi に 対する尤度特徴量とする.すなわち,単語カテゴリごとに固有のn次元の尤 度から成る部分空間を構築する(図3.1).これを,単語wi に対する尤度部分