学習進化型遺伝的ネットワークプログラミングと その性能評価に関する研究
Study on Genetic Network Programming with Learning and Evolution and Its Performance Evaluation
2006 年 2 月
早稲田大学大学院情報生産システム研究科
情報生産システム工学専攻 進化型計算システム研究
間普 真吾
i
目 次
第1章 序論 1
1.1 研究の背景 . . . . 1
1.2 研究の特色と目的 . . . . 2
1.3 本論文の構成 . . . . 5
第2章 学習型遺伝的ネットワークプログラミング 7 2.1 はじめに . . . . 7
2.2 学習型GNPの構造 . . . . 8
2.2.1 遺伝子構造 . . . . 8
2.3 ノード遷移と学習 . . . . 11
2.4 シミュレーション . . . . 14
2.4.1 囚人のジレンマゲーム . . . . 14
2.4.2 GNPの構成 . . . . 16
2.4.3 シミュレーション結果 . . . . 18
2.5 まとめ . . . . 24
第3章 最適なノード遷移の選択を行う学習進化型GNP 27 3.1 はじめに . . . . 27
3.2 学習進化型GNPの構造 . . . . 28
3.3 ノード遷移のルール . . . . 28
3.4 進化フェーズ . . . . 28
3.4.1 交叉 . . . . 32
ii
3.4.2 突然変異 . . . . 32
3.5 学習フェーズ . . . . 34
3.6 シミュレーション . . . . 35
3.6.1 タイルワールド . . . . 35
3.6.2 ノード内容 . . . . 37
3.6.3 適合度と報酬 . . . . 37
3.6.4 シミュレーション条件 . . . . 37
3.6.5 シミュレーションI . . . . 40
3.6.6 シミュレーションII . . . . 42
3.7 まとめ . . . . 44
第4章 最適なノード内容の選択を行う学習進化型GNP 47 4.1 はじめに . . . . 47
4.2 GNPの遺伝子構造 . . . . 48
4.3 ノード遷移のルール . . . . 48
4.4 進化フェーズ . . . . 50
4.4.1 交叉 . . . . 50
4.4.2 突然変異 . . . . 50
4.5 学習フェーズ . . . . 52
4.6 シミュレーション . . . . 52
4.6.1 シミュレーション条件 . . . . 52
4.6.2 シミュレーションI . . . . 57
4.6.3 シミュレーションII . . . . 62
4.7 まとめ . . . . 66
iii
第5章 Actor-Criticを用いた学習進化型GNP 70
5.1 はじめに . . . . 70
5.2 GNPの基本構造 . . . . 71
5.2.1 ノード遷移のルール . . . . 71
5.2.2 進化フェーズ . . . . 74
5.2.3 学習フェーズ . . . . 76
5.3 シミュレーション . . . . 80
5.3.1 Kheperaロボット . . . . 80
5.3.2 GNP-ACの設定. . . . 80
5.3.3 シミュレーションI . . . . 83
5.3.4 シミュレーションII . . . . 83
5.4 まとめ . . . . 85
第6章 結論 88 謝辞 91 参考文献 92 付 録A 遺伝的ネットワークプログラミング(GNP)の理論 100 A.1 GNPの構成要素 . . . . 100
A.2 遅れ時間 . . . . 100
A.3 GNPの遺伝子構造 . . . . 102
A.4 初期集団の生成 . . . . 102
A.5 ノード遷移のルール . . . . 103
A.6 進化方法 . . . . 103
A.6.1 交叉 . . . . 105
A.6.2 突然変異 . . . . 105
iv
付 録B 強化学習の理論 107
B.1 強化学習の枠組み . . . . 107
B.2 マルコフ決定過程(MDP) . . . . 108
B.3 価値関数 . . . . 110
B.4 TD学習 . . . . 111
B.4.1 Sarsa . . . . 112
B.4.2 Q学習 . . . . 112
B.4.3 Actor-Critic . . . . 113
研究業績一覧 117
1
第 1 章 序論
1.1 研究の背景
あらゆる植物,動物の進化は,その過程である種の最適化問題を解き,環境に適応す るように形を変えてきたことがわかる [1]。生物は個々に高度なメカニズムを内包し,生 物全体で生態系という調和をなしている。この考え方を基に,効率的な計算システムを 自動的に生成しようとする試みが進化論的計算手法であり,代表的な手法に遺伝的アル ゴリズム(GA)[2–8],遺伝的プログラミング(GP)[9–12]がある。進化論的計算手法の 大きな特徴は,解(進化手法では「個体」と呼ぶ)を遺伝子で表現することであり,複数 の個体の中から環境への適合度が高いものを選択し,交叉,突然変異などの遺伝的オペ レータを用いて遺伝子を組みかえることによってよりよい個体を生成していくものであ る。これまで,進化論的計算手法は関数生成 [9],回路合成 [11],プラント制御 [13], 株 価予測問題 [14–16],ロボット制御 [17–20]などに応用されてきた。従来の,設計者が予 め設定したルールに従う手法では,その性能が設計者のスキルに大きく依存するという 問題や,環境変化が起こると,与えられたルールでは対処できない問題が起こりえるこ とから,自立性と創造性に富んだプログラムの生成は魅力的であり,進化論的計算手法 はそれを実現できる手法の一つとして注目を集めている。
一方,強化学習[21, 22]と呼ばれる学習アルゴリズムに関する研究も活発に行われてい る。強化学習は,最適制御と動的計画法 [23, 24]の研究を基礎にして,1980年代後半に1 つの分野を作り上げたが,近年の研究において実際に生物の脳内で行われていることが 示唆されている [25]。我々は日常生活において,環境に対して直接的に働きかけてその
第1章 序論 2 応答を得るという,環境との相互作用を通じて様々なことを学んでいる。例えば,車の運 転を習っているとき,自分の行動に対する環境の応答をはっきりと知ることができ,そ の行動によって生じることに影響を与えようとする。相互作用から学習することは,ほ とんどの学習理論の基本的な考え方となっている。強化学習を適用する際には,取った 行動の良し悪しを数値化された報酬信号で評価する。ただし,学習者がどの行動を取る べきかは教えられず,報酬信号からどの行動を取ればよりいっそうの報酬に結びつくか を見つけ出す必要がある(教師なし学習)。また,ある状態での行動は直接的な報酬のみ ならず,次状態に影響を与え,それを通じて全ての後続報酬に影響する。したがって,学 習は現在から未来にわたって与えられる報酬を最大化するよう行われなければならない。
これらの試行錯誤的な探索と遅延報酬は強化学習の重要な特徴である。これまで強化学 習は,エレベータ配車問題[26]やバックギャモン [27–29]等に応用され,その有効性が示 されている。
本研究は以上のような背景のもとで,新しい進化論的計算手法として提案されている 遺伝的ネットワークプログラミング(Genetic Network Programming, GNP)[30–36]に 強化学習のメカニズムを導入した新しい学習進化手法「学習進化型遺伝的ネットワーク プログラミング」の研究を行い,その性能を検証したものである。
1.2 研究の特色と目的
GAは解を主に文字列で表現し,最適化問題への応用が数多くなされてきた。GPは解 を木構造で表現することによって,より多くの問題へ適用が可能となったため進化論的 計算手法の進展に大きく寄与している。また,解の表現方法の違いにより,問題に適し た特長を備えることができると考えられる。本研究では,有向グラフ構造で解を表現す る進化手法であるGNPの優れた解の表現能力を十分に利用しながら,学習と進化の組み 合わせによる新しい学習進化型計算システムの開発を目的としている。はじめに,GNP の特徴を従来手法との比較を行いながら説明する。また,GNPの基本構造と進化の方法 については付録Aに記載している。
以下に,GNPの特徴を挙げる。
第1章 序論 3
• 判定ノードおよび処理ノードを用いた有向グラフ構造
• ノードの再利用
• 暗黙的メモリ機能
まず第一に,GNPはエージェント注1が行うことのできる判定と処理の基本単位をそれ ぞれ判定ノードと処理ノードと呼ばれるノードとして用意し注2,複数のノードをグラフ 構造状に接続することによって複雑な判定・処理のルールを生成することができる。GNP は,ノード間の接続関係を進化によって適切に設定することにより,効率的なプログラ ムを作っていく。
第二に,有向グラフ構造を持つことで特定の処理を反復して行うことが可能となり,こ れがGPの分野における自動定義関数(Automatic Defined Function, ADF)[10],つま りサブルーチン的な働きを可能にする。これにより,少ないノード数で効率的なプログ ラムを生成することが可能となるため,構造が非常にコンパクトになる。したがって,メ モリの使用量と計算時間を節約することができる。また,GNPのグラフ構造はノード数 を固定して進化させることができるため,GPでしばしば問題となるブロート注3を起こ す恐れがない。
最後に,GNPのノード遷移は開始ノードから始まるが終端ノードは存在せず,ノード 間の接続関係にしたがって,判定と処理が順次実行されていく。したがって,ノード遷移 自体を過去の判定と処理の履歴と見なすことができ,これが暗黙的なメモリ機能として 働く。この機能は,特に部分観測マルコフ決定過程[37, 38]を扱う際に役立つ。実際の問 題では,センサの能力が不完全であったり,ノイズ等の影響があったりすることで,不 完全性や不確実性が存在することが多いが,過去の履歴を用いれば現在の状態を推定し やすくなる。例えば,ロボットの前後左右4方向の状況を判別できるセンサがあったと き,履歴を用いない手法の場合,現在のみの情報に基づくため,センサの情報が同じであ
注1自律的な判断で環境との相互作用を行う行動主体
注2例えば,判定ノードは「前に何があるか」などを調べて分岐を行うノード,処理ノードは「前進する」
などを決定するノード。その他に,ノード遷移開始直後に実行する処理ノードまたは判定ノードを決定す る開始ノードも1つ存在する。
注3進化を繰り返すことによって木構造の深さが極端に深くなってしまう現象
第1章 序論 4 れば異なった状態でも同じ状態と判定してしまう。GPのプログラムを例に考えてみる。
GPは木構造の非終端ノードをif −then型の機能を持つノードとし,終端ノードに具体 的な行動を指示する機能を持たせれば決定木として利用できる。このとき,行動の決定 はルートノードからif−thenの条件分岐を繰り返し,たどり着いた終端ノードの行動内 容が実行されるが,次回の行動は再びルートノードからの条件分岐を行って決定される ため,現在のみの情報を用いた行動決定がされていると言える。履歴を用いる手法では,
センサの情報が同じであっても過去に“左折した”などの記憶を用いて状態を区別するこ とができ,GNPはその機能を本来的に持っている。
これまで,グラフ構造を進化させるシステムとしては,進化論的プログラミング(Evo- lutionary Programming, EP)を用いて有限オートマトンの自動生成を行う手法が提案さ
れている [39–42]。GNPも有限オートマトンのように見えるが厳密には異なる。EPでは,
全ての状態において,全ての入力の組み合わせに対する出力と状態遷移ルールを定義す る必要があるため,状態数と入力の数が多くなると構造が極端に大きくなってしまう。一 方,GNPの判定ノードと処理ノードは,基本的に,それぞれ1種類の入力または行動を 扱い,それらのノードを必要に応じて使うようにノード間の接続を進化させていく。した がって,全ての入力に対するノード遷移を定義する必要がなく構造がコンパクトになる。
Parallel Algorithm Discovery and Orchestration (PADO) [43–45] もグラフ構造を持つ 進化手法である。GNPとの違いは各ノード内に行動部と分岐判定部があること,開始ノー ドと終端ノードがあること,外部メモリによってノード遷移が決定されること,である。
PADOは画像認識や音声認識で優れた性能を示しているため,静的な問題に優れた手法 であるといえる。GNPは暗黙的なメモリ機能を用いて,主に動的な問題を効率良く扱う ことを目的としているため,stackメモリやindexメモリを用いることを前提としていな い。また,前述のように,GNPのノードは判定と処理を分けて用意することで,より細 かく複雑なプログラムが生成できる。
次に,本研究の主題である学習進化型GNPについて述べる。一般に,進化手法はプロ グラムの実行後にどれだけの仕事を達成したかという結果のみを考慮するのに対し,強 化学習はプログラム実行中の各状態において,どの行動を選択したかという過程を考慮
第1章 序論 5 する。文献 [21]によれば,このような性質の違いにより工学的には両者を分離して考え る,とある。しかし,自然界において生物は,長い世代を通じて行われる進化と各生物 が一生の間に行う学習が,相互に影響しながらその発達を促進してきているため,両者 を分離して考える必要はなく,システムの性能向上および生物の学習と進化のメカニズ ムのモデル化という点で,学習と進化の組み合わせは有効であると考える。
本研究の目的は,学習と進化を組み合わせることによってそれらの相乗効果を生み出 し,解の探索精度および探索速度を向上させることである。具体的に,進化と学習を組 み合わせる目的について述べる。進化は,多数の個体がタスクを実行し,終了後に計算 される適合度に基づいて良い個体が選択される。このように,進化は多点探索であるた め広域探索に優れているといえる。一方,強化学習は,1個体がタスク中の判定・処理ご とに与えられる報酬に基づいてオンラインで学習が行えるため,タスク実行中に様々な 情報(センサ入力や報酬など)が得られる環境ではプログラム生成が効率良く行われる。
このように,強化学習は即時報酬を基にした漸進的な学習を行えるため,局所探索に優 れているといえる。また,本研究では,各判定または処理ノードに,強化学習における
「状態」を定義するため,ノード数が直接状態数に関係する。しかし,前述のようにGNP は非常にコンパクトな構造を実現できるため,強化学習の分野でしばしば問題となる莫 大な状態数を減らすことが可能である。したがって,強化学習を効率良く行うことが可 能となり,このことも進化と学習を組み合わせる利点の1つとなっている。
1.3 本論文の構成
本論文の構成は以下の通りである。
第2章では学習型GNPについて述べる。GNPは一般的な進化論的計算の枠組みとし て提案されたものであるが,GNPのグラフ構造上で強化学習が有効に機能するかを検証 するために,一度進化手法の枠組みから外し,強化学習のみでグラフ構造のノード遷移 ルールの生成を試みる。さらに提案手法を囚人のジレンマゲームの戦略構築に応用し,そ の性能を検証する。
第1章 序論 6 第3章では,第2章で提案した学習型GNPを進化型GNPと組み合わせることで,よ り効率の良いプログラムが生成できる手法を提案する。具体的には,第2章の手法では 各ノードから他の全てのノードへの遷移を考えて学習を行う必要があるが,本手法では 進化によっていくつかの遷移に絞り込むことにより,学習の高速化を期待する。性能の 検証にはタイルワールド[46]と呼ばれるベンチマーク問題を用い,進化型GNP,GPと の比較を行う。
第3章までは,強化学習の「行動」をノード遷移と定義してノード遷移の最適化を目 的とした強化学習を行っているが,第4章ではノード内に複数存在する判定または処理 の内容の中から1個を選択することを「行動」と定義する。すなわち,最適なノード内 容の選択を目的とした方式を提案する。性能の検証にはタイルワールドを用い,進化型
GNP,GP,ADF付きGP,EPとの比較を行う。
第5章では,これまで離散的な値の入力や出力(例えば,障害物が「右」にあるかどう か,「左」に曲がる,など)を扱ってきたが,GNPを実世界の問題へ応用するために,ア ルゴリズムの拡張を行う。具体的には,アクタークリティック(Actor-Critic)[21, 47, 48]
と呼ばれる強化学習のアルゴリズムをGNPの学習に応用することで連続値の取り扱い を可能にする。さらに提案手法をKheperaシミュレータ [49]のコントローラとして用い,
その性能を検証する。
第6章では,本研究の成果をまとめ,結論を述べる。
7
第 2 章
学習型遺伝的ネットワークプログラミング
2.1 はじめに
これまで提案されてきた遺伝的ネットワークプログラミング(GNP)(付録A)は進化 に基づいてプログラムの生成を行うものであった。すなわち,複数の個体がタスクを実 行した後,適合度にしたがって良い個体を選択していくものである。これはオフライン 学習と言え,タスク中にプログラムの変更はできない問題点がある。そこで,本章では 強化学習を用いてGNPのノード遷移規則をオンラインで学習する方式を提案する(学習
型GNP)[50–52]。ただし,本章では強化学習が有効に機能するかを検証することが目的
であるため,進化(選択,遺伝的操作)は行わず,1個体での学習を行う。
強化学習にはQ学習 [21, 53–56]と呼ばれる手法を用いた。学習型GNPはタスク実行 中に次々と与えられる報酬に基づいて学習するため,もし悪い報酬が得られたときは即 座に行動ルールを変更することができる。強化学習の基礎理論については付録Bに記載 している。
性能評価には囚人のジレンマゲーム[1, 57]を用い,オンライン学習の性能を検証した。
囚人のジレンマゲームは2人のプレーヤ間で行われるが,まず,GNPで生成された戦略と,
囚人のジレンマゲームにおける代表的な二つの戦略をそれぞれ対戦させた。また,GNP 同士の対戦も行い,相手の戦略を考えた戦略を構築しているかを確かめた。
第2章 学習型遺伝的ネットワークプログラミング 8
2.2 学習型 GNP の構造
まず,従来の進化型GNPと学習型GNPの構造の違いについて述べる。進化型GNP では,各ノードから判定結果の数(処理ノードは1本)だけ接続ブランチが延びている が,学習型GNPでは,各ノードが,判定結果の数×(ノード数−2)注1本のブランチを持
つ[Fig. 2.1]。さらに,学習型GNPのノード遷移はQ値(あるノード遷移を選択したと
きに将来得られる報酬の和の期待値。2.2.1節参照)にしたがって行われるため,全ての 接続ブランチにQ値が設定されている。
2.2.1 遺伝子構造
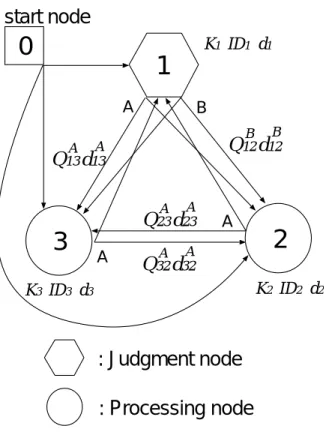
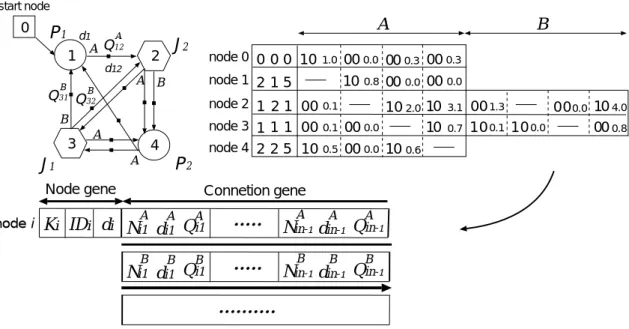
学習型GNPにおけるノードiの遺伝子はFig. 2.2のように表され,4つのノードから 構成されるグラフ構造の例をFig. 2.3に表した(ただし,図を見やすくするため全ての遺 伝子は記載していない)。まず,Fig. 2.2中のノード遺伝子(Node gene)は進化型GNP と同じであり,付録AのA.3節で説明している。しかし,接続遺伝子(Connection gene)
は進化型GNPと異なる。学習型GNPは,各ノードから他の全てのノード(開始ノード 除く)へ接続ブランチが存在するので,進化型GNPにおける接続先を表す遺伝子Ciが 存在しない。また,全てのブランチがQ値を持っており,その値が遺伝子に書き込まれて いる。例えばQA12は,ノード1の判定結果が“A”であったとき,ノード1からノード2へ 遷移する価値を表している。このような遷移が時刻tで行われたとすると,QA12は(2.1)
式で表される値となる。
QA12 = Eπ
rt+γrt+1+γ2rt+2+γ3rt+3+· · ·
= Eπ
∞
k=0
γkrt+k
(2.1) ただし,Eπはある行動方策π注2にしたがったときの期待値,rtは時刻tで与えられる 報酬,γは割引率注3を表す。d12A は判定結果が“A”で,かつノード1からノード2へ遷移 するときにかかる時間である。
注1自己ループはせず,開始ノードへの接続もしないので,全ノード数から2を引いている。
注2例:ε−greedy方策(次節参照)
注3未来の報酬をどれだけ考慮して学習を行うかを決める値
第2章 学習型遺伝的ネットワークプログラミング 9
A B
C
When the judgment results A, B and C exist,...
three branches
GNP (GNP with evolution)
GNP with Learning
Judgment node Processing node
A
one branch
node i node i
A
B C
n-2 branches
n-2 branches
n-2 branches QAi1
QAin-1 QBi1
QCi1 QBin-1
QCin-1 QAij
......
...
...
QBij
...
... QCij
Judgment node
A
n-2 branches QAi1
QAin-1
(n: the number of nodes) QAij
......
Processing node
node i node i
(no branch to a start node and itself (jҁK ) )
Fig. 2.1 Difference of nodes between GNP and GNP with Learning
第2章 学習型遺伝的ネットワークプログラミング 10
node i
K
iID
id
id
i1LIBRARY
J
1:J
2:J
k:...
P
1:P
2:P
l:...
Node gene Connetion gene
d
i1...
Q
i1BA B
Q
i1Ad
in-1AQ
in-1Bd
in-1B...
Q
in-1A...
...
Fig. 2.2 Genotype expression of node i
1
3
A B
A
2
A
K3 ID3 d3 K2 ID2 d2
K1 ID1 d1
d13A Q13A
0
d12
Q12 B B
d32
Q32 A A
d23
Q23 A A
: Judgment node : Processing node start node
Fig. 2.3 An example of a directed graph expression with four nodes
第2章 学習型遺伝的ネットワークプログラミング 11
2.3 ノード遷移と学習
本節では,Fig. 2.4を例に,ノード遷移とQ値の更新方法を説明する。Fig. 2.4では,
時刻tで実行中のノードが判定ノードであり,その判定内容IDiを実行した後,状態が 決定される。学習型GNPでは,ノードの分岐点を「状態」と定義しており,判定結果が Bであったと仮定すると状態はSiBとなる。その後,QBi1, . . . , QBin−1の中からε−greedy方 策注4にしたがって一つのQ値を選択し,対応するブランチの接続にしたがって次ノード へ遷移する。また,このようなブランチの選択と次ノードへの遷移を強化学習の「行動」
と定義する。
• case 1 : 次ノードが処理ノードの場合
時刻tでQBij1が選択されたとすると,次ノードは処理ノードj1となる。したがって,学 習型GNPはノードの処理内容IDj1 を実行し,報酬rtを得る。その後,時刻t+ 1に移 行し,状態st+1は,判定ノードと異なり条件分岐がないので決定的にsAj1となる。このと き,もしQAj1k1 がQAj11, . . . , QAj1n−1のうち最大であったとすると,この値を用いて,以下 のようにQBij1 の更新を行う。
QBij1 ←QBij1 +α
rt+γQAj1k1 −QBij1
(2.2) その後,ε−greedy方策にしたがって,再びQAj11, . . . , QAj1n−1の中から一つのQ値を選 び直す。つまり,QAj1k1 を持つブランチが1−εの確率で選択され,εの確率でランダムに 選択される。
• case 2 : 次ノードが判定ノードの場合
時刻tでQBij2が選択されたとすると,次ノードは判定ノードj2となる。したがって,判 定ノードj2の内容IDj2 を実行した後,報酬rtを得る。その後,時刻t+ 1に移行し,状 態st+1は判定結果にしたがってSjA2,SjB2,SjC2(判定結果はA,B,Cのいずれかをとる
注41−εの確率で最大のQ値を選択し,εの確率でランダムに選択する方法。
第2章 学習型遺伝的ネットワークプログラミング 12
i
n-1
...
j2
... ...
...
...
Q
i11
j1
1
Q
in-1Q
i1k1
k2
1
time t t+1
i, j1, j2, k1, k2 : node number (1≤ i, j1, j2, k1, k2 ≤ n-1
)
s
j2: action at : state st
case1
case 2
s
i1
... ...
Q
ij1s
j11
Q
j11Q
j1k1...
s
j2s
j2s
is
iQ
i1Q
in -1Q
j2k2Q
j21Q
j211
Q
ij2Q
in-1... ...
...
: Processing node : Judgement node
A B
C
A
A
B B B B
C
C
A
A
A B
C
A
A B C
n-1
n-1
j1, j2ҁKM1ҁL1, M2ҁL2
Fig. 2.4 An example of node transition
第2章 学習型遺伝的ネットワークプログラミング 13
reward r equally distributed
one iteration γ
discounted reward
current processing previous processing
r r r r
r
Fig. 2.5 An example of one iteration
と仮定する)のいずれかに移行する。判定結果がAであったとすると,状態st+1はsAj2と なる。さらに,QAj2k2が QAj21, . . . , QAj2n−1の中で最大であったとすると,この値を用いて,
以下のようにQBij2の更新を行う。
QBij2 ←QBij2 +α
QAj2k2−QBij2
(2.3) その後,ε−greedy方策にしたがってQAj21, . . . , QAj2n−1の中から一つのQ値および対応 する接続ブランチを選択する。
一般に,強化学習では全ての状態と行動の組にQ値を割り当て,ある状態でQ値にし たがってある行動を取ったとき,得られた報酬を基にしてQ値の更新を行う。したがっ て通常の強化学習では,実際に行動(前進する,など)を取ったときにQ値の更新を行 うことが一般的である。一方,学習型GNPではノードの分岐点を状態,分岐点からどの ブランチを選択するかを行動,と定義している。したがって,選択されたブランチの接 続先が処理ノードであれば,実際の処理(前進する,など)が実行されるため,それに 対する報酬を用いて,選択されたブランチのQ値を更新することができる。しかし,判 定ノードは条件分岐を行う機能しかなく,報酬は得られない(常に0)。したがって判定 ノードへ接続するブランチのQ値は常に報酬0で評価されることになる。これでは,判 定ノードを使わないほうが良いという学習が行われるため,以下のような設定をする。
第2章 学習型遺伝的ネットワークプログラミング 14 まず,Fig. 2.5のようにone iterationを定義する。つまり,ある処理ノードを実行し た後から次回の処理ノードが実行されるまでをone iterationとする。前回の処理が終了 した後,次回の処理内容は一連の判定ノードとそれに続く処理ノードで決定されるため,
one iteration中の行動(ブランチの選択)は同等に評価されるべきだと考えられる。した
がって,処理ノードを実行した結果得られる報酬は,one iteration中の全ての行動に割り 引かず与えるものとする。この考え方は,(2.3)式の割引率γを1に設定注5し,割引を行 わないようにすることで実現できる。
2.4 シミュレーション
2.4.1 囚人のジレンマゲーム
囚人のジレンマゲーム[1, 57]のモデルは,1950年ごろ,心理学研究のひとつの状況と してM. FloodとM. Dresherが考案したが,A. W. Tuckerがストーリーをつけて広めた ため,社会的モデルとして研究者の間に広まるようになった。
本節では,学習型GNPを囚人のジレンマゲームのプレーヤとして用い,ゲームを繰り 返すことによって,対戦相手の性格を考慮したプログラムを生成できるか検証する。
• ストーリー:重大な犯罪を共犯で行ったという容疑で,2人の容疑者に対する取調 べが別々の部屋で行われている。警察側は起訴するに十分な証拠は持っていない。
そこで,2人にそれぞれ次のように話をもちかける。「もし2人とも黙秘した場合に は,銃の不法所持などの余罪で2年の懲役にすることができる。もしお前が本当の ことを話して,相棒が黙っているなら,お前を釈放してやろう。その場合,相棒は 5年の刑になる。ただ,2人とも話してしまったら,2人とも4年の刑になるぞ。ど うする?」
以上の状況をまとめるとTable 2.1のようになり,それぞれ報酬0,-2,-4,-5と対応さ せることができる。また,それらにそれぞれ5を加えることでFig. 2.6のような利得行列
注5γ= 1のため(2.3)式中のγは省略した。また,判定ノードでの報酬rtは0であるため,これも省略 した。
第2章 学習型遺伝的ネットワークプログラミング 15
Table 2.1 Relation between Sentence and Confession/Silence Suspect1 Suspect2 Sentence to suspect1
Confession Silence released Silence Silence 2-year prison Confession Confession 4-year prison Silence Confession 5-year prison
suspect2
suspect1
cooperate(C) defect(D) cooperate(C)
defect(D)
3 0
5 1
R S
T P
Fig. 2.6 Profit matrix (profit for suspect1)
第2章 学習型遺伝的ネットワークプログラミング 16 を作ることができる。自分と相手が共に黙秘をすれば両者の懲役期間を短縮できるので 協調(cooperate,C)と考え,自白をすれば自分は釈放され,相手の懲役期間が長くな る可能性があるので裏切り(defect,D)と考えることができる。Fig. 2.6中のR,S,T, P が記載されている枠内の数値が以下の式を満たせばジレンマが発生する問題となる。
T > R > P > S 2R > S+T
(2.4)
本節で設定した値は,囚人のジレンマゲームの研究で一般的なものである。シミュレー ションでは,協調か裏切りかの選択を繰り返し行い,その得点を評価する。
もし,プレーヤが相手の情報を全く知らず,一回しか行動を取れない場合は,裏切り を取るべきである。なぜなら相手が協調を取っても裏切りを取っても,自分は裏切りを 取ったほうが得点が高いからである。しかし,対戦が繰り返し行われる場合,両者が裏 切りを続けるよりも協調を取り合ったほうが高い得点が得られることがわかる。したがっ て,対戦を繰り返すことによって相手の性格を把握し,過去の対戦履歴から自分の戦略 を構築することがGNPの目的となる。
2.4.2 GNP の構成
囚人のジレンマゲームのプレーヤは学習型GNPで構成されたエージェントとする。使 用する判定ノードと処理ノードは以下の通りである。
• 過去の自分の行動を判定するノード
• 過去の相手の行動を判定するノード
• 協調行動(C)を決定する処理ノード
• 裏切り行動(D)を決定する処理ノード
第2章 学習型遺伝的ネットワークプログラミング 17
S
D C O
sC sD
sD sC
Self-judgement node in the case of C
in the case of C
in the case of D in the case of D Opponent-judgement node
Cooperation Processing node
Defect Processing node
S
S S
S
S
O O
O O
O O
O
C
C
C
C C
D
C C
D
D D
D
D D C
opponent -judgement of last action
cooperation
self-judgement of last action
self-judgement of 2 actions before
defect
sC sC
sC sC
sC
sC
sC
sC
sC sC sC
sD
sD
sD sD
sD
sD
sD
sD sD
sD sD
sD sC
S D
sC sD
S O sC
sD sC
sD start
Fig. 2.7 An example of GNP structure
第2章 学習型遺伝的ネットワークプログラミング 18
Fig. 2.7は囚人のジレンマゲームにおけるGNPの構造の例を表しており,太い矢印は
ノード遷移の例を表している。ノード間のブランチは各ノードから他の全てのノードへ 実際は接続されているが,図を見やすくするために大部分を省略している。本図では,各 判定ノードの判定結果が協調であればsC,裏切りであればsDの状態へ移行するとし注6, ノード番号を表す下側の添え字と処理ノードにおける状態(各ノード1個のみ)も簡単 のために省略している。
図の例では,開始ノードに続くノードが,協調を表す処理ノードであるため,協調行 動を取る。その後,ε−greedy方策にしたがって1本のブランチを選択する。選択したブ ランチの接続先が,相手の行動を判定するノードであったとすると,1回前の相手の行 動を判定する。この例では裏切り(D)と判定されているため,状態はsDとなり,再度
ε−greedy方策にしたがって1本のブランチを選択する。次のノードは過去の自分の行動
を判定するノードであるため,1回前の自分の行動を判定し(判定結果:D),前ノード と同様の手順で次のノードへ遷移する。すると,自分の行動を判定するノードに再び遷 移するので,2回前の自分の行動を判定する(判定結果:C)。そしてたどり着いた処理 ノードの内容(D)を次回の行動として決定する。
囚人のジレンマゲームにGNPを応用する利点は,どれだけ過去の自分の行動と相手の 行動を判定すべきかを自動的に学習することができる点である。言い換えると,どの判 定ノードを何回用いれば良いかを学習できるということである。
2.4.3 シミュレーション結果
はじめに,囚人のジレンマゲームにおいて代表的な戦略である,しっぺ返し戦略,パ ブロフ戦略と対戦を行って学習型GNPの性能を評価する。本シミュレーションの目的は 対戦する相手の性格を学んで自分の戦略を構築できるかを明らかにすることである。次 にGNP同士の対戦を行う。GNPはそれぞれの戦略を対戦中に次々と変えていくと考え られ,相手の戦略変更に適応できるかを検証する。また,GNPはTable 2.2の条件下で 行った。
注6前節までは判定結果をA, B, . . . と表記してきたが,わかりやすさを考慮して,本節では協調C,裏切 りDに対応させて表記した。
第2章 学習型遺伝的ネットワークプログラミング 19 シミュレーションI(しっぺ返し戦略との対戦)
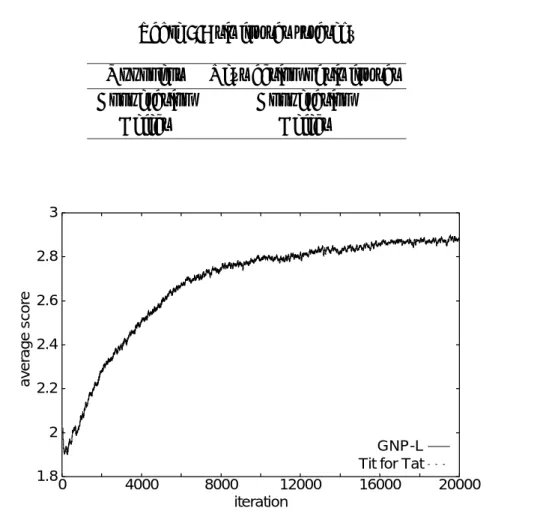
Table 2.3に示すとおり,しっぺ返し戦略(Tit for Tat strategy)は前回の相手の行動 を真似するものである。しっぺ返し戦略は相手に対して大きく負けることはなく,平均 的にほぼ同じ得点を得ることができる。したがって,この戦略は強い戦略として一般的 に認められている。例えば,多数の戦略が互いに対戦をするとき,他の戦略は互いに得 点を減らしあう可能性があるが,しっぺ返し戦略は対戦相手とほぼ同得点を得続けるこ とによって全体として強い戦略となる。
Fig. 2.8は,50回の対戦ごとの平均得点を,独立した100回の試行で平均化したもので
ある。Fig. 2.9はGNPが使ったノードの比率を一定の期間ごとに表したものであり,本 図も100回の独立した試行で平均化している。しっぺ返し戦略は対戦相手とほぼ同得点 を得るため,Fig. 2.8の曲線は重なっているが,両戦略ともゲームを繰り返すにつれて高 い得点を獲得していることがわかる。これは,GNPが次第に協調行動を多く取るように なった結果であり,Fig. 2.9からもわかる。もしGNPが裏切りを取れば,次回しっぺ返 し戦略は裏切り行動を取ってくるため,結果的に得点が下がってしまう。もしGNPが協 調を取り続ければ,しっぺ返し戦略も協調を取りつづけ,平均的に3点を獲得できる。し たがって,GNPは協調戦略を構築しており,また判定ノードの使用回数が次第に少なく なっているのは,しっぺ返し戦略の特徴を理解したため,多くの判定が必要なくなった 結果である。
シミュレーションII(パブロフ戦略との対戦)
Table 2.4は,パブロフ戦略(Pavlov strategy)を表している。この戦略は,次回の行 動を,前回の自分と相手の行動の組み合わせによって決定するものである。
Fig. 2.10とFig. 2.11はシミュレーションIと同様に,50回の対戦ごとの平均得点と,
ノードの使用比率を表している。Fig. 2.10から,GNPはパブロフ戦略に対して大差で 勝っていることがわかる。これは,Fig. 2.11からもわかるように裏切り行動を多く取る ようになったためである。GNPとパブロフ戦略が共に裏切りをとった場合,次回のパブ ロフ戦略の行動は協調となり,ここでGNPがもう一度裏切りを取ることによって5点を 獲得している。
第2章 学習型遺伝的ネットワークプログラミング 20
Table 2.2 Simulation condition the number of nodes 41
node number 0: Start node
1–10: Processing node
(1–5: cooperation, 6–10: defect) 11–40: Judgment node
(11–25: self-judgment, 26–40: Opponent-judgment)
learning parameters learning rateα: 0.8(Simulation I and III), 0.6 (simulation II) γ: 0.99, ε: 0.05
reward rt follow Fig. 2.6
Q values initial values are zero
Table 2.3 tit for tat strategy Opponent Next action of tit for tat Cooperation Cooperation
Defect Defect
1.8 2 2.2 2.4 2.6 2.8 3
0 4000 8000 12000 16000 20000
average score
iteration
GNP-L Tit for Tat
Fig. 2.8 Average score of competition between GNP and Tit for Tat
第2章 学習型遺伝的ネットワークプログラミング 21
0 0.02 0.04 0.06 0.08 0.1 0.12
0 5 10 15 20 25 30 35 40
ratio of used nodes
node number
(a) from 1 to 500 iterations
0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 0.16
0 5 10 15 20 25 30 35 40
ratio of used nodes
node number
(b) from 501 to 10000 iterations
0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 0.16 0.18 0.2
0 5 10 15 20 25 30 35 40
ratio of used nodes
node number
(c) from 10001 to 20000 iterations
Fig. 2.9 Ratio of used nodes for specific intervals in competition between GNP and Tit for Tat
第2章 学習型遺伝的ネットワークプログラミング 22
Table 2.4 Pavlov strategy
Pavlov Opponent Next action of Pavlov Cooperation Cooperation Cooperation
Cooperation Defect Defect
Defect Cooperation Defect
Defect Defect Cooperation
0.5 1 1.5 2 2.5 3
0 4000 8000 12000 16000 20000
average score
iteration
GNP-L Pavlov
Fig. 2.10 Average score of competition between GNP and Pavlov strategy
第2章 学習型遺伝的ネットワークプログラミング 23
0 0.02 0.04 0.06 0.08 0.1
0 5 10 15 20 25 30 35 40
ratio of used nodes
node number
(a) from 1 to 500 iterations
0 0.02 0.04 0.06 0.08 0.1 0.12 0.14
0 5 10 15 20 25 30 35 40
ratio of used nodes
node number
(b) from 501 to 3000 iterations
0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 0.16 0.18
0 5 10 15 20 25 30 35 40
ratio of used nodes
node number
(c) from 3001 to 10000 iterations
Fig. 2.11 Ratio of used nodes for specific intervals in competition between GNP and Pavlov strategy
第2章 学習型遺伝的ネットワークプログラミング 24 シミュレーションIII(GNP同士の対戦)
最後に,同じ構造と学習に関するパラメータ[Table 2.2]を持つGNP同士による対戦を 行った。Fig. 2.12 (a)は50回ごとの対戦の平均得点を表しているが,独立した試行で平 均化せず,典型的な一回の試行の結果を示したものである。これは,対戦中の戦略の変 更を具体的に考察するためである。Fig. 2.12 (a)の特徴は,GNP1が得点を増やしている ときに,GNP2は得点を減らし,GNP2が増やしているときにはGNP1が減るというこ とである。Fig. 2.12 (b)は4000回目の対戦から5500回目の対戦までをFig. 2.12 (a)か ら抽出したものであり,Fig. 2.13はノードの使用比率を4201回目の対戦から4900回目 まで,および4901回目から5500回目までそれぞれ表したものである。まず,4201回目 からの対戦では,GNP1が裏切り行動をより多く取っているが[Fig.2.13 (a)],GNP2は GNP1より協調行動を多く取っている[Fig.2.13 (b)]。その後,GNP2はGNP1に対抗す るために裏切り行動をより多く取るようになり[Fig.2.13(d)],4900回目付近でGNP1の 得点が下がっている。そこで,GNP1は裏切り合いを避けるために,協調行動をより多 く取るようになる[Fig.2.13 (c)]。しかし,GNP2はGNP1の戦略変更のおかげで高得点 を得られるようになってしまう。GNP1は再び裏切り行動を取るようになるが,GNP2は 裏切り合いを避けるために協調戦略に変更する。以上のような対戦が繰り返されている が,両GNPがより多くの得点を得ようと逐次戦略変更を行い,それが相互に影響しあう ことで,このような挙動が得られたと言える。
2.5 まとめ
本章では,タスク実行中にオンライン学習を行い,環境の変化に迅速に対応させるた め,Q学習を用いてGNPのノード遷移を学習させる手法,学習型GNPの提案を行った。
また,性能の評価には囚人のジレンマゲームを用い,しっぺ返し戦略およびパブロフ戦 略との対戦,GNP同士の対戦を行うことでその特徴を明らかにした。固定戦略(しっぺ 返し,パブロフ)に対して,GNPは対戦が進むにつれて相手の特徴を学習し,より高い 得点が得られる戦略を構築し,GNP同士の対戦では,相手の戦略変更に対応し,より高 い報酬を得るために自分の戦略を変更していることがわかった。また,状況に応じて必 要な判定ノードと処理ノードを使い分けていることが明らかになった。
第2章 学習型遺伝的ネットワークプログラミング 25
0 0.5 1 1.5 2 2.5 3 3.5 4
0 2000 4000 6000 8000 10000
average score
iteration
GNP1 GNP2
(a) from 1 to 10000 iterations
0 0.5 1 1.5 2 2.5 3 3.5 4
4000 4200 4400 4600 4800 5000 5200 5400
average score
iteration
GNP1 GNP2
(b) from 4000 to 5500 iterations
Fig. 2.12 Average score of competition between GNPs
第2章 学習型遺伝的ネットワークプログラミング 26
0 0.05 0.1 0.15 0.2 0.25 0.3
0 5 10 15 20 25 30 35 40
ratio of used nodes
node number
(a) from 4201 to 4900 iterations of GNP1
0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09
0 5 10 15 20 25 30 35 40
ratio of used nodes
node number
(b) from 4201 to 4900 iterations of GNP2
0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 0.16
0 5 10 15 20 25 30 35 40
ratio of used nodes
node number
(c) from 4901 to 5500 iterations of GNP1
0 0.05 0.1 0.15 0.2
0 5 10 15 20 25 30 35 40
ratio of used nodes
node number
(d) from 4901 to 5500 iterations of GNP2 Fig. 2.13 Ratio of used nodes for specific intervals in competition between GNPs
27
第 3 章
最適なノード遷移の選択を行う学習進化型 GNP
3.1 はじめに
前章では,Q学習を用いたGNPのアルゴリズム,学習型GNPを提案した。しかし,
学習型GNPは,各状態から他の全てのノードへの遷移を考え,強化学習によって最適な 遷移を決定しなければならないので,ノード数と判定ノードの分岐の数が多くなるにつ れて,Q-tableの規模(Q値の数)が大きくなり,探索が遅くなる欠点がある。そこで,
本章では学習と進化を組み合わせた新しい方式“学習進化型GNP” [58]を提案する。本 手法は,タスク終了後に計算される適合度にしたがってGNPのグラフ構造を進化させ,
有向グラフの規模(Q-table)をコンパクトにする(広域探索)。次に,グラフ構造中の ノード遷移をタスク実行中に強化学習で最適化する(局所探索)。これにより,解の探索 精度と探索速度の面で優れたシステムを構築することができる。
進化と強化学習を組み合わせた手法について文献 [59]では,GPの木構造の終端ノー ドに学習用のノードを用意し,そのノードの内容,すなわちエージェントの行動内容を Q学習によって決定している。また文献[60]では,GPの進化によってQ-tableを生成し ている。たとえば,状態変数としてx, y, zが存在した時,得られたGPのプログラムが (TAB(*xy)(+z5))であればx∗yとz+5を軸とする2次元のQ-tableを表す。
一方,GNPの学習進化は,ノード遷移の最適経路を決定するものである。具体的には,
進化によってグラフ構造の大枠,すなわち複数のノード遷移経路,を設定し,強化学習 によって1本の最適な経路を決定するものである。したがって,進化と学習の適用に関し ては各種の検討がなされているが,本章では,GNPの枠組みの中で,その最適化のため の進化と学習の統合について述べている。
第3章 最適なノード遷移の選択を行う学習進化型GNP 28
3.2 学習進化型 GNP の構造
学習進化型GNPは,Fig. 3.1のような構造をしている。学習進化型GNPは学習型GNP の構造を基にしており,学習型GNPとの違いは次の1点のみである。学習進化型GNPは Fig. 3.1に示すとおり,NijA, NijB, NijC, . . . という遺伝子が追加されている。それぞれノー ドiからノードjへの遷移が可能かどうかを表し,Nij = 1であれば可能,Nij = 0であれ ば不可能,となる。
進化型GNPは各状態から一本のブランチ,学習型GNPはn−2本(n: 総ノード数)
の遷移可能なブランチが存在した。一方,学習進化型GNPは各状態ごとにNij = 1であ るブランチを複数設定する [Fig. 3.2]。これは,進化によって複数の遷移候補を選び,学 習によって1つに決定するという学習と進化の連携を行っているためである。ただし,各 状態ですべてのNij の値が“0”であると,つぎのノードへ遷移できないので少なくとも1
つは“1”となるように設定する必要がある。
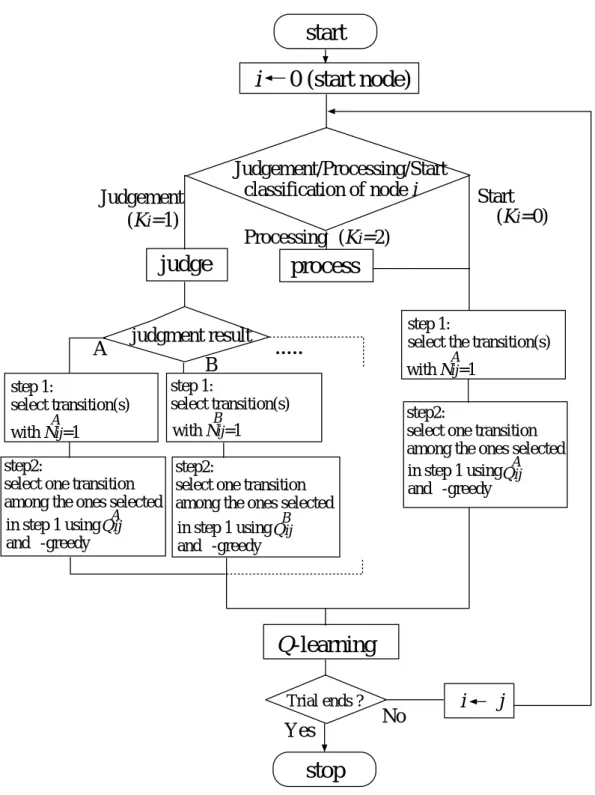
3.3 ノード遷移のルール
Fig. 3.3は学習進化型GNPのノード遷移の手続きを表している。判定ノードの場 合,割り当てられた判定IDi を行い,その結果から,参照すべき接続遺伝子の添え字
(A, B, C, . . .)を決定する。例えば,現在のノードがiで,判定結果が“B”であった場合
NijB = 1であるブランチを選択し,さらにその中からε−greedy方策による選択,つま り1−εの確率で最大のQ値を持つブランチ,εの確率でランダムに選ぶ。処理ノードの 場合,割り当てられた処理IDiを行い,NijA = 1であるブランチを選択し,その中から ε−greedy方策にしたがって1つを選ぶ。
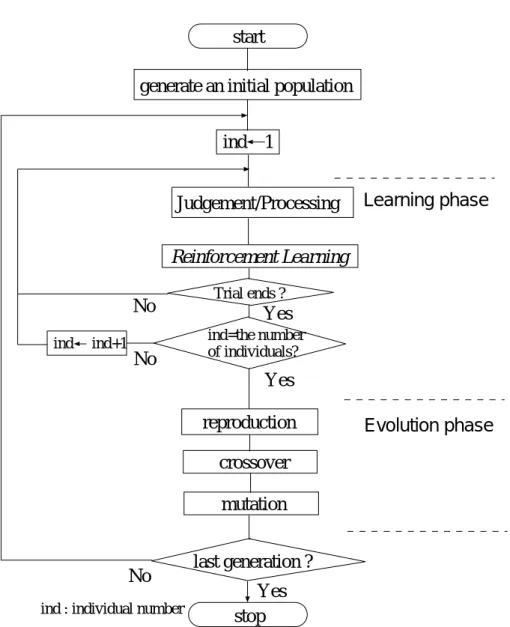
3.4 進化フェーズ
Fig. 3.4は学習と進化の流れを示している。
進化フェーズは,すべての個体がタスクを終了した後,選択,交叉,突然変異を通じ て,すべてのノード遷移の中から,複数の候補を選択することが目的である。学習フェー