Active Learning in Multilayer
Perceptrons
KenjiFukumizu
Information andCommunicationR&DCenter,RicohCo.,Ltd.
3-2-3,Shin-yokohama,Yokohama,222 Japan
E-mail: [email protected]
Abstract
Weproposeanactivelearningmethodwithhidden-unitreduction,
whichisdevisedsp eciallyformultilayerp erceptrons(MLP).First,
we review our activelearning metho d, and point out that many
Fisher-information-based metho dsapplied to MLPhavea critical
problem: the information matrix may be singular. To solve this
problem,wederivethesingularityconditionofaninformationma-
trix,andproposeanactivelearningtechniquethatisapplicableto
MLP.Itseectivenessisveriedthroughexperiments.
1 INTRODUCTION
Whenonetrainsalearningmachineusingasetofdatagivenbythetruesystem,its
abilitycan beimprovedifone selectsthetrainingdataactively. Inthis pap er,we
considertheproblemofactivelearningin multilayerperceptrons(MLP). First,we
reviewourmethodofactivelearning(Fukumizuelal.,1994),inwhichwepreparea
probabilitydistributionandobtaintrainingdataassamplesfrom thedistribution.
Thismethodologyleadsustoaninformation-matrix-basedcriterionsimilartoother
existingones (Fedorov,1972;Pukelsheim, 1993).
Activelearningtechniqueshaveb eenrecentlyusedwithneuralnetworks(MacKay,
1992;Cohn,1994). Ourmetho d,however,aswellasmanyotheroneshasacrucial
problem: therequiredinverseofaninformationmatrixmaynotexist(White,1989).
Weproposeanactivelearning techniquewhichisapplicableto three-layerpercep-
trons. Developing a theory on thesingularityof a Fisherinformation matrix, we
presentanactivelearningalgorithmwhichkeepstheinformationmatrixnonsingu-
lar. Wedemonstratetheeectivenessofthealgorithmthroughexperiments.
2.1 A CRITERIONOF OPTIMALITY
Wereviewthecriterionofstatisticallyoptimaltrainingdata(Fukumizuetal.,1994).
Weconsidertheregressionproblemin whichthetargetsystemmapsagiveninput
xtoyaccording to
y=f(x)+Z;
wheref(x)isadeterministicfunctionfromR L
toR M
,andZisarandomvariable
whose law is a normaldistribution N(0;
2
I
M ), (I
M
is the unit M 2M matrix).
Ourobjectiveistoestimatethetruefunctionf as accuratelyaspossible.
Letff(x;)gb eaparametricmo delforestimation. Weusethemaximumlikeliho o d
estimator(MLE)
^
fortrainingdataf(x ()
;y ()
)g N
=1
,whichminimizesthesumof
squared errors in this case. In theoretical derivations, we assume that the target
functionf isincludedin themo delandequal tof(1;
0 ).
Wemakeatrainingexamplebycho osingx ()
totry,observingtheresultingoutput
y ()
, andpairingthem. Theproblem ofactivelearning ishowto determineinput
data fx ()
g N
=1
to minimize the estimation error after training. Our approach is
a statistical one using a probability for training, r (x), and cho osing fx ()
g N
=1 as
independent samples from r(x) to minimize the exp ectation of the MSE in the
actualenvironment:
EMSE=E
f(x ()
;y ()
)g Z
Z
ky0f(x;
^
)k 2
p(yjx)dydQ
: (1)
Intheaboveequation,Qisthe environmentalprobabilitywhichgivesinputvectors
to thetruesystemin theactualenvironment,andE
f(x ()
;y ()
)g
meanstheexpec-
tation on trainingdata. Eq.(1), therefore, showsthe averageerror of thetrained
machinethatisusedasasubstituteofthetruefunctionintheactualenvironment.
2.2 REVIEW OFAN ACTIVE LEARNING METHOD
Usingstatisticalasymptotictheory,Eq.(1)isapproximatedasfollows:
EMSE= 2
+
2
N Tr
2
I(
0 )J
01
(
0 )
3
+O(N 03=2
); (2)
wherethematrixesI andJ are (Fisher)information matrixesdened by
I
ab
(x; )=
@f T
(x; )
@
a
@f(x; )
@
b
; I( )= Z
I(x; )dQ(x); J()= Z
I(x;)r (x)dx:
Theessentialpart ofEq.(2) is Tr[I(
0 )J
01
(
0
)], computed bythe unavailable pa-
rameter
0
. Wehaveprop osedapracticalalgorithminwhichwereplace
0 with
^
,
prepareafamilyofprobabilityfr (x;v)jv:paramatergtochoosetrainingsamples,
andoptimizevand
^
iteratively(Fukumizuetal., 1994).
ActiveLearning Algorithm
1. Selectaninitialtrainingdataset D
[0]
fromr(x;v
[0]
),andcompute
^
[0]
.
2. k:=1.
3. Computetheoptimalv=v
[k ]
tominimizeTr[I(
^
[k01]
)J 01
(
^
[k 01]
)].
k [k ] [k ]
D
[k 01]
and thenewdata.
5. ComputetheMLE
^
[k ]
basedonthetrainingdatasetD
[k ] .
6. k:=k+1andgoto3.
The ab ove metho d utilizes a probability to generate training data. It has the
advantage of making many data in one step compared to existing ones in which
only one data is chosen in each step, though their criterions are similar to each
other.
3 SINGULARITY OF AN INFORMATION MATRIX
3.1 A PROBLEM ON ACTIVELEARNING IN MLP
Hereafter, we focus on active learning in three-layer perceptrons with H hidden
units,N
H
=ff(x; )g. Themap f(x; )isdened by
f
i
(x;)= H
X
j=1 w
ij s(
L
X
k =1 u
jk x
k +
j )+
i
; (1iM); (3)
wheres(t)isthesigmoidalfunction: s(t)=1=(1+e 0t
).
Ouractivelearning metho d as well as manyother ones requires theinverseof an
information matrix J. The information matrix of MLP, however, is not always
invertible (White, 1989). Any statistical algorithms utilizing the inverse, then,
cannotbeapplieddirectly to MLP(Hagiwaraetal.,1993). Suchproblemsdonot
ariseinlinearmo dels,whichalmostalwayshaveanonsingularinformationmatrix.
3.2 SINGULARITY OFAN INFORMATIONMATRIX OFMLP
Thefollowingtheoremshowsthattheinformationmatrixofathree-layerp erceptron
issingularif andonly ifthenetworkhasredundant hiddenunits. Wecan deduce
thatiftheinformationmatrixissingular,wecanmakeitnonsingularbyeliminating
redundanthiddenunitswithoutchangingtheinput-outputmap.
Theorem 1 Assume r(x) is continuous and positiveat any x. Then, the Fisher
information matrix J is singular if and only if at least one of the following three
conditionsis satised:
(1)u
j :=(u
j1
;...;u
jL )
T
=0, forsome j.
(2)w
j :=(w
1j
;...;w
Mj )=0
T
,forsomej.
(3)Fordierentj
1 andj
2 ,(u
T
j1
;
j
1 )=(u
T
j2
;
j
2 )or(u
T
j1
;
j
1
)=0(u T
j2
;
j
2 ).
Therough sketchofthepro ofisshownb elow. Thecompletepro ofwillappearina
forthcomingpaper(Fukumizu,1996).
Roughsketchoftheproof. Weknoweasilythataninformationmatrixissingularif
andonlyiff
@f(x;)
@a g
a
arelinearlydependent. Thesuciencycanbeprovedeasily.
Toshowthenecessity,weshowthatthederivativesarelinearlyindep endentifnone
ofthethreeconditions issatised. Assumea linearrelation:
M
X
i=1 H
X
j=1
ij
@f
@w
ij +
M
X
i=1
i0
@f
@
i +
H
X
j=1 L
X
k =1
jk
@f
@u
jk +
H
X
j=1
j0
@f
@
j
=0: (4)
WecanshowthereexistsabasisofR ,hx ;...;x i,suchthatu
j
1x 6=0for
8
j, 8
l , and u
j
1 1x
(l)
+
j
1
6= 6(u
j
2 1x
(l)
+
j
2 ) for j
1 6= j
2 ,
8
l . We replace x in
eq.(4)byx (l)
t(t2R). Letm (l )
j :=u
j 1x
(l )
,S (l)
j
:=fz2Cjz=((2n+1) p
010
j )=m
(l )
j
; n2Zg, and D (l)
:=C0[
j S
(l )
j
. Thepointsin S (l )
j
arethe singularities
ofs(m (l)
j z+
j
). WedeneholomorphicfunctionsonD (l )
as
9 (l)
i
(z) :=
P
H
j=1
ij s(m
(l )
j z+
j )+
i0 +
P
H
j=1 P
L
k=1
jk w
ij s
0
(m (l)
j z+
j )x
(l )
k z
+ P
H
j=1
j0 w
ij s
0
(m (l)
j z+
j
); (1iM):
Fromeq.(4),wehave9 (l)
i
(t)=0forallt2R. Usingstandardargumentsonisolated
singularities ofholomorphicfunctions,we knowS (l)
j
areremovablesingularities of
9 (l)
i
(z),andnallyobtain
w
ij P
L
k=1
jk x
(l )
k
=0; w
ij
j0
=0;
ij
=0;
i0
=0:
Itiseasytosee
jk
=0. Thiscompletestheproof.
3.3 REDUCTION PROCEDURE
We intro duce the followingreduction procedure based on Theorem 1. Used dur-
ing BP training, it eliminates redundant hidden units and keeps the information
matrixnonsingular. Thecriterionofeliminationis very important,b ecauseexces-
siveelimination ofhiddenunits degradesthe approximationcapacity. Wepropose
an algorithm which doesnot increasethe mean squared error onaverage. Inthe
following,lets^
j :=s(^u
j 1x+^
j
)and"(N)=A=N fora p ositivenumb erA.
Reduction Procedure
1. If kw^
j k
2 R
(^s
j 0s(
^
j ))
2
dQ<"(N); theneliminatethejthhiddenunit,
and^
i
!^
i +w^
ij s(
^
j
)foralli.
2. If kw^
j k
2 R
(^s
j )
2
dQ<"(N); theneliminatethejthhiddenunit.
3. If kw^
j
2 k
2 R
(^s
j
2 0^s
j
1 )
2
dQ<"(N) fordierentj
1 andj
2 ,
theneliminatethej
2
thhiddenunitandw^
ij1
!w^
ij1 +w^
ij2
foralli.
4. If kw^
j2 k
2 R
(10^s
j2 0^s
j1 )
2
dQ<"(N) fordierentj
1 andj
2 ,
then eliminatethe j
2
th hidden unitand w^
ij1
! w^
ij1 0w^
ij2
; ^
i
! ^
i +
^ w
ij2
foralli.
FromTheorem1,weknowthatw^
j ,u^
j ,(^u
T
j2
;
^
j
2 )0(^u
T
j1
;
^
j
1 ),or(^u
T
j2
;
^
j
2 )+(^u
T
j1
;
^
j
1 )
can b e reduced to 0 if the information matrix is singular. Let
~
2 N
K
denote
thereduced parameter from
^
according to theaboveprocedure. The ab ovefour
conditionsare, then,givenbycalculating R
kf(x;
~
)0f(x;
^
)k 2
dQ.
We briey explain how the procedure keeps the information matrix nonsingular
anddoesnotincreaseEMSEinhighprobability. First,supposedetJ(
0
)=0,then
there exists K
0 2N
K
(K <H)such that f(x;
0
)=f(x;
K
0
) and detJ(
K
0 )6= 0
in N
K
. Theelimination ofhidden units uptoK, ofcourse, do esnotincreasethe
EMSE. Therefore, we haveonly to consider the case in which detJ(
0
) 6= 0 and
hiddenunitsareeliminated.
Suppose R
kf(x;
K
0
)0f(x;
0 )k
2
dQ>O (N 01
)foranyreducedparameter K
0 from
0
. Theprobabilityofsatisfying R
kf(x;
^
)0f(x;
~
)k 2
dQ<A=N isverysmallfor
probability. Next,suppose R
kf(x;
K
0
)0f(x;
0 )k
2
dQ=O (N 01
). Let
~
2N
K be
a reducedparameter madefrom
^
with thesame pro cedureas weobtain K
0 from
0
. Wewill showfora sucientlysmallA,
E h
R
kf(x;
^
K
)0f(x;
0 )k
2
dQ i
E h
R
kf(x;
^
)0f(x;
0 )k
2
dQ i
;
where
^
K
is MLE computed in N
K
. We write = ( (1)
; (2)
) in which (2)
is
changedto0inreduction,changingthecoordinatesystemifnecessary. TheTaylor
expansionandasymptotictheorygive
E h
R
kf(x;
^
K
)0f(x;
0 )k
2
dQ i
R
kf(x;
K
0
)0f(x;
0 )k
2
dQ+
2
N Tr[I
11 (
K
0 )J
01
11 (
K
0 )];
E h
R
kf(x;
~
)0f(x;
^
)k 2
dQ i
R
kf(x;
K
0
)0 f(x;
0 )k
2
dQ +
2
N Tr[I
22 (
K
0 )J
01
22 (
0 )];
whereI
ii andJ
ii
denotethelocalinformationmatrixesw.r.t.
(i)
(i=1;2). Thus,
E h
R
kf(x;
^
)0f(x;
0 )k
2
dQ i
0E h
R
kf(x;
^
K
)0f(x;
0 )k
2
dQ i
0E
h
R
kf(x;
~
)0f(x;
^
)k 2
dQ i
+
2
N Tr[I
22 (
K
0 )J
01
22 (
0 )]
0
2
N Tr[I
11 (
K
0 )J
01
11 (
K
0 )]+E
h
R
kf(x;
^
)0f(x;
0 )k
2
dQ i
:
Sincethesumofthelasttwotermsispositive,thel.h.sisp ositiveifE[
R
kf(x;
^
K
)0
f(x;
^
)k 2
dQ]<B=N forasucientlysmallB. Althoughwecannotknowthevalue
ofthisexpectation,wecanmaketheprobabilityofholdingthisenequalityveryhigh
bytakingasmallA.
4 ACTIVE LEARNING WITH REDUCTION
PROCEDURE
Thereduction pro cedurekeeps theinformationmatrixnonsingularandmakesthe
activelearningalgorithm applicableto MLPevenwithsurplushiddenunits.
ActiveLearning with Hidden Unit Reduction
1. SelectinitialtrainingdatasetD
0
fromr(x;v
[0]
), andcompute
^
[0]
.
2. k:=1,anddoREDUCTIONPROCEDURE.
3. Computethe optimalv =v
[k ]
to minimizeTr[I(
^
[k 01]
)J 01
(
^
[k 01]
)], using
thesteep estdescentmetho d.
4. Choose N
k
new training data from r(x;v
[k ]
) and let D
[k ]
be a union of
D
[k 01]
and thenewdata.
5. Compute the MLE
^
[k ]
based on the training data D
[k ]
using BP with
REDUCTIONPROCEDURE.
6. k:=k+1andgoto3.
TheBPwith reductionprocedureis applicablenotonly toactivelearning, but to
avarietyofstatisticaltechniquesthatrequiretheinverseofaninformationmatrix.
Wedonotdiscussitinthis pap er,however.
100 200 300 400 500 600 700 800 900 1000
The Number of Training Data
0.0000001 0.000001 0.00001
Mean Squared Error (log)
Learning Curve
200 400 600 800 1000
0 1 2 3 4
The number of hidden units
# of hidden units
200 400 600 800 1000
The Number of Training Data
0.000001
Mean Squared Error (log)
Active Learning
Active Learning [Av-Sd,Av+Sd]
Passive Learning
Passive Learning [Av-Sd,Av+Sd]
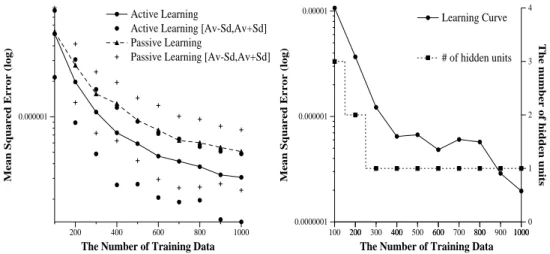
Figure1: Active/PassiveLearning: f(x)=s(x)
5 EXPERIMENTS
We demonstrate theeect of the proposed activelearning algorithm throughex-
periments. Firstweusea three-layermodelwith1inputunit,3hiddenunits,and
1 output unit. The truefunction f is a MLP network with 1 hidden unit. The
information matrix is singular at
0
, then. The environmental probability, Q, is
a normal distributionN(0;4). We evaluatethe generalizationerror in the actual
environmentusingthefollowingmeansquarederrorofthefunctionvalues:
Z
kf(x;
^
)0f(x)k 2
dQ:
We set the deviation in the true system = 0:01. As a family of distributions
for trainingfr(x;v)g, a mixture mo del of4 normaldistributions is used. Ineach
step of activelearning, 100 new samples are added. A network is trained using
onlineBP,presentedwithalltrainingdata10000timesin eachstep,andoperated
thereduction procedure oncea 100 cyclesb etween5000th and10000th cycle. We
try30trainings changing theseed of randomnumb ers. Incomparison, wetraina
networkpassivelybasedontrainingsamplesgivenbytheprobabilityQ.
Fig.1showstheaveragedlearningcurvesofactive/passivelearningandthenumber
of hiddenunits in a typical learning curve. The advantage ofthe proposed active
learningalgorithmisclear. Wecan ndthat thealgorithmhasexpectedeectson
asimple,idealapproximationproblem.
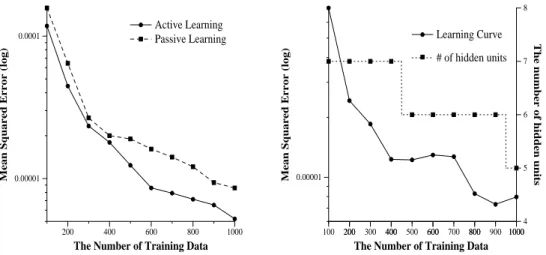
Second, we apply the algorithm to a problem in which the true function is not
includedintheMLPmodel. WeuseMLPwith4inputunits,7hiddenunits,and1
outputunit. Thetruefunctionisgivenbyf(x)=erf(x
1
),whereerf(t)istheerror
function. Thegraphoftheerrorfunctionresemblesthatofthesigmoidalfunction,
whiletheynevercoincidebyanyanetransforms. Weset Q=N(0;252I
4 ). We
train a network actively/passively based on 10 data sets, and evaluate MSE's of
functionvalues. Otherconditions arethesame asthoseoftherstexperiment.
Fig.2 shows the averaged learning curves and the number of hidden units in a
typicallearningcurve. Wendthattheactivelearningalgorithmreducestheerrors
thoughthe theoreticalcondition isnot p erfectlysatised in this case. It suggests
therobustnessofouractivelearningalgorithm.
100 200 300 400 500 600 700 800 900 1000
The Number of Training Data
0.00001
Mean Squared Error (log)
Learning Curve
200 400 600 800 1000
4 5 6 7 8
The number of hidden units
# of hidden units
200 400 600 800 1000
The Number of Training Data
0.00001 0.0001
Mean Squared Error (log)
Active Learning Passive Learning
Figure2: Active/PassiveLearning: f(x)=erf(x
1 )
6 CONCLUSION
Wereviewstatisticalactivelearningmetho dsandp ointoutaproblemin theirap-
plicationtoMLP:therequiredinverseofaninformationmatrixdoesnotexistifthe
networkhas redundanthidden units. Wecharacterize thesingularity conditionof
aninformationmatrixandprop oseanactivelearningalgorithmwhichisapplicable
to MLP with any numb er of hidden units. The eectiveness of the algorithm is
veriedthroughcomputer simulations,even whenthetheoretical assumptionsare
notperfectlysatised.
References
D.A. Cohn. (1994)Neuralnetwork explorationusing optimalexperimentdesign.
In J. Cowanet al. (ed.), Advances in Neural Information Processing Systems 6,
679-686. SanMateo,CA:MorganKaufmann.
V.V. Fedorov. (1972)Theory ofOptimal Experiments. NY:AcademicPress.
K.Fukumizu. (1996)A RegularityConditionof theInformationMatrixofa Mul-
tilayerPerceptronNetwork. NeuralNetworks,to app ear.
K. Fukumizu, & S. Watanab e. (1994) Error Estimation and Learning Data Ar-
rangementforNeuralNetworks. Proc. IEEE Int. Conf. NeuralNetworks:777-780.
K. Hagiwara, N. Toda, & S. Usui. (1993) On the problem of applying AIC to
determinethestructure ofa layeredfeed-forwardneural network. Proc. 1993Int.
Joint Conf. Neural Networks:2263-2266.
D.MacKay. (1992)Information-basedobjectivefunctionsforactivedataselection,
NeuralComputation 4(4):305-318.
F.Pukelsheim. (1993)Optimal Design ofExperiments. NY:JohnWiley&Sons.
H. White. (1989)Learning in articial neuralnetworks: A statistical persp ective
NeuralComputation 1(4):425-464.