2014 年度 修士論文
マイクロブログを対象とした
100,000 人レベルでの著者推定手法の提案
提出日: 2015 年 2 月 2 日 指導: 山名 早人 教授
早稲田大学大学院 基幹理工学研究科 情報理工学専攻 学籍番号: 5113B015-5
奥野 峻弥
i
概 要
近年,インターネットを利用した犯罪の捜査などを行うため,web 上の文章に対する著 者推定手法の研究が盛んに行われている.しかし,近年人気のwebコンテンツとなってい るマイクロブログへ投稿された文章に対し著者推定技術を用いる場合,ブログなどと比べ て一文が 140 字と非常に短く,話題に一貫性がないため,推定精度が低下するという問題 がある.さらに,マイクロブログの利用者は刻々と増加しているため,著者推定技術を使 用する際の候補者となる利用者は日本ユーザのみでも1,000万人を越えている.そのため,
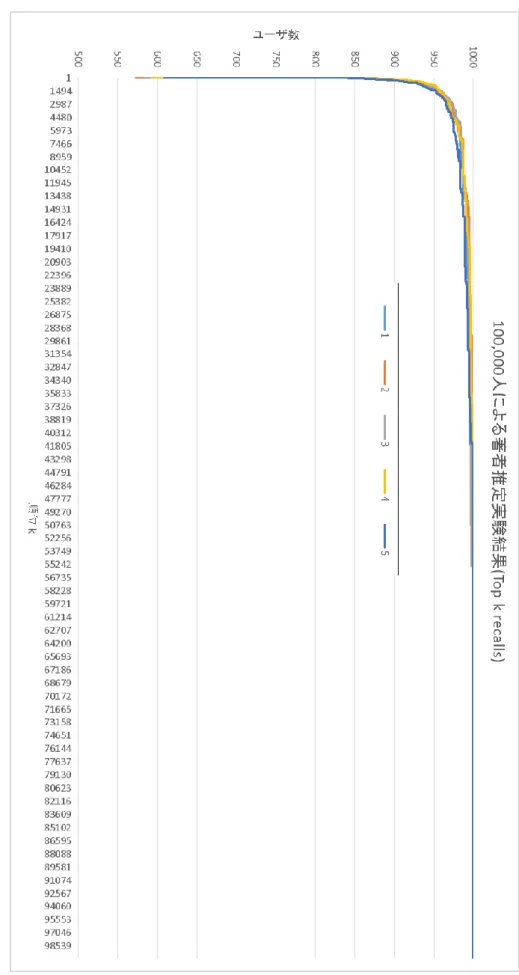
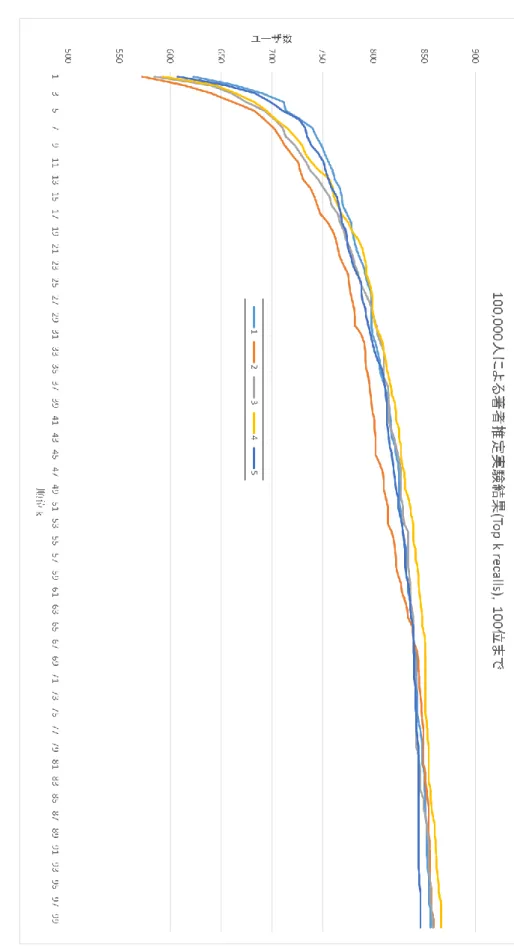
大規模な候補者群から著者を推定することを前提として,より高速に計算を行うアルゴリ ズムが必要とされている.そこで本稿では,1) 文章中から取得したn-gramに対しnの大 きさに応じた重みをかける.2) 推定対象と類似する話題分布となる訓練データの選択を行 い,推定精度を保ちつつ使用する文章量を削減する.これらの手法を用いて,より文章中 から著者の特徴を抽出することにより,より精度が高く,かつ高速な著者推定手法を提案 する.100,000ユーザによる評価実験の結果,MRRにして0.646で推定ができた.
ii
目次
第1章 はじめに ...1
第2章 著者推定タスク ...3
2.1 著者推定とは ... 3
2.2 著者推定タスクとは ... 4
2. 2. 1 定義 ...4
2. 2. 2 PBAによる著者推定タスク ...5
2. 2. 3 IBAによる著者推定タスク ...6
2.3 著者推定手法の評価 ... 8
第3章 従来手法 ...9
3.1 文学的知見に基づく著者推定手法 ... 9
3.2 IBAによる著者推定タスク ... 11
3. 2. 1 Narayananらの手法 ... 11
3. 2. 2 Silvaらの手法 ... 13
3. 2. 3 Schwartzらの手法 ... 13
3. 2. 4 IBAによる大規模著者推定タスクの問題点 ... 14
3.3 PBAによる著者推定タスク ... 16
3. 3. 1 Regalらの手法 ... 16
3. 3. 2 井上らの手法 ... 16
3.4 従来手法のまとめ ... 18
第4章 マイクロブログに対応した著者推定手法 ... 20
4.1 概要 ... 20
4.2 叫喚ツイートの除去 ... 21
4.3 メッセージからの特徴量取得 ... 22
4.4 コサイン類似度を用いた文体相違度計算方法 ... 23
4.5 多様な話題に対応するデータセット作成 ... 24
4.6 複数学習データセットにおける文体相違度計算 ... 26
第5章 評価実験 ... 27
5.1 データセット ... 27
5.2 評価方法 ... 28
5.3 予備実験 ... 28
5. 3. 1 データセットを構成するメッセージ数の決定 ... 29
5. 3. 2 文体定量化手法との評価 ... 29
iii
5. 3. 3 複数データセットによる文体相違度計算手法の評価 ... 32
5. 3. 4 叫喚フレーズ正規化の評価 ... 33
5. 3. 5 学習データセット選択手法の評価 ... 35
5.4 評価実験結果 ... 37
第6章 おわりに ... 40
1
第 1 章 はじめに
近年,インターネットバンキングにおける不正送金や,遠隔操作によるインターネット 掲示板上での犯罪予告などのサイバー犯罪が増加している.これは Twitter1や Tumblr2を はじめとするマイクロブログにおいても例外ではない.事実,2011 年から 2013 年までの
Twitterに関する犯罪報告件数は677件から1,291件と2倍近くに急増している[1][2].
サイバー犯罪における捜査上の問題点として,インターネットは匿名性が高い媒体であ るために,犯人の特定が難しいことが挙げられる.事実,遠隔操作を利用し,他者に成り すまして犯罪予告をインターネット掲示板に投稿する,という事件が発生している[3].し かし,事件の捜査において,IP アドレスによる犯人の特定ができず,誤認逮捕が発生して しまった.そこで,今後はIPアドレスや通信ログなど,偽装されうる情報のみならず,犯 人の文体をはじめとする,偽装が難しい情報を併用して犯人を特定していく捜査が必要と なる.それゆえに,近年ではWeb上のテキストコンテンツを対象として,コンテンツの著 者を推定する著者推定研究が増えてきている[4][5].これらの研究を捜査に応用することで,
偽装が難しい文体の情報を,捜査に活用することが可能となる.このような背景のもと本 稿では,代表的なマイクロブログであるTwitterに投稿されたメッセージを対象とする著者 推定手法の提案を行う.
Web 上のテキストコンテンツに対する既存の著者推定手法はいくらか存在するが,これ らの著者推定手法をマイクロブログに投稿されたメッセージに応用するためには,以下の3 つの問題が存在する.
1. 多種多様な話題に起因する精度低下
2. 推定対象となる文章の短文化による特徴量選択の失敗 3. 膨大な候補者群による計算時間の増大
1つ目は,著者推定で用いる候補者ごとの文章を,各々同一話題として収集できなくなる 問題である.これは,1つの話題について大量にメッセージを書くユーザが少ないことに由 来する.著者推定で用いる候補者の文章が同一話題でなく相違話題となる時,著者推定精 度は低下する.これは,我々の先行研究[5]で示されている.2 つ目は,推定対象として用 いる文章が短いため,文章から特徴量を十分に取得できないという問題である.既存の著 者推定手法においては,ブログや掲示板といったユーザによる一定量の書き込みを期待で きるコンテンツを対象にしている.しかし,Twitterに投稿されるメッセージは最大でも140 字であり,かつ 140 字で完結する内容のメッセージがほとんどであることに由来する.3
1 Twitter, https://twitter.com/
2 Tumblr, https://www.tumblr.com/
2
つ目は,推定対象文章の著者を推定するとき,処理しなくてはならない計算量が増加する 問題である.これは,推定対象文章ごとにすべての候補者に対して著者推定の処理をしな くてはならないことに由来する.
本稿では以上の問題点を解決するため,1) 推定対象文章と類似する話題分布となる学習 データセットの選定による,相違話題に起因する推定精度低下の回避.2) n-gramのn特徴 量として使用するn-gramのnに比例した重み付けによる,より洗練された特徴量取得の2 つの手法を用いる.1)の手法により,推定の前段階に各ユーザの学習データセットを選定す ることで,学習データセットと推定対象文章に含まれる話題が一致する可能性を上昇させ,
推定精度を向上する.同時に,推定の際に用いるデータセット数を減らすことで,計算量 を削減できる.また,2)の手法を用いることで,1文が短いマイクロブログのメッセージか ら,より多くの特徴量を取得しつつ,より著者の文体を表す特徴量を抽出することが可能 となる.
本稿では以下の構成をとる.まず 2 章では,著者推定研究で取り扱われてきた著者推定 タスクについて述べる.次の3章では,既存の著者推定手法について述べる.続く 4章で は,本稿で提案する著者推定手法について述べる.そして,5章にて既存手法と提案手法と に対する評価実験の方法と結果について述べる.最後に6章で本稿をまとめる.
3
第 2 章 著者推定タスク
本章では,著者推定タスクについての説明を行う.本章の内容については,本研究室に おいて井上らが定義した内容[5]をアップデートする形で,著者推定タスクについての説明 を行う.
まず,2. 1節において著者推定タスクが取り扱う著者推定について述べる.次の2. 2節 では著者推定タスクの定義について説明していく.最後の2. 3節では,著者推定タスクの 結果からどのようにして著者推定手法を評価するかについて述べていく.
2. 1 著者推定とは
著者推定とは,未知である文章の著者を推定することである.言語ごとにその文章に対 する著者推定研究が行われているが,日本語の文章に対する著者推定研究は計量文体学の 一研究分野として行われてきた[6][7][8][10].本稿で述べる著者推定とは,計量文体学に基 づく,日本語の文章に対する著者推定のことを示すものとする.計量文体学で行われてき た著者推定では,未知である文章の著者を定量的に推定する著者推定手法の提案を目指し ている.近年では,計算機を用いたテキストマイニングによる著者推定手法[10][11][12][13]
が提案されている.当手法を用いることで,計量文体学で当初行われてきた文学的文章に 対する著者推定に限らず,インターネットに投稿された文章に対する著者推定[4][5][14]
[15][16]も行われつつある.
計量文体学における著者推定では,文体的指標に基づく文体を文章間で比較することで,
著者を定量的に推定した.文体とは,文章を書く際に現れる,個人毎に異なる癖である.
文体が個人毎に異なることは,ソシュールの一般言語学講義[17]において言語学の知見から 述べられている.この文体は,語彙の選び方,文章の構成方法,句点,読点の打ち方など 様々な文章中の特徴で表現できる.この文体を示す文章中の特徴を文体的指標と呼ぶ.計 量文体学における著者推定では,文体的指標に基づく文体を定量的に表現することで,著 者間における文体の違いを定量的に示す.著者間の定量的な文体相違を用いることで,未 知である文学的文章の著者を,統計的に推定できる.
統計的に結果が示せる著者推定は,テキストマイニングなどの計算機科学の技術を用い ることで,更に実用的となっている.まず,MeCab[18]を始めとする形態素解析器を用い る[5][12]ことで,文体の定量的表現を容易にした.形態素解析器とは,与えられた文章を 分かち書きにし,各々の形態素に品詞などの情報を自動的に付与するものである.また,
機械学習を用いることで,統計的な知見から行う著者推定を容易に行えるようになった.
機械学習とは,複数に分類されるデータを事前に与えることで,未分類のデータを機械的
4 に自動で分類する技術である.
計算機科学の技術を用いた著者推定によって,その応用先が多様化してきている.計量 文体学における当初の著者推定[6]は,宗教書,哲学書,歴史書,文学作品などの著作物を 取り扱ってきた.これは,著作物に対する研究で障害となる著者の不明瞭さを解決するた めに,著者推定の研究が始まったためである.具体的には,著者推定研究の起源は,源氏 物語の著者が全編で同一かどうかの真贋研究[7]から始まったとされている.しかし近年で は,計算機科学の技術を用いることで著者推定が容易となったため,一般的な人が書く文 章に対して著者推定が応用されている.具体的には,インターネット上に投稿される文章 [4][5],学術論文[8]が挙げられる.
2. 2 著者推定タスクとは
著者推定タスクとは,計量文体学で行われてきた著者推定を一般化したものである.具 体的には,計量文体学を始めとする数多くある著者推定の手法を抽象化したものである.
つまり,すべての著者推定手法は著者推定タスクを基にした実装が可能になる.著者推定 タスクを定義することで,すべての著者推定手法で共通した著者推定を行うことができる.
これは,同一条件のもと,すべての著者推定手法を実行できることを意味している.この 同一条件下における著者推定手法の実行結果により,公平な著者推定手法間の比較が可能 となるため,著者推定手法を適正に評価することができる.なお,著者推定タスクは Profiled-Based Approach (PBA)と Instance-Based Approach (IBA)の 2 種類に分類する ことができる.この分類は,Stamatatos[19]らによる著者推定手法の分類を参考にしたも のである.
以下では,著者推定タスクについての定義を述べた後に,PBA 及び IBA の各々の分類 について著者推定タスクの内容を説明していく.
2. 2. 1 定義
著者推定タスクとは,計量文体学で行われる著者推定を一般化したもので,数ある著者 推定手法を同一環境下で実行することができる.具体的には,計量文体学で行われてきた 以下の手順による著者推定を,著者推定タスクと呼ぶ[5].
① 推定対象文章と候補者群の文章が与えられる.
② 推定対象文章と候補者ごとの文章に対して文体定量化を行う.
③ 推定対象著者と文体が最も類似する候補者群中の候補者を,手順②で文体定量化さ れた文章群を用いて選択する.
5
④ 手順③で選択された候補者を推定結果著者として出力する.
推定対象文章とは,著者推定の対象となる,未知である著者を推定したい文章のことで ある.推定対象著者とは,推定対象文章の著者のことであり,著者推定タスクにおいては 未知の情報である.候補者群とは,推定対象著者である可能性を持つ,複数の著者集合の ことである.文体定量化とは,与えられる文章の著者の文体を複数の数値で定量的に表現 することである.推定結果著者とは,著者推定タスクで得られる,推定対象著者と推定さ れる候補者群中の 1 人の候補者のことである.
著者推定タスクでは,候補者群中から候補者を選択することで推定対象著者を推定する ことを目的としている.当該目的を達成するため,著者推定タスクは,推定対象著者と文 体が最も類似する候補者群中の候補者を得て,推定結果著者を出力する.ここで,候補者 群中には,推定対象著者が含まれていることが,著者推定タスクの目的を達成するために 必要不可欠である.なぜならば,候補者群中に推定対象著者が含まれていないと,推定結 果著者として推定対象著者を出力することができないためである.
著者推定タスクにおける手順②及び手順③の方法は,著者推定タスクに用いられる著者 推定手法によって異なる.当該著者推定手法で決定される,著者推定タスクにおける手順
②及び手順③の方法をより良くすることで,より著者推定タスクの目的を達成しやすくす ることができる.なお,著者推定タスクにおける手順②及び手順③を,ある著者推定手法 に基づいて行うことは,「著者推定タスクを著者推定手法によって行う」と表現する.
著者推定手法は,上記の著者推定手順の手順②の方法に応じて,PBA 及び IBA の 2 種 類に分類できる.この分類は,Stamatators[19]によって提唱されている.本稿では,PBA に分類される著者推定手法によって行われる著者推定タスクを,PBA による著者推定タス クと呼ぶ.同様に,IBA に分類される著者推定手法によって行われる著者推定タスクを,
IBA による著者推定タスクと呼ぶ.PBA 及び IBA による著者推定タスクは上記で述べた 著者推定の手順によって著者推定を行うが,手順①及び手順②の方法が PBA 及び IBA で 異なる.
2. 2. 2 PBA による著者推定タスク
PBA による著者推定タスクは,情報検索タスクにおけるベクトルを用いた類似度算出方 法と同様に,図 1 の手順で行われる.つまり当該タスクは,事前に候補者毎の特徴量をベ クトルによってパラメータ化しておき,推定対象文章が入力された際に,すべての候補者 との間で特徴量の比較を行う著者推定の方法である.
当該著者推定タスクの流れは,図 1に基づき以下の流れで行われる.
6
① 候補者文章群を集める.候補者文章群とは,候補者ごとに1つの文章を集めた文章 集合のことである.
② 推定対象文章,及び候補者文章群中のすべての文章に対して,文体定量化を行う.
③ 文体定量化方法は,当該著者推定タスクに用いられる著者推定手法によって異なる.
④ 候補者文章群中の文章ごとに,推定対象文章との文体相違度を計算する.文体相違 度とは,2 文章における各著者の間で文体がどの程度異なっているのかを定量的に 表現したものである.文体相違度の計算方法は,当該著者推定タスクに用いられる 著者推定手法によって異なる.
⑤ 候補者文章群の文章を,③で得た文体相違度の低い順に並び替える.
⑥ 候補者群を並び替える.並び替える方法は,④で並び替えられた候補者文章群中の 各文章の順位と,その著者の集合である候補者群の順位が一致するようにする.
⑦ 並び替えられた候補者群の中で 1 位となる候補者を,推定結果著者として出力する
図 1 PBAによる著者推定タスク
2. 2. 3 IBA による著者推定タスク
IBA による著者推定タスクは,機械学習を用いて図 2のように著者推定を行う方法であ る.具体的に当該方法では,機械学習を用いて候補者となる著者の特徴量を学習しておき,
推定対象文章が入力された際に,学習済みの分類器を用いることで著者推定を行う.
当該著者推定タスクの流れは,図 2に基づき以下の流れで行われる.
① 学習データを集める.この学習データとは,候補者ごとに複数の文章を収集して集 められた文章集合のことである.なお,当該学習データ中の各文章には,その著者
7 である候補者の ID を付与しておく.
② 推定対象文章,及び学習データ中のすべての文章に対して,文体定量化を行う.こ の文体定量化は,PBA における著者推定タスクで行うものと同じである.文体定量 化方法は,当該著者推定タスクに用いられる著者推定手法によって異なる.
③ 学習データ中の定量化された文章群を用いて分類器を生成する.分類器とは機械学 習がラベル付きの多次元変数の集合を用いて作るもので,分類器によってラベルご とにデータ間の違いを定量的に判断できる.当該著者推定タスクでは,学習データ 中の定量化された各文章が機械学習で用いる多次元変数を表し,これらの文章に付 与する ID がラベルとなる.分類器の生成方法は,当該著者推定タスクに用いられ る著者推定手法によって異なる.
④ 定量化された推定対象文章を③で得られる分類器に入力する.
⑤ 入力した分類器が分類した推定対象文章の分類先となるラベルを出力する.このラ ベルが指し示す候補者群中の 1 人の候補者を,推定結果著者として出力する.
図 2 IBAによる著者推定タスク
8
2. 3 著者推定手法の評価
著者推定タスクの結果を用いることで,著者推定タスクに用いられる著者推定手法の性 能を評価することができる.具体的には,多数の推定対象文章に対して複数回の著者推定 タスクを行い,各々の結果を用いて著者推定手法評価を行う.以下では,著者推定タスク の結果を評価する方法について述べた後,著者推定手法評価の具体的な方法について述べ る.
著者推定タスクの結果を評価することとは,推定結果著者と推定対象著者が一致してい るかを判定することである.本来,推定対象著者は未知であるが,著者推定タスクの結果 を評価する際には推定対象著者が事前にわかっているものする.もし,推定結果著者と推 定対象著者が一致していれば,当該著者推定タスクは成功したと評価する.なお,推定結 果著者と推定対象著者の一致を判定するために,候補者及び推定対象著者に著者 ID が付 与されている必要がある.著者 ID とは,候補者及び推定対象著者を一意に定める個体識 別符号のことである.推定結果著者と推定対象著者の一致は,各々の著者 ID の一致をも って判定される.
既存の著者推定研究[5][10][11][12][13]では,著者推定手法を評価するために,複数の著 者推定タスクの結果から得られる成功確率を用いている.既存の著者推定研究では,この 成功確率のことを著者推定精度と呼んでおり,著者推定手法に対する評価値として用いら れている.著者推定精度の取得は,評価したい 1 つの著者推定手法を用いて,複数の推定 対象文章に対する複数回の著者推定タスクを行い,その成功する回数を得ることで行う.
著者推定タスクを行った回数に対する成功回数の割合を著者推定精度とする.著者推定手 法の性能の善し悪しは,著者推定精度の高さで評価することができるが,データセットに よってその精度は変動するため,同一のデータセットを用いて著者推定手法評価を行う必 要がある.なお,著者推定手法評価におけるデータセットとは,著者推定タスクに与えら れる推定対象文章や候補者文章群などの文章群のことを指す.
9
第 3 章 従来手法
本章では,従来の著者推定手法についての説明を行う.本章に関しても,本研究室の井 上ら[5]が行った,修論におけるサーベイをアップデートする形でまとめる.
既存の各著者推定研究では,数多くの著者推定手法が提案されてきた.これらの著者推 定手法は,大きく以下の2つに分類できる.
1. 文学的知見に基づく方法
2. テキストマイニングに基づく方法
文学的知見に基づく方法とは,著者推定の対象となる文章に現れる文体を文学的知見に 基づく文体的指標で表現し,その結果を用いて著者を推定する方法である.この文体的知 見に基づく文体的指標は,著者を推定する文章に合わせて選択される.テキストマイニン グに基づく方法とは,著者推定の対象となる文章に現れる文体を特定の文体的指標に基づ いて表現し,その結果を用いて著者を推定する方法である.この特定の文体的指標は多数 用いられるため,文学的知見に基づく方法よりも多大な計算量が必要となる.この特定の 文体的指標を抽出するためにテキストマイニングが用いられる.
本章では,従来の著者推定手法について,上記の分類ごとに以下の通り述べていく.ま ず,3. 1節では文学的知見に基づく著者推定の方法について述べる.次の3. 2節では,テ キストマイニングに基づく方法における,webコンテンツに対するIBAの著者推定タスク に用いられる著者推定手法について述べる.3. 3節では,同じくテキストマイニングに基づ く方法のうち,webコンテンツに対するPBAの著者推定タスクに用いられる著者推定手法 について述べる.その後,上記で述べた従来手法をインターネットに投稿された文章に応 用する,著者推定研究について述べる.最後に,本章で述べた従来の著者推定手法をまと める.
3. 1 文学的知見に基づく著者推定手法
文学的知見に基づく著者推定手法は,安本ら[20],村上ら[6]により提案されている.安 本らは日本語の文献である源氏物語に対する著者同一性検証を行った.著者同一性検証と は,著者推定の応用の 1 つで,多数の文章においてすべて著者が同じであるかを判定する ことである.この源氏物語に対する著者同一性検証は,村上らの研究でも行なわれている.
また,村上らの当該研究において,日本語の文献である複数の日蓮の書簡に対しての真贋 判定を行った.真贋判定とは,特定の著者の書いた文章と,その著者の名を偽って書かれ た文章を用いることで,未知である文章の真贋を判定するものである.真贋判定は,特定
10
著者とその名を騙る著者群を含む,候補者群に対する著者推定タスクとみなせる.以下で は,上記の各研究についてその著者推定の方法について述べていく.
安本らによる源氏物語の著者同一性検証
安本ら[20]の行った源氏物語の著者同一性検証では,55 巻ある当該文献を前半 44 巻,
後半 10 巻に分け,2 つが同一著者であるかどうかを検証した.この検証には,当該 2 部 の文章ごとに,特定の文体的指標に基づく文体を定量的に取得した値を用いている.文章 の文体を定量的に取得するために用いた文体的指標を表 1に示す.当該研究において,表 1 で示した文体的指標の基づく文体を,前半,後半での各々の文章に対して数値化し,これ らの数値の違いを統計的に検証することで行った.この統計的検証には,U検定法及びχ2 検定を用いている.
表 1 安本らの用いた文体的指標
村上らによる源氏物語の著者同一性検証
村上ら[6]の行った源氏物語の著者同一性検証では,55巻ある当該文献を 4部に分割し,
すべての部で著者が同じであるかの検証を行った.この検証は,安本らによる検証と同じ く,各部の文章ごとに,特定の文体的指標に基づく文体を定量的に取得した値を用いてい る.文章の文体を定量的に取得するために,特定の名詞及び助動詞の語の出現頻度を文体 的指標として,その値を用いている.各部の間で文体的指標を比較するために,各文体的 指標の値の平均値を用いた.また,すべての文体的指標を1つの図で図示化することで,
各部の間における文体の違いを表現し,各部の文章において著者が同一かの真偽を判定し ている.
村上らによる日蓮遺文の真贋判定
村上ら[6]は,数ある日蓮の書簡の中で,真贋が問題とされてきた 5 編の書簡に対し,計 量文体学に基づく真贋判定を行った.この真贋判定には,事前に真贋が判明している50編
11
の書簡を用いている.具体的には,当該50編の各書簡に対して特定の文体的指標に基づく 文体の定量化を行い,定量化された書簡ごとの文体に基づいたクラスタ分析を行った.当 該クラスタ分析は,平方ユークリッド距離による最長距離法が用いられている.このクラ スタ分析によって,50編の書簡は日蓮の著作の分類と,贋作の分類に2分することに成功 している.これにより,真贋を判定する 5 編の書簡は,クラスタ分析によって作られる上 記の分類方法によって,同様に日蓮の著作の分類と贋作の分類に分類することができる.5 編の書簡の分類先が日蓮の著者の分類となるかによって,当該書簡の真贋が判定できる.
なお,各書簡に対する文体の定量化には,特定単語の出現頻度,文の長さ,品詞の出現頻 度が用いられている.
3. 2 IBA による著者推定タスク
テキストマイニングに基づく方法における,webコンテンツに対する IBA の著者推定タ スクに用いられる著者推定手法には,Narayanan ら[14]の手法,Silva ら[15]の手法及び,
Schwarzら[4]の手法が該当する.これらの従来手法の間では,2. 2. 3項で述べた IBA の
著者推定タスクの手順における,文体定量化方法,及び分類器生成方法が異なる.
3. 2. 1 Narayanan らの手法
Narayananら[14]は,ブログに投稿された文章に対する著者推定を,IBAによる著者推
定タスクに基づいて行った.Narayananらの提案する著者推定手法では,文体定量化方法 には表 2に示される10種類の特徴量を使用している.それぞれの特徴量について,学習デ ータセット中に含まれる当該特徴量のうち,0でないものを除く平均値で割ることで,各特 徴量の正規化を行っている.分類器としては,最近傍法と Regularized Least Squares
Classification (RLSC) を組み合わせた著者推定を行った.100,000ブログユーザに対して
推定実験を行った結果,P@1で20%程度という結果になった.
12
表 2 Narayananらの使用した特徴量([14] Table 1.)
Category Description
Length number of words/characters in post
Vocabulary richness
Yule’s K[21] and frequency of hapax legomena, dis legomena, etc
Word shape frequency of words with different combinations of upper and lower case letters.3
Word length frequency of words that have 1–20 characters
Letters frequency of a to z, ignoring case
Digits frequency of 0 to 9
Punctuation frequency of .?!,;:()"-’
Special characters frequency of other special characters ‘ ˜
@#$%ˆ&*_+=[]{}¥|/<>
Function words frequency of words like ‘the’, ‘of’, and ‘then’
Syntactic category pairs frequency of every pair (A;B), where A is the parent of B in the parse tree
問題点
P@1で20%程度と,精度が不十分であることが挙げられる.IBAによる著者推定タスク
を行う場合,分類器を用いて多クラスの分類を行う形で著者推定を行うため,候補者の数 が多くなればなるほど推定に必要な特徴量の種類が増加してしまうためである.
3 All upper case, all lower case, only first letter upper case, camel case (CamelCase), and everything else.
13
3. 2. 2 Silva らの手法
Silva ら[15]は,マイクロブログであるTwitterに投稿されたメッセージに対する著者推
定手法の提案を行った.Silvaらの提案する著者推定手法においては,メッセージから4種 類の特徴量の取得を行っている.具体的には1) ハッシュタグや使用している短縮URLの 種類,未知語の使用頻度などを特徴量としたQuantitative Markers,2) 顔文字や’LOL’と いった感情表現を特徴量としたMarks of Emotion,3) 感嘆符などの記号を特徴量とした
Punctuation,4) 略語や’e.g.’などの簡略表現を特徴量として用いたAbbreviations の4種
類である.これらの特徴量に対し,Support Vector Machines (SVM) を用いて分類を行う ことで,著者推定を行っている.
問題点
SilvaらはTwitterユーザ3名に対して著者推定実験を行っており,結果としては最大で
もF値で0.63と,十分な精度といえるものではない.また,各候補者に対して学習データ として使用しているメッセージ数は 2,000 件であるため,それ以下のメッセージしか投稿 していないユーザには使用できない.本研究ではできる限り多くの候補者に対して著者推 定を行うことを目的としているため,本研究にSilvaらの手法を応用することは難しい.
3. 2. 3 Schwartz らの手法
Schwartz ら[4]は,マイクロブログに投稿されたメッセージを用いた1,000 人規模での著
者推定を,IBA に基づく著者推定タスクとして行っている.文体定量化手法としては,単
語n-gram頻度分布および文字n-gram頻度分布を取得するとともに,頻出単語n-gramに
よる文法パターンであるFlexible Pattern頻度分布,およびPartial Flexible Patterns頻 度分布を特徴量として用いている.また,分類器にはSupport Vector Machines (SVM) を 用いて著者推定を行っている.50ユーザに対する評価実験の結果,最大で70%以上の精度 での著者推定に成功している.
Flexible Pattern
Flexible Patternは,頻出単語であるhigh frequency words (HFW) とそれ以外の内容語
であるcontent words (CW) の組み合わせで構成される文法パターンである.コーパス中に
含まれる単語数をsとしたとき,HFW は10−4× 𝑠回以上コーパス中に出現する単語であり,
CWは10−3× 𝑠回以下のみコーパス中に出現する単語という定義になっている.また,ひと
つのFlexible Patternは,最低でも1つ以上のCWと,多くとも6つのHFWから構成さ
れる.具体的なFlexible Patternの例と,その例に当てはまる文章を次に示す[4].
14 Flexible Pattern0: 𝑡ℎ𝑒𝐻𝐹𝑊 𝐶𝑊 𝑜𝑓𝐻𝐹𝑊 𝑡ℎ𝑒𝐻𝐹𝑊
Sentence0: Go to 𝑡ℎ𝑒𝐶𝐹𝑊 ℎ𝑜𝑢𝑠𝑒𝐶𝐹𝑊 𝑜𝑓𝐻𝐹𝑊 𝑡ℎ𝑒𝐻𝐹𝑊 rising sun.
Partial Flexible Pattern
Schwartz らは,メッセージに含まれる文章中にFlexible Patternのうち一部が含まれる
場合についても考慮している.具体的には,下記の2つの文章のような場合である[4].
Flexible Pattern0: 𝑡ℎ𝑒𝐻𝐹𝑊 𝐶𝑊 𝑜𝑓𝐻𝐹𝑊 𝑡ℎ𝑒𝐻𝐹𝑊
Sentence1: 𝑇ℎ𝑒𝐻𝐹𝑊 𝑔𝑟𝑒𝑎𝑡𝐻𝐹𝑊 𝑘𝑖𝑛𝑔𝐶𝑊 𝑜𝑓𝐻𝐹𝑊 𝑡ℎ𝑒𝐻𝐹𝑊ring.
Sentence2: 𝑇ℎ𝑒𝐻𝐹𝑊 𝑔𝑜𝑜𝑑𝐻𝐹𝑊 𝑘𝑖𝑛𝑔𝐶𝑊 𝑜𝑓𝐻𝐹𝑊--- Spain.
Sentence 0については上記のFlexible Patternに対し完全にマッチしている.しかし,
Sentence1,2は上記のFlexible Patternのうち一部を含んでいるものの,完全にはマッチ
し て い な い . こ の と き ,Sentencenに 含 ま れ るFlexible Pattern0に つ い て の 特 徴 量 FP(Flexible Pattern0, Sentencen)は , 式(1)の よ う に 表 さ れ る . こ こ で ,𝐶𝑜𝑢𝑛𝑡(𝐻𝐹𝑊)は Sentencenに出現した,Flexible Pattern0とマッチするHFWの数を,𝐶𝑜𝑢𝑛𝑡𝑒𝑥𝑝𝑒𝑐𝑡𝑒𝑑(𝐻𝐹𝑊)は Flexible Pattern0に出現するすべてのHFWの数を示す.
𝐹𝑃(Flexible Pattern0, Sentencen) = 0.5 × 𝐶𝑜𝑢𝑛𝑡(𝐻𝐹𝑊)
𝐶𝑜𝑢𝑛𝑡𝑒𝑥𝑝𝑒𝑐𝑡𝑒𝑑(𝐻𝐹𝑊) (1)
具体的には,FP(Flexible Pattern0, Sentence0) = 1,FP(Flexible Pattern0, Sentence1) =0.5×33 , FP(Flexible Pattern0, Sentence2) =0.5×23 のようになる.
問題点
Schwartzらが70%以上の精度で著者推定に成功した際に,各候補者の学習データセット
として使用したメッセージ数は1,000件である.また,Schwartzらは使用するデータセッ トの条件として,最低でも 1,000 件のメッセージを投稿しているユーザのみを対象として いる.本研究ではできる限り多くの候補者に対して著者推定を行うことを目的としている ため,本研究にSchwartzらの手法を応用することは難しい.
3. 2. 4 IBA による大規模著者推定タスクの問題点
これまで述べてきたIBAによる著者推定手法に共通する問題点として,どの手法も精度が 十分でないことが上げられる.これについては,機械学習を用いる際に問題があることが わかっている.大規模な候補者群に対する著者推定タスクにおいて,IBAの著者推定タスク に基づく著者推定手法では,当該著者推定タスクにおける機械学習が上手く機能しない.
15
具体的には,当該著者推定タスクで扱う学習データが不均衡データとなるために,当該著 者推定タスクにおける機械学習は上手く機能しない[22].そこで,機械学習における不均衡 データの問題に対して,不均衡データを調節する解決案が考えられるが,大規模候補者群 に対する著者推定タスクにおいて当該解決案を講じることはできない.
不均衡データとは,正例と負例の数に極端な差がある学習データを示す.IBAによる著者 推定タスクでは,当該著者推定タスクにおける学習データ中の文章群を,特定の 1 人の候 補者の文章である正例,及び,それ以外の複数候補者の文章である負例の2つに分割する.
しかし,一般に負例を集めることは容易であるが,正例を多く集めることは困難である.
なぜならば,負例で集める文章の著者は特定1人以外の候補者と多数存在するのに対して,
正例で集める文章の著者は特定1人と少ない.このため,IBAにおける著者推定タスクでは,
正例と負例の数に差が生まれ,学習データは不均衡データとなる.
不均衡データが発生する場合に,機械学習が上手くいかないのは,機械学習が不均衡デー タにおける正例か負例における数が多いデータに結果が大きく影響されてしまうためであ る.具体的には,機械学習は正例と負例のデータを用いて分類器を生成するが,当該分類 器は入力されるデータを正例または負例の片方のデータ量が多い方に分類されやすくなる.
つまり,正例または負例が極端に多い場合は,この分類器に入力されたデータのほとんど が,正例または負例の数が多い方に分類されてしまい,分類器の役割を果たさなくなって しまう.よって,この分類器を用いる機械学習は上手くいかない.
不均衡データに対処するため,正例の数に合わせて負例の数を減らしたり,負例の数に 合わせて正例の数を多くしたりする対策が考えられる.しかし,双方の方法は大規模候補 者群に対する著者推定タスクにおいて講じることは難しい.まず,正例の数に合わせて負 例の数を減らす方法では学習が十分にできない問題が生じる.IBAによる著者推定における 機械学習では,正例の特定著者の文体と,当該著者以外の著者の文体とを別々に学習させ,
特定著者の文体を分類器が分別できるようにする.ここで,負例となる特定著者以外の著 者についてそのデータ数を減らすとなると,負例で取り扱う著者数を減らさなくてはなら なくなる.なぜならば,負例の数が多くなる原因は,負例となる文章の著者数が大規模と なるからである.つまり,負例の数を少なくするためには,負例となる文章の著者数を減 らす必要がある.しかし,負例における著者数を減らすと,負例の意味となる特定著者以 外の著者を正確に示すことができなくなる.よって,当該解決案を講じると,負例の意味 がなくなってしまい,機械学習は上手く機能しなくなる.一方で,負例の数に合わせて正 例の数を多くする対策を講じることも難しい.これは,候補者ごとに集められる文章は数 万文字の大量文章でなくてはならないが,このような文章を1人の候補者に対し多く集め ることは困難であるからである.
16
3. 3 PBA による著者推定タスク
PBA による著者推定タスクに用いられる著者推定手法としては,Regal ら[16]の手法,
井上ら[5]の手法がある.これらの従来手法の間では,2. 2. 2項で述べたPBAの著者推定タ スクの手順における,文体定量化方法,及び文体相違度計算方法が異なる.
3. 3. 1 Regal らの手法
Regalら[16]は,short message service (SMS) を用いて送信された文章に対する著者推
定手法の提案を行った.文体定量化手法としては単語n-gram頻度分布を,文体相違度計算
手法にはCosine類似度を用いている.
問題点
Regalらは最大で70名のSMSユーザに対する著者推定手法の提案を行っている.しか
し,各候補者について50件のメッセージを学習データとして用いた場合の推定精度はP@1
で 40%以下であり,十分な推定精度とはいえない.ここで,Regal らの示した実験結果で
は,各候補者につき400件のSMSメッセージを学習データとして用いることで高い推定精 度が得られることが示されている.そのため,Regalらの文体定量化手法では,各メッセー ジから取得する特徴量が不十分であるため,推定精度が低下していることがわかる.そこ で,本稿ではより多くの特徴量を取得する手法を提案する必要がある.
3. 3. 2 井上らの手法
井上ら[5]は,電子掲示板に投稿された文章を用いた10,000人レベルの候補者群に対する 著者推定を,PBA による著者推定タスクに基づいて行っている.文体定量化手法として品 詞タグ・文字混合n-gram頻度分布を,文体相違度計算方法にはピアソンの積率相関係数を 用いている.
文体定量化方法
井上らは,著者推定タスクにおける文体定量化に品詞タグ・文字混合n-gram頻度分布を 用いている.ここで,品詞タグ・文字混合n-gramとは,文章を文字または品詞タグの羅列 に変換したときに,当該羅列中に存在するn個の連続した要素順列を指す.
井上らの手法で用いる文章中の文体定量化は,文章 p 中における品詞タグ・文字混合
n-gram x の生起回数dpxの集合Dpを得ることで行う.文章を文字または品詞タグの羅列に
変換するために以下の手順をとる.まず,形態素解析器を用いて文章を形態素に分割する.
次に,「動詞」「接続詞」「記号」「副詞」「形容詞」「感動詞」「未知語」の形態素については,
文字列をそのまま採用し,これら 6 種類の品詞以外について品詞タグを用いる.井上らは
17
この文体定量化手法を用いることで,話題が異なるデータセット間であっても頑健な著者 推定手法を作成した.
文体相違度計算方法
井上らが提案する著者推定タスクにおける文体相違度計算では,文章 pおよびq につい てのDp, Dqだけではなく, 𝐶𝑝𝑞および𝑎𝑝を用いる. Cpqは,文章pと文章qの各々に存在す るすべての品詞タグ・文字混合n-gramの和集合である.apは,文章pを構成する記事の数 である.記事とは,マイクロブログにおける 1 件のメッセージのように,一度に投稿する 文のまとまりを指す.井上らは𝐶𝑝𝑞, 𝐷𝑝および𝐷𝑝を用いることで,2つの文章p, qにおける 文体相違度Dissimposを以下のように定義している.
𝐷𝑖𝑠𝑠𝑖𝑚𝑝𝑜𝑠(𝑝, 𝑞) =√∑𝑖∈𝐶𝑝𝑞(𝑓𝑝𝑖− 𝑓̅̅̅̅)𝑝𝑞 2√∑𝑖∈𝐶𝑝𝑞(𝑓𝑞𝑖− 𝑓̅̅̅̅)𝑞𝑝 2
∑𝑖∈𝐶𝑝𝑞(𝑓𝑝𝑖− 𝑓̅̅̅̅)(𝑓𝑝𝑞 𝑞𝑖− 𝑓̅̅̅̅)𝑞𝑝 (2) 𝑓𝑝𝑞
̅̅̅̅ = ∑𝑖∈𝐶𝑝𝑞𝑓𝑝𝑖
|𝐶𝑝𝑞| (3)
𝑓𝑝𝑖= {0.4 (𝑓𝑝𝑖′ > 0.4)
𝑓𝑝𝑖′ (𝑓𝑝𝑖′ ≤ 0.4) (4)
𝑓𝑝𝑖′ =𝑑𝑝𝑖
𝑎𝑝 (5)
文体相違度Dissimposはその値が小さいほど2つの文章p, qの文体が似ていることを表す.
問題点
井上らの手法をTwitterに投稿されたメッセージでの著者推定に応用する場合,使用する データセットの性質の違いによる問題が発生する.具体的には以下のような問題点が想定 される.
1. 推定に用いる文章の口語化 2. 同一話題収集困難化
1つ目の問題点についてであるが,Twitterに投稿されるメッセージは電子掲示板に投稿 される文章に比べ,Twitter特有の表現が散見されるため,文体定量化の際に行う形態素の 分割精度が低下するという問題である.本稿で推定対象としているTwitterに投稿されるメ ッセージには,140字という文字数制限が存在する.その性質上,マイクロブログはチャッ トのようなリアルタイムコミュニケーションとして使用されることも多く,投稿内容の着 想から投稿を行うまでのタイムラグが少ない.そのため,Twitterに投稿されるメッセージ は,文法の整った文章だけでなく,Twitter特有の文法を持つ文章も多く存在する.それゆ えに,これまでの著者推定研究の対象にされてきた文章とは,文体や品詞分布が大きく異 なる.そこで,そういったTwitter特有の文法を除去し,文法の整った文章に近づけること が必要となってくる.
2つ目の問題点については,推定対象文章,および各候補者の学習データセット内に含ま
18
れる話題が統一されないといった問題である.先に述べたように,本稿で推定対象として いるTwitterに投稿されるメッセージには,140字という文字数制限が存在する.そのため,
井上らの研究において使用された電子掲示板へ投稿される文章に比べ,一度に投稿される 文章が非常に短い.そのため,1つのメッセージのみを用いて著者推定を行う場合,特徴量 が不十分になるため推定精度が非常に低くなる.そこで,著者推定タスクに基づく著者推 定を行う場合,推定対象文章および各候補者の学習データとなる文章は,投稿時刻の異な る複数のメッセージから構成されることとなる.しかし,Twitterをはじめとするマイクロ ブログは通常のブログなどと異なり,一度に同一の話題について大量のメッセージの投稿 を行うユーザはそれほど存在しない.それゆえに,推定対象文章および各候補者の学習デ ータとなる文章は,それぞれ話題の異なるメッセージで構成されることとなる.
井上らの手法においては,推定対象文章および各候補者の学習データとなる文章は,推 定対象文章と学習データセット間では異なる話題であるが,推定対象文章および各候補者 の学習データで採用されている文章は,それぞれ同一の話題で統一されている.そこで,
本稿で提案する著者推定手法においては,より豊富な話題で構成されるデータセットに対 しても頑健な文体定量化手法を採用する必要がある.
3. 4 従来手法のまとめ
まとめ
本章で述べた従来の著者推定手法は,文学的知見に基づく方法とテキストマイニングに 基づく方法に2分することができた.また,テキストマイニングに基づく著者推定手法によ って,IBAまたはPBAによる著者推定タスクを行うかで,さらに2分することができた.
文学的知見に基づく著者推定手法では,著者推定手法ごとに異なる経験則に基づいて文体 的指標の選択が行われていた.当該著者推定手法では,著者推定の対象となる文章に現れ る,著者推定手法ごとに異なる文体的指標に対する定量化を行うことで,定量的な著者推 定を実現していた.当該手法による著者推定は,文学的知見に基づく正確な根拠による著 者推定が行えているが,計算機で扱うことができないほど複雑な文体の定量化が必要とな ってしまう.
IBAまたはPBAによる著者推定手法は,文体的量化,機械学習の方法,文体相違度計算 方法を表 3または表 4のように変化させることで,多様な著者推定の方法を実現できてい る.これらの手法は文学的知見に基づく著者推定手法を用いるために必要であった深い文 学的知見を用いることなく,機械的な著者推定が実現できている.つまり当該手法は,IBA またはPBAによる著者推定タスクに一般化した上で,計算機で実装可能となる.
問題点
19
既存手法を本研究に応用する場合,次の3点に対応しなくてはならない.
1. IBAに基づく著者推定手法は大規模候補者群に対する著者推定手法には不向き 2. 精度向上のため,短文からより多くの特徴量を取得する必要がある
3. 多種多様な話題に対し頑健な著者推定手法の提案
表 3 IBAに基づく著者推定手法
著者推定手法 文体定量化方法 分類器作成のために用いる機械学習
Narayananら[14] 表 2 に示した特徴量の頻度
分布
最 近 傍 法 と Regularized Least Squares Classification (RLSC)
Silvaら[15] 感情表現などの頻度分布 SVM
Schwarzら[4] 文字n-gram,単語n-gram,
Flexible Pattern
SVM
表 4 PBAに基づく著者推定手法
著者推定手法 文体定量化方法 文体相違度計算方法
Regalら[16] 単語n-gram頻度分布 Cosine類似度
井上ら[5] 品詞タグ・文字混合n-gram頻度分布 ピアソンの積率相関係数
20
第 4 章 マイクロブログに対応した著者推定手法
本章では,第3章で述べた既存の著者推定手法に存在する問題点に対応した,PBAの著 者推定タスクに用いられる著者推定手法の提案を行う.はじめに,4. 1節で提案手法の概要 を述べ,次に4. 2節以降で詳細を述べる.
4. 1 概要
3. 4節で述べたように,これまでの著者推定手法を本研究に応用するためには,以下の条 件を満たす必要が存在する.
1. 短文からより多くの特徴量を取得する
2. 多種多様な話題に対応したデータセット作成手法
そこで,文字n-gramの複数併用により特徴量を増加させつつ,推定対象文章が含む話題 に類似した話題分布を持つ学習データセットを適切に作成することで,より推定精度を向 上する手法について述べる.具体的には,予め推定に使用するすべてのメッセージに対し,
Twitter特有の表現である叫喚フレーズの正規化を施す.次に,候補者となるユーザの投稿
したツイート全てを用いてk個の学習データセットを作成し, k-means法を用いてクラス タリングを行うことで,含有する特徴量分布の異なるデータセットを選択する.また学習 データセット作成の際,メッセージから取得するn-gramのnに応じた重み付けを行うこと により,より著者の文体を表す特徴量を取得する.
作成した学習データセットとテストデータセットの間で文体相違度DissimTopの計算を行 う.全候補者の学習データセットとテストデータセットの間で文体相違度DissimTopの計算 を終了したのち,それらの文体相違度DissimTopを昇順に並べ替えることで,ランキングの 作成を行う.このランキングのうち,推定対象著者が何位以内に含まれているかどうかを 用いて著者推定の成否を決定する.
提案手法により,各ユーザの持つ学習データセット全てが互いに異なる話題分布をもち,
推定対象文章に含まれる話題と類似する学習データセットを作成できる可能性が高くなる ため,精度向上が実現できると考えられる.提案手法の概要図を図 3に示す.
21
図 3 提案手法の概要図
4. 2 叫喚ツイートの除去
3. 3. 2項で説明したマイクロブログ特有の表現を除去するため,マイクロブログ特有の
表現の1つである「叫喚フレーズ」を正規化する手法をここで述べる.我々は,浅井ら[23]
が提案した,マイクロブログ上で投稿される突発的な感情を表わす「叫喚フレーズ」と呼 ばれる表現に着目し,それらの表現を除去することによる推定精度向上を試みた.
叫喚フレーズは以下のように定義される.
語尾の母音が3回以上繰り返して付加される
母音は大文字,小文字を区別しない
母音はひらがな,カタカナの大小文字すべて
この定義から,我々は以下の正規表現に基づいて,叫喚フレーズの含まれるメッセージ の正規化を行った.
[あ|ぁ|ア|ァ]{3,}|[い|ぃ|イ|ィ]{3,}|[う|ぅ|ウ|ゥ]{3,}|[え|ぇ|エ| ェ]{3,}|[お|ぉ|オ|ォ]{3,}
具体的には,以下の手順のようになる.
1. 叫喚フレーズの含まれる文章を,本項で説明した正規表現を用いて抽出する.
例) うわあぁあどうしようぅうぅう 2. 繰り返される母音を大文字化する.
例) うわあああどうしよううううう
3. すべての繰り返される母音部分に対して,母音一文字とそれ以前の文字列を削除する.
例) うわあどうしよう
22
4. 3 メッセージからの特徴量取得
3. 3. 2項で記述したように,既存の著者推定手法で用いているn-gramでは,140字以下
の短文である各メッセージから十分な特徴量を取得することができていない.そこで,以 下の2つの手法を用いて推定精度の向上を図る.
1. 複数併用文字 {1,2,3}-gram
2. 重み付きn-gram頻度分布
1については,メッセージから特徴量として取得する文字n-gramについて,nを変化さ せて複数併用することで,特徴量を増加させる手法である.具体的には,メッセージから
文字1-gram,文字2-gram,文字3-gramの取得を行う.この複数併用文字n-gramについ
て,以降は文字 {1,2,3}-gramと表すこととする.
また,本研究では文字n-gram頻度分布を利用して,メッセージから特徴量を取得する.
我々の文体定量化手法は3. 3. 2項で説明した井上ら[5]の手法をベースにしている.しかし,
井上らの文体定量化手法である品詞タグ・文字混合n-gramについては,相違話題に対する 頑健性を持たせるために使用している手法である.しかし,我々の提案手法である多様な 話題に対応するデータセット作成手法を用いることで,推定対象文章と学習データ間での 話題分布の差異が小さくすることができる.そのため,推定対象文章と学習データセット 間での著者推定について,同一話題とみなして推定を行うことができる.同一話題である
場合,3. 3. 2項で説明した品詞タグ・文字混合n-gram頻度分布を用いるより,文字n-gram
を用いることで特徴量をより多く取得できる.そこで,本稿では文体定量化手法に文字 {1,2,3}-gramを採用した.
2については,取得した各n-gramについて,nの大きさに比例して重み付けを行う手法 である.また,一般に文章からn-gramの取得を行う場合,n-gramのnが大きくなるほど 頻度は小さくなる.しかし,文字n-gramのnが大きい場合,著者の特徴となる未知語をそ のまま素性として取得できる可能性が高い.そこで,n-gramのnに応じて,当該n-gram の出現頻度を大きくする手法を提案する.具体的には以下の手順に従う.また,具体例を 図 4に示す.
step 1. ユーザunが投稿したメッセージtに対し,4. 2節で述べた叫喚フレーズの正規化を
行う.
step 2. メッセージtから文字 {1,2,3}-gramを取得し,x⃗⃗⃗⃗⃗⃗ unを作成する.
step 3. x⃗⃗⃗⃗⃗⃗ unに含まれる各要素に対し,n-gramのnに応じて3n倍を行う.
step 4. 3. 3. 2項で説明した式(4)および式(5)に基づき,各特徴量の正規化を行う.
23
図 4 メッセージからの特徴量取得
4. 4 コサイン類似度を用いた文体相違度計算方法
文体相違度計算手法については,3. 3. 2項で説明した井上らの手法を踏襲する.ただし,
井上らはピアソンの積率相関係数を用いているが,本稿ではコサイン類似度を用いる.理 由として,我々の研究で扱うマイクロブログに投稿されたメッセージは短文であるため,
テストデータセットと学習データセットの間で重複する特徴量が少なくなる.そのため,
井上らの研究で扱った電子掲示板に投稿された文章を扱う場合と比べ,文体相違度計算の 際にテストデータセットと学習データセットの間で重複する特徴量がより重要になる.そ こで,2つのデータセット間で重複する特徴量のみを考慮するコサイン類似度を用いること で,より2つのデータセット間の差異を際立たせられるのではないかと考えたためである.
具体的には,以下の手順に従う.ここで,文体相違度計算の対象となるテストデータセ ットPおよび学習データセットQは,それぞれメッセージtをk件含む集合を表す.
1. テストデータセットP={tp,1, tp,2, … , 𝑡𝑝,k}および学習データセットQ={tq,1, tq,2, … , 𝑡𝑞,k}に 含まれるす べてのメッセージから 文字 {1,2,3}-gram を取得する.取得した字 {1,2,3}-gramの集合を𝐶𝑝𝑞と表現する.
2. テストデータセット P に含まれるすべてのメッセージから,𝐶𝑝𝑞に含まれるすべての 文字{1,2,3}-gram の生起回数を取得する.これを𝑫𝒑= {𝒅𝒑𝟏, 𝒅𝒑𝟐, … , 𝒅𝒑|𝐶𝑝𝑞| }と表現す る.Pに含まれていない文字{1,2,3}-gramについては,生起回数を0とする.
3. 学習データセットQに含まれるすべてのメッセージついても2と同様に,𝐶𝑝𝑞に含ま れ る す べ て の 文 字{1,2,3}-gram の 生 起 回 数 を 取 得 す る . こ れ を𝑫𝒒= {𝒅𝒒𝟏, 𝒅𝒒𝟐, … , 𝒅𝒒|𝐶𝑝𝑞|}と表現する.Q に含まれていない文字{1,2,3}-gram については,
生起回数を0とする.
24
4. k, 𝐶𝑝𝑞, 𝑫𝒑および𝑫𝒑を用いて,2つのデータセットP, Qにおける文体相違度Dissimcosに ついて,式(6)を用いて計算する.
𝐷𝑖𝑠𝑠𝑖𝑚𝑐𝑜𝑠(𝑃, 𝑄) =√∑𝑖∈𝐶𝑝𝑞(𝑓𝑝𝑖)2√∑𝑖∈𝐶𝑝𝑞(𝑓𝑞𝑖)2
∑𝑖∈𝐶𝑝𝑞𝑓𝑝𝑖∙ 𝑓𝑞𝑖 (6)
𝑓𝑝𝑖= {0.4 (𝑓𝑝𝑖′ > 0.4)
𝑓𝑝𝑖′ (𝑓𝑝𝑖′ ≤ 0.4) (7)
𝑓𝑝𝑖′ =𝑑𝑝𝑖
k (8)
文体相違度Dissimcos(𝑃, 𝑄)はその値が小さいほど2つのデータセットP, Qに含まれるメ ッセージの文体が似ていることを表す.ここで,式(7)で用いる 0.4 という上限については 井上ら[5]が経験的に決定したパラメータである.
4. 5 多様な話題に対応するデータセット作成
3. 3. 2項において,Twitterのメッセージに対する著者推定を行う場合,各データセット
に含まれるメッセージの話題を統一することができないという問題を述べた. 3. 3. 2項で 説明したように,井上らの手法[5]を用いてマイクロブログユーザに対する著者推定を行う 場合,テストデータセットおよび学習データセットを構築するメッセージの話題は統一さ れない.そのため,文体相違度の計算を行う際に用いるテストデータセットと学習データ セットは,異なる話題分布を持つと考えるのが自然である.しかし,井上らの研究[5]から,
相違話題間での著者推定は推定精度が低下することがわかっている.そこで,学習データ セットを複数作成することで,よりテストデータセットに類似する話題分布をもつ学習デ ータセットを選定することができれば,実質的に同一話題での著者推定を行うことができ,
推定精度の上昇が可能になると考えた.そこで,我々は各候補者につき複数の学習データ セットを作成し,そこから推定対象文章と類似する学習データセットを選択することで,
実質的に同一話題間での著者推定を行う手法を提案する.
複数の学習データセットおよびテストデータセットを作成する手順を以下に示す.ここで,
収集した全てのメッセージを𝐷𝑎𝑙𝑙= {𝑚1, … , 𝑚𝑠}とする.同様に,収拾した全てのユーザ ID 集合をUIDall= {𝑢1, … , 𝑢𝑟}とする.また,各ユーザについてのテストデータ及び学習データ セットを作成する際に用いるメッセージ数をkとする.さらに,ここではn名に対する著 者推定タスクを行うものとする.
step 1. ユーザID集合をUIDとし,UID=∅とする.
step 2. UIDallから,ランダムに1つのユーザID 𝑢𝑖を抽出し,step3からstep 9を適用し
![表 2 Narayanan らの使用した特徴量([14] Table 1.)](https://thumb-ap.123doks.com/thumbv2/123deta/9853570.1898470/16.892.115.777.131.919/表2Narayananらの使用した特徴量14Table1.webp)