九州大学学術情報リポジトリ
Kyushu University Institutional Repository
カーネル平滑化統計量に基づくノンパラメトリック 推測
森山, 卓
https://doi.org/10.15017/1931731
出版情報:Kyushu University, 2017, 博士(数理学), 課程博士 バージョン:
権利関係:
Nonparametric inference based on kernel smoothed statistics
Doctoral dissertation
Taku MORIYAMA
Graduate School of Mathematics, Kyushu University 744 Motooka, Nishi-ku, Fukuoka 819-0395, Japan
February 14, 2018
Abstract
We consider nonparametric inference based on ‘kernel smoothed’ statistics. Nonparamet- ric methods can handle data from unspecified distributions, which is called as ‘robust’ to model assumptions. An empirical distribution function estimator and a histogram density estimator are known as classical estimators, but they are not continuous as functions of ob- served values.
Kernel type nonparametric estimators have their origin in Rosenblatt (1956) who obtained a (one-dimensional) kernel type density estimator by smoothing the histogram density es- timator. The kernel smoothing method has been widely applied, and various smoothed nonparametric statistics were proposed. However, some problems which kernel type statis- tics own are reported. Their asymptotic convergence rates depend on smoothing parameters.
In addition, optimal convergence rates of most kernel type estimators are (uniformly) slower than that of ‘parametric’ estimators in general settings.
We first focus on kernel type estimation of a hazard ratio function and then discuss reduction of an asymptotic mean squared error of kernel hazard ratio estimators. The hazard ratio is a fundamental measure in survival analysis and risk management. We obtain a new kernel hazard ratio estimator by modifying ´Cwik and Mielniczuk (1989)’s method, and its asymptotic properties are examined. The proposed method gives precise estimation especially in exponential or gamma cases, which play a central role in survival analysis.
Next, we discuss the so-called ‘boundary bias problem’ in naive kernel density estimation introduced by Rosenblatt (1956). In naive kernel estimation of a probability density, it is implicitly assumed that the support of the density function covers the whole real line. If the assumption does not hold, the kernel density estimator possibly has a boundary bias.
Therefore, we should also take care with an unexpected boundary bias when the ‘exact’
support is unknown.
As the second theme of this thesis, we study the boundary bias problem in such case.
We propose a new method for simultaneous nonparametric estimation of the probability density and its support. The proposed method detects the boundary and returns a modified density estimator which is free from the unexpected boundary bias. Moreover, we discuss an extension to a simple multivariate case and propose a new method for estimating joint probability density functions.
Lastly, we consider application of the kernel smoothing method to statistical hypothesis testing. For the one sample location problem, the sign and Wilcoxon’s signed rank tests are distribution-free, but the two tests have a problem with their p-values because of their discreteness. We confirm the problem and propose two tests which are obtained by smoothing the discrete test statistics. The proposed tests can solve the problem of thep-values, and we derive asymptotic properties of the smoothed tests. The smoothed tests are equivalent to
the discrete ones in the sense of Pitman’s asymptotic efficacy respectively, and the proposed tests are higher-order asymptotically robust to model assumptions (that is, distribution-free) if the kernel functions and smoothing parameters are suitably selected. Thus, the smoothed tests inherit good properties of the original tests.
Moreover, for the two sample case, we show that the median and Wilcoxon’s rank sum tests have the same problem with their p-values. The median and Wilcoxon’s rank sum tests can be seen as two-sample versions of the sign and Wilcoxon’s signed rank tests respectively, and we propose smoothed tests which solve the problem in a similar manner. We obtain local asymptotic powers of the proposed tests and examine approximations of their p-values.
Acknowledgement
I would like to express my sincere gratitude to my supervisor Professor Yoshihiko Maesono for his guidance, valuable suggestions and kind support for my research.
I am grateful to Professor Ryuei Nishii, Professor Hiroki Masuda, Professor Yoshiyuki Ninomiya, and Professor Kei Hirose for their valuable comments which helped me to improve my research.
I would like to thank my friends for daily discussions. We have discussed a lot of interests, which encouraged me.
Finally, I want to thank my family for supporting me throughout all my studies at Kyushu University.
Taku Moriyama February 14, 2018
Contents
1 Introduction 5
2 Kernel hazard ratio estimators and numerical comparison 9
2.1 Introduction . . . 9
2.2 Kernel type hazard ratio estimators and asymptotic properties . . . 10
2.3 Comparison of kernel hazard estimators . . . 13
2.4 Appendices: Some Proofs . . . 18
3 Kernel density estimation free from unexpected boundary bias 23 3.1 Introduction . . . 23
3.2 Boundary bias reduction methods . . . 25
3.3 Kernel density estimation free from unexpected boundary bias . . . 26
3.4 Simulation study . . . 31
3.5 Extension to a simple multivariate case . . . 35
3.6 Appendices: Some proofs . . . 41
4 Improvement of one-sample distribution-free tests by kernel smoothing 44 4.1 Introduction . . . 44
4.2 Properties of the sign and Wilcoxon’s signed rank tests . . . 44
4.3 Smoothed sign and Wilcoxon’s signed rank tests and properties . . . 46
4.4 Selection of bandwidth and kernel function . . . 50
4.5 Higher order approximation . . . 52
4.6 Appendices: Some proofs . . . 55
5 Improvement of two-sample distribution-free tests by kernel smoothing 57 5.1 Introduction . . . 57
5.2 Properties of the median and Wilcoxon’s rank sum tests . . . 58
5.3 Smoothed median test and properties . . . 61
5.4 Smoothed Wilcoxon’s rank sum test and properties . . . 65
5.5 Simulation study of significance probability and local power . . . 68
5.6 Real life examples and conclusion . . . 73
5.7 Appendices: Some proofs . . . 74
6 Conclusion and Future work 83
1 Introduction
In traditional statistical inference, ‘parametric’ methods have been widely used in our deci- sion making. Parametric methods infer a finite number of parameters (e.g. the mean and variance) which index specified statistical structures. Now, we consider to infer a function p (e.g. probability density, hazard ratio, conditional density, regression function etc.) from data. Though a functional space P, which includes p, is infinite dimensional, the obtained sample size is always finite. Therefore, it seems to be natural to restrict the space P to a finite dimensional one Pθ ={pθ|θ ∈ Θ} (called parametric family) indexed by a parameter θ. Then, we do statistical inference for the parameter θ which is of our interest (paramet- ric method). In estimation of an underlying density function, we usually assume that the probability density belongs to a family of specified distributions (e.g. normal distributions).
Exponential family are known as a wide class and used to describe various random behaviors.
Parametric estimators (e.g. maximum likelihood estimator) may be ‘√
n-consistent’, which is usually an optimum rate in general settings. In statistical testing for a underlying struc- ture, not ‘approximate’ (or ‘asymptotic’) but ‘exact’ p-values of parametric test statistics may available, by specifying the structure under the null hypothesis. That is why parametric methods have gotten both researchers’ and practitioners’ attentions.
However, in both statistical estimation and testing, parametric methods work well if and only if the true function p belongs to the parametrized family Pθ. This means that the parametric function estimator pbθ, which is obtained by replacing θ with an estimated θ,b never converge to pin an ordinary sense whenp /∈Pθ. ‘Nonparametric’ methods restrict P to not finite but ‘infinite’ dimensional spaces. In other words, we do not make any restrictive assumptions about the class of the true function p. In hypothesis testing, this is often called as being ‘robust’ to model assumptions or ‘distribution-free’. The good property is needed to control ‘type I error’ especially when parametric classes of the underlying distribution cannot be specified.
Let X1,· · · , Xn be independently and identically distributed (i.i.d.) random variables with a distribution function F and f denotes the corresponding probability density function.
Unless stated, all observed values are scalar, and the support of each probability density func- tion covers the whole real line (that is,supp(f) = R). Traditionally, an empirical distribution function estimatorFnis well-known as a nonparametric estimator of the distribution function F. Random phenomena are described uniquely by their probability distribution functions, and so estimation of the distribution functions gives us much information. For example, a population mean defined by E[X] = ∫
xf(x)dx can be estimated by E[X] =[ ∫
xdFn(x), where the integral is a Riemann-Stieltjes integral. In fact, E[X] coincides with a sample[ mean ¯X =n−1∑n
i=1Xi. The assumption which ensures the asymptotic convergence of Fn is much weak (see Yamato (1973)), however, the estimated distribution function is not contin- uous. In addition, we cannot obtain any smooth density estimators by differentiating Fn. A
histogram estimator is known as a conventional density estimator given by fn(x) = 1
mn
∑n i=1
∑
j∈Z
I(x∈Lj)I(Xi ∈Lj),
where I is the indicator function I(A) = 1 (if A occurs), = 0 (if A fails). Lj = [a0 + (j − 1)m, a0+jm) anda0 is a selected origin. However, the density estimatorfnis not continuous.
By smoothing the histogram estimator, Rosenblatt (1956) obtained a smooth nonparamet- ric estimator of the probability density function f. This is called as kernel density estimator and given by
f(x) =b
∫ k
(x−y h
)
dFn(y),
wherekis a probability density function and called as kernel function. The smoothing param- eter h is called as bandwidth and satisfies bothh→0 andnh→ ∞(asn → ∞). Properties of the kernel density estimator have been investigated well, and Tsybakov (2009) gives a good introduction of them. A smooth kernel estimator Fb of the cumulative distribution function was derived by smoothing the empirical distribution function Fn, and the kernel smoothing method has been widely applied to traditional discrete nonparametric statistics.
Although various kernel smoothed statistics are proposed, most of them are not √ n- consistent. For example, an optimal asymptotic convergence rate of the kernel density esti- mator fbis of order n−2/5. In Chapter 2, we discuss improvement of a naive kernel estimator of a hazard ratio in the sense of a mean squared error (M SE). The hazard ratio function is a fundamental measure of the difference between several risk groups and given by
H(x) = f(x) 1−F(x).
By replacing F andf with the kernel estimatorsFb andfbrespectively, the naive kernel type estimator He was obtained. The optimal asymptotic convergence rate of the naive estimator is generally dominated by the numerator fb and coincides with that of fb. By modifying Cwik and Mielniczuk (1989)’s method, we obtain a new kernel hazard ratio estimator´ Hb and examine its asymptotic properties. Moreover, we compare the proposed estimatorHb with He in the sense of an asymptotic mean squared error (AM SE). Indeed, the optimal convergence rate of AM SE ofHb is not different from that of the naive estimatorH. However, it is showne that Hb performs asymptotically better, especially in exponential or gamma cases, which are important in survival analysis.
In Chapter 3, we focus on the so-called ‘boundary bias’ problem in naive kernel density estimation introduced by Rosenblatt (1956). To ensure the consistency of the density es- timator fb, in fact, it is implicitly assumed that the support of the underlying probability density covers the whole real line (that is, supp(f) = R). When the obtained sample are
(d-dimensional) multivariate, it is supposed that the support covers the whole space (Rd).
However, when the assumption does not hold, the kernel density estimator fbpossibly loses its consistency near the boundary of the support, on account of a boundary bias of order 1 (boundary bias problem). If we know the support ‘exactly’, we may reduce the bias by applying boundary bias reduction methods.
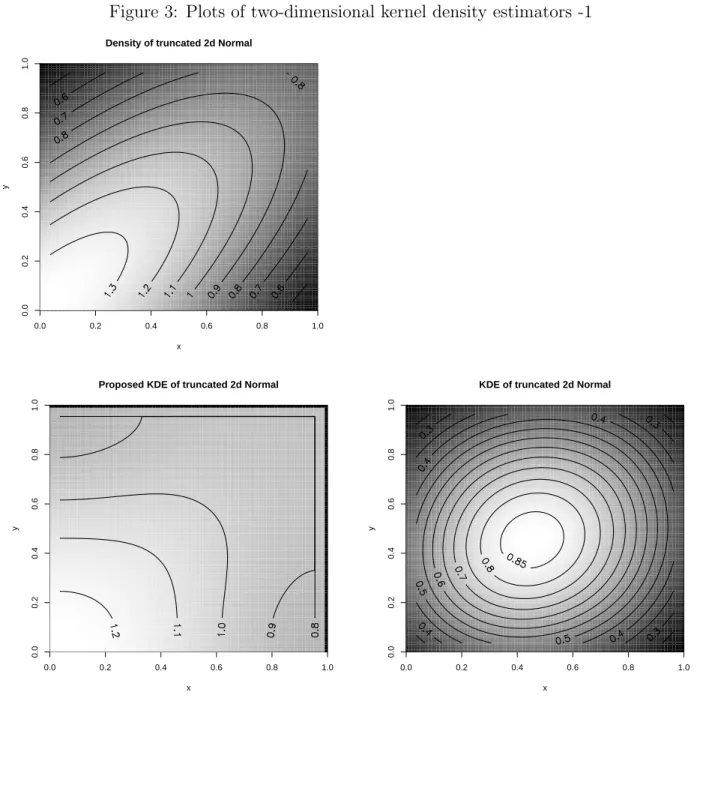
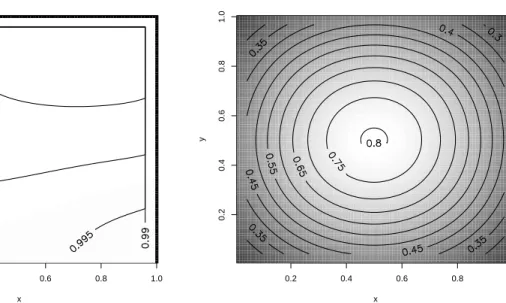
When the support is unknown, the kernel density estimatorfbpossibly has an unexpected boundary bias. We insist on the necessity of estimating the support and propose a new method for nonparametric density estimation which is free from the unexpected boundary bias in such case. The proposed method detects the boundary and gives a modified density estimator simultaneously. As mentioned by Hall and Park (2002), it is natural to estimate the support by the sample maximum (and minimum) and modify the naive kernel density estimator. However, it is shown that the proposed method gives numerically precise density estimation in the boundary region when the support is unknown. Moreover, we discuss an extension to a simple multivariate case and propose a new method for estimating joint probability density functions. By utilizing nonparametric copula estimators, the proposed method combines marginal densities, which are estimated by the proposed single variable method (in one-dimensional cases), and then returns a modified joint probability density estimator. It is shown that the obtained density estimator is also free from an unexpected boundary bias when the support of the underlying joint density cannot be specified.
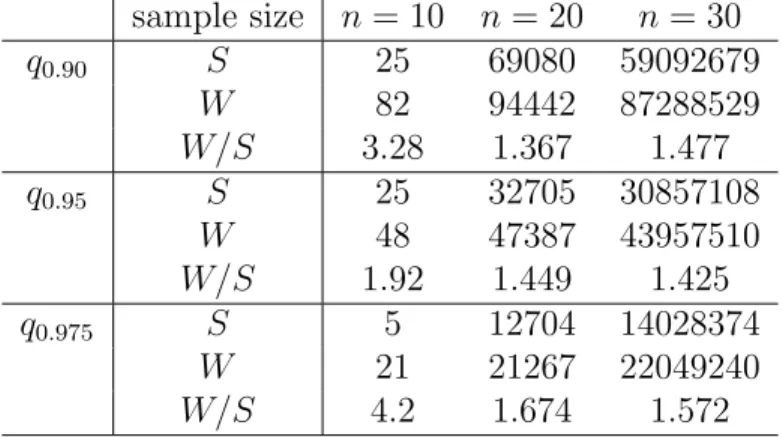
In Chapter 4, we consider application of the kernel smoothing method to (discrete) distribution-free test statistics and focus on the sign and Wilcoxon’s signed rank tests in the one-sample location problem. As pointed out by Lehmann and D’abrera (2006) and Brown et al. (2001), p-values of the sign test statistic may make a big jump in response to a change in data values especially when the obtained sample size is small. Because of this, p-values of the sign test are frequently larger than those of the Wilcoxon’s test, and so the discrete tests may allow us to make an arbitrary choice of the two tests.
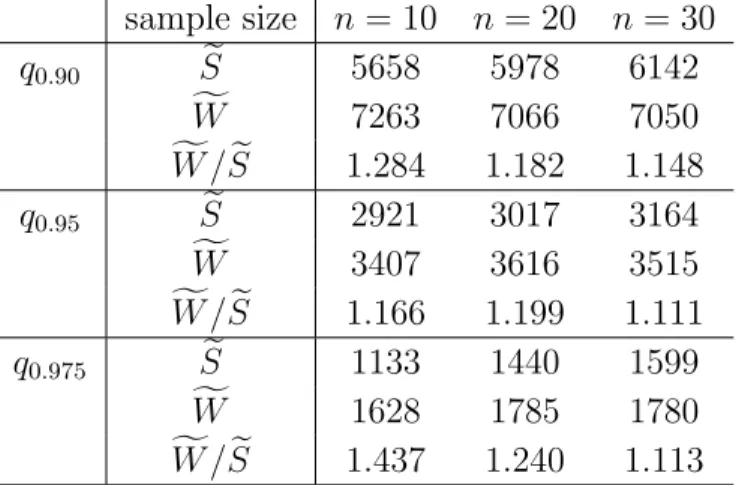
We first confirm this problem of the p-values and then propose new smoothed sign and Wilcoxon’s signed rank tests. The original sign S and Wilcoxon’s signed rank test statistics W are equivalent to estimators of the probabilities P[X1 >0] andP[X1+X2 2 >0] respectively, and the smoothed test statistics Se and fW are equivalent to kernel type estimators of each probabilities. We show that the smoothed tests can solve the problem of the p-values and examine asymptotic properties of the smoothed tests. The smoothed sign and Wilcoxon’s signed rank tests are equivalent to the discrete two in the sense of Pitman’s asymptotic ef- ficacy, respectively. In addition, it is shown that each difference between the standardized S and S, ande W and Wf converges to zero in L2-norm, respectively. We also discuss ap- proximations of their p-values. To derive higher-order approximations of the p-values of the smoothed tests, Edgeworth expansions are obtained. Under some conditions, the Edgeworth expansions are free of the underlying distribution, that is, the smoothed tests are higher-order asymptotically distribution-free.
In the last Chapter, we consider application of the kernel smoothing method to the median and Wilcoxon’s rank sum tests in the two-sample location problem, in a similar manner as Chapter 4. The median and Wilcoxon’s test statistics can be seen as equivalent to estimators of the probabilitiesP[Y1−z0 >0] and P[Y1−X2 >0] respectively, where z0 is the median of the underlying distribution of X2. The test statistics can also be seen as two-sample versions of the sign and Wilcoxon’s signed rank tests, and we show that the median and Wilcoxon’s rank sum tests have the same problem with theirp-values. We propose smoothed tests, which inherit good properties of the original tests, and then show that the smoothed tests can solve the problem of thep-values. In addition, approximations of the smoothed tests’p-values and their local asymptotic powers are examined.
2 Kernel hazard ratio estimators and numerical com- parison
2.1 Introduction
Rosenblatt (1956) proposed a kernel estimator of the probability density function f. Many researchers have since developed various kernel estimators for distributions, regression, haz- ard functions, etc. Most of the kernel estimators are biased, and many researchers have studied methods of reducing the bias. These methods are based on higher order kernels, transformations of estimators, etc. Although there are many bias reduction methods, vari- ance reduction is quite difficult. To estimate the density ratio, ´Cwik and Mielniczuk (1989) proposed a kernel estimator that they called ‘direct’. The asymptotic mean squared error (AM SE) of the direct estimator is different from the AM SE of the naive estimator. In this Chapter, we devise a ‘direct’ estimator of the hazard ratio by modifying ´Cwik and Mielniczuk (1989)’s method, and discuss its AM SE.
First, we will describe the direct estimator of the density ratio proposed by ´Cwik and Mielniczuk (1989). Let X1, X2,· · · , Xn be independently and identically distributed (i.i.d.) random variables with a distribution functionF, andY1, Y2,· · · , Ynbei.i.d.random variables with a distribution functionG. f andg are the density functions ofF and G, and we assume that g(x0)̸= 0 (x0 ∈R). A naive estimator of the density ratio f(x0)/g(x0) at the point x0 is given by fb(x0)/bg(x0) where
fb(x0) = 1 h
∫ ∞
−∞
k
(x0−w h
)
dFn(w) and
b
g(x0) = 1 h
∫ ∞
−∞
k
(x0−z h
)
dGn(z).
k is a kernel function,h is a bandwidth that satisfies h→0 and nh→ ∞ (n→ ∞), and Fn and Gn are the empirical distribution functions of X1,· · ·, Xn and Y1,· · · , Yn, respectively.
We call f(xb 0)/bg(x0) an ‘indirect’ estimator. ´Cwik and Mielniczuk (1989) proposed a direct estimator, given by
bf
g(x0) = 1 h
∫ ∞
−∞
k
(Gn(x0)−Gn(w) h
)
dFn(w).
Chen et al. (2009) obtained an explicit form of its AM SE.
In this chapter, we develop a new ‘direct’ estimator of the hazard ratio function by modifying ´Cwik and Mielniczuk (1989)’s method and investigate itsAM SE (in Section 2.2).
We compare the naive and direct kernel estimators (in Section 2.3) and find that our direct estimator performs asymptotically better especially in exponential or gamma cases, which play a central role in survival analysis. Although the bias term of the direct estimator is
large in some cases, the asymptotic variance is always small when we use same bandwidth parameters. Proofs of the theorems herein are given in Section 2.4.
2.2 Kernel type hazard ratio estimators and asymptotic properties
The hazard ratio function is a type of relative risk and is defined as H(x0) = f(x0)
1−F(x0).
The meaning of H(x)dx is the conditional probability of ‘death’ in [x, x+dx] given survival to x, and this is a fundamental measure of the difference between several risk groups. The hazard ratio also uniquely determines the ‘survival function’, as follows:
S(x) =exp (∫ x
−∞
H(u)du )
,
which gives the probability that a person survives longer thanx. These estimators have been extensively discussed over the years, and the Kaplan-Meier and Nelson-Aalen estimators are widely known. Though they are discrete, we can construct a smoothed hazard estimator by using the kernel method. If there is no censoring, the smoothed hazard estimator coincides with the naive estimator, which we will define later.
The estimator ofH is useful for describing and testing the effects of medicine, covariates, and so on. Actuaries call it the “force of mortality” and use it to estimate insurance payouts.
In reliability theory, it is called the “intensity function” and used to evaluate tolerance. The gamma and Weibull forms are typical models of the intensity function, and they describe various random behaviors. In extreme value theory, the hazard ratio determines the form of the extreme value distribution (see Gumbel 1958), which is defined as
Gγ(x) = exp(
−(1 +γx)−1/γ)
(1 +γx >0)
where γ is real and called the extreme value index. Let F be a distribution function and x∗ be its right endpoint. Under some regularity conditions, if
xlim↑x∗
( 1 H(x)
)′
=γ
holds, then F is in the domain of attraction of Gγ (i.e. the distribution of a suitably stan- dardized sample maximum converges to Gγ (see De Haan and Ferreira 2007)).
There are also many parametric models describing the dependency of covariates; the most popular one is Cox’s proportional hazard model. For the sake of simplicity, we will not consider covariates and instead focus on nonparametric estimation of the baseline hazard.
The naive nonparametric estimator of H(x0) is given by Watson and Leadbetter (1964) H(xe 0) = fb(x0)
1−Fb(x0),
where
fb(x0) = 1 h
∫ ∞
−∞
k
(x0−w h
)
dFn(w) and
Fb(x0) = 1 n
∫ ∞
−∞
K
(x0−Xi h
)
dFn(w).
Here, k is the kernel function and K is the integral of k K(u) =
∫ u
−∞
k(t)dt.
By using the properties of the kernel density estimator, Murthy (1965) proved the consistency and asymptotic normality of H(xe 0). Tanner and Wong (1983) proved these properties in the random censorship model by using H´ajek’s projection method. Patil (1993) gave its mean integrated squared error (M ISE) and discussed the optimal bandwidth in both uncensored and censored settings. For dependent data, Quintela-del R´ıo (2007) obtained the M SE of the indirect estimator. By using Vieu (1991)’s results, he obtained a modified M ISE that avoids any chance of the denominator being equal to 0. In this chapter, we assume that the support of the kernel k is a bounded and closed interval and that there is no censoring.
By extending the idea of ´Cwik and Mielniczuk (1989), we develop a new ‘direct’ estimator of the hazard ratio function, as follows:
H(xb 0) = 1 h
∫ ∞
−∞
k
(w−tn(w)−(x0−tn(x0)) h
)
dFn(w), where
tn(w) =
∫ w
−∞
Fn(u)du= 1 n
∑n i=1
(w−Xi)+
and (x)+ =x(for x≥0), = 0 (for x≤0). It is easy to see that H(x) is a smooth function.b We will discuss its asymptotic properties below. For the sake of simplicity, we will use the notation,
Ai,j =
∫ ∞
−∞
uikj(u)du.
The proofs of the theorems are in Section 2.4. For the direct hazard estimator, we have the following AM SE.
Theorem 1 Let us assume that (i) f is three-times differentiable at x0 and f(3)(x0) is bounded, (ii) k is symmetric, bounded, and the support is a bounded and closed interval
and (iii) A4,1 and A0,2 are bounded. Then, the M SE of H(xb 0) is given by E
[H(xb 0)− [ f
1−F ]
(x0) ]2
= h4 4A22,1
[{(1−F){(1−F)f′′+ 4f f′}+ 3f3}2 (1−F)10
]
(x0) + A0,2 nh
[ f 1−F
] (x0) +O
(
h6+ 1 nh1/2
)
. (1)
Remark 1 In order to get the above approximations, we perform a Taylor expansion of the integral. We can divide the integral at discrete points, so we do not need to worry about the differentiability of the density function at finite points.
On the other hand, under some regularity conditions, Patil (1993) gave the M SE of H(xe 0), as follows:
E
[H(xe 0)− [ f
1−F ]
(x0) ]2
= h4 4A22,1
[{(1−F)f′′+f f′}2 (1−F)4
]
(x0) + A0,2 nh
[ f (1−F)2
]
(x0) (2)
+O (
h6 + 1 nh1/2
) .
The asymptotic variances are the second terms on the right hand side of (1) and (2), and the direct estimator has a small variance because of 0 < 1−F(x0) < 1 when we use same bandwidth parameters. By minimizing the leading terms in the AM SE, we have an optimal bandwidth h=h∗ of H(xb 0), where
h∗ =n−1/5 (A0,2
A22,1
[ (1−F)9f
{(1−F){(1−F)f′′+ 4f f′}+ 3f3}2 ]
(x0) )1/5
.
Althoughh∗depends on unknown functions, we can obtain an estimator of the optimal band- width by replacing these functions with their estimators (i.e., by using the plug-in method).
Similarly, the following optimal bandwidth of the indirect H(xe 0) can be obtained:
h∗∗ =n−1/5 (A0,2
A22,1
[ (1−F)2f {(1−F)f′′+f f′}2
] (x0)
)1/5
. Furthermore, we can show the asymptotic normality of the directH.b
Theorem 2 Let us assume that (i), (ii) and (iii) of Theorem 1. When h = c1n−c2(0 <
c1, 15 ≤c2 < 12), the following asymptotic normality of H(xb 0) holds:
√nh
{H(xb 0)− [ f
1−F ]
(x0) }
−d
→N(B, V1), where B = limn→∞(nh5)1/2B1,
B1 = A2,1 2
[(1−F){(1−F)f′′+ 4f f′}+ 3f3 (1−F)5
] (x0) and
V1 =A0,2
[ f 1−F
] (x0).
Remark 2 If h=o(n−1/5), B = 0.
The asymptotic normality of the indirect estimator is easily obtained by using the Slut- sky’s theorem.
Moreover, we have the following higher-order asymptotic bias.
Theorem 3 Let us assume that (i′) f is six-times differentiable at x0, f(6)(x0) is bounded, (ii′) k is symmetric, bounded, and the support is a bounded and closed interval and(iii′) A6,1 is bounded. Then, the higher-order asymptotic bias of H(xb 0) is
E
[H(xb 0)− [ f
1−F ]
(x0) ]
=h2B1(x0) +h4B2(x0) +O(
h6+n−1) , where
B2(x0) = A4,1 24
[−60m2(m′)2m′′′+ 15m3m′′m′′′+ 11m3m′m(4)−m4m(5) m9
+210m(m′)3m′′−73m2m′(m′′)2−105(m′)5 m9
] (x0) and m(x) = 1−F(x).
2.3 Comparison of kernel hazard estimators
Here, we investigate the AM SE of the direct H(xb 0) and indirect H(xe 0) in certain special cases. We show that the new estimator H(xb 0) performs asymptotically better when F is an exponential or gamma distribution.
Here, we will suppose that F is an exponential, uniform, gamma, Weibull, or beta dis- tribution. The cumulative distribution function of the exponential distribution Exp(1/λ) is
F(x) = 1−exp(−λx), and the hazard ratio is constant; that is, H(x) =λ. This is one of the most common models of survival analysis. When F is exponential, the asymptotic biases of H(xe 0) and H(xb 0) vanish and the AM SEs are
AM SE
[H(xb 0) ]
= λ
nhA0,2 < AM SE
[H(xe 0) ]
= λ
nhexp(λx0)A0,2.
Thus, the new estimator is always asymptotically better regardless of the parameter λ and the point x0.
Next, let us assume that F is a uniform distribution (F(x) = x/b (0 < x < b)). The hazard ratio in this case is H(x) = (b−x)−1. The hazard ratio increases drastically in the tail area of this model. The above AM SEs are given by
AM SE
[H(xb 0) ]
= h4
4 A22,1 9b4
(b−x0)10 + 1 nh
1 b−x0A0,2 AM SE
[H(xe 0) ]
= 1
nh b
(b−x0)2A0,2.
We find that the asymptotic bias of H(xe 0) vanishes and the variance of H(xb 0) decreases.
Their asymptotic performance depends on x0 and b, but the AM SE of the new H(xb 0) is smaller when the life span b is large.
Lastly, let us suppose thatF is a gamma Γ(p,100), WeibullW(q,100), or beta distribution (100×B(r, s)), where p, q, r and s are their shape parameters. Their scales (σ = 100) are moderate. Γ(p, σ) is the distribution of the sum ofp(∈N)i.i.d.random variables of Exp(σ);
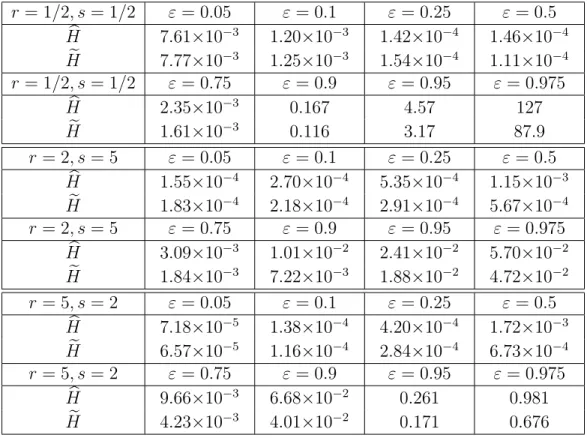
hence, it is one of most important cases. Its asymptotic squared bias, variance, and AM SE for some fixed points x0 are listed in Table 1, where we have omitted terms in powers of h.
Hb and He represent those values of H(xb 0) and H(xe 0), and every x0 is each ε-th quantile of Γ(p,100). The kernel is an Epanechnikov one with A2,1 = 1/5, A0,2 = 3/10, and h = n−1/5. The coefficients n−4/5 have been omitted.
The Weibull distributionW(q, σ) is also important in survival analysis because the hazard ratio is proportional to the polynomial degree (q−1); that is, H(x) = qσqxq−1. W(1, σ) is the exponential distribution. The beta distribution is often used to describe a distribution whose support is finite, and it has plentiful shapes. Tables 2, 3, and 4 give the least AM SE values usingh∗ orh∗∗(in Section 2.2), whereHb and He stand for theAM SE values ofH(xb 0) and H(xe 0). Every x0 is each ε-th quantile of Γ(p,100), W(q,100), or (100×B(r, s)). The tables demonstrate that the proposed estimator Hb performs asymptotically better in most cases of the gamma Γ(p,100). Moreover, the asymptotic performance of our estimator in the Weibull distribution cases is good and comparable to that of the beta cases.
Table 1: AsymptoticBias2, V ar and AM SE when F is gamma
Bias2 V ar AM SE Bias2 V ar AM SE
p= 1/2,ε = 0.05 p= 1/2, ε= 0.1
Hb 7.22×10−2 4.01×10−2 0.112 8.24×10−5 2.11×10−2 2.11×10−2 He 6.53×10−2 4.22×10−2 0.107 6.72×10−5 2.33×10−2 2.34×10−2
p= 1/2,ε = 0.25 p= 1/2, ε= 0.5
Hb 1.33×10−8 9.52×10−3 9.52×10−3 2.36×10−11 5.65×10−3 5.65×10−3 He 7.74×10−9 1.27×10−2 1.27×10−2 6.83×10−12 1.13×10−2 1.13×10−2
p= 1/2,ε = 0.75 p= 1/2, ε= 0.9
Hb 5.35×10−13 4.29×10−3 4.29×10−3 1.69×10−15 3.76×10−3 3.76×10−3 He 6.00×10−14 1.72×10−2 1.72×10−2 2.93×10−15 3.76×10−2 3.76×10−2
p= 1/2,ε = 0.95 p= 1/2, ε= 0.975
Hb 1.01×10−12 3.58×10−3 3.58×10−3 1.47×10−11 3.46×10−3 3.46×10−3 He 6.93×10−16 7.16×10−2 7.16×10−2 2.33×10−16 0.139 0.139
Bias2 V ar AM SE Bias2 V ar AM SE
p= 10, ε= 0.05 p= 10, ε= 0.1
Hb 2.49×10−18 1.56×10−4 1.56×10−4 2.16×10−18 2.55×10−4 2.55×10−4 He 7.16×10−19 1.64×10−4 1.64×10−4 1.73×10−21 2.83×10−4 2.83×10−4
p= 10, ε= 0.25 p= 10, ε= 0.5
Hb 2.61×10−18 4.77×10−4 4.77×10−4 1.37×10−17 7.72×10−4 7.72×10−4 He 2.40×10−18 6.36×10−4 6.36×10−4 7.91×10−18 1.54×10−3 1.54×10−3
p= 10, ε= 0.75 p= 10, ε= 0.9
Hb 2.84×10−16 1.07×10−3 1.07×10−3 1.19×10−14 1.32×10−3 1.32×10−3 He 1.05×10−17 4.28×10−3 4.28×10−3 9.83×10−18 1.32×10−2 1.32×10−2
p= 10, ε= 0.95 p= 10, ε = 0.975
Hb 1.84×10−13 1.45×10−3 1.45×10−3 2.75×10−12 1.56×10−3 1.56×10−3 He 8.70×10−18 2.90×10−2 2.90×10−2 7.58×10−18 6.24×10−2 6.24×10−2
Table 2: AM SE values when F is gamma and h=h∗ or h∗∗
p= 1/2 ε= 0.05 ε = 0.1 ε= 0.25 ε= 0.5 Hb 7.44×10−2 1.14×10−2 1.06×10−3 1.97×10−4 He 7.60×10−2 1.19×10−2 1.20×10−3 2.67×10−4 p= 1/2 ε= 0.75 ε = 0.9 ε= 0.95 ε = 0.975
Hb 7.40×10−5 2.11×10−5 7.26×10−5 1.21×10−4 He 1.45×10−4 1.48×10−4 1.86×10−4 2.54×10−4 p= 10 ε= 0.05 ε = 0.1 ε= 0.25 ε= 0.5
Hb 4.48×10−7 6.45×10−7 1.11×10−6 2.26×10−6 He 3.64×10−7 1.68×10−7 1.37×10−6 3.53×10−6 p= 10 ε= 0.75 ε = 0.9 ε= 0.95 ε = 0.975
Hb 5.39×10−6 1.34×10−5 2.51×10−5 4.57×10−5 He 8.46×10−6 2.05×10−5 3.76×10−5 6.75×10−5
Table 3: AM SE values when F is weibull and h=h∗ or h∗∗
q= 1/2 ε= 0.05 ε= 0.1 ε= 0.25 ε= 0.5 Hb 4.11×10−2 5.68×10−3 3.85×10−4 4.25×10−5 He 4.20×10−2 5.93×10−3 4.30×10−4 5.50×10−5 q= 1/2 ε= 0.75 ε= 0.9 ε= 0.95 ε= 0.975
Hb 9.22×10−6 3.31×10−6 3.59×10−7 2.67×10−6 He 1.53×10−5 8.61×10−6 7.68×10−6 7.90×10−6 q = 10 ε= 0.05 ε= 0.1 ε= 0.25 ε= 0.5
Hb 1.20×10−4 2.65×10−4 9.00×10−4 3.40×10−3 He 1.11×10−4 2.23×10−4 4.79×10−4 2.34×10−3 q = 10 ε= 0.75 ε= 0.9 ε= 0.95 ε= 0.975
Hb 1.38×10−2 5.49×10−2 0.135 0.309 He 1.33×10−2 5.96×10−2 0.153 0.360
Table 4: AM SE values when F is beta and h=h∗ or h∗∗
r= 1/2, s= 1/2 ε= 0.05 ε = 0.1 ε= 0.25 ε= 0.5 Hb 7.61×10−3 1.20×10−3 1.42×10−4 1.46×10−4 He 7.77×10−3 1.25×10−3 1.54×10−4 1.11×10−4 r= 1/2, s= 1/2 ε= 0.75 ε = 0.9 ε= 0.95 ε = 0.975
Hb 2.35×10−3 0.167 4.57 127
He 1.61×10−3 0.116 3.17 87.9
r = 2, s= 5 ε= 0.05 ε = 0.1 ε= 0.25 ε= 0.5 Hb 1.55×10−4 2.70×10−4 5.35×10−4 1.15×10−3 He 1.83×10−4 2.18×10−4 2.91×10−4 5.67×10−4 r = 2, s= 5 ε= 0.75 ε = 0.9 ε= 0.95 ε = 0.975
Hb 3.09×10−3 1.01×10−2 2.41×10−2 5.70×10−2 He 1.84×10−3 7.22×10−3 1.88×10−2 4.72×10−2 r = 5, s= 2 ε= 0.05 ε = 0.1 ε= 0.25 ε= 0.5
Hb 7.18×10−5 1.38×10−4 4.20×10−4 1.72×10−3 He 6.57×10−5 1.16×10−4 2.84×10−4 6.73×10−4 r = 5, s= 2 ε= 0.75 ε = 0.9 ε= 0.95 ε = 0.975
Hb 9.66×10−3 6.68×10−2 0.261 0.981 He 4.23×10−3 4.01×10−2 0.171 0.676
2.4 Appendices: Some Proofs
Proof of Theorem 1
For simplicity, we will use the following notation, t(z) =
∫ z
−∞
F(u)du, T(z) =
∫ z
−∞
t(u)du,
M(z) = z−t(z) and m(z) =M′(z) = 1−F(z).
To begin with, we consider the following stochastic expansion of the direct estimator:
H(xb 0)
= 1
h
∫ ∞
−∞
k
(M(w)−M(x0) h
)
dFn(w) + 1
h2
∫ ∞
−∞
k′
(M(w)−M(x0) h
)
{[t(w)−tn(w)]−[t(x0)−tn(x0)]}dFn(w) + 1
h3
∫ ∞
−∞
k′′
(M(w)−M(x0) h
)
{[t(w)−tn(w)]−[t(x0)−tn(x0)]}2dFn(w) +· · ·
= J1+J2+J3+· · · (say).
The main term of the expectation ofH(xb 0) is given byJ1, as we will show the later. Since J1 is a sum ofi.i.d. random variables, the expectation can be obtained directly:
E[J1] = E [1
h
∫ ∞
−∞
k
(M(w)−M(x0) h
)
dFn(w) ]
= 1
h
∫ ∞
−∞
k
(M(w)−M(x0) h
)
f(w)dw
=
∫ ∞
−∞
k(u) [ f
1−F ]
(M−1(M(x0) +hu))du
=
[ f 1−F
]
(x0) + h2 2 A2,1
[(1−F){(1−F)f′′+ 4f f′}+ 3f3 (1−F)5
]
(x0) +O(h4).
Combining the following second moment, 1
h2
∫ ∞
−∞
k2
(M(w)−M(x0) h
)
f(w)dw
= 1
h
∫ ∞
−∞
k2(u) [ f
1−F ]
(M−1(M(x0) +hu))du
= 1
h f
1−F(x0)A0,2+O(n−1),
we get the variance,
V[J1] = 1 nh
[ f 1−F
]
(x0)A0,2+O(n−1).
Next, we consider the following representation of J2 J2 = 1
n2h2
∑n i=1
∑n j=1
k′
(M(Xi)−M(x0) h
)
Q(Xi, Xj), where
Q(xi, xj) = [t(xi)−(xi−xj)+]−[t(x0)−(x0 −xj)+].
Using the conditional expectation, we get the following equation:
E[J2] = 1 nh2
∑n j=1
E [
k′
(M(Xi)−M(x0) h
)
Q(Xi, Xj) ]
= 1
nh2E [
k′
(M(Xi)−M(x0) h
) E
[ n
∑
j=1
Q(Xi, Xj)Xi ]]
= 1
nh2E [
k′
(M(Xi)−M(x0) h
)
{t(Xi)−[t(x0)−(x0−Xi)+]} ]
= 1
nh
∫ ∞
−∞
k′(u){
t(M−1(M(x0) +hu))−t(x0) + (x0−M−1(M(x0) +hu))+}
× f
1−F(M−1(M(x0) +hu))du
= 1
nh
∫ ∞
−∞
k′(u)O(hu) f
1−F(x0)du=O (1
n )
. Next, we have
J22 = 1 n4h4
∑n i=1
∑n j=1
∑n k=1
∑n ℓ=1
k′
(M(Xi)−M(x0) h
) k′
(M(Xk)−M(x0) h
)
×Q(Xi, Xj)Q(Xk, Xℓ)
= 1
n4h4
∑n i=1
∑n j=1
∑n k=1
∑n ℓ=1
D(i, j, k, ℓ) (say).
After taking the conditional expectation, we find that if all of the (i, j, k, ℓ) are different, E[D(i, j, k, ℓ)] = E[E{D(i, j, k, ℓ)|Xi, Xk}] = 0,
and
E[D(i, j, k, ℓ)] = 0 (if i=j and all of (i, k, ℓ) are different), E[D(i, j, k, ℓ)] = 0 (if i=k and all of (i, j, ℓ) are different), E[D(i, j, k, ℓ)] = 0 (if i=ℓ and all of (i, j, k) are different),
the term in whichj =ℓ and all of the (i, j, k) are different is the main term ofE[J22]. Ifj =ℓ and all of the (i, j, k) are different, we have
E[D(i, j, k, ℓ)]
= n(n−1)(n−2) n4h4 E
[ k′
(M(Xi)−M(x0) h
) k′
(M(Xk)−M(x0) h
)
×Q(Xi, Xj)Q(Xk, Xj) ]
.
Using the conditional expectation of Q(Xi, Xj)Q(Xk, Xj) given Xi and Xk, we find that E
[ E
{
Q(Xi, Xj)Q(Xk, Xj)Xi, Xk }]
= E
[
t(Xi)t(x0) +t(Xk)t(x0)−t2(x0) + 2T(x0)−t(Xi)t(Xk)
−(x+Xi−2 min(x, Xi))t(min(x, Xi))−2T(min(x, Xi))
−(x+Xk−2 min(x, Xk))t(min(x, Xk))−2T(min(x, Xk)) +(Xi+Xk−2 min(Xi, Xk))t(min(Xi, Xk)) + 2T(min(Xi, Xk))
] . Therefore, the entire expectation of the last row is
E [
k′
(M(Xi)−M(x0) h
) k′
(M(Xk)−M(x0) h
)
×(Xi+Xk−2 min(Xi, Xk))t(min(Xi, Xk)) + 2T(min(Xi, Xk)) ]
=
∫ ∞
−∞
[∫ w
∞
k′
(M(z)−M(x0) h
) k′
(M(w)−M(x0) h
)
× {(−z+w)t(z) + 2T(z)}f(z)dz +
∫ ∞
w
k′
(M(z)−M(x0) h
) k′
(M(w)−M(x0) h
)
× {(z−w)t(w) + 2T(w)}f(z)dz ]
f(w)dw.



![Table 6: ISE of the kernel estimators Beta(1, 1) f b f b u b [BK] f b X [BK](n) f b bu [R] f b X [R] (n) n = 30 .04414 .06093 .11531 .04640 .04656 n = 50 .03823 .03736 .08202 .03425 .03433 n = 100 .03161 .02057 .04270 .02353 .02357 n = 300 .02340 .00770 .0](https://thumb-ap.123doks.com/thumbv2/123deta/9884860.1907594/36.918.183.738.255.617/table-ise-kernel-estimators-beta-bk-x-bk.webp)