1.
は じ め に 人は物体を見た際,物体の様々な特徴を捉え,それらを総合 することで見た物体の認識を行う.しかし,実際にこれらの 過程は無意識に行われることが多く,特徴として捉えた箇所 を詳細に明示することは難しい.また,複数の形状の似た物 体が存在し,それらの詳細な違いを説明する場合においても 同様である.例として自動車の車型(セダン,ミニバン,SUV
などを指す)が挙げられる.自動車の形状は,車型で グループ分けされているが,基本的な車体の形状やパーツは 類似しているため,自動車に詳しくない人にとっては区別が つきにくい.さらに,近年では自動車のデザインの自由度が 増し,異なる車型同士が融合するようなデザインが混在する ことにより,元々異なっていた車型同士の車体形状の境界が 曖昧になってきている. 一方,深層学習の分野では技術の発展により,大量の データを学習させることで,特徴の抽出が可能になってきた. 深層学習の研究分野の中にはボクセル化した3D
モデル データを学習データとした3D
モデルの認識の研究が行われ ている[1
].車型同士の境界を明確にするために車型ごとの3D
モデルの特徴部位の可視化を行う必要がある.しかし,3D
モデルの認識の研究は行われているが,3D
モデルの 特徴部位の可視化の研究は行われていない.画像認識の分 野では画像の特徴部位の可視化の研究が行われていること から,著者らは画像認識による画像の特徴部位の可視化を3D
モデルの特徴部位の可視化に応用できると考えた[2
].Ding-Yun
らは,3D
オブジェクトの検索技術の手法提案と して,3D
オブジェクトの正射影画像を利用し,同じ角度の 正射影画像の類似から3D
オブジェクトの検索システムの 実装を行った[3
].著者らは,3D
モデルデータを2
次元 画像に変換することで,画像認識に必要な大量の画像を 収集できると考えた.また,画像認識の分野において,Rampasaath
らは,Grad-CAM
と呼ばれる画像の特徴部位の 可視化を行った[2
].Grad-CAM
はニューラルネットの層 の重みと勾配情報を用いることで,カテゴリごとの出力値 に影響を与える特徴部位の可視化を行うことができる. そこで本研究では,深層学習を用いて車型の判別とそれ に寄与する部位の視覚化を行う実験を通して,各車型の 特徴を明らかにすることを目的とした.具体的には,まず30
台の自動車の3D
モデルを使用し,各モデルの周囲に視 点を1
度刻みで360
点設定し,それぞれの点から見た自動車 の透視投影画像を用いて,VGG16
モデルで転移学習を行っ た.次に,学習したニューラルネットにテストデータとな る3D
モデルの透視投影画像を入力し,出力結果の値から 車型の判別を行った.さらに,出力結果の値を参照し,Grad-CAM
を用いて各車型の特徴部位の可視化を行った.2.
車型の定義 本研究では,自動車の利用者の目的に合わせてデザインさ れ,形状が大きく異なる車型のセダン,ミニバン,SUV
を畳み込みニューラルネットワークを用いた
自動車の三次元モデルにおける各車型の特徴抽出と視覚化
田中 俊太朗*, 原田 利宣**, 小野 謙二***
*和歌山大学大学院‚ **和歌山大学‚ ***九州大学Analyses and Visualization of Characteristics of Car Body Types
by Using Convolutional Neural Network
Syuntaro TANAKA*, Toshinobu HARADA** and Kenji ONO***
* Graduate School of Wakayama University, 930 Sakaedani, Wakayama-shi, Wakayama 640-8510, Japan ** Wakayama University, 930 Sakaedani, Wakayama-shi, Wakayama 640-8510, Japan
*** Kyusyu University, 744 Motooka, Nishi-ku, Fukuoka 812-8581, Japan
Abstract : The cars are classified by cars’ body types. However the characteristics are basically similar at first sight, so it is difficult
to distinguish the differences among those cars’ body types. Therefore, in this study, we considered that cars’ characteristics could be analyzed by using deep learning and image recognition technology, developed a system to visualize the judgment and characteristic parts of cars’ body types. Specifically, we made renderings of the CG model of 30 cars by setting 360 viewpoints in 1 degree increments around each car. Deep learning was performed using these 2D images as teacher signals. The car body type recognition probability of each angle is graphed, and the characteristic parts of each car body type are visualized. As a result, we clarified the visual angles and the pars contributing the judgment of cars’ body types.
Keywords : Deep learning, Convolutional neural network, Car body type, Image recognition, Visualization
対象とし,それらをニューラルネットの出力層のカテゴリと して定義する.そこで,本章ではセダン,ミニバン,
SUV
の 一般的な定義について概説する.セダン,ミニバン,SUV
の 自動車の構造と座席の配置図を図1
∼図3
にそれぞれ示す. まず,セダンは図1
の左の図より,前から赤色がエンジン ルーム,橙色が乗車空間,青色がトランクルームといった それぞれ独立した自動車の基本形となる構造である[4
]. 乗車空間とトランクルームを独立させるといったドライバーや 同乗者の快適性を重視した構造であり,自動車の前後に空間 があることから事故に対する安全性が高い.多くのセダン車 は図1
の右の図より,前から運転席,助手席,後部座席といっ た2
列座席で構成され,それぞれにドアがついた4
ドア車で ある. 次に,ミニバンは図2
の左の図より,前から赤色がエンジ ンルーム,橙色が乗車空間といった独立した構造である[4
]. セダンと異なり,トランクルームを無くし,屋根を最後尾ま で伸ばし,乗車空間を広くした乗員や荷物の容量を重視した 構造である.着座位置が高いことから,ドライバーの視点が 高く,遠くを目視できる.ミニバン車は,図2
の右の図より, 前から運転席,助手席,2
列の後部座席といった3
列座席で 構成され,運転席,助手席,2
列目座席にそれぞれドアがつ いた4
ドア車である.本研究で使用するミニバンはスライド 式ドアとスイング式ドアの両方を対象とする. さらに,SUV
は図3
の左の図より,前から赤色がエンジ ンルーム,橙色が乗車空間といった独立した構造である. ミニバンと比べ,ボンネットがはっきりしており,車高が 高く,スポーツやアウトドアに特化している.SUV
車は, 図3
の右の図より,セダンと同様に運転席,助手席,後部座 席の2
列座席で構成され,それぞれにドアがついた4
ドア車 である.3.
車型の特徴抽出システムの流れと用いる手法 本章では,システムの流れについて概説を行い,システム の流れに沿って使用する手法について説明する.3.1
システムの流れ 本研究におけるシステムの流れと用いる手法を図4
に 示す.本システムではまず,データセットの作成を行う. データセットの作成では,39
台の3D
モデルを2
次元画像に 変換し,ニューラルネットへ学習させる学習用データと実験 で使用する実験用データの作成を行う.次に,作成した学習 用データを畳み込みニューラルネットワークに学習させる. 本研究では転移学習を用いて学習を行う.また,実験用データ を学習したモデルに入力し,出力層の各カテゴリの出力値か ら入力画像の車型を判別する.さらに,各カテゴリの出力値 を参照し,Grad-CAM
と呼ばれる手法を用いて車型の特徴部 位の可視化を行う.システムの中で用いられた手法について 次節から説明する.以下,画像を入力した際出力層の各カテ ゴリの値の大きさから車型を判別することを車型認識と称す.3.2
畳み込みニューラルネットワークの手法の概説 畳み込みニューラルネットワークとは,畳み込み層および プーリング層と呼ばれる特殊な機能を持つ層が交互に接続さ れた多層構造のニューラルネットワークで,この構造以外は, 一般的な順伝播のニューラルネットワークと同様である[5
]. 本研究では,Keren
らの画像認識の研究で精度の高い結果が 得られたVGG16
と呼ばれる畳み込みニューラルネットワーク のモデルを使用する[6
].以下,畳み込みニューラルネット ワークをCNN
と称す.3.3
転移学習の手法の概説 転移学習とは,ある領域で既に学習させたモデルの一部を 転用し,新たなモデルを生成する方法である.本研究では,Fine-Tuning
による転移学習を行う[7
].Fine-Tuning
では, 学習済みモデルの出力層を対象タスクのものに付け替え, 初期パラメータとして学習済みモデルの値を使用する.学習済み 図1 セダン車の構造と座席配置図 図2 ミニバン車の構造と座席配置図 図3 SUV車の構造と座席配置図 図4 システムの流れと手法モデルは,
ImageNet
と呼ばれる120
万枚の画像を学習させたVGG16
のモデルを使用する.学習時にCNN
の出力層に最も 近い畳み込み層3
層と全結合層でパラメータの調整を行い, それ以外の層のパラメータを固定する.学習時に誤差逆伝播 法を用いてパラメータの調整を行う.3.4
Grad-CAM
の手法の概説Grad-CAM
は,Rampasaath
らによって提案された画像の 特徴抽出を行う手法である[2
].具体的には,出力層のカテ ゴリを指定することで,車型認識の際にCNN
が着目してい る入力画像の特徴箇所をヒートマップで表示し,出力層のカ テゴリの値に影響を与える特徴部位を視覚的に判断できる. 本研究では,車型認識の結果に関わらず,すべてのカテゴリ の特徴抽出を行う.4.
車型認識と特徴抽出システムの解説 本章では,自動車の属する車型における自動車の車体形状 の特徴抽出を行うための可視化システムについて詳述する. 本システムでは,自動車の3D
モデルを2
次元画像に変換し たデータをCNN
に学習させる.その後,学習させたCNN
に画像を入力した際に出力された各カテゴリの値の大きさか ら,入力した画像の車型の判別を行い,車型の特徴がどの部 位に影響を受けているかを視覚的に表現する.4.1
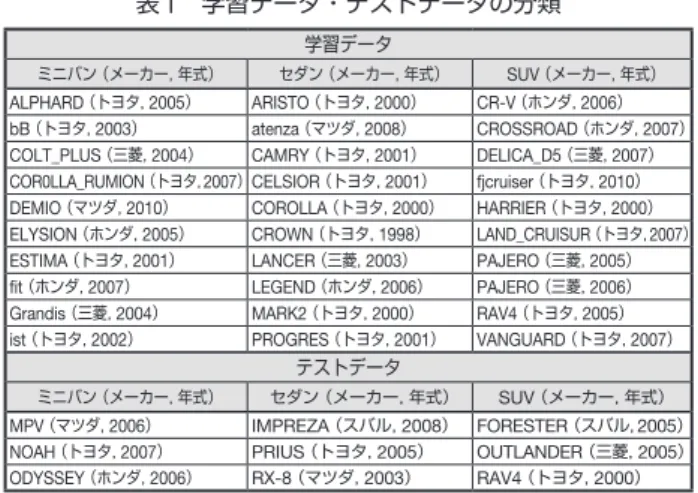
学習データ・テストデータの収集 本節ではサンプルデータ内の学習データ・テストデータ の分類と2
次元画像の作成方法について説明する.以下,CNN
の学習を行う際に使用する画像データを学習データ, 車型認識と特徴抽出に使用する画像データをテストデータ とする.本節は(1
)学習データ・テストデータの分類, (2
)学習データ・テストデータの作成,(3
)学習データの データ量の3
つで構成されている. (1
)学習データ・テストデータの分類: 本システムでは2
章で記述した車型の「セダン」「ミニバン」 「SUV
」の3
種類のカテゴリを使用する.さらに,3D
モデル を学習データ,テストデータに分類する際,学習データと テストデータそれぞれに以下のような判断基準を設けた. (ⅰ)学習データ:一般的な人でも各カテゴリに属する車 型であると視覚的に認識しやすい3D
モデル (ⅱ)テストデータ:一般的な人が各カテゴリに属する車 型であると視覚的に認識しにくい3D
モデル 学習データ・テストデータで使用した自動車を表1
に示 す.筆者だけによる分類は,筆者の車型の印象に偏った学習 結果になる可能性が考えられるため,自動車に関する知識の 多い協力者との話し合いにより分類を行った. (2
)学習データ・テストデータの作成: オープンソースの3D
コンピュータグラフィックスソフト ウェアであるblender
のレンダリング機能を用いて,3D
モデ ルから2
次元画像の作成を行う[8
].3D
モデルのソースは,3D
カーモデリングサイトのデータを使用する[9
].データの 作成方法を以下に示す.まず,3D
空間上に実寸大の1/1000
サ イズのモデルをモデルのX
軸,Z
軸の中心を座標のX
軸,Z
軸 の中心に合わせ,XZ
面を床面として配置する.次に3D
モデ ルから7.5 mm
離れた位置にカメラを配置し,3D
モデルと カメラの距離とカメラの高さ,カメラの向き先を座標の中心 で固定した状態で,モデルの正面から左回りに座標の原点を 中心に1
度ずつレンダリングを行う.ここで自動車とカメラ の距離を7.5 mm
にすることで,全ての角度においてカメラの 画角に全てのモデルが収まる.カメラの高さは,車高がわか りやすい1 mm
の位置に設定することで,車体の底の高さを含 めた3D
モデル全体のシルエットを把握できる.レンダリング の際のモデルとカメラの配置のイメージを図5
に示す.レン ダリング画像は光源の配置位置による車体の認識の誤差や モデルの色による認識の影響を避けるために,光源のない シルエット画像を使用する.シルエット以外の背景は白に 統一する.以下,レンダリングを行った際のモデルから見た カメラ配置の角度を視点角度と定義する.視点角度の0
度は 自動車の正面,90
度は左側面,180
度は自動車の背面,270
度 は右側面,360
度は0
度と重なり,自動車の正面に戻る. (3
)学習データのデータ量:1
台の3D
モデルに対し2
次元画像は角度1
度ずつレンダリ ングを行うため,360
枚作成される.また,学習データでは 車型ごとに10
台使用するため,車型ごとに3600
枚ずつ画像 データが作成される.画像サイズは,学習させるCNN
の入 力層に合わせた縦224
ピクセル横224
ピクセルとする. 表1 学習データ・テストデータの分類 学習データ ミニバン(メーカー,年式) セダン(メーカー,年式) SUV(メーカー,年式) ALPHARD(トヨタ,2005) ARISTO(トヨタ,2000) CR-V(ホンダ,2006) bB(トヨタ,2003) atenza(マツダ,2008) CROSSROAD(ホンダ,2007)COLT_PLUS(三菱,2004) CAMRY(トヨタ,2001) DELICA_D5(三菱,2007)
COR0LLA_RUMION(トヨタ,2007)CELSIOR(トヨタ,2001) fjcruiser(トヨタ,2010)
DEMIO(マツダ,2010) COROLLA(トヨタ,2000) HARRIER(トヨタ,2000)
ELYSION(ホンダ,2005) CROWN(トヨタ,1998) LAND_CRUISUR(トヨタ,2007)
ESTIMA(トヨタ,2001) LANCER(三菱,2003) PAJERO(三菱,2005)
fit(ホンダ,2007) LEGEND(ホンダ,2006) PAJERO(三菱,2006)
Grandis(三菱,2004) MARK2(トヨタ,2000) RAV4(トヨタ,2005)
ist(トヨタ,2002) PROGRES(トヨタ,2001) VANGUARD(トヨタ,2007)
テストデータ
ミニバン(メーカー,年式) セダン(メーカー,年式) SUV(メーカー,年式)
MPV(マツダ,2006) IMPREZA(スバル,2008) FORESTER(スバル,2005)
NOAH(トヨタ,2007) PRIUS(トヨタ,2005) OUTLANDER(三菱,2005)
ODYSSEY(ホンダ,2006) RX-8(マツダ,2003) RAV4(トヨタ,2000)
4.2
転移学習と学習したモデルの精度 まず,3.2
節で記述したVGG16
のImageNet
をベースに 転移学習を行う.「ミニバン」「セダン」「SUV
」それぞれを 教師データ(「ミニバン」「セダン」「SUV
」)として画像を 入力層に組み込んでいき,出力層では入力画像に属するカテ ゴリに1
を入力し,それ以外に0
を入力し逆伝播処理を行う. 学習回数は50
回といった学習時の設定を行った.学習デー タ10,800
枚のうち,学習時にモデルのパラメータを調整する ための訓練データ10,500
枚と学習の途中経過で精度を確かめ る確認データ300
枚の分類を行い,訓練データを用いて学習 を行った. 次に,学習したモデルの認識精度を評価した.図6
より, 学習回数を重ねるごとに損失が減少している.また,確認デー タを用いて,表2
の混合行列を算出したところ,全体の精度 が約98%
となった.よって,汎化性の高い車型認識のモデ ルを構築できたと考える.4.3
車型認識 前節で学習したモデルを用いて,車型認識を行う.具体 的には,入力層に画像データを入力することで出力層の 「ミニバン」「セダン」「SUV
」の各カテゴリに確率の値が 出力される.出力層の各カテゴリの中で最も大きい値を 持つカテゴリを入力画像の車型として認識する.また, 車型認識時に出力層の各カテゴリに出力された確率の値を 認識率と定義する.4.4
認識率のグラフ化 テストデータの各3D
モデルに対し360
枚分(視点角度0
∼359
度)のレンダリング画像から,カテゴリの認識率を収集 し,図7
のようなグラフを作成した.図7
のグラフの縦軸は 認識率の値,横軸は視点角度の値である.視点角度の0
度は 自動車の正面であり,360
度は0
度と重った自動車の正面の レンダリング画像であるため,グラフの両端をつなげる. 認識率のグラフは1
台の3D
モデルに対し,ミニバン,セダン,SUV
それぞれ3
つ作成される.4.5
特徴部位の可視化4.2
節で学習したモデルを用いて,grad-CAM
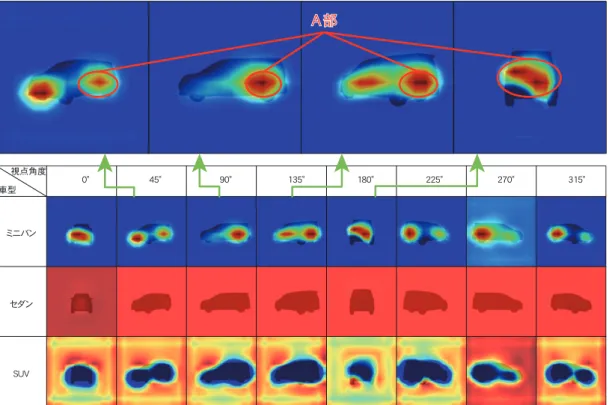
のより, 画像の特徴部位の可視化を行った.指定したカテゴリからの 逆伝搬による勾配情報を用いて,認識する要素の強い特徴を 抽出し,ヒートマップで表現する.図8
のように出力層の 各カテゴリの出力値への影響が強い順に,黒,赤,橙,黄, 緑,青の順番で色を表示する.grad-CAM
特徴として,1
枚 の画像から各カテゴリの特徴部位の可視化を行うことが可能 である.そのため,一枚の画像につき,ミニバンの特徴の 可視化画像,セダンの特徴の可視化画像,SUV
の特徴の 可視化画像の3
枚が作成できる.5.
実装結果・考察5.1
車型認識率の分析結果と考察3D
モデル1
台から得られる360
枚の2
次元画像の認識率を 各台でまとめ,グラフの作成を行った[注1
].ミニバン, セダン,SUV
それぞれのグラフを図9
∼図11
に示す.ミニ バンの解釈を以下に示す. 図6 損失と学習回数 表2 カテゴリ問題の混合行列 正解カテゴリ ミニバン セダン SUV 予測カテゴリ ミニバン 95 0 0 セダン 5 100 0 SUV 0 0 100 図7 認識率のグラフ化 図8 特徴部位の可視化•
図9
のa-1
よりミニバンに属するMPV
は,全体的にミニバン の認識率が高い.しかし,視点角度80
∼90
度ではSUV
の認識率が高く,視点角度288
∼307
度ではSUV
の認識 率がやや高い.以上のことから,MPV
はミニバンと認識 するが,真横からはSUV
とやや認識する可能性がある.•
図9
のa-2
より,ミニバンに属するNOAH
は全体的にミニバ ンの認識率が高いが,SUV
の認識率の高い部分がある. 特 に, 視 点 角 度170
∼195
度と278
∼295
度 のSUV
の 認識率が高い.以上のことから,NOAH
はミニバンと認識 するが,背面と真横からはSUV
と認識する可能性がある.•
図9
のa-3
より,ミニバンに属するODYSSEY
は全体的 にミニバンの認識率が高い.しかし,視点角度5
∼9
,176
∼190
,346
∼355
度の場合,セダンの認識率が高い. 以上のことから,ODYSSEY
はミニバンと認識するが, 正面と背面はセダンと認識する可能性がある. セダンの解釈を以下に示す.•
図10
のb-1
より,セダンに属するIMPREZA
はミニバン とセダンの認識率が高い.さらに,全体的にミニバンと セダンの認識率が交互に高くなる視点角度が多い. 特に,視点角度172
∼193
度のセダンの認識率が高く, 図9 ミニバンの認識率のグラフ化 図10 セダンの認識率のグラフ化大きく変化している.以上のことから,
IMPREZA
は角度 によりミニバンまたはセダンと認識する可能性がある.•
図10
のb-2
よ り, セ ダ ン に 属 す るPRIUS
は 全 体 的 に ミニバンの認識率が高い.しかし,視点角度1
∼10
,157
∼207
,352
∼354
度のセダンの認識率が高い.以上 のことから,PRIUIS
は実際の車型がセダンであるが, ミニバンと認識する可能性が高い.しかし,正面と背面 に関してはセダンと認識する可能性が高い.•
図10
のb-3
より,セダンに属するRX-8
は全体的にセダ ンの認識率が高い.以上のことから,RX-8
はセダンと 認識する可能性が高い.SUV
の解釈を以下に示す.•
図11
のc-1
より,SUV
に属するFORESTER
は全体的にSUV
の認識率が高い.以上のことから,FORESTER
はSUV
と認識する可能性が高い.•
図11
のc-2
より,SUV
に属するOUTLANDER
は全体 的にSUV
の認識率が高い.しかし,視点角度1
∼12
,345
∼359
度のミニバンの認識率が高い.以上のことか ら,OUTLANDER
はSUV
と認識するが,正面はミニバ ンと認識する可能性が高い.•
図11
のc-3
より,SUV
に属するRAV4
は全体的にSUV
の 認識率が高い.視点角度6
∼51
,324
∼359
度のミニバンの 認識率が高い.以上のことから,RAV4
はSUV
と認識する が,正面あたりはミニバンと認識する可能性がある. 以上の結果から,以下のようなまとめと考察を行った. ミニバンのODYSSEY
の場合,ミニバンの認識率は正面 と背面が低く,他は高い.SUV
のOUTLANDER
やRAV4
は正面のみが
SUV
の認識率が低い.これらの結果は,筆者 が実際に見た印象と同じである.
一方,セダンのPRIUS
は実 際の車型であるセダンの認識率が正面と背面が高く,その他 はミニバンの認識率が高い.また,セダンのIMPREZA
は, セダンとミニバンの認識率が交互に高くなっている.このこ とから,IMPREZA
はミニバンとセダンの車型が融合してい る自動車であると考えられる.以上の各カテゴリの認識率の 変化の原因は,4.1
節で記述したテストーデータの分類の判 断基準や,MPV
やRX-8
,FORESTER
では自身の属する車 型の認識率が高い結果が得られていることや表2
の学習モデ ルの認識精度評価より,車体形状によるものと考えられる. また,モデル1
台から作成された360
枚の画像のうち, 画像ごとの車型の認識した結果の割合をそのモデルの車型と 仮定し,図12
のような車型の位置付けを行った.1
台から作 成された画像のうち,車型の認識した結果が3
種類ある車型 が存在しなかったことから,3
つの車型が融合する車種は テストデータには存在しなかったと考えられる.また,ミニ バンとセダンの線上とミニバンとSUV
の線上のみデータが存 在することから,テストデータではセダンとSUV
の融合した 車型は存在しなかった. 図11 SUVの認識率のグラフ化 図12 車型の位置付け5.2
特徴部位可視化の結果と考察grad-CAM
を用いて,特徴部位の可視化を行った.認識率 が極めて高い,または極めて低い場合,特徴の可視化画像は 全体が赤色になり,その視点角度における特徴部位を抽出で きない.そのため,前節で作成したグラフを参照し,視点角 度によって認識率が大幅に異なる,また認識率の高いものと 低いものがほぼ同じ数含まれる自動車のモデルを対象とし 実験を行った.よって,前節のグラフからミニバンのNOAH
,セダンの
IMPREZA
,SUV
のRAV4
を対象に特徴部位の可視化を行った[注
2
].特徴部位可視化の結果を図13
∼図15
に 示す.これらの図は,視点角度45
刻みの画像それぞれにミニ バン,セダン,SUV
の特徴部位を可視化した結果である.図13 ミニバン車NOAHの特徴部位の可視化
•
図13
のミニバンの特徴部位の可視化画像のA
部より, ミニバンの特徴部位は,リアクォーター周辺であると考 えられる.2
章で記述した内容から,リアクォーター周 辺の特徴は,車内の3
列目の座席の空間を確保した車体 形状の影響を受けている.•
図14
のセダンの特徴部位の可視化画像のB
部より, セダンの特徴部位は,フロントガラス周辺であると考え られる.2
章で記述した内容から,エンジンルームが 独立していることから,ボンネットが大きく確保され, フロントガラスとの角度が大きくなることで,ミニバン やSUV
にはない角度の浅いフロントガラス周辺の影響 を受けている.•
図14
のミニバンの特徴部位の可視化画像のC
部より, ミニバンの特徴部位は,トランクルームの地上からの高さ であると考えられる.ミニバン2.2
節で記述した内容から, ミニバンの特徴とされる大容量の車内空間の確保のため, 前輪のタイヤと車体の前の幅の影響を受けている.• grad-CAM
の特徴部位の可視化は,他のカテゴリに影響 を与えるものであるため,ミニバンとセダンの特徴とし たもの以外をSUV
の特徴として加算する.図15
のD
∼F
部のような,ミニバンとSUV
はお互いの特徴が重なら ないようにそれぞれが特徴を捉えている.図14
の下の 図の視点角度90
,135
,270
度のような,セダンとミニ バンの特徴以外をSUV
の特徴として捉えているため,SUV
の特徴部位の範囲が大きい.•
図14
のセダンと認識している部位から,自動車の共通した 部位を特徴として捉えていると考えられる.つまり,自動車 の角度に関わらず3D
モデルの同じ部位を認識している.6.
結 論 本研究では,各車の周囲に視点を1
度刻みで360
点設定し, レンダリングを行い,それらを教師あり学習データとして 転移学習を行った.次に,学習したモデルを用いて,車型認識 と特徴部位の可視化を行った.その結果,認識率のグラフと 車型の位置付けから,車型の曖昧な自動車が存在することが 考察できた.また,視点角度ごとの認識率の変化や3
次元で 特徴部位をとらえることから,CNN
は人と似た物体の認識を 行っていることが考察できた. ただし,今後の課題として以下の点が挙げられる.1
)本システムでは,SUV
の特徴部位の明確化ができな かった.これは,学習時のカテゴリをミニバン,セダ ン,SUV
の順番で設定し,ミニバン,セダン,SUV
の順番で学習させたため,ミニバンとセダンの特徴の みが抽出され,それ以外の特徴がSUV
に集中したと考 えられる.そのため,学習時のカテゴリの順番を変更 し,SUV
の車体形状の特徴を抽出する必要がある.2
)本システムでは,カテゴリをセダン,ミニバン,SUV
の3
つに分類したが,3
ボックス,2
ボックス,ワンボックス といった分類も考えられるため,分類方法が異なる場合 についても実験し,今回の結果と比較する必要がある. さらに,今後の展望として,本システムの出力層のカテゴリ を車型から感性ワード(印象)に変換することで3D
モデルの 部位がどの感性ワードに影響を与えているかを明確にできる と考える.また,認識率と特徴部位の可視化の両方を組み合 わせることで,感性と形状の関係性がよりわかりやすくなる と考える. 図15 SUV車RAV4の特徴部位の可視化画像謝 辞 本研究は
JSPS
科研費16H02824
の助成を受けたものです. ここに謝意を表します. 注 [注1]画像認識で左右反転した画像をそれぞれ入力する場合, CNNでは異なる画像として認識しているため,それぞ れの認識率が完全に同じになるとは限らない. [注2]画像の特徴部位の可視化で左右反転した画像をそれぞれ 入力する場合,CNNでは異なる画像として認識している ため,特徴部位の範囲が完全に同じになるとは限らない. 参 考 文 献[1] Maturana, D., and Scherer, S.: VoxNet: A 3D Convolu-tional Neural Network for real-time object recognition, 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp.922-928, 2015.
[2] Selvaraju, R. R., Das, A., Vedantam, R., and Cogswell, M.: Grad-CAM: Why did you say that? Visual Explanations from Deep Networks via Gradient-based Localization, CoRR arXiv:1610.02391, pp.4-5, 2016.
[3] Chen, D. Y., Tian, X. P., Shen, Y. T., and Ouhyoung, M.: On Visual Similarity Based 3D Model Retrieval, Computer Graphics Forum (EUROGRAPHICS 2003), 22(3), pp.223-232, 2003. [4]【保存版】ワンボックスカーとミニバンとSUVの違いとは?, https://www.lineup-car.com/blog/5066.html(2018.04.15 閲覧). [5]岡谷貴之: 画像認識のための深層学習,人工知能学会誌, 28(6),pp.962-974,2013.
[6] Simonyan, K., and Zisserman, A.: Very Deep Convolu-tional Networks for Large-Scale Image Recognition, arXiv:1409.1556v6, pp.5-8, 2015. [7]中山英樹:深層畳み込みニューラルネットワークによる画 像特徴抽出と転移学習,信学技報,115(146),pp.55-59, 2015. [8] pythonスクリプトでレンダリングを制御: https://otonoki3d.wordpress.com/2014/08/09/(2018.01.29 閲覧).
[9] CG DATA BANK:3D CAR MODEL ONLINE SHOP,
https://cgdatabank.com. 田中 俊太朗(非会員) 2018年 和歌山大学システム工学部卒業. 同年,和歌山大学大学院システム工学研究科 システム工学専攻博士前期課程入学.現在に 至る.主として,深層学習に関する研究に従事. 原田 利宣(正会員) 1996年 千葉大学大学院自然科学研究科修了. 工学(博士).マツダ株式会社車両設計部, 日産自動車株式会社デザイン本部を経て, 1997年度和歌山大学システム工学部助教 授.2004年度より,同教授.現在に至る. 曲線(面)の分析・創成手法開発やラフ集合を中心としたデザイン 方法論の開発に従事.1996年 日本デザイン学会研究奨励賞受賞, 2004年 グッドデザイン賞受賞,2002,2004,2005,2010年 感性 工学会出版賞など. 小野 謙二(非会員) 2000年 熊本大学自然科学研究科修了,博士 (工学).日産自動車(株),東京大学,理化学 研究所を経た後,現在 九州大学教授.数値 流体力学,大規模並列計算,可視化の教育研 究に従事.