DEIM Forum 2016 A1-4
潜在領域を用いた転移学習による文書分類
白井 匡人
†劉
健全
††,†三浦 孝夫
††
法政大学 理工学研究科
〒 184–8584 東京都小金井市梶野町 3-7-2
††
日本電気株式会社 グリーンプラットフォーム研究所
〒 211–8666 神奈川県川崎市中原区下沼部 1753
E-mail:
†
[email protected],
††
[email protected],
†††
[email protected]
あらまし
本研究では,中間領域に潜在領域を用いた転移学習による文書分類手法を提案する.転移学習は,情報源
となる領域の学習結果を対象領域の解析に利用することで性能を改善する.ここでは,得られた知識を利用するため
に情報源領域と対象領域が関連していることが必要となる.しかし,対象領域に対する適切な情報源領域が存在する
とは限らない.本研究では,トピックモデルにより,教師無し文書からトピック分布を学習する.このトピックを情
報源領域と対象領域を繋ぐ中間領域として用いることで文書分類を行う.
キーワード
転移学習,NMTF,トピックモデル,文書分類
1.
前
書
き
近年,インターネットの発達から大量のデータを容易に入 手できるようになっている.ニュース記事やマイクロブログと いった大規模な文書集合は,様々な情報を含む重要な情報源と して注目されている.しかし,これらの文書集合は文書数が膨 大となるため,大半の情報が利用されないまま流れ去っている. このため,大量の文書から知識を抽出するための文書集合のモ デル化が必要となる. 文書をクラスごとに分類する文書分類では,政治,スポーツ, ITといったクラスは文書の集合として表される.文書分類は, クラスの持つ様々な特徴に基づき未知の文書を各クラスに分類 する.確率モデルにより文書分類を行う場合,文書集合を近似 する確率分布のパラメータがクラスの特徴になる.学習データ から得られたパラメータを対象に適用することで分類を行うこ とが可能となる.しかし,確率モデルは,現在の状況のモデル 化であるため,異なるクラスや時間の経過による特徴の変化と いった新たな状況に対応できない.このため,状況の変化が起 きるたびにモデルを更新する必要がある. ニュース記事やマイクロブログといった文書ストリームでは, 話題の変化に応じてクラスの特徴が変化するため,分類基準を あらかじめ固定することは困難となる.ニュース記事では新し いニュースが逐次発生するため,話題が動的に変化する.例え ば,政治に関する話題では,選挙,予算編成,法案審議のよう に時期による出来事や,外交問題や汚職事件など不定期な出来 事に依存し,発生する単語は大きく異なる.これらの出来事の 中でも,時間経過によって論じられる内容は逐次変化している. 転移学習は,情報源領域から得られた知識を異なる領域の解 析に適用する枠組みである.学習データとテストデータが同一 の領域であることを仮定しないため適用範囲が広く,様々な問 題に転移学習が用いられている.ここでは,得られた知識を利 用するために情報源領域と対象領域が関連していることが必要 となる.しかし,対象領域に対する適切な情報源領域が存在す るとは限らない.情報源領域と対象領域の関連性が低い場合, 転移学習の精度が悪化することが知られている[9].この問題を 解決するため,関連性の低い情報源領域と対象領域を中間領域 によって繋ぐ転移学習手法が示されている[10].Tanらの手法 では,あるクラスが情報源領域と対象領域を繋ぐ中間領域に対 応することを仮定している.対象領域の単語が変化していく中 で、常に2つの領域を繋ぐ適切な中間領域が存在するとは限ら ない. 本論文は,転移学習による文書分類を行うために,主に2つ の問題について論じる.第1は,如何に情報源領域と対象領域 を繋ぐ適切な中間領域を構築するか,第2は,特徴の変化が起 きる集合内で如何に中間領域を更新するかである.本論文の貢 献は,潜在トピックにより中間領域を構築し,集合の変化に応 じて中間領域を更新する転移学習の枠組みを提案しているとこ ろにある.本研究では,中間領域に潜在トピックを用いた転移 学習による文書分類手法を提案する.ここではトピックモデル により,教師無し文書からトピック分布を抽出する.この潜在 トピックを情報源領域と対象領域を繋ぐ中間領域として用いる ことで文書分類を行う. 第2章では文書ストリームの分類について述べ,第3章では 転移学習について述べる.第4章ではトピックモデルについて 述べ,第5章では提案手法について述べる.第6章では実験に より有効性を示す.第7章で結論とする.2.
文書ストリームの分類
ニュースストリーム,マイクロブログに代表されるSNSデー タは,様々な情報を含む情報源として注目されている.ニュー スストリームでは,各記事は記事が属するクラスが持つ複数の 話題を含み,話題に関連して出現する単語分布が変化する.こ の話題はストリーム中で大きく変化する可能性がある.このた め,同一のクラス内であっても単語分布は各話題に関連して多 様性を持つ.このような時間に応じて特徴が変化する集合に対 して分類を行うには,変化に応じてモデルを更新する必要があ る.文書ストリームの分類では,特徴の変化に対応するために, ストリーム中で新たなラベル有り文書により追加の学習を行う手法が示されている[11], [15].新たに到着した文書全てを人手 によりラベル付けすることは,コストが膨大となるため困難で ある.能動学習は,機械自身がモデルを改善するために有効な データを検出し,学習に用いる手法である.Bougueliaらは, ストリームベースの能動学習を用いることでストリーム中で分 類を行う手法を提案している[13].ストリームベースの能動学 習ではテスト文書が到着するたびにラベル付けを行うか判断す る.一般的な能動学習では,データの検出は自動的に行うが, 検出されたデータを人手によりラベル付けする必要がある.人 手によるコストを減少させるためには,新たなラベル付き文書 を必要としないことが望ましい.しかし,ラベル無しの文書だ けを用いたモデルの更新は,誤った特徴を学習することで性能 が悪化する可能性がある. 2. 1 問 題 設 定 本研究で扱う転移学習による文書ストリームの分類を以下の ように設定する.文書ストリームDは,時間ごとの文書チャン ク{D1, ..., Dn, ...}から成る.各文書チャンクは,ラベル無し の文書U ={u1, u2, ..., u|U|}で構成する.文書分類では,学習 文書として用いるラベル有り文書L ={l1, l2, ..., l|L|}から各ク ラスの特徴を学習し,ストリーム中で新たに到着するラベル無 しの文書uの分類を行う.ここでラベル付き文書は初期の学習 文書Lのみであり,新たなラベル付き文書の出現を考慮しない. 本研究では,追加のラベル付き文書を用いずに文書ストリー ムの分類を行うために転移学習による分類手法を提案する.こ こでは,学習文書とテスト文書を繋ぐ中間領域を設定し,この 中間領域を更新することでストリーム中の特徴の変化を考慮 する.
3.
転 移 学 習
3. 1 転移学習による文書分類 転移学習による文書分類では,情報源領域から得られるク ラス情報を対象領域の解析に利用することで分類を行う.ここ で各領域は,ラベル付きの情報源領域Sとラベル無しの中間 領域I,ラベル無しの対象領域T とする.ラベル付きの文書 は情報源領域の文書のみである.情報源領域Sと学習文書集 合Lが対応し,対象領域は時刻iの文書チャンクDi内のラベ ル無し文書である.中間領域はDiより前のn個の文書チャン ク{Di−n, ..., Di−1}で構成する.対象領域のクラスyは情報 源領域のクラス情報を中間領域を経由して伝搬することで推 定する.各領域は,情報源領域と対象領域の類似度sim(S, T ) と中間領域を用いた類似度sim(S, I),sim(I, T )が高くなる sim(S, I) < sim(S,I)+sim(I,T )2 となるような領域が存在するこ とを仮定する. 転移学習では,対象領域T に関連した情報源領域Sが存在 しない場合,有効に転移学習が行えない.このため,中間領域 Iは関連度が低い領域を接続する目的で用いる.中間領域はS とTの両方の特徴を含む必要があるが,このような集合が存在 するとは限らない.対象領域に対する適切な情報源領域の選択 の問題と同様に,各領域を接続する適切な中間領域の選択の問 題が残る.あるクラスと対応するSとTとは異なり,多数の クラスの特徴を含むように中間領域を定義する必要がある.本 稿は,中間領域を集合内の潜在的な特徴を表す潜在トピックと して抽出し,この潜在トピックを用いて各領域を接続する.3. 2 Nonnegative Matrix Tri-Factorization NMTFは,特徴空間と文書空間の共クラスタリングにより 行列を分解するアルゴリズムであり,文書分類やクラスタリン グに用いられている[5], [11].NMTFでは,特徴-文書空間の行 列X∈ Rm×nは低次元の3つの行列FAGに分解される. X ≈ F AGT (1) 行列F ∈ Rm×pは,特徴と特徴クラスタ間の関係を表す.m は特徴数であり,pは特徴クラスタの数である.行列A∈ Rp×c は,特徴クラスタと文書クラスタ間の関連を表す.cは文書ク ラスタの数である.文書分類では,cはクラス数に対応する. 行列G∈ Rc×nは,文書クラスタと文書間の関連を表す.nは 文書数である.各行列は元行列とのフロベニウスノルムが最小 となるように推定する. min∥X − F AGT∥ (2) ここで,F >= 0, A >= 0, G >= 0である. Tanらは,NMTFを基に,中間領域を用いた転移学習手法
(Transitive Transfer Learning, TTL)を提案している[10].こ こでは,情報源領域と対象領域が関連しない場合においても中 間領域を経由することで,転移学習が行えることを示している. 情報源領域の元行列Xs,中間領域の元行列Xi,対象領域の元 行列Xtを分解し,情報源領域の持つラベルを中間領域を経由 して対象領域に伝搬する. L = ∥Xs− FsAsGTs∥ + ∥Xi− FiAiGTi∥ + ∥Xi− F ′ iA ′ iGTi∥ + ∥Xt− FtAtGTt∥ (3) Fs= [F1, Fs2] , As= [A1, A2s] T Fi= [F1, Fi2] , AI= [A1, A2i]T Fi′ = [ ˆF1, ˆFi2] , A ′ i= [ ˆA1, ˆA2i] T Ft= [ ˆF1, Ft2] , At= [ ˆA1, A2t] T ここで,Fs,As,Gsは情報源領域,Fi,Ai,Gi,F ′ i,A ′ i, G′iは中間領域,Ft,At,Gtは対象領域の分解後の各行列であ る.式中の上付き文字T は転置行列を表す.特徴-特徴クラス タ空間の行列F は,領域間の共通の特徴を表すF1,Fˆ1 と領 域独自の特徴を表す行列Fs2,Fi2,Fˆi2,F 2 t を要素に持つ.特 徴クラスタ-文書クラスタ空間の行列Aは共通の特徴クラスタ と文書クラスタ間の関係を表す行列A1,Aˆ1と領域独自の特徴 クラスタと文書クラスタ間の関係を表す行列A2 s,A2i,Aˆ2i,A 2 t を要素に持つ.情報源領域のクラス情報Gsは学習文書から得 られる各文書が属するクラスを示す.ベクトルの要素は該当す るクラスに属している場合1,属さない場合0の値をとる.中 間領域のクラス情報GiはFi,Ai,F ′ i,A ′ iより対象領域と中 間領域の関係と中間領域と対象領域の関係の2つから求める. 対象領域のクラス情報Gtは学習されたGiを基に中間領域と対
象領域の関係から推定する.TTLでは,行列XsとXtが関連 しない場合においても,XsとXi,XiとXtの関連により文書 分類が行える.ここでは,如何に情報源領域と対象領域を繋ぐ 適切なXiを用意するかということが問題になる.本研究では, トピックモデルを用いることで,中間領域I ={i1, i2, ..., idi} からトピック分布を抽出し,中間領域として用いる.
4.
トピックモデル
トピックモデルとは, 1つの文書が複数のトピックの混合とし て表現されるという仮定である.1つの文書が1つのトピックで 表される混合多項分布に比べ,トピックモデルは文書が複数のト ピックの混合分布として,各トピックが単語の分布として表現さ れ,高い精度で文書をモデル化する可能性がある. その中でも最 近用いられているのがLatent Dirichlet Allocation(LDA)であ る[3].確率的潜在意味索引付け(Probablistic Latent Semantic Indexing, pLSI)では, LDAと違って, トピックの混合比を学習データの文書集合に依存して固定化している[6]. 一方, LDA ではこの混合比を事前分布から生成する点で異なる.LDAの パラメータ推定では,潜在変数であるトピックz,文書ごとの トピックの確率分布θ,トピックの単語分布ϕを文書集合に対 して尤度が最大となるように推定する.LDAを文書集合に適 用することで,文書をトピックの分布で表し,文書を特徴付け ることが可能となる.トピックは特定の意味を持たない単語の クラスタであるが,トピックが文書を特徴付ける要因と対応す ることを仮定する. 図1では,LDAのグラフィカルモデルを示す. 図中の変数 は,図1左下に,ディリクレ事前分布Dir(β),図1左下の単語 空間の多項分布M ultinomial(ϕzi), Tはトピック数,図1左上 にディリクレ事前分布Dir(α),図1中央にトピック空間の多項 分布M ultinomial(θd), Dは文書数, Ndは各文書の単語数を表 す.LDAの単語生成過程を以下で示す. まず,すべてのトピッ クtにおいてディリクレ事前分布Dir(β)からϕtを抽出し,同 様に,すべての文書dにおいてもディリクレ事前分布Dir(α)か らθdを抽出する. 次に,文書d内のi番目の単語wiにおいて, 抽出した文書dの多項分布M ultinomial(θd)からトピックzi を抽出し,そのトピックziの多項分布M ultinomial(ϕzi)か ら単語wiを抽出する. 潜在変数の推定には,ギブスサンプリング等が用いられる. ギブスサンプリングでは,サンプリングにより1つの単語に対 して1つのトピックを割り当てる.この割り当ては,更新を行 う単語以外のすべてのトピックの割り当てによって更新される. 文書dの単語wiのトピックがziとなる確率は,以下の式で求 まる. P (zi|zN\i,wN) ∝ n wi zi,N\i+ β n(.)z i,N\i+ V β nd zi,N\i+ α nd (.),N\i+ T α (4) 図 1 LDA α ディリクレ分布のパラメータ θ トピックの確率 z トピック w 単語 β ディリクレ分布のパラメータ ϕ トピックの単語の確率 Nd d 番目の文書の単語数 D 文書数 T トピック数 表 1 グラフィカルモデルのパラメータ θd= ndzi,N\i+ α nd (.),N\i+ T α (5) ϕzi= nwi zi,N\i+ β n(.)z i,N\i+ V β (6) ここで,zN\i={z1, ..., zi−1, zi+1, ..., zN}であり,i番目の 単語の割り当てを除外することを表す.nwi zi は単語wiにトピッ クziが割り当てられた回数,n(.)zi は全単語中でziが割り当て られた合計である.nd ziは,文書dでziが割り当てられた回数, nd(.)はdにトピックが割り当てられた合計である.V は単語の 種類数であり,Tはトピック数である.α,βはディリクレ分布 のパラメータである.θdは文書ごとのトピックの分布であり, 文書内のトピックの割り当てから求まる.ϕzi はトピックごと の単語の分布であり,あるトピックでの単語の割り当てから求 まる.
5.
提 案 手 法
本研究では,LDAを用いてトピック分布を抽出し,NMTF により転移学習を行うことで対象領域のクラスを推定する.ま た,ストリーム中の文書を分類するために中間領域の更新によ る分類手法を提案する. 提案手法は,LDAを用いて中間領域Iからトピックの単語 分布ϕI,文書ごとのトピック分布θIを学習する.続いて学習 されたトピックの単語分布ϕIを用いて,情報源領域Sと対象 領域TのθS,θTをMAP推定する.ここでは,トピックの単 語分布ϕの更新は行わない.領域ごとの文書ごとのトピック分 布を用いて,単語-文書空間の各領域の元行列Xs, Xi, Xtをト ピック-文書空間の行列θS, θI, θT に変換する.変換した行列を用いて式(3)と同様に以下の式より,各領域の行列を分解する. L = ∥θs− FsAsGTs∥ + ∥θi− FiAiGTi∥ + ∥θi− F ′ iA ′ iG T i∥ + ∥θt− FtAtGTt∥ (7) TTLが元行列Xの単語の出現確率を基に単語のクラスタリ ングを行っていたのに対し,提案手法はトピック分布θのト ピックの出現確率を基にトピックのクラスタリングを行う.文 書のクラスの推定は,情報源領域のクラス情報Gsを基に情報 源領域と中間領域,中間領域と対象領域のトピックのクラスタ と文書クラスタの関係から中間領域のクラス情報Giを推定す る.Giを基に中間領域と対象領域のトピックのクラスタと文 書クラスタの関係を基に対象領域のクラス情報Gtを推定する. 対象領域の文書のクラスは,Gtより各文書のベクトルの要素 中で最も値の高くなるクラスを推定結果とする. 次に,新たな文書チャンクDi+1の出現に合わせて,現在の 文書集合Diを用いて中間領域Iのトピックの単語分布ϕIの 更新を行う.トピックモデルのパラメータ更新では,オンライ ン学習手法が示されている[1].トピックモデルのオンライン学 習は,現在までに得られたパラメータを基に各単語にトピック を割り当てる.新たな文書dの単語wiのトピック割り当ては 以下の式で推定する. P (zi|zi−1,wi) ∝ n wi zi,i\i+ β n(.)z i,i\i+ V β nd zi,i\i+ α nd (.),i\i+ T α (8) 式中の各変数は,nwi zi は単語wiにトピックziが割り当てら れた回数,n(.)zi は全単語中でziが割り当てられた合計である. nd ziは,文書dでziが割り当てられた回数,n d (.)はdにトピッ クが割り当てられた合計である.V は単語の種類数であり,T はトピック数である.α,βはディリクレ分布のパラメータであ る.一括学習では単語wiのトピックをzi,N\iより推定し,単 語列wN内で繰り返し学習するが,オンライン学習では,現在 までの観測データzi−1を用いてwiのトピックを推定する. 提案手法は,更新された中間領域のパラメータを基に情報源 領域のトピック分布の再推定を行うことでθsを更新する.学 習文書集合が変化しない代わりに,中間領域から推定する情報 源領域のトピック分布を変化させることでストリーム中の特徴 の変化に対応する.
6.
実
験
実験ではReuters Corpus(RCV1)を用いて2つの実験を行 う.第1の実験では,多クラス分類を行う.比較手法との精度 の比較により提案手法を用いて高精度に文書分類が行えること を示す.第2の実験では,ストリーム中での多クラス分類を行 う.提案手法の中間領域を更新することで時間によるクラスの 特徴の変化に対応できることを示す. 6. 1 実 験 準 備 実験に用いるReuters Corpusは1996年8月20日から1997 年8月19日までの1年分のニュース記事であり,1つの記事 に128種類からなるラベルが複数付いている.Reuter Cor-pusはニュース記事であることから,該当のクラス内で繰り 返し使用される固有名詞やそれに関連した単語などの定常的 な特徴を有する.また,ある時刻に起こった出来事に関する 記事が発生することから変動的な特徴を有する. 本実験で は,”CCAT”,”MCAT”,”GCAT”,”ECAT”の4つのラベ ルを基準とし,各ラベルを含む頻度が上位となる6つのラベル セット計24個をクラスとして用いる.表2にクラスとなるラ ベルの組み合わせを示す.実験データ中の不要語は取り除く. 算用数字は*に変換し,数字列の長さにのみ着目する.文字列 は全て小文字に変換する. 第1の実験では,実験データに先頭から各クラスに該当する 250文書を情報源領域,中間領域,対象領域に用いる.各領域 の文書数は1000文書であり合計は3000文書である.各クラス のサブクラス中で最もコサイン類似度の低い組み合わせを情報 源領域と対象領域とし,2つの領域に対して最も類似度が高く なるサブクラスを中間領域として使用する.コサイン類似度は 以下の式より求める. cos(x, y) =∑
V i xi· yi√∑
V i x 2 i ·√∑
V i y 2 i (9) ここで,x,yはサブクラスに対応し,xi,yiはi番目の単語 の出現確率である.V は単語の種類数である.コサイン類似度 は0∼1の値であり,類似度が高いほど1に近い値になる.情 報源領域と対象領域に類似度が最も低くなるペアを用いること で,情報源領域の特徴により分類が行えない場合においても中 間領域を用いることで高精度に分類が行えることを示す.比較 手法には単純ベイズ,N M T FST,T T LSIT を用いる.単純ベ イズは各クラスの単語の出現確率を基にテスト文書を生成する 尤度が最も高くなるクラスを決定する.N M T FSTは中間領域 を用いずに各文書の単語の出現確率を基にNMTFにより対象 領域のクラスを推定する.T T LSIT は,式3より中間領域を用 いて対象領域のクラスを推定する.比較手法は単語を基に分類 を行うため,低頻度語の影響により分類精度が悪化する.この ため,実験データ中で出現回数が20以下の単語を全て除外す る.単語の種類数は3199である. 第2の実験では,テスト文書を時間順に10個の区間に分け て多クラス分類を行う.提案手法は,対象領域の区間に応じて 中間領域の区間も遷移させ,トピック分布を更新する.比較 手法には中間領域を変更しない場合を用いる.各区間の文書 数はクラスごとに250文書の計1000文書である.情報領域は 先頭から2つの区間の2000文書とする.中間領域は続く2つ の区間の2000文書である.提案手法では,対象領域の区間が 推移するたびに中間領域の区間も1つ推移する.テスト文書 は,残りの6個の区間を対象領域として使用する.各クラス には情報源領域とテスト文書の各区間のコサイン類似度の合 計が最も低くなるサブクラスを用いる.実験に用いるサブクIdentifier Corpus Labels C15 PERFORMANCE C151 ACCOUNTS/EARNINGS C152 COMMENT/FORECASTS C17 FUNDING/CAPITAL C172 BONDS/DEBT ISSUES C18 OWNERSHIP CHANGES C181 MERGERS/ACQUISITIONS C24 CAPACITY/FACILITIES C31 MARKETS/MARKETING CCAT CORPORATE/INDUSTRIAL GCAT GOVERNMENT/SOCIAL GSPO SPORTS
GPOL DOMESTIC POLITICS GVIO WAR, CIVIL WAR
GDIP INTERNATIONAL RELATIONS GVOTE ELECTIONS M11 EQUITY MARKETS M12 BOND MARKETS M13 MONEY MARKETS M131 INTERBANK MARKETS M132 FOREX MARKETS M14 COMMODITY MARKETS M141 SOFT COMMODITIES M143 ENERGY MARKETS MCAT MARKETS
E11 ECONOMIC PERFORMANCE E12 MONETARY/ECONOMIC E13 INFLATION/PRICES E131 CONSUMER PRICES
E21 GOVERNMENT FINANCE E211 EXPENDITURE/REVENUE E212 GOVERNMENT BORROWING
E51 TRADE/RESERVES E512 MERCHANDISE TRADE
E71 LEADING INDICATORS ECAT ECONOMICS
表 3 ラベル識別子
ラスは,”C15 C151 CCAT”,”M14 M143 MCAT”,”GDIP GVIO GCAT”,”E71 ECAT”である.
トピックモデルの各パラメータの値はトピック数100,ギブ スサンプリングの繰り返し回数200回とし,事前分布のパラ メータはα=0.1,β=0.01とする.NMTFの各パラメータは, p=20とする. 6. 2 評 価 方 法 実験の評価にはf値を用いる.f値は再現率と適合率の調和 平均であり,再現率は実際に正であるもののうち,正であると 予測されたものの割合,適合率は正と予測したデータのうち, 実際に正であるものの割合である.各ラベルのf値を以下の式 で求める. Ri= ai ai+ ci (10) 単純ベイズ N M T FST T T LSIT 提案手法 CCAT 0.788 0.828 0.808 0.940 MCAT 0.860 0.600 0.880 0.848 GCAT 0.972 0.996 0.976 0.988 ECAT 0.132 0.664 0.740 0.872 全体 0.688 0.772 0.851 0.912 表 9 再 現 率 単純ベイズ N M T FST T T LSIT 提案手法 CCAT 0.648 0.896 0.792 0.929 MCAT 0.726 0.968 0.978 0.977 GCAT 0.700 0.713 0.744 0.898 ECAT 0.623 0.626 0.964 0.872 全体 0.674 0.801 0.869 0.913 表 10 適 合 率 単純ベイズ N M T FST T T LSIT 提案手法 CCAT 0.711 0.861 0.800 0.934 MCAT 0.788 0.741 0.926 0.908 GCAT 0.814 0.831 0.844 0.941 ECAT 0.218 0.645 0.837 0.863 全体 0.681 0.786 0.860 0.913 表 11 f 値 区間 1 区間 2 区間 3 区間 4 区間 5 区間 6 合計 提案手法 0.939 0.955 0.964 0.929 0.928 0.93 0.941 更新無し 0.939 0.963 0.914 0.876 0.948 0.882 0.920 表 12 f 値の推移 Pi= ai ai+ bi (11) aiは推定結果が正である数,ciは正であるが負と推定された 数,biは正であると推定した中で正解が負である数である.こ の2つの式の調和平均であるf値を次のように定義する. fi= 2× Pi× Ri Pi+ Ri 6. 3 実 験 結 果 表9,10,11に分類結果を示す.各f値は単純ベイズで0.681, N M T LST で0.786,T T LSIT で0.860,提案手法で0.913と なっており,提案手法が最も高い値を示している.また,再現 率,適合率においても提案手法のf値は最も高精度になってい る.12より,全区間のf値は更新を行う提案手法で0.941,更 新を行わない場合で0.920となっており中間領域を更新するこ とで高精度になっている.表4より,各クラスの情報源領域 と対象領域のコサイン類似度は,CCATで0.556,MCATで 0.732,GCATで0.881,ECATで0.218とクラスごとに大き く異なっている. 6. 4 考 察 表11より,提案手法のf値はT T LSIT と比較して+5.3%向 上しており,中間領域にLDAによる潜在トピックを用いるこ とでより高精度に分類が行えている.情報源領域と対象領域の コサイン類似度が0.218と最も低くなるECATでは,中間領
CCAT MCAT GCAT ECAT C15 C152 CCAT M11 MCAT GSPO GCAT E21 E212 ECAT C15 C151 CCAT M14 M141 MCAT GPOL GCAT E71 ECAT C18 C181 CCAT M13 M131 MCAT GVIO GCAT E11 ECAT
C31 CCAT M14 M143 MCAT GPOL GVOTE GCAT E51 E512 ECAT C17 C172 CCAT M12 MCAT GDIP GCAT E13 E131 ECAT C24 CCAT M13 M132 MCAT GDIP GVIO GCAT E21 E211 ECAT
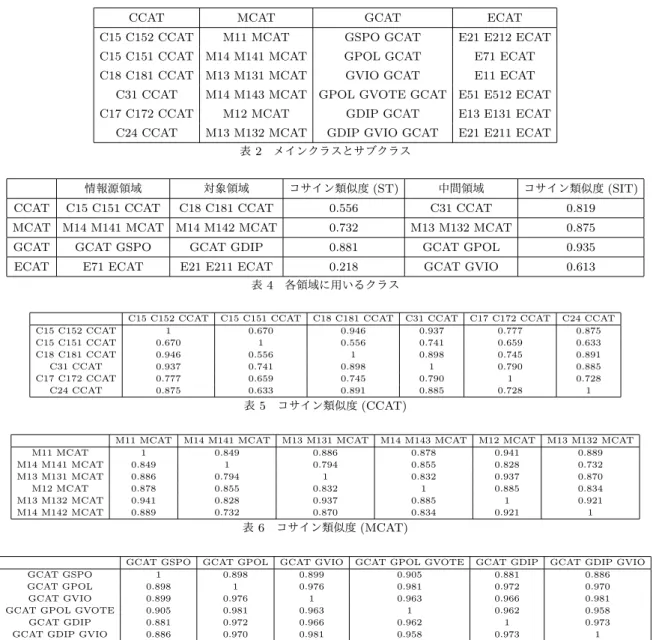
表 2 メインクラスとサブクラス
情報源領域 対象領域 コサイン類似度 (ST) 中間領域 コサイン類似度 (SIT) CCAT C15 C151 CCAT C18 C181 CCAT 0.556 C31 CCAT 0.819 MCAT M14 M141 MCAT M14 M142 MCAT 0.732 M13 M132 MCAT 0.875 GCAT GCAT GSPO GCAT GDIP 0.881 GCAT GPOL 0.935 ECAT E71 ECAT E21 E211 ECAT 0.218 GCAT GVIO 0.613
表 4 各領域に用いるクラス
C15 C152 CCAT C15 C151 CCAT C18 C181 CCAT C31 CCAT C17 C172 CCAT C24 CCAT
C15 C152 CCAT 1 0.670 0.946 0.937 0.777 0.875 C15 C151 CCAT 0.670 1 0.556 0.741 0.659 0.633 C18 C181 CCAT 0.946 0.556 1 0.898 0.745 0.891 C31 CCAT 0.937 0.741 0.898 1 0.790 0.885 C17 C172 CCAT 0.777 0.659 0.745 0.790 1 0.728 C24 CCAT 0.875 0.633 0.891 0.885 0.728 1 表 5 コサイン類似度 (CCAT)
M11 MCAT M14 M141 MCAT M13 M131 MCAT M14 M143 MCAT M12 MCAT M13 M132 MCAT
M11 MCAT 1 0.849 0.886 0.878 0.941 0.889 M14 M141 MCAT 0.849 1 0.794 0.855 0.828 0.732 M13 M131 MCAT 0.886 0.794 1 0.832 0.937 0.870 M12 MCAT 0.878 0.855 0.832 1 0.885 0.834 M13 M132 MCAT 0.941 0.828 0.937 0.885 1 0.921 M14 M142 MCAT 0.889 0.732 0.870 0.834 0.921 1 表 6 コサイン類似度 (MCAT)
GCAT GSPO GCAT GPOL GCAT GVIO GCAT GPOL GVOTE GCAT GDIP GCAT GDIP GVIO
GCAT GSPO 1 0.898 0.899 0.905 0.881 0.886
GCAT GPOL 0.898 1 0.976 0.981 0.972 0.970
GCAT GVIO 0.899 0.976 1 0.963 0.966 0.981
GCAT GPOL GVOTE 0.905 0.981 0.963 1 0.962 0.958
GCAT GDIP 0.881 0.972 0.966 0.962 1 0.973
GCAT GDIP GVIO 0.886 0.970 0.981 0.958 0.973 1
表 7 コサイン類似度 (GCAT) 域を用いない単純ベイズとN M T FSTの分類精度が非常に低く なっている.これに対し,中間領域を用いたT T LSITと提案手 法では,それぞれ0.837,0.863と高精度に分類が行えている. このことから,関連度の低い領域の分類を行うために中間領域 を用いた転移学習は有効であると考えられる. T T LSIT は,中間領域を用いることでN M T FST と比較し て精度が高くなっているが,提案手法と比較すると精度が低い. T T LSIT は,ECATのようにN M T FST で転移学習が行えな いクラスに対して有効である.しかし,CCAT,GCATのよう にN M T FST で分類が行える場合は効果が低い.提案手法は, 情報源領域と対象領域の類似度に関わらず,いずれの場合も高 精度に分類が行える.また,提案手法の中間領域を更新するこ とで更新を行わない場合と比較して精度が+2.1%上昇している. このため,提案手法はクラスの時間変化に対応可能である.
7.
結
論
本研究では,中間領域からトピック分布を学習し,トピック により情報源領域と対象領域を繋ぐ分類手法を提案した.文書 分類の結果,提案手法のf値は0.913と最も高精度に分類でき る.これにより,提案手法の有効性を示した. 文 献[1] Banerjee, A., Basu, S.: Topic Models over Text Streams: A Study of Batch and Online Unsupervised Learning, In Proc. 7th SIAM International Conference on Data Mining, 2007 [2] Bifet, A., Holmes, G., Pfahringer, B., Kirkby, R., and
Gavalda, R.: New ensenble methods for evolving data streams. In KDD ’09, ACM, 2009
[3] Blei, D. M.,Ng, A.Y. and Jordan, M.I.: Latent Dirichlet Allocation, Journal of Machine Learning Research 3, pp. 993-1022, 2003.
[4] Canini, K.R., Shi, L., Griffiths, T.L.: Online Inference of Topics with Latent Dirichlet Allocation, Journal of Machine Learning Research, Proceedings Track 5, pp.65-72, 2009 [5] Ding, C., Li, T., Peng, W., Park, H.: Orthogonal
Non-negative Matrix Tri-Factorizations for Clustering, In KDD, pp.126-135, 2006
[6] Hofmann, T.: Probabilistic Latent Semantic Indexing, SI-GIR, 1999
[7] Hoffman, M.D., Blei, D.M., Bach, F.R.: Online Learning for Latent Dirichlet Allocation, proc. 24th NIPS,
pp.856-E21 pp.856-E212 ECAT E71 ECAT E11 ECAT E51 E512 ECAT E13 E131 ECAT E21 E211 ECAT
E21 E212 ECAT 1 0.312 0.364 0.440 0.360 0.418
E71 ECAT 0.312 1 0.302 0.239 0.375 0.218
E11 ECAT 0.364 0.302 1 0.918 0.940 0.923
E51 E512 ECAT 0.440 0.239 0.918 1 0.840 0.941
E13 E131 ECAT 0.360 0.375 0.940 0.840 1 0.844
E21 E211 ECAT 0.418 0.218 0.923 0.941 0.844 1
表 8 コサイン類似度 (ECAT)
864, 2010
[8] Lewis, D.D., et al.: RCV1 (Reuters Corpus Volume 1), 2004,
www.daviddlewis.com/resources/testcollections/rcv1/
[9] Rosenstein, M.T., Marx, Z., Kaelbling, L.P., Dietterich, T.G.: To Transfer or Not To Transfer, In NIPS’05 Work-shop on Transfer Learning, volume 898, 2005
[10] Tan, B., Song, Y., Zhong, E., Yang, Q.: Transitive Transfer Learning, In KDD’15, 2015
[11] Wang, H., Nie, F., Huang, H., Makedon, F.: Fast Non-negative Matrix Tri-Factorization for Large-Scale Data Co-Clustering, In IJCAI, pp.1553-1558, 2011
[12] Zhang, Y., Yeung, D., A Regularization Approach to Learn-ing Task Relationships in Multitask LearnLearn-ing, ACM Trans-actions on Knowledge Discovery from Data(TKDD), Vol-ume 8 Issue3, 2014
[13] Bouguelia, M., Belaid, Y., Belaid, A.: A Stream-Based Semi-Supervised Active Learning Approach for Document Classification, 12th International Conference on Document Analysis and Recognition (ICDAR), 2013
[14] Wang, P., Zhang, P., and Guo, L.: Mining Multi-label Data Streams Using Ensemble-based Active Learning, SDM, pp 1131-1140, SIAM/Omnipres,2012
[15] Xioufis, E. S., Spiliopoulou, M., Tsoumakas, G., Vlahavas, I.: Dealing with Concept Drift and Class Imbalance in Multi-Label Stream Classification, Proc. 22nd IJCAI, 2011