平成
25
年度
修士学位論文
大貧民のモンテカルロ法プレイヤにおける
シミュレーション精度向上に関する研究
Improvement of Simulation Accuracy
in Monte Carlo Daihinmin Players
1165064
地曳 隆将
指導教員
松崎 公紀
2014
年
2
月
28
日
高知工科大学大学院 工学研究科 基盤工学専攻
情報システム工学コース
要 旨
大貧民のモンテカルロ法プレイヤにおける
シミュレーション精度向上に関する研究
地曳 隆将
近年,大貧民の研究においてモンテカルロ法を適用したプレイヤの研究が行われている. モンテカルロ法プレイヤは,現在の盤面からゲーム終了までのシミュレーション(プレイア ウト)を複数回行うことで各手役の評価値を算出する.プレイヤの強さはプレイアウトの精 度を向上させることで強化できる. 本研究では,大貧民モンテカルロ法プレイヤのプレイアウトの精度を向上させるために2 つの手法を取った. 1つめの手法は,プレイアウト開始時に生成する相手手札を実際の盤面に近づけることで ある.大貧民は不完全情報ゲームであるため,相手プレイヤの手札を知ることができない. そのため,プレイアウト開始時に生成した相手プレイヤの手札と,実際の盤面の相手プレイ ヤの手札の差がプレイアウト精度を下げる要因となる.プレイアウト開始時に生成した相手 プレイヤの手札を実際の盤面に近づけることでプレイアウト精度が向上する. 2つめの手法は,プレイアウト中の各プレイヤのプレイ方策を,実際のプレイヤのプレイ 方策に近づけることである.最も単純なモンテカルロ法である原始モンテカルロでは,プレ イアウト中の各プレイヤのプレイは乱数によってランダムに行われる.そのため,各プレイ ヤのプレイとは提出手役に差ができる.各プレイヤが提出する手役を真似できるようになれ ばプレイアウト精度が向上する. 本研究では,この2つの手法が大貧民モンテカルロ法プレイヤに与える影響を調査した. 1つめの手法では,モンテカルロ木探索プレイヤによって「最善手」を算出し,手札情報の異なるモンテカルロ法プレイヤが算出した「最善手と判断した手」と比較した.これに よって,手札情報の精度がモンテカルロ法プレイヤに与える影響を調査した.調査の結果, 手札推定を行うことでモンテカルロ木探索プレイヤの「最善手」の評価値にモンテカルロ法 プレイヤの評価値(モンテカルロ木探索プレイヤの「最善手」と同じ手の評価値)は近づく ことがわかった.一方,モンテカルロ法プレイヤが「最善手と判断した手」にはほとんど影 響は無く,「最善手」の推定には寄与していないことがわかった. 2つめの手法では2つの実験を行った.1つめの実験では,3層ニューラルネットワークを 用いた評価関数の性能を調査した.棋譜でプレイヤが提出した手役と,評価関数を用いて得 られる手役の一致度を調査した.調査の結果,学習に使用する盤面データを増やすことで提 出手役の一致率が上昇し,盤面データ数15,000程度で一致率が頭打ちになることが確認で きた.盤面データ数15,000の評価関数では,未知の盤面に対する提出手役一致率がおよそ 69%となった.2つめ実験では,評価関数を適用したモンテカルロ法プレイヤの性能を調査 した.モンテカルロ法プレイヤのプレイアウト中の提出手役を,3層ニューラルネットワー クを用いた評価関数によって選択するプレイヤを提案し,原始モンテカルロプレイヤと比較 実験を行った.調査の結果,原始モンテカルロプレイヤよりも評価関数を適用したモンテカ ルロ法プレイヤの方が強いことが確認できた. キーワード 大貧民,モンテカルロ法,モンテカルロ木探索,3層ニューラルネットワーク
Abstract
Improvement of Simulation Accuracy
in Monte Carlo Daihinmin Players
Takamasa ZIBIKI
In recent studies of Daihinmin, the Monte-Carlo method has been applied to Dai-hinmin players. Monte-Carlo player calculates an evaluation value of each meld by performing a lot of playouts, which are random simulations to the end of the game. The strength of Monte-Corlo players depends on the accuracy of the playouts.
In this study, we took two approaches in order to improve the accuracy of the playouts of Daihinmin Monte-Carlo players.
In the first approach, we estimate the opponents’ hands, from which playouts are performed, as close to the real ones as possible. Since Daihinmin is a game with imper-fect information, it is impossible to know the opponents’ hands. The difference between the estimated hands and the real ones would become a factor that reduces the accuracy of playouts. If we can estimate the opponents’ hands more precisely, we can improve the accuracy of playouts.
The second method is to approximate the play strategies in the playouts. The simplest Monte-Carlo method, called primitive Monte-Carlo, performs playouts just with random numbers. The difference between the random plays and the real ones would become a factor that reduces the accuracy of playouts. If we can mimic the play strategies of the players, we can improve the accuracy of playouts.
Monte-Carlo players.
For the first approach, we compared the melds computed by Monte-Carlo players with different hand informations with the best hand computed by Monte-Carlo Tree Search player with perfect information. We found after this experiments that partial information of opponents’ hands may improve evaluation values but the effects on se-lecting the best hand are small.
The two experiments were performed for the second approach. The first experiment investigated the performance of the evaluation function developed with a three-layer neural network. We investigated how often we can select the real melds played in the game records using the evaluation function. It was confirmed that the concordance rate of submission hand combination increases by increasing the training data to be used for learning, and concordance rate saturates over 15,000 training data. In the evaluation function learned from 15,000 training data, submitted hand role concordance rate for the unknown boards has become approximately 69%. The second experiment investi-gated the performance of the Monte-Carlo player applying the evaluation function. The proposed player selected the meld computed with the three-layer neural network in the playouts. We compared the proposed Carlo player with the primitive Monte-Carlo player. After the experiments, we confirmed that the Monte-Monte-Carlo player with the evaluation function is stronger than the primitive Monte-Carlo player.
key words Daihinmin, Monte-Carlo Method, Monte-Carlo Tree Search, Three-Layer Neural Networks
目次
第1章 はじめに 1 1.1 背景. . . 1 1.2 目的. . . 2 1.3 関連研究 . . . 3 1.3.1 大貧民に関する研究 . . . 3 1.3.2 モンテカルロ木探索に関する研究 . . . 3 1.3.3 棋譜を利用した評価関数の学習に関する研究 . . . 4 1.4 本論文の構成 . . . 4 第2章 大貧民とその盤面データ 6 2.1 大貧民のルール . . . 6 2.2 盤面データ . . . 7 第3章 モンテカルロ法とモンテカルロ木探索 8 3.1 モンテカルロ法 . . . 8 3.1.1 モンテカルロ法のアルゴリズム . . . 8 3.1.2 モンテカルロ法プレイヤ . . . 9 3.1.3 モンテカルロ法プレイヤの収束 . . . 10 3.2 モンテカルロ木探索 . . . 12 3.2.1 モンテカルロ木探索のアルゴリズム . . . 12 3.2.2 モンテカルロ木探索プレイヤ . . . 13 3.2.3 モンテカルロ木探索プレイヤの収束 . . . 13 第4章 3層ニューラルネットワーク 16 4.1 3層ニューラルネットワークにおける出力値の計算 . . . 16目次 4.2 誤差逆伝播法 . . . 18 第5章 手札情報の精度がモンテカルロ法プレイヤに与える影響の調査 20 第6章 3層ニューラルネットワークを用いた提出手役評価関数の性能調査 24 6.1 提出手役評価関数の性能調査 . . . 24 6.2 モンテカルロ法に提出手役評価関数を適用したプレイヤの性能調査 . . . . 27 6.2.1 対戦プレイヤ . . . 27 6.2.2 対戦実験 . . . 29 第7章 おわりに 31 謝辞 33 参考文献 34
図目次
2.1 盤面データ . . . 7 3.1 モンテカルロ法のアルゴリズム . . . 8 3.2 モンテカルロ法プレイヤの評価値の推移 . . . 11 3.3 モンテカルロ木探索のアルゴリズム . . . 12 3.4 モンテカルロ木探索プレイヤの動作 . . . 14 3.5 モンテカルロ木探索プレイヤの評価値の推移の一例 . . . 15 4.1 3層ニューラルネットワーク . . . 16 4.2 シグモイド関数 . . . 17 6.1 提出手役一致数(MCMPの棋譜 中間層数15) . . . 26 6.2 提出手役一致数(MCMPの棋譜 中間層数50) . . . 26表目次
3.1 モンテカルロ法プレイヤの各盤面における最小値と最大値の差の幾何平均 . 10 3.2 モンテカルロ木探索プレイヤの各盤面における最善手の最小値と最大値の差 の幾何平均 . . . 14 5.1 各盤面における最善手の評価値の幾何平均誤差 . . . 22 5.2 最善手の的中数 . . . 22 6.1 評価項目に使用した盤面情報 . . . 25 6.2 提出手役一致数 . . . 26 6.3 1対1の対戦結果(VS Nakanaka) . . . 30 6.4 2対2の対戦結果(VS Nakanaka) . . . 30 6.5 1対1の対戦結果(VS paoonR2) . . . 30 6.6 2対2の対戦結果(VS paoonR2) . . . 30第
1
章
はじめに
1.1
背景
ゲームはルールが明確に定められており勝ち負けによって評価を行うことができるため, 探索アルゴリズムの性能評価に用いられてきた.またこれまでに,ゲームにおいてプレイヤ を強化する過程の中で,新たな探索アルゴリズムも発見されている. 2人零和確定完全情報ゲームにおいては,ゲーム木探索手法や評価関数を適用したプレイ ヤが人間のトップレベルのプレイヤに対して勝利しその実力を示している.オセロやチェ スにおいては1990 年代に当時の世界チャンピオンに勝利している[21].将棋においては, ゲーム木探索手法と棋譜による学習を行った評価関数を組み合わせた手法によって,プロ棋 士に勝利するレベルのプレイヤが複数作成されている[17, 20, 22].囲碁においては,モン テカルロ木探索をプレイヤに適用することで,プレイヤの棋力がアマチュア有段者レベルま で向上した[19]. 一方,多人数不完全情報ゲームにおいては,2人零和確定完全情報ゲームと比較すると良 い結果は得られていない.モンテカルロ木探索を多人数不完全情報ゲームに適用する場合, 探索を開始する初期盤面の情報が確定しないことが多いため,モンテカルロ木探索を効果的 に適用することが困難である.一方,ゲーム木探索手法を用いないモンテカルロ法や評価関 数をプレイヤに適用する研究が行われている.大貧民においては,モンテカルロ法をプレイ ヤに適用することでプレイヤの強化が確認されている[10].1.2 目的
1.2
目的
本研究では,多人数不完全情報ゲームである大貧民を研究の対象とし,主にモンテカルロ 法プレイヤの強化手法について調査を行った.モンテカルロ法およびモンテカルロ木探索 は,ある局面から乱数を用いて終局までのシミュレーション(プレイアウト)を繰り返し, 合法手の評価値を算出する探索手法である.大貧民においてプレイヤを強化するためには, プレイアウト回数を増やすだけでなく,プレイアウトの精度を高める必要がある.そこでま ず大貧民においてプレイアウトの精度を下げる要因をここで明らかにする. 大貧民においてプレイアウトの精度を下げる要因は大きく分けて2つある.1つめの要因 は,プレイアウト開始時に生成する相手プレイヤの手札と実際のプレイヤの手札の差であ る.大貧民では相手プレイヤの持つ手札は分からないので,プレイアウトを行う前に相手プ レイヤの持つ手札を仮想的に生成する必要がある.ここで生じる実際の相手プレイヤの手札 と仮想的に生成した手札の差は,プレイアウトの精度を下げる要因となる.2つめの要因は, プレイアウト中の各プレイヤのプレイ方策と,実際にプレイしている各プレイヤのプレイ方 策が異なることで生じる提出手役の差である.原始モンテカルロ法と呼ばれる最も単純なモ ンテカルロ法では,プレイアウト中の各プレイヤのプレイは乱数によってランダムに行われ る.そのため,実際にプレイしているプレイヤとプレイアウト中のプレイヤの提出手役の差 は,プレイアウトの精度を下げる要因となる. そこで本研究では,これらのプレイアウトの精度を下げる要因がモンテカルロ法プレイヤ に与える影響について調査した.本研究の目的は,多人数不完全情報ゲームである大貧民に おいて強いプレイヤを作成するために必要な情報を調査し,実際に強いプレイヤを作成する ことである. 1つめの要因である手札情報の精度に関しては,手札情報が異なるプレイヤにモンテカル ロ法による評価値の算出を行わせ,モンテカルロ木探索で得られた最善手の評価値と比較を 行い,最善手の的中率と評価値の誤差について調査した.この実験を行うにあたり「次の一 手問題」を複数個用意し,それに対して実験を行う手法を用いた.1.3 関連研究 2つめの要因であるプレイアウト中のプレイ方策の精度に関しては,プレイアウト部分に 3層ニューラルネットワークを用いた提出手役評価関数を適用し,性能を調査した.対戦実 験では提出手役評価関数とモンテカルロ法を組み合わせたプレイヤの性能を調査した.
1.3
関連研究
1.3.1
大貧民に関する研究
本研究の対象とする大貧民においては,モンテカルロ法をプレイヤに適用することで, UEC コンピュータ大貧民大会(UECda)[23] で優勝するレベルのプレイヤが得られた [10, 13, 14]. 大貧民は不完全情報ゲームであり相手手札を知ることはできないため,相手プレイヤの手 札を推定する研究も行われている.須藤ら[13],および,西野ら[16]は,相手プレイヤが場 に提出した手役の情報から,相手プレイヤの手札を推定する手法を提案し,手札推定を用い ることでより強いモンテカルロプレイヤが得られることが報告されている.一方で西野ら は,相手プレイヤの手札を推定することの重要性について,手札の集合を同値類に分類した 結果から得られる考察により,大貧民においては手札推定があまり重要でないと述べている [15]. プレイヤ強化の一環として,プレイアウト中の提出手役を実際のプレイヤに近づける研究 も行われている.伊藤ら[5]は,実際のプレイヤの提出手役を模倣する手法としてナイーブ ベイズを用い,過去のUECda優勝クライアントであるsnowlに対して提出手役一致率がお よそ4割であったと報告している.1.3.2
モンテカルロ木探索に関する研究
ゲームのプレイヤに対してモンテカルロ木探索を適用する研究も行われている. 2006年にモンテカルロ木探索を適用した囲碁のプレイヤが初めて開発された[19].19路 盤の囲碁においてはそれまでのコンピュータプレイヤは非常に弱かったが[19],モンテカル1.4 本論文の構成 ロ木探索とUCB1[3]を組み合わせることで,プレイヤの棋力がアマ有段者レベルまで向上 した[1, 19].将棋においては,モンテカルロ木探索だけでは強力なプレイヤを作り出すこと は難しいが,従来の手法と組み合わせて部分的にモンテカルロ木探索を用いることでプレイ ヤの強化が可能であると示唆されている[11].その他のゲームにおいても,オセロやパック マンなどでモンテカルロ木探索を適用することでプレイヤを強化できることが明らかになっ ている[4, 18].
1.3.3
棋譜を利用した評価関数の学習に関する研究
棋譜を利用して,ゲームの行動選択に使用する評価関数の学習を行う研究も行われている. 1950年代にオセロにおいて,ゲームの棋譜を利用して線形和で表現された評価関数の重 みを調整する方法が提案された[2]. 将棋においては,棋譜で指された手を出すように重みを調整することで10,000を超える 重みの調整に成功し,コンピュータ将棋選手権で優勝するレベルのプレイヤが得られた[17]. 2013年に行われた第2回将棋電王戦[22]においては,A級棋士(日本で10名が在籍)で ある三浦弘行九段に勝利するレベルのプレイヤが作成されている[20]. また,大貧民と同じ多人数不完全情報ゲームである麻雀においても,棋譜(牌譜)を利用 して評価関数の重みを調整している [9].結果として評価関数を用いたプレイヤのレーティ ングは1318と弱かったが,棋譜と評価関数の打牌・行動一致率はツモ局面でおよそ56%と なり,鳴き局面においておよそ89%となった.1.4
本論文の構成
本論文の構成を以下に示す.第2章では,大貧民のルールについて説明し,本研究に使用 した次の一手問題と教師データについて説明する.第3章では,モンテカルロ法とモンテカ ルロ木探索について説明する.第4章では,3層ニューラルネットワークについて説明する. 第5章では,手札情報の差がモンテカルロ法プレイヤに与える影響を調査する.第6章で1.4 本論文の構成
は,3層ニューラルネットワークを用いた提出手役評価関数の性能を調査する.最後に,第
第
2
章
大貧民とその盤面データ
2.1
大貧民のルール
本研究では,大貧民のルールにはUECコンピュータ大貧民大会(UECda)の標準ルール を使用した[23].そのうち本研究に大きな影響を与える重要なルールを以下に示す. あがり時の制約 プレイヤの手札枚数が0になった状態をあがりと呼ぶ.あがり時にはどの ような手役を提出してもよい.あがり時に出す手役の制約がないことにより,モンテカ ルロ法やモンテカルロ木探索においてプレイアウトを単純に実装することができる. 8切り ランクが8のカードを含む手役が場に提出されると8切りが発生する.8切りが発 生すると場が流れ,8切りを発生させたプレイヤが次の手役を出せる.ランクが 8の カードのランク自体はそれほど強くないが,プレイにおいて適切に使用すると強力な カードにもなるため,モンテカルロ法とモンテカルロ木探索での差が生じる可能性が ある. しばり 場に同じスート(複数枚の手役のときには,全てが同じスート)の手役が連続して 提出されるとしばりが発生する.しばりが発生すると,場が流れるまで,同じスート (の組み合わせ)の手役しか場に提出できなくなる.このルールにより,特定スートの カードを持つかどうかに意味があり,相手手札の不完全情報性の一要素となる. 獲得点数 1ゲームにおける獲得点数は,大富豪であれば5点,富豪であれば4点,平民で あれば3点,貧民であれば2点,大貧民であれば1点である.2.2 盤面データ Order Normal Lock_Suits H Last_Meld Single:H5 Put_Meld Single:H8 Player0 Yes C3 S7 H7 D7 H8 C8 SJ HQ DQ Player1 Yes S3 S4 H4 S5 S6 S8 S9 S10 CQ HA D2 Player2 Yes H6 HJ CJ SQ SK HK Player3 No C7 D8 H10 DK CA C2 Player4 No C9 DJ CK S2 H2 図2.1 盤面データ
2.2
盤面データ
本研究では,盤面データを用いて「次の一手問題」と「教師データ」を作成した.次の一 手問題は,第 5章の手札情報の精度がモンテカルロ法プレイヤに与える影響の調査に用い る.教師データは,第6章の3 層ニューラルネットワークを用いた提出手役評価関数の性能 調査に用いる. 盤面データの例を図2.1に示す.盤面データは以下の情報からなる. • プレイヤに関する情報(次にプレイするプレイヤをPlayer0とする) – プレイヤが持つカードの集合 – プレイヤがそのターンでプレイ可能かどうか(パスしているか,すでにあがりであ る場合にはプレイできない) • 場に関する情報 – 強さの順番(革命の有無) – しばりがある場合にはそのスート – 最後に場に出された役(場が新しい場合には空とする) • 提出手役に関する情報 – Player0が実際に出した手役第
3
章
モンテカルロ法と
モンテカルロ木探索
3.1
モンテカルロ法
3.1.1
モンテカルロ法のアルゴリズム
モンテカルロ法は,乱数によるシミュレーションを複数回行うことで近似解を算出するア ルゴリズムである.モンテカルロ法の特長のひとつに,解析的に解を算出しにくい問題を含 む広範囲の問題に対して適用可能であることが挙げられる.一般に,モンテカルロ法の解の 精度はシミュレーション回数の平方根に比例する[12]. ゲームのプレイヤに適用したモンテカルロ法の動作を図3.1に示す.モンテカルロ法のシ ミュレーションでは,ある盤面のある合法手から始め,乱数によって各プレイヤのプレイを 図3.1 モンテカルロ法のアルゴリズム3.1 モンテカルロ法 行い,終局までプレイすることに対応する.この乱数による終局までのプレイをプレイアウ トと呼ぶ.複数回のプレイアウトを行いプレイアウトの結果それぞれに点数をつけ,その点 数の平均などを求めることで評価値を計算する. 限られた回数のプレイアウトでより良い結果を得るためには,有望そうな手に対して多く のプレイアウトを行う手法が有効である.どの手をプレイアウトすると最も高い期待値を得 られるかという問題は「多腕バンディット問題」と呼ばれ,これを効率良く解くアルゴリズ ムが複数提案されている.そのひとつであるUCB1(Upper Confidence Bound)[3]では, 手j の評価値Xj,全体のプレイアウト回数n,手j に対するプレイアウト回数nj,および ある定数cに対して,以下の式で示されるUCB1値 Xj+ c √ 2 log n nj (3.1) が最も大きいものに対してプレイアウトする.定数cはバランスパラメータと呼ばれ,プレ イアウト回数を評価する式の調整に用いる. モンテカルロ法では,プレイアウト回数だけでなくプレイアウトの精度が結果に大きく影 響する.すなわち,乱数によるプレイが実際で行われるプレイと大きく異なる場合には正し い結果に収束しない.さらに,探索する木の深さが2以上の場合には,プレイアウト回数を 無限に増やしても正しい結果に収束しない可能性がある[1].
3.1.2
モンテカルロ法プレイヤ
モンテカルロ法プレイヤは,合法手に対して指定回数のプレイアウトを行い,最終的に最 も評価値の高い手役を場に提出する.プレイアウトの対象となる合法手には(全く意味のな い,場が新しい場合を除き)パスも含める.プレイアウトでは,各プレイヤは以下のように 動作する. 1. 合法手のうち,それを出すことであがりとなるような手があれば,それを選択する. 2. パス以外の合法手が存在する場合には,パス以外の合法手の中から等確率に選択する.3.1 モンテカルロ法 表3.1 モンテカルロ法プレイヤの各盤面における最小値と最大値の差の幾何平均 測定範囲 序盤 中盤 終盤 100∼1,000 0.1474 0.1097 0.0864 1,001∼2,000 0.0351 0.0266 0.0224 2,001∼3,000 0.0214 0.0132 0.0121 3,001∼4,000 0.0152 0.0101 0.0098 4,001∼6,000 0.0150 0.0111 0.0090 6,001∼8,000 0.0103 0.0071 0.0063 8,001∼10,000 0.0085 0.0058 0.0049 3. 合法手がパスのみである場合には,パスを選択する. 上記のとおり,プレイアウトの対象となる最初の1手のみパスを含み,プレイアウト中では 意図的なパスはしないとする. 1回のプレイアウトが終了すると,選択した手役に対して点数を割り当てる.このときに 割り当てる点数はUECdaの標準ルールにならって,大富豪であれば5点,富豪であれば4 点,平民であれば 3点,貧民であれば 2点,大貧民であれば1点とした.UCB1値のバラ ンスパラメータcは1回のプレイアウトで得られる報酬の最大値と最小値の差,すなわち4 とした.
3.1.3
モンテカルロ法プレイヤの収束
モンテカルロ法プレイヤの収束について調査するため,各手役に対して10,000回のプレ イアウトを行った.調査には30問(序盤10問,中盤10問,終盤10問)の次の一手問題を 使用し,相手プレイヤの手札をすべてわかっている状態とした.図3.2は,モンテカルロ法 プレイヤを用いてプレイアウトを行ったときの各手役の評価値の推移の一例である.図3.2 を見ると,プレイアウト回数が増加するにつれて評価値の変化の幅が小さくなっていること がわかる. 表3.1は各手役の評価値の測定範囲をプレイアウト回数で区切り,その範囲内の最小値と3.1 モンテカルロ法 図3.2 モンテカルロ法プレイヤの評価値の推移 値はプレイアウト回数が増加するにつれて変化の幅が小さくなっていることがわかる.ま た,序盤,中盤,終盤となるにつれて評価値の変化の幅が小さくなっていることがわかる. 測定範囲が 100∼1,000 の範囲での各手役の評価値は,序盤で0.15,中盤で 0.11,中盤で 0.09程度の変化の幅がある.それ以降の測定範囲を見ると,徐々に変化の幅が小さくなって いるのがわかるが,3,001∼4,000,4,001∼6,000の測定範囲の変化の幅は大差ないことがわ かる.3,001∼4,000,4,001∼6,000の測定範囲では評価値の変化の幅が0.01程度に収まっ ているため,評価値が収束しているのではないかと考える.このことから,モンテカルロ法 プレイヤが各手役に対して行うプレイアウト回数は4,000回程度が適当であると考える.
3.2 モンテカルロ木探索
MCT(root) {
loop until end_flag {
leaf <- select_downwards(root) leaf.n <- leaf.n + 1 if (expand_flag(leaf)) { leaf <- expand(leaf).first_child } board = playout(leaf.board) update_upwards(leaf, getvalue(board)) } return select_best_child(root) } 図3.3 モンテカルロ木探索のアルゴリズム
3.2
モンテカルロ木探索
3.2.1
モンテカルロ木探索のアルゴリズム
モンテカルロ木探索[1]は,モンテカルロ法とゲーム木探索手法を組み合わせたアルゴリ ズムである.基本的な考え方は,プレイアウトによってある盤面のある合法手に対する評価 値を計算し(モンテカルロ法),そこで得られた有望そうな手についてその先の探索をより 深くする(ゲーム木探索手法)というものである.モンテカルロ法とは異なり,モンテカル ロ木探索ではプレイアウト回数を十分に増やすと最善手が得られる[1]. モンテカルロ木探索の疑似コードを図 3.3 に示す.モンテカルロ木探索では,終了条 件(end_flag)を満たすまでプレイアウトを行い,合法手の評価値を算出する.終了条 件は,探索回数や探索時間によって与えられる.モンテカルロ木探索では,それまでに 得られている評価値を利用して木を探索する.根ノードからある葉ノードに到達すると (select_downwards),その葉ノードに対応する盤面を開始盤面としてプレイアウトを行 う(playout).ここで,ある葉ノードにおけるプレイアウト回数がある閾値に達した場合 は(expand_flag),そのノードを展開し(expand),その盤面の1手先からプレイアウト するようにする.プレイアウトの結果から合法手の評価値を算出し(evaluate),葉ノード3.2 モンテカルロ木探索 から根ノードまでの値を更新する(update_upwards).UCB1などの手法を用いると,有 望そうな手にはプレイアウトが多く実行され,プレイアウトが集中するところはより深く木 を探索できることになる.
3.2.2
モンテカルロ木探索プレイヤ
モンテカルロ木探索プレイヤの動作を図3.4に示す.モンテカルロ木探索プレイヤにおい て,場に提出する手役,プレイアウト中の動作,割り当てる点数はモンテカルロ法プレイヤ と同じとする.木の探索においてどの子ノードを選択するかは,式 3.1のUCB1値によっ て決定した.また,葉ノードのプレイアウト回数が100回を越えるときにそのノードを展開 するものとした. プレイアウトでは,ルートノードのプレイヤだけでなく全てのプレイヤに点数を割り 当てる.葉ノードにおいては,割り当てられた点数の相加平均により,各プレイヤの評 価値を求める.その他のノードについては,maxn アルゴリズムにより,各プレイヤが その子ノードの評価値のうちそのプレイヤにとって最大となるものをローカルに選択す るようにした.例えば,図 3.4 でルートからハートの A を選んだ先のノードでは,その 子ノード(いずれも葉ノードである)のうちプレイヤ P3 にとって評価値の高い PASS ([P 0→ 3.21, P 1 → 4.25, P 2 → 1.52, P 3 → 2.88, P 4 → 2.97])がその評価値となる.3.2.3
モンテカルロ木探索プレイヤの収束
モンテカルロ木探索プレイヤの収束について調査するため,合法手全体で100,000回のプ レイアウトを行った.モンテカルロ法プレイヤと同様に,調査には30問(序盤10問,中盤 10問,終盤10問)の次の一手問題を使用し,相手プレイヤの手札をすべてわかっている状 態とした.図3.5は,モンテカルロ木探索プレイヤを用いてプレイアウトを行ったときの各 手役の評価値の推移の一例である.図3.5を見ると,各手役の評価値が大きく変動している 箇所が多数あることがわかる.これは,プレイアウトをしている手役の葉ノードを展開した3.2 モンテカルロ木探索 図3.4 モンテカルロ木探索プレイヤの動作 表3.2 モンテカルロ木探索プレイヤの各盤面における最善手の最小値と最大値の差の幾何平均 測定範囲 序盤 中盤 終盤 100∼10,000 1.5394 0.7868 0.5031 10,001∼20,000 0.3550 0.4027 0.3729 20,001∼30,000 0.4806 0.4373 0.4129 30,001∼40,000 0.4723 0.3703 0.4429 40,001∼50,000 0.4412 0.1111 0.3695 50,001∼60,000 0.3794 0.3164 0.2461 60,001∼70,000 0.3756 0.6482 0.3521 70,001∼80,000 0.4322 0.5886 0.4239 80,001∼90,000 0.4402 0.5886 0.4239 90,001∼100,000 0.5151 0.5518 0.1515 ときに,その 1つ下のプレイヤがベストな手役を提出したことでおこる現象であると考え る.このことから,多人数ゲームにおいてモンテカルロ木探索を行った場合には,木の深さ を1つ深くするだけで各手役の評価値が大きく変動することが確認される. 表3.2は最善手の評価値の測定範囲をプレイアウト回数で区切り,その範囲内の最小値と 最大値の差の幾何平均を示した図である.なお,測定範囲内で評価値が全く変化していない ものは無視して測定した.表3.2を見ると,モンテカルロ木探索プレイヤの評価値は,全体
3.2 モンテカルロ木探索 図3.5 モンテカルロ木探索プレイヤの評価値の推移の一例 のプレイアウト回数が増加しても変化の幅があまり変わらないことがわかる.これは,図 3.5のように評価値が大きく変動しながら推移するためであると考える.このことから,モ ンテカルロ木探索プレイヤを用いて正しい評価値を算出するためには,100,000回よりも多 くプレイアウトが必要になることがわかる.
第
4
章
3
層ニューラルネットワーク
4.1
3
層ニューラルネットワークにおける出力値の計算
図4.1に3層ニューラルネットワークの構成を示す.3層ニューラルネットワークは,入 力層,中間層,出力層の3層からなる.入力層に値を与えることで中間層を経て出力層から 値が得られる. 入力層のユニット iから中間層のユニットj への遷移に対する重みをωi,j,中間層のユ ニットj から出力層のユニットへの遷移に対する重みをυj とする.ωi,j の総数は,入力層 のユニット数I に中間層のユニット数J を掛けた数に等しく,υj の総数は中間層のユニッ ト数J に等しい.ωi,j(1 ≤ i ≤ I, 1 ≤ j ≤ J)をまとめてωと表す.同様にυj(1≤ j ≤ J) 図4.1 3層ニューラルネットワーク4.1 3層ニューラルネットワークにおける出力値の計算 図4.2 シグモイド関数 をまとめてυと表す.関数S(x)をシグモイド関数 S(x) = 1 1 + e−x とする.シグモイド関数は図 4.2 のように (−∞, ∞) を (0, 1) に変換する関数であり, S(x) = 0とS(x) = 1に漸近線を持つ.また,関数D(x)を D(x) = x(1− x) とする.ここで,S0(x) = D(S(x))が成り立つ. 各層の計算について以下に示す.入力層の各ユニットでは入力pによって値が計算され る.入力層のユニットiで計算される値をfi(p)とする.中間層の各ユニットでは入力層の 値fi(p)とωi,j によって値が計算される.中間層のユニットj で計算される値gj(p, ω)は gj(p, ω) = S ( I ∑ i=1 fi(p)ωi,j ) である.出力層では中間層の値gj(p, ω)とυj によって値が計算される.3層ニューラルネッ
4.2 誤差逆伝播法 トワークの出力値h(p, υ, ω)は h(p, υ, ω) = S ∑J j=1 gj(p, ω)υj となる.
4.2
誤差逆伝播法
各層の重みの調整は,多数の教師データを用いて誤差逆伝播法によって行う.教師データ は正解の入力qmと不正解の入力pmの組であり,教師データの数をM とする.教師データ の集合をP と表す.ここで,正解の出力と不正解の出力の差の度合いを示す関数E(P, υ, ω) を E(P, υ, ω) = M ∑ m=1 S (h(pm, υ, ω)− h(qm, υ, ω)) と定める.誤差逆伝播法による重み調整では,E(P, υ, ω)を最小化することを目標とする. 誤差逆伝播法による重み調整を以下に示す.あるときの調整前の重みをυ,ω,調整後の 重みをυ0,ω0 とする.学習率ηを用いて,υ,ωの重みを (υ0, ω0) = (υ, ω)− η∂E(P, υ, ω) ∂(υ, ω) によって調整する.ここで,υj の重みを調整するための勾配は αi,j(p, υ, ω) = D(h(p, υ, ω))gj(p, ω) を用いて ∂E(P, υ, ω) ∂υj = D(E(P, υ, ω)) M ∑ m=1 (αi,j(pm, υ, ω)− αi,j(qm, υ, ω))4.2 誤差逆伝播法 によって計算される.ωi,j の重みを調整するための勾配は βi,j(p, υ, ω) = D(h(p, υ, ω))υjD(gj(p, ω))fi(p) を用いて ∂E(P, υ, ω) ∂ωi,j = D(E(P, υ, ω)) M ∑ m=1 (βi,j(pm, υ, ω)− βi,j(qm, υ, ω)) によって計算される.
第
5
章
手札情報の精度がモンテカルロ法
プレイヤに与える影響の調査
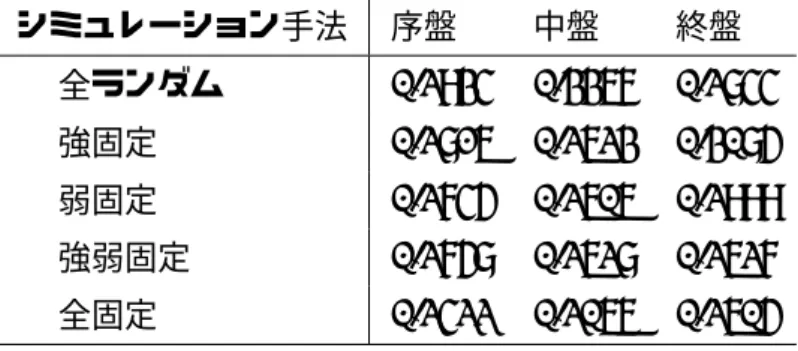
本研究では,1,500問の次の一手問題を「手札情報の異なるモンテカルロ法プレイヤ」と 「モンテカルロ木探索プレイヤ」に解かせ,手札情報の精度が大貧民モンテカルロ法プレイ ヤに与える影響を調査した.次の一手問題には図2.1のような盤面データの中から,勝ち抜 けが確定していないものを用いた次の一手問題の内訳は,枚数を基準として序盤を500個, 中盤を500個,終盤を500個とした.序盤・中盤・終盤を区別する枚数の基準は以下の通り とした. 序盤 まだ使用されていないカードが36枚以上 中盤 まだ使用されていないカードが21枚以上35枚以下 終盤 まだ使用されていないカードが20枚以下 各1,500盤面に対して6種類のシミュレーションを行い,そのときの各手役の評価値を調 査した.6種類のシミュレーションは以下の通りである. M全ランダム 相手プレイヤの全てのカードをランダムに割り当て,モンテカルロ法プレ イヤでプレイアウトを行う. M強固定 各相手プレイヤの最強のカードを 1枚固定し,その他のカードをランダムに割 り当て,モンテカルロ法プレイヤでプレイアウトを行う. M弱固定 各相手プレイヤの最弱のカードを 1枚固定し,その他のカードをランダムに割り当て,モンテカルロ法プレイヤでプレイアウトを行う. M強弱固定 各相手プレイヤの最強と最弱のカードを1枚固定し,その他のカードをラン ダムに割り当て,モンテカルロ法プレイヤでプレイアウトを行う. M全固定 相手プレイヤの全てのカードを固定し,モンテカルロ法プレイヤでプレイアウ トを行う. T全固定 相手プレイヤの全てのカードを固定し,モンテカルロ木探索プレイヤでプレイア ウトを行う. 各シミュレーションについて図 2.1を例に補足する.全ランダムは相手の手札が一枚もわ かっていない(通常の大貧民と同じ)状態である.強固定は Player1 のD2,Player2 の HK,Player3のC2,Player4のH2 がわかっており,そのカードよりも強いランクのカー ドを持っていないことがわかっている状態である.弱固定はPlayer1のS3,Player2のH6, Player3のC7,Player4のC9がわかっており,そのカードよりも弱いランクのカードを 持っていないことがわかっている状態である.強弱固定は,Player1のS3とD2,Player2 のH6とHK,Player3のC7とC2,Player4の9とH2がわかっており,各プレイヤの手 札はそれらの最弱カードと最強カードの間のカードから構成されていることがわかっている 状態である,全固定は完全情報ゲームになっている状態である. T全固定は合計100,000回のプレイアウトを行い,それ以外の5つのシミュレーションは 各手役に対して10,000回のプレイアウトを行った.T全固定時に最も評価値が高い手役を その盤面における「最善手」とし,最善手の評価値とそれ以外の5つのシミュレーションの 最善手の評価値の幾何平均誤差と,最善手の的中数について調査した. 各盤面における最善手の評価値の幾何平均誤差を表5.1に示し,最善手の的中率を表5.2 に示す.表5.2中のスラッシュの左の数値は各シュミレーションで最も評価値が高い手役が 最善手と一致した数を表し,スラッシュの右の数値は各シミュレーションで二番目に評価値 が高い手役が最善手と一致した数を表している.表5.1を見ると,すべての盤面において全 固定の最善手の評価値の誤差は,他のシミュレーション手法と比較して小さいことがわかる.
表5.1 各盤面における最善手の評価値の幾何平均誤差 シミュレーション手法 序盤 中盤 終盤 M全ランダム 0.2934 0.3367 0.2844 M強固定 0.2816 0.2623 0.3085 M弱固定 0.2745 0.2606 0.2999 M強弱固定 0.2758 0.2628 0.2627 M全固定 0.2422 0.2066 0.2605 表5.2 最善手の的中数 シミュレーション手法 序盤 中盤 終盤 M全ランダム 129 / 100 181 / 125 256 / 126 M強固定 133 / 95 187 / 120 246 / 145 M弱固定 127 / 99 178 / 122 254 / 137 M強弱固定 131 / 101 179 / 120 239 / 146 M全固定 135 / 96 180 / 123 254 / 136 合法手数の幾何平均 10.66 6.67 4.45 また,全ランダムの序盤・中盤の最善手の評価値の誤差は他のシミュレーション手法と比較 して大きいことがわかる.そのため序盤・中盤においては,相手手札を推定することで最善 手の評価値の誤差を小さくできることがわかる.終盤における最善手の評価値の誤差は,全 ランダムよりも,強固定や弱固定の方が大きく,強・弱固定や全固定の方が小さい.そのた め,終盤においては,相手手札を全体的に推定しなければ意味がないことがわかる. 表5.2について見ると,序盤,中盤,終盤となるにつれて,幾何平均合法手数が減少し, 最善手の的中数が多くなっていることがわかる. つまり,残りカード枚数が多く合法手数が 多い序盤では最善手の推定が難しく,その逆の終盤では最善手の推定がしやすいことが確認 できる. 各盤面で各盤面で最も的中率が低い手法とその的中数は,序盤は弱固定で127盤面,中盤 は弱固定で178盤面,終盤は強・弱固定で239盤面であり,最も的中率が高い手法とその的 中数は,序盤は全固定で135盤面,中盤は強固定で187盤面,終盤は全ランダムで256盤 面である.この結果から,最も高い的中数を出したシミュレーション手法は,序盤・中盤・
終盤で異なることがわかる.また,序盤と中盤では最も高い的中数と最も低い的中数の差が
10盤面もなく,終盤でも的中数の差は17盤面である.この的中数の差は調査に使用した盤 面の2∼3%程度の数であり,各シミュレーション手法の的中数に大きな差はないと考える. 表5.1と表5.2の結果から,手札情報を推定することで最善手の評価値に近づくことはで きるが,最善手の推定には寄与していないことがわかる.
第
6
章
3
層ニューラルネットワークを
用いた提出手役評価関数の性能調査
3層ニューラルネットワークを用いた提出手役評価関数の性能調査では,モンテカルロ法 に提出手役評価関数を適用したプレイヤの性能調査を,他のプレイヤとの対戦により行った.6.1
提出手役評価関数の性能調査
本研究では,3 層ニューラルネットワークを用いた提出手役関数を作成し性能を評価し た.教師データには,大貧民の棋譜を図2.1のような盤面データに切り出したもの使用した. 図2.1の盤面データでは相手プレイヤの手札がわかっているように表現されているが,教 師データでは相手プレイヤの手札枚数だけがわかっている状態とした(Player1,Player2, Player3,Player4,の手札の集合が場の残存カードに対応する).教師データにおける正解 の入力は,Player0が実際に出した手役であり,不正解の入力は,それ以外の合法手である. 図2.1であれば正解の入力はH8,不正解の入力はH7,HQ,PASSとなり,この盤面データ からは4個の教師データが作成される.多数の教師データを用いて,提出手役評価関数の重 みをPlayer0が実際に出した手役を提出するように調整することで,Player0のプレイ方策 を模倣した提出手役評価関数が作成されることが期待される. 教師データの作成には2種類の大貧民の棋譜を用いた.1つは「各合法手に対して500回 のプレイアウトを行う原始モンテカルロ法プレイヤ5名」の対戦を棋譜にしたものである. もう 1つは「人間のプレイヤ1名と各合法手に対して500回のプレイアウトを行う原始モ6.1 提出手役評価関数の性能調査 表6.1 評価項目に使用した盤面情報 盤面情報の種類 評価項目 評価項目数 場の情報 場のオーダ 1 場の役と提出役のランク差 5 場の残存カードのランク 41 提出役の情報 手役のランク 17 手役のタイプ 2 手役のサイズ 5 革命が発生するか 1 しばりが発生するか 1 8切りが発生するか 1 JOKERを含むか 1 プレイヤの情報 自プレイヤの手札のランク 41 他プレイヤのカード枚数 4 ンテカルロ法プレイヤ 4名」の対戦を棋譜にしたものである.すべての教師データに対し て1回だけ学習を行うことを1イテレーションとし,1,000イテレーションの学習を行った. 提出手役評価関数の中間層数は15と50の2通りを用意した.学習率は初期値を0.9とし, 1イテレーションごとに 0.99を掛けて使用した.評価項目に使用した盤面情報を表6.1に 示す. 以上の条件で提出手役評価関数の学習を行った.また,重みの初期値によって提出手役評 価関数の性能が変動することが考えられるため,初期値が異なるものを100個用意しそれぞ れ学習した. 性能調査実験では,提出手役評価関数の性能を調査するため「棋譜で提出された手役」と 「提出手役評価関数によって得られた評価値が最も大きい手役」がどの程度一致するか調査 した.調査に使用する盤面には,学習時に使用していないものを1,000盤面用意した.学習 時に使用していない盤面に対して調査を行うことで,未知の盤面に対して調査を行ったこと になり,実戦時の性能が評価できる. 実験結果を図6.1,6.2と表6.2に示す.図中と表中では原始モンテカルロ法プレイヤを
MCMPと表記する.Ave は平均的中数,Maxは最大的中数,Minは最小的中数,エラー バーは標準偏差における95%信頼区間を表している.
6.1 提出手役評価関数の性能調査 図6.1 提出手役一致数(MCMPの棋譜 中間層数15) 図6.2 提出手役一致数(MCMPの棋譜 中間層数50) 図6.1,6.2を見ると,中間層の数に限らず,学習に使用する盤面データを増やすことで提 出手役の一致率が上昇していることがわかる. 図6.1の平均最善手的中数を見ると,盤面データ数15,000付近で最善手的中数が頭打ち になっており,そのときの最善手一致率はおよそ69%である.盤面データ数1,000の場合と 表6.2 提出手役一致数 棋譜 中間層数 盤面データ数 平均 最大 最小 標準偏差 MCMP 15 3,000 653.22 694 603 16.17 MCMP 15 19,000 691.29 737 647 16.07 MCMP 50 3,000 670.27 714 635 14.81 MCMP 50 27,000 705.97 742 666 14.86 人間 15 2,245 420.65 469 362 29.45
6.2 モンテカルロ法に提出手役評価関数を適用したプレイヤの性能調査 比較すると,およそ4%最善手一致率が向上していることがわかる. 図6.2の平均最善手的中数を見ると,盤面データ数27,000まで最善手的中数がゆるやか に上昇し続けており,盤面データ数27,000での最善手一致率はおよそ71%である.中間層 数50の場合では最善手一致数が頭打ちになっていないため,盤面データ数をさらに増やす ことで最善手一致率が上昇する可能性がある. 表6.2を見ると,人間の棋譜を用いた学習は,原始モンテカルロ法プレイヤの棋譜を用い て学習した場合に比べて平均一致率が低くなっている.そのため,人間の棋譜を用いて充分 に学習を行うためには,原始モンテカルロ法プレイヤの棋譜よりも多くの棋譜が必要になる ことがわかる.
6.2
モンテカルロ法に提出手役評価関数を適用したプレイヤ
の性能調査
6.2.1
対戦プレイヤ
対戦に使用するプレイヤは,比較用に作成したプレイヤを5 つ,UECdaホームページ (プレイヤが入手可能な2012年度版)で公開されているプレイヤから3つの計 8プレイヤ を使用した.対戦に使用したプレイヤは以下の通りである. • Monte 原始モンテカルロ法プレイヤ • EVM 提出手役評価関数プレイヤ(コンピュータの棋譜) • EVH 提出手役評価関数プレイヤ(人間の棋譜) • MonteEVM 提出手役評価関数を適用したモンテカルロ法プレイヤ(コンピュータ の棋譜) • MonteEVH 提出手役評価関数を適用したモンテカルロ法プレイヤ(人間の棋譜) • Sample UECdaサンプルプレイヤ • Nakanaka UECdaライト級基準プレイヤ6.2 モンテカルロ法に提出手役評価関数を適用したプレイヤの性能調査 • paoonR2 2012年度UECda無差別級優勝プレイヤ 比較用に作成した5つのプレイヤの詳細を以下に示す. ■Monte プレイアウト中はパス以外の合法手の中から等確率に選択した手役を提出する ようにした.プレイアウト回数は全体で1,000回とし,プレイアウトを行う手役は UCB1 値によって決定した.場に提出する手役は,1,000回のプレイアウト終了後に最も評価値の 高い手役である. ■EVM 教師データの作成には,各合法手に対して500回のプレイアウトを行う原始モン テカルロ法プレイヤ 5名の対戦の棋譜を用いた.提出手役評価関数は,中間層数が 15,盤 面データ数が19,000,イテレーション数が1,000のものである.場に提出する手役は,提出 手役評価関数によって得られる評価値が最も大きい手役である. ■EVH 教師データの作成には,人間のプレイヤ1名と,各合法手に対して500回のプレ イアウトを行う原始モンテカルロ法プレイヤ 4名の対戦の棋譜を用い,人間のプレイヤの プレイ方策を学習した.提出手役評価関数は,中間層数が15,盤面データ数が3,245,イテ レーション数が1,000のものである.場に提出する手役は,提出手役評価関数によって得ら れる評価値が最も大きい手役である. ■MonteEVM 教師データの作成には,各合法手に対して500回のプレイアウトを行う 原始モンテカルロ法プレイヤ5名の対戦の棋譜を用いた.プレイアウトに用いる提出手役評 価関数は,中間層数が15,盤面データ数が19,000,イテレーション数が1,000のものを使 用し,プレイアウト中は提出評価関数によって得られる評価値が最も大きい手役を提出する ようにした.プレイアウト回数,プレイアウトを行う手役の決定手法,場に提出する手役は Monteと同様である. ■MonteEVH 教師データの作成には,人間のプレイヤ1名と,各合法手に対して 500 回のプレイアウトを行う原始モンテカルロ法プレイヤ4名の対戦の棋譜を用い,人間のプレ
6.2 モンテカルロ法に提出手役評価関数を適用したプレイヤの性能調査
盤面データ数が3,245,イテレーション数が1,000のものを使用し,プレイアウト中は提出 評価関数によって得られる評価値が最も大きい手役を提出するようにした.プレイアウト回 数,プレイアウトを行う手役の決定手法,場に提出する手役はMonteと同様である.
MonteEVM,MonteEVHはプレイアウト中でも合法手にパスを含むようにした.Monte,
EVM,EVH,MonteEVM,MonteEVHの手札交換のアルゴリズムはNakanakaと同じも のを使用した.
6.2.2
対戦実験
対戦実験では,比較用に作成した 5 つのプレイヤと UECdaライト級基準プレイヤの Nakanaka を対戦させた.対戦は5人対戦で行い,その組み合わせは,「比較するプレイヤ の数」と「Nakanakaの数」が 1対1もしくは 2対2となるようにし,残りのプレイヤは Sampleとした. 対戦結果を表6.3,6.4に示す.表中の点数は,平民を0点として,大富豪を+2点,富豪 を+1点,大貧民を−2点,貧民を−1点としたときの総獲得点数である.試合数は 2012 年度の大会試合数と同じ400である.表6.3,6.4を見ると,いずれの対戦でもMonte,EVM,EVHはNakanakaに獲得点数 で負けている.一方,表6.3のMonteEVMとNakanakaの対戦結果を見ると,MonteEVM
はNakanakaに獲得点数で勝っている.この結果から,モンテカルロ法に提出手役評価関数
を適用することでプレイヤが強化されたことがわかる.
また参考として,対Nakanaka戦において最も獲得点数が多いMonteEVMと2012年度
UECda優勝プログラムのpaoonR2を対戦させた.対戦結果を表6.5,6.6に示す.
表6.5,6.6を見ると,どちらの対戦においてもMonteEVMはNakanakaとpaoonR2に 獲得点数で負けている.また,表6.4のMonteEVMとNakanakaの対戦を見ると,1対1
の対戦ではMonteEVMの方が獲得点数が多かったが,2対2の対戦ではNakanakaの方が 獲得点数が多くなっている.
6.2 モンテカルロ法に提出手役評価関数を適用したプレイヤの性能調査
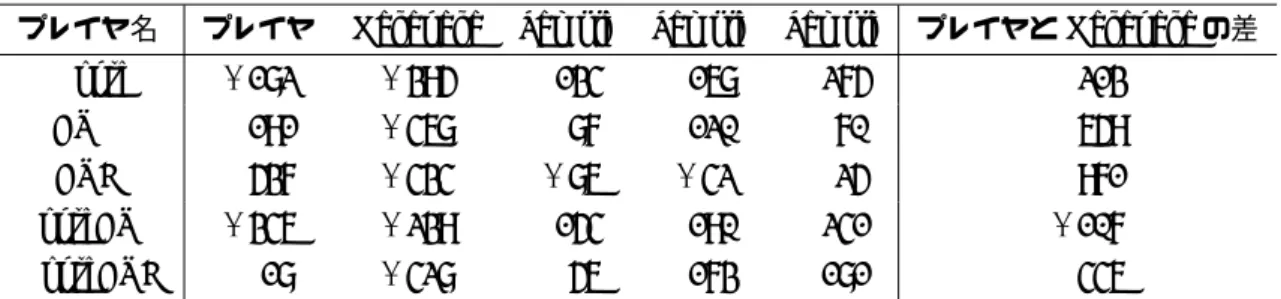
表6.3 1対1の対戦結果(VS Nakanaka)
プレイヤ名 プレイヤ Nakanaka Sample Sample Sample プレイヤとNakanakaの差
Monte +182 +395 −134 −168 −275 −213 EVM −191 +468 −87 −120 −70 −659 EVH −537 +434 +86 +42 −25 −971 MonteEVM +346 +239 −154 −190 −241 +107 MonteEVH −18 +428 −56 −173 −181 −446 表6.4 2対2の対戦結果(VS Nakanaka)
プレイヤ名 プレイヤ プレイヤ Nakanaka Nakanaka Sample プレイヤとNakanakaの差
Monte +24 −23 +157 +116 −274 −272 EVM −284 −306 +430 +312 −152 −1332 EVH −468 −479 +463 +396 +88 −1806 MonteEVM +85 −56 +240 +99 −368 −310 MonteEVH −102 −223 +323 +225 −223 −873 表6.5 1対1の対戦結果(VS paoonR2)
プレイヤ名 プレイヤ paoonR2 Sample Sample Sample
MonteEVM +243 +533 −202 −273 −301
表6.6 2対2の対戦結果(VS paoonR2)
プレイヤ名 プレイヤ MonteEVM paoonR2 paoonR2 Sample
MonteEVM −61 −61 +314 +290 −482 ため,人間の棋譜から学習した提出手役評価関数をモンテカルロ法に適用してもプレイヤが 強化されていないことが分かる.これは盤面データ数が3,245と少ないことや,盤面データ の中に人間が明らかなミスをしたものも含まれている可能性があることなどが原因であると 考える.人間の棋譜から学習した提出手役評価関数の性能は,棋譜を充実化することで改善 できると考える.
第
7
章
おわりに
モンテカルロ法プレイヤにおいて,プレイアウトの精度は重要である.本研究では,手札 情報の精度がモンテカルロ法プレイヤに与える影響と,3層ニューラルネットワークを用い た提出手役評価関数の性能の調査を行った. 手札情報の精度がモンテカルロ法プレイヤに与える影響の調査では,モンテカルロ法プレ イヤは,与えられる手札情報が多くなるにつれて正しい手役の評価値に近い値を得られる傾 向が見られた.しかし,最善手の推定には至らず,手札情報の推定だけでは強いプレイヤに ならないことが確認できた. 3層ニューラルネットワークを用いた提出手役評価関数の性能調査では,モンテカルロ法 プレイヤのプレイアウト部分に提出手役評価関数を適用することでプレイヤの強化を図っ た.提出手役評価関数の性能を評価した結果,学習に使用する盤面データを増やすことで 提出手役の一致率が上昇し,盤面データ数15,000程度で充分に学習できていることが確認 できた.盤面データ数15,000の提出手役評価関数では,未知の盤面に対する提出手役一致 率がおよそ69%となった.また,中間層数50の場合でも同様に,盤面データを増やすこと で提出手役の一致率が上昇した.盤面データ数27,000までの提出手役一致率を調査したが, 一致率が頭打ちになっておらず,充分な学習にはこれ以上の盤面データが必要であることが 確認できた.対戦実験では,2012年度のコンピュータ大貧民大会優勝プレイヤには勝てな かったが,モンテカルロ法に対して提出手役評価関数を適用することでプレイヤが強化さ れた. 今後の課題として,提出手役評価関数の改良と,棋譜の充実化が挙げられる.提出手役評 価関数の改良では,評価項目の設計を改良することや,序盤・中盤・終盤で使用する評価関数を分ける,などの方法が考えられる.また,棋譜を充実化させることで,学習によって得 られたプレイヤの棋譜による再学習や,強い人間の棋譜による学習などを行えるようにな る.改良された提出手役評価関数を用いて,充実化した棋譜からの学習を行うことで,強い プレイヤを作り出すことができると考える.
謝辞
本研究の完遂にあたって,丁寧な御指導と的確なアドバイスをしていただいた高知工科大 学情報学群准教授松崎公紀先生に心より感謝し厚く御礼申し上げます.松崎先生には研究室 に所属してからの4年間本当にいろいろとお世話になりました.私自身,学生の研究という ものはもっと孤独なものであると勝手に想像していたのですが,松崎先生には想像をはるか に超えるレベルで親身になってサポートしていただきました.おいしい食べ物やお酒に対し て経験的な知見を得られたことも,とてもありがたく感じています. また,副査として本研究を支援して頂いた同学群教授福本昌弘先生,並びに,同学群准教 授吉田真一先生に深く感謝いたします.福本先生には,コンピュータリテラシーのTAでも 2年間お世話になりました.おかげさまで,「他人に対する物事の教え方」の良い勉強になり ました.吉田先生には,学部時代にも私の卒業論文の副査を担当していただきました.学部 時代にいただいたアドバイスはその後の研究にも役立てることができたと思います. また,日頃より本研究について熱心な討論と有益なアドバイスをしていただいた松崎研究 室の皆さまに感謝いたします.皆さまのおかげで,松崎研究室は実家のように居心地の良い 場所となりました.私の4年間の研究室生活はとてもとても有意義なものでした(ここには 書ききれないほどに). 最後に,6年間の学生生活を精神的にも経済的にも支えていただいた両親と両祖父母に対 して深く感謝し,謝辞とさせていただきます.参考文献
[1] L. Kocsis and C. Szepesv´ari. Bandit Based Monte-Carlo Planning, 17th European
Conference on Machine Learning (ECML 2006), Lecture Notes in Computer
Sci-ence 4212, pp. 282-293 (2006).
[2] M. Buro. Improving heuristic mini-max search by supervised learning. Artificial Intelligence, Artificial Intelligence 134(1–2), pp. 85–99 (2002).
[3] P. Auer, N. Cesa-Bianchi and P. Fischer. Finite-time Analysis of the Multi-armed Bandit problem. Machine Learning, Vol. 47, pp. 235–256 (2002).
[4] 池畑 望, 伊藤 毅志. Ms. Pac-Manにおけるモンテカルロ木探索. 情報処理学会論文誌, Vol. 52, No. 12, pp. 3817–3827 (2011). [5] 伊藤 祥平, 但馬 康宏, 菊井 玄一郎. コンピュータ大貧民における高速な相手モデル作 成と精度向上. 数理モデル化と問題解決研究会報告, Vol. 2013-MPS-96, No. 4, pp.1–3 (2013). [6] 金子 知適. 兄弟節点の比較に基づく評価関数の調整. 第 12 回ゲームプログラミング ワークショップ, pp. 9–16 (2007). [7] 金子 知適, 田中 哲朗, 山口 和紀, 川合 慧. 駒の関係を利用した将棋の評価関数. 第8回 ゲームプログラミングワークショップ, pp. 14–21 (2003). [8] 金子 知適, 山口 和紀. 将棋の棋譜を利用した,大規模な評価関数の調整. 第13回ゲー ムプログラミングワークショップ, pp. 152–159 (2008). [9] 北川 竜平, 三輪 誠, 近山 隆. 麻雀の牌譜からの打ち手評価関数の学習. 第12回ゲーム プログラミングワークショップ, pp. 76–83 (2007). [10] 小沼 啓, 西野 哲朗. コンピュータ大貧民に対するモンテカルロ法の適用. 研究報告ゲー ム情報学 (GI), Vol. 2011-GI-25, No. 3, pp.1–4 (2010).
参考文献 誌, Vol. 50, No. 11, pp. 2740–2751 (2009). [12] 島内 剛一, 有澤 誠, 野下 浩平, 浜田 穂積, 伏見 正則. アルゴリズム辞典. 共立出版株式 会社, pp. 804–806 (1998). [13] 須藤 郁弥,成澤 和志,篠原 歩. UECコンピュータ大貧民大会向けクライアント「snowl」 の開発. 第2回UECコンピュータ大貧民シンポジウム (2011). [14] 須藤 郁弥, 篠原 歩. モンテカルロ法を用いたコンピュータ大貧民の思考ルーチン設計. 第1回UECコンピュータ大貧民シンポジウム (2010). [15] 西野 順二, 西野 哲朗. 多人数不完全情報ゲームのモンテカルロ木探索における推定の 効果. 研究報告バイオ情報学 (BIO), Vol. 2011-BIO-27, No. 31, pp. 1–4 (2011).
[16] 西野 順二, 西野 哲朗. 大貧民における相手手札推定. 研究報告数理モデル化と問題解決 (MPS), Vol. 2011-MPS-85, No. 9, pp. 1–6 (2011).
[17] 保木 邦人. 局面評価の学習を目指した探索結果の最適制御. 第11 回ゲームプログラミ ングワークショップ, pp. 78–83 (2006).
[18] 前原 彰太,橋本 剛,小林 康幸. 局面評価関数を使う新たなUCT探索法の提案とオセロ による評価. 研究報告ゲーム情報学 (GI), Vol. 2010-GI-24, No. 5, pp. 1–5 (2010).
[19] 美添 一樹. モンテカルロ木探索:コンピュータ囲碁に革命を起こした新手法. 情報処理, Vol. 49, No. 6, pp. 688–693 (2008). [20] 竹内 聖悟. コンピュータ将棋の技術とGPS 将棋について. http://www.cybernet. co.jp/avs/documents/pdf/seminar\ event/conf/19/1-3.pdf (2013). [21] 美添 一樹. コンピュータ囲碁におけるモンテカルロ法∼ 理論法∼. http://entcog. c.ooco.jp/entcog/contents/lecture/date/5-yoshizoe.pdf (2008).
[22] 第 2 回 将 棋 電 王 戦 HUMAN VS COMPUTER, http://ex.nicovideo.jp/ denousen2013/ (2013).
[23] 電 気 通 信 大 学. UEC コ ン ピュー タ 大 貧 民 大 会, http://uecda.nishino-lab.jp/ 2012/ (2012).