Comparison of Methods for Topic Classification in a Speech-Oriented Guidance System
4
0
0
全文
(2) where. N(w) is the fr叫uency of a word in an utterance, and. a(kl凹) with白(kω l )三o and 乞たα(kl切) that depend on a cJass k and a word w.. =. 1 are param巴ters. We applied ME using the package maxent Y.巴r.2.11 [12], which uses the L-8FGS-8 algorithm to estimate the parame. I巴rs. W,巴 also selected the ME model with inequality constraints [13], becaus巴 in preliminary experiments it pr巴sent巴d better per. formance.. 3.2. Support Vector Machine Figure 1: SpeeCh-Oliented guidance systell1 Takemaru・kun. Support Yector Machine (SYM) tries to find optill1al hyper planes in a feature space that ll1aximize the margin of classi 自cation of data from two diff,巴rent cJasses. For this work, LI8SYM [l4] was used to apply SYM. Specifically, we are using C. questions to a large nUll1ber of users. When a user utters an in. support vector cJassi自cation (C-SYC), which ill1plements soft. quiry, the systell1 responds with a synthesized voice, an agent. margm. anill1ation, and displays information or W,巴b pages at the 1l10ni. We used bag-of-words (80W) to represent utteranc巴s as. tor in the back, if required.. vectors, wh巴re each component of the vector indicates the fre. Since the Takemaru-kun systell1 start巴d operating, the re. quency of appearance of a word. The length of a v巴ctor cor. ceived utterances have been recorded. A database containing over. 100K. utterances recorded from November. 2002. responds to the size of the dictionary that includes every word. to Octo. in the training sample set. We selected a Radial 8asis Function. ber 2004 was constructed. Th巴 utterances were transcribed and. (R8F ) kern巴1, because in preliminary experiments it presented. manually labeled, pairing them to specific answers. lnforma. slightly better performance than a polynomial kern巴1 for this. tion concerning the age group, gend巴r and invalid inputs such. task. as noise, level overftow巴d shouts and oth巴r uncJear inputs wer巴. In the problem we are addressing, the amount of sam. also docull1ented. Yalid ullerances showed to be relatively short,. ples available for each topic is unbalanced. The SYM primal. with飢average length of 3.65 words per utterance. The an. problem formulation implell1enting soft-margin for unbalanced. swer selectio日1日ぬkemaru-kun system is based on l -nearest. amount of samples follows the form. neighbor ( l -NN), which classi自es an input based on the cJosest example according to a sirnilarity score. An input utterance is cOll1pared to example questions in the database, and the answer. jJ切+C+乞Çi+C_ L. mm w,b,{. paired to the most sill1ilar exall1ple question is output We have heuristically defined 40 topics, grouping questions. Yi(WTゆ(xi)+b)と1. subject to. that are related, using the database constructed during the first. ふさO,i. two years of operation of the systell1. Çi,. = 1, ...,l. Xi E Rへi - 1, ..., l indicates {l, -1} a class, andゆis the funct則1. where. 3. Classification Methods Overview. -. Çi 附. a training vector,. Yi正. for mapping the train. ing vectors into feature spac巴. The hyperparameters C+ and C_ penalize the sum of the slack variable ふfor each class, that allows the margin constraints to be slightly violated. By intro ducing different hyperparameters C+ and C_, the unbalanced. This sections bli巴目y 巴xpl釦ns the topic classification methods we are comparing in this work.. 3.1. Maximum Entropy. amount of data problem, in which SYM parameters are not es. Maxill1um Entropy (ME) [11] is a technique for estimating. timated robustly due to unbalanced amount of training vectors. probability distributions from data, and it has been widely used. for each cJass, can be dealt with. in natural language tasks, including speech classification, where. SYM is originaUy d巴signed for binary classification.. it has shown to outperform other conventional statistical classi. implemented the one-vs-rest approach for multi-cJass cJassifi. fiers [8]. cation, which constructs one binary cJassifier for each topic, and. As it is expressed in [8], given an utterance consisting of the. each one is trained with data from a topic, regarded as positive,. word sequenc巴ωf, the 0切ective of th巴 cJassifier is to prov出. and the rest of the topics, regarded as negative. We selected one. the most likely class label k from a set of labels K. vs-rest as in preliminary experiments it presented bett巴r perfor mance than one-vs-one for this task.. ん= argmax p(klwi"). (1). kEK. wher巴 the ME paradigm expresses the probab出ty. p( kl ur) =. 』. J. f. 3.3. PrefixSpan Boosting. p(klωf) as:. 叫 | 玄 N(ω) log α(klw) 1. In this work we are introducing Pre民xSpan 800sting (pboost) for the classification of utterances in topics. Pboost is a method. 1. 2ご叫 1 LN(w) log α(kl ) 1. proposed by Nozowin er al.. (2). Ignoring the terms that are constant with respect to. argmax kE K. ) . N (ω) l τ. (kω l ).. og α. [9]. for action cJassification in. vid巴os. Pboost implements a generalization of the PrefixSpan. algorithm by Pei. 叫. k=. We. er. al. [10] to find optimal discrirninative pat. terns, and in combination with the Linear Programming 800st ing (LP800st) classifier, it optimizes the cJassifier and performs. k yields:. feature selection simultaneously. In pboost, the presence of a single discriminative pattern in. (3). a sample, in our case a word sequence that could includ巴 gaps,ls. 1262 ηJ nδ.
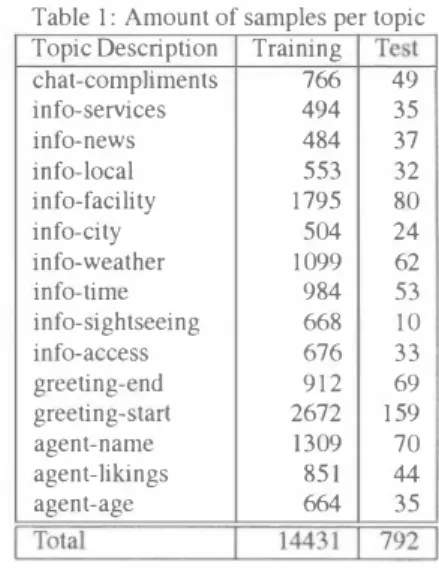
(3) h(x; ,ω), xε {xi}. x包ξRn, i 1, ..., 1 ìs a training vector, is a word sequence and ωεn, n = {-1, 1} is a variable that. checked by weak hypotheses, which have the form where. 8. Table 1: Amount of samples per topic. 8. allows the sequence to decide for either class The classification function has the form:. f(x) =. 乞. (s,ω)ESXíl. αs,wh(x;い) 1. 8. lows to implement soft-margin for unbalanced amount of sam ples. The pboost primal problem then takes this form:. 1内=1. 553. 32. 1795. 80. 504. 24. L. O:s,ω=同三日三0. 35. 37. 1099. 62. info-tim巴. 984. 53. info-sightseeing. 668. 10. info-access. 676. 33. 9 12. 69. greeting-start. 2672. 159. agent-name. 1309. 70. 851. 44. 664. じ[otal. Yi=ー1. 仰いh(Xi;い)十Çi三p,i = 1, ...,l. 1判31. 35. 己主l. For these experiments we selected the 15 topics with most training samples. The amount of samples available per topic is. (s,ω)ESX(]. shown in Table 1. W,巴 conducted experiments with transcrip tions and ASR l -best results. where XiεRぺi 1, ..., 1 indicates a training vector, Yiε{1, -1} a class, p is th巴 soft ma申n sepa則ng negaHve from pos山e samples, and D = 古 and vε(0, 1) is a hyper. 4.2. Evaluation Criteria. parameter controlling the ∞st of misclassification, which in this. Classitìcation performance of the methods on each topic was. case is separat巴d into D+ and D_, p叩alizing the sum of the slack variable for each class, that allows the margin con. evaJuated using the F-measure, as detìned by:. Çi. straints to be slightly violated. As in SVM, by introducing dif ferent hyperparameters. info-local. agent-ag巴. ( 6). 2二. (s,ω)ESX(]. 484. agent-likings. -p+ D+ L Çi + D_ L Çi. subject to:. 494. info-news. gr巴eting-end. samples, we are using an ext巴nded version of the method that al. ffiln. info-services. info-weather. and parameterω. To deal with the unbalanc巴 between positive and negative. o<,ç,ρ. 766. info-facility. and 一 αs,ω > O. which indi 一 cates the discriminativ巴 importance of a word sequence such that. Training. chat-compliments. info-city. where αs,ωis a weight for a word sequence. � �S,ω 白(s,ω)ESx(] α. (5). 'J'est I 49 I. Topic Description. F-meαsure =. v+ and v_, we can deal with the unbal. anced amount of data problem.. 2Precision .R記αII Preα8ion +ReωII. σ). The classi白cation performance of ME using word unigrams. We also implement巴d the one-vs-rest approach for multi. as features was u鈴d as baseline.. class classi自cation, as in preliminary experiments it presented better performance than one-vs-one for this task. 4.3. Experiment Results The pu中ose of these experiments was to compare the classi白. 4. Experiments. cation performance of the described methods, and evaluate their strength against ASR e町ors. Due to the sparseness of the fea. We compared the performanc巴 of the methods in the classi自ca. tures and the shortness of lhe utt巴rances, we also proposed 10. tion in topics of utterances in Japanese, receiv巴d by a speech. use characters as fealures instead of words, which is possibl巴. oriented guidance system operating in a real environment. Opti. with the Japanese language due to the presence of kanji char. mal hyper-parameter values for SVM and pboost w巴re obtained. acters. We also conducted experiments including bigrams and. experimentally using a grid search strategy, and were set a pos teriori. The experiments and obtained results are detailed below.. 95%. 4.1. Characteristics ofthe Data. 94.4�. The data used in the experiments was collected by the speech. 949も1. orient吋guidance system Takemaru-kult from November 2002. to October 2004.. For these experim巴nts we only considered. �. valid utterances from adults.. Julius Ver.3.5.3 was used as ASR 巴ngine.. 一. 93帖 |. LE. The acoustic. model was constructed using the Japanese Newspaper Article. u... Sentences (JNAS) corpus, re-training it with valid samples coJ lected by the system in the period indicated above.. 11. �� L誌面. ロCharacter. The lan. guage mod巴1 was constructed using the transcriptions of th巴 same samples. 90叫1. The samples corresponding to the month of August 2003. SVM. were used for the test set and were not included in the tr創mng set. The rest of the samples were used for the training set. The. pboost. ME. Figure 2: Besl f-measure per method for ASR l -best results. word recognition accuracy of the ASRengine was 85.66% for the training set and 85.10% for the test set.. 1263. - 184 -.
(4) iments gaps were only allowed wh巴n using worcls, but not with. Table 2: F-measure p巴r method using words as features Method. Transcriptions. Word Igram. SVM. Word 1+2gram Word 1+2+3gram. pboost. ME. A grammatical analysis of the optima! cliscriminative words. ASR l -best. 94.8%. 92.7%. 95.5%. 93.2%. 92.9%. 90.8%. 95.3%. Word 1 gram. characters se!ectecl by pboost indicated that th巴 most important part of speech (POS) for topic discrin巾ination is the noun, which ac. counted in average for more than a half of the selected pat. 92.8%. Word 1 +2gram. 93.4%. 9 1.2%. Word 1+2+3gram. 93.5%. Word 19ram. 93.79も. 9 1 . 2%. 92 .2%. Word 1+2gram. 93.9%. 9 1.9%. Word 1+2+3gram. 93.8%. 9 1.99も. 1巴rns in the different classifiers.. Following, the verb, which. accounted in average for n巴arly a seventh of the selected pat terns. Particles, Japanese pa口s o[ speech that relate the preced ing word to the rest of the sent巴nce, were also sel巴cted in some cases as optimal discriminative words. Nouns proved to be im portant for topic disc口口1ination, since some nouns are charac teristic of specific topics, as opposed to other POS that can be found in broader numbers of topics. 5. Conclusions. Table 3・F-measure per method using characters as features Transcriptions. ASR l-best. Char 19ram. 95.6%. Char 1+2gram. 96.4%. 93.5 % 94.4%. SI自cation in topics of utterances in Japanese received by a. Char 19ram. 93.8%. 9 1.4%. 94.8%. 93.5%. ing character unigrams and bigrams as features presented the. Char 1+2gram Char 1+2+3gram. 95.4%. 94.2%. Char 19ram. 94.3%. 93.6%. Char 1+2gram. 95.5%. 93.9%. Char 1+2+3gram. 95.5%. 94.19も. Method SVM. Char 1+2+3gram pboost. ME. 96.4%. This work comparecl the performance of Support Vector M a chine, PrefixSpan Boosting and Maximum Entropy for t h e clas. 94.29も. speech-oriented guidance system. Support Vector 恥1achine us best classification performance.. Using characters as features,. instead of words, yielded to improvements in the classi白cation performance of all the methods that were compar伐l. 6. References [1] A.L.Gorin, G. Riccardi, J.H.Wright, "How may Speech Communicalion, Vo1.23, pp.1l3-127, 1997.. 1. help youγ. [2] N. Gupta, G. Tur, D. Hakk削i- Tur, S. Bangalore, G. Riccardi, M. Gilbert, '寸he AT&T Spoken Language Understanding System,". ttigrams as features目. lEEE 1トans on. Audio, Speech and Language Processing, Vo1. l 4,. The F-measure was calculated individually for the classifi. No.1, pp. 213-222, 2006. cation of each topic and it was averaged by frequ巴ncy of sam. [3] R. Nisimura, A. Lee, H. Saruwatari, K. Shikano, "Public Speech. ples in the topics. Table 2 and 3 present a summary of the ob. Oriented Guidance System with Adult and Child Discrimination. tained results. Figure 2 presents th巴 best performance obtained. Capability," In Proc. o[ICASSP 2∞4, Vol.I, pp.433-436, 2004.. with each method in the classi自cation of ASR l -best results,. 14]. using words and characters as features.. [5] P. Haffuer, G. Tur, J. Wright, "Optimizing SVMs for Complex Call C1assification," In Proc. o[ICASSP 2ω3, Vol.I, pp.632-635, 2003. This suggests that, since. [6]. kanji characters also include meaning, using characters for the. Lane, T. Kaw幼紅a, T. Matsui, S. Nakamura, "Out-of-Domain. Topics," IEEE Trans. on Speech and Audio Processing, Vo1. l 5,. amount of information available for a proper c!assification. No. l , pp.150-161, 2007 [7]. We could also corroborate that the inc!usion of bigrams and. Y.. P:町k, W. Teiken, S. Gates, "Low-Cost Call Type C1assification. for Contact Center Calls Using Partial Transcripts," In Proc. o[In. trigrams as featur巴s can improve c!assification performanc巳,. lerspeech 2ω9, pp.2739-2742,. however, in some cas巴s no further improvement was achiev巴d. 2初0∞0ω9.. [8削8針] K. Eva佃nini, D. Suende町rma町nn臥n凡1, R. P刊le町r悶a配cc口101,叱1,. by including trigrams, and there were even some cases where. Automated Tro加u巾刷ble郎sho∞otmg 0叩n Large Cor中po町ra,". the per[ormance decreased by including them.. 2ω7, pp.207-212, 2007.. The difference in c!assi自cation performance between tran. 1μn. Proc. o[ ASRU. [9] S. Nowozin, G. B北ir, K. Tsuda, "Discriminative Subse司uence. scriptions and ASR l-best results was around 2% in average,. Mining for Action Classification," In Proc. o[ICCV 2007, Software available at http://www.kyb.mpg.delbsJpeople/nowozinlpboost. which indicates that the methods that were compared can be. 110]. robust against ASR errors. The method that presented th巴 b巴st performance in the clas. 1. Pei, J. Han, B. Mortazavi-Asl, J. W:阻g, H. Pinto, Q. Che n, U. Dayal, and M.C. Hsu. "防白ning S巴quential Patterns by Pallern. Growth: The Prefixspan Approach," IEEE Tra削. on Knowl. and. sification of ASR l-best results was SVM using character un an. l.. Utterance Detection using CIassification Con白dences of Multiple. c!assification of short utterances in Japanese can enhance the. igrams and bigrams as features, with. T. Kawahara, "Speech-Based Interactive Information. o[ICASSP 2ω7, Vo1.4, pp.145-147, 2007.. We can observe that by using characters as features instead of words, we could achieve improvements in the c!assi白catìon performanc巴 of th巴 three methods.. T. Misu,. Guidance System Using Question-Answering Technique;' In Proc.. Dala Eng., Vo1.l6, No.10, pp.1424-1440, 2004.. f-measure of 94.4%,. [11] A. Berger, S. DeUa Pietra,. which r巴pr巴sents a difference of 2.2% in comparison to th巴. V.. Della Pietra, "A Maximum Entropy. Approach to Natural Language 丹ocessing," Compulalional Lin. baseline; followed almost without a significant difference in. guistics, Vo1.22, No.l , 1996. [12] Maximum Entropy Modeling Package.. performance by pboost and ME using character unigrams, bi. http://mastarpj.nict.go.jp/ mutiyamalsoftware.html#maxent. grams and trigrams. [13]. Pboost can find discriminative patterns that include gaps,. J.. Kazama,. 1.. T sujii, "Evaluation and Extension of Maximum. Entropy Models with Inequality Constraints," In Proc. o[ EMNLP. as in the pattem [where][library]. When words were used as. 2∞3, Vol.lO, pp.137- 144, 2003.. features, this yi巴lded to improvements in classification perfor. [14] C.. mance; however, when using characters as features, the classi白. port. Chang, Vector. C.. Lin,. Machines,". "LIBSVM: 2001.. http://www.csie.ntu.edu.twrcjlinllibsvm. cation performance decreased. Because of that, for these exper-. 1264. -1 85-. a. Library. SoftW3I巴. for. available. Sup at.
(5)
図


関連したドキュメント
In [12] we have already analyzed the effect of a small non-autonomous perturbation on an autonomous system exhibiting an AH bifurcation: we mainly used the methods of [32], and
The general context for a symmetry- based analysis of pattern formation in equivariant dynamical systems is sym- metric (or equivariant) bifurcation theory.. This is surveyed
By applying the Schauder fixed point theorem, we show existence of the solutions to the suitable approximate problem and then obtain the solutions of the considered periodic
Nonlinear systems of the form 1.1 arise in many applications such as the discrete models of steady-state equations of reaction–diffusion equations see 1–6, the discrete analogue of
A monotone iteration scheme for traveling waves based on ordered upper and lower solutions is derived for a class of nonlocal dispersal system with delay.. Such system can be used
The reader is referred to [4, 5, 10, 24, 30] for the study on the spatial spreading speeds and traveling wave solutions for KPP-type one species lattice equations in homogeneous
Here we purpose, firstly, to establish analogous results for collocation with respect to Chebyshev nodes of first kind (and to compare them with the results of [7]) and, secondly,
“Breuil-M´ezard conjecture and modularity lifting for potentially semistable deformations after
