2019
年度修士論文報告書全点間信頼度と構築コストを考慮した ネットワーク設計問題に対する
GA ベースアルゴリズムの提案
指導教員 山本 久志
首都大学東京大学院 博士前期課程 システムデザイン研究科 電子情報システム工学域 学修番号:
18861619
陳 炯庭目次
第
1
章 序論··· p.1
1.1 はじめに ··· p.1 1.2
研究目的··· p.3 1.3 本論文の構成 ··· p.3
第
2
章 全点間信頼度と構築コストを考量した二目的ネッ トワーク問題及びその解法について··· p.4
2.1
モデルの定義··· p.4
2.2 全点間信頼度と構築コストを考慮した二目的ネットワーク問題定義 · p.7
2.3
パレート解の定義··· p.7 2.4 全点間信頼度と構築コストを考慮した二目的ネットワーク設計問題の
先行研究 ··· p.102.5 遺伝的アルゴリズム ··· p.11 2.5.1 遺伝的アルゴリズムの概要 ··· p.12 2.5.2
遺伝子の表現··· p.16 2.5.3 遺伝的操作··· p.16 2.6
並列分散遺伝的アルゴリズム··· p.19
第
3
章 層別法とネットワーク構造を考慮した交叉を取り 入れたGA
ベースのアルゴリズムの提案··· p.22
3.1 提案するアルゴリズムの概要及びフローチャート ··· p.22
3.2
ビット演算の運用··· p.24 3.3
初期染色体··· p.28 3.4 ネットワーク適合度の定義 ··· p.28 3.5
層別法··· p.29 3.6
遺伝的操作··· p.31 3.6.1 ルーレット選択法 ··· p.31 3.6.2 ネットワーク構造を考慮した交叉法 ··· p.32 3.6.3
突然変異··· p.33
第
4
章 数値実験による評価··· p.35
4.1 検証方法 ··· p.35 4.2
各パラメータの設定··· p.35 4.3
各提案手順の効果··· p.37 4.3.1 層別法(GA1) ··· p.40 4.3.2 ネットワーク構造を考慮した交叉法(GA2) ··· p.44
4.3.3 層別法とネットワーク構造を考慮した交叉法(GA3) ··· p.43
4.4 ノード7の場合で GA3
アルゴリズムの評価··· p.44 4.5 考察 ··· p.49
第
5
章 結論··· p.52
参考文献··· p.54
謝辞··· p.56
付録
··· p.57
1
第
1
章 序論本章では,1.1 節は本論文で扱うネットワーク設計問題の社会的な背景につい て説明し,1.2節では本研究の目的を述べる.そして,1.3節では本論文の構成に ついて述べる.
1.1
はじめに現代社会では,様々なネットワーク状の構造を持つシステムが存在する.例え ば, 交通網や通信ネットワーク,インターネット網などがある.また,これらの システムの中には,我々の生活に直結する重要なシステムがある.ここでは,通 信ネットワークを一つの例として挙げる.通信ネットワークは私達の生活を支え る重要なインフラストラクチャであり,故障せずに常に稼働することが求められ ている.しかしながら,通信ネットワークを構成する要素である通信回線は,事 故や自然災害などの影響により故障や,断線が発生し,通信ネットワークが正常 に稼働することができなくなることがある.すなわち故障の発生確率をゼロにす ることは現実的に不可能であると考えられる.そこで,構成要素が故障しても稼 働し続けられる通信ネットワークを設計する必要があると考えられる.
図 1.1
通信ネットワーク
回線 1
回線
2
回線 1
回線
2
回線3
(a)
ネットワーク1 (b)
ネットワーク2 B
A A B
C C
2
図
1.1
に通信ネットワークの例を表す.図1.1
の(a)
ネットワーク1
は拠点A
, 拠点B,拠点 C,回線 1,回線 2
で構成するネットワークである.それぞれの拠点 は単一の回線で繋がれているため,回線1
もしくは回線2
が1
本断線すると,通 信ネットワークが稼働できなくなり,通信が行えなくなってしまう.図1.1
の (b) ネットワーク2
はネットワーク1
に回線3
を追加したネットワークである. こ のネットワークでは回線が1
本断線したとしても,三つの拠点は引き続き通信す ることができる.すなわち,通信ネットワークは正常に稼働することができる.したがって,ネットワーク
1
より,ネットワーク2
のほうが故障しにくいネット ワークであると考えられる.ネットワークの故障しにくさを定量化するための尺度の一つとして,ネットワ ークの信頼度が知られている.ネットワークの信頼度は,ネットワークの構成要 素が一定な確率で故障するとしたときに,そのネットワークを用いて通信が行え る確率と定義される.例えば,各回線が独立に 10% の確率で断線すると設定し,
図
1.1
を用いて計算すると,ネットワーク1
が正常に稼働する確率は回線が断線 する確率と同様なので,ネットワークの信頼度は80%
となる.一方,ネットワ ーク2
ではエッジが二本以上同時に断線しない限りネットワークは稼働であるの で,このネットワークの信頼度は89.6%
となる.このようにネットワークの信頼 度を計算することで,ネットワークの故障に対する強さを定量化することができ る.しかしながら,例のような単純なネットワークの信頼度は簡単に計算できる が,ネットワークの規模が大きくなると,ネットワーク信頼度の計算が急激に複 雑になり,計算時間がかかると予想される.信頼度が十分に高ければ,ネットワークは故障しにくいため,私たちにとって,
安心して使えるネットワークであると考えられる.信頼度が低いネットワークに 対して,回線と見なすエッジを増築する必要があると考えられる.一方,エッジ を増やせば増やすほど,ネットワークの信頼度は高くなるが,現実社会では,エ ッジを構築するための費用はかかると考えられる.例えば各エッジの構築費用を
10
と設定し,図1.1
を用いて計算すると,ネットワーク1
ではエッジが二本ある ので,ネットワークを構築する費用は20
となる.一方,ネットワーク2
ではエ ッジが三本あるので,このネットワークを構築する費用は30
となる.しかしながら,ネットワーク信頼度とネットワーク構築コストは一般的にはト
3
レードオフの関係である.複数の評価指標を同時に最大または最小とする完全最 適解は一般的には存在しない.そのため,優劣が付けられないパレート解を最適 解として求めることが多い.このような解の集合,すなわちパレート解集合を求 めることがネットワーク最適化問題に用いられている.
1.2
研究目的本研究では,ネットワーク設計問題に対し,ネットワーク信頼度とネットワー クの構築コストの二つの評価尺度に注目する.この二つの評価尺度を考慮したネ ットワーク設計問題に対して,優劣がつけられないパレート最適解を効率的に探 索するアルゴリズムの提案を目的とする.
1.3
本論文の構成本論文の構成は以下のように示す.
第
1
章では,序論とネットワーク最適化問題の社会的背景および研究目的につ いて述べる.第
2
章では,本論文で取り扱う問題及びモデルの定義を述べる.第
3
章では,二目的ネットワークにおけるパレート解に関する先行研究を述べ,従来の基礎遺伝的アルゴリズムを紹介しする.また,本研究では計算速度をあげ るため,ビット演算を用いて,層別法や従来の交叉操作と違う交叉を提案したア ルゴリズムを紹介する.
第
4
章では,提案するアルゴリズムを数値実験により評価を行う.第3
章で説 明した提案アルゴリズムをそれぞれに数値実験を行い,提案アルゴリズムの有用 性を示す.また,クラフや図や表で数値実験の結果を表し,考察する.最後に,第
5
章にて本研究の結論と今後の課題および展望について述べる.4
第
2
章 全点間信頼度と構築コストを考慮した 二目的ネットワーク問題及びその解法について2.1
節では,ネットワーク問題におけるモデルの定義について説明する.2.2
節 では全点間信頼度と構築コストを考慮した二目的ネットワーク問題の定義につい て説明する.2.3 節では全点間信頼度と構築コストを考慮したパレート解の定義 を述べる.次に2.4
節では二目的ネットワーク問題の従来研究を説明する.2.5
節 では遺伝的アルゴリズムを紹介し,フローチャートや遺伝的操作を紹介する.ま た,2.6
節では並列分散遺伝的アルゴリズムについて紹介する.2.1
モデル定義本研究では,対象とするネットワークシステムは 図 2.1 に示すノードとエッ ジから構成するグラフを,ネットワークシステムを表すモデルとして扱う.例え ば,インターネット通信網であれば,ノードはサーバーやハブ,エッジは回線に 該当する.なお,本研究では,エッジに関して,流れに方向のない無向グラフを 考える.
図 2.1
ネットワークシステムのモデル例
:
ノード:
エッジ5
次に,本研究を通して用いられる記号を記す.
𝑛
: ノード数𝑚
: エッジ数𝑖 = 1,2,3 … , 𝑚
に対して,
𝑒
,: エッジ番号 𝑖
のエッジ
𝐸
: エッジ𝑒
, の集合である.つまり,𝐸 = {𝑒/, 𝑒
0, 𝑒
1, … , 𝑒
2}
𝑝
,: エッジ 𝑒
,の信頼度
𝑐
, : エッジ𝑒
,のコスト とする𝑉
: ノードの集合である.つまり,𝑉 = {1,2,3, … , 𝑛}
ノード数が
𝑛
の時,エッジ数𝑚 =
7(79/)0 である.𝐺
: ノード𝑉
,エッジ𝐸
からなる単純グラフである. す な わ ち ,𝐺 =
(𝑉, 𝐸)
とする.𝑅(𝐺): ネットワーク 𝐺 の全点間信頼度 𝐶(𝐺): ネットワーク 𝐺 の構築コスト
x
?: 全域木から完全グラフまでの全ノードがエッジで接続された連結状態 を表す 𝑗 次元ベクトル
x = (𝑥
/, 𝑥
0, … , 𝑥
B)
で表すものとする.また
𝑘
本のエッジで連結されているネットワーク,エッジ本数𝑘
は 下の式で表される.𝑘 = D 𝑥
,2
,E/
(2.1)
𝑋
: ネットワークx
の集合𝑋
?:
ネットワーク
x
? の集合𝑝x
? :𝑋
? において,パレート最適解の定義を満たすネットワーク𝑃𝑋
? :ネットワーク
𝑝x
? の集合6
本研究で扱うネットワークに対して,以下の条件を仮定する.
仮定
1)
ネットワークの各ノードは故障しない.に対して,
2)
エッジ𝑒
, は稼働か故障の二状態をとる.3)
各エッジの状態は,互い影響を受けずに独立に生起する.4)
エッジ𝑒
, はノードを連結すると信頼度𝑝
, で稼働し,構築コスト𝑐
, がか かる.ノード数
𝑛
のグラフとし,エッジ本数が𝑘
であるネットワークに対して,本研 究で扱うネットワーク構築コストはベクトルx
のノード間に存在するエッジ𝑒
,(
ただし,𝑖 = 1,2,3 … , 𝑚)
の構築コスト合計値を𝐶(x)
で表す.この時ネットワークの構築コスト
𝐶(x)
は以下の式で定義する.𝐶(x) = D 𝑐
,∙ 𝑥
,2
,E/
(2.2)
ここで,
𝑐
, はエッジのコストを表し,エッジが使用されている時𝑥
,は1
であ り,使用されていない時𝑥
, は0
である.ここで,𝑖
はエッジ番号を表すものとし て,𝑖 = 1,2,3 … , 𝑚 である.式2.2
はネットワークの構築コスト𝐶(x)
を表す.また,
𝑒
, がネットワーク構成要素である場合は 1,それ以外の場合は 0とす る二値変数である𝑥
,を設定し,全域木から完全グラフまでの全ノードがエッジ
で接続された連結状態を表した𝑗
次元ベクトル x は完全グラフの部分グラフを 表現することができる.よって,ベクトルx
を部分ネットワークと呼ぶこととす る.部分ネットワークの全ノードが稼働状態のエッジで連結されている確率を全 点間信頼度と呼ぶ.第一章では簡単な例を挙げてネットワーク全点間信頼度を計 算した.従来の研究では,信頼度の厳密な算出方法について,包除原理を用いた方法や
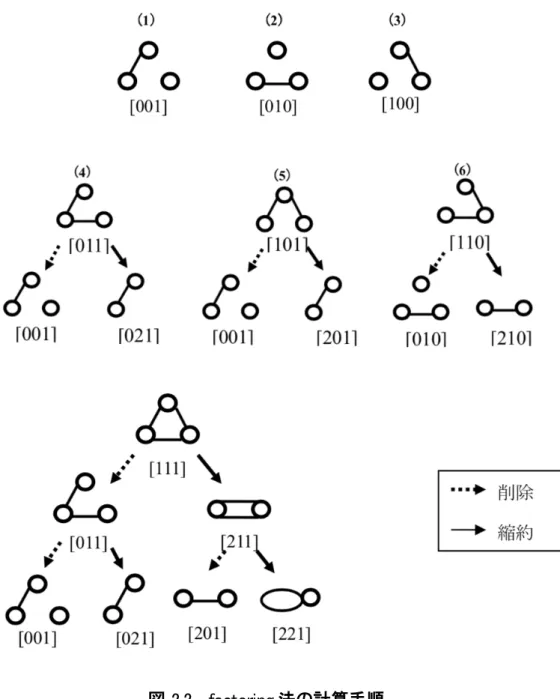
SDP(Sum of Disjoint Products)法,ファクタリング法などが知られている[5].
ファクタリング法は特定エッジの状態に注目して場合分けを行う方法で,小出
[12]
は部分ネットワークの全点間信頼度の算出について,ファクタリング法を全 部分ネットワークに対して適用する再帰的アルゴリズムを提案した.詳細な信頼 度算出方法については,付録で説明する.m
i = 1 , 2 , ! ,
7
2.2
全点間信頼度と構築コストを考慮した二目的ネットワーク問題 の定義本節では,全点間信頼度と構築コストを考慮した二目的ネットワーク問題につ いて述べる.
本研究ではネットワーク全点間信頼度とネットワーク構築コストの二つを目的 関数として問題を定義する.ネットワーク
𝐺
を無向グラフとする.ネットワー ク集合の中から,より全点間信頼度が高く,構築コストが低いネットワーク x を 解として求める.本研究で扱う問題を以下のように定式化する.𝑅(x) → 𝑚𝑎𝑥 𝐶(x) → 𝑚𝑖𝑛
𝑠. 𝑡. x ∈ 𝑋
この問題を,全点間信頼度と構築コストを考慮した二目的ネットワーク問題と する.しかしながら,この二つの目的関数は一般的にトレードオフの関係である.
従来の研究では,二目的問題を何らかの工夫により単一目的問題に変換する手 法で求めてきた.しかし,本研究で扱う二目的問題での本質は,二つの目的関数 間でいかにトレードオフをとるかという点にある.従来の解決法のようなスカラ ー化による単一の最適解を求めても不十分である場合が多いと考えられる.その ため,本研究では,二目的問題についてパレート解という重要な概念を考える.
2.3
パレート解の定義本節ではパレート解の定義を説明する.単一目的問題の場合では,全ての解候 補の中で,最も目的関数に優れた解(有点奇怪)を最適解ということができるが,
本研究で扱う二目的最適化問題の場合では,各解を単純に比較することができな いため,必ずしも最良な単一の最適解があるとは限らない.各解を単純に比較で きないため,他のどの解にも劣っていない解の集合を得る必要がある. このよう な解をパレート最適解[14]と呼ぶ.多目的最適化問題における解の優越関係の定 義とパレート解の定義を以下に示す.
8
優越関係の定義二つの連結構造であるネットワーク
x, x
O∈ 𝐺
に対して,① 全ての目的関数
𝑗
に対して,ただし,𝑗 = 1,2,3, … , 𝑁 , 𝑁
は整数である ,𝑓
B(x) ≤ 𝑓
B(x′)
のとき,ネットワークx
はx′
に優越という.② 全ての目的関数
𝑗
に対して,ただし,𝑗 = 1,2,3, … , 𝑁, 𝑁は整数である ,𝑓
B(x) < 𝑓
B(x′)
のとき,ネットワークx
はx′
に強く優越という.ネットワーク
x
がx′
に優越することは,ネットワークx
はx′
より良い解 であることを意味する.他のどの解にも優越されないような解を選ぶことで,パ レート最適解の集合を求めることができる.この優越関係に基づくパレート最適 解の定義を次に示す.
本研究では②に基づいて,パレート解の優越関係を定義す る.パレート解の定義
ネットワーク
x , x ′ ∈ 𝐺
に対して,x
に強く優越するx
O∈ 𝐺
が存在しないとき,x
を弱パレート解という. x
に優越するx
O∈ 𝐺
が存在しないとき,x
をパレート解という.
本研究では,ネットワークの全点間信頼度とネットワークの構築コストの二つ の目的関数に対し,パレート最適解を探索することを目的とする.全点間信頼度 と構築コストを考慮したパレート最適解の定義は以下に示す.
ネットワーク
x , x ′ ∈ 𝐺
に対して,①
𝑅(x) < 𝑅(x′)
かつ𝐶(x) > 𝐶(x′)
②
𝑅(x) = 𝑅(x′)
かつ𝐶(x) > 𝐶(x′)
③
𝑅(x) < 𝑅(x′)
かつ𝐶(x) = 𝐶(x′)
①だけを満たすときはネットワーク
x
に対して優越するネットワークx
Oが 存在しない場合,x
を強パレート解という.また,①,②,③ のいずれかを満 たすネットワークx
に優越するネットワークx′
が存在しないとき,x は弱パ9
図 2.2
パレートフロント
レート解という.また,パレート最適解が形成する曲面のことをパレートフロン トと呼び,以下の図
2.2
に示す.図
2.2
では縦軸はネットワークの全点間信頼度を表し,横軸は構築コストを表したものである.パレート最適解を表す黒の正方形を滑らかな線で繋ぐと,パレ ートフロントが形成される.また,灰色のひし型はパレート最適解以外の解を表 し,劣解と呼ぶ.
本研究ではネットワークの全点間信頼度とネットワークの構築コストを考慮し,
二目的最適化問題におけるパレート最適解を求める.
パレート最適解 劣解
信 頼 度
コスト
パレートフロント
10
2.4
全点間信頼度と構築コストを考慮した二目的ネットワーク設計 問題の先行研究高橋 他[13]ではパレート最適解をより効率よく求めるために,全点間信頼度と 構築コストの値においてパレートフロント付近の解となる部分ネットワークのみ の計算ができるように解の探索空間を制限する方法が提案されている.以下にそ のアルゴリズムの計算手順を示し,図 2.3 に提案するアルゴリズムの概要を示す.
はじめに,エッジ本数 𝑛 − 1 の全てのネットワーク x79/ を構成し,その集合 を 𝑋79/ とする.次に x79/
∈ { 𝑋
79/∖ 𝑋X
79/} を選択し, x
7 を構成する候補とす る.ただし,𝑋
? は,𝑋
79/ のうち選択対象外となるネットワークの集合とする.
候 補となったx
79/ にエッジ𝑒
, を追加してx
7 を構成し,その集合を𝑋
7とする.𝑋
7 に対しても同様に部分ネットワークの選択とエッジの追加を行い,ネットワーク
x
?のエッジ本数範囲を満たす式が
𝑘 = [𝑛 − 1, 𝑚] (2.3)
となる.このとき,各エッジ数𝑘
で構成可能なネットワークの集合を 𝐺∗? とす ると,𝑘 = 𝑛 - 1
のとき𝑋 = 𝑋
∗?,𝑘 = [𝑛, 𝑚]
のときは𝑋
?⊆ 𝑋
∗? となる.高橋 他
[13]
では,𝑋
? においてパレートフロント付近の解であるネットワークは,
𝑋
?]/ においてパレートフロント付近の解であるネットワークの要素である 可能性が高いと考え,エッジ本数ごとにネットワークを構成するアルゴリズムを 用いる.高橋 他[13]が提案するアルゴリズムでは,ネットワーク集合𝑋
? からパ レートフロントのネットワーク𝑋
79/∈ { 𝑋
79/∖ 𝑋X
79/}
を選択し,ネットワークx
? にエッジ𝑒
, を追加することで𝑋
?]/ を構成する方法を考える.アルゴリズ ムのフローチャートを図2.3
に示す.11
図 2.3
高橋[13]アルゴリズムの概要
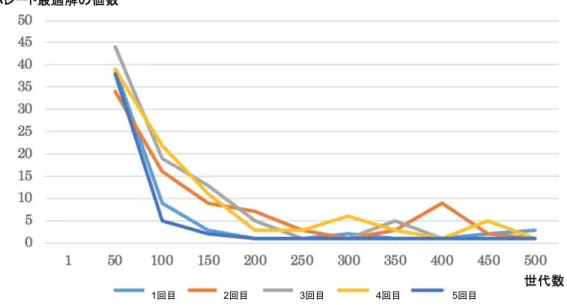
その結果,実験した範囲でわかったことであるが,提案したアルゴリズムによ り計算対象となるネットワークを大幅に制限しても,多くのパレート解を探索出 来ることが分かった.一方で,このアルゴリズムでは,全てのパレート解が求め られないことや,実際のパレート解ではない解も最適値として探索されることが あることも確認した.
また,高橋[13]の提案アルゴリズムは実際にノード数が
6
のネットワークに対 して適用すると,最適解の探索に3~4
秒程度の時間を要し,その結果全部分ネッ トワークを対象とし計算を行った場合は4~6
秒程度であり,対象となるネットワ ークの判定に負荷がかかっている状態であると考えられる.2.5
遺伝的アルゴリズム従来研究では,このような多目的最適化問題を解くために,進化的計算
(Evolutionary Computation)を多目的最適化問題に多く適用されており,特に遺伝 的アルゴリズム(
Genetic Algorithm
)が使用されていた.例えば,Schaffer(1985)
の ベクトル評価型の遺伝的アルゴリズム(Vector Evaluated Genetic Algorithm : VeGA
)[8]
をはじめ,パレート最適解のフロンティアを明示的に取り扱うGoldberg
のラ12
ンキング法や
Fonseca
らのmulti-objective GA
(moGA
)[2][9]
などが代表研究とし て挙げられる.2.5.1
遺伝的アルゴリズムの概要生物は自然淘汰,交叉,突然変異を繰り返し,環境に適応できるように進化し てきた.遺伝的アルゴリズムは生物が環境に適合して進化していく過程を工学的 に模倣したシミュレーション手法である.この進化過程を単純化し,工学的にモ デル化した確率的メタヒューリスティクスの一つが遺伝的アルゴリズムである.
遺伝的アルゴリズムは解空間に対して,多点同時に探索するという特徴があるた め,多目的最適化問題に遺伝的アルゴリズムを適用する場合,各目的関数に対し て,最優解ではないが,ある程度優良な個体を複数個同時に持ちながら次の世代 に影響を与えていくことができるため,直接最優解を求めなくても,世代数を重 ね,優良な個体をさらに優良な個体に進化しつづけることが可能であるので,パ レート解集合を求めることが可能と考える.
遺伝的アルゴリズムにおいては,ある世代を形成している個体の集合,すなわ ち個体群の中で,交叉や突然変異によって優れた個体を選択,次の世代の個体群 が形成されていく.個体群のなかに含まれる個体の数を個体群サイズと呼び,各 個体はそれぞれ染色体によって特徴がつけられている.さらに,染色体は複数個 の遺伝子の集まりにより構成されている.
13
図 2.4
二目的遺伝的アルゴリズムの概念図
図
2.4
では,本研究で扱うネットワーク全点間信頼度とネットワークを構築す るコストを二目的関数とした遺伝的アルゴリズムの各世代の解集合の推移の概念 図を示す.本研究では,二目的最適化問題における遺伝的アルゴリズムをベースとして用 いる.また,与えられたネットワークの全点間信頼度を計算する問題は #P 完全 であり,このような
NP
困難な組合せ問題や数学モデルの定式化が複雑な最適化 問題において,最良解を導出することが多い.すなわち,遺伝的アルゴリズムは 近似解を求める手法としても多く使われている.下記に本研究で扱う遺伝的アルゴリズムにおける各パラメータの値を説明する.
遺伝的アルゴリズムにおける各パラメータの値の設定
•
初期染色体個数(initial chromosomes size)初期染色体を生成する個数のこと.
•
集団サイズ(population size : 𝑝𝑜𝑝𝑆𝑖𝑧𝑒
) 集団に含まれる染色体の数のこと.•
最大世代数(maximum generation : 𝑚𝑎𝑥𝐺𝑒𝑛)
R(g)
C(g)
フロント パレート最適解
gen = 0 gen = k
gen = k-1
14
進化する過程に反復回数のこと.•
交叉確率(crossover probability :𝑝𝑐)
交叉操作を行う確率のこと.
•
突然変異確率(mutation probability :𝑝𝑚)
突然変異操作を行う確率のこと.
次に,遺伝的アルゴリズムの各ステップの概要について説明する.
遺伝的アルゴリズムにおける各ステップの概要 初期染色体集団の生成
初期解として,決められたサイズだけの染色体を問題の制約条件の元でランダ ムに生成し,初期の染色体集団を作成する.この処理手順をエンコーディングル ーチン(encoding routine)と呼ぶ.また,染色体から問題の解候補を生成する手順 をデコーディングルーチンと呼ぶ(decoding routine).
各染色体の適合度を表す評価関数
初期集団の各染色体に対して,対象問題の目的関数をもとに,定義した評価関 数である.つまり,対象問題に対しての適合度のことである.この適合度が染色 体の評価基準であり,適合度が高い染色体は世代の推移へ生き残る可能性が高く なる.
遺伝的操作
遺伝的操作は交叉,突然変異,選択3種類がある.詳細は
2.5.3
項で紹介する.遺伝的アルゴリズムのフローチャートを図
2.5
に示す.15
図
2.5 遺伝的アルゴリズムのフローチャート
遺伝的アルゴリズムでは,システム制約を満足する解候補をランダムに生成し,
これらの解を交叉や突然変異といった遺伝的操作を繰り返し行うことで,最適解 または最適解に近い近似解を導き出す.
遺伝的アルゴリズムの計算手順を以下に示す.
STEP 1
:[初期化]
初期染色体を一様乱数で複数個生成し,初期個体群に入れ.親集合を生成 する.
STEP 2
:[選択]
ルーレット選択法で親集合から個体を二つ選び,交叉を行う.
STEP 3
:[
交叉]
設定された交叉確率で一点交叉により交叉を行い新しい個体を生成する.
開始 初期集団の生成
再生
交叉
突然変異 評価
終了条件
終了
yes
no
16 STEP 4
:[
突然変異]
設定された突然変異確率で突然変異の方法により突然変異を行い,新し い個体を生成する.
STEP 5
:[終了判定]
世代数が最大世代数に達した場合,計算を終了し,得られた結果をパレー ト最適近似解集合として出力する.逆に,世代数が最大世代数に達しなか った場合では
STEP 2
へ戻る.2.5.2
遺伝子の表現生物では,遺伝情報を伝える役目をしているのは染色体(chromosome)である.
遺伝的アルゴリズムでは,問題に合わせ,解の候補を染色体と見なす,一次元の ビットまたは数値列として表すことを遺伝子の表現と呼ぶ.つまり,解のコード 化である.次の図 2.6 に染色体の例を示す.
また,対象とする問題の構造や性質を理解した上,遺伝子表現を設計することが 重要である.本研究では,ビット列を用いて遺伝子表現を設計する.図
2.6
で示 したように,染色体がビット数で示した場合,0
か 1 の数値でエッジの情報を 表すことができる.本研究では,染色体を一つのネットワークを表すために,染色体をビット数で 構成する遺伝子表現を用いる.詳細は第
3
章で説明する.図 2.6
遺伝子表現の例
遺伝子番号: 1 2 3 4 5 6 7 8 染色体: 1 0 1 0 0 1 1 1
バイナリ表現
遺伝子番号: 1 2 3 4 5 6 7 8
染色体: 1 2 5 7 4 6 8 3
順列表現
17 2.5.3
遺伝的操作遺伝的操作とは,次世代の解候補を生成するために生物の遺伝現象をモデル化 した遺伝的操作のことである.遺伝的操作は次の3種類がある.
交叉(
crossover
)交叉とは二つの親(
parent
)の染色体の間で,それぞれの遺伝子を交換する操作 である.すなわち,片方の親の部分解ともう片方の親の部分解を組み合わせるこ とにより,新たな子供(child)(子染色体(offspring))を生成することである.一般的の交叉では,二つの親に対して二つの子供が生成する.図 2.7 を例とし て示す.
図
2.7
を例として示されたのは一点交叉であり,Holland[3]
が最初に提案した 交叉方法である.また,他の交叉方法として,二点交叉,多点交叉,一様交叉な どがある.二点交叉
交叉ポイントをランダムで二つ選び,二つの交叉点に挟まれている部分を入れ 換える方法である.下記の図
2.8
は例として示す.図
2.8
が示した通り,二点交叉は一点交叉と同様に,交叉ポイントにより挟ま れている部分を交換することによって,二つの親が二つの子供が生成する.図 2.7
一点交叉例
親染色体1:
1 0 1 0 0 1 1 1
1 1 0 0 0 0 1 0
親染色体2:
1 2 3 4 5 6 7 8
交叉
1 2 3 4 5 6 7 8
子染色体1:
1 0 1 0 0 0 1 0
1 1 0 0 0 1 1 1
子染色体2:
1 2 3 4 5 6 7 8
1 2 3 4 5 6 7 8
18
図
2.8
二点交叉例多点交叉
一般に,三点以上の交叉ポイントをもつ方法を多点交叉あるいは
𝑛
点交叉(た だし,𝑛 = 1,2,3, … , 𝑁)という.一様交叉
一様交叉とは,各要素に独立でそれぞれに
1/2
の確率で入れ換える交叉である.下記の図
2.9
を例として挙げる.図
2.9
では,親染色体1
と親染色体2
の各遺伝子に対して,遺伝子番号1,4,5,7
の遺伝子では,同じ遺伝子であるため,交叉を行っても染色体は変更しない.図 2.9
一様交叉
親染色体1:
1 0 1 0 0 1 1 1
1 1 0 0 0 0 1 0
親染色体2:
1 2 3 4 5 6 7 8
交叉
1 2 3 4 5 6 7 8
子染色体1:
1 0 1 0 0 0 1 1
1 1 0 0 0 1 1 0
子染色体2:
1 2 3 4 5 6 7 8
1 2 3 4 5 6 7 8
親染色体1: 1 0 1 0 0 1 1 1
1 1 0 0 0 0 1 0
親染色体2:
1 2 3 4 5 6 7 8
交叉
1 2 3 4 5 6 7 8
子染色体1: 1 1 1 0 0 1 1 0
1 0 0 0 0 0 1 1
子染色体2:
1 2 3 4 5 6 7 8
1 2 3 4 5 6 7 8
交 換
不 交 換
交 換
交 換
19
遺伝子番号
2,3,6,8
の遺伝子では,それぞれに確率をつけると,交換,不交換,交換,交換という交叉を行った結果,子染色体
1
と子染色体2
が生成される.本研究では,従来の交叉方法ではなく,ネットワークを表す染色体構造を破壊 しないために,ネットワーク構造を考慮した交叉方法を提案する.第
3
章でその 交叉方法の詳細について説明する.突然変異(
mutation
)突然変異とは,親染色体内の遺伝子の一部を変えることで,新たな子染色体を 生成し,染色体集団の多様性を維持するための操作である.例えば,図
2.10
に示 すように,遺伝子表現に一次元のビット列の場合では,任意の遺伝子番号下の遺 伝子ビットを引っくり返させたり,数値の場合では,その任意の遺伝子番号下の 遺伝子を他の遺伝子と入れ換えるなどの方法もある.選択(
selection
)選択とは,各染色体の評価関数に基づき,適合度の高さに応じて,染色体を選 択し,次世代の染色体集団を構成するための操作である.選択方法には,適合度 比例法や期待値選択法,ランク選択法,エリート保存法などがある.
2.6
並列分散遺伝的アルゴリズム遺伝的アルゴリズムでは,世代の推移の時,適応度比例選択(ルーレット選択)
図
2.10
突然変異例変異前: 1 0 1 0 0 1 1 1
1 2 3 4 5 6 7 8
突然変異 変異後: 1 1 1 0 1 1 1 0
1 2 3 4 5 6 7 8
20
図
2.11
局所解の発生等の方法で親として染色体を選択する.これは優良な個体を確率的に多く選択す る方法であるが,これによって,全体の中での最適解ではなく,近隣の似た解の グループの中での最も良い解だけが増えてしまう傾向がある.
図 2.11 のように,ある世代で優良解が選択されると,さらに選択された局所 個体群の中での交叉によって,作り出した新たな子染色体では,前の親染色体と 似た染色体ばかりになってしまう事が起きる.これが遺伝的アルゴリズムにおけ る局所解収束の状況である.この状況に落ちると交叉またはある程度の突然変異 を行なっても,なかなか局所優良解以上の染色体を生成することが困難になる.
本質的に染色体の構造を変え,全個体群の中でさらに優れた染色体のグループに 脱出する事が重要だと考えられる.つまり,局所解から避けることが重要である.
遺伝的アルゴリズムでは「解の多様性」が重要とされる.そのため,常に一定 数の遺伝子をランダムに作り変える操作を入ることが使われている.しかしなが ら,ランダムに作った解は構造によらないため,選択される局所解との類似度は 低いが,適応度の期待ができないので,次世代の集団の中ではすぐに淘汰されて
目的関数
設計変数 大域的最適解 局所最適解
比較的評価が高い解
21
しまう.そのため,単なる多様性ではなく,進化した解の多様性を保つことが重 要である.本研究では並列分散遺伝的アルゴリズムの概念から,ネットワークを 全点間信頼度で分類して,より全点間信頼度が近いネットワークの間で遺伝的操 作を行う層別法を提案する.
次に,島遺伝的アルゴリズムを紹介する.自然の中では,多様な種族がある.
空に飛ぶ鳥族,川や海で泳ぐ魚族,陸地で生活する人族などの生息範囲によって,
環境が大きく違うことが考えられる.同じ陸地でも,砂漠と熱帯雨林の生き物の 在り方もそれぞれ違っている.様々な環境があることによって,生物の種類は多 様であることがわかる.また,離れた地域の個体同士は交流がなく,遺伝子の交 換が行わないため,その範囲内独自の進化を行なう.
島遺伝的アルゴリズムでは,島ごとに異なる交叉率や突然変異率等のパラメー タを設定出来る.しかし,進化型計算では,特定の最適化問題に適用するなど,
進化の向きを固定する必要があるため,パラメータを統一する必要がある.基本 的には島の中の個体群のみで交叉が行われるため,島ごとに異なる局所優良解に 到達する事が可能であり,島ごとで求めた局所優良解は全体の最適解であること が考えられる.
図 2.12
島遺伝的アルゴリズム
島B 島A
島C
島D
島E
22
第
3
章 層別法とネットワーク構造を考慮した交叉 を取り入れたGA
ベースのアルゴリズムの提案本章では,遺伝的アルゴリズムをベースとする提案法を説明する.本研究では 層別法と特殊な交叉方法を用いて,二目的ネットワーク問題におけるパレート最 適解を求めるアルゴリズムを提案する.
3.1
節は,提案するアルゴリズムの概要及 びフローチャートやステップ図を紹介する.3.2
節は,ビット列を用いて遺伝子表 現を設計する方法を述べ,ビット演算の概要を紹介する.次に,3.3
節では,ビッ ト列で表現された染色体および初期染色体の生成方法について述べる.またネッ トワークの適合度の設定は3.4
節で述べる.最後に3.5
節で層別法の提案および3.6
節に遺伝的操作(ルーレット法,ネットワーク構造を考慮した交叉法,突然変 異)について説明する.3.1
提案アルゴリズム及びフローチャート本研究では,二目的ネットワーク問題におけるパレート最適解を効率的に求め るために,島遺伝的アルゴリズムの戦略に基づいた層別法を提案する.全体のネ ットワーク集団をネットワーク全点間信頼度で分類し,層ごとに優良解を求める.
また,層ごとに遺伝的操作を行うことについては,
2.6
節で述べた通り,層ごとに 求めた優良解を極めて最適解に近づける方法を考える.また,計算スピードを早 くするために遺伝子表現の設計を考慮した上で,ビット演算を導入する.実行計 算上にメモリの使用量を減少し,また,それにより計算スピードをあげることが 期待できる.また,ネットワーク構造を考慮して従来の交叉方法を改善し,提案 する交叉操作による生成した新たな染色体を制御することを考えた.ネットワー ク構造を考慮した交叉方法を提案した.提案するアルゴリズムのフローチャートは下の図で示す.
23
図
3.1
提案アルゴリズムのフローチャート※1 3.2節で説明する
※2 3.3節で説明する
※3 3.5節で説明する
※4 3.6.1項で説明する
※
5 3.6.2
項で説明する※
6 3.6.3
項で説明する開始
STEP1:初期染色体を生成
※2
STEP4:
改善交叉法で交叉を行う※5
STEP5:
突然変異を行う※
6
STEP3:ルーレット法を用い,親を選択
する※4STEP6:最大
世代数を超え終了
yes
no
ビット列を利用し,染色体を表す
※1
STEP2:層別法を利用し,親集合を生
成する※324
また,提案アルゴリズムの手順を以下に示す,STEP 1:[初期化]
初期染色体を一様乱数で集団サイズ
popSize
個生成する.STEP 2:設定された全点間信頼度で層別法を実装し,親候補を洗練する.条件に
満たさないネットワークを削除し,代替のネットワークを入れて,親集合 を生成する.層別法の詳細は3.5
節で説明する.STEP 3
:[
選択]
ルーレット選択法で親集合から二つ染色体を親染色体として選択する.
選択された二つの親染色体を交叉する.
3.6.1
項では,ルーレット選択法 を詳細に紹介する.STEP 4
:[
交叉方法]
交叉ポイントとしてノードが選択され,選択されたノードに接続してい るエッジを交換し,新たな個体を生成する.ネットワーク構造を考慮した 交叉方法の詳細は
3.6.2
項で説明する.STEP 5
:[
突然変異]
ノード次数が最大なノードが選択され,連結が維持できる上で,ノードに 接続している最大コストを持つエッジをカットし,新たな個体を生成す る.突然変異の詳細は
3.6.3
項で説明するSTEP 6:[終了判定]
世代数が最大世代数に達した場合.得られた結果をパレート解集合とす る.そうでなければ
STEP 2
へ戻る.本研究は遺伝子表現を設計するために,ビット列を利用した.「
0
」 か 「1」の数値でエッジが接続する情報を表すことができる.また,交叉を行う際に,ビ ット演算を利用し,染色体間の遺伝子交換することができる.次節はビット演算 についてビット演算の概要について説明する
3.2
ビット演算ビットとは
2
進数で表されるコンピューターが扱う情報量の最小単位である.25
1
ビット で2
進数の1
桁が「0
」か「1
」かを表せる.そしてビットを並べたも のをビット列という.ビット演算 [7] とは,ビット列に対して,各々のビット全 てに対する論理演算を同時に行う演算操作である.ビット演算のメリットとして 複数の真理値を一つの変数で管理できることがあげられる.例えば,32
ビットの 符号なし整数の場合は32
個の真理値を保存でき,複数のビットに対して同時に 操作をすることができ,これにより,計算速度が早くなる.
本研究では,
2.5.2
項で説明した通り,ネットワークの構造をビット数で表す.また,頂点数 n のネットワーク g に対して,染色体の長さ
n(n − 1)/2 のビット
数で表すことができる.しかしながら,デメリットもある.ビット演算は整数型 の変数にしか適用できない.開発環境によって,最大64
ビットまでしか扱えな いことがある.ビット演算子には右シフト≫
, 左シフト≪
,論理積 & ,論 理和 |,排他的論理和^
がある.右シフト≫
と左シフト≪
はシフト演算であり,他の演算子と違って,ビット単位の演算子ではなくビット列に対しての演算であ る.また,シフト演算子とも呼ばれる.以下では,実験で使用した演算子に対し て紹介する
.
右シフト
≫
とは,ビット列を右にずらすという操作である.空いているビッ トには,「0」が入り,0 ビット目以下は切り捨てられる.例えば,1 ビット右 シフト演算させることによって元の整数は 0.5 倍になる.左シフト
≪
とは,ビット列を左にずらすという操作である.空いたビットに は, 「0
」が入る.例えば,1
ビット左シフト演算させることによって元の整 数は2
倍になる.
論理積 & とは,演算子の左辺と右辺の同じ位置にあるビットを比較して,両 方のビットが共に「1」の場合だけ「1」にする.
論理和
|
とは,演算子左辺と右辺の同じ位置にあるビットを比較して,両方の ビットのどちらかが「1
」の場合に「1
」にする.
26
図 3.2
グラフ𝐺
-, 𝐺
.同型グラフの例
排他的論理和
^
とは,演算子の左辺と右辺の同じ位置にあるビットを比較し て,ビットの値が異なる場合にだけ「1」にする. 表3.1
に7
と10
に対してビッ ト演算を行なった結果を紹介する.以下では「( )2
」で2
進数表現(
ビット 列)
を表現する.
図
3.2
の(1)
はグラフを表す正方形行列を隣接行列と呼ぶ.隣接行列は,グラフを表わすために使われる正方行列である.この行列の要素は,頂点の対がグラ フ中で隣接しているかどうかを示す.
図
3.2
の (2) は隣接行列とビット列の対応する方法を表す.本研究では隣接行列の対角線より左下の成分をビット列に対応させた.隣接行 列の
2
行1
列目の成分を0
ビット目に,3
行1
列目の成分を1
ビット目に対 応さ せ ,そ の 後順 に 対 応さ せ て い き , 最後に𝑛
行𝑛 − 1
列 目の 成分 を0 1 1 1 1 0 0 0 1 0 0 1 1 0 1 0 0 1 1 1
1 0 0 0 1 0 0 1 1 0 1 0
(1) グラフGa (2) グラフGb
(101011)
2= 43
表 3.1 ビット演算の例ビット演算子 2 進数 10 進数
≫
(0111)2≫
2 = (0001)2 7≫
10 = 1≪
(0111)2 ≪ 2 = (11100)2 7 ≪ 10 = 28& (0111)2 &(1010)2 = (0010)2 7&10 = 2
| (0111)2 | (1010)2 = (1111)2 7 | 10 = 15
^
(0111)2^
(1010)2 = (1101)2 7^
10 = 1327 0
1(1 – 3)4
5 − 1
ビット目に対応させた.これにより,各ビットにおける0
はそのビットに対応するエッジが存在しないことを表し,1 はそのビットに対応する辺が 存在することを表す.また,ビット列における 1 の数がエッジの本数に対応する.
本研究は,1 次元配列ではなくビット列でエッジ集合を記述するメリットとし て,以下の
2
つがある.for 文一つでグラフの生成ができる
エッジ集合をビット列で記述した場合,整数で表現され for 文一つでグラフの 生成ができる. ビット列で記述しない場合は再帰を用いてグラフの生成を行うた め時間がかかる.
計算が速い
ビット列で記述することで,複数の真理値を
1
つの変数で管理できるので計算 が速くなることを牧石[15]
が証明した.以下,牧石[15]
がビット列で記述した場合 と 1 次元配列で記述した場合の計算時間の比較結果を表 3.2 で表す.本研究では,遺伝子表現をビット数で表し,「1」遺伝子番号の位置でエッジ が構築したことを意味する,「0」遺伝子番号の位置にエッジが構築していない ことを意味する.
表
3.2
牧石[15]
隣接行列の記述の違いによる計算時間の比較 頂点数 5 6 7 81 次元配列 465 12579 664312 98696357 ビット列 406 9370 495945 65777018 削減率 (%) 13 25 26 33
28 3.3
初期染色体ノード数が
n
の場合,初期の染色体は,1(1 – 3)4
(
つまり,完全グラフのエッジ本 数) ビットの 2 進数で表すことができる.エッジの有無を表す各遺伝子に対して,数値「0」か「1」をランダムに生成することにより染色体を生成する.
また,
2
進数では,10
進数に変換することができるので,ビットすべてランダ ムに初期するということは 1 から2
06(6 – 7)8 5 範囲内の整数をランダムに生成す ることと同様である.ビット列を利用したことによって,一つの
10
進数で,表現することができる.よって,染色体を生成する過程が簡単になる.
3.4
ネットワーク適合度の定義本研究では,ネットワークを構築するコスト
C(x)
とネットワーク全点間信頼度
𝑅(x)
を利用し,原点からパレート最適解と劣解までを結んだ直線の傾きを計算する.ネットワーク構築するコスト
C(x)
分のネットワーク全点間信頼度𝑅(x)
と設定する.下記の式をネットワーク
x
の適合度とする.ネットワークの適合度:
𝑓(𝑠
>) =
@(>)A(>)(3.1)
である.下記の図
3.3
では,パレート最適解と劣解を一つ選択され,それぞれ原点と結 んだ直線を直線1
と直線2
とする.図で示した通り,直線1
の傾きが直線2
の傾 きより大きいことがわかり,また他の優良解を原点と結んだ直線の傾きを観察す ると,傾きが大きい傾向があるとわかった.本研究はより良い解を求めるため,扱う全点間信頼度と構築コストを考慮した ネットワークの適合度を式 (3.1) として傾きがより大きくなる解を優れた解とみ なす.
29
図 3.3
原点からパレート最適解と劣解までを結んだ直線の傾きをそれぞれ表す
3.5
層別法「層別」とは,大規模な集団の中で,ある特徴によって,いくつかのグループに 分類することである.重要と思われる項目でデータを層別して,同じ共通点や特 徴を持ついくつかのグループに分類し,比較することである.
本研究は,層別法の特徴を利用し,全点間信頼度によって,層別した染色体の 集団ごとに交叉操作をさせることによって,より優良な染色体を探索することを 考える. 親染色体を生成するとき,層別を用いて,条件に満たさない染色体を淘 汰する.層別の条件として,次に紹介する.
パレート最適解 劣解
信 頼 度
C(x) R(x)
0
直線1
直線2