2018 年度 修士論文
価値観に基づく行列ベース 協調フィルタリングに関する研究
Study on Matrix Based Collaborative Filtering Employing Personal Values
指導教員 高間 康史 教授 首都大学東京大学院 システムデザイン研究科
システムデザイン専攻 情報通信システム学域
17890521 白石 雄也
2019/02/22
目 次
1
はじめに1
2
関連研究3
2.1
情報推薦. . . . 3
2.1.1
情報推薦システム. . . . 3
2.1.2
情報推薦の問題点. . . . 5
2.1.3
情報推薦における評価指標. . . . 6
2.2
行列ベース協調フィルタリング. . . . 8
2.2.1
行列ベース協調フィルタリングの代表的手法. . . . 8
2.2.2
行列ベース協調フィルタリングにおける機械学習. . . . 11
2.2
価値観. . . . 13
2.2.1
価値観モデル. . . . 13
2.3.2
価値観に基づく情報推薦手法. . . . 15
3
提案手法17 3.1
予測スコアの計算. . . . 17
3.2
関係行列. . . . 19
3.3
最小二乗法による関係行列の生成. . . . 20
3.4 Bayesian Personalized Ranking
による関係行列の生成. . . . 22
4
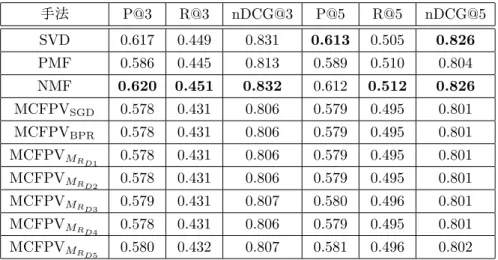
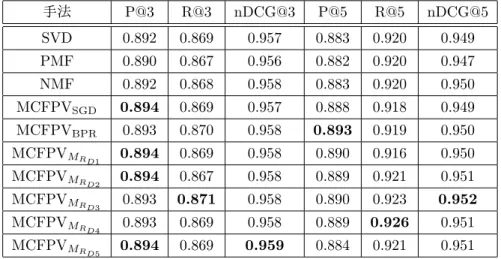
評価実験26 4.1
データセット. . . . 26
4.2
実験概要. . . . 28
4.3
評価実験. . . . 31
4.3.1
推薦精度. . . . 31
4.3.2
推薦アイテムの多様性. . . . 41
4.3
関係行列の考察. . . . 46
5
おわりに48
謝辞
49
参考文献
50
発表文献
53
1 はじめに
近年,Amazon
1
をはじめとするオンラインショッピングサイトなどにおいて,ユーザが扱うことの できる情報が増え続けている.その結果,莫大なデータ・アイテムの中からユーザの嗜好に合致した 目的のアイテムを探すのが困難になっている.この様な状況を情報過多と呼び,ユーザにとって有益 な情報を探し出すことを支援することが重要になっている.ユーザの嗜好・意図に合致したアイテム を提示する手法として,様々な情報推薦システムが広く利用されている[10, 21, 25, 32]
.代表的な情報推薦システムとして,内容ベースフィルタリング
[10]
や協調フィルタリング[32]
があ る.内容ベースフィルタリングは,ユーザが過去に閲覧・購買したアイテムと類似した特徴を持つア イテムを推薦する手法である.協調フィルタリングは,ユーザのアイテムへの評価値を用いて,嗜好 が類似するユーザを探し,推薦対象者と嗜好が似ているユーザが好むアイテムを推薦する.協調フィ ルタリングは,モデルを構築する際のアプローチとして近傍ベース[32, 25],行列ベース [21, 34],グ
ラフベース[20]
などに分けられる.その中で,評価情報が不足している場合に予測精度を向上させ るためのアプローチの一つとして,行列ベース協調フィルタリングにおける行列分解法[21]
が注目 を集めている.協調フィルタリングはドメイン知識を利用せずに推薦を行える点が利点である.しかし,協調フィ ルタリングには,
cold-start
問題[37]
やsparsity
問題[24]
といった課題が存在する.cold-start
問題 は,新たにシステムを利用し始めたユーザや評価がされていない新規アイテムといった,評価件数 が少ない対象に対して予測精度が低下する問題である.sparsity問題は,推薦システムが扱うことが できるアイテム数に対して,ユーザが付与した評価件数が少ない場合に予測精度が低下する問題で ある.嗜好に合ったアイテムを推薦することは情報推薦システムが満たすべき重要な基準であるが,ユー ザがすでに知っているアイテムを推薦することは有用ではない.予測精度向上以外の課題として,解 釈性が高い推薦や推薦アイテムの目新しさ・セレンディピティ[1, 16, 44],多様性
[7, 8],ロングテー
ルアイテムの推薦[14, 27]
などが重要視されるようになってきている.ここで,ロングテールアイテ ムとは,評価件数が少ない不人気のアイテムのことである.これらの課題に対する解決策の一つとし て,価値観を情報推薦へ応用したアプローチが研究されている.価値観は,ユーザの購買行動や意 思決定に重要な要素として知られており,マーケティングやWeb
インテリジェンスにおいて利用されている
[18, 41].情報推薦においては,アイテムの属性に対するユーザのこだわりの強さとして定
義され,評価一致率を利用したモデルの構築方法が提案されている
[15].評価一致率とは,価値観を
定量的に表す指標で,ユーザのアイテムに対する総合評価の極性(好評または不評)と,アイテム の属性に対する評価極性が一致する割合である.内容ベースフィルタリング[39]
や近傍ベース協調 フィルタリング[5]
などに応用されており,少ない評価件数で安定してモデルを生成できることが報 告されている.本論文では,価値観に基づく情報推薦の新たな手法として,近年主流である行列ベースの協調フィ
1
http://www.amazon.co.jp/
ルタリングに価値観を導入した手法を提案する.提案手法では,ユーザ・アイテムを行,アイテム の属性を列とし,各要素が評価一致率となる行列としてユーザモデル,アイテムモデルを表現する.
従来の行列ベース協調フィルタリングのアプローチでは,行列の潜在因子が何を表現しているのか解 釈が困難であるが,提案手法ではアイテムの属性を用いているため解釈が容易であり,推薦説明の 生成などにおける有効性が期待できる.また,ユーザ・アイテムを表す行列の他に,ユーザ・アイテ ムモデル間の関係を表現する行列(関係行列)を導入する.関係行列を適切に設定することにより,
ユーザモデル,アイテムモデル間の属性の対応関係を考慮し,適切なマッチングを実現することを目 指す.提案手法では,ユーザ・アイテムを表す行列と関係行列の積を求めることで,ユーザのアイテ ムに対する予測スコアを計算する.関係行列は手動で設定する方法と機械学習によって学習する方法 を提案する.機械学習を用いたアプローチでは,最小二乗法に基づき予測スコアと真値の二乗誤差を 確率的勾配降下
[21]
により最小化する手法,BPR(Bayesian Personalized Ranking)[29]によって 不評・未評価のアイテムより好評のアイテムの予測スコアが高くなるように事後分布を最大化する手 法を提案する.評価実験では,
Yahoo!
映画2
,楽天トラベル3
,ホットペッパービューティー4
,4Travel 5
,livedoor
グルメ6
といった5
種類の実際のWeb
サイトから抽出したデータセットを利用し,代表的な行列ベース 協調フィルタリングであるSVD
(Singure Value Decomposition
)[34]
やPMF
(Probabilistic Matrix Factorization)[36]
との比較を行う.ユーザに推薦された上位k
件のアイテムについて,適合率[26]
や再現率
[2],nDCG(normalized Discounted Cumulative Gain)[17]
を比較した結果,評価件数が 少ないユーザが多数存在するようなデータセットにおいて従来手法と同等の推薦精度が得られたこ とを示す.推薦アイテムの多様性[7, 8]
やロングテールアイテム[14, 27]
の推薦に関して比較した結 果,提案手法は従来手法より様々なアイテムを推薦可能であり,ロングテールアイテムの推薦に対し ても有効であることを示す.提案手法の解釈性に関して,機械学習により生成した関係行列を分析 し,評価において重要な属性に基づいた学習結果が得られていることを示す.2
http://movies.yahoo.co.jp/
3
http://travel.rakuten.co.jp/
4
http://beauty.hotpepper.jp/
5
http://4Travel.jp/
6サービス終了(2019年
2
月22
日現在)2 関連研究
2.1 情報推薦
近年,情報化技術の進展に伴ない,誰もが容易に大量の情報を発信・蓄積できるようになったこと で,ユーザが扱うことのできる情報が莫大なものとなってきている.代表的なものとして,Amazon や楽天
7
のような世界規模のオンラインショッピングサイトでは,数億種類を超える商品が登録され ている.この様な状況の中,大量に溢れている情報から,適切に有用な情報を探し出すことは困難 である.これを,情報過多(Information Overload)と呼ぶ.ユーザにとって有益な情報を提示する ことが重要になってきており,情報を探し出すのを支援する主要な技術として,情報推薦システムが 研究されている.本節では,情報推薦システムについての歴史,代表的な情報推薦手法を述べた後,問題点や評価指標について説明する.
2.1.1 情報推薦システム
ユーザの嗜好などをもとに必要な情報を取り出したり,不要な情報を排除することを,情報フィ ルタリングと呼び,情報推薦システムはその一種に位置づけられる.情報フィルタリングの研究は
1980
年代後半から行われてきた[3]
.当時注目を集めた手法として,1994
年にResnick
らが考案したGroupLens
のアルゴリズム[32]
がある.このアルゴリズムは,システムの購買履歴に基づき,嗜好が類似するユーザが好むアイテムを推薦するアルゴリズムである.
GroupLens
のアルゴリズムは協 調フィルタリングと呼ばれ,ドメイン知識を利用しない低コストの手法として,この手法を改良する 研究が多く行われるようになった[2].
情報推薦は,大きく内容ベースフィルタリング
[10]
と前述の協調フィルタリング[32]
に分けられ る.内容ベースフィルタリングは,アイテムの特徴とユーザの嗜好に基づき推薦を行う.例えば,文 書を対象アイテムとした場合,キーワードの出現頻度を表すベクトルを生成することで,ユーザの嗜 好に近い特徴をもつアイテムを推薦する.内容ベースフィルタリングの代表的な例として,Billsus らはニュース記事を対象とし,k-nearest neighbor法[12]
を利用して,ユーザが直近で評価した記事 に類似するニュースを推薦するシステムを考案している[10]
.協調フィルタリングは,アイテムの情報を利用せず,ユーザがアイテムに対して付与した評価履歴 を利用して,評価したアイテムの評点が類似しているユーザが好むアイテムを推薦する手法である.
協調フィルタリングには,嗜好が近いユーザに基づき予測評価値を求めるユーザベース方式と,アイ テム間の類似度を計算しユーザにアイテムを推薦するアイテムベース方式に分けられる.協調フィル タリングの代表例として,GroupLens [32]と
Amazon [25]
のアルゴリズムについて説明する.GroupLens
は,類似度が高いユーザが好むアイテムは,推薦対象のユーザも好むという仮定に基づく,ユーザベース協調フィルタリングに基づいている
[32].ユーザの集合を U
,アイテムの集合を7
https://www.rakuten.co.jp/
V
,ユーザx i ∈ U
がアイテムy j ∈ V
に付与した評価値をs i,j
とすると,GroupLensのアルゴリズ ムでは次のようなステップでアイテムの推薦を行う.•
推薦対象のユーザx i
と,他のユーザx t ∈ U \ { x i }
がともに評価を付与したアイテムの集合V i,t
において,ユーザ
x i
,x t
の類似度p i,t
を,Pearson
相関係数を利用して計算する.(式(2.1)
)p i,t =
∑
y
k∈ V
i,t(s i,k − s ¯ ′ i )(s t,k − ¯ s ′ t )
√ ∑
y
k∈ V
i,t(s i,k − ¯ s ′ i ) 2 √ ∑
y
k∈ V
i,t(s t,k − ¯ s ′ t ) 2
(2.1)
¯
s ′ i
は,Vi,t
に含まれるアイテムに対し,ユーザx i
がつけた評価値の平均で式(2.2)で表される.¯
s ′ i = ∑
y
k∈ V
i,ts i,k
| V i,t | (2.2)
•
ユーザx i
が未評価のアイテムy j
に関して,yj
を評価済みのユーザ集合U j
を用いて,xi
によ るy j
の予測評価値s ˆ i,j
の計算を行う.(式(2.3))
ˆ
s i,j = ¯ s i +
∑
x
k∈ U
jp i,k (s k,j − ¯ s k )
∑
x
k∈ U
j| p i,k | (2.3)
¯
s i
は,xi
が評価した全アイテム集合V i
における評価値の平均で,式(2.4)
で表す.¯
s i = ∑
y
k∈ V
is i,k
| V i | (2.4)
•
式(2.3)により計算されたユーザx i
の予測評価値から,値の大きいアイテムを降順に並べる ことで推薦リストを作成する.Amazon
のアルゴリズム[25]
では,アイテム間の類似度を求めることにより,対象ユーザが閲覧したアイテムと関連のあるアイテムを推薦するアイテムベース方式を採用している.
y ⃗ i
をアイテムy i
が全ユーザから付与された評価値を並べたベクトルとすると,y i
,y j
の類似度p i,j
はcos
類似度 により,式(2.5)
で計算される.ユーザが未評価のアイテムの評点は0
として扱う.p i,j = y ⃗ i · y ⃗ j
|| y ⃗ i || · || y ⃗ j || (2.5)
2
種類のアイテムの組み合わせ全てに対して類似度を計算し,ユーザの閲覧履歴に存在するアイテ ムと類似度が高いアイテムをユーザに提示する.アイテムベース協調フィルタリングは,事前にオフ ラインでアイテム間の類似度を計算しておくことができるため,ユーザがアイテムを閲覧したとき,高速でリアルタイム性のある推薦が可能という利点がある.
モデルに基づく観点で協調フィルタリングを分類すると,近傍ベース
[32, 25],行列ベース [21, 34],
グラフベース
[20]
などのアプローチに分けられる.近傍ベースには,前述したGroupLens
やAmazon
のアルゴリズムが該当し,類似度の高いユーザやアイテム(近傍ユーザ・アイテム)に基づき評価値 を予測する.グラフベースでは,グラフ理論におけるランダムウォークを利用し推薦アイテムを決定する.
Konstas
らは,音楽サイトlast.fm 8
における視聴楽曲,タグ,ユーザ間の友好関係をグラフ構造で表現し,ラ ンダムウォークを利用することでユーザの嗜好を予測する手法を提案している[20].評価実験におい
て近傍ベース協調フィルタリングと比較し,グラフベースの方が高い推薦精度が得られたことを報告 している.行列ベースでは,ユーザ・アイテムの潜在因子行列の積をとり予測評価値を計算し,アイテムを推 薦する.Korenらは,行列分解法により生成されるユーザ・アイテムの潜在因子行列を,機械学習を 用いて最適化し,それらの行列の積を求めることでユーザとアイテムの予測評価値行列を生成する アプローチを提案している
[21].行列分解法を利用した行列ベース協調フィルタリングは,評価情報
が不足している場合でも推薦精度が高いことで知られている[21, 34]
.行列ベースのアプローチにつ いて,2.2
節で詳しく説明する.2.1.2 情報推薦の問題点
協調フィルタリングはドメイン知識を利用せずに推薦を行える点が利点である.しかし,協調フィ ルタリングには,cold-start問題
[37]
やsparsity
問題[24]
といった課題が存在する.cold-start問題 は,新たにシステムを利用し始めたユーザや評価がされていない新規アイテムといった評価件数が 少ない対象に対して,予測精度が低下する問題である.sparsity
問題は,推薦システムが扱うことが できるアイテム数に対して,ユーザが付与した評価件数が少ない場合に予測精度が低下する問題で ある.それに対し,内容ベースフィルタリングでは,ユーザプロファイルが作成できれば,アイテムの特 徴と比較することにより推薦可能であるので,新規アイテムに対する
cold-start
問題の影響を受けに くい利点がある.しかし,内容ベースフィルタリングにおいても,推薦対象アイテムの特徴量が莫大8
https://www.last.fm/
で,新規ユーザに関する情報が不足している場合に,協調フィルタリングと同様に
cold-start
問題やsparsity
問題が発生することが指摘されている[2, 42].
嗜好に合ったアイテムを推薦することは情報推薦システムが満たすべき重要な基準であるが,ユー ザがすでに知っているアイテムを推薦することは有用ではない.そのため,推薦アイテムの多様性
(
Diversity
)[7, 8]
やロングテールアイテムの推薦[14, 27]
,目新しさ(Novelty
)・セレンディピティ(
Serendipity
)[1, 16, 44]
などが推薦の目的として注目されてきている.推薦アイテムの多様性は推薦されたアイテムの種類の多さを表し,ロングテールアイテムとはユー ザから付与される評価件数が少ない不人気アイテムのことである.両者は互いに独立ではなく,ロ ングテールアイテムを推薦することによって,推薦アイテムの多様性も高くなることが知られてい
る
[7].ロングテールアイテムは人気アイテムに比べると評価件数が少ないため,新規アイテムと同
様の問題が発生し,推薦が困難である.従って,情報推薦では,推薦アイテムが人気アイテムに偏っ てしまう課題が存在する
[8].また,Brynjofsson
らは,ロングテールアイテムと人気アイテム両方が ユーザの売上意識を改善する要因になると言及している[11].これは,推薦対象のアイテムが人気ア
イテムに偏る情報推薦システムは望ましくないことを示唆する.Goldstein
らも,ロングテールのア イテムは,新規アイテムや人気アイテムよりも導入・維持・プロモーションなどにかかるコストが低 いため,推薦アイテムの多様性が高い情報推薦システムとし,ロングテールアイテムを提示すること で,サービスのコストを低減できると報告している[14].
情報推薦におけるセレンディピティとは,推薦アイテムの目新しさに,思いがけない・予測できな かった・意外性のあるなどの要素を加えた概念である
[1].例えば,映画を推薦する場合,ユーザが
同じ監督の作品を多く視聴しているとき,その監督の新作を推薦しても,ユーザにとってその作品は 既知である可能性がある.一方で,その監督と同じ作風の,ユーザがまだ知らない監督の作品を推薦 したとすると,ユーザはその作品に関心を抱く可能性があり,意外性のあるアイテムを推薦したこと になる.セレンディピティが高い推薦とは,このようなユーザにとって思いがけないアイテムを推薦 することを表す.セレンディピティに関して,内容ベースフィルタリングでは,ユーザが関心のある特徴を持つアイ テムが推薦されるため,セレンディピティのある推薦は困難である
[2]
.映画で例えると,内容ベー スではユーザ知識に依存して同ジャンル・監督の作品が推薦されることが多くなるため,ユーザに とって意外な推薦とはならない.それに対して,協調フィルタリングでは,他のユーザが好むアイテ ムを推薦するため,自身がまだ知らないアイテムが推薦される可能性がある.そのため,セレンディ ピティの面では,協調フィルタリングが有効であると言われている[2].
2.1.3 情報推薦における評価指標
情報推薦において,推薦精度を表す指標として予測誤差が利用される.予測誤差とは,ユーザがア イテムに対して付与した評価値と,推薦アルゴリズムによって得られた予測評価値の差のことであ る.代表的な評価指標には,MAE(Mean Absolute Error)と
RMSE(Root Mean Square Error)
がある
[33].テストデータを S test
とすると,MAEは式(2.6),RSME
は式(2.7)
で表される.MAE = 1
| S test |
∑
s
i,j∈ S
test| s ˆ i,j − s i,j | (2.6)
RMSE = v u u t 1
| S test |
∑
s
i,j∈ S
test(ˆ s i,j − s i,j ) 2 (2.7)
予測誤差以外の評価指標として,推薦リストにおける上位
k
件のランキングをユーザに提示する 方法がある.ランキングに向けた推薦精度を測る指標として,Precision atk(P@k)[26],Recall at k(R@k)[2],normalized Discounted Cumulative Gain at k(nDCG@k)[17]
を紹介する.適合率
[26]
は,得られた推薦結果において,興味ありのアイテムが占める割合を表す.興味あり/無しのアイテムは,バイナリの評価値で表現する必要がある.例えば,評価値が
1〜5
のデータセッ トを利用する場合,評価4・5
のアイテムを興味あり,1〜3を興味無し,のように判断したり,閾値 を用いて興味あり/
無しの判断をすることで,評価値のスケールを変換する必要がある.r i
を,アイ テムy i
が興味ありのアイテムは1
,興味無しのアイテムは0
をとるとすると,上位k
件の推薦結果 に対する適合率P@k
は式(2.8)
で表される.P@k =
∑ k i=1
r i
k (2.8)
再現率
[2]
は,ユーザが興味を持つアイテムの集合R a
のうち,推薦結果に含まれたアイテムの割 合である.上位k
件の推薦結果に対する再現率R@k
は式(2.9)
で表される.R@k =
∑ k i=1
r i
| R a | (2.9)
DCG [17]
は,順位付けの正しさを測る指標であり,値が大きいほど良い順位付けとなる.idealDCG
をユーザが得られる最大のDCG
の値とすると,nDCGは計算されたDCG
の値がideal DCG
に近いほど1
に近づく.上位k
件の推薦結果に対するDCG@k
は式(2.10)
,nDCG@k
は式(2.11)
で 表される.G i
(i = 1, 2, · · · , k
)は推薦リスト第i
位に位置するアイテムの利得を表し,データセッ トの評価値またはバイナリの評価値を利用する.DCG@k = G 1 +
∑ k i=2
G i
log 2 i (2.10)
nDCG@k = DCG@k
ideal DCG@k (2.11)
2.1.2
項で説明したアイテムの多様性も,評価指標として利用されている[8].上位 k
件の推薦結果に対するアイテムの多様性は,
Diversity@k
として式(2.12)
で表される.ここで,L k (x i ) = { y 1 , y 2 , · · · , y k }
はユーザx i
に対する推薦リストの上位k
件に含まれるアイテムの集合を表す.Diversity@kは全ユー ザの推薦リストにおける上位k
件で推薦されたアイテムの種類の数を表し,値が大きいほどユーザ 毎に異なるアイテムを含むユニークな推薦リストが作成できていることになる.反対に,値が小さい と,どのユーザに対しても同じアイテム(多くの場合,人気アイテム)が推薦されていることになる.Diversity@k = ∪
x
i∈ U
L k (x i )
(2.12)
2.2 行列ベース協調フィルタリング
2.2.1 行列ベース協調フィルタリングの代表的手法
Koren
らは,Netflix Prize9
において行列ベース協調フィルタリングの代表的な手法である行列分解法(Matrix Factorization)を提案している
[21].Netfrix Prize
とは,映画のDVD
レンタル会社である
Netflix 10
が,自社の推薦システムの精度を10
%向上させるアルゴリズムに,100万ドルの懸賞金をかけたコンテストであり,上述の行列分解法が推薦精度を
10.5%
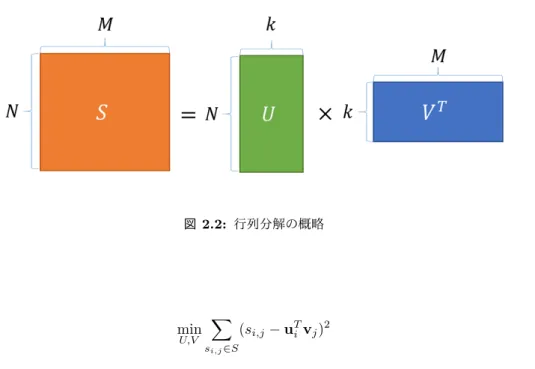
向上させ賞金を獲得した.行列分解の概略を図
2.2
に示す.N
人のユーザとM
個のアイテムからなる評価値行列S
を,N
やM
より小さい整数k
に対して,N× k
で表されるユーザ行列U
とM × k
で表されるアイテム行列V
に分解する.ユーザx i
のアイテムy j
に対する予測評価値ˆ s i,j
は,ユーザの潜在因子ベクトルu i
とアイテムの潜在因子ベクトルv j
の積によって計算され,式(2.13)
で表される.ˆ
s ij = u T i v j (2.13)
x i
がy j
に対して評価した評価値s i,j ∈ S
において,二乗誤差の総和を目的関数(式(2.14))で表
し.これを最小化するU
,V を求める.9
http://www.netflixprize.com/
10
https://www.netflix.com/jp/
図
2.2:
行列分解の概略min U,V
∑
s
i,j∈ S
(s i,j − u T i v j ) 2 (2.14)
U
,V
を求めるために利用される最適化手法として,確率的勾配降下法(Stocastic Gradient Descent
)[21]
や交互最小二乗法(Alternating Least Squares
)[43]
が利用される.求めたU
,V
を用いて,ユー ザが未評価のアイテムの予測評価値を求める.最適化手法については,次項で説明する.Koren
らは,行列分解法にユーザ・アイテムの評価値におけるバイアスや,暗黙的な評価を付与した
SVD++を提案している [21].暗黙的評価とは,評価値以外から得られるユーザの嗜好のこと
で,Webサイト利用時のクリックの履歴,アイテムを閲覧していた時間などを評価として扱う
[3].
SVD++と式 (2.14)
のような標準的な行列分解を比較して,予測精度が向上したことを報告している[21].
Sarwar
らは,特異値分解(Singular Value Decomposition; SVD)を利用した手法を提案し,少な い評価情報において予測精度が,2.1.1項で説明した近傍ベース協調フィルタリングよりも向上する ことを示している[34]
.SVD
では,評価値行列S
は,ユーザ行列U
・特異値行列Σ
・アイテム行列V
の3
つの行列の積により計算される.ここで,Σ
はk × k
の対角行列で,対角成分は特異値と呼 ばれる.S = U ΣV T (2.15)
Lee
らは,行列分解における潜在因子行列を,非負値で更新するNMF(Non-negative Matrix Fac- torization)を提案している [23].学習するモデル・目的関数は式 (2.13),(2.14)
と同じものである が,最小二乗法などを用いたときの潜在因子行列の更新で,行列の成分が負にならない制約をかけ る.画像処理の分野では,人の顔の画像を分解した際に,潜在因子行列が顔のパーツを捉えられており
[22],解釈性の高い行列分解法であると考えられる.情報推薦では,評価値行列から各ユーザ・ア
イテムの潜在因子行列を非負で生成することにより,ユーザやアイテムの評価傾向を表現した行列に
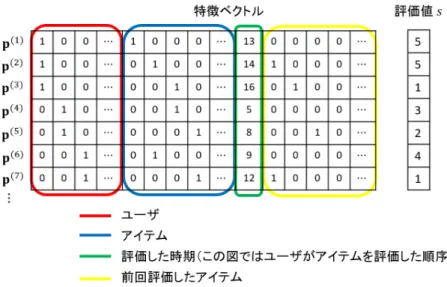
図
2.3: Factorization Machines
における特徴ベクトルなると言われている
[38].通常の行列分解の場合,ユーザのアイテムに対する興味あり/無しを学習
する場合は,ある潜在因子が負の働きをする可能性があるが,NMFでは非負であるため起こりえな い.そのため,ユーザ・アイテムの嗜好(好き/嫌い)を表す因子ではなく,評価傾向や特徴を捉え た因子が生成されやすいと考える.Salakhutdinov
らは,確率的なアプローチにより行列分解を扱うPMF
(Probabilistic Matrix Fac- torization
)を提案している[36]
.PMF
では,ユーザによるアイテムへの評価値と予測評価値との残 差s i,j − u T i v j
が正規分布に従うと仮定し,ユーザとアイテムの潜在因子行列U
,V から,評価値行 列S
の生起確率を式(2.16)
のように定義する.p(S | U, V, σ 2 ) =
∏ N i=1
∏ M j=1
[
N(s i,j | u T i v j , σ 2 ) ] I
i,j(2.16)
ここで,N(x
| µ, σ 2 )
は,平均µ,分散 σ 2
の正規分布を表し,Ii,j
はユーザx i
がアイテムy j
に対 して評価を付けたときに1,そうでないとき 0
になる関数である.この確率の対数尤度が最大となるU
,V
を求める.PMF
は,評価値行列がスパースな場合でも適切な推薦が可能であるが,潜在因子 数を少なくすると推薦精度が低下してしまうことが報告されている[36]
.Rendle
は,行列分解にサポートベクターマシーンの利点を組み合わせたFactorization Machines
を提案している[30].テンソルで表されるデータに対してモデルを構成することができるため,評価
値だけでなく,ユーザの評価履歴やブックマークのような暗黙的評価,評価した時期なども利用でき る.特徴ベクトルp
の例を図2.3
に示す.各行が,nを総評価数としたときの,あるユーザとアイテ ムの対に対する特徴ベクトルp (z) = (p z,1 , p z,2 , · · · , p z,n ) T
(z= 1, 2, · · · , n)を表し,各列が特徴量
を表す.図2.3
では,ユーザ・アイテムの情報以外に,当該ユーザがアイテムを評価した順序に関す る情報と,前回評価したアイテムを特徴として付与している.予測評価値s(p ˆ (z) )
は,式(2.17)
を利用して求める.ここで,nは特徴数(列数),w
0
はバイアス項,wi
とq i
はそれぞれi
番目の特徴量 に関する重みと潜在因子ベクトルを表す.kをベクトルq i
の次元数としたとき,<q i , q j >
は,二 つの潜在因子ベクトルの内積を表し,式(2.18)
により計算される.これにより,二つの特徴量がど の程度関連しているかが表現される.ˆ
s(p (z) ) = w 0 +
∑ n i=1
w i p z,i +
∑ n i=1
∑ n j=i+1
< q i , q j > p z,i p z,j (2.17)
< q i , q j >=
∑ k f=1
q i,f · q j,f (2.18)
式
(2.17)
におけるモデルパラメータw 0
,wi
,qi,f
を,実際の評価値と予測評価値の二乗誤差が最 小となるように,確率的勾配降下法などを用いて最適化する.Factorization Machines
は,スパースなデータセットを密なデータに変換でき,モデルパラメータ数に依存した線形時間でモデルを学習できることを報告している.評価実験では,次元数
k
を増加す ることによって,サポートベクターマシーンをそのまま情報推薦に適用した場合よりも精度が向上し たことを示している[30].また,テンソルベースの情報推薦手法である PITF(Pairwise Interaction Tensor Factorization)[31]
と比較して,テンソルの推薦精度と同等の効果が得られたことを示して いる[30].
2.2.2 行列ベース協調フィルタリングにおける機械学習
本項では,行列ベース協調フィルタリングの代表的な最適化手法である確率的勾配降下法
[21]
と 交互最小二乗法[43]
を中心に説明した後,提案手法で用いるBPR [29]
について説明する.モデルパラメータを
u i
,vj
とし,ユーザx i
がアイテムy j
に対する評価値s i,j
とモデルから得ら れる予測評価値の二乗誤差の総和E(u i , v j )
を式(2.19)
に示す.E(u i , v j ) = ∑
s
i,j∈ S
train(s i,j − u i v T j ) 2 (2.19)
式
(2.19)
を微分し,勾配を0
にすることで,二乗誤差の最小値を求める.式(2.19)
におけるu i
,v j
に関する微分は式(2.20),(2.21)
で表される.∂E(u i , v j )
∂u i
= − 2 ∑
s
i,j∈ S
trainv j · (s i,j − u i v j T )
∝ − ∑
s
i,j∈ S
trainv j · (s i,j − u i v T j ) (2.20)
∂E(u i , v j )
∂v j = − 2 ∑
s
i,j∈ S
trainu i · (s i,j − u i v T j )
∝ − ∑
s
i,j∈ S
trainu i · (s i,j − u i v T j ) (2.21)
式
(2.20),(2.21)
を利用し,勾配が小さくなる方向へ,ui
,vj
の値を更新していく.更新式は式(2.22),(2.23)
で表される.ここで,ηは学習率と呼ばれ,ηの値が大きいほど収束は早くなるが発散する恐れがある.反対に,
η
が小さすぎると収束が遅くなる.u i ← u i − η ∑
s
i,j∈ S
train∂E(u i , v j )
∂u i
= u i + η ∑
s
i,j∈ S
trainv j · (s i,j − u i v T j ) (2.22)
v j ← v j − η ∑
s
i,j∈ S
train∂E(u i , v j )
∂v j
= v j + η ∑
s
i,j∈ S
trainu i · (s i,j − u i v T j ) (2.23)
式
(2.22)
,(2.23)
では,一回の更新でトレーニングデータ全てに対して計算する必要がある.そのため,トレーニングデータが莫大になると計算コストが大きくなってしまう問題がある.その問題 点を解決するために,確率的勾配降下法では,一つのトレーニングデータ
s i,j
をランダムに抽出し,その勾配を計算して更新を行う
[21].式 (2.24),(2.25)
を,ユーザ行列U
,アイテム行列V
の値が 収束するまで繰り返すことで,式(2.19)
を最小化する.u i ← u i + η v j · (s i,j − u i v T j ) (2.24)
v j ← v j + η u i · (s i,j − u i v j T ) (2.25)
交互最小二乗法
[43]
では,行列の観点で二乗誤差を扱う.ユーザ行列U
,アイテム行列V
の積に よって得られる予測評価値行列と評価値行列S
の二乗誤差は式(2.26)
で表される.E(U, V ) = (S − U V T ) 2 (2.26)
二乗誤差を最小化するために,式
(2.26)
において,U
,V
どちらか一方を定数と見立て,E(U, V ) = 0
を解く.求められたU
,V を新しい値として更新していくことにより,U,V が収束することが知られている
[43].具体的な学習ステップを以下に示す.
Step. 1
ユーザ・アイテム行列U
,V を初期化する.Step. 2 U
を定数として,式(2.26)
をV
に対して解き,V を求められた値に更新する.Step. 3 V
を定数として,式(2.26)
をU
に対して解き,U
を求められた値に更新する.Step. 4 Step.2
,Step. 3
をU
,V
が収束するまで繰り返す.Koren
らは,確率的勾配降下法の方が,交互最小二乗法より簡単に実装でき,計算時間も早いが,計算の並列化をする場合やデータセットが密な場合は,交互最小二乗法が有効であることを報告して いる
[21].
BPR [29]
では,評価値と予測評価値の誤差を小さくすることが目的ではなく各アイテムに対するユーザの好みの順序関係を利用して,ユーザが好むアイテムのランキングを求める.ユーザ
x i
の推 薦リストにおける理想的なランキング(アイテムの順序関係)を> i
,モデルパラメータをΦ
とする.Φ
の事後確率p(Φ | > i )
を,ベイズの定理により式(2.27)
で表す.p(Φ | > i ) ∝ p(> i | Φ)p(Φ) (2.27)
式
(2.27)
における右辺の対数尤度ln p(> i | Φ)p(Φ)
を最大化するモデルパラメータΦ
を求める.求 められたΦ
から予測評価値を計算することで,推薦リストを作成する.具体的な学習方法やアルゴ リズムは,3.4節において提案手法と合わせて説明する.2.2 価値観
価値観とは,物事の重みづけの体系のことである.ユーザの嗜好や意思決定に影響を与える要因 として知られており,マーケティングや
Web
インテリジェンスといった分野において利用されてい る[18, 41]
.また,価値観を情報推薦へ応用したアプローチ[5, 15, 39]
がこれまでに提案されている.本節では,情報推薦システムにおける価値観のモデル構築方法や,情報推薦手法に価値観を導入した アプローチについて紹介する.
2.2.1 価値観モデル
Hattori
らは,情報推薦システムにおける価値観をアイテムの属性に対するこだわりと定義し,価値観に基づくユーザモデルの構築方法を提案している
[15]
.アイテムの属性とは,映画を例にとる と,ストーリーや演出,音楽といった評価のポイントとなる情報のことを指す.価値観に基づくユーザモデルの構築には評価一致率(RMRate; Rating Matching Rate)が利用さ
れる
[15].ユーザが,アイテムまたはアイテムの属性に対して与える評価の好評/不評を評価極性と
する.評価一致率とは,価値観を定量的に表す指標で,ユーザのアイテムに対する総合評価の評価極
性と,そのアイテムの属性の評価極性が一致する割合として定義される.ユーザ
x i
のアイテムに対 する総合評価の評価極性と,アイテムの属性a k
に対する評価極性が一致する回数をO i,k
,一致しな い回数をQ i,k
とすると,xi
におけるa k
の評価一致率u i,k
は,式(2.29)
で表される.u i,k = O i,k
O i,k + Q i,k (2.29)
評価一致率の値は
1
に近いほど,ユーザはその属性に対してこだわりが強く,0
に近い場合は推薦 において重要ではない属性であるとみなす.例えば,ユーザがストーリーに高評価を与え,演出や音 楽には低評価を与えたが,アイテム自体には高評価を与えたとき,ストーリーに対する評価一致率の 値は大きくなりそのユーザはストーリーにこだわりが強いと考えられる.評価一致率を利用した価 値観に基づくユーザモデルでは,少ない評価件数でも安定したモデルの構築が可能と報告されてい る[15].
山口らは,価値観に基づくアイテムモデルに対して,評価一致率を拡張したリフト値を利用した価 値観モデルを提案している
[6, 39].評価一致率では,好評と不評を区別せずに,ユーザがアイテムに
与えた総合評価の評価極性と,アイテムの属性に対する評価極性が一致した回数を利用しているが,リフト値を利用したアイテムモデルの構築では,ユーザのアイテムに対する好評
/
不評とアイテムの 属性に対する好評/
不評の組み合わせ4
通りに分けて扱う.P (X )
を事象X
の生起確率とすると,リフト値は式(2.30)
で定義される.lift(X ⇒ Y ) = P(X ∩ Y )
P (X)P (Y ) (2.30)
リフト値は,
Y
の生起確率が条件X
によって何倍増加したかを表し,相関ルールの評価指標の一 つとして用いられる[9]
.アイテムモデルの計算では,式(2.29)
において,ユーザがアイテムに与え た総合評価の評価極性と属性の評価極性をそれぞれX
とY
に対応させる.ユーザのアイテムy j
に対 する総合評価の評価極性がp t ∈ { pos, neg }
となる事象をX j t
,属性a k
の評価極性がp a ∈ { pos, neg }
となる事象をX j,k a
とする.yj
のa k
に対するリフト値lift j,k
は,式(2.31)
で表される.lift j,k (p a ⇒ p t ) = P(X j,k a ∩ X j t )
P (X j,k a )P (X j t ) (2.31)
リフト値を利用したアイテムの価値観モデルは,推薦説明の生成に有効で,ユーザのシステムに対 する満足度や理解度を向上させられることが報告されている
[39].
本論文では,価値観に基づくアイテムモデルの生成において,好評と不評を区別した好評/不評一 致率を扱う.y
j
に対する総合評価とa k
に対する属性評価において,好評で一致した回数,不評で一 致した回数をP os j,k
,N eg j,k
,y j
における好評の数,不評の数をM
,N
とすると,y j
のa k
に対す る好評一致率v p
j,k,不評一致率v n
j,k は式(2.32)
,(2.33)
で表される.v p
j,k= P os i,k
M (2.32)
v n
j,k= N eg i,k
N (2.33)
2.3.2 価値観に基づく情報推薦手法
本項では,前項で述べた価値観に基づくユーザ・アイテムモデルを,内容ベースフィルタリングや 近傍ベース協調フィルタリングに導入した情報推薦手法について述べる
[5, 15, 39].
Hattori
らは,内容ベースフィルタリングに価値観を導入し,属性ベース推薦と属性値ベース推薦の
2
通りのアプローチを提案している[15].属性ベース推薦では,推薦対象ユーザのこだわりが強い
属性に対して好評を与えたユーザが多いアイテムを推薦する.属性値ベース推薦では,推薦対象ユー ザが好評を与えたアイテムにおいて,推薦対象ユーザのこだわりが強い属性に対する属性値を抽出 し,その属性値を持つ任意のアイテムをユーザに推薦する.属性値とは,ジャンルに対する「SF
」や「アクション」のことを指す.これら二つのアプローチで,ユーザが好評としたアイテムの属性値を ランダムに選択して,その属性値を持つ任意のアイテムを推薦する手法と比較した結果,推薦精度が 向上し,cold-start問題に対して有効であることを報告している.
三澤らは,2.1.1項で述べたユーザベース協調フィルタリングに価値観を導入した手法を提案して
いる
[4, 5].近傍ベースのアプローチでは,ユーザのアイテムに対する評価値に基づき類似度を計算
するが,この手法では推薦対象ユーザと他ユーザの各属性に対するこだわりの強さ(評価一致率)に 基づき類似度を計算し,こだわりが類似しているユーザが好むアイテムを推薦する.Aを属性の集 合,u
i,k
をユーザx i
の属性a k
に関する評価一致率,u ¯ i
をx i
の全ての属性に対する評価一致率の平 均とする.x i
,x j
におけるこだわりの強さの類似度p i,j
はPearson
相関を用いて式(2.30)
で計算さ れる.p i,j =
∑
a
k∈ A
(u i,k − u ¯ i )(u j,k − u ¯ j )
√ ∑
a
k∈ A
(u i,k − u ¯ i ) 2 √ ∑
a
k∈ A
(u j,k − u ¯ j ) 2
(2.30)
x i
が未評価のアイテムy j
に対して,yj
を評価済みのユーザ集合をU j
とすると,xi
に対するy j
の予測評価値s ˆ i,j
は式(2.31)
で計算される.ˆ s i,j =
∑
u
k∈ U
jp i,k s k,j
∑
u
k∈ U
jp i,k
(2.31)
式
(2.31)
で計算されたˆ s i,j
の値を降順に並べアイテムの推薦リストを作成する.三澤らは,近傍ベース協調フィルタリングと比較し,評価件数が少ないユーザでも,ユーザ間類似 度の算出が可能になるため,
cold-start
問題に有効であることを示している[5]
.Takama
らは,前述のリフト値を利用したアイテムの価値観モデルをアイテムベース協調フィルタリングに適用したアプローチを提案している
[39].L = { a 1 , a 2 , · · · , a 4 ×| A | }
をリフト値に対する属 性集合,lj,k
をy j
のa k
に対するリフト値,¯ l j
をy j
に対する全リフト値の平均とする.ここで,4種 類のリフト値を利用しているため,Lのサイズは属性数の4
倍になっている.yi
,yj
の類似度p i,j
は 式(2.32)
で表される.p i,j =
∑
a
k∈ L
(l i,k − ¯ l i )(l j,k − ¯ l j )
√ ∑
a
k∈ L
(l i,k − ¯ l i ) 2 √ ∑
a
k∈ L
(l j,k − ¯ l j ) 2
(2.32)
ユーザ
x i
が評価したアイテムの集合をV i
とすると,xi
のy j
に対する予測評価値s ˆ i,j
の計算は式(2.33)
で表される.ˆ s i,j =
∑
v
k∈ V
ip j,k s i,k
∑
v
k∈ V
i| p j,k | (2.33)
Sarwar
らのアイテムベース協調フィルタリング[35]
と比較し,推薦説明の生成における有効性を示した他,ロングテールのアイテムに対する推薦に対して効果が期待できることを報告している.
3 提案手法
3.1 予測スコアの計算
本節では,ユーザとアイテムに関するモデルを,2.3.1項で述べた評価一致率,好評/不評一致率を 用いて行列として構築する方法について述べる.
ユーザの価値観モデルは,好評と不評を分けず,属性ごとの評価一致率で表現する.これは,一般 的にユーザ当たりの評価情報はアイテム当たりの評価情報よりも少ないため,好不評に分けてしま うとデータ量が不足することが予測されるためである.それに対しアイテムの価値観モデルは,多数 のレビューが投稿されているアイテムが一定数存在することが期待できる.先行研究においても好評 と不評を区別して評価一致率を求めることで,協調フィルタリングの推薦精度向上や,推薦説明の生 成において有効性が示されている
[39]
.そこで,提案手法ではアイテムの価値観モデルにおける評価 一致率を好評の場合,不評の場合の2
種類に分けて求める.N
人からなるユーザ集合をU
,L
個からなる属性の集合をA
とし,ユーザx i ∈ U
の属性a j ∈ A
に対する評価一致率をu i,j
とする.評価一致率u i,j
を要素とする,N× L
のユーザ行列M U
は式(3.1)
で表される.各行がユーザモデルに対応する.M U =
u 1,1 u 1,2 . . . u 1,L
u 2,1 u 2,2 . . . u 2,L
.. . .. . . . . .. . u N,1 u N,2 . . . u N,L
(3.1)
M
個のアイテムの集合をV
,アイテムy i ∈ V
の属性a j
に対する好評/不評一致率をそれぞれv i,j
,v i,L+j
(Lは属性数)としたとき,M× 2L
のアイテム行列M V
は式(3.2)
で表せる.1列目からL
列目までが好評一致率,L
+ 1
列目から2L
列目までが不評一致率を表し,各行がアイテムモデルに 対応する.M V =
v 1,1 v 1,2 . . . v 1,L v 1,L+1 . . . v 1,2L
v 2,1 v 2,2 . . . v 2,L v 2,L+1 . . . v 2,2L .. . .. . . . . .. . .. . . . . .. . v M,1 v M,2 . . . v M,L v M,L+1 . . . v M,2L
(3.2)
ユーザとアイテムに関する行列の他に,ユーザモデル,アイテムモデル間の関係を表現する行列
M R
(関係行列)を導入する.M R
を適切に設定することにより,ユーザモデルとアイテムモデル間 の属性の対応関係を考慮し,適切にマッチングすることを目指す.M R
についての詳細は3.2
節で説 明する.図
3.1:
提案手法における予測スコアの計算例提案手法では以上の
3
つの行列の積を求めることにより,行がユーザ,列がアイテム,各成分が予 測スコアの行列を計算する.予測スコアを表す行列S
は式(3.3)
により表せる.S = M U × M R × M V T (3.3)
推薦時には,ユーザの予測スコアが最大のアイテムから降順に並べることで推薦リストを作成する.
式
(3.3)
では,ユーザのこだわりが強い(評価一致率が1
に近い)属性や,アイテムにおける評価に強い影響を与える重要な(好評/不評一致率が
1
に近い)属性は,積をとるとスコアに影響が出や すい.一方で,ユーザが重視しない(評価一致率が0
に近い)属性やアイテムにおける評価に影響 を及ぼさない重要でない(好評/
不評一致率が0
に近い)属性は,積をとると0
に近づくため予測ス コアに関与しにくい.従って,ユーザのこだわりの強い属性と,アイテムにおいて重要な属性が一 致するほど値が大きくなる.予測スコアの計算例を図3.1
に示す.図3.1
では,説明を簡単にするた め,アイテムの価値観モデルも評価一致率の行列M v ′
としており,関係行列は単位行列として予測ス コアの計算はS = M u × M v ′ T
としている.行列分解のアプローチと比較した提案手法の利点として,モデルの解釈性が高いことが挙げられ る.行列分解のアプローチでは潜在因子が何を表現しているのが解釈が困難であり,ユーザが提示さ れたアイテムに対して,何を根拠にそのアイテムが推薦されたのかを理解しにくい.それ対し,提案 手法はアイテムの評価属性を扱っているため解釈が容易であり,ユーザへの推薦説明の生成などに有 効性が期待できる.
3.2 関係行列
本節では,関係行列
M R
について,好評一致率と不評一致率の特性を考慮した利用方法や行列の 成分の設定方法について述べる.好評一致率に対応する成分を正,不評一致率に対応する成分を負の値にすることにより,アイテム の予測スコア計算時に,好評一致率が大きい属性は属性に対するスコアが上昇し,不評一致率が大き い属性はその属性に対するスコアが減少する.これは,好評一致率が大きい属性を持つアイテムは,
その属性に対してこだわりを持つユーザに推薦されやすくなり,不評一致率が大きい属性を持つアイ テムは,その属性にこだわりを持つユーザに推薦されにくくなることを意味する.図
3.2
に示す例で は,アイテム行列M u
と積をとった結果,アイテムモデルの好評に対応する成分は正,不評に対する 成分が負の値になっていることがわかる.図
3.2:
関係行列の利用例M R
の設定方法について,手動で成分を設定する方法と,機械学習により自動で生成する方法を提 案する.手動で成分を設定する方法では,上述したM R
の利用方法を基に設定する.機械学習によ り自動で生成する方法では,確率的勾配降下法[21]
を用いて真値と予測スコアの二乗誤差を最小化 することにより生成する方法と,BPR [29]に基づき不評・未評価のアイテムより好評のアイテムの 予測スコアが高くなるように事後分布を最大化して生成する方法を提案する.本節では,提案手法の 基本的な考え方である手動による設定について述べる.機械学習による生成方法は3.3,3.4
節で説 明する.L × 2L
行列のM R
はw k,l
を成分として,式(3.4)
で表される.M R =
w 1,1 w 1,2 . . . w 1,L w 1,L+1 . . . w 1,2L
w 2,1 w 2,2 . . . w 2,L w 2,L+1 . . . w 2,2L .. . .. . . . . .. . .. . . . . .. . w L,1 w L,2 . . . w L,L w L,L+1 . . . w L,2L
(3.4)
異なる属性間の関係について,手動で値を設定するのは困難であるため,手動による方法では好 評一致に対応する成分の対角成分
α
と不評一致率に対応する成分の対角成分β
のみを用いて,M R
Dを式