Potential for Teaching Materials for Advanced Reading Comprehension
with the Use of Text Mining: A Report on the Practice of Using KH-Coder
Nobuko Wang 1. INTRODUCTION.The Japanese courses for international students in the undergraduate program at Senshu University include an elective course called Advanced Japanese for the students in the second year and beyond. I have given an assignment to read a novel in Japanese in this class. Prior to giving this assignment and over the course of several years, I had been giving students assignments to select and present a book they are personally interested based on a concept of ‘read a Japanese book that is not a technical book on the subject you are specialized in’. Having learned in those classes that popular authors among international students are those of contemporary novels, I chose a contemporary work as teaching material this time rather than works of the so-called big names in the history of literature. However, teaching the class turned out to be difficult because the speed of reading as well as the level of comprehension varied between students whose native language is Chinese or Korean and students whose native language is Vietnamese, Khmer, Lao or other such languages. That said, using a short novel that is easy to read would take the fun out of reading. Therefore, to allow students to feel the sense of accomplishment in finishing reading a full-length novel, I tried to analyze the morpheme of the entire assigned novel and prepare visualized teaching materials in order to help students not lose the motivation to digest the work before actually reading it and allow them to proceed with reading while checking the story. Here, I used text mining techniques and visualized the story by using tables of parts of speech prepared for easier understanding of words as well as cooccurrence network diagrams for easier understanding of the overall picture.
2. PREVIOUS STUDIES.
There are quite a few studies on practices that used a novel as teaching material. Kawamoto (1998) observed functions such as vocabulary and grammar and described for each function how one can use a full-length novel to work on reading comprehension and aim to ‘enjoy reading materials’ while accurately understanding the contents. While there are other studies with a similar approach, they all begin with an effort to read a novel anyhow. In addition, while Sano and Lee (2007) describe the potential of the use of KH-coder—which I used in my study—for researching Japanese education, they focus on the analysis of vocabulary, which is corpus research, and do not discuss about preparing teaching materials for students.
vocabulary using this software is based on the capability of the morphological parser ChaSen as mentioned in the aforementioned Sano and Lee (2007), there are some limitations. However, I believe there is no significant issue in applying it as teaching material.
3. PREPARING VISUALIZED TEACHING MATERIALS.
3-1. INTERVIEWS WITH STUDENTS. First, when I asked the students about what they thought would be an
obstacle to reading Japanese books, they gave the following responses, in addition to grammar, Japanese kanji characters, and the vocabulary they haven’t learned.
(1) Books in Japanese are hard to read because they are written vertically. It makes you read the same line over and over.
(Books in languages such as Chinese, Korean, and Vietnamese are currently written horizontally.) (2) The names of people are difficult to identify because Japanese is a foreign language. Since I cannot
remember the names as I read, I cannot easily follow the story. (3) Since there is no word divider in Japanese, it is hard to identify words.
It became clear that I needed to take the above points into consideration when preparing teaching materials and prepare the main text in a better format in addition to preparing vocabulary tables.
3-2. PREPARING ITEMS SUCH AS THE MAIN TEXT AND VOCABULARY TABLES. I selected Tegami ‘Letter’
written by Keigo Higashino this time. As teaching material, I use the book by having each student to procure own copy. For the analysis, I scanned the text of the novel and converted it into a text file to be analyzed by KH-Coder. The scanner that I used was the Fujitsu ScanSnap. The scanned material, which was saved as a PDF file, was read by an OCR software program called e-typist and converted into a text file by a piece of free software called TeraPad. After correcting errors such as misread characters, the edited text file was run by KH-Coder to analyze the vocabulary. For advance preparation, ChaSen to conduct morphological analysis and the statistical analysis program R to perform quantitative analysis are also necessary, but the KH-Coder that I downloaded this time came with both ChaSen (win-cha for Windows) and R included.
The vocabulary tables that I prepared from the above materials are as follows. (1) 150 most frequently-used words for the entire book
(2) Vocabulary tables by part of speech for the entire book (3)Ten most frequently-used words by chapter
(4) Words of interest and the sentences that cooccur before and after those words (5) Cooccurrence network diagrams
3-3. ISSUES RELATED TO DIGITIZATION. Books in Japan are not already digitized in many cases; there are
within the scope of personal enjoyment, it is illegal to outsource the digitized work to others. The act of scanning the page contents of books and magazines and digitizing them to files such as a PDF is referred to as DIY book/magazine scanning and Article 30 (1) of the Copyright Act states that ‘a user may reproduce a work that is subject to copyright’ for private use. Yet, since it is difficult prepare a book that contains over several hundred pages ready to be scanned, the vast majority of people pay a DIY book scanning agency to do the work. Whether this DIY book scanning service is a violation of the copyright law was contested in the court and the final and binding judgement was made that use of a DIY book scanning service without obtaining permission from the author is unacceptable. In the case of DIY book scanning for classroom use or research purpose, Article 35 of the Copyright Act states that ‘A person in charge of teaching or a person taking classes at a school or other educational institution (except one founded for commercial purposes) may reproduce a work that has been made public if and to the extent that it is found to be necessary for the purpose of use in the course of classes’. Based on this, I proceeded to prepare teaching materials and conduct this study with the understanding that the kind of classroom and research use done in this study would not violate the copyright law. As an aside, I took precautions by distributing the printed main text and the vocabulary tables prepared by KH-coder, rather than distributing them in the form of an electronic file. I also used the electric cutting machine Horizon PC39II owned by the university to prepare the book for scanning.
The process to correct incorrectly scanned characters and symbols after creating a text file took the longest time to complete. Ruby characters placed above Japanese kanji characters were also deleted in this stage. Not thoroughly performing this task would result in inaccurate processing of texts and incorrect detection of items such as frequently used terms during the morphological analysis conducted by the software. Here, I used a book that has not been digitized. However, if you can load a book straight onto KH-Coder by using websites such as Aozora Bunko, where books are available in the text file format, the aforementioned series of operations can be omitted and items such as vocabulary table can be easily generated.
4. EXAMPLES OF VISUALIZED TEACHING MATERIAL
Examples of the teaching materials that I visualized by modifying the analysis outputs by KH-Coder are as follows.
Table 1 shows the 150 most frequently-used words extracted by analyzing the prologue. The procedure to generate a table like the one shown below includes 1) loading the text file of the prologue onto KH-Coder as a new project, 2) running pre-processing (clicking on [Run Pre-Processing] starts the process to automatically check for issues and count the total number of characters), and 3) selecting [Top 150] after opening [Tools] and then clicking on [Words] [Frequency List] [Type of the List]. The table would be generated in Excel format.
example, advanced students could make notes only for the words they don’t know the meaning of or how to pronounce so that the students themselves as well as the teacher can grasp their current position. The table is shown in Table 2.
抽出語 出現回数 抽出語 出現回数 抽出語 出現回数 抽出語 出現回数 抽出語 出現回数 剛志 49 目 6 ガラス 4 息子 4 公園 3 入る 17 ポケット 6 キッチン 4 大きい 4 口 3 窓 16 感じる 6 コンビニ 4 痛み 4 今 3 家 14 見える 6 ソファ 4 電話 4 細長い 3 見る 14 持つ 6 テーブル4 盗む 4 載る 3 手 14 買う 6 テレビ 4 逃げる 4 思い 3 老婦 14 歩く 6 リモコン 4 内側 4 時代 3 金 12 立つ 6 音 4 聞く 4 実際 3 思う 11 ダイニング 5 画面 4 捕まる 4 首 3 緒方 11 ベルト 5 外す 4 北側 4 初めて 3 前 11 リビング 5 気づく 4 老女 4 女 3 ドライバー 10 下 5 近づく 4 アルミ 3 小屋 3 引っ越し 10 向こう 5 血 4 ジャンパー3 焦る 3 顔 10 考える 5 鍵 4 移す 3 錠 3 腰 10 使う 5 玄関 4 一つ 3 食べる 3 知る 10 思い出す 5 行く 4 引き出し 3 振る 3 貴 9 身体 5 左 4 右 3 新居 3 出る 9 袋 5 差し込む4 押す 3 身 3 先輩 9 長男 5 姿 4 横 3 人間 3 襖 8 庭 5 子供 4 嫁さん 3 早い 3 開ける 8 天津 5 住む 4 外 3 奪う 3 甘栗 8 頭 5 商店 4 気配 3 中 3 犬 8 表情 5 少し 4 叫ぶ 3 駐車 3 部屋 8 仏壇 5 人 4 近く 3 弟 3 仕事 7 門 5 声 4 軍手 3 働く 3 自分 7 和室 5 川 4 隙間 3 南側 3 足 7 話 5 想像 4 古い 3 覗く 3 塀 7 ほか 4 走る 4 戸 3 婆さん 3
抽出語 出現回数 メモ 抽出語 出現回数 メモ 剛志(つよし) 49 目 6 入る 17 ポケット 6 窓 16 感じる 6 家 14 見える 6 見る 14 持つ 6 手 14 買う 6 老婦 14 歩く 6 金 12 立つ 6 思う 11 ダイニング 5 緒方 11 ベルト 5 前 11 リビング 5 ドライバー 10 下 5 引っ越し 10 向こう 5 顔 10 考える 5 腰 10 使う 5 知る 10 思い出す 5 貴 9 身体 5 出る 9 袋 5 先輩 9 長男 5 襖 8 庭 5 開ける 8 天津 5 甘栗 8 頭 5 犬 8 表情 5 部屋 8 仏壇 5 仕事 7 門 5 自分 7 和室 5 足 7 話 5 塀 7 ほか 4
TABLE 2. Part of the teaching material example for the 150 most frequently used words. Prologue of Tegami ‘Letter’by Keigo Higashino.
The most frequently used word is Tsuyoshi, the name of character who causes the incident that triggers the story in the prologue. Since other words—including nouns, verbs, and adjectives—are also listed in the order of frequency, it can be used in a way to identify frequently-used words as keywords and infer the storyline.
the width of space—to suit the students’ level and make it easier for them to use.
TABLE 3. Part of vocabulary table by parts of speech. Prologue of Tegami ‘Letter’ by Keigo Higashino. TABLE 4. Part of vocabulary table by parts of speech. (modified)
Next, Table 3 is a vocabulary table by part of speech. The table allows you to see the frequency of used words by part of speech. Since tables generated by KH-Coder include the labels for part of speech that are unfamiliar to students, it’s probably a good idea to edit those labels to match with the textbook. It’s also probably a good idea for the teacher to work out and modify the order of parts of speech in the table. Table 4 also shows a table which has been modified from the original by switching the order and editing the labels of parts of speech to match with the textbook. For example, the labels ‘adjective’ and ‘adjective verb’ were revised to ‘i-adjective’ and ‘na-adjective’, respectively, in order to prepare the table. The software also outputs other parts of speech such as adverbs and interjections in the actual table. In addition, since words such as shōmei ‘prove’, benkyō ‘study’, and debyū ‘debut’ labeled as ‘verb formed by adding “suru” to a noun’ in KH-Coder represent ‘to prove’, ‘to study’, and ‘to debut’, respectively, I revised the part of speech label to ‘suru-verb’ for Japanese education.
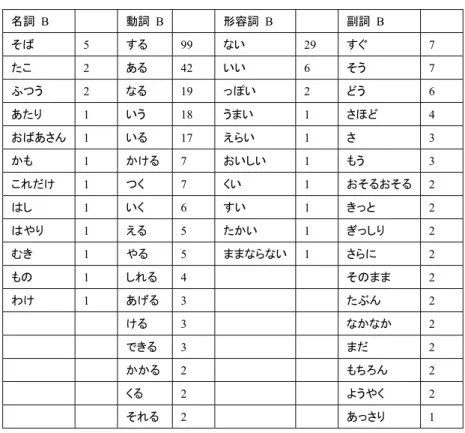
名詞 B 動詞 B 形容詞 B 副詞 B そば 5 する 99 ない 29 すぐ 7 たこ 2 ある 42 いい 6 そう 7 ふつう 2 なる 19 っぽい 2 どう 6 あたり 1 いう 18 うまい 1 さほど 4 おばあさん 1 いる 17 えらい 1 さ 3 かも 1 かける 7 おいしい 1 もう 3 これだけ 1 つく 7 くい 1 おそるおそる 2 はし 1 いく 6 すい 1 きっと 2 はやり 1 える 5 たかい 1 ぎっしり 2 むき 1 やる 5 ままならない 1 さらに 2 もの 1 しれる 4 そのまま 2 わけ 1 あげる 3 たぶん 2 ける 3 なかなか 2 できる 3 まだ 2 かかる 2 もちろん 2 くる 2 ようやく 2 それる 2 あっさり 1
TABLE 5. Part of vocabulary table by parts of speech (vocabulary in hiragana).
Prologue of Tegami ‘Letter’ by Keigo Higashino.
students from the Chinese character-using countries often overlook words in hiragana.
In addition, since you can see characteristic words in each chapter in the table of the ten most frequently-used words by chapter shown in Table 6, it is possible to explain the outline of the novel by looking at it. This is done by using the ten most frequently used words that are returned when the variables are set by chapter and specifying them as characteristic words. Table 6 below is such an example. It lists the ten most frequently-used words in each chapter from the prologue to the final chapter.
TABLE 6. Ten most frequently-used words by chapter. Prologue of Tegami ‘Letter’ by Keigo Higashino.
直貴様 剛志』読み終えた後、直貴はすぐに 手紙を封筒ごと細かく 破り 、別の紙に包んでからゴミ箱に捨てた。それか ら洗面所に行き、自分の を示していた。直貴は彼女の手から葉書を取り 返すと、びりびりと 破り 、そばのゴミ箱に捨てた。「あたしには……」朝 美が口を開い 「つまり今後一切朝美さんには近づかないこ と、連絡もしないこと、それを 破っ た時にはこのお金を返してもらうーそういう形の 契約を結びたいわけ が一通の封書を出してきた。「これがたぶん最 初の手紙だ。 破り 捨てようかと思ったが、それでは現実から逃避 する(↓)ことになると思い直して、 したくてこれを書いています。もしとちゅうでは らがたったら、 破っ てすててください。おわびする資格がないことは わかっています。本当に本当にもうしわけ
TABLE 7. Cooccurring sentences before and after a word of interest (collocation).
Example: Yaburu ‘to Tear’ in Tegami ‘Letter’ by Keigo Higashino
Cooccurrence networks are another means to illustrate the story. Figure 1 below is a cooccurrence network to show what kind of connections exist between the characters and incidents in the final chapter, which is the last scene of this story. These connections can be illustrated in this way if the circles are set to become larger as the importance increases.
5. DISCUSSION
The vocabulary tables and the cooccurrence network diagram above were presented before students read the book. They can check the list of characters’ names in the table of frequently-used words by parts of speech shown in Table 3 and see new words in advance based on the flow of the story by looking at the table of the ten most frequently-used words by chapter in Table 6, for example. As a result, it seems that even students from countries where Chinese characters are not used were able to get a foothold for starting to read without feeling difficulty.
6. FUTURE PLAN
I would like to continue using text mining techniques by trial and error for a while with an aim to better realize ‘enjoyable reading in Japanese’. To do so, I would like to further analyze more novels and use them in classroom activities and try analyzing vocabulary and extracting example sentences necessary for students based on their native language.
Acknowlegments
This study was supported in part by a Senshu University research grant 2017, Nihongo kyouiku ni okeru Dokkai shien kyouzai eno teian-KH-Coder wo shiyoushita kyouzai sakusei- [Proposal for Teaching materials for reading comprehension with the use of KH-Coder-]
REFERENCES
Higuchi Koichi. 樋 口 耕 一 (2004) “Quantitative Analysis of Textual Data ::Differentiation and Coordination of Two Approaches” 「テキスト型データの計量的分析:―2 つのアプローチの 峻別と統合―」Sociological Theory and Methods, 『理論と方法 19』pp.101-115、Japanese Association for Mathematical Sociology, 日本数理社会学会
---(2014) Quantitative Text Analysis for Social Researchers: A Contribution to Content
Analysis, 『社会調査のための計量テキスト分析』Nakanishi Publishing ナカニシヤ出版
Kawamoto Yumiko. 河元由美子 (1998) “Dokkai de chohenshosetsu o yomu -Sokudoku kara kansho he-”「読解で長編小説を読む-速読から鑑賞へ-」Koza Nihongo Kyoiku 34, Center for
Japanese Language,Waseda University,『講座日本語教育 34』pp.106-125、早稲田大学日本
語教育研究センター
Maruyama Takehiko. 丸山岳彦 (2009) “Nihongo Kopasu no genjou-(Shogengo no Kopasu)-”「日本語
コーパスの現状(諸言語のコーパス)」 Kokubungaku:Kaishaku to Kanshou, 『国文学:解
釈と鑑賞』pp.122-130 Shibundo Publishing, 至文堂
Language Acquisition & Japanese Language Education Research”, 「KH Coder で何ができる
か : 日本語習得・日本語教育研究利用への示唆」、Japanese Language Education, 『言語