要旨:
Ant Colony Optimization (ACO)はDorigoに提案されて以降,様々なアルゴリズムの拡張が行われている。
従来の ACOでは個々のアリが独自の情報を持つことは無く,グローバルな情報のみに従って探索を行 っていた。本稿では個々のアリの記憶情報を探索に利用するACOを提案する。さらに,個々のアリの 記憶が一定確率で忘れられるケースも考える。また,性能比較実験にはTSPライブラリーの標準テスト 問題を使い,拡張アルゴリズムの有効性を示す。
Abstract:
Since Ant Colony Optimization (ACO) algorithm was introduced by Dorigo in 1992, several researchers have enhanced it. Each ant in basic ACO algorithm has no long-term memory; it searches using only pheromone information. In this paper, we propose a variant of ACO algorithm that uses external memory of each ant to seek an optimum solution. Moreover, it incorporates not only the case in which each ant’s memory is permanent but also the case in which the memory is lost with a certain probability. The effectiveness of our proposed algorithm is demonstrated by testing with benchmark test problems from the TSP library (TSPLIB).
1.
はじめに
メタヒューリスティクスの
1種であるAnt Colony Optimization (ACO)アルゴリズムは,
Dorigo and Gambardella [1]により紹介されて以降,巡回セールスマン問題(Traveling Salesman Problem, TSP),スケジューリング問題などの
NP困難な順列型の最適化問題に数多く応用されている。
ACO
は,アリがフェロモンを介した群行動により暗示的に情報を共有している様からヒント を得て開発されたアルゴリズムである。
本稿では,個々のアリが解を生成する際,標準的な
ACOで利用されるフェロモンマトリク ス情報だけではなく,個々のアリに探索過程で得た優良解を記憶させ,その記憶も利用する新 たな
ACOアルゴリズムを提案する。さらに,
TSPライブラリーの標準テスト問題を使い,拡 張されたアルゴリズムの評価実験を行う。
本稿の構成は,第
2節において
TSPについて説明する。第
3節では,
ACOの代表的な手法 を紹介する。第
4節では,提案アルゴリズムについて述べる。第
5節では,性能評価実験の結 果を示す。最後に第
6節を本稿の帰結とする。
2.
巡回セールスマン問題(
Traveling Salesman Problem, TSP)
巡回セールスマン問題(TSP)[2] は,都市とその都市間の距離のリストが与えられ,各都市を
1回だけ訪問し,すべての都市を巡る最短経路を求める問題である。
個々のアリの外部記憶を利用した Ant Colony Optimization
Ant Colony Optimization with External Memory of Each Ant
井上寛規
†坂上智哉
‡加藤康彦
‡ Hiroki Inoue† Tomoya Sakagami‡ Yasuhiko Kato‡†久留米大学 経済学部
‡熊本学園大学 経済学部
†Faculty of Economics Kurume Univ.
‡Faculty of Economics Kumamoto Gakuen Univ.
図1 単純なTSP
図
1のように都市数が少なければ巡回路の組合せの数も少ないため,すべての巡回路の距 離を計算することが可能であるが,都市数が多くなると組合せの数が爆発的に増え現実的な 時間内で組合せのすべての巡回路の距離を計算することが不可能となる。このような現象を 組合せ爆発という。
TSPは計算複雑性理論において
NP困難と呼ばれる問題のクラスに属して おり,最適解の近似解を求めるアルゴリズムの研究が盛んにおこなわれている。
TSPのメタヒ ューリスティックスには,ボルツマン・マシン,
Genetic Algorithm (GA)やSimulated Annealing (SA),リン・カーニハン・アルゴリズムなどが挙げられる。本稿では提案アルゴリズムの性能 評価実験で,
TSPLIB[3]で公開されている
TSPをベンチマーク問題として用いた。
3. Ant Colony Optimization (ACO)
Ant Colony Optimization (ACO)
は,アリの食料収集におけるフェロモンを介した伝達行動を
応用し,組合せ最適化問題を解決するメタヒューリスティクスである。
ACOで人工アリエー ジェントは都市間の距離とアリが路に残したフェロモンの量をもとに解の探索を行う。各路 のフェロモン量が一様に近い初期の探索では,都市間の距離が路を選択する上での最も重要 な情報となり短い距離の路を選択する確率が高くなる。さらに探索が進むにつれて各路のフ ェロモン量はアリが多く通れば通るほど濃くなり,その路は多くのアリが通るようになり探 索の集中化が起こる。その逆で,各路のフェロモンは時間経過に従って蒸発することで探索の 多様化(分散化)が起こることで探索の初期収束を防いでいる。以下では本研究に関連する
ACOについて説明する。
3.1 Ant System (AS)
Ant System (AS)
は,
Dorigo and Gambardella [1]によって提案された最初のACOである。AS の基 本的なアルゴリズムを以下で示す。
アリエージェントを複数用意し,すべてのアリが別々の都市を出発点とするように配置す る。そして,各アリは巡回路(解)を生成していく。
アリk が現在いる都市をi として,次の移動先に都市j が選ばれる確率は,(1)式で与えられる。
ただし,都市j は未訪問とする。フェロモンの量を
τij,TSP の都市間の距離をd
ijとし,アリは「フ
ェロモンの量」と「距離の近さ」から次の訪問都市を選択していく。
Nk
l il il
ij k ij
pij
(1)
Nk
はアリ
kの未訪問都市集合を表す。
TSPでは一度訪問した都市を再度訪問することは禁じ られているため,次の移動先は未訪問都市の中から選ばれることになる。
α,
βはそれぞれ「フ ェロモンの量」と「距離の近さ」の重要度を決定するパラメータである。
ηijは都市間の距離
dijの逆数とする。なお,フェロモンの初期値は
τ0で与えられている。
図 2 Ant Systemにおける次の訪問都市の選択
すべてのアリが巡回路を生成した後に,フェロモン
τijのアップデートを以下のルールに従 って行う。アリの数を
m,フェロモンの蒸発率を
ρとする。
m
k k ij ij
ij
1
1
(2)
otherwise
T j i if
Lk k
k
ij 0
, /
1 (3)
Lk
はアリ
kが生成した巡回路の総経路長,Tkは生成した巡回路に含まれる経路集合を表す。つ
まり,多くのアリが利用した経路のフェロモン濃度は高まり,あまり利用されなかった経路の フェロモン濃度は時間とともに薄まっていく。また,巡回路長が短いアリほど,濃いフェロモ ンを残すため,アリが選択する経路の集中化が起こるようになる。これは自然界においてフェ ロモンが揮発することを表現したものである。
上記の処理を設定したステップ(世代)数繰り返し,探索中で見つかった最良解を出力して アルゴリズムは終了する。
TSP
を解くための
Ant Systemアルゴリズムの流れは,図3に擬似コードで示す。
図 3 擬似コードによるAnt Systemアルゴリズム
3.2 Ant Colony System (ACS)
Ant Colony System (ACS)
は
ASと同じく
Dorigo and Gambardella[4]によって提案されたアル ゴリズムであり,都市選択の方法とフェロモンアップデートが改良されている。
ACSでは擬 似確率的方法(pseudo-random-proportional rule)によって都市選択を行う。このルールでは任意 の確率で選択確率が最大の都市を次の都市とすることで,探索の集中化を図ったものである。
都市
iにいるアリは次の式によって与えられたルールによって次の都市
jを選択する。
otherwise J
q q j argmaxl Nk il il if 0
(4)
ここで
qは[0,1]の一様乱数,q
0 (0 ≤ q0 ≤ 1)はパラメータである。
Jは(1)で与えられた確率分布 に従って選択された確率変数である。つまり,
q ≤ q0が満たされない場合には,従来どおり
(1)式に従って,次の訪問都市を確率的に選択することになる。
ACS
のフェロモンアップデートは「大域的更新ルール」と「局所的更新ルール」の
2段階 で行われる。
ASでは前者の「大域的更新ルール」のみを行っているといえる。
1)
局所的フェロモン更新ルール
局所的更新ルールは,アリが次の都市を選択して移動するたびに適用される。つまり,
1ステップ中に(アリの数× 都市数)回のフェロモンのアップデートが行われることになる。
そのため,
1ステップ中にも探索領域の集中化が進行していく。また,ここでのフェロモン 増加量はフェロモンの初期値にフェロモン蒸発率を乗じた値となり,局所的更新ルールは フェロモンの値を初期値に近づける効果を持つ。この効果により探索領域が集中しすぎて しまうことを防いでいる。すべてのアリが少しずつ異なるフェロモン情報を参照している と考えることもでき,局所的フェロモンルールには探索の多様性維持の効果が期待できる。
1
0ij ij (5)
ψは局所的フェロモン更新での蒸発率である。
2)
大域的フェロモン更新ルール
大域的更新ルールではAS と同様にすべてのアリが巡回路を生成し終えた後に適用される。
AS
ではすべてのアリがフェロモンアップデートを行っているが,ACS ではそのステップで
の最良解
(iteration best)を生成したアリのみがアップデートを許される。この大域的更新ル
ールによるフェロモンアップデートは,探索領域を最良解(iteration best
)の方向へと集中化させる効果を持っている。
ij ijij
1 (6)
otherwise T j i if L
ij 0
, /
1 (7)
T+
,L
+はそのステップでの最良解
(iteration best)の巡回路と,その巡回路長を表す。
3.3 Max Min Ant System
Max Min Ant System (MMAS)はStutzle[5]によって提案されたアルゴリズムであり,フェロモ
ンに上限値と下限値を設けて,常に一定以上の探索の多様性を維持しようというアルゴリズ ムである。フェロモンも初期値は
τ0のかわりに上限値
τmaxが用いられる。フェロモンのアップ デートは,各ステップ中の最良解(iteration best
)を生成したアリのみが許されるため,ACSと同様に(6)式に従って行われる。
アップデート後フェロモンの値をチェックし,フェロモンの値を以下の条件式で調整する。
otherwise if
if
msx ij
ij
ij ij
max
min
min min
(8)
さらに
MMASでは探索の収束を防ぐメカニズムが導入されている。収束の判定には
λ- branching factorが使われている。λ-branching factor の値を
Λとして以下の式によって収束の判 定が行われる。
n
i j nj i
n 1 1 | ij
1 (9)
otherwise
if ij
ij 0
1 max min min
(10)
ここでnは都市の数を表す。もし
Λの値がある閾値以下になったときにはフェロモンの値を初 期化する。これにより,探索に揺り戻しを起こし,局所解に収束してしまった際に,そこから 抜け出す術を与えている。
3.4 Ant System with Elitist Strategy and Ranking
Ant System with Elitist Strategy and Ranking (ASrank) [6]はMMASと同様にフェロモンアップ
デートに改良が加えられている。
ASがすべてのアリ,
MMASが最短経路を生成したアリのみ
がフェロモンのアップデートが許されるのに対し,
ASrankでは経路長の短い上位
σ位までの アリがフェロモンのアップデートが許されている。
1
1
1
ij ij ijbest ij (11)
otherwise
T j i if
Lbest best
best
ij 0
, /
1 (12)
otherwise
T j i if L
ij 0
,
/
(13)
Tbest
,L
bestは探索を通して得られた最良解の巡回路と,その巡回路長を表す。
μは順位を表し,
Tμ
,
Lμはその巡回路と総経路長を表す。
4.
個々のアリの記憶情報を利用した
ACOの提案
まず本研究のヒントとなった論文を以下で簡単に紹介する。Guntsch and Middendorf[7]は,
外部記憶として,コロニー全体としての探索過程の優良解を
k個保持するというものである。これらk個の優良解は,さらに良い解が見つかれば入れ替えが行われるのであるが,その際に,
除外される解のフェロモンがフェロモンマトリクスから減じられる。さらに外部記憶を利用 した論文であるAcan [8]では,解のセグメント化により過去の優良な部分解をフェロモン更新 に利用する方法が述べられている。また
Middendorf et al. [9] の論文からは,多様性維持のための情報交換は,フェロモンマトリクスどうしの操作よりも,アリの作り出した優良解でフ ェロモンマトリクスを直接操作するほうが良いという結果を提案アルゴリズムの設計の際に 参考にした。
個々のアリの記憶情報を利用した
ACO (ACO with External Memory of Each Ant)は,AS,MMAS およびASrank を基礎として拡張されているので,以下では拡張点だけに的を絞り説明する。
主な拡張点は,(i) 個々のアリが記憶能力(外部記憶
1)を持つ点と,
(ii)フェロモンの更新方法,(iii)アリの記憶情報が一定の確率で消去される点の3
点である。
まず,
(i)は,個々のアリに過去の探索過程での最適解を記憶させる。また(ii)の更新方法は,
各繰返しでのフェロモン更新は,
ASと同じであるが,各アリが経路選択をする際に使うフェ ロモンマトリクスは全体のフェロモンマトリクスではなく,各アリが独自に発見した過去の 最適解でさらに全体のフェロモンマトリクスを更新したものを使う。つまり,場に残された フェロモンをさらに独自の記憶により強化した後に,それぞれのアリは経路を選択する。
1 アリは社会性昆虫なので、集団内部の情報共有であるフェロモンマトリクスを「内部記憶」、そ の反対に、フェロモンマトリクス以外の記憶である個々のアリの持つ記憶情報を「外部記憶」と して本論文では使用した。
Nk l
il k il il
ij k ij k ij
pij
(14)
otherwise T j i if
Lbestk bestk
k
ij 0
, /
1 (15)
ここでbest
kとは探索中でアリエージェントkが生成した最良解を表す。共通のフェロモンマト リクスはMMAS に基づいて,各ステップでの最良解を生成したアリ(
iteration best)でアップ デートする。今回は最良解のみでフェロモンアップデートを行っているが
Cordon et al. [10]のように最悪解も利用する手法も存在する.また,
MMASに倣い,フェロモン値には上限値と下 限値を設定する。
従来型のACOと提案アルゴリズムにおける個々のアリが利用するフェロモン情報の違いを 表したものが図
4である。都市間に付与されているフェロモン情報はマトリクスで保持され ている。従来型の
ACOでは共通のフェロモンマトリクスを利用して,すべてのアリが順回路の探索を行う。それに対し,提案アルゴリズムでは共通のフェロモンマトリクスを個々のアリ が記憶している自身の最良解でアップデートし,独自のフェロモンマトリクスを一時的に生 成している。その独自のフェロモンマトリクスを使って,巡回路の生成を行うことにより,探 索に多様性が生まれる。
図4 アリの利用するフェロモンマトリクスの違い
中道・有田[11] では,ASrank アルゴリズムにアリがランダム選択を一定の割合で行う機能を
追加することによる,最適化における解探索の集中化と多様化のバランス調整の効果を検討
し,その有効性を見出している。そこで本研究では,(iii)一定の確率で個々のアリの記憶情報
を消去する機能を追加することで,場に残されたフェロモンのみで経路の選択を行うアリと
独自の記憶情報を加味して経路の選択を行うアリという性質の異なるアリを用いた。記憶が
消去されたアリは式(1)に従って次の都市を選択する。これにより探索における多様性維持の 効果が期待できる。
提案アルゴリズムの全体的な流れは,図
5に擬似コードで示す。
図5
擬似コードによる個々のアリの記憶情報を利用した
ACO アルゴリズム5.
性能比較実験
実験には
TSPライブラリーの標準テスト問題
eil51, eil76, eil101, kroA100, d198の
5つを用い る。問題名についている数値は都市数を表している。比較するアルゴリズムには,
ACOの中 でも優れた性能で知られる
MMASを採用した。この実験に使用した各パラメータは
α = 1.0, β= 2.0, ρ = 0.02, λ = 0.05
,そして
Λの閾値は
1.00001である。アリの数
mは都市の数
nと等しく する。
τmaxと
τminはそれぞれ以下の式によって与えられる。
j ij
i d
min 1
max
(16)
n 2
max min
(17)
次に実験の結果を表
1~表
5に示す。実験は試行数
50回,世代数
10000とした。
Best,Avg.,Worst
,
Time(sec.)は,それぞれ
50回の実験で得られた,最良解,平均値,最悪値,実験の平均
時間を表す。また,
Refresh rateはアリの記憶情報を消去する確率である。さらに,データの分 布や外れ値を可視化した
Boxplotも示す。
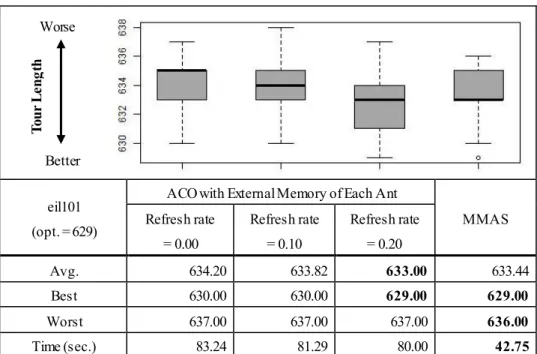
eil51
を除いて,提案アルゴリズムが
MMASよりも同等以上の探索性能を有していること
が確認された。実験で得られた平均値
Avg.に着目すると,
eil51では
Refresh rateが大きくなる
ほど探索性能が向上することがわかる。また,
Boxplotの中央値を見ても,
MMASが最も高確
率で最適解を見つけ出せると考えられる。
eil51
を除いた
eil76,
eil101,
kroA100および
d198では,アリの記憶を永続させるよりも,
一定の確率で記憶の消去がある場合の方が優れたパフォーマンスを示した。つまり,対象とす る問題の都市数が多い難しい問題は,
Refresh rateを適切に調整する必要であると言える。
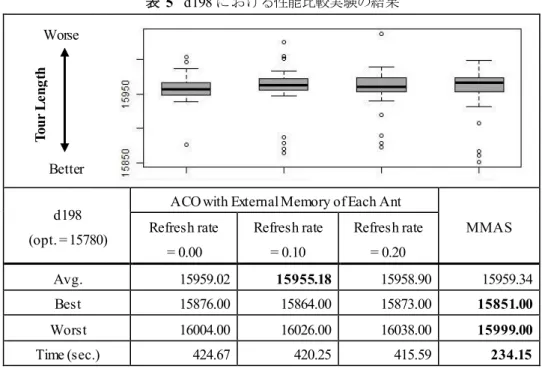
d198では平均値
Avg.が,Refresh rate = 0.10の時に最良値となっているが,
Boxplotの形状から判断
すると,
Refresh rate = 0.00の方が安定して良い解を見つけられるとも解釈できる。
実験結果全体としては,アリの記憶が永続的に保持されるケース
(Refresh rate = 0.0)よりも,
一定確率でアリの記憶が消去されるほうが良い性能を示すことが明らかとなった。
表1 eil51における性能比較実験の結果
eil51 (opt. = 426)
ACO with External Memory of Each Ant
MMAS Refresh rate
= 0.00
Refresh rate
= 0.10
Refresh rate
= 0.20
Avg. 427.32 426.88 426.86 426.72
Best 426.00 426.00 426.00 426.00
Worst 428.00 428.00 428.00 428.00
Time (sec.) 18.45 17.82 17.46 11.17
表2 eil76における性能比較実験の結果
eil76 (opt. = 538)
ACO with External Memory of Each Ant
MMAS Refresh rate
= 0.00
Refresh rate
= 0.10
Refresh rate
= 0.20
Avg. 538.46 538.36 538.28 538.48
Best 538.00 538.00 538.00 538.00
Worst 540.00 539.00 540.00 544.00
Time (sec.) 42.79 42.51 41.72 29.19
Worse
Better
Tour Length
Worse
Better
Tour Length
表3 eil101における性能比較実験の結果
eil101 (opt. = 629)
ACO with External Memory of Each Ant
MMAS Refresh rate
= 0.00
Refresh rate
= 0.10
Refresh rate
= 0.20
Avg. 634.20 633.82 633.00 633.44
Best 630.00 630.00 629.00 629.00
Worst 637.00 637.00 637.00 636.00
Time (sec.) 83.24 81.29 80.00 42.75
表4 kroA100における性能比較実験の結果
kroA100 (opt. = 21282)
ACO with External Memory of Each Ant
MMAS Refresh rate
= 0.00
Refresh rate
= 0.10
Refresh rate
= 0.20
Avg. 21300 21230 21297 21303
Best 21282 21282 21282 21282
Worst 21379 21379 21379 21379
Time (sec.) 85.31 80.20 78.79 44.38
Worse
Better
Tour Length
Worse
Better
Tour Length
表5 d198における性能比較実験の結果
d198 (opt. = 15780)
ACO with External Memory of Each Ant
MMAS Refresh rate
= 0.00
Refresh rate
= 0.10
Refresh rate
= 0.20
Avg. 15959.02 15955.18 15958.90 15959.34
Best 15876.00 15864.00 15873.00 15851.00
Worst 16004.00 16026.00 16038.00 15999.00
Time (sec.) 424.67 420.25 415.59 234.15
6.
まとめ
本稿では,個々のアリが自身の探索で発見した最良解を記憶して,その記憶とフェロモンマ トリクス情報を基に自身の経路選択を行う手法を提案した。さらに,探索の集中化と多様化の バランス調整を行う方法として,一定確率でアリの記憶が失われる機能を追加した。比較実験 の結果から,提案アルゴリズムは
ACOの中でも非常に優れた性能を持つ
MMASに匹敵する 性能を持つことが示された。さらにアリの記憶情報は恒久とするよりも一定確率で消去した ほうが好ましいことも明らかとなった。概して,難しい問題に対しては一定の確率でアリの記 憶が消去されることで探索のランダム性が増し,その結果,局所的探索に比べて大域的探索が 強化され最適解を求める確率が上がると考えられる。
今後の課題としてはアルゴリズムの並列化などが挙げられる。本研究では
1つの集団で探 索を行っているが,集団を複数のサブ集団に分割し,それぞれのサブ集団が独自の探索を行う ことで探索の多様化を図ることが考えられる。さらに,記憶情報を消去する機能が局所的探索 と大域的探索のバランスにどのように影響しているかの効果を詳細に分析することも今後の 重要課題である。
参考文献
[1] Dorigo, M., and Gambardella, L. M., “Ant Colonies for The Traveling Salesman Problem,”
BioSystems, Vol. 43, pp.73–81, 1997.
[2] Bellmore, M., and Nemhauser, G. L., “The Traveling Salesman Problem: A Survey,” OPERATIONS RESEARCH, Vol.16, No.3, pp.538 –558, 1968.
Worse
Better
Tour Length
[3] TSPLIB, [Accessed 21 December 2020]. Ruprecht-Karls-Universität Heidelberg. Available from:
http://comopt.ifi.uni-heidelberg.de/software/TSPLIB95/tsp/
[4] Dorigo, M., and Gambardella, L. M., “Ant colony system: a cooperative learning approach to the traveling salesman problem,” Evolutionary Computation, pp.53–63, 1997.
[5] Stutzle, T., “Max-Min Ant System,” Future Generation Computer Systems, Vol.16, No.8, pp.889–
914, 2000.
[6] Bullnheimer, B., Hartl, R. F., and Strauss, C., “A New Rank Based Version of The Ant System: A Computational Study,” Central European Journal of Operations Research and Economics, Vol. 7, No.1, pp. 25–38, 1999.
[7] Guntsch, M., and Middendorf, M., “A Population Based Approach for ACO,” Applications of Evolutionary Computing, Vol. 2279, pp. 72–81, 2002.
[8] Acan, A., “An External Memory Implementation in Ant Colony Optimization,” in Proc. the 4th International Workshop of ANTS, pp. 73–82, 2004.
[9] Middendorf, M., Reischle, F., and Schmeck, H., “Information Exchange in Multi Colony Ant Algorithms,” in International Parallel and Distributed Processing Symposium, pp. 645–652, 2000.
[10] Cordon, O., de Viana, I. F., Herrera, F., and Moreno, L., “A New ACO Model Integrating Evolutionary Computation Concepts,” in Proc. Ants’2000, pp. 22–29, 2000.
[11]