Evaluation of Cross-Language Voice Conversion Based on GMM and Straight
4
0
0
全文
(2) 2.1. GMM・based voice conversion algorithms. Table 1: Recording conditions.. 1n the GMM algorithm, the training data size and the number of trainable paramet巴rs ar巴 variable [3],[4). The probability distribution of acoustic features æ can be de scribed as. =乞αiN(æ ; J-ti,Ei), 玄αi = 1,. p(x). i=l. aiさ0,. (1). 1=1. where N(æ;μ, E) denot巴s the normal dist巾ution with the mean vector μ and the covariance matrix E.αi de notes a weight of class i, and m denotes the total number of the Gaussian mixtures.. Conversion of the acoustic features of the source speaker to those of the target speaker is performed by a Mapping Function, defined as follows,. Microphone. SONY C355. Recording equipment. DAT SONY DTC-ZA5ES. Sampling frequency. 48000 Hz. Number of sentences. 60. 4. IM PLE九fENTATION OF THE. CONVERSION ALGORITH民fS. = E[ylæ]. =芝〉(z)[μr hi(X). Sound treated room. high quality vocoder dev巴loped to meet the necessity of a tlexible and high quality analysis-synthesis [5],(6). It consists of pitch adaptive spectrogram smoothing and fun damental frequ巴ncy extraction (TEMPO), and allows ma nipulation of speech paramet巴rs such as vocal tract length, pitch, and speaking rate.. 2.2. Conversion of acoustic features. F (æ). Recording place. +. Et"(Ei"')-l(æ一月)] ,. ( 2). """ N(æ ;μi, Eア) = 2L白川町j, '. Ej"'). where μ?and μy denote mean vectors of c1ass i for the source and target speakers. Eアis covariance matrix of class i for th巴 source speaker. Er" is the cro怯covanance matrix of class i for the source and target speakers. These matrices are diagonal.. The GMM-based voice conversion algorithm has been implemented in STRAIGHT by Toda et al [7J, [8). 1n their system, acoustic features are described by the cep strum of the smoothed sp巴ctrum analyz巴d by STRA1GHT 1n our work, however, we used Mel cepstrum because of it's closeness to human auditory perception. The prosodic characteristics have not been considered yet but the fun damental frequency (Fo) of the sourc巴 speaker is adjusted to match the target speaker's Fo in average of log-scale for the source information. Th巴 adjusting function is dc scribed as follows,. 1� =主主×ん μz. 2.3. Training of The島1apping Function. EYY. 1. J. μ μ. 1. Eア. μ. fEfz zz-l Ey". 『E EJ E-E EBE EE Z Z 制y z FE --L -E一一 z z. 1n order to estimat巴 parameters such asα1)μ?,μr, Ei", Ey", the probability distribution of the joint vectors z = [æT, yT]T for the source and target speakers is represented by the GMM whose parameters are trained by joint density distribution [9). Covariance matrix Ef and mean vector μf of class i for joint vectors can be written as (3). Expectation maximization (EM) is used for estimating these parameters. 3. A NALYSIS-SYNTHESIS M ETHOD 1n a voice conversion system, not only the voice conver sion algorithm but the quality of the analysis-synthesis method determines the quality of the synthesized voice. Therefore, choosing a reliable analysis-synthesis method is of importance. 1n our work, STRAIGHT was employed as the analysis-synthesis method. STRAIGHT is a very. (4). where 10 and f� denote log scale Fo of source speaker and converted speech of source speaker, and μ" and μv denote mean log scale Fo of source speaker and target speaker. s. EXP ERIM ENT 5.1. Speech Databases. Bilingual (Japanese and English) speech utterances of two Japanese female speakers were recorded, sampled at 48000 Hz. Each speaker has long experience living in abroad or having learned English from a nativ巴 speaker since be fore the age of seven. The speakers read 60 bilingual sentences selected from the ATR phonetically balanced sentences [10). After down sampling to 16000 Hz, the 50 sentences were us巴d for training data sets, and the remaining 10 were used for evaluation sentences for the converted utterances. Table 1 shows other recording con ditions.. 円/】 、,5 6 14 円。.
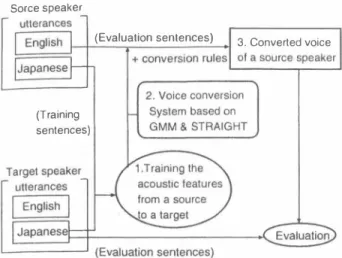
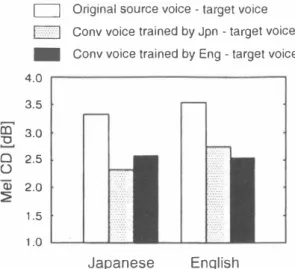
(3) Sorce speaker. Sorce speaker (Evaluation sentences). (Evaluation senlences). 3. Converted voice. + conversion rules. (Training. (Training. sentences). sentences). Figure 1: Diagram of cross-Ianguage conversion proce dure, English converted voice trained by Japanese.. 3. Converted voice 01 a source speaker. Figure 2: Diagram of singJe-Janguage conversion proce dure, Japanese convert巴d voice Irained by Japanese. TabJe 2: AnaJysis parameters.. 5.2. Voice Conversion. In order to investigate the differences between voice con version across differenl languages, both Japanese and En glish trained mapping funclions were used for learning Ihe source and larget speaker's parameters for conversion of acoustic fealures. Therefore, Ihe syslem was lesled on 4 Iypes of female 10 female convert巴d voice, (1) English (Eng) converted voice trained by Japanese (Jpn), (2) Jpn converted voice Irain巴d by Jpn, (3) Eng converled voice Irained by Jpn, and (4) Jpn converted voice Irained by Jpn.The procedure for producing ulterances of (1) Eng converted voice trained by Jpn and (2) Jpn converted voice Irained by Jpn are depicled in Figure I and Figure 2. The procedures of voice conversion trained by English is the sam巴. According to Ihe previòus work of Toda et al [7],[8], Ihe relation between the numb巴r of GMM c1asses and cepslrum dislortion (CD) salurales at a certain number of classes, approximately 64, so we used 64 GMM classes. Other analysis parameters were shown in TabJe 2. Note that the mean Fo of speakers is different 6. EVALUATION To evaluat巴 sp巴aker individuality objectively, a Mel cep strum distortÌon (MeJ CD) function was caJcuJated be Iween the converted speech and Ihe target speech. MeJ (conv) �_... (t r) CD is caJculated as beJow, where mc)"u"V) and mc� ) a dcnote MeJ CD coefficien'ts of converted voice and target voice, respectiveJy.. _. MωD=州nl0. 1. {町21(mcj …) - mc\ tar)V.. (5). AnaJysis Window. Gaussian. sampling frequency. 16000 Hz. Shift length. 5 ms. Number of FFT points. 1024. Number of the GMM cJass. 64. Training sentences. 50. EvaJuation senlences. 10. mean Fo (source speaker). Jpn: 270.0 Hz Eng: 248.6 Hz. mean Fo (target speaker). Jpn: 227.6 Hz Eng: 233.9 Hz. If the value of MeJ CD is smaller, speaker individuality of converted voic巴 is c10ser to that of target speaker. Figure 3 shows the results of Mel CD whose conversion ruJes were trained by 50 English and 50 Japanese senlences. Table 6 shows the values numerically‘ We can see from the results in the tabJe that character istics of converted speech were also improved within the cross-Ianguage voice conversion. However, since there are normally large spectral differences between Japanese and English speech sounds, the resulls of the converted speech trained by the same language show c10ser vaJ ues (i.e. English converted voice trained by English and Japanese converted voice trained by Japanese is still pre feπed). In addition, for producing a higher quality con verted voice, we must consider the voice quality differ ences between Japanese and English of Ihe same speaker. nぺu 円J RU nO 14 司J.
(4) 仁コ. Original source voice - target voice. (::::::<-1. Conv voice trained by Jpn - target voice. _. Conv voice trained by Eng - target voice. 4.。. 3.5 宅3.0 o 2.5 0 2.0 2 1.5 1.0. 9. References [1] M. Abe, K. Shikano and H. Kuwabara,“StatislÌ cal analysis of bilingual speaker's speech for cross language voice conversion," 1. Acoust. Soc. Am. 90(1),pp. 7ι82,July 1991 [2] M. Abe, S. Nakamura, K. Shikano, and H. Kuwabara,“Voice conversion through vector quan tization," J. Acoust. Soc. Jpn. (E), vol. 11,no. 2, pp. 71-76,1990.. Q). Japanese. Y. Stylianou, O. Cappé, E. Moulines,“Statistical methods for voice quality transformation," Proc. EUROSPEECH, Madrid,Spain,pp. 447-450,Sept. 1995.. [4]. Y. Stylianou,O. Cappé, “A system voice conversion based on probabilistic classification and a harmonic plus noise model," Proc. ICASSP, Seattle, U.S.A., pp. 281-284,May 1998.. English. Figure 3: Result of t山h巴O同巴ct附eva叫a剖lu帥Jat of speak巴r individuality.. Table 3: Values of Mel cepstrum distortion. Jpn (Hz). Eng (Hz). Original Sourc巴ーTarget. 3.33. 3.53. converted voice - Target. 2.32. 2.75. 2.59. 2.52. (trained by Jpn) converted voice - Target. [3]. (trained by Eng). [5] H. Kawahara, “Speech representation and trans formation using adaptive int巴rpolation of weight巴d spectrum: vocoder revisited," Proc. ICASSP, Mu nich, Germany,pp. 1303-1306, Apr. 1997. (6) H. Kawahara, 1. Masuda-Katsuse,A. de Chev巴igné, “Restructuring speech representations using a pitch-adaptive time-frequency smoothing and an instantaneous-frequency-based FO extraction: pos sibl巴 role of a repetiti ve structure in sounds," Speech Communication, vol. 27, no. 3-4, pp. 187-207, 1999.. 7. CONCLUSION In this paper, we evaluated the effect of applying cross language voice conversion to a system based on GMM (Gaussian Mixture恥10del) and STRAIGHT. From the re sults of the objective evaluation using Mel cepstrum dis tortion,it was found that the system performs cross-Iangu ag巴 voice conversion nearly equivalent to that of single langu- age conversion. This indicates that it has a pos sibility to be employed to a language learning system. For the next step, the problem of mean fundamental fre quency (Fo) differences between Japanese and English utterances of the same speaker and variation of the quaト ity of voice must be considered, as this wiU cause irト consistency in perception of converted voice sounds. Fu ture work will include developing a method of perceptual evaluation which takes such differences into account. 8. ACKNO、司/LEDGM ENT. (7) T. Toda, J. Lu, H. Saruwatari, K. Shikano, “STRAIGHT-based voice conversion algorithm based on gaussian mixture model, " Proc. ICSLP, PAe(09-10)-K-05, pp. 279-282, Beijing, China, Oct. 2000 [8]. T.. H. Saruwatari, K. Shikano,“Voice conver algorithm based on Gaussian mixture model with dynamic frequency wa中ing of STRAIGHT spectrum," Proc. ICASSP, Salt Lake City, U.S.A., May 2001. Toda,. sion. [9] A. Kain,and M.W. Macon, “Spectral voice conver sion for text-to-speech synthesis," Proc. ICASSP, Seattle,U.S.A., May 1998. [10] M. Abe, Y. Sagisaka, T. Umeda and H. Kuwabara, “Speech Database Usr's Manual," ATR Technical Report (in Japanese). This work was partly supported by JST/CREST (Core Research for Evolutional Science and Technology) in Japan.. A也 A『 F D 、 3 14 3.
(5)
図
関連したドキュメント
Figure 3 shows the graph of the solution to the optimal- ity system, showing propagation of CD4+ T cells, infected CD4+ T cells, reverse transcriptase inhibitor and a protease
In this paper, we focus not only on proving the global stability properties for the case of continuous age by constructing suitable Lyapunov functions, but also on giving
If condition (2) holds then no line intersects all the segments AB, BC, DE, EA (if such line exists then it also intersects the segment CD by condition (2) which is impossible due
2 Combining the lemma 5.4 with the main theorem of [SW1], we immediately obtain the following corollary.. Corollary 5.5 Let l > 3 be
In this paper a similar problem is studied for semidynamical systems. We prove that a non-trivial, weakly minimal and negatively strongly invariant sets in a semidynamical system on
A connection with partially asymmetric exclusion process (PASEP) Type B Permutation tableaux defined by Lam and Williams.. 4
nuclear power generation equipment, construction and maintenance of power transmission and conversion equipment and civil engineering and construction equipment, nonlife
Amount of Remuneration, etc. The Company does not pay to Directors who concurrently serve as Executive Officer the remuneration paid to Directors. Therefore, “Number of Persons”
