DEIM Forum 2016 G3-2
株価とニュース報道を用いた上場企業の暗黙関係の発見
馬場
慧
†馬
強
†††
京都大学工学部情報学科 〒 606–8501 京都市左京区吉田本町
††
京都大学大学院情報学研究科 〒 606–8501 京都市左京区吉田本町
E-mail:
†
[email protected],
††
[email protected]
あらまし 企業間の関係分析は,マーケティングや意思決定において重要である.企業の Web サイトなどで子会社や
グループ会社などに関する記述は多いが,スポンサー関係や取引先などの暗黙的に関連する企業に関する情報は少な
い.本研究では,関連するニュースイベントに対する株価の動向の類似性を分析して,上場企業間の暗黙的な関係を
発見する手法を提案する.提案手法では,まず,株価を市場,業種と企業自身の三つの要因の合成モデルから生成さ
れると仮定し,市場や業種の影響を調整した企業の株価を抽出する.調整済みの株価系列データを正規化した上,関
連するニュースイベントの日付を元に実価データの部分系列を抽出し,抽出された部分系列の類似度を計算すること
で,関連性の強い企業を発見する.東京株式市場の株価データとの財経新聞のニュース記事を用いて提案手法の評価
を行う.
キーワード
関係マイニング,投資情報分析,時系列データ
1.
は じ め に
企業は組織であり,他の組織との関わり合いの中で存続させ 成長させることが重要である.企業は他の企業との関係によっ て多種多様な組織間のネットワークを構成している.このよう な組織と組織の関係ネットワークを分析する「組織間関係論」 は長年研究の対象となっており[1],現在も研究が行われている. 企業間には様々な関係が存在しており,企業のWebサイト 等やニュース記事を見ることによって他の企業との関係を調べ ることができる.しかし,企業間の関係には様々な種類があり, グループ会社,子会社といった明示的な関係もあれば,スポン サー関係や取引先など直接は明らかにされていない暗黙的な関 係もある.企業間の関係性を分析する研究は既に行われている が,インターネットで得られるテキスト情報から明示的な関係 のみの分析を行っているものが多い[2]. 本研究では,企業同士の関係を株価という観点から明らかに し,関係のある企業を集めた企業間のネットワークを分析する ことで,企業の競争力の分析や戦略決定,個人投資家の企業の 成長性の分析や投資企業選定の支援を行う. 本研究では意思決定支援に重要である,業績に影響を及ぼす 関係を対象とし,株価とニュースイベント情報を併用した手法 を提案する.企業間に業績に影響を及ぼす関係が存在すれば, 両企業の株価の動きに類似性があると考えられる.企業の業績 を調査するに当たって株価は非常に重要な要素の一つであり, 株価が上昇しているときは企業の業績もよく,株価が下落して いるときは企業の業績も悪いといったことが多い.企業間の株 価の動きの関連性を調査することで,その企業間の関係性を明 らかにすることもできる.例えば,ある企業が自動車の開発を 行った際に別の企業の部品を使用していれば,その部品の売れ 行きは自動車の売れ行きに左右される.そのような時,自動車 が売れて,開発した企業の業績が良くなり株価が上昇すれば, 図 1 2015/10/19 MORNINGSTAR より抜粋 部品を供給している企業の業績も良くなり株価が上昇する. 企業の株価が上昇するような材料が出ているにも関わらず, 株価が下落しているといった場合も存在する.図1は2015年 10月19日のMORNINGSTAR(注1)で発表されたニュース記 事である.北川鉄工所(6317)は「15年9月中間期の連結利益 予想を引き上げ,純利益は一転して増益見通し」という株価が 上昇するような材料が出ているが,実際の株価は3円のマイナ ス(前日比-0.993%)になっている.そのような場合に,我々は, 企業の業種,市場全体の影響が大きく関係していると考える. 以後本論文では純粋な企業自身のみの株価を実価,業種の指数 を業種指数,市場の指数を市場指数と呼ぶ.本研究では,企業 の株価は実価,業種指数と市場指数からなるとし,株価の合成 モデルを提案し,それに基づいて実価を求めて企業の関係を分 析する. 企業間の関係を分析する際に,まず,異なる企業の株価の値 (注1):http://www.morningstar.co.jp/幅の差を調整するため,企業の実価の前日比を求めて正規化す る.次に,企業間の関係が動的に変化することを考慮して,企 業に関係するニュースイベントをトリガーとして株価の比較す る範囲を決定する.比較範囲の系列データを用いて,企業間の 関連度を推定する.本研究では,正規化した実価データを用い て企業間の関連度を計算する手法として,ハミング距離,SAX 法,相関係数と偏相関係数の四つの手法を検討する. 本研究の主な貢献は以下にまとめる. • 企業の株価の合成モデルを提案し,市場や業種の影響を 調整して,より企業自身の業績を反映している実価を用いて企 業間の株価の動向の類似性を求める.(3節) • 前日比を用いて株価を正規化して類似度を計算する手法 を提案している.提案手法は異なる企業間の株価の単価の差を 吸収し,値のトレンドにフォーカスした分析ができる.(4節) • ニュースイベントを用いて比較する株価の範囲を決める. 企業間の関係は時間の経過と共に変化するため,比較対象の株 価の範囲の選別が非常に重要である.提案手法は,ニュースイ ベントをトリガーとし,比較範囲を動的に決めることで,直近 のニュースイベントが発生してからの企業間の関係を抽出する ことが可能である.(4. 5節) 本論文の構成は次の通りである.2節では企業間の関係や, テキスト情報が株価に与える影響に関する関連研究を示し,3 節では本研究で仮定する株価データの合成モデルについて記す. 4節では企業間の関係を分析する際の手法を説明し,5節では 評価実験の方法とその結果を示す.そして,6節は本研究のま とめである.
2.
関 連 研 究
企業間ネットワークを抽出,分析し,知見を得る研究は盛ん におこなわれている.金らはWeb上に存在している情報から 企業間の関係を明らかにし,企業ネットワークを抽出する手法 を提案している[2].金らの研究は企業間の関係性を導き出す情 報として,Web上のテキスト情報のみを対象としており,抽出 する関係性の対象も提携関係と訴訟関係のみに絞っているが, 本研究では関係性の対象を取らず,企業の業績に焦点を当てて 関係性があるかどうかを判断する. Wooらは協調性,適応性,雰囲気といった観点から企業間関 係の質を評価し,関係とサービスの質の関係を明らかにする手 法を提案している[3].また,Rauyruenらは企業間関係の質を 決定する要因としてサービスの品質や売り手へのコミットメン ト,信頼性,満足度をあげており,関係の質と購買の意図,繰 り返し買うかどうかの忠実性に及ぼす影響の関係を調べた[4]. WooらやRauyruenらは企業間の関係の質をサービスの向上 や顧客分析に利用するものと位置づけており,意思決定には利 用しない. サッカーとファイナンスの関係の分野では,Michaelらや Aliakbarらはサッカーのクラブチームの試合結果がスポンサー 企業の株価に影響を与えることを明らかにしている[5] [6].こ れらの研究では暗黙に関係する企業をスポンサー関係をもとに 手動で与えているが,本研究では株価のデータをもとに自動的 に発見する. ニュース記事やソーシャルネットワーク等のテキスト情報 が株価に影響を与えるという研究も多く存在する.TetlockはWall Street Journalの市場観測のコラム記事から悲観度を抽出
し,ダウ工業平均株価と関係していることを明らかにした[7]. また,BollenらはTwitterのテキスト情報であるツイートを解 析し,世間のムードを測ることによってダウ工業平均株価の変 動の予測する試みを行っている[8].このようにテキスト情報は 株価の変動を測るうえで重要な指標のひとつとなっている.こ れらの研究では,テキスト情報を将来的な株価変動の予測に用 いているが,本研究では株価変動の予測ではなくテキスト情報 を株価の変動のタイミングを示す情報として利用する.
3.
株価データの合成モデル
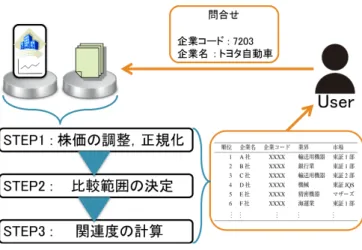
本節では株価データの合成モデルについて述べる.業界や市 場の影響によって変動し,企業そのものの動きを表していない 株価のデータで関連度を計算することを避けるため,株価の合 成モデルを提案する.さらに,この合成モデルを用いて,企業 の株価から市場と業種の影響を調整する手法を提案する. 1節で説明したように,本研究は,企業自身の業績のみから なる株価を実価,業種の指数を業種指数,市場の指数を市場指 数と呼ぶ.実価,業種指数,市場指数が株価を構成している式 を求める際に,季節調整[9]の考え方を用いる.季節調整とは経 済統計の時系列データから季節要因を取り除く手法であり,株 価の分析にも使用される.本研究では季節調整で利用される合 成モデルである乗法モデルを用いる.元の株価のデータをXt, 実価をCt,業種指数をIt,市場指数をMtとすると,株価の 合成モデルは下記のように定義される. Xt= Ct× It× Mt (1) ただし,Itには調節する企業が属する業種の業種別株価指数, Mtには調節する企業が東証1部であればTOPIX,東証2部 であれば東証2部株価指数といったようにその企業が属する市 場の株価指数を用いる.企業が属する業種は,東京証券取引所 が定めた33業種を利用する.この合成モデルを用いて,調整 する企業の株価の実価Ctを式(2)のように計算する. Ct= Xt It× Mt (2) 例として,トヨタ自動車(7203)の2015年12月30日の 実 価 を 求 め る 手 順 を 示 す.ト ヨ タ 自 動 車 は 業 種 と し て 輸 送 用 機 器 ,市 場 と し て は 東 証1部 に 属 し て い る .2015年 12月30日 の 株 価 ,業 種 指 数 ,市 場 指 数 は そ れ ぞ れ7488, 3267.86,1547.3であるので,トヨタ自動車の実価(ctoyota) はctoyota= 7488 3267.86× 1547.3= 0.00148である.表 1 データセット 株価データ (株価データ ダウンロードサイト) ニュースデータ (財経新聞) 企業情報 (Yahoo! Finance) 個別銘柄の株価 ニュース記事のタイトル 企業コード 業種別株価指数 ニュース記事の本文 企業名 市場ごとの株価指数 ニュース記事の日付 業種名 市場名
4.
関係分析手法
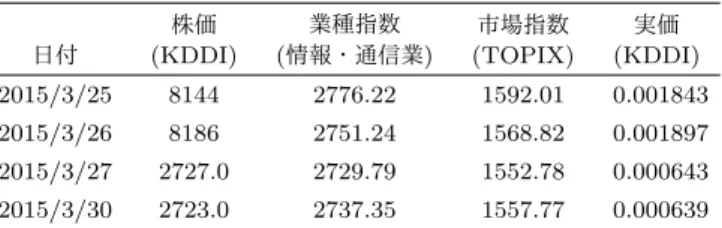
本節では,株価とニュースを用いた企業間の関係の分析手法 について述べる.4. 1節では本研究で扱うデータセットについ て説明し,4. 2節では入力データと出力データおよび処理の流 れを示す.4. 3節では,問合せの企業とその関連企業候補の株 価データの正規化について述べる.4. 4節と4. 5節では,正規 化されたデータを用いて企業間の関連度とそのためのデータ範 囲の決める方法についてそれぞれ説明する. 4. 1 データセット 本研究で使用する入力は表1にまとめる. 株価データは株価データダウンロードサイト(注2)のデータ を用いる.株価データダウンロードサイトから2007年から現 在までのTOPIX,業種別株価指数等の様々な株価指数データ, 全ての上場企業の個別銘柄データをcsvファイルでダウンロー ドして利用する.各株価指数データには株式市場営業日の始値, 高値,安値,終値,各個別銘柄データには株式市場営業日の始 値,高値,安値,終値,出来高,売買代金が保存されているが, その日にあったニュースイベントの全ての影響を反映している 終値を株価のデータとして用いる.各個別銘柄データの中でも, 東証1部,東証2部,東証マザーズ,ジャスダックに上場して いる企業のうち,Yahoo! Finance(注 3)に企業のページが存在す る銘柄のみを対象とし,株価データに欠損値を含んでいる銘柄 は対象としない.本研究では使用するニュース記事を2010年 9月14日以降のものとしているので2010年から2015年の株 価データを使用する. ニュース記事のデータは財経新聞(注4)のニュース記事を使用 する.財経新聞は様々なカテゴリのニュース記事を配信してい るが,本研究では株価に直接影響を与えやすい企業の動きの ニュースを多く扱っている企業・産業カテゴリのニュース記事 のみを対象とする.対象とするニュース記事の期間は最大にさ かのぼることができる2010年9月14日から2015年の株式 市場最終日である2015年12月30日の5年強とする.また, ニュースイベントによって比較範囲を決定した際に,範囲内の データがすべて揃っていない企業は関連度を計算することが不 可能であるため,そのような銘柄は対象としない. 企業名の記事への言及の有無に基づいてその企業の関連ニュー スであるか否かを決める.企業名としてはYahoo! Financeで (注2):http://k-db.com/ (注3):http://finance.yahoo.co.jp/ (注4):http://www.zaikei.co.jp/ 図 2 処理の流れ 使用されているものを用いる.例えば,企業コード7203の企 業であれば‘トヨタ自動車’であり,企業コード7267の企業は ‘ホンダ’である.また,企業名に全角アルファベット等が含ま れている場合には半角に変換したのちに検索する. 4. 2 手法の概要 提案手法の処理の流れを図2に示す. • 入力データ 入力データは4. 1節に説明したように,ニュースデータと株価 データを用いる.また,調べたい企業コードをユーザから入力 する問合せとする.つまり,入力は問合せである企業コード, 企業株価データベースとニュースデータベースからなる. • 出力データ 出力データとして問合せである上場企業とその他の上場企業の 関連度を比較し,高い順にランキング形式で表示する.ユーザ には上場企業のランキングを提示し,企業間関係の分析の支援 をおこなう. • 処理 入力データを出力データにする際の処理の流れは以下の通りで ある. – STEP1 企業の株価データ,業種指数,市場指数を3節の式(2)を用い て計算し各企業の実価を求め,正規化を行う. – STEP2 ニュース記事の中から対象としている企業に言及しているニュー ス記事を取り出し,発表された日付を元に関連度を求める際に 用いるデータの範囲を決定する. – STEP3 実際に,STEP1で求めた実価とSTEP2で設定した範囲を元 に問合せである上場企業とその他すべての上場企業との関連度 を計算する. 4. 3 実価の正規化 前日比は株価データを解析する際に重要な指標のひとつであ る.多くのファイナンスのWebサイトで公開していることか表 2 KDDI の終値 日付 株価 (KDDI) 業種指数 (情報・通信業) 市場指数 (TOPIX) 実価 (KDDI) 2015/3/25 8144 2776.22 1592.01 0.001843 2015/3/26 8186 2751.24 1568.82 0.001897 2015/3/27 2727.0 2729.79 1552.78 0.000643 2015/3/30 2723.0 2737.35 1557.77 0.000639 らもその重要度がうかがえる.前日比は現在の株価が前日の株 価の終値の値から何%増減しているかを表している.企業に よって値の大きさが違う株価をすべて同じスケールのデータに 変換できるので,比較することが容易になる.また,ニュース イベントが発生してから株価がどのように推移したのかを見る 必要がある本研究では,前日比により前日からの株価の推移を 明らかにする. 前日比を求める際,前日のデータが必要であるため,前日の データが存在しない株取引開始の日の値は0とする.式(3)は 前日の株価の終値をcpd−1,当日の株価の終値をcpdとしたと きの前日比(δd)を求める式である. δd= 0, d = 1 cpd− cpd−1 cpd−1 × 100, d > 1 (3) 株式分割や株式併合が行われた際にはδの絶対値が非常に大 きな値となってしまう場合がある.例として,KDDI(9433)の 株式分割が行われた時の株価の変動を示す.表2は,株式分割 が行われた前後2日間の株価データである.この時,実価を前 日比での正規化を行うとそれぞれの期間の前日比は (−2.844, 194.798, 0.747) となり,株式が分割された日の前日比の値が極端に大きくなっ ているのがわかる. そこで,前日や翌日の値に比べて当日のδの絶対値が極端に 大きくなっていることがあれば,外れ値として処理することに よって,株式分割や株式併合の際の値の変化に対処する.実価 の前日比のデータをδi(δ1 = 0, i = 1, 2,· · · , n)とし,µをδi の平均値,σをδiの標準偏差とすると,δiの式(4)(注 5)が成り 立つ際にδiは外れ値であるとする.外れ値を処理する際の式は 式(5)である. δi<= µ − 10σ or δi>= µ + 10σ (4) δi= δn−1, i = n δi−1+ δi+1 2 , i |= n (5) (注5):σ の係数である 10 は実験的に決定した値であるので,最適な係数は今 後検討していく予定である. この式により,大きく外れた値を棄却し,その日の前日比とし ては前後の日の前日比の平均値を与える. さらに,比較する企業群の中で外れ値を除いた一番大きなδ の絶対値ですべてのδを割ることによって,−1から1の値に 正規化する. 4. 4 関 連 度 時系列データの関連性分析の手法には様々なものがあり,文 字列にエンコードしたのち,文字列の類似度を計算する手法も あれば,そのままのデータを比較していく手法もある.本研究 では,時系列データの関連度を求めるにあたって,両方の手法 を用いる.文字列にエンコードしたのちに文字列同士の類似度 を計算する手法としては4. 4. 1節のハミング距離と4. 4. 2節の SAX法を使用し,そのままの時系列データの関連度を求める 手法としては4. 4. 3節の相関係数と4. 4. 4節の偏相関係数を使 用する.実験では,この4種類の手法について実験結果を用い て考察を行う. 4. 4. 1 ハミング距離 同じ長さをもつ文字列同士の類似度を示す尺度としてハミン グ距離が利用されている.ハミング距離では距離が小さいほど 比較する二つの時系列データは類似しているといえ,2つの文 字列の距離は,一方の文字列に文字の置換を行いもう一方の文 字列に変形する最小のコストとして求められる.従来のハミン グ距離の計算では,文字の置換コストはすべて1であるが,本 研究では文字の辞書順を考慮する. 正規化した実価を文字列にエンコードする際,使用する文字 の数k(注 6)はパラメータとして与え,実験的に変更できるよう にする.kの値はすべてのデータが同じ文字にエンコードされ ないように1より大きくとる.各文字のとる値の範囲は−1か ら1までの範囲をkの値で等間隔に割ったものとする. 文字の種類は前日から株価がいかほど上昇下落したかを表す ものであるので,文字の置換のコストをすべて1にしてしまう と株価の関連度を測る際に不都合が生じる.このような不都合 を防ぐために,ハミング距離の文字の置換に文字の差によるコ ストを付加する.具体的には隣接する文字に置換する場合のコ ストを1とする.aからjへの置換のコストは9となり,aか らbのコストは1となるので,文字の種類によってコストが 変わる.この新たに文字の置換の定義を変更したハミング距離 を用いて文字列同士の距離を求める.2つの比較する文字列を A = a1a2a3· · · an,B = b1b2b3· · · bnとし,関数dict(x)を文 字xを辞書順でならべたときに何番目かを表す関数とすると, ハミング距離を求める式は式(6)のようになる. dh(A, B) = n ∑ i=1 |dict(ai)− dict(bi)| (6) 関連度(rh(a, b))を求める式は以下の式である.この値が0 に近いほど関連度が高いと言える.len(X)は文字列Xの長さ (注6):最適な k の値を求める方法については,今後の研究で検討する予定であ る.
を表す関数とする.本研究では,比較する文字列の長さは同じ
であるのでlen(A) = len(B)である.以下,関数len()は同様
の定義のものとして扱う.
rh(A, B) =
dh(A, B)
len(A) (7)
4. 4. 2 S A X法
SAX法(Symbolic Aggregate approXimation)は時系列デー
タを分析する際に用いられる手法の一つであり,Linらによっ
て提案された手法[10]である.SAX法も時系列データを文字
列にエンコードしてから類似度を測る手法であるが,ハミング 距離の際に用いた文字列へのエンコードとは異なり,標準正規 分布に従いエンコードを行う.
SAX法ではまず,PAA(Piecewise Aggregate
Approxima-tion)という操作を行う.PAAは時系列データを時間軸に沿っ て等間隔にw個のフレームに分割し,各フレームの平均値を求 め,各フレームに含まれているデータをそのフレームの平均値に 置き換えるという操作である.時系列データC = c1, c2,· · · , cn をC = c1, c2,· · · , cwに変換するとき,変換後の値を求める式 は式(8)のようになる. ci= w n n wi ∑ j=wn(i−1)+1 cj (8) 本研究では1日ごとの前日からの実価の上昇下落に注視し ているため,平均値を取ると特徴が失われてしまう可能性が高 い.そのため,SAX法ではPAAで時系列データを操作して から類似度の計算を行うのに対し,本研究ではフレームの数を ニュース発生時から経過した日数とし,1日ごとの実価のデー タをPAAの変換を行った後のデータとして扱う.つまり,実 価は1日のデータの平均と考える. PAAで変換した後の実数値のデータはアルファベットの文 字列にエンコードされる.データが標準正規分布に従うとい う仮定のもとエンコードを行うので,文字列の各アルファベッ トが同一確率で出現する.アルファベットの文字数をアルファ ベットサイズと呼び,文字の分割点はアルファベットサイズご とに決めておくことができる.例えば,アルファベットサイズ が10のときの分割点はは(β1, β2, β3, β4, β5, β6, β7, β8, β9) = (−1.28, −0.84, −0.52, −0.25, 0, 0.25, 0.52, 0.84, 1.28)となる. Q = q1q2· · · qwとC = c1c2· · · cwを文字列にエンコード後 の時系列データとする.QとCの距離を求めるために,Leeら は式(9)の距離関数を定義している. dm(Q, C) = √ n w v u u t∑w i=1 (dist(qi, ci))2 (9) ただし,dict(q, c)は以下の通りの定義により計算される関数で ある. cellr,c= 0, |r − c| <= 1
βmax(r,c)−1− βmin(r,c), otherwise
(10) ただし,cellr,cは辞書順に並べたときのr番目とc番目のアル ファベット間の距離を表す.アルファベットサイズが10のとき を例にとって考えると,aとeの距離はdict(a, e) = cell1,5 = β4− β1=−0.25 − (−1.28) = 1.03となる. 関連度(rs(Q, C))を求める式は以下の式である.この値が0 に近いほど関連度が高いとする. rs(Q, C) = dm(Q, C) len(Q) (11) 4. 4. 3 相 関 係 数 相関係数は2つの変数データの相関の程度を示す数値であり, 統計学の相関分析の分野で広く用いられている.相関係数を求 める際に様々な手法があるが,本研究ではピアソンの積率相関 係数を用いる. 2つのデータ列をX = x1, x2,· · · , xnとY = y1, y2,· · · , yn とすると,ピアソンの積率相関係数rはX とY の共分散と XとY それぞれの標準偏差で求めることができる.相関係数 cor(X, Y )を求める式は式(12)のようになる. cor(X, Y ) = ∑n i=1(xi− X)(yi− Y ) √∑n i=1(xi− X)2 √∑n i=1(yi− Y )2 (12) ただし,X,Y はそれぞれX,Y の相加平均を表している. 関連度(rc(X, Y ))を求める式は以下の式である.この値 が1に近いほど関連度が高いと言える.lendata(X)はデー タX の個数を表している.以下lendata()は同様の定義と し て 扱 う.本 研 究 で は ,扱 う デ ー タ の 個 数 は 同 じ な の で , lendata(X) = lendata(Y )である. rc(X, Y ) = cor(X, Y ) lendata(X) (13) 4. 4. 4 偏相関係数 相関係数では2つの変数の相関を明らかにするものであるが, 2つの変数に影響を与える他の変数が存在する可能性を考慮し ていない.このような影響を与える変数が存在していて,本来 相関がないような2つの変数が相関があるような結果が出てし まうことを疑似相関といい,相関関係を調査する際に考慮すべ きものとなっている.偏相関係数は2つの変数の間に存在する 相関関係を求める際に,その他の影響を与えている変数の影響 を取り除いた相関の程度を示す数値である. 本研究で扱うデータである実価は時系列データなので,両方 が時間に関係している変数である.よって,2つの実価から時 間という変数の影響を除外した相関を求める.2つの実価をX,
Y,時間をT とおき,cor(X, Y ),cor(X, T ),cor(Y, T )をそ
れぞれ変数間の相関係数とすると,偏相関係数pcor(X, Y, T )
は式(14)で求められる.
pcor(X, Y, T ) = cor(X, Y )√ − (cor(X, T ) × cor(Y, T )) 1− cor(X, T )2√1− cor(Y, T )2
(14) 関 連 度 (rp(X, Y, T ))を 求 め る 式 は 以 下 の 式 で あ る .こ の 値 が 1 に 近 い ほ ど 関 連 度 が 高 い と 言 え る .こ の と き ,
lendata(X) = lendata(Y ) = lendata(T )である.
rp(X, Y, T ) = pcor(X, Y ) lendata(X) (15) 4. 5 ニュースイベントによる比較範囲の決定 企業同士の関連性は時間の経過とともに遷移する.企業間の 関係を調べるときに,対応する時間の範囲を決める必要がある. 時間の範囲を決定することにより,企業間の関係をダイナミッ クに捉え,データセットに用意されている全ての期間を比較す る必要がなくなるので計算量も小さくすることができる. 例えば,ある企業が他の企業に部品供給をしている場合を考 える.納品先の企業が部品供給する企業をコンペティション方 式で決めているとすると,コンペティションに勝利して部品供 給をしている間は企業同士の業績はリンクしており,関連度は 高くなると考えられるが,別の企業がコンペティションに勝利 してしまうと,その瞬間から部品供給が打ち切られるので関連 度が低くなってしまうと予想される. 企業の関係を調査するにあたって過去の企業同士の関係も重 要であるが,意思決定を行う際には今現在の関係性を考慮すべ きである.2節で述べたように,ニュースイベントは株価の上 昇下落を判断するうえで必要不可欠な材料であり,発生して株 価が大きく変動する可能性が高い.よって2015年12月30日 現在,一番最近発生したニュースイベントから現在までの範囲 を比較範囲とし,実価の比較を行うことで,最新の企業間同士 の関連度を抽出することができる. ニュース記事は収集できる最も過去のニュース記事が発表さ れた2010年9月14日以降のものとし,t = τのときにニュー スイベントが発生したとする.期間[τ, 2015/12/30]の間隔が十 分に大きければその時間帯に対応する実価データを比較するこ とで関連度を計算し,関連性の推移を測る.しかし,本研究で 用いる時系列データの比較手法はデータ数が少なすぎれば関連 度が大きいか全くなしかの二極化してしまうため,時系列デー タにある程度の長さがなければ関連度を導出することができな い.そこで,期間[τ, 2015/12/30]の間隔に使用するデータの 長さの最小値を設定しなければならない(注 7).本研究では,使 用するデータの長さの最小値として30日間と設定することに する.つまり,式(16)がいつでも成り立つものとする. (注7):最適な最小値を求める方法について今後検討する予定である. 表 3 評価実験における問合せ企業の一覧 企業名 企業コード 業種 市場 JT 2914 食料品 東証 1 部 セブン&アイ・ホールディン グス 3382 小売業 東証 1 部 武田薬品工業 4502 医薬品 東証 1 部 トヨタ自動車 7203 輸送用機器 東証 1 部 ホンダ 7267 輸送用機器 東証 1 部 キヤノン 7751 電気機器 東証 1 部 三菱 UFJ フィナンシャル・グ ループ 8306 銀行業 東証 1 部 みずほフィナンシャルグルー プ 8411 銀行業 東証 1 部 日本電信電話 9432 情報・通信 東証 1 部 NTT ドコモ 9437 情報・通信 東証 1 部 (2015/12/30− τ) + 1 >= 30 (16) この期間に起こったニュースイベントは現在の関連度に関する ニュースイベントとする.決定された比較範囲を用いて比較手 法を適応する.
5.
評 価 実 験
5. 1 実験の概要 株価の合成モデルおよびそれを用いた企業間の関係分析手法 を評価するための実験を行った.実験では,被験者が実際に調 べてつけた企業の関連度のランキングと提案手法によって導出 された企業の関連度のランキングを比べてnDCG(NormalizedDiscounted Cumulative Gain) [11]を計算する.被験者として
4人の大学(院)生に対し,10社の問合せ企業と提案手法でラ ンクインしたそれぞれの問合せ企業との関連の強い企業群を与 え,企業間の関係の強さを5段階評価してもらい,その結果に 基づいて提案手法と比較手法のnDCGの値をそれぞれ算出し た.関連度を求める際に使用する4つの手法で得られたランキ ングのnDCGを計算し比較を行う.次に,合成モデルを用い て株価調整を行った場合のランキングと調整を行わない場合の ランキング結果のnDCGを比較し,合成モデルの有用性につ いて考察する. 5. 2 データセット 評価実験において,問合せとなる対象企業を2016年1月18 日当時時価ランキングを元に上位10社とした.また,業種によ る違いも考慮するため,一つの業種に対して最大2社までとし, ニュースイベントが発生してから2015年12月30日のデータ が揃っていない企業は対象外とする.対象とする10社は表3 にまとめる.ニュース記事は2010年9月14日から2015年12 月30日までの財経新聞の記事を用いた. 5. 3 パラメータの設定 企業の実価データを文字列にエンコードする際に用いられる 文字数kの値(4. 4. 1節を参照)を決定する調査を行った.調査 では計算量の観点からも考えて,kの値をk = 10からk = 102
10 20 30 40 50 k 60 70 80 90 100 0.70 0.75 0.80 0.85 0.90 0.95 1.00 nD C G @ i 図 3 k の nDCG@30 までの間に存在するkの値を10刻みで変動させ,2016年1月 18日当時時価総額1位のトヨタ自動車(7203)を問合せの対象 企業として関連企業のランキング結果に基づいてkを選定した. kの値一つに対して4. 4. 1節で述べた手法を用いてランキン グを上位30件まで導出し,各kの値で導出された企業のOR をとって企業の和集合を作成する.ランキングの評価を行う際 にはnDCGを用いる.その企業の和集合に被験者一人が企業間 の業績の関係を5段階で評価した後,kの値ごとにnDCG@30 を計算し,nDCGの値が最大となったものをハミング距離での kの値として使用する.結果のグラフを図3に示す. 図3から,k = 80のときにnDCG最大となる.kの値が小 さい時はランキングに出てくる企業が変化していないことから, kの値はある程度大きい方がよいと思われる.今回の実験では, ハミング距離を用いる際にnDCGの値が最大だったk = 80と するが,最適なkの値を決める方法については今後検討してい く予定である. 5. 4 評 価 方 法 評価方法としては,まず,各関連度計算手法を用いて対象と する企業とその他の企業とのランキングの上位15件を求める. 次に,各手法で求められた企業群のORをとり,4手法のいず れかにランクインした企業の和集合を作成する.和集合に含ま れる企業と問合せとなる対象企業の業績の関係性が大きいと思 われるものから順に5点,4点,3点,2点,1点というように 5段階で4人の被験者に評価してもらった.人間が与えた関係 の強さのランキングと手法で計算されたランキングの各手法の nDCGを算出して比較することで,関連度の計算手法の精度を 比較する. nDCGの値は問合せとする対象企業10社の値の平均とする. また,その値が最も大きかった手法を使用し,合成モデルを用 いて株価調整を行った場合のランキングと調整を行わない場合 のランキングのnDCGを比較する.nDCGは上位5件,10件 と15件での値を考慮する. 5. 5 実 験 結 果 5. 5. 1 合成モデルとそれに基づく株価調整手法の評価 実価のnDCG@i(i = 5, 10, 15)の各値をプロットし,グラフ化 表 4 nDCG の平均値 ハミング距離 SAX 法 相関係数 偏相関係数 実価 0.865 0.857 0.902 0.903 株価 0.844 0.837 0.844 0.838 したものが図4である.調整前の株価のnDCG@i(i = 5, 10, 15) の各値をプロットし,グラフ化したものが図5である.横軸i が評価するランキングの長さ,縦軸がnDCG@iの値を表して いる.図4から文字列にエンコードし,文字列同士の距離を計 算する手法(ハミング距離,SAX法)より,文字列にエンコー ドすることなくデータ同士の相関係数を計算する手法(相関係 数,偏相関係数)が適していることがわかる. 図4と図5を比較して,nDCG@iのiの値が小さい時には nDCGの大きな差は見られないが,iの値が大きくなると図5 ではnDCGの値が急落しているのが見て取れる.このことか ら,nDCG@iのiの値を大きくすれば,調整を行っていない株 価データを比較するよりも,提案したモデルで比較を行った方 が企業の関連度をより正確に捉えられることが分かる. 図4と図5のnDCG@i(i = 5, 10, 15)の値の平均値をとった 値を表4にまとめる.表4より,相関係数よりも偏相関係数の 手法がより適していると言える.また,全ての手法において, 調整を行った実価のnDCGの平均値が調整していない株価の nDCGの平均値よりも大きくなっており,提案した株価モデル が効果的であるとわかる. 5. 5. 2 ニュースイベントを用いた比較範囲の選定手法の 評価 ニュースイベントによって比較する範囲を決定した場合の偏相 関係数のnDCG@i(i = 5, 10, 15)と比較する範囲を限定せずに 2010年9月14日以降の両企業の株価のデータが存在している範 囲全てで比較した場合の偏相関係数のnDCG@i(i = 5, 10, 15) を表したグラフが図6である.なお,実験で用いた企業の中に は比較範囲を広げると欠損値を含んでいる企業も存在したため, 株価データに2日連続で欠損値を含んでいる企業については比 較を行わないものとし,それ以外の株価データに欠損値を含ん でいる企業については,元の株価データをxi(i = 1, 2,· · · , n) とし,欠損値(xj)を以下の式(17)に基づいて補完した. xj= x2, j = 1 xn−1, j = n xj−1+ xj+1 2 , otherwise (17) 図6から,ニュースイベントを使い,範囲を限定して比較した 方が全期間を比較範囲としたときよりnDCG@iの値が大きい ことがわかる.このことから,ニュースイベントを活用するこ とで,計算量が減少するだけでなく,企業間の関係性として正 しいランキング順に並べることができると考えられる. 5. 6 議 論 この節では問合せの対象企業ごとの結果を調査する.表5は nDCG@15のときの結果である.
5 10 15 i 0.70 0.75 0.80 0.85 0.90 0.95 1.00 nD C G @ i 㴦㴶㵊㴇ڑ 4"9๏ ૬ؔ ภ૬ؔ 図 4 実価の nDCG@i 5 10 15 i 0.70 0.75 0.80 0.85 0.90 0.95 1.00 nD C G @ i 㴦㴶㵊㴇ڑ 4"9๏ ૬ؔ ภ૬ؔ 図 5 株価の nDCG@i 5 10 15 i 0.70 0.75 0.80 0.85 0.90 0.95 1.00 nD C G @ i 㴢㴼㱟㴐㳻㴰㵊㴟㳇㳤㳧ظؒ શظؒ 図 6 比較範囲ごとの nDCG@i の値 表 5 nDCG@15 企業コード ハミング距離 SAX 法 相関係数 偏相関係数 2914 0.872 0.847 0.830 0.834 3382 0.695 0.718 0.850 0.856 4502 0.868 0.798 0.806 0.804 7203 0.878 0.916 0.917 0.920 7267 0.847 0.856 0.894 0.894 7751 0.811 0.729 0.838 0.832 8306 0.804 0.819 0.866 0.867 8411 0.912 0.936 0.915 0.916 9432 0.772 0.798 0.776 0.806 9437 0.809 0.809 0.919 0.895 表5において相関係数と偏相関係数の値はかなり似通った値 となっている.これは実価という時系列データは時間に比例し て増えるなどといったデータではないため,時間の変数の影響 はほとんどないものと考えられる. nDCG@i(i = 5, 10, 15)の平均をとった結果としては偏相関 係数の値が一番高いが,企業によっては文字列にエンコード して文字列同士の距離を計算する手法が有用である企業もあ る.武田薬品工業(4502)はハミング距離のnDCG@15が最大 となっている.iの値にもよるが,ハミング距離やSAX法の nDCGiが高くなっている企業も存在する.よって,エンコー ド手法を改良して他の距離関数に基づく関連度の計算手法につ いて今後検討したい. 特に,編集距離では置換の他にも削除と挿入の操作を定義し ているので,時系列データのずれに対応することができる.本 研究では株価のデータとして終値を使用しているので1日のず れというのは大きいかもしれないが,株価データの粒度を大き くした時などはずれを考慮することによって,企業の業績推移 から関連企業への業績の推移が始まるまでのタイムラグの影響 を排除することができると考えられる.
6.
お わ り に
本研究では,株価の合成モデルとそれに基づく,株価とニュー ス報道を併用した企業の関係分析手法の提案を行っている.提 案手法は企業間の関連度の強さをランキング形式で明らかにし, 企業や個人投資家などの企業間ネットワーク分析の支援を行う 効果が期待できる. 評価実験において,上場企業10社の関連企業を提案手法で 算出する関連度でランキングし,nDCGの結果を用いて評価を 行った.実験結果から,株価の合成モデルによる株価の調整と ニュースイベントによる比較範囲の選定の有効性を確認した. また,ケーススタディの結果では,株価を文字列にエンコード して編集距離で関連度を計算することの可能性が示された. 今後,クラウドソーシングを用いた大規模な評価実験の実施, パラメータkの設定,比較範囲の最小値の決定,暗黙な関係発 見の評価や応用システムの構築について行う予定である.謝
辞
本研究の一部は,科研費(課題番号25700033)とSCAT研究 費助成による. 文 献 [1] 山倉健嗣: 組織間関係と組織間関係論, 横浜経営研究, Vol. 16, No. 2, pp. 166–178 (1995). [2] 金英子, 松尾豊, 石塚満: Web 上の情報を用いた企業間関係の抽 出, 人工知能学会論文誌, Vol. 22, pp. 48–57 (2007).[3] Woo, K., Ennew, C. T.: Business‐to‐business relationship quality: An IMP interaction‐based conceptualization and measurement, European Journal of Marketing, Vol. 38, pp. 1252–1271 (2004).
[4] Rauyruen, P. and Miller, K. E.: Relationship quality as a predictor of B2B customer loyalty, Journal of business re-search, Vol. 60, No. 1, pp. 21–31 (2007).
[5] Hanke, M. and Kirchler, M.: Football championships and jersey sponsors’ stock prices: an empirical investigation, The European Journal of Finance, Vol. 19, pp. 228–241 (2012).
[6] Ramezani, A., Mardani, H., Emamgholipour, M. and Mar-dani, S.: The Effect of the Results of Football Champions League Games on Sponsors’ Stock Prices: Evidence from Iran, World Applied Sciences Journal , Vol. 20, pp. 102–106 (2012).
[7] Tetlock, P. C.: Giving Content to Investor Sentiment: The Role of Media in the Stock Market, The Journal of Finance, Vol. 62, pp. 1139–1168 (2007).
[8] Bollen, J., Mao, H. and Zeng, X.: Twitter mood predicts the stock market, Journal of Computational Science, Vol. 2, pp. 1–8 (2011).
[9] 有田帝馬: 入門 季節調整, 東洋経済新報社 (2012).
[10] Lin, J., Keogh, E., Lonardi, S. and Chiu, B.: A Sym-bolic Representation of Time Series, with Implications for Streaming Algorithms, DMKD ’03 , pp. 2–11 (2003). [11] J¨arvelin, K. and Kek¨al¨ainen, J.: Cumulated gain-based
evaluation of IR techniques, ACM TOIS , Vol. 20, No. 4, pp. 422–446 (2002).