並列事前実行における再利用バッファの高速化
6
0
0
全文
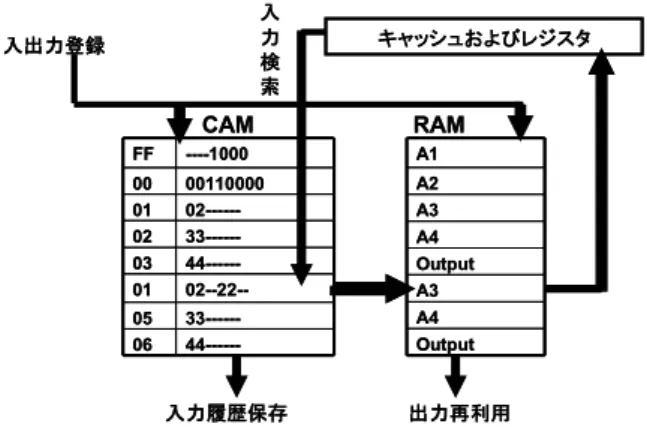
(2) 図 4 再利用バッファの操作. 図2. 再利用の仕組み. 図3. 入出力の木構造. が不可欠である.本稿は,再利用バッファの高速化につい て述べる.. 2. 並列事前実行 本章では,再利用を用いた非対称の SpMT である並列 事前実行について述べる. 2.1 並列事前実行機構 並列事前実行機構の概要を図 1 に示す.Main Stream Processor(以下,MSP)は,通常実行を行うプロセッサ であり,可能である場合は命令区間の再利用を行うことが できる.一方,複数の Shadow Stream Processor(SSP) は,MSP と並行して投機的実行を行う.演算器,レジス タ,一次キャッシュは,各プロセッサごとに独立しており, 再利用バッファ,二次キャッシュ,及び主記憶は全プロセッ サで共有される.MSP は,常に通常実行のみを行い,SSP. −28− 2. は常に投機実行のみを行う.Region Table は,MSP で実 行された入力の履歴から,ストライド予測により入力を予 測する.そして SSP は予測された入力を用いて命令区間 (関数及びループ)の実行を MSP に先がけて行い,結果 を再利用バッファに登録する.入力の予測が正しかった場 合,MSP により通常実行が行われる時点では,命令区間 は既に SSP により実行済であり,結果が再利用バッファ に登録されているため,再利用手法により高速化を図るこ とができる. 2.2 再利用バッファの操作 区間再利用とは,関数呼出しやループなどの命令区間に おいて,入力と出力の組を記憶しておき,再び同じ入力に よりその命令区間が実行されようとした場合に,過去の出 力を利用することで,命令区間の実行自体を省略する手法 である. 区間再利用の仕組みは図 2 のように,命令区間 を検出すると再利用バッファで一致パターンがあるかどう かを検索する.一致パターンがなければ,本命令区間を実 行し入力パターンが再利用バッファに保存される;一致パ ターンがあれば,記憶しておいた結果を一次キャッシュー に書き戻す. 再利用バッファに要求される機能は,登録 (Search & Write) 及び検索 (Search & Read) である.図 3 に示す命 令区間の場合を検討する.命令区間の先頭アドレスが 1000 であるとすると,命令 2 はアドレス A1 からロードした 4Byte データ 00110000 をレジスタ R1 に格納する.この 場合,アドレス A1 及びデータ 00110000 が入力,レジス タ番号 R1 及びデータ 00110000 が出力となる.命令 4 で は,A2 及び 02 が入力,R2 及び 02 が出力となる.以上の ように入出力を確認し,当該命令区間の実行が完了すると, 入力値を枝とし,次入力のレジスタ番号や主記憶アドレス をノードとする木構造として図 4 に示すようにそれぞれ CAM と RAM に登録する.登録操作では CAM から空き エントリを検出する機能 (Search Free Entry) が必要で ある.後続の命令区間を実行する前に,再利用できるかど うかを判断するために入力値を比較する.図 3 に示す命令 区間の場合に,まず命令区間の先頭アドレス 00001000 を CAM で検索し,あれば当該行に対応する RAM に格納し.
(3) ている次入力のアドレス A1 によって,次入力値 00110000 を CAM で検索する.このように入力パターンを最後まで 繰り返し比較し,当該命令区間の全ての入力が CAM に格 納している入力パターンと同じであれば,RAM に登録し ている出力をレジスタ及びキャッシュに書き込み,当該命 令区間の実行を省略することができる.図 4 に示す再利用 バッファは,連想メモリ (CAM) と通常メモリ (RAM) に より構成される連想検索装置であり,ブロック化が可能で あれば,省電力化や高速化により,並列事前実行の効果を 向上させることができる.. 3. 再利用バッファのブロック化 本章では,再利用バッファのブロック化について述べる. 連想検索装置 (CAM) の設計により,ブロックごとにエン トリ数が多ければ多くほどアクセス時間が長くなる.同時 に,再利用バッファ全体へのアクセスに比べ,より小さい ブロックへのアクセスする場合は消費電力が少なくなる. そのため再利用バッファのブロック化が必要となる.再利 用バッファのブロック化により,連想検索装置の高速動作 および低電力化を図る.我々は 1K エントリの再利用バッ ファを 16 ブロックと設定し,ブロックごとに 64 エント リーとす,三つの分割方法の評価により,ブロック化しな い結果に比べ再利用のサイクル数がほぼ同じようになった. 同時にいくつかの問題ともなる.一つ目は,どうすれば事 前条件により,再利用データを特定のブロックに対応でき る.二つ目は再利用データを平均的に各ブロックに分散し, 再利用率を下がらないようにする. 3.1 再利用バッファの分割手法 a:命令区間の先頭アドレスに基づいて分割する.図 5(a) に示すように,命令区間の先頭アドレス中の何ビットを Block Number として利用し,再利用データの登録及び検 索がそれに対応するブロックで行われる.16 分割の場合 に命令区間の先頭アドレスの 4∼7 ビットを使って 16 分割 する.この分割方式の特徴は,同じ命令区間の再利用デー タが同じブロックに集中し,大量の引数が少ない命令区間 が含まれるプログラムに適応できることになる. b:引数の順番に基づいて分割する.図 5(b) に示すよう に,再利用区間が登録される時,引数の順番により順番 ID を付ける.順番 ID に基づいて再利用データがそれぞれの ブロックに分散される.b 方式の特徴は,同一命令区間の データ列を各ブロックに分散できる.大量の引数が少ない 命令区間が含まれるプログラムには大きい番号に対応する ブロックの利用率が低くなる.逆に,長い木に対して効果 だと考えられる. c:先頭アドレスと順番を合わせる分割する図 5(c) に示 すように,先頭アドレス中の何ビットと順番 ID を OR 演 算し,結果をブロック番号として利用する.c方式の特徴 は,引数の数と命令区間の数に関わらず再利用データが分 散できるため,a 方式及び b 方式の長所を生かせる. 3.2 予 備 評 価 区間再利用プロセッサソフトウェアシミュレータを用い, Stanford ベンチマークの実行ステップ数を実測した.図 6. −29− 3. 図 5 先頭アドレスによる分割. は 1KB の再利用バッファを 16 分割した結果である.縦 軸は再利用を行うおよび行わない時のサイクル数の比率で ある.横軸は,分割しない,先頭アドレスによる分割,引 数順番による分割,先頭アドレスと順番合わせる分割に対 応する.引数順番による分割及び先頭アドレスと引数順番 による分割は分割しない結果に比べ,ほぼ同じようになっ た.分割しても再利用性能が悪くならないことが分かった.. 4. 専用連想検索装置 以上の結果とふまえて,64 エントリの連想検索装置を 考える. 4.1 汎用 CAM を使う場合の問題点 通常の連想検索装置 (図 7(a)) では,連想メモリに検索 を行わせた結果,複数のマッチラインがアサートされ得る ために,アサートされたマッチラインのうち唯一のマッチ アドレスを出力するためのプライオリティエンコーダを設 け,最優先ラインに対応するマッチアドレスのみを生成す る.その後,改めて当該マッチアドレスを用いて通常メモ リを参照する構成とすることにより,連想検索装置全体に おけるマッチアドレスの競合を防止する.しかし,プライ.
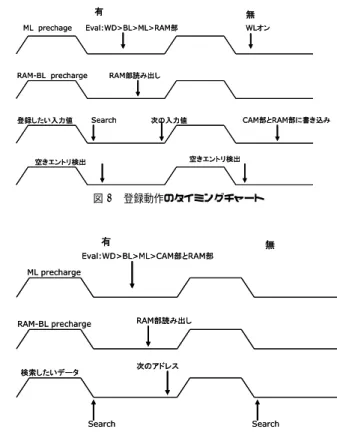
(4) 図 8 登録動作のタイミングチャート 図 6 16 分割の評価. 図 9 検索動作のタイミングチャート. 図 7 連想検索装置. オリティエンコーダは,マッチライン数の増加とともに遅 延時間が増大する.このため,深い連想メモリ,すなわち, 多くのマッチラインを有する連想メモリを構成する際には, プライオリティエンコーダがボトルネックとなり,高速化 が困難となる.プライオリティエンコーダ自身の消費電力 も問題となる.また,検索の結果一致した連想メモリの内 容を読み出す際には,改めて読み出しサイクルを設けるた め,多くのサイクルが必要となり,性能低下を招く.. −30− 4. 4.2 専用連想検索装置の構成 汎用 CAM を使った場合の問題点を解消するために,専 用連想検索装置 (図 7(b)) ではプライオリティエンコーダ を省略する.指定した書き込みデータが登録済であれば登 録せず,未登録であれば空きエントリに対して高速に登録 し,唯一のマッチラインがアサートされることを保証する. また,検索の結果,一致した連想メモリの内容を読み出す 機能は,連想メモリを直接読み出す代わりに,連想メモリ にセットしたマスクビットパターンを通常メモリ内に重複 して設け,通常メモリが読み出される際に当該マスクビッ トパターンを同時に読み出し,さらに,検索データ自身と 組み合わせることにより,間接的に連想メモリの内容を読 み出すことで実現する.専用連想検索装置は,CAM 部, 制御部,空きエントリ検出回路,RAM 部からなっている. 検索データは CAM 部 に与えられ,検索結果が MATCH 信号により制御部に入力される.同時に,空検出回路から CAM に空きエントリが1つ選択される.制御部は以上の 情報に基づいて,検索データに一致するエントリが存在す る場合には RAM 部に対して Read 動作を指示し,存在し ない場合には,CAM 部及び RAM 部に対して Write 動作 を指示する.専用連想検索装置では,登録動作あるいは検 索動作が 1 サイクル内に実現することを目標とする. 4.3 専用連想検索装置に求められる動作 図 8 は,入力パターンを連想検索装置に登録するタイ ミングチャートである.サイクルの前半では,CAM 部の.
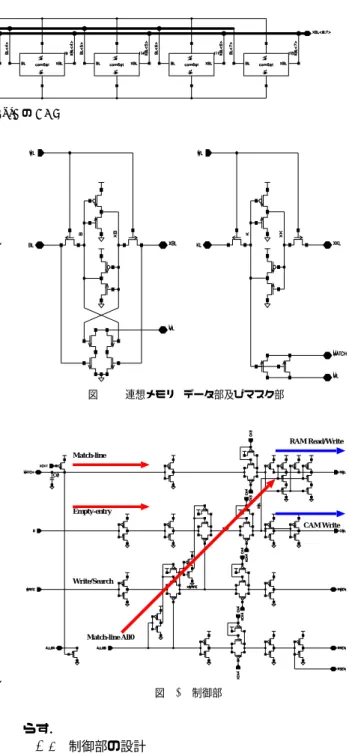
(5) 図 10. 1Byte の CAM. 全 Match-line(ML) を 1 にプリチャージし,同時に RAM 部の Bit-line(BL) もプリチャージすることにする.また, 未登録であることが判明した際の空きエントリを 1 つ探 し,CAM と RAM に書き込める空きエントリを事前に準 備しなければならない.サイクルの後半では,登録したい 入力値を CAM で比較する.既登録であれば Match-line を経て RAM 部に格納してる次入力のアドレスを読み出 す.次エントリの内容と比較して検証を行う.未登録であ れば全 Match-line が 0 となるので,これを検知して,あ らかじめ探しておいた空きエントリの Word-line(WL) を オンにし,当該空きエントリに入力を書き込むことにす る.図 9 は,連想検索装置の検索及び読み出し動作に関わ るタイミングチャートである.サイクルの前半では CAM 部の連想検索に備えて,全 Match-line を 1 にプリチャー ジする.また,RAM 部の読み出しに備えて,RAM 部の Bit-line を 1 にプリチャージすることにする.サイクルの 後半では,検索したい現レジスタ等の内容が既登録であれ ば Match-line から MATCH 信号を経て RAM 部に格納 している次入力アドレスを読み出す.また入力を予測する ために,CAM 部の内容を履歴として読みす必要がある. RAM 部には CAM 部のマスクビットパターンを格納して おり,検索したい現レジスタ等の内容と合わせて,CAM 部の直接読み出しに替えることにする.未登録であれば全 MATCH が 0 となるので,これを検知し,検索を終了す ることにする. 4.4 CAM の設計 1Byte の CAM ごとに 1bit のマスクビットを設け (図 10),当該 Byte を比較対象とするかどうかを判断す る.マスクビットが 1 であればマスク部の Match-line が データ部の Match-line と繋がり,当該 Byte のデータを比 較する.マスクビットが 0 であればマスク部の Match-line はデータ部の Match-line と繋がらず,当該 Byte は比較 しない.図 11 が,CAM のデータ部とマスク部である. CAM Cell は 10 個のトラジスタから構成される.正負 1 組の Bit-line は書き込みデータを伝える Bit-line と検索 データを伝える Bit-line を兼ねる.検索データを比較する 時,まず Match-line を 1 にプリチャージし,検索データ を BL 及び XBL 上に置く.もし,Search DATA と合わ ないデータをもつセルが存在する場合には,Match-line を 0 に引き下げる.CAM の幅は 16Byte であり,検索を高 速化するために長い Match-line を分割し,遅延時間を減. −31− 5. 図 11. 連想メモリ (データ部及びマスク部). RAM Read/Write Match-line. Empty-entry CAM Write. Write/Search. Match-line All0. 図 12 制御部. らす. 4.5 制御部の設計 図 12 は,制御部の各行ごとの構成である.登録動作の場 合には 1,検索動作の場合には 0 となる Write/Search 信号, CAM 部からの MATCH 信号,及び空きエントリ (Emptyentry) を検出する D 信号から,RAM 部の Word-line を駆 動する RWL と,CAM 部の Word-line を駆動する CWL を生成している.RWEN,RREN,RSEN は,各々,RAM.
(6) ている CAM 及び RAM は,各々1KB であり,動作ク ロックは 1.6ns である.Cycle0(Search & Found) では, Write/Search 信号が1となり,当該サイクルが登録サイ クル (Search & Write) である.CAM 部の全 Match-line が,1 にプリチャージされ,同時に RAM 部の Bit-line もプリチャージする.CAM の 0 行目の Match-line が アサ―トされるため,入力値が既登録であることを検知 している.Cycle1(Search & Not-Found & Write) では, CAM の Match-line が1つもマッチしないため,ALL0 信号が1となり,あらかじめ探しておいた空きエントリ (CAM の 1 行目) に関する CAM 及び RAM の WordLine(CWL/RWL) をオンにし,センスアンプの WRITEENABLE 信号(CWEN 及び RWEN)もオンにし,入力 データを CAM の 1 行目に登録している.Cycle2(Search & Found & Read) では,Write/Search 信号が 0 となるの で,検索動作になる.検索したい入力値が,CAM の 2 行 目に既登録であることを検知し,2 行目の Match-line に対 応する RAM 及び CAM の Word-line をオンにし,次入力 のアドレスを読み出し,同時に間接的に CAM の内容を読 み出し,履歴として履歴表 (Region Table) に登録してい る.Cycle3(Search & Found) では,検索データが CAM に未登録であることを検知し,検索を終了している.以上 のシミュレーションの結果により,動作クロックが 1.6ns である場合に,連想検索装置が正しく動作することを確認 した.1KB ブロックの再利用バッファの平均電流は 5mA で,電力は 9mW であった.. Voltages Voltages (lin) Voltages (lin) Voltages (lin) Voltages (lin) Voltages (lin) Voltages (lin) Voltages (lin) Voltages (lin) Voltages (lin) Voltages (lin) Voltages (lin) Voltages (lin) Voltages (lin) Voltages (lin) Voltages (lin) (lin). 表 1 CAM の性能評価(測定環境温度:85 ℃) Table 1 Speed of CAM. Read Write Search. 32x128bit 0.3ns 0.31ns 0.39ns. cycle0. cycle1. 64x128bit 0.38ns 0.33ns 0.39ns. Panel 1 1.5 1 500m 0. cycle2. cycle3. 1.5 1 500m 0 1.5 1 500m 0 1.5 1 500m 0 1.5 1 500m 0. Search&Write. 1.5 1 500m 0. Search&Read. #0-Match. 1.5 1 500m 0 1.5 1 500m 0. #2-Match Found. 1.5 1 500m 0. Not-found. Found. Not-found. RAM#0-WL(R). 1.5 1 500m 0. RAM#1-WL(W). 1.5 1 500m 0. RAM#2-WL(R). 1.5 1 500m 0. CAM#1-WL(W). 1.5 1 500m 0. RAM-writeEN. 1.5 1 500m 0. RAM-readEN. 1.5 1 500m 0. RAM-senseEN. 1.5 500m1 0 0. 1n. 2n. 3n 4n Time (lin) (TIME). 図 13. 全体の評価. 5n. 6n. 6. お わ り に. の Write enable 信号,Read enable 信号,Sense enable 信号である.Match-line の全てが 0 である場合,検索が 失敗するため,書き込み動作を行う必要があり,このため に全ての Match-line が 0 であるかどうかを示す ALL0 信 号を作る.1つもマッチしない場合には ALL0 信号が1 となることを受けて,あらかじめ探しておいた空きエン トリに関する CAM および RAM の WL(CWL/RWL) を オンにし,当該空きエントリに登録データを書き込むこ とができる.同時に,書き込みデータを CAM/RAM 内 の Bit-line に伝えるために,ALL0 信号を受けてセンスア ンプの WRITE-ENABLE 信号(CWEN および RWEN) をオンにする.. 5. 評. 価. 本章では,64 エントリの連想検索装置 (16 分割) の動作 シミュレーションについて述べる.富士通の 0.18um ルー ルを用い,Synopsys 社の Hspice を用いて評価を行った. 幅が 128bit である CAM の検索は,最悪の場合(1bit の み mis-match)に 0.39ns で検索動作が完了できる.CAM の性能評価は表1のとおりである. 図 13 に示すように,専用連想検索装置の四つの動作 サイクルを Hspice を用いてシミュレートした.設定し. −32− 6. 本稿では,並列事前実行機構に必要となる再利用バッファ の高速化及び評価した.本手法では,従来の再利用バッファ をブロック化し,専用連想検索装置を設計した.汎用連想 検索装置のプライオリティエンコーダを省略し,また,デー タ検索時の CAM からの読み出しを不要とし,再利用バッ ファの高速化動作を可能とした.評価の結果,全体の連想 検索装置動作クロックは 1.6ns であり,1KB ブロックの再 利用バッファの平均電流は 5mA で,電力は 9mW であっ た.このように,従来多くのサイクルが必要であった登録 及び検索動作を 1 サイクル内に実現でき,連想検索装置の 小型化,高速化及び省電力化が可能となった. 謝辞 お世話になった富士通 LSI 事業本部久保田勝久氏 に心から感謝します.. 参. 考. 文. 献. 1) 中島康彦, 津邑公暁, 五島正裕, 森眞一郎, 富田眞治:動的 命令解析に基づく多重再利用および並列事前実行,情報処理 学会論文誌コンピューティングシステム, Vol. 44, No. SIG 10(ACS 2), pp.1-16 (2003). 2) 津邑公暁, 中島康彦, 五島正裕, 森眞一郎, 富田眞治: 並列 事前実行機構における主記憶値テストの高速化, 情報処理学 会論文誌:コンピューティングシステム, Vol. 45, No. SIG 1(ACS 4), pp.31-42 (2004)..
(7)
図

関連したドキュメント
点から見たときに、 債務者に、 複数債権者の有する債権額を考慮することなく弁済することを可能にしているものとしては、
① 新株予約権行使時にお いて、当社または当社 子会社の取締役または 従業員その他これに準 ずる地位にあることを
手動のレバーを押して津波がどのようにして起きるかを観察 することができます。シミュレーターの前には、 「地図で見る日本
本判決が不合理だとした事実関係の︱つに原因となった暴行を裏づける診断書ないし患部写真の欠落がある︒この
QRされた .ino ファイルを Arduino にき1む ことで、 GUI |}した +どおりに Arduino を/((スタンドアローン})させるこ とができます。. 1)
この設備によって、常時監視を 1~3 号機の全てに対して実施する計画である。連続監
前ページに示した CO 2 実質ゼロの持続可能なプラスチッ ク利用の姿を 2050 年までに実現することを目指して、これ
また、同制度と RCEP 協定税率を同時に利用すること、すなわち同制 度に基づく減税計算における関税額の算出に際して、 RCEP
