社会のグローバル化とともに, 多国間での情報流 通は急速に増大している. それに伴い, 機械翻訳に 対するニーズもますます高まっている. 中でも共通 語としての英語の重要性は言うまでもない. 日英機 械翻訳の研究は今日まで長年に渡って行われてきた が, 現時点でもなお翻訳サイトや翻訳ソフトが出力 する文章の訳質は十分であるとは言い難い. 正確な
訳質を得るためには, 辞書の語彙を十分にした上で 文の意味を正しく認識することが必要である.
日本語文の文末構造は, 述語に後接して, 時制, 判断, 否定, 話し手の態度など, 広義の様相情報を 与える助動詞, 終助詞およびそれらに相当する連語 がいくつか接続した形になっており, この文末構造 を的確に訳出するシステムは少ないようである.
本論文では日本語述部の日英翻訳システムの枠組 みについて述べる. 本論文の構成は以下の通りであ る. まず第2章で, 日本語述部の構造, 助述表現に 付加した意味関数について述べる. 次に第3章では 市販されている現在の日英翻訳システムの性能につ いて考察する. 第4章から第5章にかけ, 構築した
意味構造を介した日本語文末表現の英訳*
田 辺 利 文**
田 中 喜 子***
吉 村 賢 治****
首 藤 公 昭****
Generally, the meaning of a sentence consists of
( )
propositional contents and( )
non- propositional contents. Not only the propositional contents but also the non-propositional contents play a critical role in various NLP applications.In this paper, we introduce an experimental machine translation system, whose input is a Japanese sen- tence-final predicative parts and whose output is its English surface forms. The system recognizes non- propositional semantic structure of input predicative parts as a pivot language in the translation process.
Key Words: Natural Language Processing, Multiword Expression, Modality, Machine Translation, Non- Propositional Contents
On the Translation from Japanese Sentence-Final Predicative Parts into English Expressions
Toshifumi T
ANABE, Yoshiko T
ANAKA, Kenji Y
OSHIMURAand Kosho S
HUDO1 はじめに
*平成20年6月10日受付
**電子情報工学科
***㈱電通国際情報サービス
****工学研究科情報・制御システム工学専攻
システムと実験について概説し, 第6章でまとめと 今後の課題を論じる.
2. 日本語述部とNPS
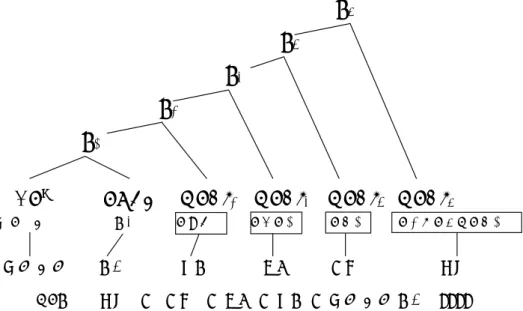
日本語は, 一般的に図1に示す構造をしていると 考えられる.
一般的に自然語文は, 命題的内容(Propositional
Content; PC) と 非 命 題 的 内 容 (Non-Propositional Content; NPC)の2つを示している場合が多く, 日本語の場合には, 命題的内容を表わす部分に, 非命 題的内容を表わす部分が後接しているものと考える ことができる. 非命題的内容を表わす部分は, 述語 に後接した, 時制, 判断, 否定, 話し手の態度など, 広義の様相情報を与える助動詞, 終助詞およびそれ らに相当する連語により構成される. 図1に典型的 な日本語文末の構造を示す. 図1において,
BP*は文節の連接,
PREDは述語, 記号 「・」 は通常の単 語境界を表し, また 「
/は意味の観点で分割した単 語境界を表わす. これらの, 述語に後接する, 意味 の 観 点 で 分 割 し た 単 語 ま た は 連 語 (Multiword
Expression; MWE)を 我 々 は 助 述 表 現 (Non-
Proposional Content Indicator; NPCI)と呼ぶが, 助述表現の適切な認識が自然言語処理における意味処 理の質の向上のために必要であると考えている. 図 1の
NPCIiは助述表現を表わしている. これまで 著者らの研究室では, 約1500種の助述表現を辞書と
して収集, 整理し, 助述表現に関する様々な研究発 表を行ってきた (首藤ら, 1977, 田辺ら, 2001,
Tanabe et al.,2001,
Shudo et al.,2004, 田辺ら, 2006). 助述表現には図1に示されている 「始める」
「ている」 「ない」 「かもしれない」 の他, 「たことが ある」 「できる」 「なければならない」 「らしい」 「た ほうがよい」 「べきである」 「おそれがある」 などが ある.
各々の助述表現には意味関数 (Non-propositional
primitive function; NPF) を付加している. 助述表現と意味関数の対応の例を表1に示す. 現在意味関 数は139種設定しており, 意味関数間の関係は浅い 木構造で整理している. 木構造における葉ノード (leaf node) が意味関数に対応している.
NPS
(Non-Propositional semantic Structure) は 次 式のような入れ子型で表すことが出来る.
但し, は命題的な骨格文 (命題的内容を表わす 部分), は助述表現が与える意味関数
図1 「彼は動き始めていないかもしれない」 に対するNPSの例
ᙼ ࣭ ࡣ / ືࡁ / ࣭ጞࡵ / ࣭࡚࣭࠸ /࣭࡞࠸ / ࣭ࡶ࣭ࡋࢀ࣭࡞࠸
ᙼ࣭ࡣ࣭ ືࡃ ㉳ື ྰᐃ ᥎㔞 NPS ᥎㔞 [ ྰᐃ [ [ ㉳ື [ ᙼ࣭ࡣ࣭ືࡃ ] ] ] ]
S
4S
3S
2S
1PRED S
0BP
㸨NPCI
1NPCI
2NPCI
3NPCI
4表 1 助述表現に対する意味関数の例
助 述 表 現 意味関数
の、 か、 のか、 のかな、 のかなあ、 かね、
のですか、 なのか、 ものか… 疑問1
ない、 ぬ、 ません、 … 否定1
おわろうとしている、 … 終了直前
はじめる 起動
である. 助述表現が文の述部にいくつも並んだ複雑 な文末表現の場合でも, 意味関数との対応をとるこ とにより
NPSを求めることが可能である.
NPSは, 構造のシンプルさと同時に対応可能な表現の多様さ から工学的に重要な性質
1)を持っていると考えられ, さらに言語依存性も無いとされるため, 言い換えや 機械翻訳を行う際の中間表現として有効であると考 えられる.
3. 市販の日英翻訳システムの性能
現在の翻訳システムがどれだけ助述表現を正しく 認識できるかを判定するため, 市販されている翻訳 ソフト4種(A,B,C,D)を用いて予備的に日英翻訳 実験を行い出力された英訳を人手で評価した
2).
EDR日本語コーパス(EDR, 1996)のうち述語に助述 表現が1つ以上後接した1000文を無作為に抽出し, 文末のみを翻訳ソフトへの入力として用いた. また,
NPS中の意味関数の個数ごとに結果を分類した.
正誤判定には3人の評価者のうち2人以上が正解と みなした場合には正解, それ以外は不正解とみなし た
3). 性能評価結果を表2に示す
4).
これらの翻訳ソフトの結果の一部を以下に示す.
まず例文1として 「まねているんだ」 を入力とした 場合には,
市販翻訳ソフトA ⇒
It mimics it.市販翻訳ソフトB,C,D⇒
I imitate it.と翻訳された英文叙述形が正しく出力されていると 思われる. しかし, 例文2 「まねているんだな」 を 入力とした場合には,
市販翻訳ソフトA ⇒
Do not mimic it.市販翻訳ソフトB,C,D⇒
It is imitating and it is “RUNDANA”.
と出力される. 例文1 「まねているんだ」 と例文2
「まねているんだな」 の意味はほとんど同じである が, 例文2の出力翻訳結果はいずれの翻訳ソフトも 誤りとなった. 誤訳の原因としては, 「な」 が詠嘆 を表す助述表現であることが認識されず,
Aでは命 令を表わす単語として誤って認識されており,
B・C・D
では 「るんだな」 が認識できないなど辞書に おける単語の網羅性の欠陥が見える. また, 概して,
NPS中の意味関数の個数が増えるほど性能が低下 していることが分かる.
4. 構築したシステム
4.1. 構築したシステムの位置づけ
現 在 の 翻 訳 シ ス テ ム は , 統 計 ベ ー ス 方 式 (Statistical Machine Translation; SMT) , 用 例 ベ ー ス方式(Example-based Machine Translation; EBMT), ルールベース方式(Rule-based Machine Translation;
RBMT)に大別される. 統計ベース方式および用例
ベース方式は, 対訳コーパスに挙げられるような原 言語と目的言語のペア (用例) を大量に蓄積し翻訳 を行う方式である. いずれも高性能の出力結果を得 るためには必然的に大量の用例が必要となり, 実用 化されているものは少数のようである . 一方ルー ルベース方式は, トランスファー方式と中間言語方 式に大別される. トランスファー方式は, 形態素解 析, 構文解析, 意味解析からなる解析ステップ, 変 換ステップ, 生成ステップを持つ. トランスファー 方式では, 市販の日英・英日翻訳システムでは多く 採用されているが, 翻訳システムが扱う対象の言語 数を
nとした場合
n*(n−1)種類の変換ステップを必要とするデメリットがある. 一方, 中間言語方式 は, 翻訳システムが扱う対象の言語数を
nとした場 合2n 種類の変換ステップで済み, 翻訳システムが 扱う対象の言語数が増えるほど, 必要とする変換ス テップ数において, 中間言語方式を採用するメリッ トが大きくなる. ただし, 中間言語方式では, 中間 言語の仕様は言語に依存するため, 中間言語の仕様 をどのように決めるかが問題である.
日本語述部の英訳において,
NPSに言語依存性 がないと考えられること, 意味関数の種類が139種 類と多いこと,
NPSが容易に生成できること, 及 び,
NPSから英文叙述形が容易に生成できること
表 2 性能評価結果市販翻訳ソフト 意味関数の個数
A B・C・D
正解 不正解 正解 不正解 1 586 153 551 188
2 146 75 142 79
3 16 16 16 16
4 5 3 2 6
全体 753 247 711 286
から,
NPSは中間言語方式における中間表現とし て好都合である. 構築したシステムは
NPSを中間 言語とみなした機械翻訳システムと位置づけること ができる.
4.2. 構築したシステムの動作
構築した日本語述部の英訳システムの動作につい て述べる. システムへの入力は日本語述部を仮定す る. 助述表現から意味関数への変換においては, 表 1に示すように, 助述表現 「のかなあ」, 「ません」,
「はじめる」 は, それぞれ意味関数 「疑問1」, 「否 定1」, 「起動」 が対応する. システムは, 日本語述 部から
NPSを作成し, 作成された
NPSから変換規 則を適用し英訳を出力する.
4.2.1. NPSの作成
NPS
の作成手順は, 概略以下の通りである
6).
①入力文を拡張文節で分かち書き (形態素解析) する(首藤ら, 1979, 添島ら, 2003).
②述部内の助述表現を対応する意味関数に変換し, 述語を基本形にする.
(③意味関数の並びの順序を逆にする.)
例えば, 「彼は戻らざるを得ないでしょう」 の場 合には, 次のように
NPSを作成する.
①彼は
/戻ら
/ざるを得ない
/でしょう
②彼は戻る
/必要性7
/推量3
③推量3 [必要性7 [“彼は戻る”] ]
つまり, 日本語においては, 適切に助述表現を意 味関数に変換することで
NPSを得ることができる.
日本語述部から
NPSを生成する実験は(Shudo et
al.,2004)で述べられており, 再現率約0.90, 適合率 約0.38が得られている.
4.2.2. 変換規則
次に,
NPS中の各々の意味関数に対し, 「変換規 則」 を適用し, 英訳を得る. 変換規則とは, 例えば, 意味関数が 「過去時制」 であるときは 「訳語動詞を 過去形に変換」 また, 「進行中」 は 「動詞を現在分 詞形にし, その前方に
be動詞を挿入する」 という 規則をいい, 各々の意味関数に対応した変換規則を 作成した. 意味関数に対する変換規則は1個とは限 らない. 例えば, 意味関数が“必要性[X]”である場 合には,
“have to X”及び“must X”の2種類の変換規則を対応させている. 作成した変換規則は279個
であり, 意味関数は139種であることから, 意味関 数1個あたりの変換規則数は平均約2.0個である.
4.2.3. 変換過程
変換過程は次のようになる. 例えば, 日本語述部
「 行かなければならなかった 」 の場合の
NPSは過 去 [ 必要性 [ 行く ] ] となる. 先ず, 格文の述 語 「行く」 を 「go」 に英訳し, 次に 「必要性」, 「過 去」 の変換規則を順次適用する.
過去 [必要性 [go]]
=過去 [have to go]
=had to go
この変換過程で, 日本語述部に対応した英訳「had
to go」 が得られる. しかし, 過去 [ 必要性 [ 行く ] ] には, 次のような変換も考えられる.
過去 [必要性 [go]]
=過去 [must go]
=φ
ここでφは変換が存在しないことを表す. 助動詞
mustには過去形が存在しないので変換は不可能で あり, 英訳は出力されない. 変換過程においては意 味関数に対する変換規則を全て適用・変換し, 妥当 な全ての英訳を出力する.
5. 実験
5.1 実験手法
EDR
日本語コーパスから, 述語に助述表現が1 つ以上後接した文末表現を無作為に2969個抽出し, これらを学習データとみなして人手で変換規則を作 成した.
次に
EDR日本語コーパス中から, 述語に助述表 現が1つ以上後接した文末表現であり, かつ, 学習 データ用の2969文とは異なる959個を無作為に抽出 し英訳を行い, 市販の日英翻訳ソフトが出力する英 訳と比較する. 比較に際しては,
NPS中の意味関 数の個数ごとに適合率, 再現率を用いる
7). 今回は 客観的に評価を行うため, 英訳出力の正誤判定は英 語に精通した評価者が行う.
5.2. 実験結果
実験結果を表3に示す.
5.3. 考察
市販翻訳ソフトの英訳結果を見ると, 予備的実験
と同様に,
NPS中の意味関数の個数が増えるほど 性能が低下していることが読み取れる. それに対し, 構築したシステムの再現率には大きな低下は見られ ず, 特に意味関数を4個含むような日本語述部に対 する英訳の再現率は0.77と市販翻訳ソフトの値を上 回った. これは,
NPSが入れ子型構造であること のメリットが表れていると考えられ, 特に, ブログ などに代表される
Webテキストなど意味関数を多 く含むと考えられる日本語文の英訳を行うには好都 合である考えている. 表3は, 直接日本語述部から 英語叙述形を生成させる実験結果であるが,
NPSから英語叙述形を生成させる過程での適合率は0.72, 再現率は0.91であり,
NPS生成を別にした場合の本 モデルによる英訳自体の性能は良いと考えられる.
一方, 構築したシステムにおいて適合率が大幅に 低下しているのは, 主として日本語述部から生成さ れる
NPSの曖昧さの増大が原因であると考えられ る. 今後はどのように曖昧さを絞り込むかが重要と なる. また, 本実験では動詞による変換規則の適用 条件は考慮していない. 例えば 「V ていく」 が日本 語述部とすると, 生成される
NPSは 「持続2[V]」
となり, 「持続2[V]」 に対する変換規則は 「go on
V-ing」 と設定している. そのため, 例えば 「乗り換えていく」 を日本語述部として入力した場合には
「go on transferring」 と誤訳が出力されることにな る. そのため, 変換規則の適用条件をより詳細に検 討する必要がある.
6. おわりに
本研究では助述表現を含む日本語述部の日英翻訳 システムを提案し, 実験を行った. 翻訳に際しては, 助述表現を含む日本語述部を意味的構造(NPS)に一 旦変換し,
NPS中の各々の意味関数に対する変換 規則の適用により英訳を出力する. 実験の結果から, 意味関数の個数が増えても再現率はおおむね良好で
あり, 日英翻訳において,
NPSの枠組みの有用性 が示されたと言える.
今後の課題として, 市販ソフトで誤訳の目立った 詠嘆など口語で多く使われる意味関数に対する変換 規則を充実させるため, ブログなどの
Webテキス トなどを含めた変換規則の学習が必要であると考え ている. 実験の考察でも述べたが, 変換規則の適用 条件の詳細な検討も必要であり, さらに変換規則を どう記述するかも検討が必要である. また, 受身や 使役などの意味関数に対応する変換規則は複雑にな り, 変換は述部内にとどまらず日本語文全体に対し て行う必要がある. この場合には, 文中の格関係を 把握する必要があり (首藤ら, 1979, 古賀ら, 2003, 古賀ら, 2002), 残された今後の課題の1つとなって いる.
謝辞
英訳実験の際の英文の正誤判定を快くお引き受け 頂いた福岡大学人文学部英語学科 毛利史生准教授 に心より感謝する.
1) 例えば, 助述表現を 「発話者の主観表現」 とみ なすことにより,
NPSを主観情報処理に応用す ることも考えられる(本田ら, 2008).
2) 市販翻訳ソフトは, 基本的に翻訳ソフトとして 有名であり, 市販されているものの中でも翻訳精 度が高いものを選定している.
3) 入力が日本語文末のみのため, 翻訳ソフトの出 力には
Iや
itなどが補完される. 補完された単語 は考慮せず正誤判定を行った.
4) 4種類の翻訳ソフトのうち3種類の翻訳ソフト (B,C,D)は全文に対して同じ出力であったため 表2ではB・C・Dとまとめている.
5) 統計的機械翻訳を採用している
google翻訳が ある(google 翻訳, 2008).
6) 述部以外に現れる非命題的意味を表わす単語 (副詞や副助詞の一部など) は, 今回は取り扱わ ない.
7) 構築システムは複数の英訳を出力する. 一方, 市販の翻訳ソフトでは出力は1つしかないため,
表 3 実験結果注
意味関数の個数 1 2 3 4 全体
市販翻訳ソフトA 0.86 0.75 0.62 0.57 0.83 市販翻訳ソフトB 0.84 0.72 0.48 0.71 0.81 構築システム 適合率 0.30 0.22 0.19 0.14 0.27 再現率 0.85 0.76 0.71 0.77 0.82
再現率も適合率も同一値となる.
EDR
日本語コーパス. 1996. 独立行政法人情報通信 研究機構,
http://www2.nict.go.jp/r/r312/EDR/J_index.html
翻訳. 2008.
http://translate.google.co.jp/translate_t
Kosho Shudo, Toshifumi Tanabe, Masahito Takahashi and Kenji Yoshimura.
2004.
MWEs as Non- propositional Content Indicators. The Proc. of the ACL2004 Workshop on Multiword Expressions:Integrating Processing: pp.32-39.
Toshifumi Tanabe, Kenji Yoshimura and Kosho Shudo.
2001. Modality Expressions in Japanese and Their
Automatic Paraphrasing, The Proc. of the NLPRS2001: pp.507-512.
本田聖晃, 田辺利文, 吉村賢治, 首藤公昭. 2008.
非命題的意味解析のための日本語文末表現意味体 系. 主観表現処理の最前線シンポジウム, 電子情 報通信学会言語理解とコミュニケーション研究会,
NLC-2007-94, pp.39-44.古賀基和, 添島創, 田辺利文, 吉村賢治, 首藤公昭.
2002. 標準形変換規則によるデータスパースネス
の解消, 電気関係学会九州支部第55回連合大会 古賀基和, 田辺利文, 吉村賢治, 首藤公昭. 2003.
日本語文における態の処理について−格変換と補 文の抽出−, 福岡大学工学集報70号,
pp.107-112首藤公昭, 鶴丸弘昭, 吉田将. 1977. 日英機械翻訳
のための述部処理システム, 電子通信学会論文誌,
J60-D/10, pp.830-837首藤公昭, 楢原斗志子, 吉田将. 1979. 日本語文の 標準形変換に関する考察. 昭和54年度電気四学会 九州支部連合会大会論文集
首藤公昭, 楢原斗志子, 吉田将. 1979. 日本語の機 械処理のための文節構造モデル, 電子通信学会論 文誌,
J62-D/12, pp.872-879添島創, 田辺利文, 吉村賢治, 首藤公昭. 2003. 日 本語文分かち書きのための新しい枠組み, 福岡大 学工学集報70号,
pp.99-106田辺利文, 本田聖晃, 高橋雅仁, 小山泰男, 吉村賢 治, 首藤公昭. 2006. 日本語文末表現の取り扱い について,
FIT2006第5回情報科学技術フォーラム.
田辺利文, 吉村賢治, 首藤公昭. 2001. 日本語モダ リティ表現とその言い換え, 言語処理学会第7回 年次大会. ワークショップ論文集.
参 考 文 献