第 I 部
線形モデルと最小二乗法
第 1 章 データ科学と線形モデル
計測技術と情報技術の発展によって様々な分野で大規模データ(ビッグデー タ)を取得できるようになった.データ分析を通して研究開発を行うアプロー チはデータ科学(data science) と呼ばれている.データ科学は実験,理論,
計算(シミュレーション)による科学に次ぐ第
4の科学と呼ばれ,様々な分 野で有望視されている.データ科学は,統計科学,情報科学,機械学習,人 工知能などの分野と関わりが深い.
本講義では,特に,データ科学において最も重要な基礎となる統計科学を理 論と実践の両面から学ぶ.これまで統計科学は数学の一分野と捉えられ,数 理的な側面が重視されることが多かったが,本講義では実践的な側面と直感 的な理解に重点を置く.統計科学の枠組でデータの背後に潜む現象を解明し,
予測や理解を行うアプローチは統計的モデリング
(statistical modeling)と呼ばれている.本章では統計的モデリングの基本的な考え方を理解するた め,もっとも基本的なモデルである線形モデル
(linear model)とその推定 法である最小二乗法
(least-square method)を学ぶ.
1.1 線形モデル
例えば,ある自動車会社が新車を販売するため広告宣伝費をいくらにすべ きか検討しているとしよう.広告宣伝費を
x万円
,販売台数を
y台とし,
xと
yがどのような関係であるかを捉えることによって販売目標に必要な広告宣 伝費を知ることができる.この課題は原因である
xを入力,結果である
yを 出力とする関数関係
y=f(x) (1.1)
を推定する問題として定式化できる.
統計的モデリングでは過去のデータを利用する.自動車販売会社の例題で は,過去に販売した車の広告宣伝費と販売台数のデータが利用できる.例え ば,過去に販売されたの
10車種のデータが表
1.1のようであったとしよう.
これら
10車種それぞれを区別するため,添字
i= 1, . . . ,10を用い, それぞれ
の広告宣伝費と販売台数を
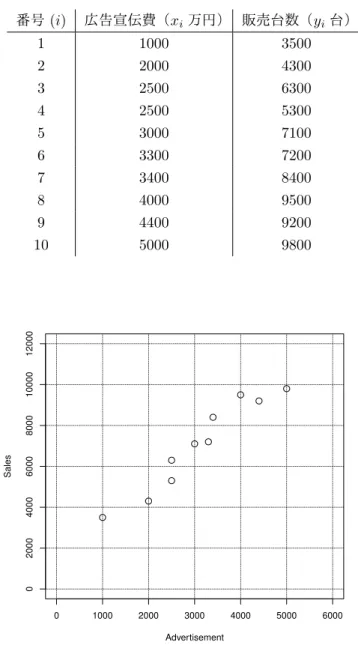
{(xi, yi)}10i=1と表記することにしよう.図
1.1は
xiを横軸,y
iを縦軸にプロットしたものである.モデルを推定するために利
用する過去のデータのことを訓練データ(traning data)と呼ぶ.
表
1.1:広告宣伝費と販売台数のデータ(仮想データ)
番号
(i)広告宣伝費(x
i万円) 販売台数(y
i台)
1 1000 3500
2 2000 4300
3 2500 6300
4 2500 5300
5 3000 7100
6 3300 7200
7 3400 8400
8 4000 9500
9 4400 9200
10 5000 9800
0 1000 2000 3000 4000 5000 6000
020004000600080001000012000
Advertisement
Sales
図
1.1:広告宣伝費と販売台数のプロット(仮想データ)
さて,図
1.1からどのようなことがわかるであろうか.まず,広告宣伝費
が増えると販売台数が増えることがわかる.また,両者の関係が概ね直線関
係にあることもみてとれる.統計的モデリングでは,まず,モデルのクラス
を決める必要がある.図
1.1のデータに関しては
xと
yが直線関係であると
思われることから
y=β0+β1x (1.2)
というクラスを考えるのが適切であろう.
(1.2)
式のように
xと
yを直線関係で表すモデルを線形モデルと呼ぶ.線形
モデルは統計的モデリングにおいて最も基本的なモデルである.次節では,ま ず,過去のデータを用いてどのように線形モデルを推定できるかを考えよう.
1.1.1 線形モデルのパラメータ推定
(1.2)
式の線形モデルには
2つのパラメータ
β0, β1が含まれている.過去 のデータを用いて,これらのパラメータを推定するタスクを考えよう.さき ほどの例では過去のデータとして
10車種を考えたが,一般的な表記として過 去の事例が
n例あるとしよう.すなわち,我々が利用できる過去のデータは
{(xi, yi)}ni=1と表される.
(1.2)
式の線形モデルを用いると
i番目の事例の予測値は
ˆ
yi=β0+β1xi (1.3)
となるので,実測値と予測値の誤差は
εi=yi−yˆi=yi−(β0+β1xi) (1.4)
となる.実測値と予測値の大小関係によって誤差
εiの値は正にも負にもなる ので,二乗誤差
ε2i = (yi−yˆi)2= (yi−(β0+β1xi))2 (1.5)
を考えることが多い.過去の
n事例全体に対する二乗誤差の和は
S=∑n
i=1
ε2i =
∑n
i=1
(yi−(β0+β1xi))2 (1.6)
と表される.
図
1.2は自動車販売数データに対し,二乗誤差の和
Sを最小にするよう線 形モデルのパラメータ
β0と
β1を推定し,その結果をプロットしたものであ る.二乗誤差の和を最小にするように線形モデルのパラメータ
β0と
β1を推 定することを最小二乗法
(least-square method)と呼ぶ.
1.2 最小二乗法
この節では最小二乗法を学ぼう.二乗誤差の和
Sを最小にするように線形 モデルのパラメータ
β0と
β1を決める問題は
( ˆβ0,βˆ1) = arg min
β0,β1∈R
∑n
i=1
(yi−(β0+β1xi))2 (1.7)
0 1000 2000 3000 4000 5000 6000
020004000600080001000012000
Advertisement
Sales
図
1.2:広告宣伝費と販売台数の関係を表す線形モデル
と定式化される.(1.7) 式は二変数
β0と
β1に関する二次関数を最小化する問 題である.解
( ˆβ0,βˆ1)が
(1.7)式の最小化問題の最適解であるたけの必要十分 条件は
∂S
∂β0
β0= ˆβ0 = 0, (1.8a)
∂S
∂β1
β1= ˆβ1 = 0, (1.8b)
である(このように,最適化問題の最適解が満たすべき条件を最適性条件
(optimality conditions)と呼ぶ).
(1.8)式の偏微分を計算して整理すると,
nβˆ0+ ( n
∑
i=1
xi
) βˆ1=
∑n i=1
yi (1.9a)
( n
∑
i=1
xi
) βˆ0+
( n
∑
i=1
x2i )
βˆ1=
∑n
i=1
xiyi (1.9b)
と整理される(演習問題2).(1.9) 式は
2つの変数
β0,β1に関する連立一次 方程式であるため,行列
[
n ∑n
i=1xi
∑n
i=1xi ∑n i=1x2i
]
(1.10)
0 1000 2000 3000 4000 5000 6000
020004000600080001000012000
Advertisement
Sales
図
1.3:線形モデルに基づく予測の例
の逆行列が存在すれば一意に解が定まる.自動車販売データの例に最小二乗 法を適用したところ,
βˆ0= 1468.472,βˆ1= 1.798 (1.11)
と推定された(図
1.3参照).
線形モデルのパラメータが推定されると,これを予測と理解に利用できる.
入力
x0に対する予測値は
ˆy0= ˆβ0+ ˆβ1x0 (1.12)
と与えられる.例えば,新たな車の広告宣伝費を
3500万円とすると,約
7761台の車を販売できるであろうと予測される.また,推定されたパラメータ
βˆ1の値は,広告費を
1万円増やすことによる販売台数の増加量を表しており,上 述の例では,広告宣伝費を
1万円増やすことで,1.798 台分の販売の増加が 見込まれると解釈できる.
最小二乗推定値
βˆ0と
βˆ1の理解を深めるため,以下のような表記を用いて これらを書き直してみよう:
¯ x= 1
n
∑n i=1
xi,y¯= 1 n
∑n i=1
yi, (1.13)
sx= 1 n
∑n i=1
(xi−x)¯ 2, sy = 1 n
∑n i=1
(yi−y)¯ 2, (1.14)
sxy= 1 n
∑n
i=1
(xi−x)(y¯ i−y).¯ (1.15)
ここで,
x, ¯¯ yはそれぞれ
xiと
yiの(標本)平均,
sx, xyはそれぞれ
xiと
yiの(標本)分散である.また,s
xyは(標本)共分散と呼ばれる.以上の表記 を用いると,最小二乗推定値は
βˆ0= ¯y−sxy
sxx,¯ βˆ1=sxy
sx (1.16)
と表される(演習問題
3).すなわち,線形モデルの傾きを表す
βˆ1は
xiと
yiの 共分散を
xiの分散で割ったものとなっている.また,線形モデル
y=β0+β1xに
βˆ0と
βˆ1を代入すると
y−y¯= sxy
sx (x−x)¯ (1.17)
と表され,線形モデルが
xと
yそれぞれの平均
(¯x,y)¯を通ることがわかる.
自動車販売データの場合,
¯
x= 3110,y¯= 7060, sx= 1398778, sy= 4869333, sxy= 2514889 (1.18)
であり,確かにこれらの値を用いて計算しても,
βˆ0= 1468.472, ˆβ1= 1.798となることが確認できる.
1.3 決定係数と相関係数
過去のデータをもとにフィッティングした線形モデルがいかに有益である のかを定量化できるとよい.そのような指標のひとつとして,決定係数と呼 ばれる指標を学ぼう.
ここでのデータ分析の目的は
yiを予測することであるので
yiのバラツキ について考えよう.まず,入力
xiが与えれらていないときの
yiのバラツキ は全変動の平方和(total sum of squares)と呼ばれ,
Sall:=
∑n i=1
(yi−y)¯ 2 (1.19)
と定式化される
1と定義される.一方,線形回帰モデルを使って得られて予 測値
ˆ
yi= ˆβ0+ ˆβ1xi (1.22)
1自動車販売データの例において広告宣伝費xiを知らずに販売台数yiを予測するイケてな い状況を考えると,
ˆ
yi=β0 (1.20)
0 1000 2000 3000 4000 5000 6000
020004000600080001000012000
Advertisement
Sales
0 1000 2000 3000 4000 5000 6000
020004000600080001000012000
Advertisement
Sales
0 1000 2000 3000 4000 5000 6000
020004000600080001000012000
Advertisement
Sales
Sall Sreg Sres
図
1.4: 3つの変動の例
と
y¯の二乗誤差の和は,回帰変動の平方和(regression sum of squares)
と呼ばれ,
Sreg:=
∑n i=1
(ˆyi−y)¯2 (1.23)
と定義される.また,予測値と実測値の二乗誤差の和は残差変動の平方和
(
residual sum of squares)と呼ばれ,
Sres:=
∑n i=1
(yi−yˆi)2 (1.24)
と定義される.これら
3つの値は
Sall=Sreg+Sres (1.25)
の関係にあり,y
iの変動
Sallが,x
iを観測することによって説明できる変動
Sregとそれでも説明できない誤差に基づく変動
Sresに分解されると解釈でき る.図
1.4はこれら
3つの変動を自動車販売データに対して図示したもので ある.
決定係数
R2は
R2:=SregSall =
∑n
i=1(ˆyi−y)¯ 2
∑n
i=1(yi−y)¯ 2 = 1−Sres
Sall = 1−
∑n
i=1(yi−yˆi)2
∑n
i=1(yi−y)¯ 2 (1.26)
と定義される.すなわち,決定係数
R2は
yiの変動のうち,線形モデルによっ て説明できる変動
Sregの割合であり,この値が
1に近いほど,線形モデルが
yiの予測に有益であることを示唆している.
という定数モデル(constant model)を考えることになる.定数モデルのパラメータβ0の 最小二乗推定値は
βˆ0= arg min
β0∈R
∑n
i=1
(yi−β0)2= 1 n
∑n
i=1
yi= ¯y (1.21)
となるので,(1.19)式のSallは定数モデルの最小二乗推定値の二乗誤差の和であると解釈でき る.
βˆ0= 0.50,βˆ1= 0.50 βˆ0= 0.90,βˆ1=−0.75 βˆ0= 0.40,βˆ1= 0.05
0.0 0.2 0.4 0.6 0.8 1.0
0.00.20.40.60.81.0
x
y
0.0 0.2 0.4 0.6 0.8 1.0
0.00.20.40.60.81.0
x
y
0.0 0.2 0.4 0.6 0.8 1.0
0.00.20.40.60.81.0
x
y
R2= 0.64, r= 0.80 R2= 0.85, r=−0.92 R2= 0.01, r= 0.07
図
1.5:線形モデルと相関係数の例
2つの確率変数
x,yから得られたサンプル
{(xi, yi)}ni=1の関連を定量化す るための指標として,相関係数と呼ばれるものがあり,以下のように定義さ れる:
r= sxy
√sxsy =
∑n
i=1(xi−x)(y¯ i−y)¯
∑n
i=1(xi−x)¯ 2∑n
i=1(yi−y)¯ 2. (1.27)
相関係数は
−1から
1の値をとる.相関係数が正であるとき,x と
yは正の 相関があるといい,x が増えると
yも増える傾向にあることを示唆している.
逆に相関係数が負であるとき,
xと
yは負の相関があるといい,
xが増えると
yが減る傾向にあることを示唆している.(1.26) 式の決定係数と相関係数は
R2=r2 (1.28)
の関係にあり(演習問題
4),xと
yの相関(の二乗)が大きいとき,線形モ デルが
yiを予測するのに有効であることを示唆している.
図
1.5には,3 つのデータセットがプロットされており,線形モデルをあて はめた結果と相関係数の値がプロットされている.また,自動車販売データ の場合,決定係数は
R2= 0.929,相関係数はr= 0.964となっており,広告 宣伝費の値を知ることで,販売台数のバラツキの
92%が説明できることを意 味している.
1.4 線形単回帰分析とその発展
これまでに学んだ線形モデル
f(x) =β0+β1xを最小二乗法により推定す
る問題は線形単回帰分析
(simple linear regression)と呼ばれている.線
形単回帰分析は最も基本的な統計的データ分析法の一つであり,その性質を
詳しく理解することは統計的モデリングを学ぶうえで重要である.以降の章
では,線形単回帰分析をさまざまな視点から掘り下げて学んでいく.
図
1.2の例にもあるように,通常,x と
yの関係が完全に線形モデルで表 されるわけでなく,実測値と予測値の間には誤差
εiが存在する.不確実性を 伴う誤差を系統的に扱うため,誤差の確率分布をモデルに導入したものを統 計モデル
(statistical model)と呼ぶ.第
2章では誤差分布の性質と最小二 乗法の関係を明らかにする.また,最小二乗法では誤差の二乗和を最小化す るという規準を用いたが,なぜそのような規準がよいのか,他の規準はない のかといった点も考察する.
本章で学んだ線形単回帰分析では,変数
yを予測するために
1つの変数
xのみを利用したが,より多くの変数を利用して予測する方がよい場合がある.
新車販売台数の例では,広告宣伝費のみを用いていたが,価格や燃費など他 の変数も用いた方がよい予測ができると考えられる.複数の変数を
x1, . . . , xdと表すと,これらを用いた線形モデルは
f(x1, . . . , xd) =β0+β1x1+. . .+βdxd (1.29)
と表される.このモデルのパラメータ
β0, β1, . . . , βdを最小二乗法によって求 める問題は線形重回帰分析
(multiple linear regression)と呼ばれている.
第
3章では線形重回帰分析を学ぶ.
統計的モデリングでは過去のデータを利用するが,データそのものに興味 があるのでなくデータの背後に潜む現象を解明することが目的である.統計科 学では,背後に潜む現象のことを母集団
(population)と呼び,データは母 集団から確率的に得られたサンプルに過ぎないとみなす
2.したがって,デー タを用いて推定したパラメータ
β0,β1もデータに潜む確率的な誤差の影響を 受けてしまうと考えなくてはならない.データの背後に潜む母集団に関して 予測・理解をしたい場合には,推定されたモデルパラメータの信頼性を適切 に評価しなくてはならない.データに基づく推定結果の信頼性を評価する枠 組は統計的推測
(statistical inference)と呼ばれている.第
4章では線形 モデルの統計的推測を学ぶ.
1.5 演習問題
1.
表
1.2のようなデータ
{(xi, yi)}ni=1が与えられているとする.まず,こ のデータを図
1.1のようにプロットせよ.続いて,このデータに対する 線形回帰分析を行い,切片
β0と傾き
β1を最小二乗法によって推定せ よ(小数点以下第
3位を四捨五入して小数点以下第
2位まで求めよ).
最後に求めた直線
y= ˆβ0+ ˆβ1xを図示せよ.
2. (1.8)
式の線形単回帰分析の最適性条件が
(1.9)式の連立方程式を解く
問題に帰着されることを示せ.
2実際,統計科学ではデータのことをサンプル(sample)と呼ぶこともある.
表
1.2:演習用データ 番号
(i)入力(x
i) 出力(y
i)
1 1 1
2 2 3
3 4 2
4 4 4
5 5 3
3.
最小二乗推定値
βˆ0,βˆ1が
x,¯ y, s¯ x, sy, sxyを用いて式
(1.13)のように表 されることを示せ.
4.
決定係数と相関係数の関係が
(1.28)となることを示せ.
5.
表
1.2のデータの決定係数
R2と相関係数
rを求めよ.
6.
図
1.6のデータは入力
xと出力
yが直線関係にないため線形回帰分析 を適用できそうにない.図を観察すると,このデータは正弦曲線によっ てうまくモデル化できそうであるが,本章で習った方法を用いて正弦曲 線のモデルを推定するにはどのようにすればよいか考察せよ(R によ る演習課題).
0.0 0.2 0.4 0.6 0.8 1.0
−2−1012
xx
y
0.0 0.2 0.4 0.6 0.8 1.0
−2−1012
xx
y
図
1.6:非線形な入出力関係の例
7.