符号分割多重法により勾配推定を行う
機械学習アルゴリズムの提案
Code Division Multiple Acquisition
佐藤 功人
1 ∗圷 弘明
1 †近藤 雄樹
1 ‡Katsuto SATO
1,
Hiroaki AKUTSU
1,
Yuki KONDOH
1.
1
(株) 日立製作所 研究開発グループ
1
Hitachi,Ltd. Research & Development Group.
Abstract: Back propagation is widely used for deep learning, however, it requires white box cost
functions that is formulated and differentiable. It is difficult for non-experts to build the model for the problem for which the effective cost function is not known. In this report, we propose the gradient estimation method with code-division multiplexing that can calculate gradients of weights in the neural network by using multiple forward propagations. The proposed method enables machine learning for the problem with black box cost functions that cannot be formulated but can calculate cost value. In this report, the proposed method is evaluated on the MNIST problem. Evaluation results shows the proposed method can build the model to recognize MNIST digits and the appropriate lengths of spreading code are small in starting phase and large in finishing phase in learning term.
1
はじめに
ニューラルネットワーク (Neural Network, NN) を ベースとした機械学習技術の発展は,画像認識 [1],音 声認識,機械翻訳等の分野で精度の良い推論モデルを 生成することを可能としてきた.画像の自動生成分野 においても VAE[2] や GAN[3] などのように問題に適し たネットワークの構成とコスト関数が提案され,以前 に比べて高い品質の画像を自動生成できるようになっ てきている. ニューラルネットワークの階層構造を深くすること で推論精度の向上を図る Deep Learning[4] では、学習 に誤差逆伝播法 (Back Propagation)[5] を用いており、 ネットワーク重みを修正するための勾配を高い計算効 率で算出可能である。誤差逆伝播法ではコスト関数の 微分を計算しなければ勾配を得られないため、コスト 関数は明確に数式で定義されている必要がある。しか し、任意の問題に対するコスト関数の定義は容易なも のではなく、ベイズ推論や統計理論の知識が無ければ 適切なコスト関数を設計することは難しい。 ∗Email: [email protected] †Email: [email protected] ‡Email: [email protected] Output Data(a) Simple Machine Learning (b) Complex Machine Learning Cost Function (Black Box)
Reference Data Another System Input Data Output Data Reference Data Input Data P ar am e te r U p d a te P ar am e te r U p d a te Cost Function (White Box) 図 1: 単純型・複合型機械学習システム しかし、図 1(a) のようにコスト関数が定式化されて いる単純な機会学習システムではなく、図 1(b) のよう にコスト関数に別のブラックボックスになっているシ ステムを含む場合であっても、順伝播計算を行った出 力に対して定量的な評価を行うことは比較的容易であ ることが多い。 複合型の例として、大江らは複数の低次 NN と推論に 1
最適な低次 NN を選択する高次 NN を組み合わせた複 合的人工ニューラルネットワーク (Composite Artificial NN, CANN)を提案している [6]。この方式では高次 NN の出力は CANN の直接の出力とならず、高次 NN の出 力結果を用いて低次 NN を選択し、選択された低次 NN の出力結果を CANN の出力としている。そのため高次 NNの学習では、複数の低次 NN とその選択機構がコ スト関数相当になるが、低次 NN 群の挙動を定式化す ることは容易ではないため、誤差逆伝播法を使うこと は難しい。大江らの成果においても、高次 NN の学習 には粒子群最適化 [7] を用いている。 粒子群最適化では状態が異なる複数実体の出力に対 する評価の差を利用することで学習を進めるため、順 伝播計算ができれば学習を進めることが可能である。 しかし、粒子群最適化では複数実体の状態を保持して 計算を進める必要があるため、十分な数の実体を用い てネットワーク全体の学習を行う場合には、保持しな ければならないデータ量が多くなる課題がある。特に GPUや FPGA などのメモリ容量が制限されるハード ウェアでは適用に困難が伴う。 実社会の複雑な問題に対して推論モデルを作る要求 に答えるためには、このような複合的な構成のニュー ラルネットワークが増えていくと考えられる。一方、潤 沢なメモリを必要とする手法は学習に必要な計算機規 模を増大させるため、IoT 機器などを用いて現場で学 習させる際には不適である。本論文ではメモリ使用量 が少なくてすむ勾配降下法をベースとし、順伝播計算 のみを用いて勾配推定を行うことが可能な、誤差逆伝 播法の代替となる手法として符号分割多重習得法を提 案する。 本論文の構成は以下のとおりである。第 2 節では関 連研究として、基本的な勾配推定法である数値微分法 と、現在一般的に用いられている誤差逆伝播法につい て説明する。第 3 節では、提案手法の元となる概念に ついて説明する。第 4 節では、符号分割多重法を応用 して勾配推定法を行う機械学習手法を提案する。第 5 節では提案手法の初期評価として、誤差逆伝播法を用 いた機械学習と同様の学習を提案手法でも可能である ことを示すために、MNIST の手書き文字認識問題をベ ンチマークとした評価結果を示す。第 6 節では、本論 文のまとめと今後の展望を述べる。
2
関連研究
最急降下法によるニューラルネットワークの学習は、 重みに対して勾配を算出する (1) 勾配推定段階と、推 定された勾配を用いて重みを更新する (2) 最適化段階 の二段階で構成される。これら 2 つの段階を学習デー タを変えながら交互に繰り返すことで、データセット 表 1: ニューラルネットワークの勾配計算法 名称 微分方法 計算量 制約条件 数値微分法 数値的 O(N2) -誤差逆伝播法 解析的 O(N ) 微分可能 数式化必須 提案手法 数値的 O(N log N ) -• N · · · ネットワークに含まれるの重みの数 に対してコスト関数が極小となる重み設定を探索する ことで学習を進める。 勾配推定段階では、ネットワークの現在の重みの値 に対して入力されたデータと教師データからコスト関 数を通して得られる損失値が小さくなる方向を勾配と して求める。勾配推定法には数値的に求める方法と解 析的に求める方法が存在し、それぞれ計算量と制約条 件が異なる。本報告ではこの勾配推定法について新し い手法を提案する。 数値微分法はニューラルネットワークを構成する重 み一つ一つを微小量変化させた際のコスト関数の値の 変化を微小量で除して勾配を求める。この手法はたと えコスト関数が明確でなくとも、順伝播方向の計算さ えできれば勾配計算を行うことが可能であるが、重み の数だけ順伝播計算を行わなければならず、重みの数 N に対して O(N2)の計算負荷が発生する。N の数に 対して急激に計算量が増加するため、現在主流の Deep Learningでは計算量が現実的な量ではなくなる問題が ある。 誤差逆伝播法は、微分の連鎖律を利用して解析的に 勾配計算を行う。順伝播と同程度の計算負荷ですべて の重みに対する勾配を計算できるため、重みの数が多 くなったとしても計算量を現実的な範囲内に収めるこ とが可能である。しかし、誤差逆伝播法は逆方向に伝 播させる経路すべてで微分可能であることが求められ るとともに、コスト関数を数式の形で明確に定義しな ければならない。 以上のように、数値的に勾配を求める数値微分法は 制約が少ないが計算量が多く、解析的に勾配を求める 誤差逆伝播法は計算量が少ないが制約がある。コスト 関数部分をブラックボックスとするためには数値微分 法が向いているが、Deep Learning と数値微分法の組 み合わせでは、計算量が現実的・実用的ではない。本 研究では、数値微分法の計算量を実用的な規模まで削 減するために、誤差逆伝播における連鎖律の利用によ る計算の高速化と同様に、数値的な微分計算に高速化 手法を導入することを試みる。QŠyÍÿ
½Éã–ëñ
?¸&/A@& 5”Yv“– =cöú©Uy#?
A10 (' Ç–ÏÝñ Good? Bad?
ú˜Q 4^Q z •´y=cöú©Uy#?s Ç–ÏÝñóUy#?V” ²C•´Ï`f–O´(± )•, WµÈÕ·yCû©?€2BWE^ z \™¤S‡€Š`¥y#? z ß± q€ßßv“–²C z \™y²CCN•Ç–ÏÝñ N\–•Oœbq=c z ±·Æ <y#?–sQŠy•˜#? –•=Oj<••þv“•± •‹\ W±vJOQŠ•Íÿ z \™y#? z ±·Æ <v“–²C z ±·Æ <y²C•y#? –•‹\b½Éã–ëñ v=c L Í á UÜ F PÜ 6 'L ' F 'È ½NNvU\– <••þv“– ¸8é–Õ övU\– <•&± Q ¸8@ˆ U \ UE U z µÈÕ·Cû©Uy5”Yv“• =cöúy©Uv•˜–y#?WE^ µÈÕ· Cûy ©?/2BWE^ z µÈÕ·Cû©Uy5”Yv“• =cöúy©Uv•˜–y#?WE^ ™ç\ SçE ó ™ç>5L SçE ß ' ó QŠy•˜–#? ½Éã–ëñ 図 2: 脳の数値的勾配法学習仮説 30 20 10 10 ÑSö ) Volume Transmission
VT
W T WŠ_m• œö ) Wiring Transmission w / WŠ_m•„ Ô žg:s HôŽƒ 図 3: 拡散性伝達と結合性伝達3
符号分割多重習得法のコンセプト
本節では提案する学習手法の背景にある考え方につ いて述べる。3.1 節では、脳科学分野の知見を参考と して、脳の学習過程についての仮説を述べる。3.2 節で は、前節の仮説を実現するために克服しなければなら ない課題について通信分野との類似性を指摘し、通信 技術の応用について述べる。3.1
脳科学分野の知見に基づいた仮説の構築
ニューラルネットワークの発展を考える上で、脳科 学の研究成果は重要な知見をもたらしている。本研究 では、順伝播のみで勾配推定を行う手法を検討するに あたり、脳を構成する要素のひとつである報酬系に着 目して仮説を立てた。 哺乳類の報酬系は欲求が満たされる、または満たさ れることが期待されるときに活性化して化学物質を放 出すると言われており、該当する神経系はドーパミン 神経系 (A10 神経系) と呼ばれている。ドーパミンはシ ナプス結合を強化する作用があることが知られており、 この強化作用はスパインが活性してから 2 秒以内でし か発生しないことが報告されている [8][9]。 このドーパミン神経系が放出するドーパミンの量に 相当するものがコスト関数の出力値と仮定すると、図 2のように数値微分による重みの調整アルゴリズムと 報酬系の動きを対応付ける仮説を立てることができる。 数値微分では、重みのひとつを微小量変化させたと きに出力に対するコストがどの程度変化するかに基づ いて勾配を推定している。一方、脳内のシナプスにお いても毎回同じ信号強度で伝達されているとは考えに くく、熱雑音などに影響されてわずかに強弱が異なる 信号が伝達されている可能性が高い。 伝達信号強度の揺らぎにより出力が変化すると、外 部状況が変化する。外部状況の変化に対して現状への 評価が変化し、この評価に応じてシナプス周辺のドー パミン濃度が変動するとしたとき、伝達信号強度の増 減量とドーパミン濃度の増減量から勾配を算出して結 合強度を調整すると仮定する。このように数値的に勾 配算出を行って学習ループを回す過程を “脳の数値的 勾配法学習仮説” と呼ぶこととする。 伝達信号強度の揺らぎは複数のシナプスで同時に発 生し得ることに加えて、シナプス個々の空間的大きさ よりもドーパミンの濃度分布は図 3 に示すように大域 的であると考えられる [10]。古典的な 1:1 関係の結合 性伝達 (WT, Wiring Transmission) に対して、ドーパ ミンを介した低速度で距離が長い情報伝達を拡散性伝¢•(m¨ '“zû™ Á< Áú‰"úIØþìëšì D at a # 2 D at a # 2 ¢•(m¨ 'µ”Ûf AGVõXÍþìëšì s j # 2 s j # 2 #0 #1 #2 #3 #4 ¢•ì ö…• Ÿ•ì 図 4: 符号分割多重法による通信と機械学習 達 (VT, Volume Transmission) と呼び、脳内において 1対 N の情報伝達が行われていることが Zoli らによっ て主張されている [11]。従って、ドーパミンの濃度変 化の影響は複数のシナプスに対して同時に作用し得る ことが仮定できるが、本仮説に基づいて複数のシナプ スの結合強度を同時に調整していくためには、複数の シナプスにおける伝達信号強度の揺らぎによって引き 起こされるドーパミン濃度の変化から、それぞれの信 号強度の揺らぎの影響の寄与量を個々のシナプスに対 して推定しなければならない。 同様に、人工ニューラルネットワークの学習におい て本仮説に基づいて学習を行うには、重みに同時に揺 らぎを与えたことによるコスト関数値の変化量に対し て、個別の重みの寄与量を算定する手法が必要となる。 次節では寄与量の算定を行う方法について述べる。
3.2
通信技術転用による寄与量分離
符号分割多重 (Code-Division Multiplexing)[12] は主 に無線通信分野で使われている多重化方法であり、携 帯電話や GPS など同じ周波数帯で複数の端末が同時 に通信する需要を満たすために用いられる手法である。 端末ごとに異なる符合を割り当て、その符号を送信信 号に掛け合わせて送出することで、受信側で複数端末 からの信号が混合された状態で受信されたとしても、 一定の計算を行えば端末ごとの送信信号を復元するこ とができる。この通信方式を Code-Division Multiple Access (CDMA)方式と呼ぶ。 この手法を、重み変化がコスト関数値に与える影響 量の分離に応用する。図 4 に示すように、通信端末を ニューラルネットワークのそれぞれの重みに対応する と考え、重みを変化させることを端末から信号を送出 すると考える。重みを一斉に変化させることは通信端 末が一斉に通信を行うことに相当し、ニューラルネット ワークの出力はそれぞれの重みの変化が重なり合った 状態となる。ニューラルネットワークの出力をコスト関 Cost Function Reference Data Input Data Output Data ±·Æ <• VT ±·Æ <• #?–4 W T W T W T W T W T W T W T W T ±·Æ <• E ¨†S=c (²l ö) CûS=c ( ½Éã–ëñ yz ö) QŠ #0 QŠ #1 QŠ #N W T WT W T W T ½Éã–ëñ 図 5: 符号分割多重学習システム構成 数によって評価した値は、ある時間における電磁波の強 度であるとみなしたとき、重みを割り当てられた符号 に基づいて変化させながら得られる評価値の数列に対 して一定の計算を行えば、重みごとの影響を復元する ことができるはずである。本論文ではこのコンセプトに 基づいて重みの調整を行う手法を、“符号分割多重習得(Code-Division Multiple Acquisition, CDMA)
法” と呼ぶことにする。
この考え方に基づけば数値微分法は時間分割多重習 得 (Time-Division Multiple Acquisition, TDMA) 法に 相当するといえる。符号分割多重習得法を用いて数値 微分を行うことで、数値微分の問題であった計算量の 増大問題を軽減することが可能である。 前述のシナプスの結合強度の揺らぎは、CDMA 法で は重みを変化させる符号によって表現されることにな る。個々のシナプスは自身の揺らぎの履歴に相当する符 号さえ保持しておけば、大域的なドーパミン濃度の変 化に相当するコスト関数値の変化量との間で一定の計 算を行うことで、勾配の算出を行うことが可能となる。
4
符号分割多重法による勾配推定
本節では符号分割多重法を用いて数値微分法の計算 を高速化する手法について提案する。第 4.1 節では、提 案する学習アルゴリズムを採用したシステムの構成に ついて説明する。第 4.2 節では、提案する勾配推定法 の数学的考察を述べる。第 4.3 節では、提案手法と最 急降下法を組み合わせた場合の性質について考察する。4.1
学習システム構成
提案する機械学習システムの全体構成を図 5 に示す。 一般的な順伝搬ニューラルネットワークは結合性伝達 (WT)で構成されているものと考え、新たにコスト関数による評価結果の変化量を一斉に配信する経路を設 ける。この一斉配信経路が拡散性伝達 (VT) を担うこ ととなる。 学習の手順概要を以下に示す。 (1) 順伝搬計算時に、重みの値に一定の規則に沿って 疑似乱数を加え、化学結合シナプスにおける伝達 信号の揺らぎを模擬する。 (2) 重みの揺らぎによって引き起こされる出力の変 化、およびそれに対する評価の変化量を算出し、 全人工ニューロンに一斉配信する。 (3) (1)∼(2) の手順を複数回実行する。 (4) 個別のニューロンは、配信されてきた評価の変化 量数列と疑似乱数列を用いて一定の計算を行い、 自らの重みについての勾配を得る。 (5) 算出した勾配を用いて重みを更新する。更新アル ゴリズムは誤差逆伝播法を用いた学習と同じもの を利用できる。 以上を繰り返すことで重みの最適化を実現する。
4.2
符号分割多重法を用いた勾配推定
CDMA通信システムでは、特定の性質を持つ疑似雑 音 (PN, Pseudo Noise) を用いることで多重通信を実現 している。ここで用いる疑似雑音は、周期自己相関性 特性を持ち、同期がとれていない場合には相関性が弱 くなるという性質を持つものである。周期自己相関特 性を持つ疑似雑音発生アルゴリズムの代表的なものと して、M 系列発生器 [13] が存在する。 疑似雑音発生器は内部状態として位相を持っており、 位相が同じ疑似雑音発生器から発生させる数列の相関 性は高くなり、位相が異なる場合には低くなる。この 位相が同じ場合を同期していると表現する。疑似雑音 発生器は-1 と 1 を等確率で発生させるものとし、疑似 雑音発生器から生成される数列を拡散数列 ⃗Cと定義す る。以降、x 番目の位相を持つ拡散数列 ⃗Cの y 番目の 要素を ⃗Cx[y]と表現する。初期位相が n と m で自己相 関周期が T の拡散数列 ⃗Cn, ⃗Cmの間では以下の性質が 満たされる。 ⃗ Cn· ⃗Cn = T ∑ t ⃗ Cn[t]· ⃗Cn[t] = T, (1) ⃗ Cn· ⃗Cm = T ∑ t ⃗ Cn[t]· ⃗Cm[t]≈ 0. (2) すなわち、同位相の拡散数列の各要素の積を T の期間 累積した値は T となり、異なる位相の拡散数列の各要 素の積を周期 T の期間累積した値は 0 に漸近する。 拡散数列の長さ T は拡散係数と呼ばれ、疑似乱数発 生器の周期によって決まる値となる。ただし、誤差を 許すのであれば拡散係数を周期よりも短くすることも 可能であり、拡散係数が短い場合には、式 (2) の 0 へ の収束性が悪化する。 提案学習手法ではニューラルネットワークの重みそ れぞれを異なる位相の拡散数列に従って変化させ、評 価値の変化を積分することで特定の重みの勾配を推定 する。 4.2.1 勾配推定アルゴリズム 提案する勾配推定アルゴリズムでは、拡散数列が持 つ性質を利用して重みの変化がコスト値に与える影響 の推定を行う。数値微分法では重みを一つずつ変更し て評価値に与える影響量を推定するが、本手法では重 み一つ毎に異なる位相を持つ疑似雑音発生器から得ら れる数列に従って重みを微少量だけ変化させて順伝播 計算を行い、評価値を得る操作を繰り返す。 このとき、k 番目の重みは k 番目の位相を持つ拡散 数列 ⃗Ckを用いて、微少数 ϵ と当該重みの元の値 pkを 用いて以下のように表される数列 ⃗Pkを生成する。 ⃗ Pk = pk+ ϵ ⃗Ck (3) = {pk+ ϵ ⃗Ck[1],· · · , pk+ ϵ ⃗Ck[T ]} (4) この手順を全ての K 個の重みに対して適用し、それぞ れの t 番目の要素を用いて順伝播計算を行う。得られ たニューラルネットワークの出力について評価値を計 算する手順を T 回繰り返して得られる評価値数列を ⃗E としたとき t 番目のコスト値 ⃗E[t]は以下のような線形 結合の近似式で表せると仮定する。なお、EOは重みを 一つも変化させない状況での評価値の値であるとする。 ⃗ E[t] = EO+ ϵ K ∑ k gk· ⃗Ck[t] (5) = EO+ g1· ⃗C1[t] +· · · + gK· ⃗CK[t] (6) この仮定は、全ての重みを同時に変化させたときの 評価値の変化量は、重みを個別に ϵ だけ変化させたと きの変化量 g の線形結合で近似できることを意味して いる。実際には活性化関数やコスト関数が非線形性を 持つため評価値の変化量も非線形性を持つことが予想 されるが、提案手法では真の勾配値に対して線形近似 を行うことで簡略化している。 機械学習において重み更新のために求めなければな らない値は、重みの勾配値 g である。前述の式から q 番目の重みの勾配 gqを求めるために、式を以下のよう に変形する。 ⃗ E[t]− EO ϵ = K ∑ k gk· ⃗Ck[t] (7)ここに、q 番目の重みを変化させたときに用いた拡散 数列 ⃗Cq を用いて T 回の試行の中の t 番目の結果 ⃗E[t] に拡散数列の要素 ⃗Cq[t]を掛け合わせて和をとる計算を 行う。 T ∑ t ⃗ Cq[t]· ⃗ E[t]− EO ϵ = T ∑ t K ∑ k gk· ⃗Cq[t]· ⃗Ck[t] (8) 数列 ⃗Ck と ⃗Cq の累積計算した場合、前述の定義から q = kでは T 、q ≠ k では 0 に収束するため、T が十分 に大きければ右辺はの大部分の項を無視することがで き、以下のように近似できる。 T ∑ t K ∑ k gk· ⃗Cq[t]· ⃗Ck[t]≈ gq· T (9) したがって、式 (8) に式 (9) を適用した結果は以下のよ うになる。 T ∑ t ⃗ Cq[t] ⃗ E[t]− EO ϵ ≈ gq· T (10) この式を求めたい勾配 gqを残して変形することで、勾 配を求める式を得ることができる。 gq ≈ 1 ϵT T ∑ t ⃗ Cq[t]( ⃗E[t]− EO) (11) 4.2.2 ミニバッチ法への最適化 実際の学習ではミニバッチ法が使われることが多く、 複数の入力データに対する平均勾配に基づいて重みの 更新を行う計算過程を取る。複数のデータに対する平 均勾配を求める場合、一つ一つのデータに対して勾配 を計算してから平均化するよりも、データ方向にも拡 散数列を設定することで勾配推定精度を改善すること ができる。 d番目のデータに対する q 番目の重みの推定勾配を gq,dとした時、D 個のデータに対する平均勾配 ¯gqは ¯ gq = 1 D D ∑ d gq,d (12) となる。それぞれのデータに対する勾配 gq,dに対して 同じ拡散数列 ⃗Cq を用いても平均勾配の算出は可能で あるが、データ毎に異なる拡散数列要素を割り当てて 拡散係数を大きくすることで、勾配推定精度を向上さ せることができる。 データあたりの繰り返し回数を R と置き、拡散数列 の長さ T を T = R から T = R× D に伸ばしたとす る。d 番目のデータに対する r 回目の順伝播計算をし た結果を ⃗E[t]と置く。ただし t = d + r· D (13) とする。d 番目のデータについて、重みを変化させないと きの順伝播計算結果に対するコスト関数の値を EO[d]、 k番目の重みを変化させたときの勾配を gk,dとして、 以下のような仮定を置く。 ⃗ E[t] = EO[d] + ϵ K ∑ k gk,d· ⃗Ck[t] (14) この式を 4.2.1 節と同様に変形すると、以下のように なる。 ⃗ E[t]− EO[d] ϵ = K ∑ k gk,d· ⃗Ck[t] (15) ここで、求めたい平均勾配を ¯gqを求めるために、デー タ方向と繰り返し方向の両方について q 番目の重みに 対応する拡散数列 ⃗Cq を用いて、4.2.1 節と同様に t 番 目の結果に ⃗Cq[t]を掛け合わせて和をとる計算を行う。 D ∑ d R ∑ r ⃗ Cq[t]· ⃗ E[t]− EO[d] ϵ = D ∑ d R ∑ r K ∑ k gk,dCq⃗ [t]· ⃗Ck[t] この場合も拡散数列どうしの積の性質から以下の近似 が成り立つ。 D ∑ d R ∑ r K ∑ k gk,d· ⃗Cq[t]· ⃗Ck[t]≈ D ∑ d R ∑ r gq,d (16) この関係を利用して式を整理すると、 D ∑ d R ∑ r ⃗ Cq[t] ⃗ E[t]− EO[d] ϵ ≈ D ∑ d R ∑ r gq,d = RD· 1 D D ∑ d gq,d = RD¯gq (17) となるため、平均勾配を以下のように表すことができる。 ¯ gq ≈ 1 ϵRD D ∑ d R ∑ r ⃗ Cq[t]( ⃗E[t]− EO[d]) (18) 本式は前述のデータ毎に勾配を計算して平均化した 場合の式と形は似ているが、途中の計算で行われる拡 散数列 ⃗Cqと ⃗Ckの積分の長さ T がデータ数 D 倍となっ ているため、q ̸= k の場合における 0 への収束性が改 善される。
(a) Back Propagation + SGD (b) The proposed method + SGD Start Goal ± , Ì¢¸yê» v“– èO´y5— 図 6: SGD と提案手法を組み合わせた場合の学習挙動
4.3
確率的勾配降下法との組み合わせ
提案手法を用いて勾配推定した場合、拡散係数が十 分大きくなければ精度が高い勾配値を得ることができ ないため、小さい拡散係数で動作させると学習ができ ないように思われる。しかし、推定された勾配は真の 勾配に対して誤差を含んでいるとしても、それらを積 分した平均的な進行方向では提案手法が推定した勾配 方向に含まれるノイズが打ち消し合い、極小解の方向 に進むことが見込まれる。 ただし、極小解への接近速度は誤差逆伝播法と最急 降下法を組み合わせた場合に比べて低下する。図 7(a) のように誤差逆伝播法を用いて最も急勾配となる方向 を正確に求めて下る方法に比べて、提案手法では勾配 推定に誤差を含むため図 7(b) のように勾配降下方向に ノイズが含まれた状態で進むことになる。そのため、1 回の重み更新で極小点に近づく量は誤差逆伝播法より は小さくなり、学習の進捗速度は低下することが見込 まれる。 提案手法の勾配推定ノイズを減少させるためには拡 散係数を大きくする必要があるが、拡散係数を大きく するほどの計算時間が長くなることが問題となる。計 算時間を抑えるために、拡散係数を大きくするのでは なく勾配推定値に対して何らかの方法で尤度を推定し、 カルマンフィルタ等を用いてフィルタリングを行うこ とで学習速度の改善を図ることができる可能性がある。 このようなフィルタリングは、AdaM や AdaDelta 等 の最適化器(オプティマイザ)が副次的にその役割を 果たす場合があるため、単純な最急降下法を用いるよ りも学習速度が改善する可能性が高い。4.4
従来手法との比較
提案手法と既存手法の相違点を表 2 に示す。提案手 法は数値微分法と同様に数値的に微分を行うが、これ 表 2: 勾配計算法の比較 名称 微分方法 高速化原理 数値微分法 数値的 -誤差逆伝播法 解析的 連鎖律 符号分割多重習得法 数値的 符号分割多重法 に符号分割多重法を用いて高速に計算を行うための工 夫を適用したものとなっている。5
学習精度および速度の評価
5.1
評価対象と評価指標
評価対象には、MNIST[14] の手書き文字認識の課題 を選択した。本課題は初歩的かつ著名な課題であり、手 書き文字が書かれている 28 × 28 ピクセルのグレース ケール画像から、0∼9 の 10 種類の数字を識別すること が求められる。本課題に対して適切に学習できている かを評価するための指標として、同じ設計のニューラ ルネットワークを用いて誤差逆伝播法と同程度の正答 率が得られることを目標とした。また、学習の進捗速 度について評価するために学習曲線も評価指標とした。5.2
評価条件
評価に用いたニューラルネットワークの諸元値を表 3 に示す。また、ネットワーク以外の重みを表 4 に示す。 ニューラルネットワークは隠れ層 4 層の全結合ネッ トワークとし、活性化関数には ReLU を用いた。学習 精度を示すテストデータに対する正答率の算出は重み を 10 回更新する毎に行い、推論精度の確認を 1,000 回 繰り返したところで学習終了とした。訓練用の手書き 文字認識画像は 60,000 枚から構成され、一度の重み更 新のためのミニバッチで 400 枚ずつ使うため、学習終 了までのエポック数は約 66.67 epocs となる。 数値微分における微少変化量である ϵ は 1.0× 10−3 を初期値として、重みを更新する毎に 0.999 を掛け合 わせて少しずつ小さくする。このように ϵ を少しずつ 小さくすることで最初は中心点と離れたところの値か ら勾配を推測し、徐々にごく近傍の値から勾配を推測 するように動作させて局所最適に陥りにくくする効果 を狙った。図 7: 評価に用いたニューラルネットワークの構造 表 3: ニューラルネットワークの設計パラメータ レイヤタイプ ニューロン数 活性化関数 Input 784 -Affine 100 ReLU Affine 50 ReLU Affine 20 ReLU Affine 10 ReLU Output 10
-5.3
評価結果
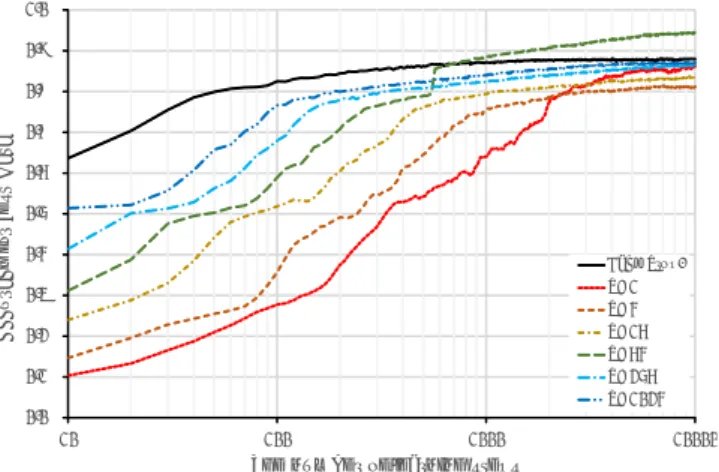
5.3.1 学習精度に関する評価 テスト用画像の分類正答率の評価結果を図 8 に示す。 一番左側に誤差逆伝播法を用いた場合の正答率を示し、 それ以外には繰り返し回数 R を変化させた場合の正答 率を示している。本結果は提案手法が誤差逆伝播法と 同様に学習が可能であり、縦軸で示されている到達学 習精度についても遜色ないことを示している。 提案手法固有の傾向として、繰り返し回数 R を増加 させる毎に到達精度が向上する傾向が明らかとなった。 ただし、初期値と繰り返し回数に依存して最終的に到 達する極小解が異なるものになる場合があり、学習精度 について異なる傾向を示す2つのグループが生じる結 果となっている。図 8 の第一の傾向曲線 (1st Trend) は 誤差逆伝播法による学習結果とは異なる極小解にたど り着いたと思われるものであり、第二の傾向曲線 (2nd Trend)は同じ極小解にたどり着いたと考えられる。 提案手法と誤差逆伝播法のどちらにおいても同じ乱 数列による初期状態から学習を開始しているが、提案 手法は誤差を含んで勾配推定を行うため異なる極小解 に到達する可能性があることを示している。第 1 の傾 向曲線は誤差逆伝播法で見つけた極小解よりも高い学 習精度を達成していることから、提案手法は誤差逆伝 播法よりも汎化性能が高い極小解に到達したと考えら れる。提案手法は誤差を含んだ勾配推定をする手法で 表 4: 実験条件 項目 設定値 備考 疑似雑音生成多項式 x33+ x13+ x M-sequence オプティマイザ AdaM 重み総数 84,780 微少数 ϵ 初期値 1.0× 10−3 微少数 ϵ 減衰係数 0.999 ミニバッチデータ数 400 学習ステップ数 10,000 表 5: 実験環境 項目 仕様CPU Intel Xeon E5-2690
2.9 GHz, 16 cores, 2 sockets Memory 64GiB (DDR3-1600) OS CentOS 7.2.1511 Linux 3.10.0-327.el7.x86 64 あるため、学習結果が安定する時は極小解がコスト関 数が作る穴の中でも、広く重み変化に対してロバスト な性質を持っていることが期待できる。 一方、同じ傾向曲線にのっている場合には繰り返し 回数 R を大きくした方がより高い学習精度を達成可能 であることが明らかとなった。提案手法では、繰り返 し回数 R に比例する拡散係数が小さい場合に勾配推定 ノイズが大きくなることに起因して、同じ学習ステッ プ数で到達できる位置が真の極小解の位置から離れる。 この影響が繰り返し回数 R に到達精度が比例するよう に見える原因であると考えられる。 以上より、提案手法は誤差逆伝播法と同様に学習可 能であることと、繰り返し回数が小さいときには凡化 能力の高い極小解の探索性能が良いこと、大きいとき には学習ステップ数に対する収束速度が速いことが明 らかとなった。 5.3.2 学習速度に関する評価 図 9 に横軸に重み更新回数を表す学習ステップ数、 縦軸にテスト用データの正答率を取った学習曲線を示 す。なお、グラフの視認性を上げるためにプロットす る繰り返し回数 R については間引いている。学習速度 については提案手法は誤差逆伝播法に比べて遅いこと が確かめられ、繰り返し回数 R を大きくして拡散係数 を大きくするほど学習ステップ数に対する学習速度が 速いことが明らかとなった。
図 8: 提案手法における手書き文字分類正答率の評価 結果 図 10 には、横軸に実計算時間、縦軸にテスト用デー タの正答率を取った学習曲線を示している。実時間に おいては、繰り返し回数 R が小さい方が学習速度は速 いことがわかる。繰り返し回数 R を大きくすると一回 の学習ステップあたりの計算時間は伸びるため、図 9 と図 10 では逆の傾向を示すことになる。 以上の結果から、現実的な時間で実用的な学習精度 を持つモデルを生成するためには、繰り返し回数 R は 小さい方が良いことが明らかとなった。ただし、繰り返 し R が小さい場合には勾配推定精度の低さに起因して 極小解の周辺を行き戻りする状態になってしまい、最 終到達精度が低くなる可能性がある。これを防ぐため には、学習の初期段階では繰り返し回数 R を小さく設 定して一定精度まで学習を行い、学習精度の向上が飽 和した段階で繰り返し回数 R を段階的に大きくしてい くような手順が有効であると考えられる。
6
まとめ
機械学習において、コスト関数は学習の中心的な役 割を果たす重要な関数であるが、問題種別に対して適 切なコスト関数の設計や定式化を行うことは専門的な 知識を必要とするため困難が伴う。 本論文では、脳科学分野の知見から得たアイデアと 符号分割多重法を組み合わせて、順伝播計算のみで勾 配推定を行う機械学習アルゴリズムを提案した。コス ト関数の定式化が困難であっても、最終的な結果に対し てコストを計算することは可能である場合が多い。提 案手法を用いれば、最終結果に対するコストの変化を 用いて学習が可能であるため、間にブラックボックス が存在しても学習を進めることが可能である。 初期評価として提案手法を用いて手書き文字認識問 題の学習が可能であることを実証した。従来手法であ る誤差逆伝播法に対して定数倍の計算コストで同等の 学習が可能であること、および勾配推定精度と計算コ ストがトレードオフ関係になることを示した。 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 10 100 1000 10000 A ccu racy for T est DataThe number of learning steps
Back Prop. R=1 R=4 R=16 R=64 R=256 R=1024 図 9: 学習ステップ数に対する学習曲線 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 1 10 100 1000 10000 100000 1000000 A ccu racy for T est Data
Learning Time [sec]
Back Prop. R=1 R=4 R=16 R=64 R=256 R=1024 図 10: 学習時間に対する学習曲線 今後の課題として、本提案手法の設計目的であるコ スト関数が定式化できない問題においても、学習が可 能であるかを検証すること、および学習速度の高速化 を図るための手法について検討していきたいと考えて いる。
参考文献
[1] Alex Krizhevsky, Ilya Sutskever, and Ge-offrey E Hinton. Imagenet classification with deep convolutional neural networks. In F. Pereira, C. J. C. Burges, L. Bottou, and K. Q. Weinberger, editors, Advances in
Neu-ral Information Processing Systems 25, pp.
1097–1105. Curran Associates, Inc., 2012. URL: http://papers.nips.cc/paper/4824- imagenet-classification-with-deep-convolutional-neural-networks.pdf.
[2] Diederik P Kingma and Max Welling. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013. URL: https://arxiv.
org/pdf/1312.6114.
[3] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sher-jil Ozair, Aaron Courville, and Yoshua Ben-gio. Generative adversarial nets. In Z. Ghahramani, M. Welling, C. Cortes, N. D. Lawrence, and K. Q. Weinberger, editors,
Ad-vances in Neural Information Processing Sys-tems 27, pp. 2672–2680. Curran Associates, Inc.,
2014. URL: http://papers.nips.cc/paper/ 5423-generative-adversarial-nets.pdf. [4] Yann LeCun, Yoshua Bengio, and Geoffrey
Hin-ton. Deep learning. Nature, Vol. 521, No. 7553, pp. 436–444, 2015.
[5] DRGHR Williams and Geoffrey Hinton. Learn-ing representations by back-propagatLearn-ing errors.
Nature, Vol. 323, No. 6088, pp. 533–538, 1986.
[6] 大江亮介, 鈴木育男, 山本雅人, 古川正志. 複合的人 工ニューラルネットワーク. 精密工学会誌, Vol. 79, No. 6, pp. 552–558, 2013. doi:10.2493/jjspe. 79.552.
[7] J Kennedy and R Eberhart. Particle swarm op-timization. In Neural Networks, 1995.
Proceed-ings., IEEE International Conference on, Vol. 4,
pp. 1942–1948. IEEE, 1995. [8] 東京大学大学院医学系研究科・医学部. ニュー スリリース: ドーパミンの脳内報酬作用機構を 解明∼依存症など精神疾患の理解・治療へ前進 ∼. 2014. URL: http://www.m.u-tokyo.ac.jp/ news/admin/release_20140926.pdf.
[9] Sho Yagishita, Akiko Hayashi-Takagi, Gra-ham C.R. Ellis-Davies, Hidetoshi Urakubo, Shin Ishii, and Haruo Kasai. A critical time window for dopamine actions on the structural plasticity of dendritic spines. Science, Vol. 345, No. 6204, pp. 1616–1620, 2014. URL: http://science. sciencemag.org/content/345/6204/1616, arXiv:http://science.sciencemag. org/content/345/6204/1616.full.pdf, doi:10.1126/science.1255514. [10] 小林克典. ドーパミン. 脳科学辞典, 2013. URL: http://bsd.neuroinf.jp/w/index.php? title=%E3%83%89%E3%83%BC%E3%83%91%E3%83% 9F%E3%83%B3&oldid=27830.
[11] Michele Zoli, Carla Torri, Rosaria Ferrari, An-ders Jansson, Isabella Zini, Kjell Fuxe, and Luigi F Agnati. The emergence of the volume transmission concept. Brain Research Reviews, Vol. 26, No. 2, pp. 136–147, 1998.
[12] スペクトラム拡散技術のすべて. 東京電機大学出 版局, 2002. ISBN 978-4501322403.
[13] 羽渕裕真. M 系列を基に構成される系列とその通 信への応用. 電子情報通信学会 基礎・境界ソサイ エティ Fundamentals Review, Vol. 3, No. 1, pp. 1 32–1 42, 2009.
[14] Yann LeCun, Corinna Cortes, and Christo-pher JC Burges. MNIST handwritten digit database. AT&T Labs [Online]., Vol. 2, , 2010. URL: http://yann.lecun.com/exdb/mnist.