The 28th Annual Conference of the Japanese Society for Artificial Intelligence, 2014
3L3-OS-26a-4
実取引環境
複利型強化学習 用
取引戦略 獲得
Acquiring Trading Strategy Using Compound Reinforcement Learning
in Online Trading Platform
松井 藤五郎
∗
1Tohgoroh Matsui
長瀬 舜
∗
1 Shun Nagase後藤 卓
∗
2 Takashi Goto和泉 潔
∗
3 Kiyoshi Izumi陳
∗
3Yu Chen
鳥海 不二夫
∗
3Fujio Toriumi
∗
1中部大学
Chubu University
∗
2株式会社三菱東京
UFJ
銀行
Bank of Tokyo-Mitsubishi UFJ, Ltd.
∗
3東京大学
The University of Tokyo
This paper describes an application of compound reinforcement learning to an online trading platform. We use TradeStation that is the most popular online trading platform among individual investors. We propose a measure for commission fee in order to improve the winning rate.
1.
我々 , ,日本株 仮想取引環境
複利型強化学習 [松井11a, Matsui 12, 松井11b,
松井13b,松井13a] 用 取引戦略 獲得 手法 開発
[松井07,松井09,後藤13]. ∗1 ,Java
環境 ,
分析 指標 株取引 必要 API 提供
,様々 環境 高度 取引戦略 実装
[鳥海06]. ,注文 出 機会 前
場 開 前 後場 開 前 1日2回 制限 ,
行 .一般的
注文 出 機会 多 安定 運用 行 可
能性 高 ,本研究 , 安定運
用 目指 .
対 ,TradeStation∗2 ,価格情報 更新
実行 ,更新間隔 短
行 . ,TradeStation
,開発 用 実際 取引 行
.
,本論文 , 開発 複利型強化学習
用 取引戦略 獲得 手法 TradeStation上 実装 ,
行 方法 提案 . ,TradeStation
EasyLanguage 独自 言語 用 ,取引 必要
API 十分 提供 . ,複利型強化学習
用 取引戦略 獲得 実装上 工夫 必要 .
, ,価格 変動 小 ,手
数料 場合 細 取引 行 勝率 極端 悪
. ,本論文 , 防 手数料対策 方法
提案 .
従来研究[後藤13] 本研究 環境 違 表1 示
.従来研究 最大 違 ,時間足 日足 分足
行 点 . 他 ,[中原13] ,
強化学習 用 株取引 行 研究 行 研究
,実取引 可能 環境 強化学習 行 .
連絡先: 松井藤五郎, 中部大学, 愛知県春日井市松本町1200,
[email protected] ∗1 http://www.kaburobo.jp ∗2 http://www.tradestation.com
表1:従来研究[後藤13] 比較
[後藤13] 本研究 TradeStation 使用言語 Java EasyLanguage
○ ○
実取引 × ○
対象商品 日本株 米国株
時間足 日足 分足
2.
複利型強化学習 用
株取引戦略 獲得
複利型強化学習 ,割引複利利益率(割引複利 )
(
1+
Rt+1f)(
1+
Rt+2f)
γ(
1+
Rt+3f)
γ2 . . .
=
∞
∏
k=0
(
1+
Rt+k+1f)
γk
期待値 最大化 行動規則 学習 . ,Rt
時刻t 観測 利益率( ),γ 割引率
,f 投資比率 表 .割引複利利益率 ,
対数 取 ,従来 強化学習 同 再帰的 形
表 . ,行動規則π 下 状態s
価値Vπ
(
s)
行動規則π 下 状態s 行動a 価
値Qπ
(
s,a)
次 表 .Vπ
(
s) =
E π[ log
∞
∏
k=0
(
1+
Rt+k+1f)
γk
st
=
s]
=
∑
a∈A
π
(
s,a)
∑
s′∈S
P
ssa′ (Rssa′
+
γVπ(
s′)
) (1)Qπ
(
s,a) =
E π[ log
∞
∏
k=0
(
1+
Rt+k+1f)
γk
st
=
s,at=
a]
=
∑
s′∈S
P
ssa′(Rssa′+
γVπ(
s′)
) (2),π
(
s,a)
行動規則π 下 状態s 行動a選択 確率(行動選択確率),
P
ass′ 状態s 行動
a 行 次 状態 s′ 確率(状態遷移確率),
Rass′ 状態s 行動a 行 次 状態 s′
The 28th Annual Conference of the Japanese Society for Artificial Intelligence, 2014
Algorithm 1複利型OnPS .
入力:割引率γ,強化学習率α,初期優先度p,初期投資比率f,投資 比率学習率η
for alls,ado
P(s,a) p 初期化
f(s,a) f 初期化
end for
loop(各 対 繰 返 )
c(s,a)←0 for alls,a
状態s 初期化
repeat( 各 対 繰 返 )
P 導 行動規則 従 s 行動a 選択 c(s,a)←c(s,a) +1
行動a 実行 ,利益率R 次 状態s′ 観測 for alls,ado
P(s,a)←P(s,a) +αlog(1+R f(s,a))c(s,a)
c(s,a)←γc(s,a) end for
f(s,a)← f(s,a) +η1+R fR(s,a)
s←s′
untils 終端状態
end loop
得 利益率 投資比率 掛 1 加
対数 期待値
Rass′
=
Eπ[
log
(
1+
rt+1f)|
st=
s,at=
a,st+1=
s′] (3)表 .複利型強化学習 , s, a 対
Qπ
(
s,a)
最大化 行動規則π 学習 .
本論文 ,取引戦略 学習 勾配法 用
投資比率最適化 複利型OnPS [後藤13,松井13b] 用
.複利型OnPS Algorithm 1 示 .
複利型強化学習 状態 ,終値 移動標準偏差 基
二次元空間 表現 .株価 大 変動 ,直近
比較 相対的 値 正規化
,株価 大 異 場合 学習 行動規則 利用
.具体的 ,移動平均 移動標準偏差 算
出期間 k ,以下 相対化[Matsui 09] .
ot
=
vt−
µt,k4σt,k (4)
,vt t 値,µt,k 時刻t 直近k個
求 移動平均,σt,k 同 移動標準偏差 表 .終値
相対化 値 相対終値(RCP),移動標準偏差 相対化
値 相対移動標準偏差(RMSD) 呼 .RCP 正
現在 株価 移動平均株価 大 , ,株価 上
昇 表 .RMSD 正 現在 標
準偏差 移動平均標準偏差 大 , ,株価 変動
大 表 . 値 共 連続
値 ,15
×
15 格子状 配置 動径基底関数 用線形関数近似 行 .
行動 買 売 2種類 .株式
購入 状態 ・ ,株式 信用売
状態 ・ . ,複
利型強化学習 学習 取引戦略 行動 選択
, 勾配法 学習 投資比率 f
大 調整 .
3.
TradeStation
Strategy
構築
TradeStation ,米国 TradeStation社 提供 個
人投資家向 実取引環境 .TradeStation ,米国
株式, ,先物,FX 4種類 金融商品 取引
行 , 行
.2011年4月 ・
同社 株 買収 ,日本向
公開 予定 .本研究 ,米国 版
TradeStation9.1 使用 .
TradeStation 自動取引 ,Strategy 呼 .Strategy ,TradeStation 提供 様々 機 能 ,Chart 呼 機能 適用 .
Strategy ,EasyLanguage 呼 専用 言語 記述 .TradeStation TradeStation Development Envi-ronment 呼 EasyLanguage専用 開発環境 用意
, 利用 Strategy 作成・編集 .
TradeSta-tion ,銘柄,時間足,期間 指定 ,指令
銘柄,時間足,期間 Chart(時系列 ) 作成 .
Chart Strategy 適用 ,Strategy 記述
従 , 期間 行 .
EasyLanguage ,TradeStation専用
記述 言語 .例 ,
Buy 100 shares next bar at market;
命令 ,次 足(next bar) 成行(at market)
100株(100 shares)買注文 出 (Buy) 表 .
,単純 専用 ,
,実取引 前提 言語 ,複利型強化学習
用 Strategy 構築 上 必要 中
取引 ,保有資産評価額,総資産額等 計算
API 用意 . , ,強化学
習 上 必要 ,保有資産評価額,総資産額
取引記録 基 算出 .
本論文 ,状態変数 相対終値 相対移動標準偏差
直近30足 求 .相対化 前 移動標
準偏差 計算 直近30足 用 ,状態変数
求 直近60足 必要 .証券取引所 ,
平日 昼間 取引 行 ,市場 開 直後 ,
直近60足 前日 含 .市場 開
直後 株価 前日終値 大 乖離
,本研究 ,市場 開 60足 間 取引 行
.
実際 Strategy TradeStation 実行画 面 図1 示 .Chart 横軸 時間,縦軸 株価 示 ,
(移動標準偏差) 表示 .足 対
下 矢印 買注文,上 矢印 売注文 ,数値
取引 株数 示 .Chart中 縦 破線 営業日 境目 示
. Chart ,営業日 境目 株価 大 変
確認 . ,市場 開 間,
取引 行 確認 .
我々 ,[長瀬13] ,上場投資信託 SPDR S&P
500 ETF Trust (SPY) 取引対象 ,時間足 1分足,手数
料 0 実験 行 .学習期間 1週間,2週間,1
月,3 月,6 月,1年,2年,運用期間 1日 ,
無作為 30回 行 ,利益率,最大
, 評価 .参考 ,2012年
2013年 SPY 値動 (日足終値) 図2 示 .
The 28th Annual Conference of the Japanese Society for Artificial Intelligence, 2014
図1: TradeStation 実行画面.
図2: SPDR S&P 500 ETF Trust (SPY) 値動 .
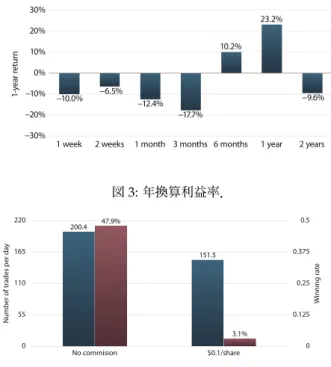
図3 ,30回 結果 幾何平均利益率 1
年間 250営業日 年換算 利益率 求 結果 .
学習期間 3 月以下 2年 利益
,学習期間 6 月 年換算
10.2%,学習期間 1年 年換算 23.2% 利益
. ,学習期間 1年 ,
利益 取引戦略 獲得 確認 .
, 結果 手数料 ,
手数料 一株当 $0.1 ,極端 勝率 悪 ,利
益 出 判明 . ,購入価格
価格 動 関 ,細 取引
行 . ,本論文 ,以下 手数料対
策 提案 .
4.
手数料対策
,株価 購入価格 変動 手数料分 小 間
,取引 . ,購入価格 変動
手数料分 小 間 , 取引 行 必 損
失 発生 .実際 ,損失 発生
取引 行 場合 得 , ,
場合 考 .
次 ,現在学習中 最適投資比率 実際 投資比率 乖離
際 生 追加注文 部分決済 調整
取 . 調整 行 ,細
取引 大幅 削減 期待 . 調整
行 ,平均購入価格 変動 ,変動 手数料分 小
間 取引 行 対策 影響 大 .
例 ,追加注文 行 ,平均購入価格 上昇 ,平均
購入価格 対 手数料 上乗 分 上昇 取引
図3:年換算利益率.
図4:定数量導入前後 学習期間中 一日 取引回数
勝率 比較.
行 .
,含 益 状態変数 追加 . ,
状態 相対終値,相対移動標準偏差,含 益 3次
元 表現 . , ,現在含 益
出 知 ,含 益 出
決済 行動 学習 期待 .
,状態変数 加 状態 特徴数 増 ,動径
基底関数 15
×
15×
15 9×
9×
9 格子状 配置.
5.
実験結果
提案 手数料対策 有効性 確認 ,実験 行
.取引対象 手数料対策 導入 前 同 SPY ,時
間足 導入前 同 1分足 .2013年 各月 第3水曜
日 期間 , 直前 1年間 学習期間 .結
果 図5 示 .
左側 縦棒 一年 250営業日 換算 一日
取引回数 表 ,右側 棒 勝率 表 .手数
料 導入 勝率 47.9% 3.1% 激減 ,提案
手法 手数料対策 行 勝率 37.1%
回復 .一日 取引回数 ,手数料
200.4回 対 ,手数料 導入 後 151.5回,手
数料対策 行 24.5回 .
,取引 勝 状況 絞 込 ,負
取引 大幅 削減 意味 .一日 勝
取引回数 ,手数料対策 行 ,4.71回
9.09回 増加 .
提案 手数料対策 勝率 大幅 改善 ,手
数料 場合 運用成績 正 .
,個人投資家向 手数料 適用 場合
, 頻繁 行 利益 得 難
.
The 28th Annual Conference of the Japanese Society for Artificial Intelligence, 2014
図5:学習期間中 一日 取引回数 勝率.
6.
本論文 ,複利型強化学習 用 取引戦略 獲得 手
法 TradeStation上 実装 , 行 方法
述 .本手法 直近 状態変数 求
, 市場 開 直後 状態変数
前日 影響 受 ,前日 影
響 間 取引 行 .本手法 用 評価 ,
学習期間 1年 複利利益率 最大
確認 . ,手数料 ,勝率 極端
下 利益 出 .
,本論文 ,手数料対策 ,価格 変動 手数
料分 小 間 取引 行 ,資産評価額 変動
状態 遷移 実際 投資比率 推定 最
適投資比率 乖離 調整 行 ,状態
変数 含 益 加 3点 提案 .実験 ,
提案手法 用 手数料 場合 勝率 大
改善 確認 .
,勝率 改善 ,運用成績 正
. 個人投資家向 手数料
場合 資産 安定的 運用
難 ,今後 ,強化学習
等 運用成績 正 検討 行
.
留意事項
本論文 三菱東京UFJ銀行 公式見解 表
.
謝辞
本研究 使用 TradeStation
証券株式会社 提供 . 感謝
意 表 .
参考文献
[Matsui 09] Matsui, T., Goto, T., and Izumi, K.: Acquiring a government bond trading strategy using reinforcement learning,Journal of Advanced Computational Intelligence and Intelligent Informatics, Vol. 13, No. 6, pp. 691–696 (2009) [Matsui 12] Matsui, T., Goto, T., Izumi, K., and Chen, Y.:
Compound Reinforcement Learning: Theory and An Ap-plication to Finance, in Sanner, S. and Hutter, M. eds., Recent Advanced in Reinforcement Learning: Revised and
Selected Papers of the European Workshop on Reinforcement Learning 9 (EWRL 2011), Vol. 7188 ofLecture Notes in Com-puter Science, pp. 321–332 (2012)
[後藤13] 後藤 卓,松井 藤五郎,大澄 祥広:複利型強化学習 株
式取引 応用,第27回人工知能学会全国大会(JSAI 2013),
4I1-OS-16-4 (2013)
[鳥海06] 鳥海 不二夫:株式売買 株
作 !,秀和 (2006)
[中原13] 中原 孝信,羽室 行信,岡田 克彦,宇野 毅明:強化学
習 用 相場 検知 株取引 適用,第27回人
工知能学会全国大会(JSAI 2013), 1E4-3 (2013)
[長瀬13] 長瀬 舜, 松井 藤五郎, 後藤 卓, 和泉 潔, 陳 , 鳥
海 不二夫:TradeStation 複利型強化学習 用
Strategy構築,第12回人工知能学会金融情報学研究会 (SIG-FIN), pp. 51–55 (2013)
[松井07] 松井 藤五郎: 招待–人工知能 用 株
式取引–,人工知能学会誌, Vol. 22, No. 4, pp. 540–547 (2007)
[松井09] 松井 藤五郎,後藤 卓:強化学習 用 金融市場取
引戦略 獲得 分析, 人工知能学会誌, Vol. 24, No. 3, pp.
400–407 (2009)
[松井11a] 松井 藤五郎:複利型強化学習,人工知能学会論文誌,
Vol. 26, No. 2, pp. 330–334 (2011)
[松井11b] 松井 藤五郎,後藤 卓,和泉 潔,陳 :複利型強化学
習 枠組 応用,情報処理学会論文誌, Vol. 52, No. 12, pp.
3300–3308 (2011)
[松井13a] 松井 藤五郎:複利型強化学習—強化学習
応用—,計測 制御(計測自動制御学会誌), Vol. 52,
No. 11, pp. 1022–1027 (2013)
[松井13b] 松井 藤五郎,後藤 卓,和泉 潔,陳 :複利型強化学
習 投資比率 最適化,人工知能学会論文誌, Vol. 28,
No. 3, pp. 267–272 (2013)