モーメントカーネルを用いた分類手法の分析
Moment Kernel Application to Classification
田中謙次
1∗申吉浩
1Kenji Tanaka
1Kilho Shin
11
兵庫県立大学大学院応用情報科学研究科
1
Graduate School of Applied Informatics, University of Hyogo
Abstract: The purpose of this study is to investigate the application methods of moment kernel to classi-fication.
1
はじめに
近年、構造を持つデータのカーネルの重要性が増し ており、文字列データや木構造データへの応用事例も 多く報告されている [1][2][3]。 モーメントカーネルは、データ間の情報をより多く 利用するためのカーネルとして提案された [4]。モーメ ントカーネルには次数のパラメータがある。モーメン トカーネルを利用する場合、異なる次数のモーメント を組み合わせる方法や、組み合わせる次数の選択につ いて考える必要がある。しかし、モーメントカーネル の既存の手法への応用事例は報告されておらず、応用 手法についても研究がなされていない。本研究では、木 構造データと SVM を用いた実験を通して、モーメン トカーネルの分類への応用方法について分析する。2
マッピング
2.1
要素とオブジェクト
構造を持つデータのように、要素から構成されたデー タをオブジェクトと呼ぶことにする。原始的要素の集 合をΩ とし、オブジェクトの空間を W とする。 例 1 (文字列) Σ をアルファベットとし、Ω = Σ×N とす る。k 文字の文字列 X⊂ Ω は X = {(s1, 1) , ..., (sk, k)} と表すことができる。例えばΣ = {A,C,G,T} とする と、Y = GTAC は Y ={(G,1),(T,2),(A,3),(C,4)} と表現する。 例 2 (根付きの順序木) 根付き木をノードの半順序集合 として捉える。ノード s がノード v の祖先である時、 ∗連絡先: 兵庫県立大学大学院応用情報科学研究科 〒 650-0047 神戸市中央区港島南町 7-1-28 E-mail:[email protected] s > v とする。Ω をノードの集合とすると、次の 2 つの 条件を満たす X⊂ Ω が根付き木となる。 1. 根 r∈ X が存在し、任意の v ∈ X に対して r ≥ v が成り立つ 2. 任意の v∈ X について、Vv={w|w ≥ v} が全順序 集合となる。 さらに、根付き木に兄弟順序を導入したものが順序 木となる。兄弟順序の導入のために葉と NCA を導入す る。子を持たないノードのことを葉と呼ぶ。また、v◦w は、v, w の最も近い共通の祖先 (NCA) を表す。 1 2 3 4 5 6 7 図 1: 順序木 葉の集合を L とし、任意の 1≤ i < j < k ≤ |L| に対 して、li◦ lj◦ lk = li◦ lkを満たすように葉に番号を付 け L ={l1, . . . , l|L|} とする。図 1 の木には、条件を満 たすように葉に番号が振られている。兄弟順序≺ を、 v≺ w ⇔ max{i | li≤ v} < min{i | li≤ w} と定義する。
2.2
マッピングの導入と木のマッピング
2 つのオブジェクト X ,Y の要素を対応させることを 考える。X,Y の要素数の等しい部分集合 A⊆ X,B ⊆ Y に関して、要素の 1 対 1 の対応関係µ: A→ B をマッ 人工知能学会研究会資料 SIG-FPAI-B803-17ピングと呼ぶ。マッピングを2つのオブジェクト間の 部分写像と言い換えることもできる。X,Y 間のマッピ ングからなる集合を MX ,Y と表す。µX ,Y ∈ MX ,Y∧µY,Z∈ MY,Z→µX ,Y◦µY,Z∈ MX ,Zを満たすとき、マッピングが 推移的であるという。推移性は、後述のカーネルが正 定値性を満たすために必要となる重要な概念である。 次に、本研究の実験で用いる順序木のマッピングを 導入する。 定義 1 (Ta¨ıマッピング) 世代順序と兄弟順序を保存する マッピングを Ta¨ıマッピングという。 定義 2 (束縛マッピング) Ta¨ıマッピングであり、任意の xk, xi, xj∈ Dom(µ) に対して、xi̸≷ xj, xj̸≷ xk, xk̸≷ xi, xi◦ xj= xi◦ xk⇒µ(xi)◦µ(xk) =µ(xj)◦µ(xk) が成り立つ マッピングµを束縛マッピング (constrained mapping) という。 定義 3 (ルーマッピング) Ta¨ıマッピングであり、任意の xk, xi, xj∈ Dom(µ) に対して、xi◦ xj= xi◦ xk⇔µ(xi)◦ µ(xk) =µ(xj)◦µ(xk) が成り立つマッピングµをルー マッピング (lu mapping) という。 定義 4 (合意部分木マッピング) 任意の xi, xj∈ Dom(µ) に対して、µ(xi)◦µ(xj) =µ(xj◦ xj) が成り立つマッピ ングのことを合意部分木マッピング (agreement subtree mapping) という。また、マッピングの定義域と像が合 意部分木になっている。 本節の最後に、特徴的な木の形を導入する。全ての ノードが子を 1 つ以下しか持たない木を Path と呼ぶ。 また、根が 1 つ以上の子を持ち、それ以外のノードが 1 つ以下の子しか持たない形を Cascade と呼ぶ。根が 2 つの子を持ちそれ以外のノードが子を 1 つ以下しか持 たない木のことを Worm と呼ぶ。図 2 は、Path、Worm、 Cascade の例である。 図 2: 木の形の例. また、マッピングの定義域と像が特定の形になって いるものをその形の名前で呼ぶことがある。例えば、 マッピングの定義域と像が Path となっている場合、そ のマッピングを Path マッピングと呼ぶ。
2.3
類似度評価指標
マッピングによって対応する要素の類似性を評価す る指標を導入する。要素の類似度指標φ:Ω × Ω → R から類似度評価指標を次のように定義する。 Φ(µ) =∏
(x,y)∈µφ (x, y) 2 つのオブジェクト X ,Y 間の類似性の率直な評価方 法として max{Φ(µ)|µ∈ MX ,Y} を利用する手法がある。 編集距離は、max{Φ(µ)|µ∈ MX ,Y} を用いて表すこと ができる [4]。2.4
マッピングカーネル
要素間のマッピング集合と類似度指標を用いたカー ネルにマッピングカーネル [5] がある。 定義 5 (マッピングカーネル) K (X ,Y ) =∑
µ∈MX ,Y Φ(µ) マッピングが推移的であり、要素の類似度指標φ:Ω× Ω → R が正定値であれば、マッピングカーネルは正 定値カーネルとなる [5]。カーネルが正定値であれば、 データを再性核ヒルベルト空間上に移すことができ [6]、 SVM や PCA といった手法を応用することができる。3
確率分布とモーメント
モーメントカーネルを導入する準備として確率分布 とモーメントについてみる。3.1
モーメント
モーメントは確率分布を記述する統計量である。確 率変数 X、定数α に対して、 E[(X −α)n] と定義され、α まわりの n 次モーメントという。E は 期待値である。 よく利用されるモーメントとして、0まわりの1次 モーメントである平均、平均まわりの2次モーメント である分散、3次標準化モーメントである歪度、4次 標準化モーメントである尖度が挙げられる。3.2
特性関数
X を標本空間R 上の確率変数とし、その確率密度関 数を fXで表す。 fXのフーリエ変換 ˆfXを、X の特性関 数と定義する。即ち、 ˆ fX(t) = ∫ ∞ −∞e itxf X(x)dx =E(eitX) が成り立つ。フーリエ逆変換により、fXと ˆfXの間には 一対一の関係があることが分かる。一方、eitxを t = 0 の周りでのテーラー展開する。 ˆ fX(t) = ∫ ∞ −∞ ∞∑
n=0 (itx)n n! fX(x)dx において、極限と積分が可換であると仮定すると、 ˆ fX(t) = ∞∑
n=0 (it)n n! ∫ ∞ −∞x nf X(x)dx = ∞∑
n=0 inE(Xn) n! t n が得られ、これは ˆfX のテーラー展開となるが、その 係数は X のモーメントにより決定される。即ち、X の モーメントが ˆfXを一意に決定し、従って、 fXを一意 に決定する。 極限と積分はいつでも可換であるわけではなく、一 般には、優収束定理1が必要となるが、関数 f nが測度 有限な共通の台 S を持ち(x̸∈ S ならば常に fn(x) = 0 であり、かつ、∫ Sµ<∞ が成り立つ)、更に、fnが f に 一様収束する場合は、 ∫Dfndµ− ∫ D f dµ ≤ ∫ S| fn− f |dµ→ 0 であるので、可換性が成り立つ。 本論文で扱う離散有限確率分布の場合、即ち、R ⊃ D ={x1, . . . , xd} 上で確率分布が与えられる場合は、D 上の数え上げ測度に関して∫ Ddµ= d が成り立ち、か つ、確率分布 fX(xi) = Pr[X = xi] に関して gn(xj| t) = ∑n k=1k!1(itxj) kf X(xj) は、g(xj| t) = eitxjfX(xj) に一様収 束する。従って、 d∑
j=1 eitxjf X(xj) = ∫ D eitxfX(x)dµ = ∞∑
n=0 in k! (∫ D xxfX(x)µ ) tn = ∞∑
n=0 in k!E(X n)tn が成り立つ。一方、{eitxj} は一変数実関数空間において 一次独立であるので、∑ fX(xj)eitxjとベクトル ( fX(x1), . . . , 1測度空間 (D,F ,µ) 上の可積分関数族 f n が f に各点収束し、 かつ、可積分関数 g が存在して、| fn(x)| ≤ g(x) が常に成り立つ時、 limn→∞∫Dfndµ= ∫ Df dµが成り立つ。 fX(xn)) は一対一に対応し、{E(Xn)| n = 0,...,∞} が与 えられれば、 fX が一位に定まることが分かる。 D が有限集合の場合は、∫Dextdx は収束するので、母 関数で同様の議論ができる。より直接的に、以下のよ うに示すことも可能である。 E(1) E(X) E(X2) .. . E(Xd−1) = 1 1 . . . 1 x1 x2 . . . xd x21 x22 . . . x2d .. . ... . .. ... xd−11 xd−12 . . . xd−1d fX(x1) fX(x2) fX(x3) .. . fX(xn)) = M fX(x1) fX(x2) fX(x3) .. . fX(xn)) 一方、|M| = ∏i> j(xi−xj)̸= 0 が成り立つので、次の定 理が成り立つ。 定理 1 有限集合{x1, . . . , xd} ⊂ R 上の確率分布は、1 次 から (d− 1) 次のモーメント E(X),...,E(Xd−1) により 一意に決定される。4
モーメントカーネル
マッピングの類似度指標Φ(µ) の分布を評価するこ とを目的にモーメントカーネルを導入する。編集距離 は、本質的に max{Φ(µ)|µ∈ MX ,Y} を評価するもので 分布全体を評価するものではない。一方、マッピング カーネルに 1 |MX ,Y|を乗じると、Φ(µ) を標本とする確率 変数の 1 次モーメントになる。マッピングカーネルだ けでは分布全体を評価できないが、3節で見たように 高次モーメントを合わせることで、分布全体を評価す ることが可能になる。従って、モーメントカーネルを 以下のように定義する。 定義 6 (モーメントカーネル [4]) Kn(X ,Y ) =∑
µ∈MX ,Y Φ(µ)n マッピングが推移的であり、要素の類似度指標φ:Ω× Ω → R が正定値であれば、モーメントカーネルは正定 値カーネルとなる [4]。 モーメントカーネルを分析手法に応用する場合に、 モーメントカーネルの次数について考えなければなら ない。より多くの情報を利用するためには、異なる次 数のモーメントを組み合わせる方が良いと考えられる。 異なる次数のモーメントカーネルを組み合わせる手法 として率直なものに、モーメントカーネルの和を用いる手法がある。よく知られている通り、正定値カーネ ルの和は正定値カーネルとなり、また、対応する再生 核ヒルベルト空間は足し合わせたカーネルに対応する 再生核ヒルベルト空間の直積空間となる。
5
実験
1
5.1
実験内容
3 種類の木構造データを用いた分類実験を通して、異 なる次数のモーメントを組み合わせることの有効性を 調査する。本実験では、モーメントカーネル Kn(X ,Y ) と次の 2 つのカーネルを比較する。 K0,n(X ,Y ) = n∑
i=0 Ki(X ,Y ) K1,n(X ,Y ) = n∑
i=1 Ki(X ,Y ) K0,n(X ,Y ) は 0 次モーメントカーネルから n 次モーメ ントカーネルを足したカーネルであり、K1,n(X ,Y ) は 1 次モーメントカーネルから n 次モーメントカーネルを 足したカーネルである。n を 0 から 15 までの自然数で 実験を行い、n の値と分類精度の推移を見るとともに、 単独のモーメントカーネル Kn(X ,Y ) との比較を行う。 分類手法には SVM を使用し、5分割の交差検証を 行い評価する。マッピングは 23 種類を試し、要素の類 似度指標には φ(x, y) = { α(x = y の時) β(x̸= y の時) を使用する。ただし、α≥βとする。5.2
データセット
KEGG/GLYCAN データベース [7] から生成された 3 つの糖鎖と疾患のデータセットを使用する。データセッ トは病気の発症の有無によりクラスラベルが与えられ ており、病気を発症している人間から採取された糖鎖 を正例(ラベル「+1」)、そうでない人間から採取した 糖鎖は負例(ラベル「−1」)としている。本実験で使 用する 3 つのデータセットは Colon-cancer(大腸癌)、 Cystic-fibrosis(嚢胞性線維症)、Leukemia(白血病)の データセットである。 表 1: データセット データセット データ数 正例数 負例数 Colon-cancer 134 87 47 Cystic-fibrosis 160 89 71 Leukemia 479 177 302 表 2: マッピングの表記 p1:ギャップの有無 a 合意部分木マッピングである c ギャップを認めない s ギャップを認める p2:マッピングの形 c マッピングの形が Cascade である ct マッピングが Contiguous Tree[3] p マッピングの形が Path である t マッピングの形が木である w マッピングの形が Worm である f マッピングの形が森である lu ルーマッピング cd 束縛マッピング p3:根同士の対応 i 根同士が対応する必要はない r 根同士の対応を必ず含む5.3
使用するマッピング
マッピングは 3 つのパラメータ p1, p2, p3を用いて、 [8] で導入された記法に基づいて p1-p2-p3と表す。 本実験で用いるマッピングは、a-t-i、a-t-r、c-c-i、c-c-r、c-ct-i、c-ct-r、c-p-i、c-p-r、c-t-i、c-t-r、c-w-i、c-w-r、 s-c-i、s-c-r、s-cd-i、s-f-i、s-lu-i、s-p-i、s-p-r、s-t-i、s-t-r、 s-w-i、s-w-r の 23 種類である。5.4
パラメータの調整
要素の類似度指標のパラメータα,β、および、SVM の パラメータ C は、ベイズ最適化を用いて調整した。ベイ ズ最適化で使用した評価指標は Accuracy = T P+T N T P+FN+FP+T N である。探索範囲はそれぞれ、1.0≤α≤ 2.0,0.0 ≤β≤ 1.0,0.0 < C≤ 100.0 とした。5.5
実験1の結果
はじめにデータセットごとの Accuracy の最高値と、 その時のマッピングとカーネルの種類を表 3 にまとめ る。Colon-cancer と Leukemia では、0 次モーメントカー ネルと 1 次モーメントカーネルを足し合わせたカーネ ルがもっとも良い成果を出している。ここから、異な表 3: データセットごとの Accuracy の最高値 データセット マッピング カーネル Accuracy Colon-cancer a-t-i K0,1 0.948 s-lu-i K0,1 0.948 Cystic-fibrosis s-lu-i K4 0.813 Leukemia s-c-i K0,1 0.921 る次数のモーメントカーネルを組み合わせて使うこと が有用であると言える。 次に、n の値と Accuracy の推移に注目する。Colon-cancer で Accuracy が高かった a-t-i マッピングに注目す る。下の図 3 は、データセット Colon-cancer でマッピ ング a-t-i を用いた場合の、Accuracy の推移を示したグ ラフである。 図 3: n と Accuracy の推移。データセットは Colon-cancer、マッピングは a-t-i である。 K0,nに注目すると、K0,1で最高値となり、それ以降 は Accuracy が僅かな増減をしながらほぼ一定となって いる。K1,nの場合も同様である。同様の傾向は、他の データセットとマッピングの組み合わせでも頻繁に見 られる。 これらのことから、モーメントカーネルを組み合わ せることは有効な手法であること、組み合わせる数を 多くすれば良いというわけではないことが分かる。
6
実験
2
6.1
実験内容
実験 1 では異なる次数のモーメントカーネルを組み 合わせることの有用性と、組み合わせる次数の選択の 重要性を見た。本章では、3 種類の木構造データを用 いた実験を通して、組み合わせる次数の選択方法につ いて分析を行う。組み合わせる次数について知見を得 るために、0 次から 5 次までの全ての組み合わせを試 す。つまり、次のカーネル KD(X ,Y ) =∑
i∈D Ki(X ,Y ) を空集合を除く全ての D⊂ {0,1,2,3,4,5} に対して計 算し、各々を用いた場合の分類結果を比較する。 実験 1 と同様に、SVM による分類を行い、5分割の 交差検証によって評価する。使用するマッピングは実 験 1 と同じ 23 種類、要素の類似性指標φ(x, y) も実験 1 と同じものを使用した。6.2
パラメータの調整
要素の類似性指標のパラメータα,β、および、SVM のパラメータ C はグリッドサーチを用いて調整した。C の探索範囲は{1,10,100,1000} とし、α はβ、0以上 2以下の範囲を 0.1 刻みで探索した。6.3
実験 2 の結果
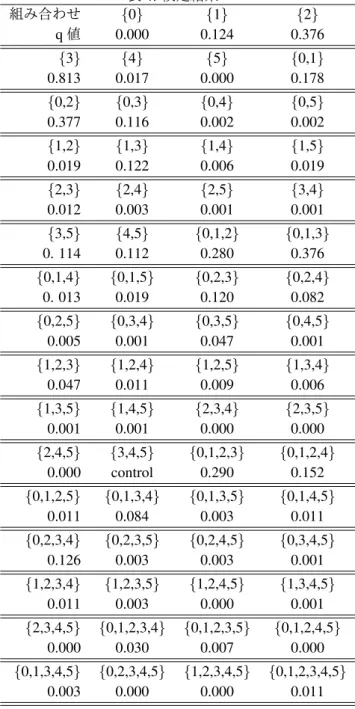
次数の組み合わせによる Accuracy の差を見るために、 Wilcoxon の符号順位検定と Benjamini-Hochberg 法 [9] による多重比較検定を行う。最も Accuracy の順位が高 かった{3,4,5} を control として、{3,4,5} と他の組み合 わせに差があるかを検定した。その結果を表 4 に示す。 {0,3,4},{0,2,4},{0,1,3,4},{3,5},{0-2-3},{1},{0,1,2,4}, {0,1},{0,1,2},{0,1,2,3},{2},{0,1,3},{0,2},{3} が棄却でき ず、差があるとは言えないという結果になった。特に、 マッピングカーネルと等価である{1} や、マッピング カーネルの探索範囲を変えたものと等価な{2} や {3} と差が出なかった。7
今後の課題
実験 2 では、明確な差を検出することが出来なかっ た。実験2では、検定を行うための標本の要素をデー タセットとマッピングの組ごとの Accuracy の最大値と したが、この方法はあまり良い方法ではない。マッピン グの種類も調整するべきパラメータとして扱い、デー タセット毎に値を取る手法が良いだろう。その手法で 検定を行うためには、より多くのデータセットでの実 験が必要となる。また、本研究で使用したデータセッ トは、全て糖鎖のデータセットである。普遍的な傾向 を調べるためにも、糖鎖以外のデータセットで実験す る必要がある。 本研究では、モーメントカーネルを組み合わせる手 法について、モーメントカーネルの和をとる手法を採 用した。しかし、重み付きの和を取る等の他の手法も表 4: 検定結果 組み合わせ {0} {1} {2} q 値 0.000 0.124 0.376 {3} {4} {5} {0,1} 0.813 0.017 0.000 0.178 {0,2} {0,3} {0,4} {0,5} 0.377 0.116 0.002 0.002 {1,2} {1,3} {1,4} {1,5} 0.019 0.122 0.006 0.019 {2,3} {2,4} {2,5} {3,4} 0.012 0.003 0.001 0.001 {3,5} {4,5} {0,1,2} {0,1,3} 0. 114 0.112 0.280 0.376 {0,1,4} {0,1,5} {0,2,3} {0,2,4} 0. 013 0.019 0.120 0.082 {0,2,5} {0,3,4} {0,3,5} {0,4,5} 0.005 0.001 0.047 0.001 {1,2,3} {1,2,4} {1,2,5} {1,3,4} 0.047 0.011 0.009 0.006 {1,3,5} {1,4,5} {2,3,4} {2,3,5} 0.001 0.001 0.000 0.000 {2,4,5} {3,4,5} {0,1,2,3} {0,1,2,4} 0.000 control 0.290 0.152 {0,1,2,5} {0,1,3,4} {0,1,3,5} {0,1,4,5} 0.011 0.084 0.003 0.011 {0,2,3,4} {0,2,3,5} {0,2,4,5} {0,3,4,5} 0.126 0.003 0.003 0.001 {1,2,3,4} {1,2,3,5} {1,2,4,5} {1,3,4,5} 0.011 0.003 0.000 0.001 {2,3,4,5} {0,1,2,3,4} {0,1,2,3,5} {0,1,2,4,5} 0.000 0.030 0.007 0.000 {0,1,3,4,5} {0,2,3,4,5} {1,2,3,4,5} {0,1,2,3,4,5} 0.003 0.000 0.000 0.011 考えられるため、別の手法についても検証する必要が あるだろう。 また、類似度指標α,β の値が僅かに変わるだけで、 分類結果が変わる場合がある。より良い精度を出すため には、α,βの最適化手法についても改善が必要である。
参考文献
[1] Xu, J. C., Shin, K., Liu, Y. L.: Detecting Fake Sites based on HTML Structure Analysis, In Proceedings
of the 6th International Conference on Communica-tion and Network Security 86-90 (2016)
[2] Leslie, C., Eskin, E., Noble, W. S.: The spectrum kernel: A string kernel for SVM protein classifica-tion. In Biocomputing 2002 564-575 (2001)
[3] Collins, M., Duffy, N.: Convolution kernels for natu-ral language, In Advances in neunatu-ral information
pro-cessing systems, 625-632 (2002)
[4] 申吉浩. : 射にもとづく類似性理論, SIG-FPAI, 5(03), 58-63 (2016)
[5] Shin, K., Kuboyama, T.: A generalization of Haus-sler’s convolution kernel: mapping kernel, In
Pro-ceedings of the 25th international conference on Ma-chine learning, 944-951 (2008)
[6] Van Den Berg, C., Christensen, J. P. R., Ressel, P.: (2012). Harmonic Analysis on Semigroups: Theory of Positive Definite and Related Functions, Springer, (1984)
[7] Hashimoto, K., Goto, S., Kawano, S., Aoki-Kinoshita, K. F., Ueda, N., Hamajima, M., Kawasaki, T., Kanehisa, M.: KEGG as a glycome informatics resource, Glycobiology, 16(5), 63R-70R (2006)
[8] Shin, K., Kuboyama, T.: A comprehensive study of tree kernels. In JSAI International Symposium on
Ar-tificial Intelligence , 337-351 (2013)
[9] Benjamini, Y., Hochberg, Y.: Controlling the false discovery rate: a practical and powerful approach to multiple testing, Journal of the Royal statistical
society: series B (Methodological), 57(1), 289-300