データ研磨によるコンセンサスクラスタリングの精緻化
Stabilize and Elaborate Concensus Clustering by Data Polishing
宇野 毅明
1∗岩崎 幸子
1中原 孝信
2中元 政一
3羽室 行信
3Takeaki UNO
1, Sachiko IWASAKI
1, Takanobu NAKAHARA
2,
Masakazu NAKAMOTO
3, Yukinobu HAMURO
13 1国立情報学研究所
1
National Institute of Informatics
2専修大学
2Senshu University
3関西学院大学
3
Kwansei Gakuin University
Abstract: Concensus clustering is a method to take the concensus of several clustering results. Usually the objective of the method is to improve the accuracy, but here our goal is to make a clustering algorithm stable. Unstability of clustering caused by randomness of clustering algorithms is a big issue in the use of clustering algorithms in practice. Especially, it makes the data analysts hard to tackle with the interpretation. Our way of stabilization is to cluster the clustering results and take the concensus of each cluster, as usual concensus clustering way. By using data polishing algorithm for this cluster-clustering, we could get a stable result that is siginificantly better than the usual clustering algorithms.
1
はじめに
クラスタリングは,教師無し学習の中でも中心的な 問題の一つである.とくに,マーケッティングなどで の現実社会でのデータ分析においては,それしかない というほどの存在感があると言ってもいいだろう.そ の一方で,クラスタリングを行う際には大きな困難性 が伴うことが多い.クラスタリングによってデータは いくつかのクラスタに分割され,得られたクラスタ自 体は良い評価値を得ていることも多いのだが,なぜそ のように分かれたのか,その意味はなんなのか,それ ぞれのクラスタはいったい何者なのか,といった本質 的な観察を得ることが難しいのである.この,意味解 釈の難しさは,現実社会でのデータ解析全般に見られ ることであり,この分野に横たわる大きな課題である と言ってよいだろう.たとえば,データ解析を受けおっ たとき,解の提示自体は簡単にできるのだが,その解 から得られる知識を言語化,あるいは可視化して,依 頼者に貢献できるような成果物を得ることは,一筋縄 にできることではないのである. 一方で,クラスタリング手法自体にも,解釈性に関 わる問題をより難しくしている側面がある.その一つ が,ランダムに生成した初期解に計算結果が依存する ∗連絡先:国立情報学研究所 〒 101-8530 千代田区一ツ橋 2-1-2 E-mail: [email protected] ことである.著名な k-means[5] などのアルゴリズムは, 初期解としてランダムに k 個のクラスタ中心を生成し, そこから出発して局所最適解を出力する.よって,本 質的に,初期解に依存して解が大きく変わる可能性を 持っている.現実社会のデータ分析に携わる方々の多 くが,この点を大きく問題視している.依頼主に解を 提示するときに,これがなぜ良いのか,という根拠を 与えづらくしているのである.つまり,もう一回計算 し直したら,ひょっとしたらより良い解が見つかってし まうかもしれない,という不安を払拭しきれないので ある.この問題は解釈性にも大きく関わる.あるクラ スタリングの結果を解釈したとして,クラスタリング の結果が仮に唯一なのであれば,その解釈は,たとえ 今一つの物であっても,「がんばってもこれくらいしか わからない」という知見を与えることができる.しか し,他に解がいくらでも存在するなら,もっと上手に 解釈できて,役に立つ解があるかもしれない,という 不安が出てくる.結果として,データ解析者は何度も クラスタリングを実行し,大量の解を解釈して,その 中から納得がいくものを選ぶ,という,大変なコスト を伴い,かつ手法としては形の悪いアプローチをとる こととなる.著者らが独立に様々な人からこのような 話を聞いているため,現実にこのようなことは頻繁に 行われていると言ってよいだろう. ランダム性が入ったアルゴリズムの解を安定させる 定石の一つは, 何回もアルゴリズムを実行して多数の解 人工知能学会研究会資料 SIG-FPAI-B509-08を得, その平均, あるいは中心を求めて, 解とするもの である. 古くは最適化問題で多数の解を求めて頻度の 高い部分構造を部品として使うアイディアや, 近年では 機械学習におけるランダムフォレスト法がこれに対応 する. 実際のところ, クラスタリングに対しても同様の アイディアはすでにあり, コンセンサスクラスタリング (consensus clustering) あるいはアンサンブルクラスタ リング (ensemble clustering) とよばれ, いくつかの研 究がある. [11] にサーベイがある. しかし, 手法開発の 目的が精度の向上にあり, クラスタリングの安定化とい う点は着目されていない. クラスタリングの他の手法 も, クラスタリングの安定化に関して着目しているもの は, 少なくとも我々の知る限り存在しない. そもそも, クラスタリングは正解のない問題である. それに対して, 精度を, ある程度推測することは可能と しても, それを極限まで突き詰めることにどれほどの意 味があるのか, 我々にはわからない. 一方で, 現実世界 では, 精度の高まりが必ずしもクラスタの質を保証する ものではなく, ときには大きな乖離があるような状況で あり, その意味で精度の向上には興味が持たれていな いであろう. 一方で切実に願われることはむしろクラ スタリングの安定化であり, それが長い間見過ごされ, 実利用において大きな負荷を生んでいたことには忸怩 たる思いを禁じ得ない. クラスタリングの精度は, 数理 的に測りにくいが, クラスタリングの安定度合いは, 簡 単に測ることができる. それであるのに, 簡単に測れ て, かつ現実の要望の大きな問題に, 向き合わないとい う選択肢はありえないであろうし, それをしてこなかっ たことには大きな反省をするべきであると考えている. 本研究では, このような現状を鑑み, クラスタリング の安定化という「目的」を提唱し, 既存のクラスタリン グ手法, および既存のコンセンサスクラスタリングの安 定化度合を現実データの上で検証する. また, 我々が開 発しているデータ研磨手法をコンセンサスクラスタリ ングで利用し, 安定化度合の向上をする手法を提案す る. データ研磨はデータから似たものの集まりを明確 化させることで, 独立性を担保しつつ見つけるため, こ のような中心を取るタイプのクラスタリングには向い ている. また, 乱数や添え字順の変化による影響を受け ないため, 常に同じ解を得られる点も, 本研究の目的に 合致している. バスケットデータを用いた実験結果では, 既存のクラ スタリング, 特に k-means や k + + の結果は惨憺たる ものであり, 2つのクラスタリング A と B を比べる と, A のクラスタにもっとも似ている B のクラスタを 取ってきても, Jaccard 係数が 0.2 つまり, その共通部 分は 1/3 程度であることがわかった. これでは, とても 同じようなものを見つけているとは言えず, 毎回違うも のが出てきて安定しない, と言われてもしかたのないこ とであろう. PLSA を用いた場合は安定性は向上する が, それでも最も似ているものとの共通部分は 1/2 か ら 2/3 程度である. これを, コンセンサスクラスタリ ングを用いて安定化させると, k-means や k + + の場 合, 既存手法でも Jaccard 係数を 0.5 程度に, データ研 磨を用いれば 0.7 以上に高められることがわかった. データ研磨は実行速度の上でも非常に使いやすく, ア ルゴリズムもシンプルである. 意味解釈のしやすさも, 他のクラスタリングの結果と比べると抜群に良くなっ ている. ただし, まとまっている部分のみを見つけるた め, どのクラスタにも属さない要素が多く出てきてしま うという特性があるが, コンセンサスクラスタリングに 用いた場合は, そのような要素は全体の 2 割程度である こともわかった. これは実用では十分に全体の特徴を とらえていると言ってよいだろう. 結論としては, デー タ研磨を用いてクラスタリングの安定化を行うことで, 実用上非常に使いでの良いクラスタリングアルゴリズ ムが, 複雑なプロセスなしに利用できるようになったと 言えるだろう.
2
安定度の検証法とクラスタリング
安定化アルゴリズム
我々はこのような現状を鑑み,前回の研究会報告 [9] にて, 著名なクラスタリングが実際どの程度「不安定」 なのかを検証した. 4 千人ほどの買い物データを用いて ユーザをクラスタリングする, 典型的なマーケッティン グの問題において行ったテストでは, 2 つのクラスタリ ングの類似度の平均は k-means や k + + の場合に 0.2 程度であった. これは大きさ 10 のクラスタと, それに 最も似ている大きさ 10 のクラスタの共通部分が要素 3 個程度であるということである. これはとても安定し ているとは言いがたい. PLSA を用いれば多少類似度 は上がるが, それでも共通部分は 6 個程度である. そもそもクラスタリングの結果が安定しないのは,ク ラスタの境目がはっきりしないからである.もしも,す べてのデータ項目が,数カ所に集中していれば,それ がクラスタとして出力されるであろう.たとえ本来の クラスタの数と,アルゴリズムに分割数としてあたえ た k が異なる場合でも,いくつかのクラスタが分割さ れ,あるいはいくつかのクラスタが併合されるはずで, 初期値の異なりによる大きな変動はないであろう.し かし,現実のデータはこのように美しくはない.典型 的には,ある程度データ項目が集中している部位があ るだろう.その一方で,そのような集中領域から離れた 場所にあるデータ項目も多く存在する場合である.も し,クラスタリングアルゴリズムがある程度優秀であ れば,このようなデータの集中領域をあやまって分割 してしまうことは,k が本来のクラスタ数よりはるか に大きくない限り,少ないであろう.つまり,そのような,いわば「芯クラスタ」は,どのクラスタリング結 果においても,ある1つのクラスタに完全に含まれて おり,かつたいていはちょうど1つ,あるいは少数ず つ含まれているであろう.つまり,このような仮説の もとでは,いくつかのクラスタリング結果から,似て いるクラスタを集め,それらの多くに共通して含まれ るデータ項目を集めれば,芯クラスタが見つかるであ ろうと考えられる.このアイディアに基づいて安定化 手法を提案したのが [9] になる. その後, このアプロー チがコンセンサスクラスタリングという名前で研究さ れていることが判明したため, 今回は, 既存のコンセン サスクラスタリングの安定性と, 我々のデータ研磨によ るアプローチの安定度合いを比較するとともに, 解釈性 の良さについても検証を行った. 我々は以前からデータ研磨による新しいクラスタリ ング手法を開発し,改良を進めている [8, 7].データの 中から似た項目の集合を見つけるタスクに対するもの だが,パターンマイニングやコミュニティマイニング の手法が, 非常に似ているクラスタを大量に出力してし まう一方で,データ研磨はクラスタでありそうな部分 を濃く,クラスタでなさそうな部分を薄くすることで, 独立性が高いクラスタを網羅性高く発見することに成 功している.今回の問題に対して,データ研磨クラス タリングは非常に相性が良いと考えられる. 実際に検証した方法は, Meta-CLustering Algorithm (MCLA) と Cluster-based Similarity Partitioning Al-gorithm (CSPA) とである. ランダム性を持つクラスタ リングアルゴリズムを用いて,異なるランダムシード を用いてクラスタリングを h 回実行し,クラスタリン グ結果を h 個得る.MCLA では,h 個のクラスタリン グの各クラスタに対して,他のクラスタリングのクラ スタに対する Jaccard 係数を計算する.そして Jaccard 係数が θ 以上のクラスタのペアを集め,それらが枝と なっているようなグラフを構築する.これは,頂点集合 が h 個のクラスタリングのクラスタの集合で,Jaccard 係数が θ 以上の頂点間に枝が張られている類似度グラ フとなっている.このグラフを h 個のクラスタ集合に 再分割するのが既存手法である. ここで用いられたア ルゴリズムは METIS[4] である. 我々の方法では, こ こにデータ研磨を用いる. そして得られたクラスタ集 合に対して,そのメンバーのクラスタのうち, ρ 以上 の割合が共通して含むデータ項目を集め,それを芯ク ラスタとする.つまり,クラスタ集合 Y に対して,芯 クラスタは {x||{S ∈ Y |x ∈ S}|/|Y | ≥ ρ} で定義され る.複数のクラスタリング結果からこのようにして芯 クラスタを求めることにより,安定したクラスタが得 られるだろう,というのが我々のもくろみである.得 られたすべての研磨クラスタから芯クラスタを求めて も,データ項目すべてを覆うとは限らない.しかし,解 釈性を求めるような応用では,すべての項目を網羅す る必要は少なく,むしろ類似性が低いデータ項目は邪 魔であり,取り除きたい場合もある.よって,被覆の 完全性の低さは,我々の狙う応用分野では,問題とは ならないと考えられる.
Cluster-based Similarity Partitioning Algorithm (CSPA) は, h 個のクラスタリングを用いて, 各要素 x に対して 特徴文字列 x1x2...xh を構成する. ここで xi は i 回目 のクラスタリングにおいて x が所属したクラスタの ID である. ここで, 要素集合を頂点集合とし, 特徴文字列 のハミング距離が h 未満, つまり1つは共通の文字が ある要素間に枝をはり, その枝の重みを h からそのハ ミング距離を引いたものとした類似度グラフを構築す る. これを METIS でクラスタリングして再クラスタ を得るのが既存手法である. 我々の手法では, ハミング 距離が 0.3h 以下のペアのみに枝を引いてグラフを構築 し, データ研磨アルゴリズムを適用する.
3
計算速度
MCLA ではクラスタ間の類似度計算のコストが高く, 得られたクラスタリングの問題は, たとえばクラスタリ ング繰り返し回数 h = 10, クラスタ数 k = 30 の場合で も 300 程度であり, 計算コスト的に問題とはならない. 最後の芯クラスタを計算する部分も線形時間程度であ る. クラスタ間の類似度計算は, クラスタ数の 2 乗× 「一回の比較時間」であり, 類似度の計算に時間がかか る場合には高コストとなる. しかし, 買い物履歴データ のような, 高次元ではあるが疎なデータでは計算は高速 であることがわかっており [8, 7] 問題ない. CSPA においては, 各要素間の類似度を計算する必 要がありここには多大な計算コストが必要となる. バ スケットデータのように, 各文字を持つ要素の数が少な いと, 計算コストを下げることができる. ここでいう少 ないとは, 「ウイスキーを買う人は 1000 人に一人」程 度の割合の意味である. しかし, あいにく CSPA では, ある程度の大きさを持つクラスタが多く, そのクラスタ ID を文字として持つ要素は全体の 1/30 なり 1/10 な り存在するであろう. つまり, データの疎性を活用した 高速化は期待できないのである. しかし一方で良い性 質も期待できる. いくつかの要素は, まったく同じ特徴 文字列を持つことがしばしばあり, それらは一つにまと めることで計算が省略できる. 実際, 我々の計算実験で は, 14000 件のデータのうち, 自身とまったく同一の特 徴文字列を持つものがある要素がほとんどであり, それ らを同一化することでデータは 4000 件程度に縮約され た. この方向での高速化は十分に可能である. ただ, 疎 性を使う類似度が効率が悪いといっても, 1 万 4 千件程 度であれば, 実際には 5 分 10 分程度で計算が終了する ので, 実用上この程度の大きさであればまったく問題はない. 類似性の閾値があまり小さくない, Jaccard 係数 でいえば 0.5 以上の場合には, 複数ソート法 [10] を用 いることもできる. これは, 文字列集合からハミング距 離が閾値以下のペアをすべて列挙するアルゴリズムで, 閾値が小さければ実用的には出力するペアの線形時間 で実行が終了し, 実用的に非常に高速である. 本研究の 場合は, データが 100 万件を超えるような場合には, 威 力を発揮すると考えてよいだろう.
4
計算実験
ここで,実際にクラスタリングを用いた計算実験の 結果を紹介したい.実験に使ったクラスタリングアルゴ リズムは,k-means[5],k + +(kmeans++)[1],PLSA (Probabilistic Latent Semantic Analysis)[3] の3つで ある.実装としては,(株)NTT 数理システムの Visual Mining Studio を用いた.このような商用システムを 用いることは,実際の計算がどのように行われている か,本当のところはわからない,ということがある一 方で,実際に現実社会でユーザが触れるものを解析す るという意味で,今回の研究には意味があるであろう. クラスタ数 k としては 30 を選んだ. これは, 実問題に おいては 30 以上の多数に分割をしても全体像がとらえ にくくなること, これより少ない場合は多様性が観察で きないことが多いことから実際にこの程度の数が良く 用いられることに加え, 解釈することや全体を俯瞰する のが難しくなるところとして 30 を選んだ. 用いたデータは (株) マクロミルより消費者購買履歴 データ「QPR」である. 分析対象は, 2013 年 1 月∼12 月までの 1 年間で, 12 か月間継続して購買報告を行っ ているモニターの購買履歴のみ, およそ 1 万 4000 人分 のデータを用いた. また, 解析プログラムが大量の属性 を扱うことが難しいため, 品目を直接用いるのではな く, 生鮮食品, 雑誌, 頭痛薬, など 500 程度に分類された カテゴリとしてあつかった. つまり, オレンジジュース とリンゴジュースを買った場合, ジュース類を 2 回買っ た, というように扱ったということである. 購買履歴の 比較や, 相関分析を行う場合, 各品目について複数の購 買が行われうる場合, 通常はたとえ複数回購入を行った としても, 購入数を1にして解析を行うことが多い. し かし, 1 年間のデータを用いて解析を行う場合, 食器洗 剤や生鮮食品などの品目に関して, ほとんどのモニター が 1 回以上購買しており, 違いを見えなくなっていま う. そのため, 1 年間での平均の購買回数と標準偏差を 各カテゴリについて計算し, 平均よりも標準偏差以上多 く購入している人のみ, そのカテゴリの値を 1 とする こととした. つまり, そのカテゴリの品物を平均よりき わめて多量に買っているときのみ, そのカテゴリを, そ のモニターの特徴とするということである. 今回,クラスタリングとクラスタリングの比較に対 して,ある種単純な,Jacard 係数を用いた評価手法を 開発し,それを用いた.クラスタリング結果 A と 結 果 B が与えられ,A も B もデータ項目集合{1, · · · , n} の部分集合の集合,つまり部分集合族であるとする. たとえば 1,· · · , 7 をクラスタリングした結果,A は {1, 2, 3, 4} と {5, 6, 7} に,B は {1, 3, 5} と {2, 4} と {6, 7} に別れたとすると,A = {{1, 2, 3, 4}, {5, 6, 7}} ,B ={{1, 3, 5}, {2, 4}, {6, 7}} となる.ここで,A のク ラスタ x に対して,B のクラスタの中で,Jaccard 係 数の意味で最も似ているものを選び,その Jaccard 係 数の値を M (x) とする.つまり,B のクラスタ y の中 での Jaccard (x, y) の最大値が M (x) である.Jaccard 係数とは,|x ∩ y|/|x ∪ y| で定義される集合の類似度 で,もっとも著名な物の一つである.上記の例の場合, {1, 2, 3, 4} に対して最大化させるものは {2, 4} であり, M (x) = 0.5 である.A のすべてのクラスタに対して M (x) を求め,その平均をとった物をクラスタ A と B の類似度とした.この計算方法,A と B に対して対象 ではなく,数学的には美しくないと思われるだろうが, 今回の目的のためにはこの程度の単純な物で十分であ ろうし,また,不必要に複雑化しないことのほうが大 事であろうと考えた. それぞれのクラスタリング結果から,コンセンサス クラスタリングによって得られたクラスタリングの安 定度の評価を行った.k-means,k + +,PLSA それぞ れで 100 個のクラスタリングを生成し,それを 10 個ず つのグループにわけ,それを元に MCLA と CSPA の手 法を, いろいろなクラスタリング手法を用いて行った. そして, グループ 1 と 2, 2 と 3,· · · ,10 と 1 の再クラス タリング結果の類似度を計算し, その平均値を計算す ることで, その手法の安定度合いを評価することとし た. クラスタリングするクラスタリングの数 h として 10 を選んだが, これは大きくすればするほど安定度は 増加する. しかし, 計算コストの面から, 10 程度が適当 であると考えた. 表にクラスタリング数を 5 や 20 に 変更した場合の結果を示しているが, 20 に増加しても 大きな差異はないことが観察されるが, 5 個に減じると 大きく安定度が損なわれることもわかる. データ研磨を用いた MCLA では, 大きさ1のクラス タを除外した物と,4 以下のものを除外したもの,2 通 りを実験した.また, CSPA においては, 大きさ 5 未満 のものを捨てた場合と, 大きさ 30 未満のものを捨てた 場合の二通りを実験した. これは小さすぎるクラスタ には興味がないだろうという自然な動機付けによるも のである. 類似度グラフを作るための閾値 θ として 0.3 を選び,データ研磨の重複許容度閾値にも 0.3 を用い た.これは,クラスタの半分程度が一致した場合に類 似すると判断する物であり,今回の目的にはかなって いると考える.両閾値の変化に対する結果の変化は, 表表 1: 手法間の安定度の比較 (大きいほど安定) k-means k + + PLSA 元のクラスタリング 0.293 0.286 0.523 MCLA 元の手法を利用 0.129 0.018 0.024 MCLA データ研磨≥ 2 0.419 0.374 0.643 MCLA データ研磨≥ 5 0.459 0.507 0.696 MCLA METIS 0.392 0.303 0.683 MCLA Spectral Clustering 0.379 0.387 0.47 CSPA 元の手法を利用 0.385 0.404 0.551 CSPA データ研磨≥ 5 0.198 0.202 0.515 CSPA データ研磨≥ 30 0.422 0.42 0.722 CPSA METIS 0.233 0.217 0.362 CSPA Spectral Clustering 0.426 0.409 0.731 HBGF METIS 0.284 0.28 0.182
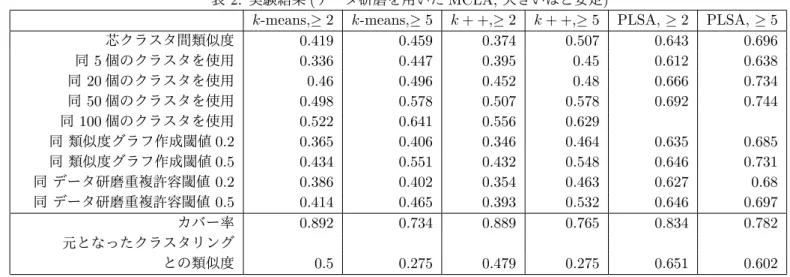
表 2: 実験結果 (データ研磨を用いた MCLA, 大きいほど安定)
k-means,≥ 2 k-means,≥ 5 k + +,≥ 2 k + +,≥ 5 PLSA, ≥ 2 PLSA, ≥ 5
芯クラスタ間類似度 0.419 0.459 0.374 0.507 0.643 0.696 同 5 個のクラスタを使用 0.336 0.447 0.395 0.45 0.612 0.638 同 20 個のクラスタを使用 0.46 0.496 0.452 0.48 0.666 0.734 同 50 個のクラスタを使用 0.498 0.578 0.507 0.578 0.692 0.744 同 100 個のクラスタを使用 0.522 0.641 0.556 0.629 同 類似度グラフ作成閾値 0.2 0.365 0.406 0.346 0.464 0.635 0.685 同 類似度グラフ作成閾値 0.5 0.434 0.551 0.432 0.548 0.646 0.731 同 データ研磨重複許容閾値 0.2 0.386 0.402 0.354 0.463 0.627 0.68 同 データ研磨重複許容閾値 0.5 0.414 0.465 0.393 0.532 0.646 0.697 カバー率 0.892 0.734 0.889 0.765 0.834 0.782 元となったクラスタリング との類似度 0.5 0.275 0.479 0.275 0.651 0.602 表 3: 実験結果 (データ研磨を用いた CSPA, 大きいほど安定)
k-means,≥ 5 k-means,≥ 30 k + +,≥ 5 k + +,≥ 30 PLSA, ≥ 5 PLSA, ≥ 30
芯クラスタ間類似度 0.198 0.422 0.202 0.42 0.515 0.722 同 5 個のクラスタを使用 0.158 0.326 0.166 0.324 0.368 0.6 同 20 個のクラスタを使用 0.228 0.504 0.227 0.468 0.508 0.743 同 50 個のクラスタを使用 0.293 0.558 0.305 0.539 0.603 0.804 同 100 個のクラスタを使用 0.363 0.643 0.37 0.623 同 類似度グラフ作成閾値 0.2 0.266 0.461 0.288 0.49 0.647 0.734 同 類似度グラフ作成閾値 0.5 0.174 0.328 0.169 0.323 0.302 0.587 同 データ研磨重複許容閾値 0.2 0.236 0.483 0.238 0.458 0.467 0.668 同 データ研磨重複許容閾値 0.5 0.148 0.364 0.139 0.337 0.381 0.634 カバー率 0.953 0.921 0.970 0.948 0.979 0.963 元となったクラスタリング との類似度 0.04 0.036 0.041 0.035 0.023 0.022
2 と 3 にまとめたとおり, 大きなものではなかった. 両 パラメータ共に大きくするほど結果は良く,以下の結 果は予備実験の中でのベストを選んでいるわけではな いことを報告しておく.また, ρ は 0.7 とした. 表 1 に各手法間での安定性の比較, 表 2 にデータ研磨を使っ た MCLA における, 各種パラメータの違いによる安定 性の変化, 表 3 に同じくデータ研磨を使った CSPA に おけるものをまとめた. 類似度グラフを用いる他手法 は, これと同じ方法で類似度グラフを作成した. まず, 手法間の安定度の違いを見てみる. MCLA と CSPA を, 元のクラスタリング手法 (k-means で作った クラスタリングを k-means で再クラスタリング, k + + で作ったクラスタリングを k++ で再クラスタリング,,,) で再クラスタリングしたもの, データ研磨を用いて大 きさ 1 のクラスタを捨てたもの, 同じく 4 以下のもの を捨てたもの, METIS, Spectral Clustering を用いた もの, に加えて, METIS によって HBGF 法 (Hybrid Bipartite Graph Formulation [2]) を行ったものを比較 した. HBGF はクラスタと要素の包含関係を表すグラ フを直接 METIS によって分割することでクラスタリン グを得るコンセンサスクラスタリング手法である. まず MCLA については, 元のクラスタリング手法を用いたも の, METIS, Spectral Clustering ともに値は悪く, デー タ研磨のアプローチが非常に良い安定を示している. た だし, PLSA に対して METIS と Spectral Clustering を 適用した場合は数値が良く, もともと PLSA が安定し たクラスタを生成しているのであろうことがうかがえ る. MCLA に METIS や Spectral Clusteing などを用 いる既存の手法では, クラスタ間の類似度を, 両者が共 有する要素数で定義していた. このような定義である と, 大きなクラスタは, 他のクラスタと比べて, 各クラ スタとの類似度が非常に大きくなりがちである. また, 大きなクラスタと大きなクラスタは, 巨大な類似性を 持つこととなる. 結果として, MCLA の出力するクラ スタリングは, 大きなクラスタが集まったクラスタがで きやすくなる. 再クラスタリングの結果は, 非常に大き な, 全体の 3 割程度を占めるクラスタが1つ2つあり, その他のクラスタも大きくなりがちである. 意味解釈 をする場合にも, ぼやけて意味がとりにくいクラスタば かりになってしまう. また METIS などの手法は, クラ スタ間の枝密度が薄くなるようにするため, 1つの再 クラスタに全く似ていないクラスタが含まれることが 多々ある. 例えば同一のクラスタリング結果のクラスタ が4つ5つ, 同一の再クラスタにまとめられることがあ る. このような場合, この再クラスタは, そのメンバー の多くが含む要素がまったくない, という状況が頻発す る. たとえば, 閾値 ρ を 0.7 にして, 7 割以上のクラス タに含まれる要素を取り出そうとすると, まったくその ようなものがない, となる再クラスタが 8 割以上になっ てしまう. 閾値を 0.5 まで下げると防止できるのだが, 今度は一つの要素が複数の再クラスタで出てきてしま い, 再クラスタリングの結果では, 1つの要素が平均的 に2つ以上のクラスタに属するようになってしまう. 次に CSPA を見ると, 元のクラスタリング手法, METIS, Spectral Clustering ともに MCLA より高い安定性を 示している. 特に Spectral Clustering と PLSA の相性 は良いようで, 0.7 を超えている. データ研磨を用いた ものは, 小さなクラスタが安定しないようで, 大きさ 5 以上のクラスタを対象としているほうが安定度が悪く なっている. これは, 小さいクラスタに関わる構造は偶 発的に見つかっており, 試行を変えれば見つかるものも 変わるということを示しているだろう. METIS などは 比較的全体的な近接性に着目してクラスタリングを行 うため, これらの細かい構造が大きな構造に含まれるた め, 安定しているものと思われる. 小さい構造を安定し て抽出したいのであれば, 試行の数を 10 から 50 など に大きくすればよい. MCLA にしても CSPA において も, 全体的にデータ研磨はクラスタの安定化に大きい効 果を与えていることがわかる. 表 2, データ研磨を用いた MCLA での安定度は,k-means や k + + では 0.4, PLSA では 0.65 程度であっ た. 大きさ 2 以上のクラスタを対象とした場合と 5 以 上にした場合では, 5 以上にした方が 0.05 ほど類似度 が高くなる傾向があり, より安定性が増していること がわかった. 全般にもとのクラスタよりも類似度が高 くなっており,データ研磨によって安定したクラスタ が得られていることがわかる.また,クラスタサイズ を 5 以上とすることで,より安定化させることが可能 であることもわかる.類似度の閾値, 重複度の閾値, 一 回の試行に用いるクラスタリングの個数の変化に対し て, 安定度の変化は小さく, パラメータの変化に対して 頑健であることがわかる. また, クラスタリングの数が 極端に小さくなった場合は安定度が低くなることがわ かる. 次に芯クラスタのカバー率を見る.それぞれのグ ループにおいて,求めた芯クラスタの和集合が,デー タ項目全体のどの程度の部分を覆っているかを調べた. 全体的に 8 割以上をカバーしており, 実用上は十分全 体的な説明が得られていると考えてよいだろう. 大き さ 4 以下のクラスタを捨てることで,k-means おおび k + + では 10-15%のカバー率を失っていることがわか る.一方で,PLSA では大きな影響は見られず,PLSA がより安定していることがうかがえる.このデータの 場合は,芯クラスタが全体の 8 割ぐらいをカバーして いるということが観察できる.認識問題のように,す べての項目について予測が必要,というものではなく, 全体をざっくりと眺めたいような,マーケティングな どのタスクにおいては,この精度で十分であろう. 次に,得られた芯クラスタともとのクラスタの比較を お見せしたい.クラスタリング A を,もとのクラスタ リング,つまり k-means などで求めたクラスタリング
とし,クラスタリング B をそこから得られた芯クラス タとして,両者の類似度を比較した.結果は k-means と k + + では 0.4 程度, PLSA では 0.6 程度であった. k-means, k + + では,大きさ 2 以上に比べ,5 以上 の値が大幅に小さくなっている.これは,小さなクラ スタがある程度まとまって,小さな芯クラスタをたく さん作っていたところが,大きさ 4 以下の研磨クラス タを捨てたことで消えてしまったのであろう.つまり, k-means,k + + は小さい芯クラスタをも見付けてい るが,初期解によって見つかったり見つからなかった りするため非常に安定しないことがわかる.PLSA は, こちらでも安定的である. 次に表 3, データ研磨を用いた CSPA の評価である が, MCLA とは異なり, 各種パラメータの変化に安定度 が大きく依存することが見て取れる. まず大きさ 5 以 上のクラスタを扱うとしたものの方が安定度が大きく 低かった. これは, CSPA では小さなクラスタが多く出 てきており, それらが試行ごとに異なってしまうため, 安定度を下げてしまうことにつながっていることがわ かる. 実利用においては, あまり小さなクラスタは注目 する意味が小さいため, 安定している大きなクラスタを 利用すれば自然と利便性が高く活用できる. 大きさ 30 以上のクラスタを対象としたものの結果は, MCLA の 結果とほぼ同程度の安定度を示している. 重複度の閾 値と類似度グラフの閾値は, 小さい方が安定度が高い. これは類似度が低い要素までを含めた大きめのクラス タを見つけたほうが安定度が高くなるということを示 している. また, 多数のクラスタリングを用いて再クラ スタリングを行った方が, 安定度が格段に良くなってい る. 大きなクラスタを見つけるため, カバー率は非常に 高くなっている. その一方で, 元となったクラスタリン グのクラスタからの類似度は非常に低く, いくつものク ラスタが一つにまとめられて大きなクラスタが生成さ れている構造が見て取れる.
5
解釈性の違い
解の解釈とは, データ解析等の結果の解が, 現実の何 に, どのような意味に対応するかを考え, そのような解 が出る理由, 計算上の理由ではなく, 世の中の様子や社 会現象, システムのメカニズムなどから考えることであ る. このような解釈を行うときに, 解釈が行いやすいか どうかを解釈性という. 解釈性が高いことは, データ解 析を現実問題に適用する上で大きな重要性を持つ. し かし, 現実には, 研究分野で開発されるデータ解析手法 の多くが, 仮想的に想定された「精度」なるものを高め る方向に深化されており, ユーザの利便性に重きを置 き, 解釈性を高める方向でデザインされている手法は 少ない. 解釈性は古くから着目されているが, 最近でも 機械学習, データマイニング業界でもまことしやかに 共有され, 課題とされている. しかし, 科学的な取り扱 い方が難しく, 数量化しにくいため, 論文の形で成果と して発表されているものは少ない. 解釈性に光を当て るべきであるという問題意識は共有されているようで, 解釈性に関する問題定義やワークショップなどは開か れ始めているが, 根本的に研究分野, 研究テーマとして 開拓されている感はない. 本研究でも, 解釈性を高めることは大きな目標であ り, 提案手法と既存手法の解釈性を比較したいと考えて いる. しかし, 上記のような理由から, 学術的に立脚し た, 数値などによる評価を提示することは難しい. その ため, 非常にシンプルな方法でクラスタの特徴を表示 し, それを著者らが「データサイエンティストの目」で 眺めたときに, どの程度解釈性が高いと感じたかを報告 したいと思う. 主観的なアプローチではあるが, 人間の 認識能力というものは計算よりも非常に高い面はあり, 特にこのような認知の問題では「これは明らかであろ う」とはっきりと認識できることは, ある程度社会的な 一般性を持っていることが普通である. また, 著者らは 今までに様々な分野にまたがる多くのデータを解析し てきた実績があり, このような多方面にわたる分野の データに対して解析経験がある人間は, 世界的にも珍し いと考えている. 著者らのデータ研究者としての経験 の豊富さは, 根拠として主張したい. クラスタの特徴を捉える方法として, 今回は単純に, クラスタ X の人々の a という品物の購入数平均が, 全 体平均よりも大きかったら, a はそのクラスタの特徴で ある, とした. ただし, 単に平均よりも大きいのではな く, 偏差値を使って大きさを評価した. そして, 偏差値 が上位 30 位までのカテゴリと, 購入数量が 30 位までの もの, 両者を合わせたリストを作り, 見せることで, ク ラスタの特徴を可視化することとした. この可視化手法を用いて, まずコンセンサスクラス タリングを行っていない, もとのクラスタリングから解 釈性を評価した. k-means と k + + は, 非常に大きい, 全体の 2 割 3 割を占めるような大きなクラスタと, 非 常に小さい, 2 個か 3 個の要素しか含んでいないクラス タが混在している. 小さなクラスタは例外としての価 値はあるが, 全体の分析には資さない. 大きなクラスタ は, マーケットデータでいえば「普通」の人々のクラス タなのであるが, その普通の人を分解して詳しく調べた いのがマーケッティングであるとすれば, 分割に失敗し ているといわざるを得ない. 実際, 巨大なクラスタは特 徴が少なく, 目立たず, 解釈が難しい. PLSA ではクラ スタの大きさがある程度そろっており, 大きさのばらつ きの問題はない. しかし, 同じような特徴, 生鮮食品と 日配品を多く買う, のような特徴を持つクラスタが複数 存在していたり, 関連づけにくいカテゴリがリストに並 び, 意味のつけにくいクラスタは依然として存在した.次に CSPA の手法であるが, 全体的に細かくて意味 が非常にはっきりしているものと, 大きくて意味がつけ にくい, ぼやけたクラスタが主であった. これは, 小さ くてつながりが非常に強い要素たちが小さいクラスタ を作り, それらを抜き取ったあとの残りの要素がいくつ かのクラスタに分解された, という構造にクラスタリン グがなっているであろうことが推測される. MCLA の手法は, 全般的に意味解釈がしやすいもの が多かったが, METIS は大きなクラスタを生成してし まうため, 意味が解釈しにくいものができてしまってい る. データ研磨によるものは, 特徴が似ている, 複数に 分かれてしまったと思われるクラスタも少なく, 独立性 が高い上, 解釈性が非常に高かった. 冷凍食品と日用品, 生鮮食品を買っている「子供の弁当を作っている家族」 のクラスタ, インスタント食品と冷凍食品が多い「一人 暮らしで簡単な食事をとるクラスタ」, お酒とおつまみ などを買っているクラスタ, 和総菜と薬を多く買ってい る「老人夫婦クラスタ」といった感じである. 正直な ところ, これを使えばマーケット分析はもっと簡単にで きそうである, 今までの方法では苦労が大きいだろう, ということが自然に彷彿されるような, そのような質の 違いがはっきりと見える結果となった.
6
むすび
前回の報告に引き続き, 実世界での多大な困難と要 求を鑑み, クラスタリングの解を安定化させることの 必要性を説いた. Jaccard 係数を用いてクラスタリング を比較することで安定性の評価を行う新しい尺度を提 案し, クラスタリング安定化問題を提案した. 同時に, バスケット分析に用いられる現実データを用いて, コン センサスクラスタリングによる解の安定化度合の評価 を行い, ある程度満足できる結果が得られることを示 した. さらに, データ研磨によるコンセンサスクラスタ リングは, もとのクラスタリングの解が非常に不安定 な場合でも高い安定化を行うことが可能であることを 示した. また, 得られたクラスタがカバーする要素の割 合, カバー率が 8 割以上と, 現実的に十分高いことを確 認した.また, 意味解釈を実際に行い, データ研磨で得 られるクラスタが非常に意味解釈がしやすくすぐれて いることを確認した. このような, 現実社会で実際に必 要とされる問題・課題の抽出や, 既存データ解析手法の 問題点や上手な使い方など, データ解析におけるアル ゴリズムエンジニアリングはまだまだ発展途上である. この研究がその発展の礎になれば幸いである.謝辞
データをご提供いただいた (株) マクロミル様に感謝 いたします.この研究は,JST CREST グラントナン バー JPMJCR1401 のサポートを受けた.参考文献
[1] D. Arthur, S. Vassilvitskii, “k-means++: the advantages of careful seeding”, SODA2007, pp. 1027-1035, (2007).
[2] X. Z. Fern, C. E. Brodley, “Solving cluster en-semble problems by bipartite graph partition-ing,” ICML’04: Proc. Twenty-First Int. Conf. Machine Learning, pp. 36, (2004).
[3] T. Hofmann, “Probabilistic latent semantic anal-ysis”, Proc. of Uncertainty in Artificial Intelli-gence, pp. 289–296 (1999).
[4] G. Karypis, V. Kumar, METIS–Unstructured Graph Partitioning and Sparse Matrix Ordering System, version 2.0. (1995).
[5] H. Steinhaus, “Sur la division des corps ma-triels en parties”, Bull. Acad. Polon. Sci. 4 (12), pp. 801-804, (1957) (French).
[6] A. Strehl, J. Ghosh, “Cluster ensembles: A knowledge reuse framework for combining multi-ple partitions”, J. Mach. Learn. Res. 3, pp. 583– 617 (2002).
[7] Takeaki Uno, Hiroki Maegawa, Takanobu Naka-hara, Yukinobu Hamuro, Ryo Yoshinaka, and Makoto Tatsuta, “Micro-Clustering by Data Pol-ishing, ” IEEE Big Data 2017 (2017).
[8] 宇野毅明, 中原孝信, 前川浩基, 羽室行信, “データ 研磨によるクリーク列挙クラスタリング”, 情報処 理学会アルゴリズム研究会 146, pp. 1–8 (2014). [9] 宇野毅明, 岩崎幸子, 中原孝信, 中元政一, 羽室行 信, “乱数シード依存のクラスタリング手法の安定 化に対するアプローチ”, 人工知能学会人工知能基 本問題研究会 105, pp. 58–62 (2018).
[10] T. Uno, “Multi-sorting Algorithm for Finding Pairs of Similar Short Substrings from Large-scale String Data”, Knowledge and Information System 25, 229–251 (2010).
[11] S. Vega-Pons, J. Ruiz-Shulcloper, “A survey of clustering ensemble algorithms”, International Journal of Pattern Recognition and Artificial In-telligence, 25(03), pp. 337–372 (2011).