On the Use of Phonetic Information for Mapping from Articulatory Movements to Vocal Tract Spectrum
4
0
0
全文
(2) In the HMM-based conv巴rsion system. we construct feature vectors using param巴ters obtained from the parallel acoustic and articulatory speech database. The feature vector consists of mel-ceps町al coe節ci巴nts as spectral paramet巴rs. EMA data as articulatory p紅ameters. and their delta and delta-delta pa rameters. The joint probability densities of articulatory and acoustic spectral parameters are modeled by the HMM using th巴se feature vectors In the training stage. first. monophone HMMs are esti mated by the isolated training and the following embedded training. After converting to context dependent HMMs. they are re-estimated by the embedded 町aining. To avoid inaccu rate estimates caused by a limited amount of data. we apply the tree-based cont巴xt clustering technique [6].. 4.1. Maximum likelihood spectral estimation In the maximum lik巴lihood (ML) spω回1 estimation. given the articul制'Y features. To conve民the articulatory parameters to acoustic ones. the joint probabiIity densities over two features 紅e trained using the HMM. Each articulatory location is shown by x- and y coordinates. therefore articulatory movements 紅巴 represented as 14 dimensional vector s巴quence. Moreover. the proposed syst巴m can represent probability densities more precisely using multi-mixture comp紅ed with the conventional HMM-based be articula司 and system using single mixture [5]. Let tory and acoustic featur巴 vectors. respectively. Let the vector. Yt. Z t = [XJ.YJr be a joint feature of these two features. and its vector sequence Z = [Zi. Zr. . . . z; r is modeled by the HMM À. The output probability of Z given the HMM can be. •. ]. .. ー. 可γ. I. is ob・. 〆MA)=55lMq|XJ). (1). q.X.À) 日 p(Yt Xt• mt.q" À) ]. 例 I. where the output probability distribution is written as follows:. p(Y,1 X"qt =j.m, = =N(Y,; Ej,j(t).Dj,j) i.λ). (5). and. Ej,j(t) =μ(?+zjアzjjゎ-1(Xt-A?), D;; = J,) I;(YY) - I;(YX)I;(XX)-II;(XY). ・・J. '. }. l.}. I,J. (6) (7). Furth巴rmore. the post巴rior state transition probability p(q I x.λ) is also calculated us印d the mixture weight and model p紅ametersλ. Since ing articulatory parameters equation (4) includes hidden variables. th巴 optimal sequence is estimated via the EM algorithm. The EM algorithm of is an iterative method for approximating the m但imum like lihood estimation. It maximizes the expectation of the complete data log-likelihood so cal1edQ-function (auxiliary func tion):. .X.λ p(ml Xq ). Y. Q(Y.. Î'). =1:: 1::. [p(m. q I. 叫Iq allm. Y.X.. À)log p(Y. m. q I x. À)]. (8). Taking the derivative of theQ-function. the spec位al sequence Y which maximizes出eQ・function is given by. f=(F)-1日. (9). where. =(ml.m2.・・・ .mr). (2) 1 - 94. -118-. D-1= [Dïl.不 ,耳] • D戸=1::1:γ: ιJ(t)D;j, diag N. Mj. 日= [可河2T, RTT[ D-1Et =エエγj,j(t)Di.J Ej,j(仏 N. MJ. (10) (. where q = (ql. q2γ・・. qr) is a state sequence of the HMM. denotes a component numb巴r sequenc巴 m of mixture distributions. The probabilities p(q Iλ)叩d p(mlq.λ) denote a state transition probability and mixture weights of output probability. respectively. In this pap巴r. the mixture component is assumed to be a Gaussian distribution:. p(Ztlmt=叩=μ)=N(zdj),zjj)),. . ・ ・ ・. 、‘,J 'EA --A. p山t.q"À). I. tained by maximizing th巴 following conditional probability.. written as follows. 崎. as an input.. r. T. 4. TRAINING JOINT PROBABILITY DISTRIBUTION WITH ITh品f. Iλ 川. X= [Xi.Xr.. .. ー• X;r Y = Y_; • Y2 Y�. 出e optimal spec回1 features. xp (ml. In the conversion stage. first. th巴 text to be synthesized is converted to a context dependent label s巴qu巴nce. Then. th巴S巴ntence HMM is constructed by concatenating context dep巴ndent HMMs according to the label sequence. Articula tory param巴ters are converted to spec町um features based on the maximum likelihood estimation. Finally. a speech wave form is synthesized from the generated p紅白neters by using a speech synthesis filter.. 山=22 ト(q. (. -=. whereμand I; denote a mean vector and a covariance matrix. respectively目In the above-mentioned condition. the parame t巴rs of the HMM À is estimated via出e EM algorithm,. 3. CONVERSION SYSTEM OVERVIEW. Xt. ) 弓3. i VE vs J -JF X t i ( z z わ め x JT J z z i - Z J Z l m川 Jη J μ μ 'E EE' ' rE'ga' HV げW μ. articulators (top lip. bottom lip. bottom incisor. tongu巴 tip. tongue body. tongue dorsum. and velum) and two referenc巴 points (the bridge of nose and the upper incisor) are sampled in the midsagittal plane at 500 Hz.. (12) (13).
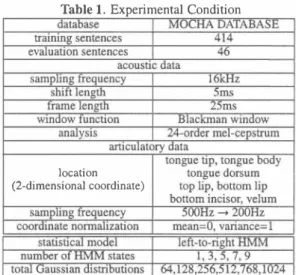
(3) γiþ). =. == =. p(qt j I X, Y, À) xp(mt ilqt j,X, Y,λ).. Table 1. Exp巴rimental Condition. (14). The occupancy probability Yi,j(t) can be calculated by the forward-backward algorithm. Using the updated probabilities Yi,j(t), a new vector sequence Y is calculated by equations (9),. z. and then Y is substituted for Y. This procedure is iteratively performed until a certain conv巴rgence condition is satisfied.. 4ムMaximum likelihood spectral estimation using dynamic features. location (2-dimensional coordinate). In this pap巴r, w巴 appropriately estimate the sp巴C仕al feature sequence using dynarnic features as d巴scribed [4, 5J. Let. =. =. [x;r,ð.x;r, ß2x;rf and Yt [y;r, ßy;r, ß2y;rf be an 紅 ticulatOlγfeature and an acoustic feature, respectivel子Where xt and yt denote static features, and the notations, .1 , .12 rep resent first and second order dynamic features, respectively, calculated from the neighboring frames of time t. The rela tion between the static spectral sequence y = [y 1 T, y T,・ 2 'YT Tr and the static-dynamic features Y can be written as the following linear transformation:. Xt. Y. =. Wy. 3. Perform血巴 context clustering until the predetermined number of clusters紅'e generated.. (15). 4. Back off the tree in the reverse ord巴r of divisions until the designed size of tr巴e.. where W is a matrix which concatinates dynamic features to the static f,巴ature sequence y. Under this relation, the static feature vector sequence y which maxirnizes 巴quation (8) is given by. y. = (WTD-1W( WT百. 附. Sirnilarly to equation (9), the update is iterated until a certain convergence condition is satisfied. 5. EXPERIお1ENT 5.1. Experimental conditions. We investigated the effectiveness of using phonetic and tem poral information by varying the importance of these proper ties. The acoustic-articulatory data described in Section 2 was used. Experimental conditions are shown in Table 1. To investigate the mapping accuracy of the HMMs, we fixed the total number of parameters of HMMs, then assigned them variously. Wher巴 the importance of temporal informa tion is represented by the state number of 1品1Ms, and that of phonetic information is repr巴sented by th巴 size of decision tree in context clustering. 1n context clustering, a larg巴 single tr田including all出phone H�仏1s was constructed for each temporal HMM state, which allows parameter sharing among differ巴nt phone HMMs. Furthermore, to assign白巴 optimal number of rnixtures for each state (cluster), we apply the fol lowing procedure: 1. Construct a root node for all states of all HMMs. 2. Apply the questions which divide all temporal HMM states.. 1. 5. In the new leaf node obtained in 4, nodes of the sub佐田 are used as th巴 rnixture components, and their weights are deterrnined by the∞cupancy count of the trai凶ng data. The variance p紅ameters of lTh仏1s were trained as diagonal covariances, and aft巴r the context clustering they were esti mated by the embedded training as full covariance matrices. In Section 4.2, we presented the process which iteratively estimates a spectral feature sequenc巴 and posterior probability distributions of the state transition and the rnixture compo nents. However, in this experiments we use出e state align ment generated from the natural articulatory-acoustic data, hence only the posterior probabilities of rnixture components were re-estimated, iteratively. In the experiment, Fo sequenc巴s which automatically extracted from natural speech are used for synthesizing speech to focus on the spec位al conversion. The mel-cepstral distortion between the target and the es・ timated mel-cepstrum given by the following equation was used as the evaluation measure: Mel小. 品刊 2( 2. j. j )2. mc t)-mc e). 間. where mc�1) and mc�e) denote the i-th coefficient of the target and the estimated mel-cepstrum, respectively. 5.2. Experimenta1 results. To investigate only the effectiveness of phonetic information, we apply the context clustering to the GMM-based mapping. Figure 2 shows the MelCD of the GMM-based mapping with ∞ntext clustering, which is equivalent to the multi-mixture. - 95. QJ 唱EA.
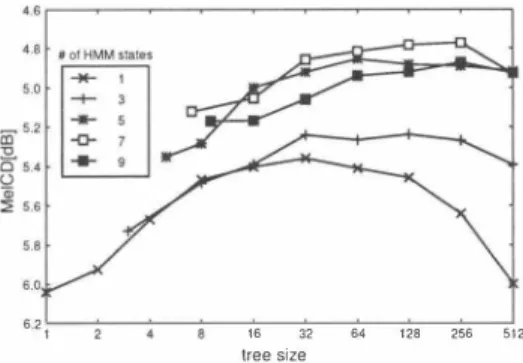
(4) 5.5. Ciì6 tコ 口 仁J. 主. 6.5. \6. Fig.2.. tree size. 64. 256. 1024. 6.2. 16. 1. 32. 64. 128. 256. 512. tree size. =. M巴ICD of the GMM-based mapping with context clustering (� of HMM states 1). HMM-based mapping with the number of states is one, hence temporal information could not be modeled. As the decision tree becomes large, phonetic information becomes positively used, and the left end of the graph indicates the mapping with out using phonetic information, which is equivalent to the conventional GMM-based method. It is observed that the mapping accuracy without phonetic information decreases in proportion to th巴 decrease of the number of mixtures. However, the mapping using phonetic information (the tree size is around 64) achieved high accu racy even with fewer p紅ameters. Furthermore, the result of 64 Gaussians with phonetic information is superior than the conventional GMM mapping of 1024 Gaussians. These re sults show that phonetic information is useful for conve口mg articulatory features to acoustic ones. We investigate the e恥ctiveness of introducing temporal information to the GMM-based mapping. Figure 3 shows出巴 M巴ICD of the multi-mixture HMM-based mapping, where the total number of Gaussian distributions is fixed to 512. It can be seen that the mapping accuracy can b巴 improved by using t巴mporal information. However the use of too many HMM states degrades the p巴rformance, which may be due to inadequate state alignments. The tree siz巴s, which achieved the highest accuracy in each number of HMM state tend to increase with the increase of HMM states. 1t is supposed that, indep巴ndently of the number of H恥仏1 states, a similar num ber of c1usters is r巴quired for each HMM state to represent its context d巴pendency. This result suggests that the simultane ous use of phonetic and temporal information is e仔ective for the conversion system.. Fig. 3. MelCD of the HMM-based mapping (total. sians = 512). � of Gaus. Acknowledgments: Authors 紅e grateful to Dr. Heiga Zen. for h巴Ipful discussions. 7. REFERENCES. [1) M. M. Sondhi, “Articulatory modeling: a possible role in concat巴native text-to-speech synthesis," IEEE 2002 w,フrkshop on Speech Synthesis, Sept. 2002. [2) T. Yoshimura, K. Tokuda, T. Masuko, T. Kobayashi, and T. Kitamura, “Simultaneous modeling of spectrum, pitch and duration in hmm-based speech synthesis," Eu rospeech, vol. 5, pp. 2347-2350, Sept. 1999. [3) A. Wrench,“http://www.cstr.ed.ac.ukfartic/mocha.html... Queen Margaret University College, 1999. [4) T. Toda, A. W. B1ack, and K. Tokuda, “Mapping from ariticulatory movements to vocal tract spectrum with gaussian mixture model for ariticulatory speech synthe sis," 5th ISCA Speech Synthesis <<ゐrkshop-Pittsburgh, pp. 31-36. June 2004 [5) S. Hiroya and M. Honda, “Estimation of articulatory movements from sp∞ch acoutstics using an hmm-based speech production model," IEEE Transactions on Speech and Audio Processing, pp. 175-184, Mar. 2004. [6) J. J. Odell,. 6. CONCLUSION. In this paper, we examined an e仔'ectiven巴ss of using phonetic and temporal information for converting articulatory move ments to vocal tract spectrum. In the obリ巴ctive evaluation, it was confirmed that mapping accuracy is improv巴d by us ing both phonetic and temporal information. Future works include investigating more e仔ective contexts for articulatory acoustic conversion. Constructing a TIS system for synthe sizing articulatory features and Iistening tests are also future works.. 1 - 96. -120-. The Use of Context in Large Vocabulary Speech Recognition, Ph.D. thesis, Cambridge University,. 1995..
(5)
図
![Figure 1 shows the proposed TIS system with articulatory parameter conversion. First, Fo and articulatory parameters are generated from the HMM-based TIS [2] which could be 巴asily constructed by using articulatory parameters as train](https://thumb-ap.123doks.com/thumbv2/123deta/8634797.1341346/1.895.462.764.381.510/articulatory-parameter-conversion-articulatory-parameters-constructed-articulatory-parameters.webp)
関連したドキュメント
Kilbas; Conditions of the existence of a classical solution of a Cauchy type problem for the diffusion equation with the Riemann-Liouville partial derivative, Differential Equations,
Since the boundary integral equation is Fredholm, the solvability theorem follows from the uniqueness theorem, which is ensured for the Neumann problem in the case of the
Key words and phrases: Optimal lower bound, infimum spectrum Schr˝odinger operator, Sobolev inequality.. 2000 Mathematics
The variational constant formula plays an important role in the study of the stability, existence of bounded solutions and the asymptotic behavior of non linear ordinary
Going back to the packing property or more gener- ally to the λ-packing property, it is of interest to answer the following question: Given a graph embedding G and a positive number
The classical Schwarz-Christoffel formula gives conformal mappings of the upper half-plane onto domains whose boundaries consist of a finite number of line segments.. In this paper,
This paper presents an investigation into the mechanics of this specific problem and develops an analytical approach that accounts for the effects of geometrical and material data on
A bounded linear operator T ∈ L(X ) on a Banach space X is said to satisfy Browder’s theorem if two important spectra, originating from Fredholm theory, the Browder spectrum and
