論 文
PESQ と室内音響指標を用いた雑音・残響指標 NRSR-PA に基づく雑 音・残響下音声認識性能の予測 *
福森 隆寛
†a)中山 雅人
††b)西浦 敬信
††c)山下 洋一
††d)Performance Estimation of Noisy-and-Reverberant Speech Recognition Based on Noisy-and-Reverberant Criteria NRSR-PA with PESQ and Acoustic Parameters
∗Takahiro FUKUMORI
†a), Masato NAKAYAMA
††b), Takanobu NISHIURA
††c), and Yoichi YAMASHITA
††d)あらまし 実環境において音声認識システムを利用すると,雑音や残響などの外乱の影響を受けて音声認識性 能が著しく劣化する.ここで外乱による性能劣化を事前に予測できれば,その結果に基づいて性能改善手法を前 処理等に反映できる.これまでに雑音下ではPerceputual Evaluation of Speech Quality(PESQ)を,残響下 では室内音響指標(D値,残響時間(T60))を用いて音声認識性能を予測する手法が提案されている.しかし,
これらの手法には予測指標が表現できない外乱が混入すると音声認識性能の予測精度が低下する問題がある.そ こで本研究では,雑音・残響下における音声認識性能の予測精度を向上させるために,PESQ,D値,T60を用 いた音声認識性能の予測式を提案する.提案法では事前に計測した発話音声やインパルス応答を用いて算出し たPESQ,D値,T60,音声認識性能から雑音・残響指標Noisy-and-Reverberant Speech Recognition criteria with PESQ and Acoustic parameters(NRSR-PA)を策定する.そしてNRSR-PAを用いて性能予測を行う 発話位置におけるインパルス応答と発話音声から音声認識性能の予測を試みる.評価実験の結果,従来の雑音指 標・残響指標を個別に用いて性能予測する手法よりもNRSR-PAは頑健に雑音・残響下音声認識性能を予測でき ることを確認した.
キーワード 雑音・残響下音声認識,音声認識性能の予測,PESQ,室内音響指標
1.
ま え が きここ数年,万人にとって使い勝手の良い理想的な情 報機器の操作環境として,音声を利用して情報機器 を操作するハンズフリー音声インタフェースが注目さ れている.しかしながら,ハンズフリー音声インタ フェースはマイクロホンを装着しない上,入出力間距
†立命館大学大学院情報理工学研究科,草津市
Graduate School of Information Science and Engineering, Ritsumeikan University, 1–1–1 Nojihigashi, Kusatsu-shi, 525–8577 Japan
††立命館大学情報理工学部,草津市
College of Information Science and Engineering, Ritsumeikan University, 1–1–1 Nojihigashi, Kusatsu-shi, 525–8577 Japan a) E-mail: [email protected]
b) E-mail: [email protected] c) E-mail: [email protected] d) E-mail: [email protected]
*本論文は学生論文特集秀逸論文である.
DOI:10.14923/transinfj.2014PDP0011
離や発話方位も様々な状況を想定しているため実環境 下で使用者がマイクロホンから離れて発話した際に,
雑音や室内残響等の混入により音声認識性能が著しく 低下するという問題がある.これまでに実環境下で音 声認識性能を向上させるために数多くの雑音対策
[1]
〜[4]
や残響対策[5]
〜[8]
が提案されている.そして,ハ ンズフリー環境などに存在する外乱に対して,これら の対策手法を適切に講じることで音声認識性能を改善 できる可能性がある.これに関連して,現在,実環境における音声認識性 能の予測に関する研究に高い注目が集まっている.利 用環境に存在する外乱が音声認識性能に与える影響を 事前に予測し,その予測結果に基づいて外乱対策を音 声認識システムの前処理等に適切に反映させることで,
音声認識性能の劣化を未然に防ぐことができ,結果的 に各利用環境で音声認識性能を最大限に発揮できるよ うになる.例えば,複数の外乱対策に対する音声認識
性能を予測し,その中から最も高い予測値を達成した 外乱対策を選択することで,その対策が利用環境にお ける最適な外乱対策であることを示すことができる.
また,この予測手法は音声認識性能を評価するため の音声収録や音声認識処理に必要なコストを削減でき ると考えられる.これまで音声認識システムを導入す る環境において,音声認識性能を評価するには,事前 にその環境で収録した音声データを用いて音声認識実 験を行うことが多かった.しかしながら,実際の利用 環境において大量の音声データを収録することや,収 録した音声データを認識評価することには膨大なコス トが必要となる.そこで雑音やインパルス応答などの 外乱成分を収録するだけで音声認識性能を予測するこ とができれば,これまで必要だった大規模な音声収録 や音声認識処理を省略できるため,結果的に音声認識 性能の評価コストを大幅に削減できる.
雑音下ではこれまで信号対雑音比を示す
Signal-to- Noise Ratio
(SNR
)によって音声認識性能を予測す る研究が一般的であったが,非定常雑音を取り扱う場 合,高精度なSNR
推定に長い分析区間と計算時間を 用いるため,これに伴って音声認識性能予測に必要な 計算コストが増加する問題があった.そこで,2006
年 に山田らによって原信号と劣化信号に基づいて品質を 予測するPerceputual Evaluation of Speech Quality
(
PESQ
)を利用した研究[9]
が提案され,雑音下にお ける音声認識性能の予測精度と簡便性は飛躍的に向上 した.一方,残響下に対する音声認識性能についても,これまで残響時間測定法
[10]
を用いた音声認識性能の 評価[11]
が主流であったが,2011
年に入出力間のイ ンパルス応答と室内音響指標に基づいて音声認識性能 を予測する手法を我々が提案しており,残響下におけ る音声認識性能の予測精度も大幅に改善した[12]
.しかし,これらの手法には予測指標を表現できない 外乱成分が混入すると音声認識性能の予測精度が低下 する問題がある.つまり,複数の外乱成分が混在する ような実環境においては,雑音指標や残響指標などの 複数の指標を組み込んだ予測指標を策定する必要が ある.これによって,一つの指標では表現できない外 乱成分を,それ以外の指標で表現することが可能とな り,結果的に高精度な音声認識性能予測の実現につな がると考えられる.そこで本研究では,少ない計算コ ストで雑音や残響にも頑健な音声認識性能の予測指標
Noisy-and-Reverberant Speech Recognition criteria with PESQ and Acoustic parameters
(NRSR-PA
)を提案し,雑音・残響下における音声認識性能の高精 度かつ簡便な予測を試みる.具体的には,
PESQ
と室 内音響指標(残響時間とD
値)と音声認識性能の関係 に基づいてNRSR-PA
の策定を試みる.そして,策定 したNRSR-PA
を用いて,音声認識性能予測を行う発 話位置におけるインパルス応答と発話音声をもとに雑 音・残響下音声認識性能の予測精度を検証する.2.
音声認識性能予測のための従来指標2. 1 PESQ
を用いた雑音下音声認識性能の予測 雑音に対する音声認識の難しさを表現するために,これまでに山田らが
PESQ [13]
を用いて音声認識性能 を予測する手法を確立している[9]
.PESQ
は主観品 質評価との対応が良い客観品質評価法であり,特に時 間軸上で離散的に発生するひずみを扱えるという特長 を有する.ここで,図1
にPESQ
スコアの算出アルゴ リズムを示す.はじめに,クリーン信号と劣化信号を 知覚モデルを用いてセルと呼ばれる時間・バークスペ クトル領域に射影する.そして,セル間のひずみから 認知モデルを用いて主観MOS
の推定値(PESQ
値)を計測する.山田らは,
PESQ
と雑音下での音声認識 性能に強い相関が保たれていることを確認し,雑音下 で音声認識性能が予測できることを明らかにした.2. 2
室内音響指標を用いた残響下音声認識性能の 予測我々は残響による音声認識性能の低下を予測するた めに,室内音響指標
[14]
のD
値に基づいて,残響時間 ごとに策定した残響指標Reverberant Speech Recog- nition with D
n(RSR- D
n)
を用いて音声認識性能を 予測する手法を提案している[12]
.これはインパルス 応答の初期と後続の反射エネルギー比と音声認識性能 の間に強い相関関係があることを明らかにし,このエ ネルギー比を表現できる室内音響指標のD
値を用い て高精度に音声認識性能を予測できることを実証して いる.D
値とは系のインパルス応答をもとに式(1)
よ り算出され,直接音と初期反射音のエネルギーに対す る直接音と全ての反射音のエネルギー比を示す.図1 PESQスコアの計測方法 Fig. 1 Calculation of the PESQ score.
表1 実験条件(従来指標と音声認識性能の関係分析)
Table 1 Experimental conditions for the relation analysis between conventional criteria and speech recognition performance.
Environments Japanese style room(T60=400 ms,72 RIRs)
for speech Meeting room(T60=600 ms,120 RIRs)
recognition Lift station(T60=850 ms,120 RIRs)
Speech ATR phoneme balance 216 words [15]
Speaker 2 female and 2 male speakers Decoder Julius rev. 4.2.1 [16]
(Gender-dependent model)
Feature 12 orders MFCC+
vectors 12 orders ΔMFCC+
1 order ΔPower
Noise white noise
SNR -5, 0, 5, 10, 15 and 20 dB
D
n=
n0
h
2( t ) dt/
∞0
h
2( t ) dt
,(1)
ここでh ( t )
はインパルス応答を,n
は初期反射音と後 続残響音の境界時間を示す.直接音と初期反射音のエ ネルギーが大きいほどD
値は向上を示し,後続残響の エネルギーが大きいほど低下する.D
値は音声認識性 能に影響を与える初期反射音と後続残響音の割合を表 現できることから,音声認識性能に与える劣化の度合 いを表現するパラメータとして有効であることが明ら かとなっている[12]
.2. 3
従来指標の問題点と解決方策従来指標の問題点として,それぞれの指標が表現で きる外乱成分とは異なる外乱成分が混入することで音 声認識性能の予測精度が劣化することが挙げられる.
ここで実際に雑音と残響が混在する環境において,
従来指標と音声認識性能の関係を評価した.この実 験では,表
1
に示す条件において,クリーン音声に 残響を畳み込んだ信号に白色雑音を所望のSNR
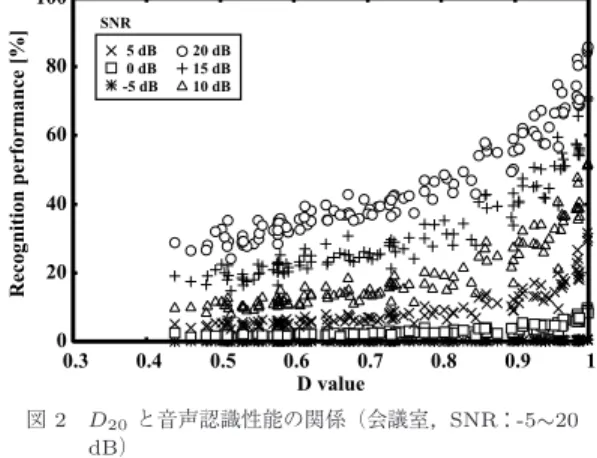
で加 算した評価音声を用いて音声認識を行った.図2
にD
値と音声認識性能の関係(会議室:T
60=600 ms
,SNR
:-5 ∼ 20 dB
)を,図3
にPESQ
と音声認識性能 の関係(和室:T
60=400 ms
,会議室:T
60=600 ms
, エレベータホール:T
60=850 ms
,SNR
:10, 20 dB
) を示す.まず,図2
の残響指標と音声認識性能の関係 より,雑音(特にSNR
)の影響を受けたことによっ て,同じD
値に対して音声認識性能のばらつきが確認 できる.また図3
の雑音指標と音声認識性能の関係に おいても,残響(残響時間や発話位置)の影響を受け たことによって,同じPESQ
に対して音声認識性能の ばらつき(特にPESQ
が1.8
のときの和室の音声認識 性能に20 %
以上のばらつき)が確認できる.これら図2 D20と音声認識性能の関係(会議室,SNR:-5∼20 dB)
Fig. 2 Relationship betweenD20 and speech recog- nition performance (Conference room, SNR:
-5∼20 dB).
図3 PESQと音声認識性能の関係(和室,会議室,エレ ベータホール,SNR:10, 20 dB)
Fig. 3 Relationship between PESQ and speech recog- nition performance (Japanese style room, Conference room, and Lift station, SNR: 10, 20 dB).
の結果より,
1
種類の指標だけで複数の外乱成分(雑 音と残響)が音声認識性能に与える影響を表現するこ とに限界があると予想される.ただし,図
2
に着目すると,D
値と音声認識性能の 関係がSNR
に依存する傾向が確認できることから,D
値とSNR
を組み合わせることで雑音・残響下にお いて高精度な音声認識性能予測が期待できる.しかし ながら,SNR
を雑音(特に非定常雑音)と音声が混 在する観測信号から正確に推定することは容易ではな い上に計算コストの増大にも繋がるため,本研究にお いてはSNR
に代わって雑音成分が音声認識システム に与える影響を表現できる別の雑音指標の検討を考え る.そこで,本研究ではPESQ
を用いることで,雑音成分が音声認識性能に与える影響を
SNR
や定常・非 定常性に依存することなく正確かつ簡便に表現できる という従来研究の知見[9]
に着目し,雑音と残響成分 が音声認識性能に与える影響を同時に表現できる新し い外乱指標の策定を試みる.具体的には,残響指標のD
値や残響時間では表現しきれない雑音成分の影響を 雑音指標のPESQ
で表現できるような雑音・残響指標 を策定して,雑音と残響が混在する環境における頑健 な音声認識性能の予測に取り組む.3.
頑健な音声認識性能予測のための雑音・残響指標
NRSR-PA
の提案本研究では,
2. 3
で指摘した雑音・残響指標の問題 点を解決するために,雑音・残響に対して頑健な音声 認識性能予測指標を提案する.具体的には,雑音指標(
PESQ
),残響指標(室内音響指標)と音声認識性能 の関係を重回帰分析して算出された予測式を予測指標 とし,その指標を使って音声認識性能の予測を試みる.3. 1
雑音・残響指標NRSR-PA
策定のアルゴリ ズム音 声 認 識 性 能 を 予 測 す る た め の 雑 音・残 響 指 標
NRSR-PA
の策定アルゴリズムを図4
に示す.[
事前準備]
インパルス応答,雑音,クリーン音声 の計測雑音・残響下音声認識性能の予測指標を策定するた めに,事前にインパルス応答,雑音,クリーン音声を 計測する.インパルス応答については,残響時間が異 なる環境において,入出力間距離や発話方位が異なる 伝達特性を数十〜数百箇所で計測する.また雑音は音 声認識システムの利用環境に存在する雑音を計測し,
図4 予測指標の策定概要
Fig. 4 Overview of designing the estimation criteria.
クリーン音声は大規模音声データベースを利用したり,
ヘッドセットマイクなどで話者の音声を近接収録する.
[Step 1]
音声認識評価とPESQ
計測用の劣化音 声の作成事前準備で計測した信号から音声認識評価と
PESQ
計測に用いる劣化音声を作成する.具体的には,イン パルス応答とクリーン音声を畳み込んだ残響信号に対 して雑音を所望のSNR
で加算する.[Step 2] D
値,残響時間の算出事前準備で計測した各インパルス応答に対して式
(1)
に基づいてD
値を算出する.また初期反射音と後 続残響の境界時間を表すn
は,音声認識性能とD
値 の最大相関値を示すように設定する必要がある.なお 先行研究[12]
よりn =20 ms
が適切な境界時間である ことが明らかとなっている.またインパルス応答から
D
値と併せて残響時間を 式(2)
に基づいて算出した残響曲線から算出する.< Sd
2( t ) > = N
∞t
h
2( x ) dx
,(2)
ここでN
は単位周波数当りのパワー,< Sd
2( t ) >
は残響曲線を表す.残響時間は算出した残響曲線に基 づき
60 dB
減衰するまでの時間と定義されている.な お残響時間は同一室内では固有の値をもつため,計測 したインパルス応答の全てから残響時間を算出する必 要は無く,数箇所のインパルス応答から算出した残響 時間の平均を各環境の残響時間とすることが一般的で ある.[Step 3] PESQ
と音声認識性能の計測Step 1
で作成した劣化音声を用いて,PESQ
と音 声認識性能を計測する.なおPESQ
の計測には,劣 化音声と併せてクリーン音声を用いる必要がある.そ して音声認識性能はJulius [16]
などの音声認識エンジ ンを用いて算出する.[Step 4]
音声認識性能の予測式の算出雑音・残響下における音声認識性能を予測するため に,
Step 2
とStep 3
で計測したD
値,PESQ
,音声認 識性能に対して残響時間ごとに重回帰分析を行い,雑 音・残響指標NRSR-PA
の評価関数を策定する.策定 した雑音・残響指標NRSR-PA
を示すR
Est( x
d, x
p, T )
は,式
(3)
で表現される.R
Est( x
d, x
p, T ) (3)
= A
T· x
d+ B
T· x
p+ C
T,
x
dはD
値を,x
pはPESQ
を,T
は残響時間を,A
T, B
T, C
Tは重回帰分析によって得られた回帰係数を表 す.式(3)
は,D
値とPESQ
の線形和で表現される音 声認識性能の予測式が残響時間ごとに構成されること を表している.なお回帰係数の予測方法は,最小2
乗 法[19]
を用いる.3. 2
雑音・残響下音声認識性能の予測アルゴリズム3. 1
で策定した雑音・残響指標NRSR-PA
を用いた 音声認識性能の予測アルゴリズムを図5
に示す.[
事前準備]
インパルス応答,雑音,クリーン音声 の計測雑音・残響下音声認識性能を予測するために,事前 に発話者と音声認識システム間のインパルス応答と劣 化音声を事前に計測する.なお,音声認識性能の予測 にはクリーン音声も併せて必要であるが,本研究では 大規模音声データベースや事前にヘッドセットマイク などで近接収録した話者音声を利用する.
[Step 1] D
値,残響時間,PESQ
の計測 事前準備で計測したインパルス応答から式(1)
に基 づいてD
値を,式(2)
に基づいて残響時間を計測す る.また計測したクリーン音声と劣化音声からPESQ
を併せて計測する.図5 音声認識性能の予測概要
Fig. 5 Overview of estimating speech recognition performance.
[Step 2]
音声認識性能の予測Step 1
で計測したD
値,PESQ
と残響時間を式(3)
の雑音・残響指標NRSR-PA
の評価関数に適用するこ とで音声認識性能の予測を試みる.4.
雑音・残響指標NRSR-PA
の性能評 価実験雑音・残響指標
NRSR-PA
の有効性を明らかにす るために評価実験を行った.まず,様々な残響時間の 実環境において算出したD
値,PESQ
と音声認識性 能の関係について重回帰分析を行い,雑音・残響指標NRSR-PA
を策定する.そして策定したNRSR-PA
と 性能を予測するためのインパルス応答と劣化音声に基 づいて,雑音・残響下音声認識性能の予測を行う.ま た本論文では,従来・提案手法による音声認識性能予 測に必要なデータ量及び計算量の評価も実施し,提案 手法のコスト削減性能を明らかにする.4. 1
雑音・残響指標NRSR-PA
の策定に関する 実験条件D
値,PESQ
,音声認識性能の関係を分析するため に表2
に示す六つの学習環境にて計560
箇所のインパ ルス応答を計測した.表中のRIRs
は,Room Impulse Responses
の略称であり,計測したインパルス応答数 を表す.なお表2
に示す環境は,様々な残響環境を想 定するために,残響時間が異なる環境でインパルス応 答を計測した.また各残響環境の中でも,近距離発声 だけでなく遠隔発声も考慮したハンズフリー発話環 境を想定して10
〜500 cm
の入出力間距離及び正背左 右の放射面の条件で計測を行った.本評価実験では,表2 実 験 条 件 Table 2 Experimental conditions.
Environments Japanese style room(T60=400 ms,72 RIRs)
to design Meeting room(T60=600 ms,120 RIRs)
NRSR-PA Lift station(T60=850 ms,120 RIRs)
Environments Laboratory(T60=450 ms,72 RIRs)
in open test Corridor(T60=650 ms,120 RIRs)
Standard stairs(T60=850 ms,56 RIRs)
Speech ATR phoneme balance 216 words [15]
Speaker 2 female and 2 male speakers Decoder Julius rev. 4.2.1 [16]
(Gender-dependent model)
Feature 12 orders MFCC+
vectors 12 orders ΔMFCC+
1 order ΔPower Noise white noise and factory-noise
SNR -5, 0, 5, 10, 20, 30, 40, and 50 dB
表3 重回帰分析で得られたNRSR-PAの係数値 Table 3 NRSR-PA coefficients calculated by multi-
ple regression analysis.
white noise factory-noise AT BT CT AT BT CT
T60=400 ms -35.0 74.0 -54.8 -33.6 68.1 -41.0 T60=600 ms -33.5 58.4 -28.5 -35.4 57.9 -23.4 T60=850 ms -26.0 57.4 -33.0 -29.5 58.0 -26.9
表4 重回帰分析で得られた相関係数 Table 4 Correlation coefficients calculated by multi-
ple regression analysis.
white noise T60=400 ms T60=600 ms T60=850 ms
D value 0.11 0.24 0.32
PESQ 0.91 0.90 0.90
NRSR-PA 0.96 0.94 0.94
factory-noise T60=400 ms T60=600 ms T60=850 ms
D value 0.08 0.20 0.29
PESQ 0.90 0.89 0.90
NRSR-PA 0.94 0.93 0.93
残響音声に対して白色雑音と電子協騒音データベー ス
[17]
の工場騒音を8
種類のSNR
で加算した.音響 モデルは,IPA
の日本語ディクテーション基本ソフト ウェア[18]
に収録されている性別依存モノフォンモデ ルを使用した.なお音声認識性能は特徴量や言語・音 響モデルなどに依存するため,雑音・残響尺度策定と 音声認識性能予測における認識条件を統一させた.4. 2
雑音・残響指標NRSR-PA
の策定に関する 実験結果残響時間が異なる
3
環境(和室( T
60=400 ms)
,会議 室( T
60=600 ms)
,エレベータホール( T
60=850 ms)
) におけるD
20,PESQ
,音声認識性能の関係を図6
に 示す.そして,図6
には,重回帰分析により得られた 式(3)
の係数値(表3
)を用いて近似平面を描画して いる.また,そのときの相関係数を表4
に示す.ま ず,表
3
のNRSR-PA
の 係 数 値 よ り,和 室( T
60=400 ms)
における係数値B
T,C
T を除くと,環境に依らずに同等の係数値が得られた.このことか ら,和室
( T
60=400 ms)
のような低残響環境について は,環境別に予測指標NRSR-PA
を策定する必要があ るものの,それ以上の高残響環境であれば雑音や残響 の環境に依存せずに音声認識性能を予測できると考え られる.表
4
に示す相関係数より,NRSR-PA
の相関係数が 全ての雑音・残響環境において0.93
を上回り,D
値,PESQ
と音声認識性能の関係を高精度に近似できた.一方,
D
値単体の相関係数は最大で0.32
であり,雑音・残響下における音声認識性能と
D
値の関係を高精 度に近似することが難しかった.なおPESQ
単体の相 関係数は最大で0.91
であったが,更にD
値を組み合 わせることで相関係数が最大で0.96
に向上したこと から,NRSR-PA
を用いることで高精度な音声認識性 能の予測が期待できると考えられる.この結果から音 声認識性能の予測値をPESQ
とD
値の線形結合で表 現したNRSR-PA
は有力な雑音・残響指標であること が分かった.4. 3
雑音・残響下音声認識性能の予測に関する実 験条件4. 2
で策定した雑音・残響指標NRSR-PA
の有効性 を検証するために音声認識性能予測実験を行う.各環 境の予測精度を比較するために,環境クローズテスト 及び環境オープンテストを行う.環境クローズテスト では,残響環境が既知という条件で,学習時と同一環 境のNRSR-PA
から音声認識性能を予測する.本研 究では表2
に示す3
環境(和室( T
60=400 ms)
,会議 室( T
60=600 ms)
,エレベータホール( T
60=850 ms)
) において策定したNRSR-PA
を用いて同一環境の音 声認識性能の予測を試みる.一方,環境オープンテス トでは,残響環境が未知という条件で,学習時と残響 時間は近いが環境が異なるNRSR-PA
から音声認識 性能を予測する.本研究では表2
に示す3
環境(和 室( T
60=400 ms)
,会議室( T
60=600 ms)
,エレベータ ホール( T
60=850 ms)
)において策定したNRSR-PA
を用いて,三つのオープン環境(研究室( T
60=400 ms)
, 廊下( T
60=600 ms)
,階段( T
60=850 ms)
)の音声認 識性能の予測を試みる.なお,音声認識性能予測では,雑音・残響指標
NRSR-PA
の策定とは異なる雑音区間 を用いて評価を行った.予測精度評価にはNRSR-PA
から算出した音声認識性能の予測値とテストデータの 真値との差を示す平均予測誤差を用いた.なお本研究 では,従来手法としてD
値とPESQ
を個別を用いて 音声認識性能予測も併せて行った.4. 4
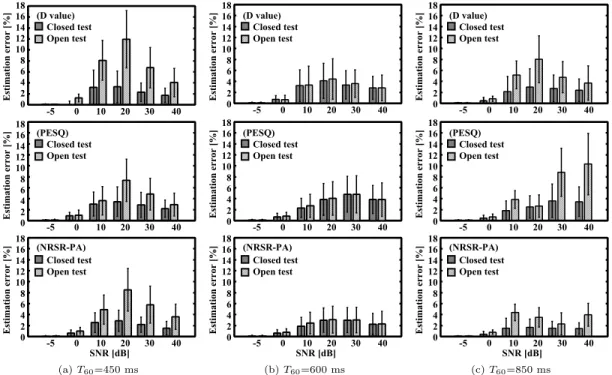
雑音・残響下音声認識性能の予測に関する実 験結果図
7
,8
に各環境の環境クローズテスト及び環境オー プンテスト結果を示す.また図中のエラーバーは,音 声認識性能の予測誤差に対する標準偏差を表す.評価 実験より,提案手法は,全ての残響環境やSNR
に対し て,D
値単体やPESQ
単体と同程度あるいはそれ以上 の予測性能(全環境で10%
以下の平均性能予測誤差)を達成できていることを確認した.なお,
D
値単体で図6 D値,PESQ,音声認識性能の関係(上段:白色雑音,下段:工場騒音)
Fig. 6 The relationship among D20, PESQ and speech recognition perfor- mance (Upper: white noise, Lower: factory-noise).
図7 平均予測誤差(雑音:白色雑音,上段:D値,中段:PESQ,下段:NRSR-PA)
Fig. 7 Average estimation error with white noise (Upper: D value, Middle: PESQ, Lower: NRSR-PA).
は
SNR
が10
〜20 dB
の音声に対してはD
値では表 現が難しい雑音の影響を受けているのに対して,雑音 と残響の影響が考慮された提案手法では予測精度の向 上が確認できる(例えば,図5
の左上の環境オープンテスト
(SNR=20 dB)
における予測誤差がD
値単体 では8.1 %
であるのに対して,提案手法では3.4 %
で あった).また,PESQ
単体でも高残響環境の音声に 対してはPESQ
では表現が難しい残響の影響を受け図8 平均予測誤差(雑音:工場騒音,上段:D値,中段:PESQ,下段:NRSR-PA)
Fig. 8 Average estimation error with factory-noise (Upper: D value, Middle:
PESQ, Lower: NRSR-PA).
ているのに対して,雑音と残響の影響が考慮された提 案手法では予測精度の向上が確認できる(例えば,図
6
の右中の環境オープンテスト(SNR=30 dB)
におけ る予測誤差がD
値単体では12.1 %
であるのに対して,提案手法では
5.4 %
であった).またSNR
が-5
〜0 dB
のとき,全ての予測指標に対して1 %
以内の平均性能 予測誤差を達成した.これは,これらの音声に対する 認識性能が最大約7 %
であり,ダイナミックレンジも 小さいために,顕著な差異を確認できなかったと考え られる.4. 5
音声認識性能予測のコスト評価に関する実験 条件ここでは,従来・提案手法による音声認識性能予測 に必要なデータ量及び計算時間を評価する.ここでの 従来の音声認識性能評価とは,クリーン音声にインパ ルス応答を畳み込んだ信号に雑音を付加した評価音声 データを大量に用意して音声認識性能を予測する手法 を指す.そして提案手法は,インパルス応答,クリー ン音声,及び雑音から室内音響指標と
PESQ
を算出 して音声認識性能を予測する.また本実験では計算機 サーバ(Debian Linux 6.0.7
,CPU:Intel Xeon 3.60
GHz
,メモリ:16 GB
)を用いて評価した.なお,従来手法を用いて正確に音声認識性能を評価 するには,大量の音声データを用いて統計的な処理を 行う必要がある.そのため,本実験では表
2
の実験条 件に基づいて評価を行うが,クリーン音声のみ12
話 者分のATR216
音素バランス単語を用いた.一方,提案手法で音声認識性能を予測するときは,
複数の評価音声を用いて算出した
PESQ
の平均値を 用いるが,このPESQ
の平均値を算出するのに十分 な音声データ数を明らかにする必要がある.そこで予 備実験として,表2
に示すクリーン音声(合計864
発 話),エレベータホールのインパルス応答(1
ヶ所),そ して白色雑音(SNR=10 dB
)を用いて評価音声デー タを用意してPESQ
の平均値と分散値を評価した.そ の結果,50
発話以上の評価音声データを用いること で,全てのデータを用いた場合と同等のPESQ
の平 均値と分散値を達成したことから,本実験ではPESQ
算出に用いる評価音声データ数を各環境につき50
発 話とした.表5 音声認識性能予測に必要なデータ量 Table 5 Data for estimation of speech recognition
performance.
Conventional method Speech 216 words×12 speakers = 81 MB Total 81 MB×248 RIRs×2 noises×8 SNRs
=321.408 GB
Proposed method 1. D value
Laboratory (72 RIRs = 2.1 MB) + Subtotal Corridor (120 RIRs = 4.5 MB) +
Standard stairs (56 RIRs = 3.0 MB)
= 9.6 MB 2. PESQ
Speech 50 words = 1.575 MB
Subtotal 1.575 MB×248 RIRs×2 noises×8 SNRs 6.250 GB
Total 9.6 MB + 6.250 GB6.260 GB
4. 6
音声認識性能予測のコスト評価に関する実験 結果音声認識性能予測に必要なデータ量を表
5
に,そし て計算時間を表6
に示す.表5
に示すデータ量の結果 より,従来の音声認識性能評価では合計で約321 GB
の評価音声データを必要としていたのに対して,提案 手法を用いることでデータ量を約6.3 GB
まで大幅削 減することができた.また,表6
に示す計算時間にお いても,従来手法(1
環境当り約4
分)と比較して,提案手法(
1
環境当り約46
秒)を用いることで,お よそ8
倍の速さで音声認識性能を予測することができ た.しかしながら,提案手法では50
発話のPESQ
を 計算するのに41.4
秒を必要としているため,更なる 計算コスト削減のためにはPESQ
算出の高速化が重 要であると考えられる.これらの評価結果より,提案 手法を用いることで,音声認識性能予測に要するコス トを大幅に削減できることが明らかとなった.5.
む す び実環境下における音声認識ではマイクロホンから離 れた地点で発話すると壁や床からの反射音や雑音の混 入の影響を受けて音声認識性能が低下する.ここで外 乱による音声認識性能の劣化を事前に予測できれば,
その予測結果に基づいて外乱対策を適切に講じること ができ,音声認識性能の劣化を未然に防ぐことができ る.そこで本研究では,雑音にも残響にも頑健な音声 認識性能の予測指標を提案し,雑音・残響下における 音声認識性能の高精度な予測を試みた.評価実験の結
表6 音声認識性能予測の計算時間
Table 6 Computation time for estimation of speech recognition performance.
Conventional method 1. RIR convolution: 214.9 sec.
2. Noise addition: 21.2 sec.
3. Speech recognition: 120.1 sec.
Total 214.9 sec.+21.2 sec.+120.1 sec.=356.2 sec.
Proposed method 1. D value
D value calculation: 1 ms.
2. PESQ
1. RIR convolution: 4.2 sec.
2. Noise addition: 0.4 sec.
3. PESQ calculation: 41.4 sec.
Total 1 ms.+4.2 sec.+0.4 sec.+41.4 sec.46.0 sec.
果,提案した雑音・残響指標を用いることで,残響指 標(
D
値)単体や雑音指標(PESQ
)単体と同程度あ るいはそれ以上の予測性能を達成できた.今後は提案 手法の実用化に向けて,D
値を算出するためのインパ ルス応答や事前にクリーン音声を必要とするPESQ
を 簡便に推定できる手法の検討に取り組む予定である.謝辞 本研究の一部は,科研費特別研究員奨励費,
科研費基盤研究による研究助成を受けた.また社団法 人 情報処理学会 音声言語情報処理研究会 雑音下音 声認識評価ワーキンググループの諸氏に感謝する.
文 献
[1] J.L. Flanagan, J.D. Johnston, R. Zahn, and G.W.
Elko, “Computer-steered microphone arrays for sound transduction in large rooms,” Journal of the Acoustical Society of America, vol.78, no.5, pp.1508–
1518, Nov. 1985.
[2] O.L. Frost, “An algorithm for linearly constrained adaptive array processing,” Proc. IEEE, vol.60, no.8, pp.926–935, Aug. 1972.
[3] M.J.F. Gales and S.J. Young, “An improved ap- proach to the hidden markov model decomposition of speech and noise,” Proc. ICASSP, vol.1, pp.233–
236, 1992.
[4] H.M. Cung and Y. Normandin, “Noise adaptation algorithms for robust speech recognition,” Speech Communication vol.12, no.3, pp.267–276, July 1993.
[5] S. Furui, “Cepstral analysis technique for automatic speaker verification,” IEEE Signal Proc. Society, vol.29, pp.254–272, April 1981.
[6] M. Miyoshi and Y. Kaneda, “Inverse filtering of room acoustics,” IEEE Trans. Acoust. Speech Signal Pro- cess., vol.ASSP-36, pp.145–152, 1988.
[7] 清水秦博,梶田将司,武田一哉,板倉文忠,“空間音響特性を 考慮したスペースダイバシチ型音声認識,”信学論(D-II), vol.J83-D-II, no.11, pp.2448–2456, Nov. 2000.
[8] T. Takiguchi, M. Nishimura, and Y. Ariki, “Acoustic model adaptation using first-order linear prediction for reverberant speech,” IEICE Trans. Inf. & Syst., vol.E89-D, no.3, pp.908–914, March 2006.
[9] T. Yamada, M. Kumakura, and N. Kitawaki, “Per- formance estimation of speech recognition system un- der noise conditions using objective quality measures and artificial voice,” IEEE Trans. ASLP, vol.14, no.6, pp.2006–2013, Nov. 2006.
[10] M.R. Schroeder, “New method of measuring rever- beration time,” JASA, vol.37, pp.409–412, 1965.
[11] R. Petrick, X. Lu, M. Unoki, M. Akagi, and R.
Hoffmann, “Robust front end processing for speech recognition in reverberant environments: Utilization of speech characteristics,” Proc. INTERSPEECH 2008, pp.658–661, Sept. 2008.
[12] 福森隆寛,森勢将雅,西浦敬信,山下洋一,“室内音響指 標を用いた残響指標RSR-Dnに基づく残響下音声認識性 能の予測,”信学論(D),vol.J94-D, no.4, pp.712–720, April 2011.
[13] “Perceptual evaluation of speech quality (PESQ):
An objective methodfor end-to-end speech quality assessment of narrow-bandtelephone networks and speech codes,” ITU-T Rec. P.862, 2001.
[14] ISO3382:Acoustics-Measurement of the reverberation time of rooms with reference to other accoustical pa- rameters. Internatinal Organization for Standardiza- tion, 1997.
[15] K. Takeda, Y. Sagisaka, and S. Katagiri, “Acoustic- phonetic labels in a Japanese speech database,” Proc.
European Conference on Speech Technology, vol.2, pp.13–16, Oct. 1987.
[16] A. Lee, T. Kawahara, and K. Shikano, “Julius — An open source real-time large vocabulary recogni- tion engine,” Proc. European Conf. on Speech Com- munication and Technology, pp.1691–1694, 2001.
[17] 電子協騒音データベース,http://research.nii.ac.jp/src/
JEIDA-NOISE.html
[18] 鹿野清宏,伊藤克亘,河原達也,武田一哉,山本幹雄,IT Text音声認識システム,オーム社,2001.
[19] 田中敏幸,数値計算法基礎,コロナ社,2006.
[20] AURORA-J/CENSREC, http://www.slp.cs.tut.ac.jp /CENSREC/
[21] T. Fukumori, T. Nishiura, M. Nakayama, Y. Denda, N. Kitaoka, T. Yamada, K. Yamamoto, S. Tsuge, M.
Fujimoto, T. Tetsuya, C. Miyajima, S. Tamura, T.
Ogawa, S. Matsuda, S. Kuroiwa, K. Takeda, and S.
Nakamura, “CENSREC-4: An evaluation framework for distant-talking speechrecognition in reverberant environments,” Acoustical Science and Technology, vol.32, no.5, pp.201–210, Sept. 2011.
(平成26年6月7日受付,10月6日再受付,
12月4日早期公開)
福森 隆寛 (学生員)
平22年 立命館大・情報理工・メディア 情報卒.平24年 同大大学院・理工学研究 科・博士課程前期課程程了.同年4月 同大 大学院・情報理工学研究科・博士課程後期 課程入学.同年4月 日本学術振興会特別 研究員(DC1),現在に至る.音声・音響 信号処理の研究に従事.日本音響学会,情報処理学会,各会員.
中山 雅人 (正員)
平13年 近畿大・生物理工・電気システ ム情報工卒.平15年 和歌山大大学院・シ ステム工学研究科・博士前期課程修了.平 20年 立命館大大学院・理工学研究科・博 士後期課程満了.博士(工学).立命館大・
情報理工・助教及び近畿大・生物理工・非 常勤講師.音響信号処理,音声情報処理に関する研究に従事.
日本音響学会会員.
西浦 敬信 (正員)
平9年 奈良高専・専攻科・電子情報卒.
平11年 奈良先端大・情報科学研究科・博 士前期課程修了.平13年 同大博士後期課 程修了.同年 和歌山大・シス工・助手.平 16年 立命館大・情報理工・助教授.平19 年 同准教授,平26年同教授,現在に至る.
博士(工学).音響信号処理,主として音環境の解析・理解・再 現・生成に関する研究に従事.日本音響学会,情報処理学会,
日本騒音制御工学会,日本バーチャルリアリティ学会,各会員.
山下 洋一 (正員)
昭57年阪大・工・電子卒.昭59年同大 大学院修士課程修了.同年阪大・産研・文 部技官,平5年同助手,平6年同講師,平 9年立命館大・理工・助教授,平13年同 教授,平16年同大・情報理工・教授,現 在に至る.博士(工学).音声情報処理に 関する研究に従事.日本音響学会,情報処理学会,人工知能学 会,ISCA,IEEE各会員.

![Fig. 5 Overview of estimating speech recognition performance. [Step 2] 音声認識性能の予測Step 1で計測したD値, PESQ と残響時間を式 (3)の雑音・残響指標NRSR-PAの評価関数に適用することで音声認識性能の予測を試みる.4.雑音・残響指標NRSR-PAの性能評価実験雑音・残響指標NRSR-PAの有効性を明らかにするために評価実験を行った.まず,様々な残響時間の実環境において算出したD値,PESQと音声認識性能の関係について](https://thumb-ap.123doks.com/thumbv2/123deta/5628948.1500693/5.774.81.352.745.957/FigOverview音声認識性能予測Step計測D値残響試みる響指標明らかについて.webp)