オンチップルータにおける
バッファ構成最適化手法に関する研究
指導教授 柳澤 政生 教授
早稲田大学大学院 理工学研究科 情報・ネットワーク専攻
3606U090–3 傍士 雄介 Yusuke Houji
2008 年 2 月 4 日
第1章 序論 3
1.1 本論文の背景と目的 . . . . 4
1.2 本論文の概要 . . . . 6
第2章 Network-on-a-Chip 7 2.1 本章の概要 . . . . 8
2.2 NoC の基礎知識. . . . 9
2.2.1 ネットワークトポロジ . . . . 9
2.2.2 パケット転送法 . . . . 10
2.2.3 ネットワークインタフェース . . . . 13
2.2.4 オンチップルータ . . . . 16
2.2.5 ルーティング法 . . . . 17
2.3 バスアーキテクチャとの比較 . . . . 20
2.4 NoC アーキテクチャ最適化に関する研究 . . . . 23
2.5 本章のまとめ . . . . 25
第3章 バッファ構成最適化手法 26 3.1 本章の概要 . . . . 27
3.2 バッファ構成最適化問題 . . . . 28
3.3 既存手法 . . . . 31
3.4 提案手法 . . . . 35
3.4.1 NoCシミュレータ . . . . 35
3.4.2 パケット転送のブロック . . . . 36
3.4.3 バッファ構成最適化フロー . . . . 39
3.5 本章のまとめ . . . . 42
第4章 計算機実験結果 43 4.1 本章の概要 . . . . 44
4.2 シミュレーション方法 . . . . 45
4.3 Uniform Traffic . . . . 46
4.4 Hotspot Traffic . . . . 48
4.5 提案手法の評価 . . . . 50
4.6 本章のまとめ . . . . 53
第5章 結論 54
謝辞 57
参考文献 58
序論
1.1 本論文の背景と目的
近年,SoC設計におけるIPコア同士を結合するチップ内接続網としてNetwork- on-a-Chip(NoC)が提案され,バスアーキテクチャに代わる技術として注目を集
めている[9][20].SoCにおいて,IP コア同士を結合するチップ内接続網は,アプ
リケーションの性能とコストを決定付ける重要な要素である.これを受けて.チッ プ内接続網として従来から用いられているバスアーキテクチャにおいても,バス の階層化等,様々な性能改善手法が提案されている.しかし,プロセス技術の微 細化に伴い,ゲート遅延よりも配線遅延の影響が深刻化し,バス・アーキテクチャ のグローバル配線が性能のボトルネックとなりつつある.また,プロセス技術の 微細化は,クロストーク等の事前に予測することが困難な物理事象を引き起こし,
不確実なチップ内通信が問題となる.
このような背景から,並列計算機やSystem Area Network(SAN)で用いられ てきたパケット転送技術をチップ内のIP コア間のデータ転送に応用し,チップ内 でネットワークを構築するNoC が注目を浴びている.図1.1はNoC の概念を表 したものである.チップ内ネットワークではプロセッサコアやオーディオ/ビデオ コーデックなどの専用IP,広範なインタフェースIP(USB,イーサネット,シリ
アルATA,DVB-H,HDMI等)やメモリ等をオンチップルータとネットワークイ
ンタフェースを介して接続する.これらのネットワークでデータを送信する場合,
送信元ノード1のネットワークインタフェースでデータにヘッダを加えパケット化 し,オンチップルータがこれを転送,最終的に宛先ノードでデータが取り出され る.複数のパケットが同時に同一チャネルを取り合わない限り,複数パケットを並 列に転送できるので,バスよりも通信帯域に優れている.また,チップ内ネット ワークではパケットを構成する各フリットは固定長のリンク上を移動し,ルータ ごとにバッファリングされる.そのため,グローバル配線はいくつかの隣接ノー ド間配線に置き換えられ,配線遅延の問題も解決できる.さらに,チップ内ネッ トワークにエラー訂正や再送技術を導入することで,信頼性の高い通信が可能に
DSP
RAM
CPU Co-
processor MPEG
CPU
リンク ネットワーク
インタフェース
ルータ
図 1.1: Network-on-a-Chip.
なると期待されている.
しかし,一方でNoC アーキテクチャを用いるには面積,消費電力のオーバー ヘッドが問題となる.これらのオーバーヘッドは,ネットワークを構成する大量 のオンチップルータによる影響が大きい.そしてオンチップルータにおいて多く の面積,消費電力を占めるのが,各チャネルに設けられるバッファ領域である.こ の問題に対する最も単純な解決策として,使用するバッファ資源を減らす(バッ ファ長を短くする,仮想チャネルを用いない)ことが挙げられる. しかし,単純 にバッファ領域を小さくするだけでは,ネットワークの性能が低下する. そこで チャネルごとの効率的なバッファ構成の構築が必要となる.具体的には,よりト ラフィックの負荷が大きい,あるいは重要なチャネルには多くのバッファ資源を 割当て,そうではないチャネルには少量のバッファ資源を割当てる. そうするこ とで,少量のバッファ資源で高いネットワークのパフォーマンスを実現できる.
このような背景から,NoCを設計するために使用可能なバッファ資源は有限で あると考える必要がある.提案手法では,限られたバッファ資源を用いて,各チャ ネルに最適なバッファ構成を構築することを目的とする.本論文で提案するバッ ファ構成最適化手法を用いることで,ターゲットアプリケーションにおいて予測 される通信パターンに基づいて,各チャネルのバッファ構成を自動的に構築する ことが可能となる.
1本論文では,チップ内ネットワークによって結合されるIPコアをノードと呼ぶ.
1.2 本論文の概要
本論文は5章で構成される.以下に各章の概要を示す.
第2章「Network-on-a-Chip」では,NoC の基礎事項について説明し,従来 のチップ内接続形式であるバスアーキテクチャとの比較を行い,その優位性,問 題点を考察する.そしてNoC アーキテクチャの最適化手法に関する研究動向を 示す.
第3章「バッファ構成最適化手法」では,バッファ構成最適化問題を示し,バッ ファ長の最適化を図る既存手法について説明する.そしてシミュレーションベー スのバッファ構成最適化手法を提案する.既存手法は待ち行列モデルを基にした 高速な手法だが,提案手法はシミュレーションベースであり,解の探索時間は多く かかる.しかし,提案手法は既存手法では対応できないワームホールルーティン グと仮想チャネルに対応することが可能である.現在,NoC においてはオンチッ プルータの面積,消費電力の観点から,この仮想チャネルを用いたワームホール ルーティングが最適であると言われている.
第4章「計算機実験結果」では,ネットワークで発生するパケットの入力パター ンとしてuniform trafficとhotspot trafficを想定し,提案手法の有効性を示す.ま ず,uniform traffic とhotspot traffic について,全てのチャネルを均一なバッファ 構成とした場合の実験結果について述べる.そして提案手法を適用した結果との 比較を行い,提案手法の有効性を示す.
第5章「結論」では,本論文全体のまとめと今後の課題について述べる.
Network-on-a-Chip
2.1 本章の概要
本章では,Network-on-a-Chip(NoC) に関する基礎知識や問題点,研究動向 について述べる.
2.2節「NoC の基礎知識」では,NoCを構成する各要素について説明する.具 体的にはネットワークの接続形態を表すネットワークトポロジ,ネットワーク上 でのパケット転送法,ルーティング法,そしてネットワークを構成するハードウェ ア的な要素としてネットワークインタフェース,オンチップルータについて文献 調査の結果も含めて述べていく.
2.3節「バスアーキテクチャとの比較」では,文献[3]による,従来のチップ内 接続網であるバスアーキテクチャとNoC アーキテクチャの性能比較を紹介する.
バスアーキテクチャとしてクロスバで接続した階層型バスを用い,NoC アーキテ クチャとして改良型のMESHトポロジを用いる.そして処理速度,スケーラビリ ティ,面積,消費エネルギーの観点から考察をい,NoCの優位性と問題点を明ら かにする.
2.4節「NoC アーキテクチャ最適化に関する研究」では,NoC アーキテクチャ の最適化を目的とする既存研究について説明する.ここで説明するのは,各IPコ ア間の通信量を事前に見積り,その通信情報を入力とする手法であり,提案手法 でも同様の入力を想定している.
2.2 NoC の基礎知識
本節では本研究を行うにあたって必要となるNoCの基礎知識について述べる.
具体的にはネットワークの接続形態を表すネットワークトポロジとネットワーク 上でのパケット転送法,ルーティング法について述べ,ネットワークを構成する ネットワークインタフェース,オンチップルータについて説明する.
2.2.1 ネットワークトポロジ
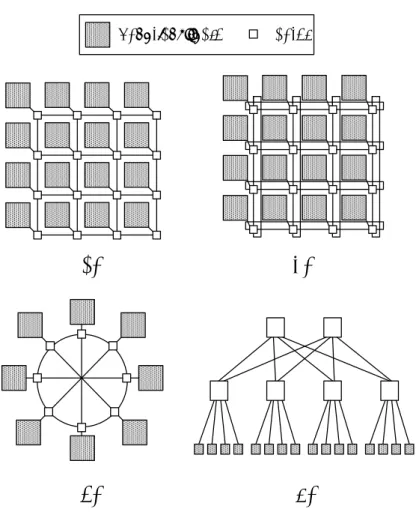
NoCは複数のノードとオンチップルータ(以後ルータと呼ぶ)を接続して構成 される.データを送信する場合,送信元ノードでパケット化されたヘッダ情報を 持つデータをルータで解析し,ルーティングを行い,最終的に宛先ノードでデー タが取り出される.NoC のトポロジは,ノードとルータの物理的なレイアウトを 決定付けるもので,システム全体のスケーラビリティとパフォーマンスに大きな 影響を与える.
Kumar らによって提唱されたMESH[17](図2.1(a))は,m×n の格子状に配 置された最もシンプルなトポロジであり,ルータとルータと同数のノードから構 成される.各ノードとルータ,そしてルータ間は双方向の通信チャネルから構成 され,端に位置するルータ以外は全て5×5入出力ポートを持つルータとなる.こ のアーキテクチャはルーティングが非常に容易である.その結果,ルータの構造 は単純なものとなり,低面積,低消費電力なルータを使用することができる.ま た,物理的なレイアウトの際にも非常に規則正しいレイアウトが得られるため,ス ケーラビリティに優れている.
Dally らによって提唱されたTORUS[20](図2.1(b))は,基本的にはMESHと 同様の構成である.唯一の違いは端に位置するルータとその反対側の端に位置す るルータがwrap-around チャネルによって直接接続される点である.このアーキ テクチャでは,MESH と比較してパケットの伝送距離自体は長くなるが,全体的 にホップ数(経由するルータの数)が小さくなる傾向がある.また,配線数を増 やした結果として利用可能なバンド幅が大きくなり,ネットワークの混雑の回避 にもつながる.
Karimらによって提唱されたOCTAGON[4](図2.1(c))は,8つのノードとルー タ,12本の双方向通信のリンクによる八角形を基本単位とするトポロジである.
基本単位となる八角形の中ではホップ数を2に抑えることができ,各パケット通 信の経路が重なりあうことが少ないため,高いスループットが得られる.しかし,
ノード数が8以上となるシステムの場合は,多次元の八角形トポロジに拡張され る.そのため,物理的なレイアウトの段階で配置配線が複雑化してしまい,スケー ラビリティは低い.OCTAGONの物理的レイアウトの一例を図2.2(a)に示す.図 中の0〜7の数字は八角形の各頂点を意味し,16個のノードを持つ.
Pande らによって提唱されたBFT(Butterfly Fat Tree)[15](図2.1(d))は,
ノードを葉,ルータを頂点とした木構造のアーキテクチャである.木上の各ノー ドは,葉を0とする木の高さ(level ),右端から左端への順番(position)によっ て,(level, position)の座標で表される.図2.1(d)では,level 0 では4つのノー
ドがlevel 1のルータで接続され,level 2のルータは4つのlevel 1のルータと接
続されている.そしてlevel 1 のルータが接続されるlevel 2 のルータは2つとな る.BFTでは,木のレベル数はノードの数をN とした場合,log4N となる.さら
にlevel i におけるルータの数はN/2i+1 となり,N を大きくしていった場合,全
ルータの数はN/2 に近づいていく.このトポロジの利点としては,他のトポロジ と比較してもルータの数がよく制御されており,ネットワーク全体の面積が予測 しやすいという点である.さらに,ノード間のトラフィック情報を事前に知るこ とで,通信頻度の高いノードを1つのルータの子に割当てる等,ネットワークの 混雑回避にも有効である.BFTの物理的レイアウトの一例を図2.2(b)に示す.
このようにトポロジによってそれぞれ特徴を有するが,ルーティングの困難性 やそれに伴うルータ構造の複雑化,配線複雑度などはトポロジによって異なり,ど のトポロジが優れているか一概には言えない.目的に応じて最適なトポロジを選 択することが必要である.
2.2.2 パケット転送法
チップ内ネットワークで使用されるパケット転送法について述べる.パケット転 送法は,パケットの転送単位,バッファ構成によって以下の3種類に分類される.
• ストアアンドフォワード
(a) (b)
(c)
Router Functional core
(d)
図 2.1: ネットワーク・トポロジ (a)MESH, (b)TORUS, (c)OCTAGON, (d)BFT.
(a) (b)
0 1 2 3
7 6 5 4
3 2 1 0
5 4 6 7
図 2.2: レイアウト例(a)OCTAGON, (b)BFT.
• バーチャルカットスルー
• ワームホールルーティング
いずれのパケット転送法を用いるかは,ネットワークのパフォーマンスだけでな く,ルータの面積,消費電力にも影響を与える.
まず,ストアアンドフォワードは,データをパケット単位で転送する.各ルー タにパケット全体を保持できるサイズのバッファを持ち,一旦パケット全体を受 け取ってから次のルータに転送する方式である.パケットの転送に時間がかかり,
バッファサイズも大きくなることから,通常はバーチャルカットスルー,ワーム ホールルーティングが用いられる.
バーチャルカットスルーとワームホールルーティングは,パケットをフリット と呼ばれる固定長のデータに分割して転送を行う.図2.3に示すように,パケッ トはルーティング情報を持つヘッダフリットと,データ本体であるペイロードフ リットに分割され,フリットごとにパイプライン転送される.この2種類のパケッ ト転送法の違いはバッファサイズである.バーチャルカットスルーでは,パケッ ト全体を格納できるサイズのバッファを使用する.こうすることでヘッドフリッ トの転送が中断された際に,後続のフリットは複数のルータにまたがることなく バッファに保持され,ネットワークの混雑回避につながる.しかし,パケット全体 を格納できるサイズのバッファがルータの各ポートに必要となることから,バッ ファサイズが大きくなりやすく,ルータの面積,消費電力を小さく抑える必要が あるNoC には適さないと言われている[16].
パケット
フリット1 フリット2 フリット3 フリット4 フリットn
ヘッダ(パス) ヘッダ ペイロード
ヘッドフリット テイルフリット
フリットタイプ 00 フリットタイプ 01 フリットタイプ 11
・・・
フリットタイプ 01 フリットタイプ 01
ヘッダ(パス) ペイロード
図 2.3: パケットのフリットへの分割.
ワームホールルーティングもバーチャルカットスルーと基本的には同じである.
ただし,バッファサイズはバッファ長より小さいものを用いるという点で異なる.
そのため,パケット転送がブロックされた場合,後続のフリットの転送も中断さ れ,ヘッドフリットが経由したチャネルはその間,予約された状態となる.その 結果,1つのパケットが複数のルータのバッファを占有してしまうため,パケット 転送がブロックされてしまうと他のパケット転送のブロックが頻繁に発生すると いう問題点がある.例えば,図2.4のように,停止したパケットAが他のパケッ トBをブロックするという事態が発生する.そこで,図2.5のように別のバッファ を用意して仮想的な経路を設ける.これを仮想チャネルと呼ぶ.仮想チャネルを 設けることで,パケットBはブロックされることなく先に進むことができる.
仮想チャネルの追加は,原理的にはストアアンドフォワード,バーチャルカッ トスルーにも適用可能である.しかし,ワームホールルーティングに対して使用 されることが一般的である.その理由として以下の2点が挙げられる.
• パケット全体を格納するバッファを必要としないため,他の2つの方法より も少ないコストで仮想チャネルを付加することができる
• 仮想チャネルを追加する結果として,パケット転送のブロックが発生しやす いワームホールルーティングの方が性能の向上が大きい
以上の理由により,面積,消費電力,パケット転送遅延時間の観点から,仮想 チャネルを追加したワームホールルーティングがNoCに最も適していると言われ おり,提案手法でもこのパケット転送法を対象とする.
2.2.3 ネットワークインタフェース
IP 再利用設計におけるインタフェースの研究は,これまでにもバスアーキテク チャにおいて行われてきた.バスにおいてIP コアのインタフェースは,IP に適 切な信号線を接続し,必要なIP の機能を用いるために適切な手順で信号を変化さ せ,データを与えることで,IP とバスの接続を行うという機能を持つ.しかし,
IPごとにインタフェース回路を新たに設計するためにはIPの内部動作についても 知る必要があり,余計な手間が発生し,IPの再利用性を損なうことになる.そこ で,特定のCPUやバスのプロトコルに依存しない,システムLSIのオンチップ・
:パケットA :パケットB :パケットC
図 2.4: パケットのブロック.
:パケットA :パケットB :パケットC
図 2.5: 仮想チャネルの追加.
バスに特化した標準プロトコルとしてOCP(Open Core Protocol)[14]やAMBA
AXI[1] が提唱されている.このように標準プロトコルに準拠したIP を設計する
ことで,同一インターフェースをサポートするシステム設計では,インターフェー スを変更する必要がなくなり,再利用のために余計な時間をかける必要がなくな る.このようなインタフェースの標準化はNoCにも受け継がれており,ここでは OCP に準拠したネットワークインタフェースについて述べる.
まず,OCPについて述べる.OCP は,上記したように特定のCPUやバスのプ ロトコルに依存しないオンチップ・バスの規格である.OCPインタフェースがIP コアとバスを接続する様子を図2.6に示す.OCP ではマスタとスレーブでコマン ドとレスポンスを独立したタイミングで送ることができ,また,スレッドを複数 に分けることにより,コマンドの発行順とは異なる順番でレスポンスを返すこと もできる.このようにIPコアがOCPインタフェースに準拠してさえいれば,そ れをOCP インタフェースに準拠したオンチップバスと接続することができる.
マスタ
スレーブ
マスタ スレーブ スレーブ
スレーブ マスタ マスタ
IPコア IPコア IPコア
OCP インタフェース
オンチップバス
リクエスト
レスポンス
図 2.6: OCP インタフェースによるIPコアとバスの接続.
次にOCP に準拠したネットワーク・インタフェースについて述べる.図2.7は マスタとスレーブ両方を持つIPコアをネットワークに接続する様子を示してい る.IP から送られてくるOCP に対応した信号は,第2のインタフェースである ネットワーク・インタフェースでパケット化される.そして,バーチャルカット スルーやワームホールルーティングでは,ルーティング情報を持つヘッダフリッ トやデータ本体であるペイロードフリットに分割された状態でネットワークに送 信される.そしてデータを受け取る際には,データタイプに応じて不要な情報を 破棄してパケットを元のデータに戻し,データをIPに送信する.このようにして
ネットワークと各IPコアは接続される.
CORE
OCP MASTER
NETWORK FABRIC
OCP SLAVE UNPACKPACK
OCP signals packets
OCP Interface
Network Interface
図 2.7: ネットワーク・インタフェース.
2.2.4 オンチップルータ
文献[10]で説明されているルータのアーキテクチャについて述べる.まず,図 2.8の仮想チャネルを持たないワームホール・ルータについて述べる.入力チャネル のバッファに到着したヘッダフリットは,routing logicで送信方向を決定し,各入 力チャネルごとに用意されているステートマシン(inpc state)の書換えをを行う.
inpc stateでは,各パケットがrouting,switch arbitration,crossbar traversalのい ずれの状態にあるかを保持している.そして,クロスバを制御するswitch arbiter は全ての入力チャネルのinput controller からリクエスト信号を受け取り終える と,各出力ポートの状態を保持しているステートマシン(outpc state)の状態を 見て,1つのパケットにクロスバの使用許可を与える.outpc state では隣接する ルータのバッファの状態が,full であるかどうかの情報を保持している.そして,
クロスバによるパケットの転送が始まると,転送はパケットが全て送られるまで,
あるいは宛先となるoutpc state がfull の状態になるまで固定され,その後クロ スバが解放されると別のパケットに使用許可を与える.なお,switch arbiter によ るクロスバの使用許可は一般的にround-robinで行われる.
次に図2.9の仮想チャネル・ルータについて述べる.invc state では,各パケッ トがrouting,virtual channel allocation,switch allocation,crossbar traversalの いずれの状態にあるかを保持している.ヘッダフリットを受け取り,ルーティン グを行った後,vc allocator にリクエスト信号を送り,仮想チャネルの状態を保持
しているステートマシン(outvc state)の状態を見て,出力する仮想チャネルを 予約する.そして仮想チャネルの予約が成立しているパケットの中から,swtich allocatorがクロスバの使用許可を与える.vc alocator による仮想チャネルの予約 も,switch allocatorと同様に一般的にround-robin で行われる.
sw arbiter(p) inpc
state routing
lobic
・・
・・
outpc state
outpc state
・・・・
credit out
flit in
credit in
flit out Xbar(p,w)
input controller
・・
図 2.8: ワームホール・ルータ.
2.2.5 ルーティング法
ネットワークで利用されるルーティング法は,以下の2種類に分類される.
• 適応型ルーティング
• 固定型ルーティング
適応型ルーティングではパケットごとに動的に通信経路が選択されるが,固定型 ルーティングでは静的に経路を定める.適応型ルーティングは,ネットワークのト ラフィック情報をその都度ルーティングに用いるため,ルータにかかるトラフィッ ク負荷を効率的に分散できるという利点がある.しかし,ルーティングロジック 部分はハードウェア的なコストが大きくなる.一方,固定型ルーティングは静的 に経路を決定しているため,ハードウェア的なコストは小さく,またパケット転 送のFIFO 性が保証されるという利点がある.前述したように,NoCにおいては ルータの面積,消費電力のオーバーヘッドが問題となる.このことからコスト制
sw allocator(p) vc allocator(p,v) invc
state
invc state routing
lobic
・・
・・ ・・
outvc state
outvc state
・・・・・・
credit out
flit in
credit in
flit out Xbar(p,w)
input controller
・・
FIFO
FIFO
図 2.9: 仮想チャネル・ルータ.
約が厳しいチップ内ネットワークでは,より単純な固定型ルーティングが適して いる[6].
チップ内ネットワークで広範囲に利用されている固定型ルーティングとして,
XY ルーティング[21] が挙げられる.XY ルーティングはMESHやTORUS等の 格子上のトポロジを対象とする.まず,送信元ノードからx軸方向のチャネルを 使って移動し,次に,y軸方向のチャネルを使って宛先ノードに到達する.x軸方 向,y軸方向にそれぞれどれだけ進むかは,ヘッダフリットにオフセットを与え,
1つのルータを通過するたびにデクリメントする.XY ルーティングを使用する と,デッドロックの原因となるルーティングパスのループ状態が発生しないため,
デッドロックを回避できる.一方,適応型ルーティングによって提供される経路 候補の中から1つの経路を選択し,静的に経路を設定する方法もある[6].文献[5]
で提案されているodd-evenルーティングは,格子上のトポロジにおいて用いられ る適応型ルーティングの一種である.odd-evenルーティングは,以下のような制 約に基づいて経路を決定する.
1. 偶数列に配置されているルータにおけるENターン(東⇒北),ESターン
(東⇒南)を禁止
2. 奇数列に配置されているルータにおけるNWターン(北⇒西),SWターン
(南⇒西)を禁止
このような制約をルーティングに設けることで,ルーティングパスのループ状態 をなくし,デッドロックを回避している.このようにして生成されるルーティン グパスの中から,事前に経路を設定することでデッドロックフリーな経路で構成 される固定型ルーティングが実現できる.
2.3 バスアーキテクチャとの比較
文献[3]では,バス規格としてAMBA2.0 AHBを使用したMuti-Layer(ML) AMBA を用いて設計されたアーキテクチャと,変形型のmesh型トポロジ(xpipes mesh) を用いて設計されたアーキテクチャの比較が行われている.比較に用いられたプ ラットフォームを図2.10に示す.図2.10(a)の各階層のAHBバスは1つのアービ タにより通信が制御され,IPコアに対してマスタ,スレーブのインタフェースを 持つ.ML AMBAには5×5のクロスバが使用されており,異なる階層のバスが 複数のマスタとやり取りをするスレーブと接続されている.図2.10(b)のxpipes mesh はマスタ,スレーブのネットワークインタフェースを持ち,各タイルにはマ スタとスレーブ(例えばプロセッサとメモリ),ルータが含まれている.また,用 いる30個のIPブロック(15個のマスタ,15個のスレーブ)は0.13μmプロセ スを用いると単純なプロセッサ,32kB メモリが約1mm2であることから,ダイ エリアを1mm2と仮定している.これらの仮定の基,0.13μmプロセスを用いて 実装を行い得た実験結果が表2.1,2.2である.まず,得られた最高動作周波数につ
M0
P0 T0 M1
P1 AMBA AHB Layer
M2
P2 T1 M3
P3 AMBA AHB Layer
M4
P4 T2 M5
P5 AMBA AHB Layer
M6
P6 T3 M7
P7 AMBA AHB Layer
M8
P8 T4 M9
P9 AMBA AHB Layer
AMBAAHB crossbar
S10
S11
S12
S13
S14
M0
P0 T0
S10 M1
P1 M2
P2 T1
S11
M0
P0 T0
S10 M1
P1 M2
P2 T1
S11
M0
P0 T0
S10 M1
P1 M2
P2 T1
S11
(a)
(b)
図 2.10: プラットフォーム. (a) ML AMBA AHB; (b) ×pipes mesh. M: ARM7 masters; T: traffic generators; P: privately accessed slaves; S: shared slaves.
表 2.1: Pre- and post-placement achievable frequencies[3].
Max Frequency ML AMBA xpipes mesh After synthesis 480 MHz 910 MHz After place&route 400 MHz 885 MHz Frequency drop 16.7 % 2.7 %
いて,論理合成後の結果と配置・ルーティングパス決定後の結果を表2.1に示す.
表2.1の2行目を見ると,論理合成後において見積もられる最高動作周波数にお
いてxpipes mesh の方がML AMBA を大きく上回っていることが分かる.さらに
配置・ルーティング決定後の最高動作周波数においては,論理合成後からの最高 動作周波数の減少がxpipes mesh では2.7%,ML AMBA では16.7%となり,ML AMBA の方が性能の減少がはるかに大きい.これは長距離配線の伝播遅延が原 因であり,論理合成を行った段階では予測不可能な容量性負荷によるものである.
xpipes mesh は規則的な短距離配線で構成されているため損失は小さい.このよ
うに配線長をコントロールしやすく,性能予測性が高いことはNoCの長所の1つ である.
次に表2.2について述べる.まず面積だが,各IPコアの面積は1mm2と仮定し ているためIPコア部分の総面積は30mm2 であり,IPコア間を接続するために はML AMBA では約5mm2,xpipes mesh では約13mm2が割当てられている.
xpipes meshの方が面積のオーバーヘッドが大きくなることが分かる.次に利用可
能なバンド幅についてはxpipes meshが大きい.これはxpipes mesh は最高動作 周波数が大きく,且つルータ間の配線数が多いためである.消費エネルギーと実 行時間は,マルチメディアアプリケーションのベンチマークを実行した際の実験 の結果である.消費エネルギーはルータの消費エネルギーが大きいため,xpipes mesh が大きいが,ベンチマークの実行時間はxpipes mesh の方が約10%短くな る.この理由として以下の3点が挙げられる.
• 利用可能なバンド幅が大きい
• ヘッドフリットに対してはパケット化や各ルータでのルーティング処理に 時間がかかるが,データフリットはルータやネットワークインタフェース
を1cycleで通過するだけなので,負荷の集中するバーストトラフィックには
表 2.2: Consumption of the fabrics[3].
Achitecture Area Available bandwidth Energy Exe. Time
ML AMBA 35.30mm2 26.5 GB/s 0.072 mJ 750 μs
xpipes Mesh 43.03mm2 100 GB/s 0.339 mJ 640 μs
強い
• ネットワーク部分とIPコアを異なる動作周波数で動作させることができる ため(Global Asynchronous Local Synchronous),IPコアの動作周波数を適 切に設定することができる
両アーキテクチャともに最適化は充分ではないが,これらの実験結果から,処 理速度,スケーラビリティに関してはNoC が優れているが,面積,消費エネル ギーに関しては従来型のバスアーキテクチャの方が優れているということが言え る.このことは,NoCが次世代のチップ内接続網としての地位を確立するために は,オーバーヘッドを低く抑えた中で,高いパフォーマンスを発揮することが重 要となることを意味する.次節ではNoCアーキテクチャの最適化に関する研究に ついて述べていく.
2.4 NoC アーキテクチャ最適化に関する研究
バスアーキテクチャからNoCに変更することによって,面積,消費電力の増加 が問題となる.しかし,多くの場合,NoCの低面積,低消費電力化はネットワー クの性能を損なうことにつながる.そのため,高性能且つ低面積,低消費電力の ネットワークを実現するために数多くの研究が行われている.これらの研究のア プローチとして,各IPコア間の通信量をシステムレベルで見積り,そのトラフィッ ク情報に基づいて最適化を図るというものがある.SoC の主要なアプリケーショ ンは組込み機器であり,メディア処理や通信分野では高負荷なストリーム処理が 行われることも多い.近年のSoC 設計では,対象アプリケーションはSystemCな どのシステムレベル言語で記述され,設計の初期段階からシミュレーションされ る.この段階で,各ノードのタスク割り当てが決まるのでノード間のデータ転送 量をある程度見積もることができる.多数のタイル構造を持つリコンフィギャラ ブルシステムやオンチップマルチプロセッサにおいても,対象アプリケーション とマッピングが決まれば,同様にノード間の転送量の見積もりが可能である.
文献[6]の手法は,このような通信情報に基づいて,バンド幅制約を満たす範囲 内で低消費エネルギー化を図るマッピング手法である.固定のトポロジに対して 通信頻度の高いIPコア同士が近接するようにマッピングを行い,各通信のホップ 数(ルータを経由する回数)を削減する.
文献[8],[19]はネットワーク・トポロジに着目する手法である.文献[8]は,制
約条件と通信情報に基づいてトポロジを自由に合成する手法で,消費電力を最小 化する目的式とパケット遅延時間,面積の増加やルータ混雑を回避するための制 約式を定義して,整数線形計画問題として扱う.文献[19]はMESH トポロジを 部分的にカスタマイズする手法で,利用可能な配線資源を定義し,その範囲内で MESHの格子状の配線を迂回する長距離配線を挿入することで平均パケット遅延 時間の削減を図る.
文献[11]では,ネットワークの性能を損なうことなくハードウエアコストの大 きいバッファ領域を削減することを目的として,仮想チャネルを使用せずにルー ティング・パスを割当てる手法を提案している.
最後に文献[7]ではルータのバッファ長最適化手法が提案されている.この手法 はチャネルごとにバッファ長を最適化する手法で,少量のバッファ領域でネット ワークの高い性能を発揮することを目的としている.本研究でもこのようなバッ ファ構成最適化問題に着目しており,文献[7]については次章で詳細を述べる.
2.5 本章のまとめ
本章では,NoCに関する基礎知識や問題点,現在のNoC アーキテクチャ最適 化の研究動向について説明した.
2.2節NoC の基礎知識では,NoC を構成する各要素について説明した.ネッ トワークトポロジの代表的な例として,MESH,TORUS,SPIN,OCTAGONの 論理構造について説明し,その特徴について述べた.パケット転送法としては,3 種類の転送方式について述べ,ワームホールルーティングの優位性と仮想チャネ ルについて述べた.さらにNoC アーキテクチャ特有のハードウェア要素である ネットワークインタフェースとオンチップルータについて,そのアーキテクチャ と機能について示した.最後にルーティング法として,適応型ルーティング,固 定型ルーティングについて述べ,固定型ルーティングの優位性を示し,さらに固 定型ルーティングを実現する方法について述べた.本論文で提案する手法におい ても固定型ルーティングを前提としている.
2.3節バスアーキテクチャとの比較では,バスアーキテクチャとしてクロスバで 接続した階層型バスを用い,NoC アーキテクチャとして改良型のMESH トポロ ジを用いて性能の比較を行った.そしてその結果から,NoCはスケーラビリティ,
処理速度に優れているが,面積,消費エネルギーのオーバーヘッドが問題となる ことを示した.これらのオーバーヘッドを低く抑えつつ,ネットワークの高い性 能を実現することが必要である.
2.4節NoC アーキテクチャ最適化に関する研究では,NoCアーキテクチャ最適 化に関する研究動向について述べた.これらの研究はいずれも高性能且つ低面積,
低消費電力を目的とするもので,各IPコア間の通信量を事前に見積り,その通信 情報を入力としていることを示した.提案手法ではこれらの研究の中でも,オン チップルータのバッファ構成に着目することについて述べた.
バッファ構成最適化手法
3.1 本章の概要
本章では,オンチップルータのバッファ構成最適化問題を示し,バッファ長を 最適化する既存手法について述べ,新たなバッファ構成最適化手法を提案する.
3.2節「バッファ構成最適化問題」では,オンチップルータのバッファ構成最適化 問題について述べる.まず,NoCの問題点である面積,消費電力のオーバーヘッ ドについて説明する.そして,その解決にルータのバッファ領域削減が有効であ ることを示し,高性能且つ低面積,低消費電力のNoC を実現するためには,各 チャネルごとにバッファ構成を最適化することが有効であることを示す.F
3.3節「既存手法」では,文献[7]の手法について説明する.オンチップルータ のバッファ構成をチャネルごとに最適化する手法は,現在,文献[7]の手法以外 に確認できていない.この手法はパケット転送法としてストアアンドフォワード,
バーチャルカットスルーを対象とし,待ち行列モデルを用いてオンチップルータ の各チャネルのバッファ長を最適化する手法である.手法の内容と共に,問題点 を示す.
3.4節「提案手法」では,提案手法で用いるNoCシミュレータの仕様を説明し,
シミュレーションベースのバッファ構成最適化手法を提案する.提案手法では,シ ミュレーションによってボトルネックとなるチャネルを検出し,そのチャネルに 対して逐次バッファ資源を割当てていく.その際の,ボトルネックチャネルの検 出方法として,パケット転送のブロックの分類と判別方法について説明する.そ して,検出したブロック回数に基づくバッファ構成最適化フローを示す.
3.2 バッファ構成最適化問題
チップ内の接続アーキテクチャとしてNoCを使用する場合,面積,消費電力の オーバーヘッドが問題となる.その主要な原因は,ルータに要するコストである.
これは,バスアーキテクチャと比較して,NoCではトラフィックのアービトレー ション回路であるルータを大量に必要とするためである.そして多くの場合,ルー タの面積,消費電力の大部分をバッファが占める[13],[7]. 例えば,文献[7]では 5×5入出力のルータにXYルーティングを実装し,各リンクのバンド幅を32[bits]
として0.16[μm]テクノロジを用いて実装を行っているが,この時,各入力ポー
トのバッファ長を64[bits]から96[bits]に増やした場合,ルータの面積は30% 増 加している.
この問題に対する最も単純な解決策として,使用するバッファ資源を減らす(バッ ファ長を短くする,仮想チャネルを用いない)ことが挙げられる. しかし,単純に バッファを小さくするだけでは,ルータの面積,消費電力は小さくなるが,ネット ワークの性能は低下する. バッファ構成を変更することで,ネットワークのパフォー マンスにどのような影響があるかを検証するためにシミュレーションを行った. こ の実験はパケット長を16[flits],トポロジを8×8 meshとしXYルーティングを実装 している.また,パケット生成期間を10000[cycles]とし,この期間に生成されたパ ケットが全て宛先ノードに到着するまでシミュレーションを行い,10回分の平均値 をとった.トラフィックの発生パターンは4.3節で述べるuniform trafficで,ランダ ムにパケットを発生させている.またシミュレーションには3.2節で説明するNoCシ ミュレータを用いた. 図3.1と図3.2は,それぞれ異なるパケット発生率とバッファ構 成における平均パケット遅延時間とスループットである. これらの図を見ると,バッ ファ使用量を増やすことで平均パケット遅延時間が減少し,より高いスループットが 得られている.例えば,パケット発生率1が0.007[packets/cycle/node]の場合,仮想 チャネル数が4(VN=4),バッファ長2が16[flits](BD=16)の時(plot A)の平均パ ケット遅延時間3は157.91[cycles]でスループット4は0.006676[packets/cycle/node],
1パケットが1サイクルの間に特定のノードで発生する確率.
2バッファ長はフリット単位でカウントする.
3パケットが発生してから宛先ノードにパケット全体が到着するまでの平均時間.
4パケットが1サイクルの間に特定のノードに到着する確率.
一方,VN=2,BD=4 の時(plot B)の平均パケット遅延時間は724.19[cyles]でス ループットは0.005606[packets/cycle/node]となり,バッファ使用量を増やすこと がネットワークのパフォーマンス改善につながることが分かる.
しかし,上記したようにバッファ使用量を増やすことが面積,消費電力に与え る影響は大きい. そこで効率的なバッファ構成の構築が必要となる. メモリやプ ロセッサ,DSP等異なるコンポーネントを混載するSoC において,多くの場合,
ネットワークのトラフィックは均一ではない. そのため,よりトラフィックの負荷 が大きい,あるいは重要なチャネルには多くのバッファ資源を割当て,そうでは ないチャネルには少量のバッファ資源を割当てる. そうすることで,均等に各チャ ネルにバッファ資源を割当てる場合よりも少量のバッファ資源で,高いネットワー クのパフォーマンスが得られると考えられる.文献[12]では,バッファを効率的に 割当てた場合と均等なバッファ構成の場合とで実験を行い,50% 以上平均パケッ ト遅延時間が短縮されるという結果を得ている.また,このことは第4章の実験 結果でも確認することができた.
このように同量のバッファ資源が使用可能であった場合,どのチャネルにバッ ファ資源を多く割当てるのか,そしてそのバッファ資源をバッファ長を増やすた めに使うのか,あるいは仮想チャネルを増やすために使うのかによって,ネット ワークのパフォーマンスは大きく変化する.一方で,最適なバッファ構成を得る ために,チップ上のチャネルのバッファ構成を全通りシミュレーションすること は現実的に不可能である.そこで,ターゲットアプリケーションにおいて予測さ れる通信パターンに基づいて各チャネルのバッファ構成を自動的に生成する提案 手法が有効となる.
0 200 400 600 800 1000 1200 1400 1600 1800 2000
0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 0.009 0.010
パケ ット 発生率 (pa ckets/cy cle/node)
平均パケット遅延時間(cycles)
VN:2,BD:4 VN:2,BD:8 VN:2,BD:16 VN:4,BD:4 VN:4,BD:8 VN:4,BD:16
plot A plot B
図 3.1: 平均パケット遅延時間.
0 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008
0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 0.009 0.010 パケッ ト発生率 (pa cket s/cy cle/noce)
スループット(packets/cycle/node)
V N:2,BD:4 V N:2,BD:8 V N:2,BD:16 V N:4,BD:4 V N:4,BD:8 V N:4,BD:16
plot A plot B
図 3.2: スループット.
3.3 既存手法
提案手法と同様に,オンチップルータの各チャネルのバッファ構成を最適化す る研究として文献[7]の手法がある.文献[7]で提案されているシステムは,m×n MESH トポロジとし,固定型ルーティングのルーティング法としてXY ルーティ
ングとodd-even ルーティングの2パターンを実装している.そして,パケット
転送法としてストアアンドフォワード,バーチャルカットスルーを対象とし,待 ち行列モデルを用いてオンチップルータの各チャネルのバッファ長を最適化する.
ストアアンドフォワードとバーチャルカットスルーは,いずれも各チャネルにパ ケット全体を格納できるサイズのバッファを持つパケット転送法である.文献[7]
では,これらのパケット転送法を用いた上で,全てのパケットは同じサイズであ ると仮定し,パケット転送の中断が発生しない環境を想定している.このように パケット転送を単純化することで,各パケットに対するルータの処理時間を一定 と考えることができ,事前にサイクル単位で計算することが可能となる.
表3.1にこの手法で用いられているパラメータを示す.これらのパラメータを 用いると目的関数は以下の式で表される.
Given:
利用可能なバッファ資源 B
アプリケーションの通信特性 ax,y,dxx,y0,y0
オンチップルータにおけるパケット処理時間 S ルーティング・ファンクション R
Determine:
平均パケット遅延時間 Lが最小となる各チャネルのバッファサイズ lx,y,dirを求 める.すなわち,
min(L) s.t.X
∀x
X
∀y
X
∀dir
lx,y,dir ≤B. (3.1)
この目的関数を満たすために,まず各チャネルに最小のバッファ長を与え(この 場合はパケット1つ分のバッファ長),バッファ資源制約の範囲内でボトルネック となるチャネルのバッファ長を増やしていく.このボトルネックとなるチャネルを 検出する指標として,チャネル Cx,y,dirにおいてバッファが一杯になっている確率
bx,y,dirを用いる.そしてこのbx,y,dirを解析するために用いられるのがM/M/1/K待 ち行列モデルである.初めの2つの“M”はcustomar の到着時間とserverのサー ビス時間が指数分布に従うことを意味し,“1”はserver の数が1つであること,
“K”は行列が有限であることを意味している.この場合,チャネルCx,y,dirは長さ
lx,y,dirの有限行列としてモデル化され,サービス率µx,y,dirで処理されるパケット
の到着率はλx,y,dirとしてモデル化されている.そして,パケットの到着率λx,y,dir
は,固定型ルーティングによって事前に各通信のパスが決定されており,また,パ ケット転送が途中で中断されないため,事前に計算することができる.λx,y,dirは,
パケットの発生確率ax,yと発生したパケットが(x0, y0)を通る確立dxx,y0,y0 を用いて 以下の式で表される.なお,例としてdir=North の場合を示す.
λx,y,N =X
∀j,k
X
∀j0,k0
aj,k×dj,kj0,k0×R(j, k, j0, k0, x, y, N) (3.2) このとき,R(j, k, j0, k0, x, y, N)はP Ej,kからP Ej0,k0に向かうパケットがチャネル
Cx,y,Nを通る場合は1,そうでない場合は0とする.また,バッファが一杯になっ
ていることによりパケット転送がブロックされる確率bx,y,N はM/M/1/Kモデル の公式により,以下の式で表される.
ρx,y,N = λx,y,N µx,y,N
(3.3) bx,y,N = 1−ρx,y,N
1−ρlx,y,Nx,y,N+1 ×ρlx,y,Nx,y,N (3.4) よって,サービス率µx,y,dirを求めることで,bx,y,dirを求めることができる.
ここからさらに平均待ち時間等を用いた近似によって以下の式が得られる.
µx,y,N =pNx,y,N ×µNx,y,N +pEx,y,N ×µEx,y,N +pWx,y,N ×
µWx,y,N +pSx,y,N ×µx,y,NS +pLOx,y,N ×µLOx,y,N (3.5)
µx,y,N =λx,y,N + 1
1
1/S−λx,y,N + µ 1
x,y,N−λx,y,N
(3.6)
この非線形方程式をMatlab の関数 fsolve を用いて解くことにより,オンチップ ルータのチャネルごとにµx,y,dirを求めることができ,式(3.3),(3.4)を用いてbx,y,dir が分かる.bx,y,dirが最も大きいチャネルがボトルネックである.そしてこれらの 解析モデルを用いて以下の手順でバッファ長の最適化が行われている.
1. 初期構成(各チャネルにパケット1個分のサイズのバッファ)の状態でチャ ネルごとにbx,y,dirを求める.
2. ボトルネックとなるチャネルにパケット一個分のバッファ長を追加.
3. これまでに割当てたバッファの合計がバッファ資源制約Bの範囲内であるか どうかを確認し,範囲内であれば再びボトルネックとなるチャネルの検出,
Bに達しているなら終了する.
計算複雑度はCをチャネルの数とし,F(C)を非線形計画問題のソルバーの複雑 度とした場合,O(B×F(C))で得られる.
文献[7]では以上のようにしてバッファ長の最適化を図る.長所として
• 数学的な解析モデルを使用しているため非常に高速である という点が挙げられるが,短所として
• ワームホールルーティングに対応できない
• パケット長を一定にする必要がある
• 仮想チャネルの追加に対応できない
等が挙げられる.これらの欠点はパケット転送を単純化する必要性からきている が,いずれもNoC の性能を減少させる要因となる.ストアアンドフォワードと バーチャルカットスルーは,パケット全体を格納できるサイズのバッファが各チャ ネルに必要となる.また,パケット長を一定にしなければならない.よってパケッ ト長の設定が重要となる.まず,パケット長を短くするという方法が考えられる が,マルチメディア処理のように大量のデータをやり取りする必要がある場合,同 一の宛先のパケットを分けて送信することになり,性能低下の原因となる.一方 で,パケット長を長くした場合においてもバッファサイズが大きくなってしまう という問題がある.提案手法はシミュレーションベースとしているため,解の探 索時間は長くかかるが,これらの問題点を克服するものである.
表 3.1: Parameter Notation[7]
Parameter Description
SP The size of a packet
B The total buffering space budget L The average packet latancy
S Packet service time in a router without contention dir Direction,i.e. North,South,East,West,Local
R Routeing function
Rx,y The router located at tile (x, y)
Cx,y,dir Thedirdirection input channel in routerRx,y
P Ex,y The PE located at tile (x, y) lx,y,dir The buffer size of channelCx,y,dir
ax,y Packet injection rate ofP Ex,y
dxx,y0,y0 The probability of a packet generated byP Ex,y to be delivered toP Ex0,y0
λx,y,dir The packet arrival rate at channelCx,y,dir
pdirx,y,dir0 The probability of a packet at channelCx,y,dir to be delivered towarddir0 direction µx,y,dir The service rate for packet at channelCx,y,dir
ρx,y,dir The unilization factor of channelCx,y,dir
bx,y,dir The probability of the buffer atCx,y,dir being full
3.4 提案手法
現在,ワームホールルーティング,仮想チャネルに対応したバッファ構成最適 化手法は提案されていない.提案手法はこれらに対応するものであり,限られた バッファ資源の範囲内での平均パケット遅延時間の最小化を目的とする.パケッ ト遅延時間とはヘッドフリットが処理ノードから1対1で接続されているルータ に送信されてから,テイルフリットが宛先ノードに送信されるまでに要するサイ クル数である. まず,シミュレーションによってパケット転送のブロックの発生回 数を検出し,ボトルネックとなるチャネルを発見する.そして,ボトルネックと なるチャネルに対して,バッファ長を追加,あるいは仮想チャネルを追加するこ とでバッファ資源を割当てていく.
なお,仮想チャネルを追加することによって,仮想チャネルを選択する部分に 面積等のオーバーヘッドが発生するが,提案手法では考慮しない.これは発生す るオーバーヘッドは使用するバッファ資源と比較して十分に小さいことに起因し,
文献[12]においてもオーバーヘッドを考慮せずにバッファ構成を比較している.
3.4.1 NoC シミュレータ
作成したNoC シミュレータは,C++言語で記述されたフリットレベルのイベ ントドリブン型シミュレータである.ネットワークにおけるパケット通信の平均 パケット遅延時間,スループット,そして,後述するパケット転送のブロックの 発生回数を出力する.
トポロジにはMESH を用い,ルーティング法としてXY ルーティングを実装 している.パケット転送法にはワームホールルーティングを用い,ヘッダとして
1-flit分を持ち,パケット長は全て同じにするかランダムで設定することができる.
各ルータは5つのポートを持ち,1つはノードとルータの接続に,残りは隣接ルー タとの接続に用いる.ルータは2.2.4節で説明したアーキテクチャを用いる.仮想 チャネル・ルータではヘッダフリットの転送に以下の4サイクルを要する.
1. routing computation:ヘッダフリットを解析して送信方向を決定し,転送方 向の仮想チャネルとの関連付け要求をvc allocatorに送る.
2. virtual-channel allocation:パケットを受け取る側のルータの入力チャネル から,関連付けがされていない仮想チャネルをラウンドロビンで選択し,パ ケットと関連付ける.
3. crossbar allocation:関連付けが成立している全入力チャネルの仮想チャネ ルから,1組にだけクロスバの使用許可を与える.
4. crossbar transfer:関連付けられた仮想チャネルにフリットを転送する.
仮想チャネル無しのルータではvirtual-channel allocationを除く3サイクルかかる.
なお,現在はこれらの条件で提案手法を実装しているが,シミュレータのプロ グラムを変更することで,他のネットワーク・トポロジやパケット転送法,ルー ティング法にも適用可能である.
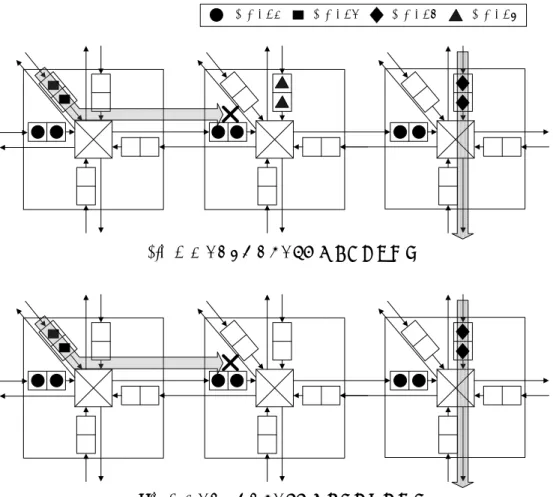
3.4.2 パケット転送のブロック
ネットワークで発生するパケット転送のブロックは,
1. バッファ長を増やすことで回避できるブロック 2. 仮想チャネルの追加で回避できるブロック 3. バッファ構成の変更では回避できないブロック
の3種類に分類することができる.提案手法では,シミュレーションによって1サ イクルごとに1. と2. のブロックの発生回数をカウントし,回数が最も多いチャ ネルをボトルネックとして検出する.そしてバッファ資源をバッファ長の増加に 割当てるか,仮想チャネルの追加に割当てるかを決定する.これらのブロックに ついて述べる.
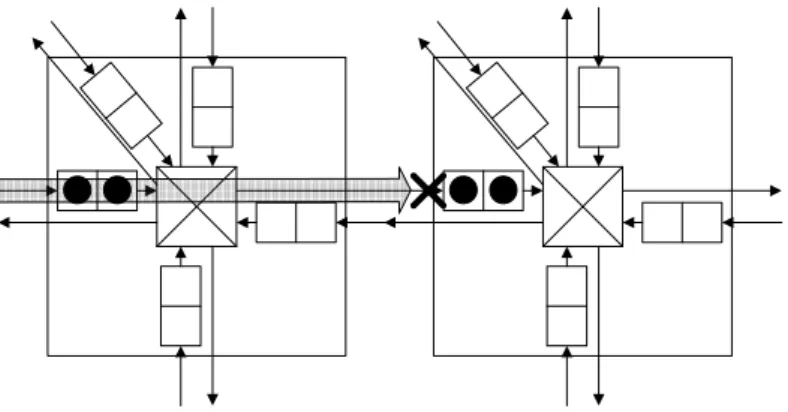
バッファ長を増やすことで回避できるブロック : crossbar allocationで検出す る.図3.3に示すように,フリットを受け取る側のバッファが一杯である場 合,パケットAの転送は中断され,そのサイクルでは他にパケットがあった としてもクロスバを使用できない.このとき,受け取る側のバッファのサイ

![表 2.2: Consumption of the fabrics[3].](https://thumb-ap.123doks.com/thumbv2/123deta/9785918.1869169/23.892.219.724.195.276/表-consumption-of-the-fabrics.webp)
![表 3.1: Parameter Notation[7]](https://thumb-ap.123doks.com/thumbv2/123deta/9785918.1869169/35.892.160.829.434.874/表-parameter-notation.webp)