国立研究開発法人産業技術研究所(以降,産業技術 総合研究所という)が人工知能に関わる研究拠点である 人工知能研究センター形成の一環として整備を進めてい る人工知能処理向け計算システムである「産業技術総合 研究所 AI クラウド(AAIC)」と「AI 橋渡しクラウド (ABCI)」を紹介する.これらはいずれも近年のコモディ ティハードウェアを活用した省電力スパコン構築の技術 トレンドを取り入れて設計されており,人工知能研究開 発における膨大な計算需要に応えると同時に,運用・管 理コストの圧縮を実現する.
1.は じ め に
産業技術研究所では,人工知能に関わる研究拠点であ る人工知能研究センター形成の一環として,段階的に人 工知能処理向け計算システムの整備を進めてきている. こうした計算システムは,人工知能・IoT 技術の研究加速・ 研究競争力の維持・強化,NEDO 次世代人工知能・ロボッ ト中核技術開発プロジェクトなどを通じて収集・開発さ れるデータおよびソフトウェアの利用促進,企業との共 同研究の迅速な立上げによる産業界との連携強化を目的 とするものである. 本解説では,産業技術総合研究所が平成 29 年 6 月か ら利用サービスを開始した「産業技術総合研究所 AI ク ラウド(AAIC)」[AAIC Computer Resource] と,平成30年度前半のサービス開始に向けて開発を進めている 「AI 橋渡しクラウド(ABCI)」を紹介する. これらは,いずれも近年のコモディティハードウェア を活用した省電力スパコン構築の技術トレンドを取り入 れて設計されている.特に,電力性能に優れたスループッ トコアを多数搭載したアクセラレータ(GPGPU,マル チコアプロセッサなど)を採用したサーバを多数集約し, サーバ間を高速ネットワークで結合した構成を採る.こ うすることで,同一の CAPEX(Capital Expenditure) を投じてその時点で入手可能な最新のハードウェアをな るべく多く確保し,ディープラーニングを含む人工知能 研究開発における膨大な計算需要に応えることができ る.その一方,OPEX(Operating Expense)の観点で は,サーバを均質にすることで運用・管理に関わる人件 費などを圧縮するとともに,省電力化によって光熱水費 (OPEX においてほぼ支配的となる)を削減することが 可能となる.
2.産業技術総合研究所 AI クラウド(AAIC)
「産業技術総合研究所 AI クラウド(AIST AI Cloud)」 (以降,AAIC という)は,平成 27 年度補正「人工知能・ IoTの研究開発加速のための環境整備事業」の一環とし て,産業技術総合研究所が整備した人工知能処理向けの 計算システムである.構築事業者は NEC であり,平成 29年 3 月に産業技術総合研究所つくば本部・情報棟の 計算機室に納入,6 月より利用サービスが開始された. システムの概観を図 1 に示す. 主な技術的特徴は,以下のとおりである. ● NVIDIA社の GPGPU(Tesla P100 SXM2)400 基 を用いたディープラーニングを含む機械学習処理の 高速実行 ● Spectrum Conductorを用いた各種ビッグデータ処人工知能・ビッグデータ処理向け
クラウド基盤の構築
─産総研 AI クラウドと AI 橋渡しクラウド─
Construction of Cloud Infrastructure for AI and Big Data Processing
─ AIST AI Cloud(AAIC) and AI Bridging Cloud Infrastructure
(ABCI)─
小川 宏高
産業技術総合研究所人工知能研究センター,Hirotaka Ogawa 実社会ビッグデータ利活用オープンイノベーションラボラトリ
Artificial Intelligence Research Center & Real-World Big Data Computation Open Innovation Laboratory, National Institute of Industrial Science and Technology(AIST)
[email protected], https://ogawa.github.io/
Keywords:
high-performance computing, cloud, GPGPU. 「AI 計算資源」9 人工知能・ビッグデータ処理向けクラウド基盤の構築─産総研 AI クラウドと AI 橋渡しクラウド─ 理用の分散フレームワーク,OpenStack ベースの IaaS機能の提供 ● 4 PiB超の大容量ストレージシステム ● 上記を組み合わせることで複合的なアプリ,サービ スの構築を支援 ● 定格で最大消費電力 150 kW の省電力設計 すでに複数の産学官のユーザが利用を開始しており, ユーザ数は 140 名以上,利用率も常時 70%を上回る. 画像認識,音声認識,自然言語処理や,ハイパーパラメー タ最適化など膨大な計算量を必要とする処理に広く利用 されている. 2・1 システムの概要 AAICでは,ユーザは図 2 にあるように,インタラク ティブノードに SSH ログインしてバッチジョブを投入・ 実行する環境を提供するほか,ポータル経由で仮想マシ ンや,Hadoop,Spark,Cassandra などのビッグデー タ処理用の分散フレームワークを起動し,利用すること ができる.また,大容量ストレージシステムは,これら のジョブや仮想マシン,分散フレームワークから透過的 に,かつ高スループットで読み書きできる. このほか,バッチジョブ環境には,さまざまなユーザ 向けのツール群が導入・提供されている.GPGPU 向け SDKやライブラリ,Caffe, Chainer, CNTK, TensorFlow,
Torchなどのディープラーニングフレームワークのほか,
主に Lawrence Berkeley National Laboratory で開発が 進められている Singularity [Singularity] と呼ばれるコ ンテナ技術が導入されており,Docker イメージをその ままインポートして利用する環境も提供している. こうした環境を実現する AAIC のハードウェアの全体 概要を図 3 に示す. AAICのハードウェアは,AI 計算システム,大容量 ストレージシステム,それらを結合する計算ネットワー ク,サービス・管理系ネットワーク,後者ネットワーク を介して外部接続するためのファイアウォール装置から なる.このうち,AI 計算システムは,50 基の GPGPU サー バ,68 基の non-GPGPU サーバ,その他サーバからなる.
このうち,GPGPU サーバは,Intel Xeon E5-2630Lv4
を 2 基,NVIDIA Tesla P100 SXM2 を 8 基, メ モ リ 256 GiB,SSD 480 GB を搭載する 4U ラックサイズの サーバである. この GPGPU サーバの設計において,我々は,主に単 体サーバでディープラーニングを含む機械学習処理を行 うサービスをクラウド的にユーザに提供することを念頭 に置いた.すなわち,なるべく多くの GPGPU(NVIDIA Tesla P100 SXM2)を高速接続インタフェース NVLink により相互結合し,ノード内の GPGPU を用いて高ス ループット処理を行う設計とした.結果的に,理化学研 究所(理研)革新知能統合研究センターの RAIDEN で も採用された NVIDIA DGX-1 や Facebook Big Basin
[Singularity]など,人工知能研究開発に今日広く使われ
ている GPGPU サーバと同等のハードウェア構成となっ ている.
一方で,GPGPU サーバ間を接続する計算ネットワーク は,Infi niBand EDR(100 Gbps)の一系統とし,CAPEX の多くを GPGPU サーバ,特に GPGPU そのもの,に 割いたシステム構成となっている. 2・2 GPGPU と電力性能 今日,ディープラーニング向けフレームワークの多く が,CPU との比較で 10 ~ 100 倍の処理スループットが 得られることから,AAIC でも採用している NVIDIA 社 の GPGPU に積極的に対応し,デファクトスタンダード となり,産業からアカデミアまで幅広く使われるように なっている. 図 1 AAIC の概観 ユーザ ⼤容量 ストレージ システム バッチ利⽤ インタラクティブ ノード スケジューラジョブ SSHログイン ジョブ投⼊ フレームワーク・VM利⽤ ポータル HTTPSログイン 起動 クラウド管理コントローラ 計算ノード群 ジョブ割当て・実⾏ コンテナ・VM起動 データ アクセス 利⽤状況に合わせて 割当て変更可能 図 2 AAIC の利用イメージ AI計算システム ⼤容量ストレージシステム GPUサーバ ×50 •Intel Xeon E5-2630L v4 ×2 •NVIDIA Tesla P100 SXM2 16GB × 8 •256GiB Memory, 480GB SSD Non-GPUサーバ ×68 •Intel Xeon E5-2630L v4 ×2
•256GiB Memory, 480GB SSD 管理サービスノード×16 インタラクティブ ノード×2 400 Pascal GPU 29.5TiB Memory 56TB SSD DDN SFA14K •ファイルサーバ (w/10GbE×2, IB EDR×4) ×4 •8TB 7.2Krpm NL-SAS HDD×730 •GRIDScaler (GPFS) 実効容量4PiB RW速度100GB/s 計算ネットワーク
Mellanox CS7520 Director Switch •EDR (100Gbps) ×216
⽚⽅向100Gbps フルバイセクションバンド幅
サービスネットワーク・管理ネットワーク
IB EDR (100Gbps / node) IB EDR (100Gbps x16)
GbE or 10GbE GbE or 10GbE
ファイアウォール •FortiGate 3815D ×2 •FortiAnalyzer 1000E ×2 UTMファイアウォール 40-100Gbpsクラスに対応 ⼆重化 10GbE SINET5 10-100GbE 図 3 AAIC のハードウェア概要
プロセッサアーキテクチャの観点では,レイテンシコ ア(シングルスレッド性能志向の演算コア)主体の従来 型 CPU が,微細化やアーキテクチャの改良による大幅 な演算性能向上の限界に達しつつある一方,スループッ トコア(データ並列性・スレッド並列性のあるプログラ ムの高速実行に特化した演算コア)主体のアクセラレー タやマルチコアプロセッサ(以降,スループットプロ セッサという)には性能向上余地が大きいことから,活 発に開発されてきた.特に大規模 HPC システム(スパ コン)では,石油探査やコンピュータ支援エンジニアリ ング,創薬などの応用のために採用が進んできた,とい う状況がある.その結果として,スループットプロセッ サは,スループットコアを微細化の限界まで詰め込むこ とでコア数,すなわち並列度を増大させる一方,CPU の介在なしになるべく多くの計算を単体で行うために独 自の L1 キャッシュや大容量共有メモリを備える,デー タ並列性を効率化するためのプレディケーションによ る分岐除去を行う,スレッド並列性を効率化するための スレッド間同期のサポートを行うなど,プロセッサ技 術の state-of-the-art を具現化する実装フィールドとも なっている.Graphics Processing Unit のプログラマブ ルシェーダを起源にもつ GPGPU は,スループットプ ロセッサ実装のインスタンスの一つで,ほかにも MIC, Cell,Clearspeed など複数の選択肢がある.
一方,ディープラーニング,あるいはディープニュー ラルネットワークの高速計算技術の起源は,Google が 2012年に発表した Google Brain の DistBelief の論文 [Dean 12]にある.Google Brain は 1 000 ノード,2 000
CPUからなる大規模クラスタで 600 kW の電力を必要 としたが,その翌年,NVIDIA と Stanford の共同研究 により GPGPU を用いれば,4 ノード,12 GPU のクラ スタ,4 kW の電力で同様の計算が行えることが示され た [Coates 13].これが可能となったのは,ディープラー ニングの計算手法が Google の論文で明らかになり,そ れが GPGPU を用いた,データ並列による並列実行に非 常に適したものだったからである.このように,もとも とは HPC システム由来であった GPGPU 技術が,ディー プラーニングという応用と結び付き,今日の爆発的普及 に至ったといえる. GPGPUを含むスループットプロセッサのもう一つの
性質は,上述の Google Brain(600 kW)と GPGPU ク ラスタ(4 kW)の例にもあるように,電力性能である. 端的にいえば,スループットコアはレイテンシコアとの 比較で動作クロックが低いため,低電圧・低容量だが低 消費電力のトランジスタを利用でき,性能当たりの消費 電力を大幅に抑えられる.したがって,スループットコ アを集約したスループットプロセッサの消費電力当たり の性能も,レイテンシコアを集約した CPU と比較して 大幅に高くなる. Top 500/Green 500と 呼 ば れ る ベ ン チ マ ー ク ラ ン キングがある.Top 500 は,世界中の計算システムの Linpackベンチマーク(密行列の LU 分解)の実行性 能(TFLOPS/s)を半年ごとに 500 位までランキング するものであるのに対し,Green 500 は,Top 500 に ランクする計算システムの電力性能(実行性能 / 消費 電力,GFLOPS/W)をランキングするものである.電 力の計測方法は,Energy Efficient High Performance Computing WG(EE HPC WG)において標準化され, 業界標準として認められているものである.
NVIDIA社の GPU を採用した AAIC は,2017 年 6 月に公表された Green 500 List [Green 500] において, 東京工業大学 GSIC の TSUBAME 3.0(温水冷却)の 14.110 GFLOPS/W,Yahoo! Japan の kukai(液浸冷却) の 14.046 GFLOPS/W に次いで,12.681 GFLOPS/W で 3番目に電力性能の高い計算システムとなった.図 4 は その実行の際のパワーログをプロットしたものである. 150 kWの定格電力に対して,約 90 kW が上限(平均は 75.78 kW)となるようにチューニングがなされている. この AAIC のスコアは,空冷システムとしては 1 位であ り,同等の条件の他システムに比べて 20 ~ 30%高い電 力性能を達成している.言い換えると,同等の計算を行 うのに,AAIC は他システムに対して 20 ~ 30%低い光 熱水費で済む.これは OPEX を抑える意味で大変重要 である.また,AAIC はいわゆるスパコンではないが, 図 4 AAIC のパワーログデータ
11 人工知能・ビッグデータ処理向けクラウド基盤の構築─産総研 AI クラウドと AI 橋渡しクラウド─
Top 500で 148 位にランクしている.
3.AI 橋渡しクラウド(ABCI)の構想
「AI 橋渡しクラウド(AI Bridging Cloud Infrastructure)」 (以降,ABCI という)は,平成 28 年度二次補正「人工 知能に関するグローバル研究拠点整備事業」の一環とし て,産業技術総合研究所が東京大学柏Ⅱキャンパスに導 入を計画している人工知能処理向けの大規模計算システ ムである. ABCIは,アルゴリズム(Algorithm),ビッグデータ
(Big Data),計算能力(Computing Power)の協調に よる,高度な人工知能処理を可能にする大規模かつ省電 力なクラウド基盤である.本システムは,世界最高水準 の機械学習処理能力,高性能計算能力,および省電力性 を備え,画像,音声,テキストなどの超大規模なデータ セットを対象とした,ディープラーニングを含む高度な 機械学習処理およびシミュレーションなどを,超省電力 で超高速に処理する必要がある.そればかりではなく, ABCIは,我が国の人工知能技術開発のためのオープン なリーディングインフラストラクチャとして,画像認識, 音声認識,自然言語処理など,種々の機械学習アルゴリ ズムやデータモデルの高度化,自動車・ロボットの自動 運転・制御,創薬向け化合物推定,音声対話,自動翻訳 など,幅広い分野での新たなアプリケーションの創出や, これらを支えるクラウド基盤の設計・運用ノウハウの民 間への技術移転など,人工知能技術の社会実装を強力に 支援することが期待される.ゆえに,産業技術総合研究 所はこれらの理念をいかに実現するか,人工知能処理の リーディングインフラストラクチャの「ロールモデル」 はいかにあるべきかを念頭において設計を進めてきた. ABCIには既存のスパコン調達にはないユニークな点 が数多くあるが,代表的なものを以下にあげる. ● 補正予算成立から約 1 年半という超短期プロジェ クトであること.東京大学柏Ⅱキャンパス内にスク ラッチから,図 5 にあるように,サーバ棟,設備機 器置場,外構の設計・施工,給電設備,冷却設備, サーバラックなどを含む付帯設備の整備,サーバシ ステムの調達・製造・納品までを完了する必要があ る.特にサーバシステムの調達では,産業技術総合 研究所 AI クラウド(AAIC)および今年 8 月導入予 定の東京工業大学 TSUBAME 3.0 の成果を取り込 むことで基本設計フェーズの加速を図るとともに, 最先端のコモディティハードウェアを効果的に取り 込み,インテグレートする技量が問われる. ● HPC向けではなく,人工知能処理のための,「初め てのスパコン」であること.すなわち,人工知能処 理においてシステムの絶対性能およびキャパシティ を定めるメトリックや,システムの評価基準となる ベンチマークセットを我々自身が新たに定義し,世 に問うていく必要がある. ● ディープラーニングを含む高度な機械学習処理に代 表される人工知能分野でのワークロードにおいて, 高性能かつ費用対効果の高いシステム設計が未知で あること.ベンチマークセットの定義と並行して, state-of-the-artなシステムである産業技術総合研究 所 AAIC などを用いて基礎的なデータの取得を迅速 に行い,その知見からシステム設計および改善を行 う必要がある. 以下では,ABCI のサーバシステムにフォーカスしつ つ,ABCI の概要について紹介する. 3・1 ABCI の 概 要 ABCIの導入の目的を達成するため,ABCI では実現 されるべき機能・性能について,概念要件,技術要件を 以下のとおり定めている. § 1 概念要件 AI Infrastructure:人工知能技術を支え る機械学習の超高速処理 ● ディープラーニングを含む超高速な機械学習処理を 実現する 100 ペタ AI-FLOPS(3・2 節にて後述)超 級の演算性能 ● ディープラーニングの予測結果に基づく高度なシ ミュレーション解析や,高精度演算を必要とする機 械学習アルゴリズムなど,ビッグデータ処理と高性 能計算の融合を可能にするマルチ PFLOPS 級の倍 精度浮動小数点演算性能 ● 上記を支えるペタバイト毎秒級の超高速な I/O,ペタ ビット毎秒級の超広帯域・超低遅延なネットワーク § 2 概念要件 Bridging Infrastructure:民間への技術 移転のためのオープンプラットフォーム ● 機械学習の対象となるマルチペタバイト級のビッグ データを収集・蓄積・共用可能なストレージ ● 汎用製品により構成されたコストパフォーマンスが 良く模倣しやすいアーキテクチャ ● 広範囲のオープンソースソフトウェア,商用アプリ ケーションが動作可能なソフトウェアエコシステム のサポート 図 5 ABCI サーバ棟の概観図
§ 3 概念要件 Cloud Infrastructure:TCO に優れた最 新鋭のクラウド基盤・運用 ● 資源のパーティショニングやプロビジョニング,動 的な計算環境のデプロイメントなどによるマルチテ ナントのサポート ● 自動的な障害回復など,少人数で運用可能なクラウ ド運用管理 ● 温液冷却や高効率給電系を含む次世代省電力設計 § 4 技術要件の概要 ABCIのシステムは,高性能計算システム,大容量ス トレージシステム,各種ネットワークなどから構成され るハードウェア(図 1)と,システムを最大限活用する ためのソフトウェア群からなる. 以下にシステムの機能および性能に関する技術要件の 概要を示す. ● 高性能計算システムの合算理論ピーク演算性能は 130ペタ AI-FLOPS 以上であること.また,倍精度, 単精度浮動小数点演算での合算理論ピーク性能はそ れぞれ 8 PFLOPS 以上,55 PFLOPS 以上であるこ と. ● 高性能計算システムのメモリの合算容量は 435 TiB 以上,かつ合算理論ピークバンド幅は 3.8 PB/s 以上 であること. ● 大容量ストレージシステムは,全体で 22 PB 以上の 実効容量を備え,高速かつ高信頼な並列ファイルシ ステムを提供すること.高性能計算システムのすべ ての計算ノードから利用できること. ● 計算ネットワークは,高性能計算システムおよび大 容量ストレージシステムを相互に接続すること.理 論転送バンド幅 100 Gbps 以上のネットワークを用 いて,なるべく高いバイセクションバンド幅を有す る構成をとること.なお,計算ノード間,および計 算ノード・大容量ストレージシステム間の理論転送 バンド幅は 100 Gbps 以上とすること. ● サービスネットワークは,高性能計算システムおよ び大容量ストレージシステムの外部アクセスを必要 とする機器群を接続するとともに,計算ネットワー ク,管理ネットワーク,および SINET5 に接続す ること. ● 産業技術総合研究所が準備する給電設備および冷却 設備を最大限活用した効率の良いシステムを構築 すること.ただし,システムの有効総消費電力は 3 000 kW以下とすること. ● システムを最大限活用し,クラウド運用,人工知能 処理の高速化・高度化,ビッグデータの活用を実現 するソフトウェア群を有すること. 3・2 AI-FLOPS
Caffe [Dean 12],CNTK,TensorFlow,Chainer を はじめとする多くのディープラーニング向けフレーム ワークでは,一般的に学習フェーズに単精度浮動小数点 数(FP32)を用い,その演算カーネルは HPC 分野でも 一般的に用いられる SGEMM に相当する. 一方,チップメーカはディープラーニングの高速化に 資するべく,また自社製品のマーケットバリューを高め るべく,しのぎを削っている.NVIDIA 社は Pascal 世 代で FP16 精度の演算コアを,Volta 世代で FP16/FP32 混合精度の演算コア(Tensor Core)を追加することで, より低精度の演算スループットを訴求してきた.Intel 社は Knights Mill(KNM)で,4 個の単精度 FMA 演算 を 1 命令にパッキングする QFMA の導入により従来精 度の演算の高速化を図る一方,INT16/INT32 の混合精 度の積和演算 VNNI,4 個の VNNI 演算を 1 命令にパッ キングする QVNNI などを追加することで低精度の演算 スループットの改善も図ってきている.また,Google も TPU1 は FP16 演算にフォーカスしており,Google I/ O 2017で発表された TPU2 については詳細が明らかに なっていないものの,おそらくは FP16 演算と推測され る [Jouppi 17]. このような状況下で,ABCI のような人工知能向けの 大規模システムで絶対性能を定めるには,メトリックを どう定めるのが適切か.FP32 に固定すると,チップメー カの state-of-the-art なエフォートを考慮しないことに なり,旧製品でよいという意味になる.ましてや FP16 ルータ装置 ファイアウォール装置 拠点間接続ネットワーク 伝送装置 ストレージアレイ装置 サービスネットワーク 管理ネットワーク 計算ネットワーク ⾼性能計算システム GW 100GbE 100GbE 400Gbps 以上 400Gbps以上 10GbE以上 ノードあたり 200Gbps以上 ノードあたり200Gbps以上 ⼤容量ストレージシステム 全体で⽚⽅向 140GB/s以上 GbEまたは 10GbE SINET5 ファイルサーバ群 メタサーバ群 プロトコルサーバ群 計算ノード群 インタラクティブ ノード群 管理サービス ノード群 マルチプラット フォームノード群 ノードあたり100Gbps以上 かつ(100Gbps×スループット プロセッサ数÷3)以上 130 Peta AI-FLOPS以上 倍精度演算性能:8 PFLOPS以上 単精度演算性能:55 PFLOPS以上 22PB以上の実効容量 図 6 ABCI のシステム概要
13 人工知能・ビッグデータ処理向けクラウド基盤の構築─産総研 AI クラウドと AI 橋渡しクラウド─ にすると,特定メーカを利することになり,産業技術総 合研究所のような公的機関に求められるべき公平性に欠 き,また,演算精度や収束性能は二の次であるというメッ セージになる. 我々は,ベンチマークを規定し,それに基づいて理論 AI-FLOPS値,実効 AI-FLOPS 値,実行効率,検証指標, 評価値という複数のメトリックでシステムを評価するこ とで,この課題を解決する方法を提案している. § 1 理論 AI-FLOPS 値 「参照精度」を FP32(または FP64)とする.「設定精度」 は AI-FLOPS 値の算出根拠となる精度とし,参照精度 と同一精度,参照精度を縮退または拡張した精度,混合 精度のいずれであってもよい,すなわち state-of-the-art なプロセッサないしスループットプロセッサの計算精度 に適合するように選んでよい.ただし,後述のベンチマー クの検証指標が pass/fail criteria をパスするように選ば なくてはならないとする. このとき,理論 AI-FLOPS 値は,各プロセッサが設 定精度で理論的に 1 秒間に実行できる演算の回数を指 すものと定義する.端的に言えば,理論 AI-FLOPS は, ベンダの自己申告による理論的なピーク演算性能であ る.したがって,例えば NVIDIA の Tensor Core,ある いは Intel の QVNNI 命令のそれぞれ理論ピーク性能と してよい. § 2 ベンチマークによる実測 AI-FLOPS 値 入 力 行 列 A(M×K 行 列 ),B(K×N 行列 ), 出力 行 列 C(M×N 行列)に対する GEMM 計算を行い,性能 を測定することを考える.簡単のため,α=1,β=0, M=N=K とする. C=αAB+βC 行列のサイズは,参照精度での計算に必要なメモリサ イズがプロセッサのオンチップメモリの 2 倍弱以上とな るように選ぶ.具体的にはオンチップメモリ量 Mem バ イト,参照精度の表現バイト数 b とするとき,行列のサ イズは以下の条件を満たす値を選ぶとする. M=N= K ≧ sqrt Mem×κ × b 1 3 , whereκ=1.75 このときベンチマークは以下の手順の計算を行う.ま ず,参照精度に従う入力行列 Aref,Brefを生成し,これ らを用いて GEMM を計算し,参照精度の出力行列 Cref を得る.次に設定精度に従う入力行列 A,B を生成し, これらを用いて GEMM を計算し,出力行列 C を得る. この計算に要した時間を t 秒とすると,実効 AI-FLOPS 値は以下のように算出できる. Effective AI-FLOPS=MN(2K-1)⁄ t ま た, 実 行 効 率 efficiency は 設 定 精 度 で の 理 論
AI-FLOPS値を Peak AI-FLOPS とすると,以下で求め られる.
efficiency= Effective AI-FLOPSPeak AI-FLOPS
参照精度と設定精度の計算結果を比較し,L2 ノルム を検証指標(validation metric)とする. validation metric= i<M, j<N i=0, j=0 Ci, j−Ci, jref 2 i<M, j<N i=0, j=0 Ci, jref 2 このとき,設定精度は下記の pass/fail criteria を満た さなければならないとする.理論 AI-FLOPS 値の算出 において,あらかじめこの条件を満たせない精度を設定 精度に選んではならないということである.
validation metric≦ [pass ⁄ fail criteria] = 0.1 実効 AI-FLOPS 値と検証指標から下記の評価値を得 る.
score=(Effective AI-FLOPS)×e(- 1 × validation metric×κ),
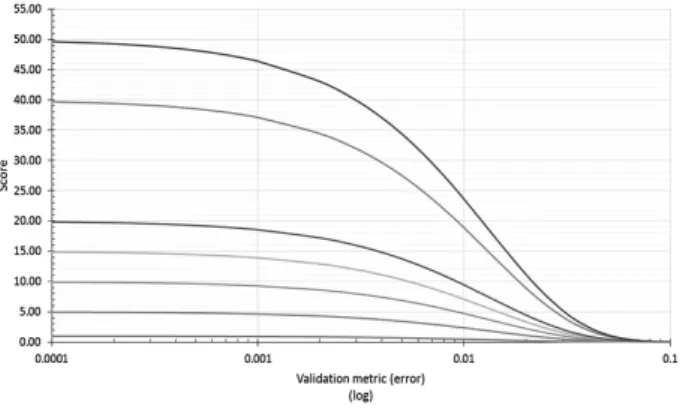
where κ= 75 この評価式の詳細な導出過程,根拠は本稿では省略す るが,意図するところは,プロセッサの処理性能を CNN の処理スループットとその計算の質である精度の積とし て,モデル化することである(図 2).この評価式では validation metricが大きく(悪く)なるにつれ,最初 はなだらかに途中から急激に悪化する.ResNet[He 15] を用いて行った予備的実験では validation metric が一定 以上悪化すると精度も急激に悪化するという傾向があり (validation metric が 0.001 では精度にほとんど影響が ないが 0.01 では 1%程度悪化する),1%の精度向上に約 2倍の計算量が必要であることからκを導出している.
4.お わ り に
本解説では,産業技術総合研究所が平成 29 年 6 月か ら利用サービスを開始した「産業技術総合研究所 AI クラウド(AAIC)」と,平成 30 年度前半のサービス開始 に向けて開発を進めている「AI 橋渡しクラウド(ABCI)」 を紹介した. ABCIに関しては,平成 29 年 9 月末に契約事業者が 確定しているが,来年度春のサービス開始時点をもって, 詳細が公開される予定となっている.
◇ 参 考 文 献 ◇
[AAIC Computer Resource] AAIC Computer Resource, http:// www.airc.aist.go.jp/computer-resources/
[Coates 13] Coates, A., et al.: Deep learning with COTS HPC systems, Proc. 30th Int. Conf. on Machine Learning, PMLR, Vol. 28, No. 3, pp. 1337-1345(2013)
[Dean 12] Dean, J., et al.: Large scale distributed deep networks, NIPS 2012(2012)
[Green 500] Green 500 List for June 2017, https://www. top500.org/green500/lists/2017/06/
[He 15] He, K., Zhang, X., Ren, S. and Sun, J.: Deep residual learning for image recognition, CoRR(2015)
[Introducing Big Basin] Introducing Big Basin: Our next-generation AI hardware, https://code.facebook.com/ posts/1835166200089399/introducing-big-basin-our-next-generation-ai-hardware/
[Jouppi 17] Jouppi, N. P., et al.: In-datacenter performance analysis of a tensor processing unit, 44th Int. Symp. on Computer Architecture(ISCA)(2017)
[Singularity] Singularity, http://singularity.lbl.gov
2017年 11 月 6 日 受理