1.は じ め に
2012年の ILSVRC(ImageNet Large Scale Visual Recognition Competition)において Hinton らのチーム が優勝をさらって以降,深層学習(Deep Learning)は 画像認識,音声認識,テキスト処理など多くの応用分野 における強力なモデリングツールとして,広く使用され るようになった [Krizhevsky 12].深層学習は特徴抽出 と識別や回帰などのタスクに対する予測モデルとを一気 通貫的に学習することができるため,過度な特徴量エン ジニアリングをしなくともある程度高精度な特徴マップ を得ることが可能である.そうした延長で,何らかの意 味で良い特徴マップを学習により獲得することを目的と した学習,換言すれば,データを何らかのよい空間へう まく埋め込む方法*1をデータから学習することが,機械 学習の基本的な問題設定としてさらに注目されるように なった.従来法ではこれらの埋込みはデータを実ユーク リッド空間内のベクタとして表現することで実現される ことが通常であったが,最近,複素空間や双曲空間のよ うな実ユークリッド空間以外の空間へ埋め込むことで, より効率的な表現が得られるという研究がいくつか報告 されてきている.本稿ではそういった手法を概観する.
2.Word Embedding
テキストデータにおける単語の埋込みを実現する最 も代表的な手法は Tomas Mikolov らにより Skipgram モ デ ル,CBoW(Continuous Bag-of-Words) モ デ ル[Mikolov 13a, Mikolov 13b]であろう*2.これら両モデ
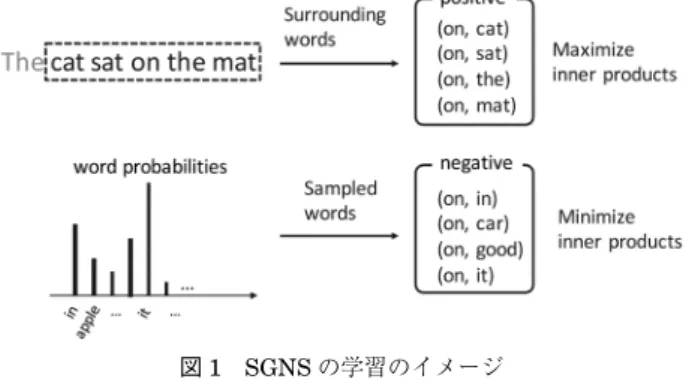
ルは,テキストデータ中の単語埋込みを得るための非常 にシンプルで強力なベースライン手法として,広く使用 されている.Skip-gram,CBoW はテキストにおける単 語の隣接情報をもとに単語の埋込み(表現ベクタ)を特 徴付けるモデルであり,所定サイズの sliding window を文に対して動かしていくときに得られるその中心語 (sat)と周辺語(The,cat,on,the)との共起関係を それらの語の埋込みの相関(内積)の大小として学習す る(図 1). 以下,今日最も標準的に使われていると思われる, Negative Samplingによる Skip Gram(Skip Gram with Negative Sampling:SGNS)の学習方法を説明する. 図 1 の左上の図ではサイズ 5 の sliding window がテキ スト中の‘cat sat on the mat’という部分を囲んでいる が,SGNS は,この window の中心の語(on)とそれ以 外の囲われた語(cat,sat,the,mat)の対(図 1 の右上) とテキスト中の語彙集合から語の頻度分布に従って乱択 された対(図 1 下段)との比較により学習される.具体 的には,下記の目的関数が最適化される.
実ユークリッド空間を超えた埋込み手法の
新展開
Recent Advances in Super-Real-Euclidean Embedding Techniques
白川 達也
ABEJA, Inc.Tatsuya Shirakawa ABEJA, Inc.
Keywords:
word embedding, graph embeddings, knowledge graph embedding, Poincaré embedding. 「深層学習周辺の最新動向」 *1 本稿では曖昧性のない限り空間に埋め込まれたデータのこと も埋込みということにする. *2 こ れ ら の モ デ ル が 実 装 さ れ た ツ ー ル で あ る word2vec や gensimは広く使用されている. 図 1 SGNS の学習のイメージmaximize E(i, j)~ P[log σ(score(i, j))]
+kE(i, j )~ Q[log(1-σ(score(i , j ))],
score(i, j):= ui, vi :=uTivj . (1)
ここで,(i, j)~ P は前述の sliding window を文章全体 に対して動かしていったときの中心語 i とサンプリング された周辺語 j のペア(positive sample)の出現分布 である.また,(i, j)~ Q=P uni×Puniは語彙の頻度分 布 Puniから独立に i, jをサンプリングすることによっ て得られたペア(negative sample)である.ui, uj, ui, uj∈ Rdはそれぞれ語彙 i, j, i, jの d 次元の埋込みであ り,σ(x)=1/(1+exp(-x))はシグモイド関数である. positive sampleと negative sample のバランスをとる
ために定数 k ∈ R≥0が導入されているが,モデルにとっ てあまり本質的ではないので,以降 k=1 とする*3. SGNSの最適化は,sliding window 中に共起する中心 語と周辺語のペアについてはそれらの埋込みの内積値を 相対的に大きくし,unigram 分布に従って乱択された語 のペアについては相対的に内積値を小さくするという学 習を行っていることになる. なお,最適化問題(1)の最適解は埋込みの次元が十 分大きければ uT i vj≈ log P(i, j) P(i)P(j) (2) となることが知られており,右辺の量はpoint-wise mutual information(PMI)と呼ばれる.上式より,SGNS は PMIを要素値としてもつ行列(PMI 行列)の行列分解 を近似的に学習していることがわかる.一般的には語の 出現頻度は文頭・文中・文末で異なると考えられるため P(i, j)≠P( j, i)であり,中心語としての埋込みと周辺語と しての埋込みは区別して扱うべきであるが,これらを一 致させて取り扱ってしまっても実用上は良く動作する*4.
ま た SGNS で 学 習 さ れ た 埋 込 み は,uking-uman
uqueen- uwomanの よ う な 意 味 的 な 並 行 関 係(linear
regularity),uran- urun -uwalked-uwalkのような文法的
な並行関係を満たすことが知られている(図 2).
3.Graph Embedding
SGNSは sliding window 中の周辺語一語と中心語と の共起をモデリングしていたが,その最適化問題(1) はテキストに限らず,より一般的な状況に適用可能で ある.最も直接的な適用例として,LINE(Large-scaleInformation Network Embedding [Tang 15])を紹介す る.LINE はグラフ中のノードの埋込みを求める手法で あり,SGNS の最適化問題をノードの隣接関係に翻訳 したものとみなせる.具体的には表 1 に示したように, SGNSでの単語の代わりにグラフ中のノードをとり,周 辺語と中心語の共起関係をノードの隣接関係(エッジで の連結関係)とみなして,SGNS と最適化(1)と全く 同様の最適化を行う.ただし,SGNS のときとは異なり, (i, j)~ P はグラフのエッジを一様サンプリングすること で得られ,i, j~Q はノードの次数に比例した確率でノー ド i, jを独立にサンプリングして得られる.
4.Knowledge Graph Embedding
例えば「Star Wars のジャンルは SF である」という 事実は,「Star Wars」という主体(subject)が「SF」 という客体(object)と「◯◯のジャンルは△△」とい う関係性で結ばれているものと考えることができる.こ のように,subject s と object o(subject と object を合わ
図 2 埋込みの線形性. [Mikolov 13b]より抜粋 図 3 Knowledge Graph. [Nickel 16a]より抜粋 表 1 SGNS と LINE の対応関係 *3 k > 1 ととることは同時経験分布 P(i, j)に対する相対的な割 引効果を与えるものと思われる. *4 区別しないことによりパラメータ数が削減される効果がある. 多くのツールでは区別しない実装になっている.
せて entity と呼ぶ)が relation r で結ばれていることを 表す三つ組(s, r, o)として知識を表現するとき,それら の集合(s, r, o)を知識ベース(Knowledge Base)と呼ぶ. Knowledge Baseは,subject s と object o をノードとし て,それらが relation r でラベル付けられたエッジで結 ばれたグラフとして表現することもでき,そのようなグ ラフを知識グラフ(Knowledge Graph)と呼ぶ(図 3 に Knowledge Graph の例を,表 2 に代表的なデータセッ トを示した).一般的には知識がすべて完全な形で列挙 されているわけではないので,s, r, o のいずれか一つが 欠損した場合に Knowledge Graph の構造からそれを推 定・補完することで知識の拡充を行うことが重要なタス クとなる.近年,Knowledge Graph を構成する entity,
relationの埋込みを考えることによりこれらの推論タ
スクを実行する研究(Knowledge Graph Embedding) が盛んに行われており,これまでさまざまなモデルが提 案されてきた.ここではそれらの成果の中から,本論に 関係しそうなものをかいつまんで紹介したい.
4・1 TransE
Knowledge Graphの代表的な埋込み手法として TransE [Bordes 13]がある.先述のとおり,SGNS で学習され た埋込みは意味・文法内容の並行関係をもつので,例 えば king-man+woman= ? という,女性の場合の
kingに相当する語を求めたければ,埋込みの間で計算
uking- uman+uwomanを行い,これに最も近い埋込みをも
つ単語を探索することによって推論することができた. TransEは Knowledge Graph において,このような推 論を直接的に学習するモデルである.具体的には,訓練 用の Knowledge Base D={(s, r, o)} に対して,ue, vr ∈
Rdを entity e ∈ E:= S ∪ O,relation r ∈ R の埋込み
として,下記のマージンロス最小化を行う. minimize {u}, {v} (s, r, o)∈ D (s , r, o )∈D (s, r, o) (s , r, o ) loss(s, r, o, s′, o′), loss(s, r, o, s′, o′):= [γ+score(us, vr, uo)+score(us, vr, uo)]+, D ={(s, r, o)| ′s∈ S}∪{(s, r, o )|o ∈ O} (3) ここで,γ≥ 0は所与のマージンである.score(s, r, o)は 三つ組(s, r, o)の結び付きの良さを表す関数で, score(s, r, o)=‖us+vr-uo‖1 または
‖us+vr-wo‖2 (4) などとして定義される.また [x]+=max(x, 0)である. D (s, r, o)は与えられた(s, r, o)に対して,s または o を入 れ替えて得られる三つ組全体を表す集合である.TransE は デ ー タ と し て 与 え ら れ た 三 つ 組(s, r, o) が us+ vr uoを満たすように埋め込み,us, vr, uoを学習する モデルとなる. 4・2 CP 分解モデル,DistMult TransEは(s, r, o)の間の関係性を us+vr uoとい う具合にモデル化したものであったが,SGNS をその まま三つ組データへ拡張するという方向性もあり得る. SGNSの場合,中心語と周辺語の共起をモデル化してい
たが,Knowledge Graph の場合には,(s, r, o)の三つ組 を取り扱う必要がある.SGNS の目的関数を三つ組へそ のまま延長すると下記のようになる.
maximize Eu, v, w (s, r, o)~ P[ log σ(score(us, vr, wo))]
+ E(s , r , o )~ Q[ log (1 (- score(uσ s,vr,wo))], Q(s , r , o )=P(s )Ps (r )Pr o(o ) (5) ここで(s, r, o)~ P は三つ組(s, r, o)の同時分布であり, s~ Ps,r ~ Pr, o~ Poはそれぞれ s, r, o の頻度分布であ る.また,us, vr, wo∈ Rdは s, r, o の埋込みであり, score(u, v, w):= u, v, w := i uv wi= i uiviwi (6) は 3 階テンソルに対する高階内積である.SGNS の場合 と全く同様にして,score(us, vr, wo)の表現力が十分高 ければ, us, vr, wo log P(s, r, o) P(s)Ps (r)Pr (o)o (7) が成り立つことがわかるが,これは右辺の 3 階テンソル log P(s, r, o) P(s)Ps (r)Pr (o)o s, r, o に対する CP 分解 [Harshman 70] とみなせるので,CP 分解モデルと呼ぶことにする.CP 分解の性質より,構 成するベクトル us, vr, woの次元 d を十分大きくとるこ とで任意精度で定式を近似させることができるはずであ るが,実は [Trouillon 17] で実験的に示されているよう に,CP 分解モデルは限られたサイズのデータセットで は十分な精度が出ない.CP 分解の場合,s, r, o に対して それぞれ独立の埋込みを用意することになるので,表 2 表 2 代表的な Knowledge Graph データセット
のようなデータセットの場合,データ数に対して相対的 にパラメータ数が過多となることが原因と考えられる (実際,TransE でも Subject と Object で埋込みを共有 することでパラメータの削減を行っている).なお,CP 分解において entity E=S ∪O に対しては共通の埋込み
ue=ve,e∈S∩O を用いることも考えられるが,それ に近いモデルとして DistMult モデル [Yang 14] がある. DistMultは CP 分解のようにロジスティックロスの最 小化を行うのではなく,TransE の目的関数(3)にお いて,スコア関数 s(us, vr, uo)を高階内積(6)でとっ たものであり,CP 分解と異なり,DistMult は比較的 良好な収束性を示すことが知られている(ただし,埋 込みにおいて Subject と Object の区別をしないので, (s, r, o)と(o, r, s)の区別ができないという欠点がある). 4・3 HolE,ComplEx
HolE [Nickel 16b]および ComplEx [Trouillon 17] は entity,relation を複素空間へ埋め込むことで表現能力 の向上を測ったモデルであり,それぞれ独立に提案され たが,スケール倍を除いて互いに等価であることが示さ れている [Hayashi 17].ここでは,よりわかりやすいと 思われる ComplEx の解説を行う.ComplEx は三つ組 (s, r, o)をなす Entiry s, o および Relation r それぞれを
複素空間への埋込み us, vr, uo∈Cdを考え,スコア関数 を s (us, vr, uo)=Re( us, vr, u¯o ) = Re( i usivri¯uoi) (8) により定義する.ここで,Re()は複素数の実部を とる関数である.ComplEx はこのスコア関数を用い て,TransE の目的関数(3)の最適化を行う.なお, ComplExのスコア関数(8)は要素ごとに見ると(スケー ル倍を無視すれば)s と o のなす角度が r の偏角に一致 するときに最大化されるため,ComplEx は Relation を 複素空間内の回転として表現していると思うことができ る.また,ComplEx は Object 側の複素埋込みについて は共役をとっているため,DistMult とは異なり,s と o とで埋込みの共有をしつつも(s, r, o)と(o, r, s)の区 別ができている.
5.Poincaré Embedding
ここまでに紹介したモデルは実ユークリッド空間もし くは複素空間における埋込みであったが,こうした空間 はいずれも数学的にはフラットな空間である.一方,数 学的にはひずみをもった空間を考えることができ,その ひずみがデータの特性を表現しているようなものであれ ば,その空間で埋込みを構成することで,より効率的に データを表現することができるかもしれない.Poincaré 埋込み [Nickel 17] は双曲空間という,階層構造を自然 に表現することができるひずみを備えた空間へデータを 埋め込む手法である.以下,双曲空間についての必要な 基本事項および,双曲空間での Poincaré 埋込みの構成 方法について解説する*5. 5・1 計 量 実ユークリッド空間や複素空間の任意の二点に対し て,それらの間の距離はそれらを結ぶ線分の長さとして 自然に定義されるが,球面などのフラットでない空間に おいても二点間の距離を一般的に定義するためには計量 という数学的な道具立てを必要とする.計量とは空間の 各点において定義される局所的なモノサシである.実 ユークリッド空間 X においては二点 x, y ∈ X を結ぶ曲 線 s:[0, 1]→X, (0)= ,s x s(1)= y の長さは 1 0 ‖ 1 0 s˙(t)‖dt = ‖ s˙(t), s˙(t) ‖dt, s˙(t) = ds(t) dt で定義された.計量とは,空間 X の各点 x ∈ X ごとに 定義された連続かつ半正定値,対称な双線形関数 g(u, v) x である.より具体的には,X 上で連続な行列関数 A(x) ∈ Rd2 に対して,各点 x ∈ X における内積を g(u, v)=x A(x)u, A(x)v と定義することで,計量 g(u, v)を定x 義することができる.この構成の場合,A(x)が空間の ひずみを表現していることが明確になる.実ユークリッ ド空間の場合は恒等的に A(x)=Identity となるので, その意味で実ユークリッド空間はフラットな空間という ことができる.一般に計量が導入された空間 X 内の二点 x, y∈ X を結ぶ曲線 s:[0, 1] X, s(0)=x, s(1)=y の長 さは 1 0 ds(t) dt ds(t) dt gx , dt (9) で定義される*6.したがって各点の計量の大小に応じて, 距離が見た目よりも伸び縮みすることになる.計量が導 入された空間における二点 x, y ∈ X の距離は二点 x, y を結ぶ最短の曲線(測地線という)の長さとして定義す る.一般に測地線は直線にはならず,例えば球面であれ ば二点を結ぶ測地線は,その二点を通る大円の短いほう の円弧となる.一般には,計量が明示的にわかっていて も測地線や測地線の長さはいつも陽な形で求まるわけで はない. *5 多様体や計量などのより厳密な構成方法については,[松本 88]などを参照のこと. *6 一般の空間において ds(t)/dt をどう定義するかは本当は自明 でなく,正式には接空間という概念を導入する必要がある.5・2 双 曲 空 間
双曲空間は計量が導入されたゆがんだ空間の一種 であるが,いくつか同値な構成方法がある.ここでは [Nickel 17]に従って Poincaré Ball を用いた構成方法を 述べる.この場合 d 次元双曲空間 X は原点 o 中心の d 次元単位球の内部に下記の計量を付与した空間として定 義される. gx 2 1-‖x‖2 2 gE = (10) ただし,g(u, v)=u, v はユークリッド空間として見E たときの計量(通常の内積)である. したがって,双曲空間においては,単位球の外側に近 づくほど計量の値がどんどん大きくなるため,空間とし ては外側ほど密度が高くなる(図 4).双曲空間におい ては実は測地線の長さは陽に計算されることが知られて おり,二点 x, y を結ぶ測地線は x, y を通り単位球の境界 (単位球面)と垂直に交わる円弧であり,その長さは d(x, y) = arccosh 1+2 ‖x-y‖2 (1-‖x‖2)(1-‖y‖2)) (11) となる.ここで arccosh(γ)は逆双曲余弦関数であり, arccosh(γ)= log(γ+ γ-1 γ+1 ) (12) と定義される.さらに,双曲空間は木構造を等長に埋め 込める空間としても知られている.ただし,木のノード 間距離はそれらを結ぶ最小辺数の経路の辺数(家系図で いうところの 1 親等,2 親等,…の 1, 2)で定義する. したがって,双曲空間は測地線の長さが陽に計算される だけではなく,木構造をも自然に表現できるという非常 に有用な性質がある.したがって,木構造のような階層 構造を内在するようなデータの場合,双曲空間に埋込み を構成することで,より自然で無理のない埋込みが実現 されると想像される. 5・3 Poincaré 埋込みの構成方法 Poincaré 埋込みは実ユークリッド空間ではなく双曲空 間(Poincaré Ball)へデータを埋め込む手法である.し たがって,Poincaré 埋込みの場合,データは単位球内に 表現されるが,二点間の距離は式(11)によって計算さ れる.各データを単位球内のどこへ配置するかはタスク に応じたロス関数の設計によって決まる.[Nickel 17] で は WordNet に含まれる名詞からの上位・下位概念の推 定タスクや,科学者の共著関係に基づくソーシャルネッ トワークの解析などのタスクに対して Poincaré 埋込み の有効性の検証がなされているが,ここでは説明のため 前者のタスクに則して,Poincaré 埋込みの構成・学習方 法を説明する*7. WordNetは英語の概念辞書である.本タスクでは WordNetから名詞のみを抽出し,各名詞について上位 概念に相当する名詞を遡れるだけ遡っていき,その途上 で現れた上位概念名詞ともとの名詞の対をつくることで 下位・上位概念関係にある名詞対を列挙し,データセッ トとする(表 3).このデータセットを D とするとき, 下記の目的関数を最大化することで,各名詞 n ∈ Noun の d 次元 Poincaré Ball Bd:= x ∈ Rd|∥x∥≤ 1 への埋込 み un∈ Bdを構成する.
minimize Lu (u)= (m, n)l (u),
(m, n)∈ D l (m, n)(u):=−log e−d(um, un) e−d(um, un) n∈ N(m)∪ {n} ∑ (13)
ここで,d(u, v)≥ 0 は式(11)で定義される Poincaré Ball における距離である.(m)⊂ {n(m, n| )∉D} は名詞 m
に対する負例集合であり,[Nickel 17] では (m)∪{n} のサイズは 10 程度にとっている.この学習により,デー タセット D に現れる名詞対(m, n)∈D 同士は相対的に
図 4 M. C. Escher, Circle Limit Ⅲ(1959)
表 3 WordNet から抽出されたデータセット
*7 最近,gensim に Poincaré 埋込みが実装された.https:// radimrehurek.com/gensim/models/poincare.html また,著者の実装も下記にある.https://github.com/
距離が小さくなり,そうでない名詞対(m, n)∉ D 同士 は相対的に距離が大きくなるように各名詞の埋込みが学 習される. 最適化(13)は確率勾配降下法(Stochastic Gradient Descent:SGD)によって行うが,Poincaré Ball には 非ユークリッド的な計量(10)が入っているため,下 記のような補正を施した勾配降下を行う(Riemannian SGD). ui proj(ui-ηg-1ui∇unl(m, n)(u)) (14) ここで, η> 0 は学習率であり,proj()は埋込み uiの
勾配降下後の値 ui-ηg-1ui ∇un(m, n)l (u)を Poincaré Ball
へ引き戻す写像で, proj(x):= x (‖ x ‖≤ 1) x /(‖x‖+ε)(otherwise) (15) などとして定義される.ただし,ε> 0 は十分微小な実 数である. 元論文では Riemannian SGD の学習により得られた 名詞の埋込みを用いて,上位概念の補完などのタスクの 評価を行っている.上位概念の補完タスクは,データ セット中の名詞対(m, n)∈ D の Poincaré Ball 内での 埋込みの間の距離 d(um, un)の { d(um, un(m, n| )∉ D } における相対順位(もちろん小さいほど良い)を計測 することで評価される.評価指標としては,Rank(平 均順位)および MAP(Mean Average Precision)を用 いている.論文で報告されている結果を表 4 に記載し ている.表 4 において,Euclidean は距離を dEuc(u, v)
=∥u-v∥2でとって式(13)を学習したものであり,
Translationalは TransE と同様,関係性を表すベクタ r を追加し距離を dTrans(u, v)=∥u-v+r∥2でとって式
(13)を学習したものである(ただし,r も学習する). Poincaré埋込みがこれらの手法に対して大きなアドバン テージをもつことが確認できる. また,先に Poincaré Ball には木構造が等長に埋め 込まれることに触れたが,実際に学習された二次元の Poincaré埋込み結果を可視化すると概念のもつ階層構造 が原点を中心に放射状に展開されたような様子が確認で きる(図 5)*8.
6.ま と め と 展 望
本稿では,実ユークリッド空間への埋込みが,複素・ 双曲空間(Poincaré Ball)への埋込みに発展するまでの 流れを概観した.今後も Poincaré 埋込みのような,デー タのもつ内在的な構造(Poincaré 埋込みの場合は木構造) を自然に表現できる空間への埋込みへの関心は高まって いくものと思われるが,そのような空間は Poincaré 埋 込みが対象とした双曲空間のように「計算可能」である 必要がある.以下,著者の考える今後の研究の方向性を 述べ,まとめとしたい. ● 埋込み方の変更による精度向上がモデルの表現能 力の向上によるものなのか,最適化がしやすくなっ たためなのかの見極めが必要.実際,後になって等 価性が示された HolE と ComplEx もそれぞれの論 *8 ただし,本タスクにおいては,データセットをつくる段階で 名詞の上位・下位概念の対を明示的に与えているので,階層構 造が何の前提もなく自動獲得されたとはいえない. 表 4 WordNet における上位・下位概念関係に関する実験結果. [Nickel 17]より抜粋 図 5 Mammal の下位概念からなる部分木. [Nickel 17]より抜粋文で公表されている精度には大きな食い違いが存在 する.また,シンプルな線形モデルでも同程度以上 の精度改善が可能であるという報告がある [Joulin 17]. ● どのような空間が「計算」可能なのか.Poincaré 埋込みは運良く数学的には非常に性質の良い空間で あったが,そのような空間がほかにも存在するのか. ● 空間の計量をデータから学習することは可能か. Poincaré埋込みはデータに内在する木構造を自然に 表現可能な空間であったが,データに内在する構造 自体を空間の計量として獲得することは可能か.
● Poincaré埋込みを Knowledge Graph へ拡張するこ
とは可能か.Poincaré 埋込みは本質的に双曲空間に おける二点間の距離の計算に依存しているため,知 識グラフで扱われる三つ組へどのように拡張するの がよいのかは自明ではない. ● 双曲空間において,正値・負値をとり得る適切な スコア関数は定義可能か.Poincaré 埋込みでは双曲 空間の距離関数を基礎としているため,負値のスコ アの表現を自然に行うことは自明ではない.
◇ 参 考 文 献 ◇
[Bordes 13] Bordes, A., Usunier, N., Garcia-Duran, A., Weston, J. and Yakhnenko, O.: Translating embeddings for modeling multirelational data, Advances in Neural Information Processing Systems, pp. 2787-2795(2013)
[Harshman 70] Harshman, R. A.: Foundations of the parafac procedure: Models and conditions for an“explanatory” multimodal factor analysis(1970)
[Hayashi 17] Hayashi, K. and Shimbo, M.: On the Equivalence of holographic and complex embeddings for link prediction, Proc. ACL, UCLA Working Papers in Phonetics(2017)
[Joulin 17] Joulin, A., Grave, E., Bojanowski, P., Nickel, M. and Mikolov, T.: Fast linear model for knowledge graph embeddings, arXiv preprint arXiv:1710.10881(2017) [Krizhevsky 12] Krizhevsky, A., Sutskever, I. and Hinton, G.
E.: ImageNet classification with deep convolutional neural networks, in Pereira, F., Burges, C. J. C., Bottou, L. and Weinberger, K. Q., eds., Advances in Neural Information Processing Systems, Vol. 25, pp. 1097-1105, Curran Associates, Inc.(2012)
[松本 88] 松本幸夫:多様体の基礎,基礎数学,東京大学出版会(1988) [Mikolov 13a] Mikolov, T., Chen, K., Corrado, G. and Dean, J.: Efficient estimation of word representations in vector space, arXiv preprint arXiv:1301.3781(2013)
[Mikolov 13b] Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S. and Dean, J.: Distributed representations of words and phrases and their compositionality, Advances in Neural Information Processing Systems, pp. 3111-3119(2013) [Nickel 16a] Nickel, M., Murphy, K., Tresp, V. and Gabrilovich, E.:
A review of relational machine learning for knowledge graphs, Proc. IEEE, Vol. 104, No. 1(2016)
[Nickel 16b] Nickel, M., Rosasco, L., Poggio, T. A., et al.: Holographic embeddings of knowledge graphs, AAAI, pp. 1955-1961(2016)
[Nickel 17] Nickel, M. and Kiela, D.: Poincaré embeddings for learning hierarchical representations, in Guyon, I., Luxburg, U. V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S. and Garnett, R., eds., Advances in Neural Information Processing Systems, Vol. 30, pp. 6341-6350, Curran Associates, Inc.(2017) [Tang 15] Tang, J., Qu, M., Wang, M., Zhang, M., Yan, J. and Mei, Q.: Line: Large-scale information network embedding, Proc. 24th Int. Conf. on World Wide Web, pp. 1067-1077, International World Wide Web Conferences Steering Committee(2015)
[Trouillon 17] Trouillon, T., Dance, C. R., Welbl, J., Riedel, S., Gaussier, É. and Bouchard, G.: Knowledge graph completion via complex tensor factorization, arXiv preprint arXiv:1702.06879(2017)
[Yang 14] Yang, B., Yih,W.-t., He, X., Gao, J. and Deng, L.: Embedding entities and relations for learning and inference in knowledge bases, arXiv preprint arXiv:1412.6575(2014)
2018年 1 月 22 日 受理
![図 2 埋込みの線形性. [Mikolov 13b] より抜粋 図 3 Knowledge Graph. [Nickel 16a] より抜粋表1 SGNSとLINE の対応関係 *3 k > 1 ととることは同時経験分布 P (i, j)に対する相対的な割 引効果を与えるものと思われる. *4 区別しないことによりパラメータ数が削減される効果がある. 多くのツールでは区別しない実装になっている.](https://thumb-ap.123doks.com/thumbv2/123deta/8198466.1278257/2.892.462.797.122.434/埋込み線形より抜粋ととるに対する与えるによりパラメータツール.webp)

