Title A Proposal for the Establishment of an EAP Vocabulary Listand an Analysis of Its Appropriateness
Author(s) Mizoguchi, Setsuko; Shiina, Kiyoko; Sano, Masako; Thrasher,Randolph; Yoshioka, Motoko
Citation 大学英語教育学会紀要(23): 77-96
Issue Date 1992-08-25
URL http://hdl.handle.net/20.500.12001/10148
A Proposal for the Establishment of an EAP Vocabulary List and an Analysis of Its Appropriateness
Setsuko Mizoguchi Masako Sano Motoko Yoshioka International Christian Kiyoko, Shiina Randolph Thrasher University I. INTRODUCTION
Among the many research priorities in English education at the university level in Japan is to empirically define what constitutes English for Academic Purposes (EAP). There is wide agreement on the importance of such a task. The EAP vocabulary list proposed here and the research on which it is based are our anempt to provide meaningful criteria in this area. It is hoped that this study will pr~vide significant insights into EAP vocabulary and encourage future empirical studies in the field of EAP.
EAP comprises many sub-fields and, as a first step, we have focused our research specifically on vocabulary. Our interest in vocabulary research originated from previous research conducted by some members of our group, in which an interplay
bet~een reading comprehension and vocabulary control in English as a second/foreign language was studied. The purposes of our present study are to create an EAP vocabulary corpus, to analyze this corpus and the pans that compose it, and ultimately to establish an empirically based vocabulary list useful for pursuing academic activities in English at the university level.
Our first task was to produce a database by inputting a sizqble sample of text from introductory university textbooks in ten academic disciplines. Out of this database was created the EAP Vocabulary Corpus, which served as the basis of our analysis. We examined this corpus to discover the pattern of vocabulary overlap in the ten texts we surveyed. A number of studies on vocabulary published so far have been conducted on the basis of word frequency, but what distinguishes our present research from these is, that we have focused on the pattern of distribution of vocabulary over ten academic subjects. We have taken this approach because our interest was in determining vocabulary which would be 'of service to a number of different fields and in creating a list of vocabulary common to the majority of
The Japan Association of College English Teachers (JACET)
78
academic disciplines. This list will be called the EAr Vocabulary. The present report is concerned with an explanation of how that list was arrived at and an evaluation of its appropriateness. The evaluation was done by comparing our list with those prepared by Zeneiren and JACET and by analyzing our data from various aspects such as token-entry ratio, frequency, and level of difficulty.
During the analysis of the EAP Vocabulary Corpus that we created, a number of interesting additional findings emerged. The major ones relate to characteristics of the vocabulary in the Physical Science (PS) and Social Science' (SS) areas, the characteristics of different academic subjects in these two areas, and the percentage of Junior High School basic vocabulary in the whole corpus. The first two findings were reported in detail in
leu
Language Research Bulletin, Vol. 4, 1989.II. PROCEDURES USED FOR TIlE CREAnON OFTIiEEAP VOCABULARY
CORPUS
ll-l. Selection of the Materials to beSurveyed
The flfSt task of this study was to select the academic fields lobe included.. The ten academic fields examined in our research were selected from among those offered at Inten:ational Christian University (lCU), the institution with which all members of the research team are associated. lCU is a liberal arts college with five divisions at the time this research was started: Natural Sciences, Social Sciences, Languages, Humanities, and Education. Four disciplines from the Natural Sciences Division and six from the remaining four divisions were selected.
Table 1: PS and SS Disciplines Surveyed
Physical Science Social Science
Disciplines Disciplines
Biology (NS) Anthropology (SS)
Chemistry (NS) Economics (SS)
Mathematics (NS) Education (Ed)
Physics (NS) Linguistics
(Lj
Philosophy (H)
Following the usual custom in Japan, we have labelled the four disciplines selected from the Natural Sciences Division as Physical Science (Ri-kei, PS) and the six selected from the other divisions as Social Science (Bun-kei,SS).
II-2. Inputting of the pata
The professors in each of the above-mentioned ten disciplines at ICU were asked to recommend an introductory textbook they thought was appropriate for college students beginning work in their ~ajorfield (see Appendix A). In order to obtain the database, approximately 200 pages from each of the recommended textbooks were inputted into the ICU Computer Center IBM 4341. This data is called the ICU Database. Since the text was inputted as it appeared in the textbooks. it was convened to alphabeticallisls.
1I-3. Exclusion, Elimination, and Modification Procedures Step 1: Exclusion of Junior High School Vocabulary
To establish the basic English vocabulary needed at the university level, it was first necessary to remove from the database the words that are designated as Junior High School Vocabulary Or High Voc). We have defined this Jr High Voc as those words appearing in the Zeneiren list with an asterisk, that is, those marked as junior high school vocabulary, and their inflectional forms. We also added those words in the appendix to the Zeneiren list which are designated as junior high school
vocabulary in the Course of Study issued by the Ministry of Education in 1977. Step2: Elimination Procedures
Since the text was inputted as it appeared in the textbooks, the corpus contained proper names, foreign words, and other entries that would obscure our purpose of preparing a list of the most useful vocabulary for EAP. Therefore, the database was examined and the following eight categories of words were eliminated from the database.
1. Personal and place names and their derivations. Exceptions were those proper nouns that have come to be used as common nouns such as Christian, Buddhist, etc.
2. Foreign words, that is, those entries in italics in the Kenkyusha's New English-Japanese Dictionary. (e.g. conte, milieu, nouveau)
The Japan Association .of College English Teachers (JACET)
80
4. Compound words with -like,' -shape, and -wise. (e.g. leajlike, 'eggshape, clockwise)
5. Entries that occurred in the original database as one word but were listed in the above mentioned dictionary as multiple words. (e.g. check list, p~roll, side step)
6. Interjections. (e.g. ah, alas, 10 )
7. Archaic or rare words. (e.g. betwix, chi/de, gobbet)
8. Abbreviations. (e.g. a.d, a.m., mt., st.)
Step 3: Modification Procedures
The following modifications were made.
1. The various inflected forms 0"[nouns, verbs, and adjectives were combined into a single citation form. (e.g. gran:fying, gratified, and gratifies--> gratify )
2. Adjectives occurring with both -ic and -ical endings were checked to detennine if they had an entry for each spelling both in the K enkyusha's New English Japanese Dictiomiry and th"e'Shogakukan Random House Dictionary o/the English Language. If they were listed separately in the dictionaries, both fonns were retained. Ifthey were not listed separately, the fonn listed first was selected as the .entryin our corpus. (e.g. graphic, graphical
-->
graphic; theoretical, theoretic-->
theoretical; buteconomicandeconomicalwere both retained.)
3. Words with the adverbial suffix -ward or-wards were listed only in the form without the -so (e.g. cowards-->coward)
4. Words spelled differently in British and American English were listed under the American spelling. (e.g. behaviour -->behavior, analyse --> analyze; sulphur
--> sulfur). However, the British spelling was retained when it was listed before the American spelling. (dialogue, dialog -->dialogue)
II-4. The EAP Vocabulary Corpus
As the result of Steps 1-3 (See II-3), a corpus consisting of 255,495 tokens (12,935 entries) was obtained. The term 'token' is used in the same sense as inThe American Heritage Word Frequency Book, that is, 'tokens' are the total number of words in the input data. However, whereThe American Heritage Word Frequency . Book uses the term 'type', we use the term 'entries' to denote the distinct words among the 'tokens'. This terminology is adopted because Our entries are citation
.
.
forms. The corpus thus obtained, on which our whole analysis is based, is named the EAP Vocabulary Corpus (EAP Voc Corpus).
Table 2: EAP Voc Corpus, Jr High Voe, and Combined Corpus EAP Vocabulary Corpus Junior High Combined C.
Subject Tokens Enoies Tokens Tokens
Biology 27343 4108 45936 73279 Chemistry 27137 2222 38835 65972 Mathematics 19040 1458 46626 65666 Physics 27130 2069 56258 83388 Economics 24981 3719 53310 78291 Linguistics 25897 3211 56247 82144 Philosophy 22151 2708 64327 86478 Psychology 31616 4403 60794 92410 Anthropology 26510 5603 47793 74303 Education 23690 4405 53253 76943 Totals 255495 523379 778874
The columns 2 and 3 of Table 2 present the EAP Voc Corpus in the ten subjects. Column 2 is the number of tokens and column 3 the number of entries. Column 4 shows the number of Jr High Voc tokens in the original corpuses and column 5 the combination of columns 2 and 4. It should be noted that the numerical figures in column 5 do not include the words eliminated in Step 2 (see II-3). The bottom line reports the totals of columns 2, 4, and 5.
IT-5. Statistical Adjustment of the Data
Since the size of the corpuses of the 10 subjects differed, the frequency of each entry was adjusted to reflect its occurrence in a corpus of 100,000 tokens and then the ennies of the ten corpuses were combined and arranged in alphabetical order (see Appendix B).
II-6. Ranking of the Entries
The ennies in this combined list were ranked according to the total number of adjusted occun:ences in all ten corpuses (see Appendix C).
TIl. A PROPOSAL FOR TIlE ESTABLISHMENT OF TIlE EAP VOCABULARY III-I. Two Stages Followed for the Establishment
The Japan Association of college English Teachers (JACET)
82
first stage was based on eight subjects, four of which represent the PS and the remaining four represent the SS and the second stage was based on ten subJects with two more subjects added from the SS disciplines. The reason for adopting the [Wo-stage analysis was that it was first necessary to obtain the vocabulary general enough to be of service across both the social science and physical science areas, not focusing on individual academic disciplines. The second stage analysis was undertaken because there was a wider range of disciplines represented in the social science area than in the physical science area.
llI-2. SLage 1: Area-based EAP Vocabulary in the Eight Subjects
To fairly represent both the physical and social sciences in our study to detennine which vocabulary was common to both fields and which was common to only one or the other, an equal number· of disciplines in each area needed to be studied. All of the four PS disciplines were used and four of the six SS disciplines were selected. For the latter, one discipline was selected to represent each of the four non-physical science divisions then at JCU: philosophy from the Humanities Division, economics from the Social Science Division, linguistics from the Language Division, and psychology from the Education Division.
ITI-2-1.
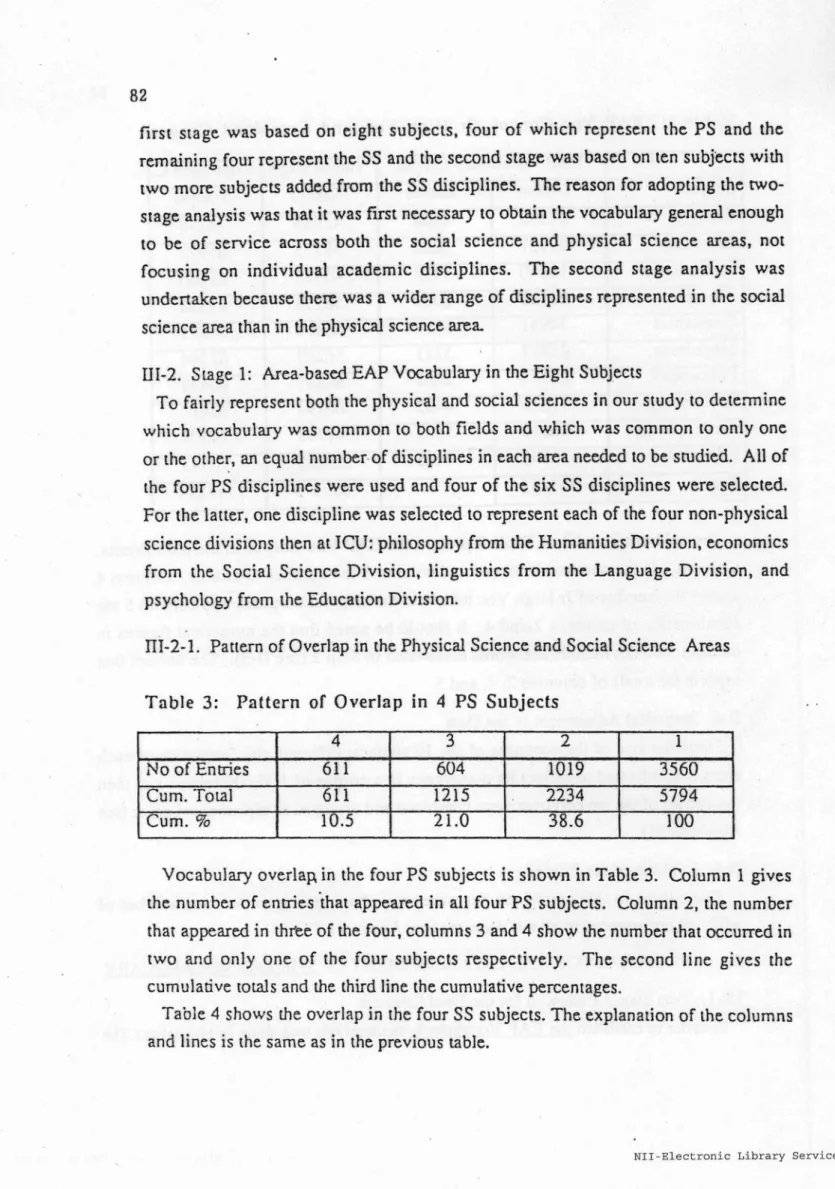
Pattern of Overlap in the Physical Science and Social Science AreasTable 3: Pattern of Overlap in 4 PS Subjects
4
3
2
1No of Enlries
611
604
1019
3560
Cum. TOLaI
611
1215
2234
5794
Cum. %
10.5
21.0
38.6
100
Vocabulary overlap. in the four PS subjects is shown in Table 3. Column 1 gives the number of entries 'that appeared in all four PS. subjects. Column 2, the number that appeared in three of the four, columns 3 and 4 show the number that occurred in two and only one of the four subjects respectively. The second line gives the cumulative totals and the third line the cumulative percentages.
Table 4 shows the overlap in the four S5 subjects. The explanation of the columns and lines is the same as in the previous table.
Table 4: Pattern of Overlap in 4 SS Subjects
4 3 2 1
No of Entries 912 873 1550 4673
Cum Total 912 1785 3335 8008
Cum. % 11.4 22.3 41.6 100
The same data perhaps can be grasped more easily if it is presented in the fonn of bar graphs. These graphs illustrate the great similarity in the pattern of overlap in the PS and SS areas. This remarkable similarity in two areas usually considered quite different is a significant finding which provides strong support for our decision to
analyze PS and SS data on an equal basis.
1 t~~lt.~~~{\~~{~w~tWqf&!.!.~~*{I<if~WWrmgfi%t~**~14~r.Mti~Wt~~{~~~I 3 5 6 0
.
o
1000.
.
2000 3000 4000
Figure 1: Pattern of Overlaps in 4 PS Subjects
4
WXWMW1NI
9 1 2
of-o
1000 2000 3000 4000 5000Figure 2: Pattern of Overlap in 4 SS Subjects
1II-2;.2. Common Vocabulary in the PS and 55 Areas
An examination of Tables 3 and 4 shows that, in each area, approximately 10 percent of the entries are common to all four subjects and another 10 percent common to three of the four. It was decidedtoconsider entries that occur in at least
The Japan Association of College English Teachers (JACET)
84
three of the four subjects as essential EAP vocabulary. Those entries that occur in at least three of the four PS subjects are designated Physical Science Common (PS Common). Likewise, those occurring in at least three of the four SS subjects are called Social Science Common (SS Common).' Requiring that a word appear in all four subjects before it could be considered essential EAP vocabulary would be too severe a restriction. Such a restriction assumes that there is more homogeneity than our detailed analysis of the individual corpuses indicates. On the other hand, including in our list of essential EAP vocabulary entries that occur in only two of the four corpuses would not be restrictive enough because such vocabulary could not be considered representative of the area. The total number of PS Common entries is
1215 and the number of SS Common entries is 1785.
"
III-2-3. Core Vocabulary--- Vocabulary Overlap between PS and SS Common Figure 3 shows the pattern of overlap between PS and SS Common. Some of the same entries occur in both PS Common and SS Common. The 874 entries occurring in both PS Common and SS Common are called Core Vocabulary, Those occurring in only one list or the other are designated PS Non:..core Common and SS Non-core Common respectively.
[]
~~ Core J . ~~ J . ~till
341--
PS Non-coreD
.: 55 Non-core " " "Figure 3: Overlap between' PS and S5 Common
Figure 4 gives the percentages of Core and Non-core COmmon for both PS Common and SS Common, It can be seen that Core Voc occupies 71.93 percent of PS Common while it occupies only 48.96 percent of SS Common.
51.0490 48.96%
01Core
o
PS Non-core Commonm C
liiJ ore
o
55 Non-core CommonFigure 4: Propo'dion of Core Vocabulary in PS and S5 Common
III-2-4. A Proposal for the Area-based EAPVocabulary
The Core Voc (874), PS Non-core Common (341), and SS Non-core Common, (911) have been combined and designated as the Area-based EAP Vocabulary, which contains2126entries in total.
4 PS S b" t
d R 'd I V
b d EAP V
Table 5," Area- ase oc an eSt ua DC In u 'Jec 5
Entries Tokens
Biology Chern Math Physics Biology Chern . Math Physics
4108 2222 1458 2069 Total 27343 27136 19040 27130 1537 1312 1033 1314 AreaEAP 15809 22481 16574 23476 37.41 59.05 70.85 63.51 % .57.82 82.85 87.05 86.53 2571 910 425 755 Residual 11534 4655 . 2466 3654 62.59 40.95 29.15 36.49· % 42.18 17.15 12.95 13.47
4 SS S b'
t d R 'd I V b d EAP VTable 6", Area- ase DC an eSt ua OC In U IJec S
Entries Tokens
Econ Ling Phil Psy Econ Ling Phil Psv
3719 3211 2708 4403 Total 24981 25897 22151. 31616
1710 1619 1572 1789 Area EAP . 17298 . 18744 19117 23314
45.98 50.42 58.05 40.63 % 69.24 72.38 86.30 73.74 (
2009 1592 1136 2614 Residual 7683 7153 3034 8302
The Japan Association of College English Teachers (JACET)
86
Tables 5 and 6 show the number and percentage of the Area-based EAP Voc and Residual Voc in the four PS and SS subjects respectively. The term Residual Voc is used to designate the tokens or entries that are not the Area-based Voc.
One of the most striking things about Tables 5 and 6 is that, in both the PS and SS areas, three of the four subjects show a great similarity of distribution, while one subject shows a different pattern than the others. The proportion of the Area-based and Residual Voc entries in chemistry, mathematics, and physics is roughly 2 to 1.. The proportion is reversed in biology. An examination of tokens yields the similar results. Biology is different from the other three PS subjects. In the SS area it is philosophy that shows a different pattern. This uniqueness of biology and philosophy is discussed at length in the Language Research Bulletin Vol; 4, 1989, and it is mentioned here onlyto point out that the other three subjects in each area are more representative of that area. The mean percentage of the Area-based EAP Voc entries in the three typical PS subjects is 64.4 (for tokens, 85.5) and the mean percentage of Area-based EAP Voc entries in the three typical SS subjects is 45.7 (for tokens, 71.8). These figures show that Area-based EAP Voc typically makes up a much smaller part of the total vocabulary in the SS subjects than it does in the PS subjects.
III-3. Stage 2: Subject-based EAP Vocabulary in the Ten Subjects
A consideration of section III-2-4 leads to the conclusion that the Area-based EAP Voc, that is, the list based on four PS and four SS subjects, is not adequate for reading in social sciences. Ifwe are going to expand the list, it is obvious that the increase should be in SS vocabulary rather than in PS. Therefore, the data from Anthropology and Education that had been excluded from the Stage 1 analysis was re-examined. This means that a tptal of six SS subjects were included so that, together with the original four PS subjects; a total of .ten were considered.
TII-3-!. Pattern of Overlapin the Ten Subjects
Table 7 shows that 391 entries occur in all ten subjects, an additional 258 occur in 9 out of la, and that 271 occur in 8 of the 10 subjects and so on. The second line shows the cumulative total of entries and the bottom line the cumulative percentage of entries in all 10 subjects, 9 out of la, 8 out of la, and so on.
Table 7: Pattern of Overlap in 10 Subjects
10 9 8 7 6 5 4 3 2 1
# of Entries 391 258 271 329 394 547 824 1301 2281 6337
Cum Total 39] 649
920
1249 1643 219U 3014 4315 659E 12933Cum % 3.0 5.0 7.1 9.7 12.7 16.9 23.3 33.4 51.0 100
III-3-2. Four-way Common Vocabulary in the Ten Subjects
As was mentioned above, the SS subjects were under-represented in the Area-based EAP Voc and their weight needed to be increased. To realiz.e this, the original ten corpuses were examined to determine the number of subjects that each word occurred in. On the basis of the pattern of distribution shown in Table 7, it was decided to select entries that. occurred in four of the ten subjects and to designate them as the Subject-based Four-way Common Vocabulary, which contains '3014 entries. This list of 3014 is comprised of 2041 entries which have already been selected in the Stage 1 analysis and 973 additional new words. Our decision to use four-way common as the criterion in the Stage 2 analysis was reached by a careful consideration of what kinds of new wo~ds should be selected to supplement the list already obtained in the Stage 1 analysis. Requiring that an entry occurs in four out of ten subjects suggests three possible ways new words could enter the list. 1) They could occur in two PS and two SS subjects. 2) They could occur in one PS subject and three SS subjects. In this case, at least one of the SS subjects must be either Anthropology or Education. 3) They could occur in four S5 subjects. In this case, the word must occur in both the Anthropology and Education corpuses. These possibilities make it clear that by using four-way common as our standard for inclusion, the need to increase representation from the 55 area is satisfied.
1II-3-3. ,A Proposal for the Subject-based EAP Vocabulary
As was stated above, the number of ennies obtained by this second stage analysis was 3014. In this total are included 2041 entries which also appear in the Area-based EAP Vocabulary. This leaves 973 entries which are unique to this second corpus. These 973 entries are designated as the Subject-based EAP Vocabulary. III-4. Establishment of the EAP Vocabulary
It is proposed that the vocabulary consisting of the 2126 entries of the Area-based EAP Vocabulary plus the additional 973 entries of the Subject-based EAP
The Japan Association of College English Teachers (JACET)
88
Vocabulary be established as the EAr Vocabulary (see Apprendix D). This gives a total of
3099
entries in our final list and this number is roughly the same as the number of entries in the Zeneiren and JACET lists.IV. ANALYSIS OF TIlE EAP VQCABULARY
IV-1: TIle Percentage of the EAP Vocabulary in each of the Ten Su bjects
Table 8: Breakdown of EAP Voc Corpus into EAP &Non-EAP (Tokens)
Subjects EAPVoc EAPVoc Non-EAP Voc
Corpus No % No % Biology
27343
19466
T1.197877
28.81
Chemisrry27136
23391
86.20
3745
13.80
Mathematics19040
17172
90.19
1868
9.81
Physics27130
24245
89.37
2885
10.63
Economics24981
20329
81.38
4652 -
18.62 :
Linguistics25897
20326
78.49
5571
21.51
Philosophy22151
20089
90.69
2062
9.31
Psychology31616
25818
81.66
5798
18.34
An thropolo gy26510
19439
73.33
7071
26.67
Education23690
18268
77.11
5422
22.89
ITable 8 shows the numbers and percentages of the EAP and Non-EAP Voc (tokens) within what is called the EAP Vocabulary Corpus. It is clear from the Table that the EAP Vocabularv accounts for a very high percentage within each academic discipline. If it is reasonable to assume a close relationship between reading comprehension and knowledge of vocabulary, the findings presented above indicate that university level reading skill depends to a great degree on the EAP Vocabulary that has been recommended.
Table 9 shows the breakdown of the Combined Corpus (see II-4). Column 1 presents the total number of tokens in each of the ten corpuses. Columns 2 and 3-sh·ow the number and the percentage of the Jr High Voc tokens, Columns 4 and 5 those of the EAP Voc tokens, columns 6 and 7, those of the Non-EAP Voc tokens. Itshould be noted that the Jr High Voc and the EAP VocabularY together make up
90
or more percent of the tokens in all subjects. This is another demonstration of the appropriateness of our proposed EAP Vocabulary because the students who havelearned this vocabulary will find a large portion of the vocabulary in their specialized field familiar.
Table 9: Breakdown of the Combined Corpus (Tokens)
Subjects Comb'd Jr High Voe ' EAP Voc Non-EAP Voc
Corpus No % No % No % Biology 73279 45936 62.69 19466 26.56 7877 110.75 Chemistry 65972 38835 58.87 23391 35.46 3746 5.68 Mathematics 65666 46626 71.00 17172 26.15 1868 12 .84 Physics 83388 56258 67.47 24245 29.07 2885 13.46 Economics 78291 53310 68.09 20329 25.97 4652 5.94 Linguistics 82144 56247 68.47 20326 24.74 5571 6.78 Philosophy 86478 64327 74.39 20089 23.23 206~ 12.38 Psychology 92410 60794 65.79 25818 27.94 5798 16.27 Anthropology 74303 47793 64.32 19439 26.16 7071
!
9.52 Education 76943 53253 69.21 18268 23.74 5422i
7.05IV-2. Token-Entry Ratio of the EAP Vocabulary
In this section the EAP Vocabulary is analyzed i~ tenns of the Token-Entry Ratio (TER). The TER is obtained by dividing the number of tokens by the number of entries and shows how frequently individual words are used.
Table 10 shows the TER for the EAP and Non-EAP Voc in the ten subjects. Table 10: TER of EAP and Non-EAP Voe in 10 Subjects
Subjects EAPTER Non-EAPTER
Biology 9.4 3.9 Chemistry 15.0 5.6 Mathematics 15.1 5.8 Physics 15.8 5.4 Economics 9.3 3.G' Linguistics 10.3 4.5 .Philosophy 10.7 2.5 Psychology 11.1 2.8 Anthropology 7.9 2.2 Education 8.1 2.5 Average 11.27 3.82
The Japan Association of College English Teachers (JACET)
90
The Table shows that the EAr Vocabulary has a considerably higherTER value than that of the Non-EAP Voc. The average for the EA? Vocabulary across the ten subjects is 11.27, while the average for the Non-EAP is only 3.82. This means that words in the EAr Vocabulary list occur repeatedly in each of the subjects and this is a fanher demonstration of its appropriateness.
The TER also shows the characteristic difference between the PS and SS areas.
Table 11: TER for PS and 55 Areas
PS Subjects TER Biology 6.7 Chemistry 12.2 Mathematics 13.1 Physics 13.1 Average 11.3 SS Subjects TER Economics 6.7 Linguistics 8.1 Philosophy 8.2 Psychology 7.2 Anthropology 4.7 Education
5.4
Average 6.7Table 11 presents the TER for each subject. The mean TER of the PS subjects is 11.3 and that of the SS is 6.7. The mean TER in the three typical PS disciplines (chemistry, mathematics, and physics) is 12.8 which is neal}y double the mean figure for the SS disciplines. The peculiar nature of biology is again obvious in the TER (seeIll-2-4). The TER of biology more resembles those of SS s~bjects than it does those of the other PS subjects.
IV-3. The EAr VocCfbulary in Terms of Frequency
As was mentioned in II-5, the raw frequency of occurrence was adjusted to reflect frequency in a corpus of 100,000 words in order to make the corpuses of the ten subjects comparable. Using this adjusted frequency data, a rank list was obtained.
Figure 5 shows the proportion of the EAP and Non-EAP Voc in ranks 1 to 1000, 1001 to 2000, 2001 to 3000, and above· 3001. The percentage of the EA P Vocabulary in the first 1000ranks shows 92.3, in 1001-2000ranks, 75.7, and iri 2001-3000 ranks, 60.7. It drastically drops at 3001 ranks or above. (7.7%) Of the 3099 EAP Voc entries, 2337 entries (75.4%) fall in the first3000 ranks. Only 762
entries (24.6%) do not fall in 1 through 3000 ranks. In other words, the appropriateness of the EAP Vocabulary list is supported by this examination of frequency just as it was in our examination of the TER.
Above 3001@1
I
2 0 0 1 . 3 0 0 0 :§R~Mt~f.Witt.1l~WfWWII
1 001 - 2 000 ~ltia~.(*~~~{~W?t}~(~I1
1 - 1 0 0 0 [email protected],~X~'wm1~~~~'*ti~1~N~~~_1.in1
0% 20% 40% 60% 80% 100 %o
Non-EAPFigure 5: Percent:lge of EAP and Non-EAP Voe In the Stratified Rank
·List
The characteristic difference between the PS and SS areas is also observed in the disnibution of high and low frequency words.
Table 12: Percent:lges of High and Low' Frequency Words
Bio Chern Math Phy Eco Ling Phil Psy Anth Ed
1-9 83.2 77.9 74.8 . 76.8 86.0 81.3 82.4 83.8 89.2 87.3
10+ 16.8 22.1 25.2 23.2 14.0 18.7 17.6 16.2 10.8 12.7
Table 12 shows the percentage of words that occur from one to nine times and the percentage of those occurring 10 or more rimes in the ten subjects. If the PS and SS areas are compared, the percentages of words occurring from 1 to 9 times (low frequency words) in the S5 is higher than those in PS disciplines except for biology. V-4. Level of Difficulty of theEAP Vocabu lID
For the purpose of analyzing theEAP Vocabulary in tenns of diffic;ulty, the three level difficulty distinction, A, B, and C, which was validated in our previous research (lCU Language Division Anllual Reporcs, Vols. 2 and 3) was adopted. The A level words are those includedin the Zene.iren list, the B level words are those occurring with a single asterisk in Kenkyusha's New Collegiace English-Japanese Dictionary (4th ed.). Words not appearing in A or B are classified as C level. For purposes of comparison, the aneiren list and the list derived from the dictionary
The Japan Association of College English Teachers (JACET)
92
were modified by using the exclusion, elimination, and modification procedures described in Section II-3.
18.10% 61.31%
[0 A level
D
B levelEill
C levelFigure 6: Breakdown of EAP Voc According to Levels of Difficulty Figure 6 shows the division of the EA P Vocabularv into the three levels of difficulty. Out of 3099 entries, 1900 (61.31 %) are A level, 561 (18.10%) are B level, and 638 (20.59%) are C level. An observation of the lCU Placement Test Vocabulary Subtest results indicate that the High-A level vocabulary (see ICU Language DivisionAnnual Report, Vol. 5) has not been fully acquired yet by April
ent.eri~gfreshmen. This shows the appropriateness of having a large percentage of the A level words in the EAP Vocabulary list. The inclusion of 18.10% ofB level and 20.59% of C level vocabulary is also appropriate because A level alone is not adequate for university reading.
V. THE EAP VOCABULARY IN COMPARISON WIlli TIIE ZENElREN AND JACETLISTS
In this section the EAP Vocabulary list is compared with the lists recommended by Zeneiren and JACET. In dealing with the JACET list, we used the same exclusion, elimination and modification procedures described in Section II-3.
Table 13: Overlap between Proposed EAP Voc List and Zeneiren and JACET
Zeneiren JACET either Z or J UniqueEAP
3099 1900 1720 2051 1048
Table 13 shows the pattern of overlap between our proposed EAP Vocabulary list and those of Zeneiren and JACET. Itcan be seen that the percentages of overlap between our list and those of Zeneiren and JACET is 61.3% and 55.5% respectively. The percentage of items on our proposed list to occur in either one or the other of these lists is 66.2%, which is a sizeable overlap. The remaining 33.8% is unique to our list.
VI. CONCLUSION
This research can be deemed successful if the EA? VQcabulary list is useful tQ students in a variety of disciplines. It has commonly been thought that the most effective language teaching would take place if students were divided according to their specialization. However, the vocabulary overlap among all of the ten disciplines we surveyed is large enough to make it reasonable for students in all disciplines to study the EA? VQcabulary rather than only the vocabulary specific to their subject area. The empirically based vocabulary list which we propose in this paper supports the notion that there exists such a category as essential English vocabulary for academic purposes. The appropriateness of the list is well validated by the result Qf comparison with other already published lists and of analyzing Qur data from the standpoints Qf the TER, frequency, and level of difficulty.
It should also be mentioned that, in spite of the overlap described above, some characteristic patternings of vocabulary distributiQn in the Physical and Social Sciences were also observed. Although the popular image of the physical science area is that there is a,great number of vocabulary unique to each discipline, we found that the number of specialized words is smaller than in SS but that the frequency of . Qccurrence Qf these words is higher than that of specialized words in SS. However, 'biology and philosophy are exceptions to the typical characteristics of the PS and SS
disciplines respectively.
It is aUf hope that this list will serve as a standard in determining appropriate vQcabulary for various academic fields as well as becoming the basis for further research in the area of English for Academic Purposes.
Because of limitation of space, only samples of the EA? Vocabulary list, the Adjusted Frequency list, and the Rank list are given in this paper.
The Japan Association of College English Teachers (JACET)
9t1
References
Carroll, John B., et al. (1971) The American Heritage Word Freguency Book. New York: American Heritage Publishing Co., Inc.
. Carter, Ronald. (1987) Vocabulary: Applied Linguistic Perspectives. London: Allen & Unwin.
Dollerup, Cay, etaI. (1989) "Vocabularies in the Reading Process," ATLA Review. Vol. 6, 21-33.
Linde, Richard, et al. (1977) uAn Analysis of the English Vocabulary Items Attained by High School Graduates in Japan--An Interim Report," Annual Reports, Vol. 2. ICU Division of Languages, 61-89.
Linde, Richard, et al. (1978) "An Analysis of the English Vocabulary Items Attained by High School Graduates in Japan--The Second Interim Report," Annual Reports, Vol. 3. ICU Division of Languages, 85-114.
Linde, Richard, et al. (1980) "Factors Contributing to the English Reading Ability of Japanese University Students--Vocabulary," Annual Reports. Vol. 5.
ICUDivision of Languages, 87-109.
Mizoguchi, Setsuko, et a1. (1989) "Patterns of Vocabulary Overlap In Eight Physical and Social Science Subjects," lCULanguage Research Bulletin,
Vol. 4. No. 1,39-61.
Ta)<efuta, Yoshio. (1981) Computer no Mira Gendai Eigo-:-Vocabularv no Kagaku [Computer Analy:ds of Contemporary English--An Empirical Study of Vocabulary). Tokyo: Ejuka Publishing Co.
The: compilation of the ICU EAP Vocabulary Corpus was partially funded by a .
Mombusho Grant for Scientific Research, Grant No. 590101011.
Appendix A: The Author's ~nd the Titiles of the Textbooks Used
Biological Systems by Shelby D. Gerking. Chemistry by Michell J. Sienko.
Calculus and Analvtic GeometrY by George B. Thomas, Jr. Fundamentals of Physics by David Halliday and Robert Resnick. Economics by Paul A. Samuelson.
General Linguistics: An Introductory Survey by R. H. Robins. The Cenrral Questions of Philosophy by A. J. Ayer.
Psychology by Guy R. Lefrancois.
Social Anrhropologv in Perspective by 1. M. Lewis.
Appendix B: The Ajusted Frequency of Occurrences and Distribution
by Areas and Subjects
PS(.4) SS(4) (oth.,..) Toh\. Rank Bio eh. Mat Phy Eco Lin Phi Pay I Ant Ed'"
absance e 2 0 121 6 19 1 26: 8 6 96 848 abso\.ute 1 24 40 6\ 15 ,5 3 :I : 8 16 120 611 abso\.uh\.y 0 2 14 01
'"
1 0 12 : 0 0 33 1780 .bsorb 56 9 2 11 1 0 0 0: 1 6 76 943 .bsorption 49 6 0 0 0 0 0 2: 1 0 66 1190 ",baorptive 1 0 0 0 0 0 0 0: 0 0 1 9163 abstain 0 0 0 0 6 0 0 0: 1 1 7 4669 .bstention 0 0 0 0 0 0 I 0: 0 0 1 9163 abstinanca 0 0 0 0 1 0 0 0: 0 0 1 9163 abstract 4 3 2 0 ,3 39 32 6: 11 9 108 678 abst,..ctab\.e 0 0 0 0 0 4 0 0: 0 0'"
6979 abst,..cUon 0 0 0 0 1 46 1 I : 0 0 49 1316 abstr.ct\.y 0 0 0 0 0 0 1 0: 1 0 2 7970 abal,.usa 0 0 0 0 0 0 0 0: 1 0 1 9163 ~bsu,.d 0 0 0 0 3 2 6 0:"
0'"
3081 .bsurdity 0 0 0 0 0 0 5 0: 0 0 6 6341 .bsurdly 0 0 0 (I 0 0 1 0: 0 0 1 9163 abundance 15 Ii 0 0 0 0 0 0: 7 0 28 2002 .bundant Ii 2 0 0 3 0 1 I : 7 1 20 2476 .bundant\y 0 0 0 0 0 0 0 0: 0 1 1 9153 .bu•• 0 0 0 0 1 11 0 2: 6 Ii 13 3204Appendix C:, The Rn'nk List
ran\( fraq rank fraa ,.an\( frao
1 forca 1914 17 flgura 991 33 a'lamant 714
,2 axIUIlp\.a 1679 18 rasu\.t 990 34 typa 713
3 eystam 1381 19 a\.actr,on 968 35 mo\.acu\.a 611.4
"
anargy 1376 20 how.ver 960 36 aqua\. 676 6 function 1:1.43 21 charg. 106 37 •• n •• 672 6 aquation 11811 22 prob'lam 897 38 condi tlon 66.4 7 tartft 1170' 23 ar.a 863 39 prooaa. 6'628 faot 1100 24 incr •••• 863 <40 g.nar.\' 649 9 thus 1017 2!i con.tant 849 <41 lIIe thod 646 10 atom 1076 26 "'
...
BAli . 42 invo'lv. 640 11 ca"'\, 1070 27 objact 830 43 consldar S2112 pa,.Uc\'a 1066 28 IllOti on 791 44 dam and 619
13 curv. 1035 29 \.ava\ 741 45 raqui'ra 618 14 va\.ua 1026 '30 uni t 734 046 tamperatura 616 16 thaory 1020, 31 socia\. 729 47 \1m1t- 607 16 education 992 32 individua\. 716 48 poal tion 699
The Japan Association of College English Teachers (JACET)
96
Appendix ·D: The
EAP
Vocabulary
ill!.l (Freq, Rank)
Recommended EAP Vocabu\ary: Occurrencee in eatabloi.hed List.
B .oc ••• ( 29, 1951·) F
(JACET &Zen Eir.n)
B acoa.alb\a ( .28, ?0~2) S F
Adju.ted Fraquancy and Rank
J A ecoidant ( 48, 1333) C p S F
Di.tribution by EAP SUbcategori.e
C aocidenhl.\~ ( 9, 3997) F
A acoolMlodata ( 33, 1780) F
Occurrence. in EetabUeh.d Li.ts
J A acoompany ( 106, 895) C P S F J A acoo"'pl.i.h ( 75, 988) S F J JACET 1720 B aocord ( 101, 726) S F A Zen Eir.n
..
1900 B accordanca ( 12, 3383) S F J'A aocording ( 228, 290) C P S F Levalo. of Difficul.ty a acoordingl.y ( 43, 1453) S F J A account ( 481, 89) C P S F A \ev.l....
1900 B aooumu\at. ( 37, 16014) F a l.eve\ ... 561 B acoumul.a ti on ( 15, 2961 ) S F C \eve\...
638 A acouracy ( 47, 1367) S F J A accurat. ( 74, 968) C P S F B accurata\y ( 44, 1437) C P S F EAP Subcategories J A accu.a ( 21, 7392) 9 F J A accuatom ( 16, 2837) S F C Ar.a-ba •• d Cora J A achi.va ( 172. 412) C P S F P Ar.a-ba.ed PS COlMlon A achiavamant ( 66, 1068) C P 9 F S Ar.a-ba.ed 99 Common j B acid ( 161. 473) P FF '"
.
SUbjact-ba.ad 4-way Common, Aacknow\.dga ( 31 ; 1869) p. F B acknowl.adgmant ( 6, 4960) S F C P S F
...
874 A acquaint ( 8. 427"5") F P F • • • • • , . .I t• • 301 A acquaintanca ( 18, 2636) S l= S F ... 866 J A acquira ( 118, 621) S F P • •I t• • • • • • • 40 a acqulaiUon ( 20, 2476) S F 5...
45 J A acra ( 24, 2200) F F...
973 J A act ( 628, 72) CPS F J A· action ( 210. 322) CPS F J A activa ( 66. 1064) 9 FLave\ ( Fraq, Rank)
J A activity ( 367, 160) 5 F' J A abandon ( 21, 2392) S F J A actual. ( 242, 268) C P,S F C abandonm.nt ( 4, 6979) F J A actua\\y ( 243, 266) C P S F B abbraviate ( 10, 3783) P F A acuta ( 23, 2261) S F B abide e II, 3547) F J A adapt ( 43. 1463) 5 F J A ab1\1ty e 191, 363) C P S F B adaptation ( 48, 1333) 5 F B abnormal. ( 27, 2048) F J A add e446, 110) C P 5 F
B abo\i.h ( 4. 6979) F J A addi tion
( 238, 276) CPS F J A abroad e 21! 2392) F J A addi tional.
( 91, 799) CPS F J A ab •• nc. ( 86, 848) C P 9 F J A ad.quate ( 41, 1617) S F J A ab.o\ut. ( 120. 611> C P S F C adaquatel.y ( 19, 2660) C P S F J A absoloutel.y ( 33, 1780) S F a adhara ( 12. 3383) 5 F J A absorb ( 76, 943) P F C adh.ranca e 9, 3997) S F a absorption ( 66, 1190) F C adheaion ( 8, 4276) F J A abstract ( 108, 678) C P S F B adjacant ( 61. 1129) C P 5 F
C abstraction ( 49, 1316) S F J B adj acth,a
( 107, 686) S F A absurd ( 14. 3081) S F J A adju.t ( 35, . 1713) C P S F , abundant ( 20, 2476) S F ( 47, 1367) S F A B adju.t",.nt A abus. ( 13. 3204) F B adminIst.r ( 28. 2002) F J B acadamic ( 62, 111e) S F J A admlnlst,.aUcin ( 40, 16-42) S F A academy ( 16, 2837) F C admis.lb\a ( Ii,' 6341) S C acc.\erata ( 108, 678) P F J A admission ( 8, 4276) S F C acca\.raUon ( 378, 142) P F J A admi t ( 72. 992) S F J A accent ( 9" 3997) F J A adopt ( 113. 64~) C P S F J A accept ( 178', 390) C P S F B adop~ion ( 14. 3081) F J C acc.pt~b\. ( 49. 1315) S F J A adu\t ( 77, 935) S F J B accaptanca ( 76, 943) S F C adu\thood ( 22, 2326) 5 F