筑波大学大学院博士課程
システム情報工学研究科修士論文
クラスタ情報の可視化による 大規模2部グラフの可読性向上手法
佐藤 修治
(
コンピュータサイエンス専攻)
指導教員 田中 二郎2008
年3
月概要
ネットワークの情報が容易に取得できるようになった近年,大規模ネットワークの描画手 法の開発への要求は高まっている.従来手法ではネットワークにおける要素の数を減らすこ とで対応することが多かったが,この手法では曖昧な情報のみしか読み取ることができない.
また,読み手により適切なグラフの規模は異なるということに対応することができない.
本研究では,2つの新しい描画手法を用いて2部グラフを対象とした大規模ネットワーク の可読性向上を狙う.可読性向上には,「見易さ」と「読取りやすさ」の向上が不可欠である.
見易さを向上させる手法として「縮退描画手法」を開発した.クラスタリングによりノー ド間の類似度を求めておき,閾値を超えた類似度のノード集合を
1
つのクラスタとして描画 する可視化手法である.閾値は読み手がスライダにより変更でき,ネットワーク図の拡縮を 自由に行うことが可能である.読取りやすさを向上させる手法として「等類似度線描画手法」を開発した.縮退描画手法 同様クラスタリングの情報を用い,閾値を超えた類似度のノード集合を閉曲線で囲み描画す る可視化手法である.ノード間の類似度の高さを等高線のように表示することで関連性を直 接可視化することにより,より理解しやすくさせるのが狙いである.
縮退描画手法と等類似度線描画手法の有効性の検証と評価をするため被験者実験を行った.
結果として,両手法ともグラフの可読性を向上させることに成功しており,特にグラフから の情報の読取りやすさが向上することが確認された.
本描画手法は,読み手が求める適切な情報を表示することで,大規模ネットワークの可読 性向上を達成している.従来手法では困難であった,大規模ネットワークの全体的な俯瞰と 特定の注視要素の関係情報が一度に読取ることが可能になった.
目 次
第
1
章 序論1
1.1
ネットワーク. . . . 1
1.2
ネットワークの可視化. . . . 1
1.3
可視化の目的. . . . 2
1.4
可視化方法の重要性. . . . 3
1.5
ネットワークの肥大化と可視化への影響. . . . 3
1.6
目的. . . . 4
1.7
本研究の貢献. . . . 4
第
2
章 ネットワーク描画と可読性5 2.1
グラフ. . . . 5
2.2
2部グラフ. . . . 5
2.3
2部グラフの表現形式. . . . 6
2.3.1
数学的形式. . . . 6
2.3.2
行列形式. . . . 7
2.3.3
網図形式. . . . 7
2.4
スプリングモデル. . . . 7
2.5
アンカーマップ. . . . 9
2.6
ネットワーク図における可読性. . . . 10
第
3
章 可読性を向上させるためのアプローチ14 3.1
概要. . . . 14
3.2
クラスタリング. . . . 14
3.2.1
クラスタリング手法の選択. . . . 15
3.2.2
ノード間類似度の導出方法. . . . 15
3.2.3
クラスタの構築. . . . 17
3.2.4
本手法の特徴. . . . 20
3.3
描画システム. . . . 21
第
4
章 縮退描画手法24 4.1
概要. . . . 24
4.2
手法. . . . 24
4.2.1
グラフ構造の変換. . . . 25
4.2.2
描画. . . . 26
4.3
実装. . . . 26
第
5
章 等類似度線描画手法30 5.1
概要. . . . 30
5.2
手法. . . . 31
5.2.1
グラフ構造の変換. . . . 31
5.2.2
描画. . . . 32
5.3
実装. . . . 34
第
6
章 評価実験35 6.1
実験目的. . . . 35
6.2
実験方法. . . . 35
6.3
実験結果. . . . 36
第
7
章 適用例と考察40 7.1
購買データの可視化. . . . 40
7.1.1
小規模購買データ. . . . 40
7.1.2
大規模購買データ. . . . 42
7.2
論文共著者情報の可視化. . . . 46
7.3
考察. . . . 49
7.3.1
縮退描画手法の有効性. . . . 49
7.3.2
等類似度線描画の有効性. . . . 49
7.3.3
グラフ読解の支援. . . . 49
7.3.4
本手法の問題点. . . . 49
7.4
今後の課題. . . . 50
7.4.1
ラベリング. . . . 50
7.4.2
より大きなグラフへの対応. . . . 50
第
8
章 関連研究51 8.1
グラフの自動描画. . . . 51
8.2
知識の抽出. . . . 51
8.3
大規模グラフへの対応. . . . 51
8.4
クラスタ構造の活用. . . . 52
8.5
可読性向上の追求. . . . 52
第
9
章 結論55
謝辞
56
参考文献
57
後注
62
図 目 次
1.1
ネットワークの例. . . . 2
1.2
グラフを図で表す例. . . . 2
2.1
2部グラフの表現形式. . . . 8
2.2
スプリングモデルのイメージ. . . . 8
2.3
スプリングモデルによるレイアウト. . . . 9
2.4
アンカーマップ. . . . 10
3.1
クラスタリング手法の分類. . . . 16
3.2
デンドログラム. . . . 16
3.3
最短距離クラスタリング. . . . 17
3.4
クラスタリングの過程. . . . 19
3.5
クラスタリング順による変化. . . . 21
3.6 ClusteredAnchorViz
の概観. . . . 22
3.7
システム構成. . . . 23
4.1
スライダ変更時の走査. . . . 26
4.2
デンドログラム切断時の表示するノードとクラスタ. . . . 27
4.3
アプリケーション初期画面. . . . 28
4.4
クラスタの展開の様子. . . . 29
5.1
等類似度描画手法を用いた表現. . . . 31
5.2
アノテーションで囲み線を用いる例. . . . 32
5.3
凸包. . . . 33
5.4
閉曲線を描画する方法. . . . 34
6.1
実験に用いたグラフをアンカーマップにより描画. . . . 36
6.2
実験に用いたグラフを縮退描画手法で描画した様子. . . . 38
6.3
実験に用いたグラフを等類似度線で描画した様子. . . . 39
7.1
購入時間帯–
商品の関係のアンカーマップによる描画. . . . 41
7.2
提案手法による購入時間帯–
商品の関係の描画. . . . 42
7.3
購入者—
商品のアンカーマップによる描画. . . . 44
7.4
等類似度線描画手法(t = 100%
)による購入者–
商品の関係の描画. . . . 44
7.5
縮退描画手法による購入者–
商品の関係の描画. . . . 45
7.6
2ホップ. . . . 46
7.7
アンカーマップによる論文共著者情報の可視化. . . . 47
7.8
等類似度線描画手法(t = 0%
)による論文共著者情報の可視化. . . . 47
7.9
縮退描画手法による論文共著者情報の可視化. . . . 48
8.1
本研究の位置付け. . . . 54
第 1 章 序論
1.1
ネットワークネットワークはこの世界の至る所に満ちあふれている.言葉こそインターネットの普及に より身近になったばかりという感覚を受けるが,人間関係,鉄道路線,電話回路網など人間 の生活には切り離せない場所に偏在している(図
1.1
1).近年
Web2.0
という言葉が叫ばれるようになり,一般のユーザが他のユーザに影響を与えるようなシステムが増えてきている.ソーシャル・ネットワーキング・サービス(
SNS
)はそ の典型であり,リアルな世界以外のヴァーチャルな友人関係が世界の様々な場所で構築され,その人間関係のネットワークは拡大の一途を辿っている.
人間関係のネットワークの研究において,しばしば「スモールワールド」もしくは「六次 の隔たり(
6–degree
)」という単語が現れる.これは,スタンレー・ミルグラムが1967
年に 行ったスモールワールド実験[1]
に依るもので,友人関係のネットワークから2人を任意に抽 出した場合,最高でも6人の人間の仲介で接続されるという仮説である.ソーシャル・ネットワーキング・サービス
mixi
の例を示すと,2005
年の湯田ら,森ら,安 田らによる分析結果によると,友人関係のネットワークはマイミク(友人)の平均数が10.4
,6
ホップで96%
をカバーでき,スモールワールドの特徴を備えっていることがわかっている[2]
.このようなネットワークの場合,分析には友達同士の関係だけではなく,彼らが所属する コミュニティを読み解くことで,理解が深まるというと言うことが知られている
[3]
.人と所 属の関係は2部グラフ(2部ネットワーク)という形式で表現され,社会的なネットワーク の特徴を捉える上で重要な役割を担う表現であると考えられている[4]
.1.2
ネットワークの可視化普段のネットワークを意識して生活している人々はそれほど多くはない.なぜなら,ネッ トワークは目に見えない抽象的なオブジェクトであるためである.
ネットワークは物(オブジェクト)とそのつながりにより構成される構造体の内,フロー
(流れ)が発生するものを指す.この構造体はグラフとして数学的に表現することが可能であ る.言い換えると,何らかの意味を持ったグラフがネットワークである.
数学的表現のグラフは,人間が直感的に要素間のつながりを認知するには困難な表現手法 である.そこで,我々は日常的グラフを認識する方法として用いているのが,「図」というイ
(a)鉄道路線図 (b) LAN回線図
図
1.1:
ネットワークの例図
1.2:
グラフを図で表す例ンタフェースである.図
1.2
にグラフの数学的表記から図への変換例を示す.このように,抽 象的な「データ」を,直接見ることが出来る表現へ変換することを,可視化(Visualization
) と言う.可視化の用途は,構造の認識や他人との意思疎通,データマイニング,問題発見などがあ り,様々な分野で研究が盛んに行われている.
1.3
可視化の目的人間は外界の情報を視覚,聴覚,触覚,味覚,嗅覚の五感を使い知覚している.この中で も視覚は全情報の
80
%もの情報を得ていると言われており[5]
,視覚情報をわかりやすくす ることがいかに理解につながるかが想像できる.本研究で扱う情報可視化(
Information Visualization
)は科学的なデータを視覚化する科学的 可視化(Scientific Visualization
)の流れを汲むものである[6]
.情報可視化の目的は知識の取 得と発見である.多量のデータをコンピュータにより可視化により支援し,人間だけでは得られない情報と知識の取得,発見を促進する.すなわち,グラフをコンピュータで処理をし て結果を見せることではなく,人がそれを情報として利用するための仕組みが目的の技術で ある.
そのため,結果を読み手に提示させるだけの一方向作用だけではなく,読み手が入力した 操作を反映させるインタラクションシステムの環境が適していると言われている
[7]
.1.4
可視化方法の重要性ネットワークの可視化における表現手法には様々有るが,図は大きく分けて4つに分類す ることが出来る.
•
座標系:
折れ線グラフ,棒グラフなど•
行列系:
表など•
領域系:
ベン図など•
網図(連結)系:
ネットワーク図,フローチャートなどこれらの表現手法の内,座標系や行列系は従来から研究が進んでおり,比較的表現方法が はっきりしている.それに対し領域系,網図系,およびその複合系は,ネットワーク構造の 視覚的記法として重要で有るにもかかわらず,描画方法があまり発達していない.
領域系や網図系の図は日常的に利用され,それにより理解が容易になることは経験的に認 識されている.ただし,その図の認識のしやすさ,されやすさは,図の書き方に強く依存す る.図の美しさによりその図の価値が決定され,理解の支援にも混乱を引き起こす原因にも 成り得るのである
[8]
.そのため,構造がわかりやすい等の美しい図を描くことは,可視化に とって最も重要な点の一つであり既存研究の大きな課題となっている.1.5
ネットワークの肥大化と可視化への影響情報技術の発展により,身の回りにあるネットワークが肥大化の一途を辿っていることは 衆知の事実である.
先に述べた
mixi
は,2005
年時点でノード数36
万個,エッジ数190
万リンクであった.2008
年1
月現在では既に1000
万ノードを超えており,顕著な規模増加が起きている.また,mixi
の友人関係は擬集性の高いネットワークであることが判明している.つまり,これを2
次元 平面上に可視化した場合,狭い空間にノードがひしめき合い,エッジの交差が多数存在する 塊が随所に現れるような表現で描画されることが予想される.ノード数とエッジ数の増加は,読み手によるネットワークの認識を難しくさせる
[9]
.その 理由の一つに可視化結果の可読性の低下がある.表示するデバイスの解像度を上げることで きめ細かい描画を行い,すべてのノードとエッジを表示することは可能であるが,人間の理解度の向上には繋がりにくい.人間の空間認識能力がはある一定以上上がらないためである.
つまり,読み手がネットワークを認識・理解するのに適当な大きさの領域に,簡潔に描画す ることが重要となる.
グラフ描画において可読性の問題は重要なトピックスの一つであり,可読性の向上に関す る研究は盛んに行われている.
1.6
目的本研究では,2部グラフで構成される大規模ネットワークの可視化における可読性を向上 させることを目的とする.2部グラフという特殊な構造を持ったネットワークを,その特徴 を利用した可視化を行うことで読み手の理解を高める.従来の手法は読みることが難しかっ た構造を読み手に把握し易くし,新たな知識の取得を支援する.
1.7
本研究の貢献従来手法では注目されていなかったグラフの意味を読み取り易くするという観点を取り入 れ,大規模2部グラフの可読性を向上させる手法を開発した.この手法を用いることで,グ ラフ描画のエキスパートだけではなく普段グラフを読まない人にも,効率よく知識を得られ るような描画が可能となる.
第 2 章 ネットワーク描画と可読性
本章では,ネットワークの可視化およびその可読性についての考察を行う.まず,ネット ワークの構造であるグラフの説明を行い,本研究で扱う2部グラフについて構造と描画手法 の説明を行う.最後に,グラフを可視化したときの可読性とは何かについてを考察する.
2.1
グラフグラフとは,ノード(節点・頂点)の集合とノード間を接続するエッジ(辺・リンク)の 集合により構成される数学的なデータ表現である.ノード集合を
V
,エッジ集合をE
とした とき以下の式2.1
として表記される.G = (V, E)
E ⊆ V × V (2.1)
グラフはネットワークの特性により分類することが可能である.エッジには有向エッジと 無向エッジの2種類が有り,それを有するグラフのことはそれぞれ有向グラフと無向グラフ と呼ばれる.一般に木構造と言われる構造も,閉路を持たず単連結である無向グラフのこと を指す.グラフは抽象化された概念の1つの有力な表現形式であるので,様々な分野で基礎 的なモデルとして広く利用されている
[8]
.様々なグラフ構造のうち,本研究では2部グラフとして表現されるネットワークに焦点を あてる.
2.2
2部グラフノードの集合を二つの排他的な集合
V
1とV
2 に分割することができ,エッジの集合E
がV
1× V
2の部分集合であるようなグラフを2部グラフという.数学的には以下の式として表現 される(式(2.2)
).G = (V
1∪ V
2, E) V
1∩ V
2= ϕ E ⊆ V
1× V
2(2.2)
2部グラフをもつ構造のネットワーク(二部ネットワーク)は実世界の様々な場面で現れて いる.一般的に所属関係のネットワークは必ず2部グラフの構造を持っている.これは,ソー シャルネットワークにおける「コミュニティ」と「メンバー」の関係であったり,芸能界における「出演作品」と「出演者」の関係,購買ネットワークにおける「顧客」と「購買商品」
の関係などが例に挙げられる.
amazon.com
で買い物をする際に,「この商品をチェックした人 はこんな商品もチェックしています」という項目があるが,これも「商品」と「購入者」の2 部グラフの関係が形成されているものであり,日常的に利用される二部ネットワークの一例 である.研究分野でも2部グラフは注目されている.特に社会ネットワークにおいてその注目度は 高い.ソーシャルネットワークに関しては友人関係だけを見るのではなく,彼らの属するコ ミュニティの関係も読み解くことで,理解が深まるのではないかという仮説があることは先 に述べた通りであり,それに関しての研究も多数行われている
[10]
.ウェブログについても ブロガーとコミュニティの2部ネットワークを解析することで,ネットワークが発展すると の報告がある[4]
.論文の共著者関係のネットワークにおいても,その著者を結ぶ論文の存在 との関係を見ることで,ネットワークの特徴の新たな発見を期待できる[11, 12, 13]
.2.3
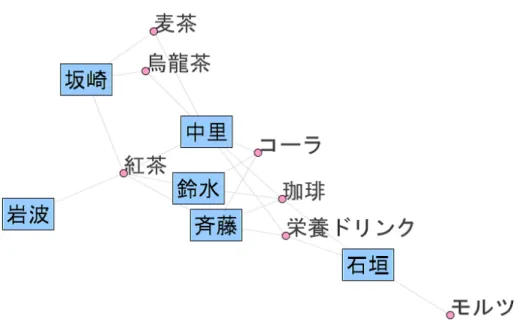
2部グラフの表現形式2部グラフは様々な形式で記述することが可能である.グラフは基本的に数学的な構造体 であるが,先に述べた通り人間にとって数式表現のまま構造をとらえるのは難しい.そのた め,人間に読みやすい形に視覚化を行う.本節では2部グラフの可視化表現のうち代表的な 表現形式を述べる.商品と購買者から成る購買関係の2部グラフを例に用い,実際に図で表 しながら説明を行う.
2.3.1
数学的形式数学的表記はグラフ構造の表現形式としては基本である.2部グラフにおいてもそれは変 わらず,グラフのすべての情報を表現出来るため,情報が欠落してはいけない伝達をする時 やグラフを定義する時に用いられる.
G =(V
1∪ V
2, E)
V
1={
石垣,
岩波,
斉藤,
坂崎,
鈴水,
中里}
V
2= {
珈琲,
紅茶,
麦茶,
烏龍茶,
ビール,
コーラ,
栄養ドリンク} E = { (
石垣,
珈琲), (
石垣,
ビール), (
石垣,
コーラ), (
岩波,
紅茶),
(
斉藤,
珈琲), (
斉藤,
紅茶), (
斉藤,
烏龍茶), (
斉藤,
栄養ドリンク), (
坂崎,
紅茶), (
坂崎,
麦茶), (
坂崎,
コーラ), (
鈴水,
紅茶), (
鈴水,
烏龍茶), (
中里,
珈琲), (
中里,
紅茶), (
中里,
麦茶),
(
中里,
烏龍茶), (
中里,
コーラ), (
中里,
栄養ドリンク) }
上記がグラフを数学的形式で表現した例である.この手法は無論グラフを読み解く際には あまり向かない.
2.3.2
行列形式グラフ構造は行列形式で記述することが可能である.エッジは2つの集合間にのみ存在す るという2部グラフの特性から通常のグラフよりも簡潔に表現されるため,よく用いられる 手法である.それぞれのノード集合を行と列に分解して表記する図
2.1(a)
の例では行に購入 者,列に商品を対応させ,購入者が購入した商品の欄に数値を入れることで表現している.行列表現の特徴としては,一つのノードを注目したときの,エッジの量がわかりやすいこ とから他のノードの関係を認識するのに良好であることがあげられる.
また,行列表現では情報を落とさない表現が可能であることも特徴の一つである.例えば,
購買情報においては「購入者がどれだけその商品を買ったか」といった情報が存在する.グ ラフ表現において,この情報はエッジの「重み(
weight)
」として表現される.行列表現にお いてはこのエッジの重みを数値として明確に表現することが出来るため,正確な詳しい情報 を知り得たいような状況では,特に有効な手法である.但し,視覚的な工夫がなされている訳ではないため,購入者同士の関係構造などの把握に はあまり適さない.また,描画領域の空間効率は他の手法と比較してあまり良くないため,大 規模なグラフを表現するときには広い描画領域が必要となる.
2.3.3
網図形式ネットワークの可視化にはよく網図形(連結系)の表現が用いられる.そのうち,2部グ ラフの表記に特化した形式では2層形式がある.二層形式はノードの2つの集合をそれぞれ 1列で表現する形式である.ノードを点や丸,長方形などで表し,ノード間を直線や曲線で 接続することでエッジを表し,グラフの関係を表現する.
図
2.1(b)
は,左側に購入者を,右側に購入商品を配置した二層形式の図である.一列に集合が整列されているおり,それぞれの集合に属するノードが理解しやすいことが特徴である ため,2部グラフの概要を説明する際に用いられることが多い.他の特徴としては,それぞ れの集合に属するノードの数の把握がしやすいこと,エッジ数の多いノードが把握しやすい などが挙げられる.
この手法の場合エッジの交差の問題の解決が難しく,完全2部グラフに近くなるほどどの ノードとどのノードが接続しているかがわかりにくくなってしまう.また,エッジの重みを表 現することが難しいため,グラフの解析を目的する時の可視化手法としてはあまり適さない.
2.4
スプリングモデルグラフの可視化に用いられる網図系の代表的な描画法の1つとして,スプリングモデル(ば ね埋込モデル,
Spring Embedded Model
)[14]
がある.エッジを自然長をもつバネと仮定し,(a)行列形式 (b)2層形式
図
2.1:
2部グラフの表現形式(a)エッジをばねに見立てる (b)斥力発生
図
2.2:
スプリングモデルのイメージエッジにより接続されないノード同士は斥力により反発力を発生させる(図
2.2
).バネと斥 力によりノードを配置し,安定状態を計算することで最終的にノードのレイアウトを求める 手法である.ノードのレイアウトに関しては以下の流れで行う.
1.
初期配置を決定する(ランダム配置など)2.
各々のノードに働く力の合計を求める3.
求めた力に従い,ノードのレイアウトを変更する4. 2
に戻る.スプリングモデルは2部グラフ専用の表現形式ではないが,二層形式と異なり重みのある
図
2.3:
スプリングモデルによるレイアウトエッジを表現することが可能であるため,ノードの関係をより良く知ることが出来る.その ため,グラフの自動描画の基本レイアウトとして多くの研究で用いられている.
図
2.3
は,スプリングモデルを適応した例である.長方形で表示したノードが購買者を,円 で表示したノードが商品を表しており,エッジは直線の接続で表現されている.エッジに埋 め込まれたばねの力で接続情報が似ているノードが近くにレイアウトされ,ノード同士の関 連性が認知しやすくなっている.2.5
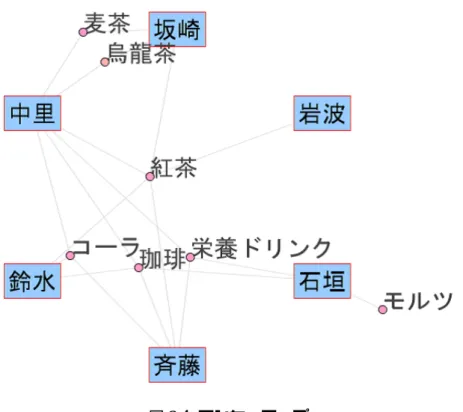
アンカーマップアンカーマップ
[15]
は,スプリングモデルを発展させて2部グラフに特化させた描画手法 である.2部グラフの2種類のノードの集合のうち一方のノード集合の位置に制約を課した 描画スタイルと定義される.前節のスプリングモデルでは全体的な構造は把握しやすいが,2つの集合(例では購買者 と商品)が混在しているため,ネットワークの構造がわかりやすいとはいえない.二層形式 ではノード集合同士は分割されているので把握はしやすいが,それぞれのノード集合内部同 士の関連性の把握は難しい.
ネットワーク構造を効率よく把握するには観点の導入が有効であり,それによりネットワー クの構造的特徴を認知するのが容易となる.アンカーマップは,片方のノード集合を固定し 座標軸のような効果を与え,観点導入の役割を果たしている.2種類のノードは位置に制約 を課す方をアンカーと呼び,もう片方をフリーノードと呼ぶ.アンカーとフリーノードは交 換可能で,どちらをアンカーにするかは自由に変更することが出来る.アンカーは円周上に 等間隔配置(正多角形の頂点に配置)され,フリーノードはアンカーとの関係を表現する適
図
2.4:
アンカーマップ切な位置にスプリングモデルでレイアウトされる.エッジはアンカーとフリーノードを直線 で接続する形式で表現される.
アンカーの配置(順番)はいくつかの美的基準を満たすように行われる.
•
エッジの総線長を最も短くする•
エッジの交差数を最も少なくする•
同じフリーノードに接続するアンカーを近くに配置する図
2.4
は,購入者をアンカー,商品をフリーノードとしてアンカーマップで描画した図であ る.「紅茶はグラフの中心に配置されているため多くの購買者に買われている」といった,ス リングモデルからは発見が難しい情報を素早く認知することが出来る.現在,数多の2部グラフの表現手法の内,アンカーマップは2部グラフを最も効率的に表 現できる手法の一つと考えられる.
2.6
ネットワーク図における可読性ネットワークを可視化した図は,良い描画をすることは重要であることは第
1
章で述べた.その描画の善し悪しはグラフの可読性に影響する.
先に述べたアンカーマップにおいても,アンカーの配置順により可読性の向上を狙ってい る
[16]
.しかし,ノードの数が増大していくと既存手法のみで対応することは難しい.出力す る画面というものは大きさが限られており,画面を埋め尽くすほどのノードを描画しなけれ ばならないときには,ノードのレイアウトを変更しても読み手は見易いと感じないと予想で きる.また,必要以上に大きい画面や異常なまでに高精細な解像度で出力したところで,こ れもまたグラフの意味を掴むのは用意ではないだろう.では,可読性とは如何なるものなのか.
従来のグラフレイアウト手法において可読性を高めるための指標として設定されているの が美的基準(
Aesthetic Criteria
)である.人間の認知特性に関係する様々な基準が定義されて いる.•
ノードの重なりが少ない•
エッジの重なりが少ない•
隣接関係を持つノードが近くに配置される•
エッジの交差数が少ない•
エッジの総線長が短い•
描画領域が小さい•
エッジの屈折点が少ない•
ノードが一様に分布されている•
構造の階層性を表現する•
構造の対称性を表現するこれらを満たすレイアウトを生成することが望ましいと考えられている.むろんこれらは排 他的な性質を持つわけではなく,競合的な性質を持つ組み合わせや,逆に相乗効果をもたら す組み合わせも存在する.
私は可読性にはいくつかの側面があり,その中でも以下の二つが重要であると考えた.
•
空間構造的な可読性•
意味的な可読性「空間構造的な可読性」は,可視化したグラフの「見易さ」のことを指す.見易さとは,人 間が視覚的に見易いと感じることの指標であり,見た目に「すっきりしている」という抽象的 な感覚のことをここでは定義する.具体的にグラフ描画においては「構成要素(ノード・エッ ジ)が少ない」であったり,「エッジがあまり交差していない」,「ノードが大きい」などのこ とで,空間構造的な可読性が向上すると考える.既存手法のアンカーマップにおいてのアン
表
2.1:
可読性向上手法とその効果(情報を保ったままの手法) (情報を削減する手法)
レイアウト変更など クラスタリングなど
可読性(全体)
⃝ ⃝
構造的な可読性
⃝ ⃝ ◦
意味的な可読性
⃝ △ ↔ ⃝
カーのレイアウトの美的基準に「エッジの交差数を最小にする」というものがあるが,これ はこの可読性を直接的に向上させるものである.
この指標はグラフの自動描画の既存手法で,可読性において一番重要視されてきた点であ ると考える.なぜなら,「見易い」「見難い」はグラフのみならず,広範囲の分野で人間の感覚 に直接効果を及ぼすものであるからである.全く同じ意味を持つ2つの対象があり,見易い ものと見づらいものがあれば,見易いものが良いことは自明の理であり可視化の目的の1つ はまさにそれである.
大規模グラフの空間構造的な可読性においての先行研究のアプローチとしては,高精細描 画とクラスタリングが主なものとしてあげられる.高精細描画は解像度の高い出力を行い,広 大な出力空間を有効に用いてノードを配置することで可読性を向上させようという試みであ る.解像度を高くするため,グラフの規模が増大すれば一つ一つの要素は拡大しなければ目 視できなくなる可能性もある手法である.クラスタリングとは集合分類手法のひとつで,
3.2
にて詳しく述べる.類似した情報を持つノードを1つのノードとして表示する手法をとるこ とで,ノードとエッジの数を減少させてグラフを「すっきり」と描画する.空間構造的な可 読性を向上させるに当たっては,単純であるが極めて効果的な方法であると考えられる.「意味的な可読性」は,可視化したグラフの「読み取り易さ」のことを指す.読み取り易 さとは,読み手がどの程度グラフの意味を掴みやすいと感じるかということである.こちら は,「見易さ」と違い直接視覚に訴えてくることはない.しかし,人間が可視化したグラフを 見る目的はグラフの内容を知ることである.すなわち,内容を取りやすい可視化結果は可読 性の高い可視化結果であると言い換えることも可能である.
先に述べたクラスタリングによるノードの数を減らす手法では,描画したグラフの構造と クラスタリング前の元のグラフの構造とが異なってしまう.すなわち,可読性を確保するた め情報量を犠牲にしているのである.そのため,グラフの構造を正しく理解することが難し くなる危険性がある.
先行研究において,意味的な可読性はあまり重要視されていない.無論,この可読性を向 上させる手法もあるが,多くが空間構造的な可読性を向上した結果の間接作用であり,直接 的に効果を及ぼす既存手法は少ない.グラフの自動描画の可読性においては,見易さは一番 重要なファクターだと考えられる.しかし,意味がとれないように見易くしても本末転倒で ある.
いかなる表現にも共通することだが,「読み手」により解釈が変化するという点も重要で
ある.いかに作り手が一番わかりやすい表現を作成したところで,全世界の人間が一番わか りやすいとは考えない.人間はそれぞれが異なった感覚を持ち認識能力も各々異なるためで ある.画面上に配置されているノードの数がどの程度で適切であると感じるかは人によって 異なる.加えて,その時の目的により欲しい描画は異なる
[17]
.すなわち,可読性の向上を 考える際には「読み手」が読みやすい可視化を考える必要性は常に付きまとう.私は,「空間構造的な可読性」「意味的な可読性」という2つの可読性の向上が大規模グラフ の可読性向上のキーであると考えた.加えて「読み手」各々に最適な出力結果が得られるよ うな表現手法を取り入れることで,更なる可読性の向上が期待できる.次章よりその手法に ついて説明を述べる.
第 3 章 可読性を向上させるためのアプローチ
本章では大規模なネットワークの可読性を向上させる手法を述べる.第
2.6
節で述べた2つ の可読性,「空間構造的な可読性」「意味的な可読性」を向上させることを目的とし,そのアプ ローチとして,グラフの構造をコンピュータで解釈し,その情報が読み手によって効果的に 反映させることが可能な表現手法で対応する.3.1
概要私は大規模な2部グラフの可読性を向上させる描画手法として,「縮退描画手法」と「等類 似度描画手法」を考案した.
可読性向上のためには,第
2.6
節で述べた「空間構造的な可読性」と「意味的な可読性」の 向上が必要であると考える.加えて,読み手の意図に対応した描画状態,つまり読み手の操 作に対応して構造を変更・描画に反映させる手法が可読性向上に繋がると考える.本描画手法を開発するにあたってのコンセプトは以下の二つである.
•
コンピュータで構造を解析し,それを可視化結果に反映させること•
読み手の操作に対応して可視化結果を変更するインタラクションシステムであること まず,グラフの構造を捉えるためにクラスタリングを用いた.描画にはアンカーマップの 拡張表現を用い,読み手に最適な描画状態を与える手法を加えた..本章では,データの解析から描画までの仕組みを述べ,描画手法については次章以降で詳 しく述べる.
3.2
クラスタリングクラスタリングとは、異なる性質のもの同士が混在している集合の中から互いに類似した ものを集めてクラスタを形成することで,集合を分類する手法である
[18]
.一般的にグラフ描画におけるクラスタリングは,論理的に同じ接続構造を持つノードを一 つのノードとして描画する手法として扱われることが多い.しかし,この手法はグラフが大 規模になると効果が低くなる.グラフ全体に対して同じ接続構造をもつノードの割合は減少 すると考えられるためである.無論,対象とするグラフに依り効果に違いはあるが,すべて のグラフに対応することはできないことがわかる.
上記の手法を拡張し,階層型クラスタリングを用いて多階層のクラスタ構造を形成する手 法がある.この手法ではスケーラビリティが高く,どんな大きいグラフでも小さくすること が出来るが,
•
小さくしたことにより情報が欠落する•
クラスタの集約・展開方法が洗練されていない といった問題が残されている.本研究で扱うクラスタリング手法は,ノード間のエッジの接続関係から類似度を計算し,階 層構造のクラスタを生成するものである.ただし,クラスタが2部グラフの2種類の集合を 跨いで形成されることはないようにして,2部グラフの構造を保持するよう注意する.
3.2.1
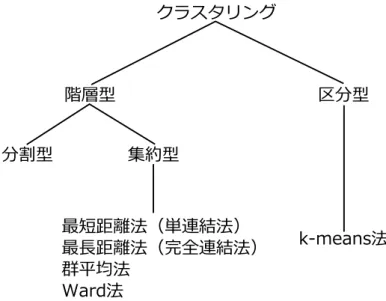
クラスタリング手法の選択クラスタリングの手法は,まず大きく「階層型クラスタリング」と「分割型(区分型)ク ラスタリング」の二つに分けることが出来る(図
3.1
).分割型(区分型)クラスタリングとは,要素全体をいくつかのグループに分割する手法で あり,自己組織化マップの生成などに利用される.代表的な手法に
k-means
法などがあり,あ らかじめ,分割するクラスタの数が分かっている場合には有効な手法である.階層型クラスタリングとは階層構造を成すようにグループを生成するものである.入れ子 を構成するようにクラスタを生成すると考えても良い.
階層型クラスタリングは「分岐型(分割型)」「凝集型(併合型)」に二分される.分岐型は,
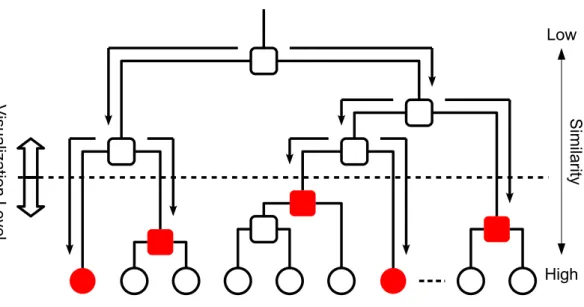
要素集合を1つの大きなクラスタとして考え,クラスタを分割しながら,階層構造を形成し ていく物である.逆に凝集型は1つの要素を1つのクラスタとする初期状態を与え,最も距 離が近い二つのクラスタを逐次的に結合していき,すべての要素が1つのクラスタになるま で階層構造を形成する.両者ともクラスタリングの結果はデンドログラムで表現することが 出来る(図
3.2
).一般的に階層型クラスタリングは集約型の方が多く用いられ,方法論的にも整理されてい る
[19]
.集約型の代表的な手法としてはウォード法などがある.グラフ構造の解析と描画をする上で,スケーラビリティが高いのは階層型クラスタリング である.また,クラスタリングの情報を1つの一貫した軸で扱いたいため,集約型の最短距 離法を用いて開発を行った.詳しい特徴については後述の
3.2.4
節で述べる.3.2.2
ノード間類似度の導出方法クラスタリングを行う際には,要素同士の関連性を表す何らかの指標が必要となる.一般 にその指標は要素間の「距離」や「類似度」,「非類似度」などで定義される.グラフにおい てはノード同士の関連度からクラスタリングを行う.本論文ではこの関連度のことを,ノー ド間の「類似度」という言葉で定義する.本手法では,ノード間の類似度の指標としてジャッ カード係数を採用した.
図
3.1:
クラスタリング手法の分類図
3.2:
デンドログラム図
3.3:
最短距離クラスタリング ジャッカード係数(距離)ジャッカード係数を用いて定義したノード間類似度
S
は,以下のように求められる.ノー ドx
が接続するノードの集合をA(x)
としたとき2つのノードx, y ( ∈ V )
の類似度S(x, y)
は 式(3.1)
で表される.S(x, y) = | A(x) ∩ A(y) |
| A(x) ∪ A(y) | (3.1)
例として,
A(x) = { α, β, γ }
,A(y) = { α, β }
としたとき,S(x, y)
は以下のように算出さ れる.S(x, y) = |{ α, β }|
|{ α, β, γ }|
= 2
3 ≈ 0.66
3.2.3
クラスタの構築最短距離クラスタリングとは,クラスタとクラスタの類似度(距離)を内包する要素でそ れぞれ一番小さいものをクラスタの類似度とする考え方である.
図
3.3
の例に従って,最短距離クラスタリングを説明する.小さい青い円はノードを表して おり,青い円を大きく囲んだ緑色の閉曲線はクラスタを表す.青い円の距離は類似度に比例 しているとする.ここで,Cluster A
とCluster B
の類似度を求めるとしたとき,Cluster A
に 含まれる要素とCluster B
に含まれる要素のペアのうち,一番近いペア(類似度が高いペア)の類似度を,クラスタ間の類似度にする.すなわち,図中の
A
5とB
2の類似度が,Cluster A
と
Cluster B
の間の類似度になる.これを数学的に定義し,構築の方法を以下に述べる.
クラスタ
C
はノードとクラスタの集合であり,以下の式で定義する.C = { c
1, · · · , c
n} (n ≥ 2)
c
1, · · · , c
n∈ V ∪ C
クラスタにおける類似度
S(C)
を以下のように定義する.S(C) = max
1≤i<j≤n
S(c
i, c
j) (c
i, c
j∈ V ∪ C)
式
(3.1)
に加え,類似度S(p, q) (p, q ∈ V ∪ C)
を以下のように定義する.S(p, q) = S(q, p)
可換性S(p, q) =
| A(p) ∩ A(q) |
| A(p) ∪ A(q) | (p, q ∈ V )
∀
max
q′∈qS(p, q
′) (p ∈ V, q ∈ C)
∀p′∈
max
p,∀q′∈qS(p
′, q
′) (p, q ∈ C)
類似度が上記の定義になるようなクラスタを構築する手順を以下に示す.
1. s = max
∀x,∀y∈V2,x̸=y
S(x, y)
となるs
を求める.2. S(x, y) = s
となるノードx
,y
が存在する場合,x ∈ C
x,y ∈ C
yを満たすクラスタC
x,C
yが存在するかを確認する.(a) C
xとC
yが両方存在しない場合,x
とy
を含み,類似度S(C) = s
のクラスタC
を 生成する(図3.4(a)
).(b) C
xが存在し,C
yが存在しない場合,C = G(C
x)
とを満たすクラスタC
を求める(図
3.4(b)
).i. S(C) = s
の場合,C
にy
を加えるii. S(C) > s
の場合,y
とc
を含み,類似度S(C
′) = s
のクラスタC
′を生成する.(c) C
yが存在し,C
xが存在しない場合,2b
のx
とy
を入れ替えて同様の動作を行う(図
3.4(c)
).(d) C
xとC
yが両方存在する場合,C
x′= G(C
xC
y)
とC
y′= G(C
y)
を求める(図3.4(d)
).i. s = S(C
x′) = S(C
y′)
の場合,C
x′ とC
y′ を結合するii. s = S(C
x′)
かつs < S(C
y′)
の場合,C
x′ にC
y′ を加える.iii. s = S(C
y′)
かつs < S(C
x′)
の場合,C
y′ にC
x′ を加える.iv.
それ以外の場合は,C
y′ とC
x′ を含み,類似度S(C) = s
のクラスタC
を生成 する.3. s
であるノードの組み合わせが残っていれば,2
に戻る4. s > 0
の場合,s
より小さい類似度の値中次に大きいものをs
として,2
に戻る(a) (b)
(c) (d)
図
3.4:
クラスタリングの過程G(C)
はC
の最上位の親クラスタで,以下の式で定義する.When C
′⊇ C
′⊇ C G(C) = C
′satisfied S(C
′) = min
∀c′∈C′
S(c
′)
以上を行うことにより,2つのノードの組み合わせの結果から全ノードのクラスタを木構 造で構築していくことが出来る.エッジについては,それぞれの接続ノードを包含するクラ スタにも同様に接続する.
v
1v
2v
3v
4v
1- 0.9 0.8 0.72
v
2- 0.9 0.81
v
3- 0.9
v
4-
表
3.1:
類似度表3.2.4
本手法の特徴このクラスタリングの特徴として,通常の階層型クラスタリングよりも計算速度が速いこ とが挙げられる
[20]
.通常の階層型クラスタリング手法は,1.
すべてのノードの組み合わせの内最も高い類似度の要素を1組探索し,クラスタとして 結合させる2.
残りのノードの集合と生成されたクラスタの類似度を再計算を繰り返し,階層構造を形成していく.それと比較し,本手法は類似度の計算は1回で良い ので,類似度計算自体のオーダは
O(n
2)
にとどめることが出来る.加えて,類似度の情報が 絶対値で与えられることも特徴である.通常のクラスタリングは,類似度が高い要素ごとに クラスタリングを行うため,後にクラスタリングした要素の類似度がその前にクラスタリン グした要素の類似度よりも高いか低いかは不明である.後に述べる描画手法ではこの類似度 の絶対性が有効に働く.もう一つの特徴は,ノードの並び順(クラスタの結合順序)によりクラスタリング結果 が変わらない一貫性である
[19]
.例として,4
つのノードv
1, · · · , v
4 の接続ノードの集合A(v
1), · · · , A(v
4)
をA(v
1) = { 2, 3, 4, · · · , 10 } A(v
2) = { 1, 2, 3, · · · , 10 } A(v
3) = { 1, 2, 3, · · · , 9 } A(v
4) = { 0, 1, 2, · · · , 9 }
として,類似度を計算した結果を表3.1
に示す.ここで,類似度が
0.9
のものが3
つあるが,結合する順番はノードの並び順に依る.すなわ ち,v
1-v
2,v
2-v
3,v
3-v
4のどれを始めにクラスタとするかである.それぞれを最初にクラス タリングを行い,全ノードをクラスタリングした場合の結果をデンドログラムとして表した のが,図3.2.4
である.v
1-v
2とv
2-v
3は論理的に同じ構造であるが,v
3-v
4は他二つとは異な る構造になる.本論文のクラスタリング手法でこれらノード集合のクラスタリングを行うと,どの順番で 行っても,
v
1〜v
4は類似度0.9
のクラスタで結合され,結果の一貫性が保たれる.通常のク(a)v1–v2 (b)v2–v3 (c)v3–v4
図
3.5:
クラスタリング順による変化ラスタリングよりも高い類似度で結合されるクラスタが多くはなるが,可読性は変わらない と考える.また,後から形成されたクラスタが,以前に形成したクラスタよりも類似度が高 い状態になる「反転現象」とよばれる歪みも発生しない.順序依存性と反転現象の影響を受 けない階層型クラスタリング手法は,最短距離法のみである.
3.3
描画システム本研究ではクラスタリングを行ったデータを可視化するツールとして,「
GTBC–GraphML Translater for Bipartite Clustering–
」と「ClusterdAnchorViz
」の開発を行った[21]
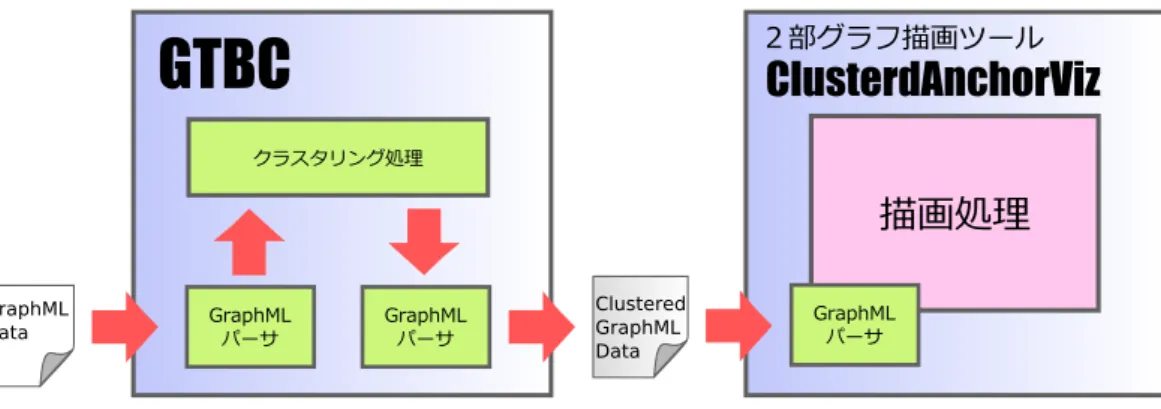
.GTBC
はグラフのクラスタリングツールであり,2部グラフのデータにクラスタリングを 付加する.GTBC
はJava
TM6.0 (Java
TMPlatform, Standard Edition 6 Development Kit
2)
を用 いて製作した.GraphML
3 形式で記述された2部グラフのXML
データファイルを入力とし て,クラスタリングのデータを付加したNestedGraph
のGraphML
形式のXML
を出力する.GraphML
とはグラフをXML
で記述する形式の内の一つであり,多くの可視化研究においても用いられている
[22]
.ClusterdAnchorViz
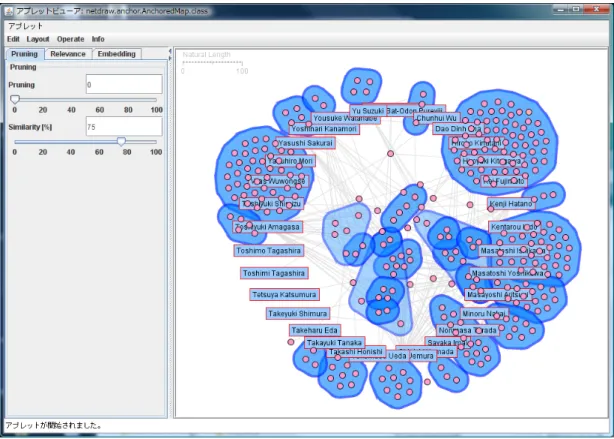
は,クラスタ情報を効率的に可視化する描画機能を備えた2部グラフ描画ツールである(図
3.6
).グラフの描画レイアウトには,アンカーマップ[16]
のレイアウトを 用いている.ClusteredAnchorViz
もJava
TM6.0
を開発言語とし,Applet
として作成している.クラスタリングの情報を用いてのネットワーク描画スタイルは,従来手法ではノードとエッ ジをまとめて表示する手法が一般的である.加えて,そのインタラクションには該当ノード のクリックにより集約と展開を行う手法が多い.これらの手法では,大規模の場合読み手が 要求するネットワーク図にたどり着くまでかなりの作業を要する,似た傾向をもつクラスタ の発見などが困難であるなどの問題がある.
ClusterdAnchorViz
には「縮退描画手法」と「等類似度線描画手法」という二つの描画機能が備わっている.縮退描画手法は,クラスタの類似度情報によって複数のノードを1つのノー ドとして表示させる手法である.等類似度線描画手法は,クラスタに属するノードを閉曲線 描画するスタイルである.集約と展開とは異なる描画スタイルで,要素間の関連性の情報を