動的再構成可能なパイプライン型 アーキテクチャ向け配置配線手法
肥塚 真由子
電気通信大学大学院情報システム学研究科 博士(工学)の学位申請論文
2013 年 3 月
動的再構成可能なパイプライン型 アーキテクチャ向け配置配線手法
博士論文審査委員会
主査 渡辺 俊典 教授
委員 本多 弘樹 教授
委員 吉永 努 教授
委員 古賀 久志 准教授
委員 近藤 正章 准教授
著 作 権 所 有 者
肥 塚 真 由 子
2013
Mayuko Koezuka Abstract
Recently, high-definition and multifunctional mobile computers have been developed.
These battery-powered mobile computers require large processing power with low power consumption and small area. Dynamically Reconfigurable Architecture (DRA) has been proposed to meet these needs in recent years. Compilers for DRA need to map processing operations to DRA. Therefore, we present an algorithm that places and routes process- ing represented by a directed acyclic graph (DAG) in DRA. A typical structure of DRA includes array architecture and pipeline architecture. The pipeline architecture has fewer data paths than the array type architecture, and attracts attention as the architecture which realizes small area and low power consumption.
This paper chooses the pipeline architecture as the target architecture. However, it is difficult to apply placement and routing (P&R) algorithm for the array architectures to pipeline architectures, because the pipeline architecture has low degree of freedom of P&R. Here, Simulated Annealing (SA) is known as the typical P&R algorithm for the array architectures. On the other hand, simple full search algorithm is hard to solve the problem in realistic time, since the computational complexity increases exponentially, as the size of pipeline architecture increases.
Therefore, we propose a P&R algorithm using the pruning method according to data path restriction of the pipeline architecture. This algorithm searches alternately placement and routing for every pipeline stage. The main functions of this algorithm consist of the candidate solution pruning according to data path restriction of the input DAG, the search direction prediction, and the function to remove non-search nodes.
Furthermore, we propose to introduce a complexity index calculated from the input DAG and the target architecture size to enable the prediction of the possibility to discover
by using this prediction, which increases the overall availability of the compiler systems wherein the proposed algorithm works.
In the evaluation, we compare the proposed P&R algorithm with SA in terms of the search time and the rate of the solution discovery. Moreover, we confirmed the effectiveness of the main functions of our algorithm. Then, we evaluated the search time for various sizes of the pipeline architectures to show the scalability of the proposed P&R algorithm.
We concluded that meta-heuristics algorithms like SA are not applicable to the pipeline architecture with severe restrictions and that the proposed algorithm which uses the ar- chitectural restrictions is valid.
肥塚真由子
概要
近年,携帯端末機等における高機能化に伴い,これらの機器向けのLSIに要求される処理能 力が増大している.また,高性能に加え,低消費電力,小面積なアーキテクチャへの要求も高 まっている.これらの要求を満たす解の1つとして,動的再構成可能なアーキテクチャが提 案されている.動的再構成可能なアーキテクチャ向けのコンパイラでは,処理演算をアーキ テクチャにマッピングする技術が必要となる.そこで,本論文では処理を Directed Acyclic
Graph(DAG)で表現されたデータフローグラフに変換し,これを動的再構成可能なアーキテ
クチャに配置配線する手法を提案する.動的再構成可能なアーキテクチャとして,代表的なも のにパイプラン型とアレイ型の2種類があるが,パイプライン型アーキテクチャは,アレイ型 アーキテクチャと比較して配線が少なく,小面積・低消費電力を実現するアーキテクチャとし て注目されている.そこで,本論文ではターゲットアーキテクチャとしてパイプライン型アー キテクチャを採用した.しかしながら,パイプライン型アーキテクチャは配線が少なく配置配 線の自由度が低いため,アレイ型アーキテクチャに適用されている配線自由度の高さを利用し た既存手法(シミュレーテッドアニーリング)を適用することは困難である.また,単純な全 探索手法を導入した場合も,パイプラン型アーキテクチャ規模が大きくなるにつれ探索範囲が 非常に広くなり,計算量が指数関数的に増大し現実的な時間内で解を得るのは困難になる.そ こで,本論文ではパイプライン型アーキテクチャの配線制約による枝刈り手法を用いた配置配 線手法を提案する.これは,パイプライン段毎に演算の配置と配線を交互に探索していく問題 であり,入力DAGの配線制約を用いた探索領域の枝刈り,探索方向予測,探索不要ノード削 除機能を併用している.さらに,入力DAGとターゲットアーキテクチャ規模から算出する複 雑度指標を導入し,探索解発見率や探索時間を予測可能とした.これによって探索の上限時間 設定を可能にし,本方式を含むコンパイラシステム全体の可用性を向上させた.実験評価で は,アレイ型アーキテクチャのマッピング探索で用いられているシミュレーテッドアニーリン グと提案手法において,マッピング探索の実行時間とマッピング探索解の発見率を比較した.
イプラインに適用可能であるかどうかを検証するため,アーキテクチャのパラメータを変化さ せた上で提案手法を適用し,マッピング探索の実行時間の比較を行った.その結果,アーキテ クチャのような配置や配線制約の厳しいアーキテクチャにおいては,シミュレーテッドアニー リングのようなメタヒューリスティクスアルゴリズムを用いることは困難であり,逆に制約に よる探索範囲の削減による提案手法が有効であることが示され,コンパイルフローの可用性向 上が可能となった.
目次
第1章 はじめに 8
1.1 本研究の背景と目的 . . . 8
1.1.1 LSI市場の動向 . . . 8
1.1.2 Dynamically Reconfigurable Architecture (DRA) . . . 9
1.1.3 パイプライン処理 . . . 9
1.1.4 コンパイラ構成 . . . 11
1.1.5 DRAにおけるアプリケーション実装 . . . 12
1.2 関連手法 . . . 16
1.3 DRA構造 . . . 16
1.4 本研究のアプローチ . . . 18
第2章 パイプライン型アーキテクチャとデータフローグラフのモデル化 20 2.1 パイプライン型アーキテクチャ . . . 20
2.1.1 ALU . . . 23
2.1.2 PE Connection (PEC) . . . 23
2.2 データフローグラフ . . . 24
第3章 関連手法の分析 26 3.1 全探索によるマッピング探索手法 . . . 26
3.2 SAによるマッピング探索手法 . . . 28
第4章 提案手法 31 4.1 複雑度指標 . . . 31
4.2 マッピング手法 . . . 34
4.2.1 PreProcess . . . 34
4.2.2 P&R Search . . . 38
4.2.3 Pruning . . . 42
4.2.3.1 Search Nodes Selection . . . 42
4.2.3.2 Search Direction Decision . . . 44
4.2.4 PostProcess . . . 45
第5章 実験評価 46 5.1 全探索アルゴリズム . . . 47
5.2 SA P&R Algorithm . . . 48
5.3 比較評価 . . . 49
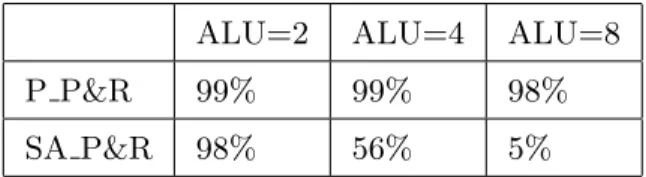
5.3.1 ALU値変動評価. . . 49
5.3.2 PE値変動評価 . . . 54
5.3.3 PEC値変動評価. . . 60
5.3.4 比較評価のまとめ . . . 64
5.4 枝刈り手法評価 . . . 64
5.4.1 Search Nodes Selection評価 . . . 64
5.4.2 Search Direction Decision評価 . . . 70
5.4.3 枝刈り手法評価のまとめ . . . 81
5.5 スケーラビリティ評価 . . . 81
5.5.1 パラメータ変動評価 . . . 82
5.5.2 PE値変動における複雑度評価 . . . 90
5.5.3 スケーラビリティ評価のまとめ . . . 99
5.6 FlexSwordT M コンパイラ運用フローの改良 . . . 100
5.6.1 改良案の概要 . . . 100
5.6.2 P&R累計所要時間の推定手法 . . . 101
5.6.3 フィードバック機構 . . . 103
5.6.3.1 典型的作業シナリオ. . . 103
5.6.3.2 典型的作業シナリオに対する実行時間の推定 . . . 104 5.6.3.3 Feedback CheckerへのP&R実行時間推定グラフの活用法. 108 5.6.3.4 Search Time Checkerへの実行時間推定表の活用法. . . 109
第6章 まとめ 110
謝辞 112
参考文献 113
関連論文の印刷公表の方法及び時期 118
参考論文の印刷公表の方法及び時期 119
図目次
1.1 Dynamically Reconfigurable Architecture (DRA) . . . 9
1.2 FlexSwordTM アーキテクチャ . . . 10
1.3 DRAによるアプリケーション実装 . . . 12
1.4 DRAコンパイラフロー . . . 14
1.5 アレイ型アーキテクチャ . . . 17
1.6 パイプライン型アーキテクチャ . . . 17
2.1 パイプライン型アーキテクチャモデル . . . 21
2.2 PE間接続の配線パターンライブラリ . . . 22
2.3 ALU . . . 23
2.4 DAG . . . 25
4.1 FlexSwordTM コンパイラにおけるフィードバック機構 . . . 33
4.2 PreProcessフロー . . . 35
4.3 PreProcessによるFWDノード追加 . . . 38
4.4 入力DAG . . . 40
4.5 配線パターン(PE3) . . . 41
4.6 ALU位置(PE3) . . . 42
4.7 マッピング結果 . . . 43
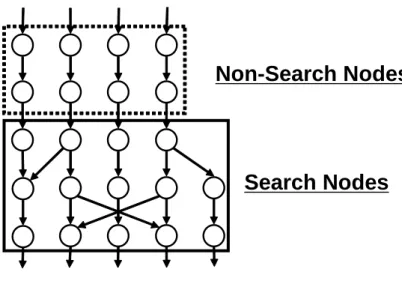
4.8 探索対象ノード,探索非対象ノード . . . 44
4.9 PostProcess : 探索非対象ノードの配置配線 . . . 45
5.1 全探索アルゴリズムと提案手法における探索パターン数比較 . . . 48
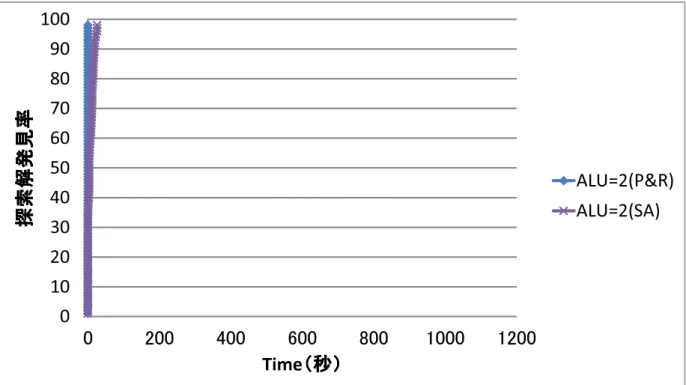
5.2 提案手法とのマッピング解発見率比較(ALU=2) . . . 51
5.3 提案手法とのマッピング解発見率比較(ALU=4) . . . 52
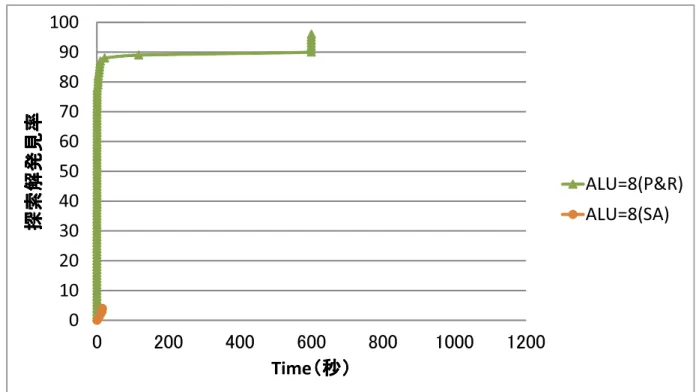
5.4 提案手法とのマッピング解発見率比較(ALU=8) . . . 53
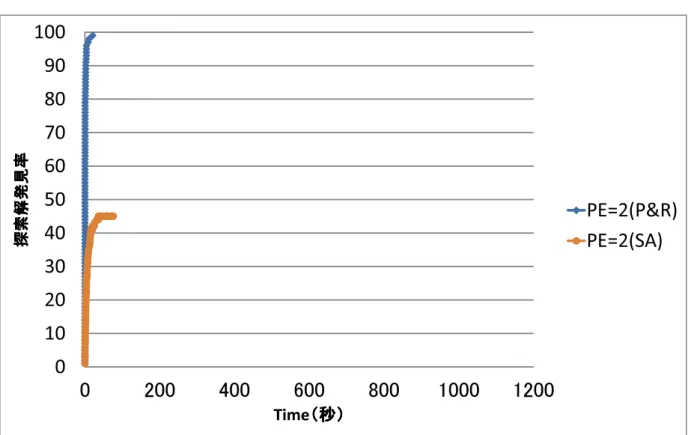
5.5 提案手法とのマッピング解発見率比較(PE=2) . . . 55
5.6 提案手法とのマッピング解発見率比較(PE=4) . . . 56
5.7 提案手法とのマッピング解発見率比較(PE=6) . . . 57
5.8 提案手法とのマッピング解発見率比較(PE=8) . . . 58
5.9 提案手法とのマッピング解発見率比較(PE=10) . . . 59
5.10 提案手法とのマッピング解発見率比較(PEC=2) . . . 61
5.11 提案手法とのマッピング解発見率比較(PEC=4) . . . 62
5.12 提案手法とのマッピング解発見率比較(PEC=8) . . . 63
5.13 Search Nodes Selectionにおける探索解発見率(PE=2) . . . 65
5.14 Search Nodes Selectionにおける探索解発見率(PE=4) . . . 66
5.15 Search Nodes Selectionにおける探索解発見率(PE=6) . . . 67
5.16 Search Nodes Selectionにおける探索解発見率(PE=8) . . . 68
5.17 Search Nodes Selectionにおける探索解発見率(PE=10) . . . 69
5.18 Search Direction Decision機能検証(PE = 2,手法OFF-Bottom-) . . . 71
5.19 Search Direction Decision機能検証(PE = 2,手法OFF-Top-) . . . 72
5.20 Search Direction Decision機能検証(PE = 4,手法OFF-Bottom-) . . . 73
5.21 Search Direction Decision機能検証(PE = 4,手法OFF-Top-) . . . 74
5.22 Search Direction Decision機能検証(PE = 6,手法OFF-Bottom-) . . . 75
5.23 Search Direction Decision機能検証(PE = 6,手法OFF-Top-) . . . 76
5.24 Search Direction Decision機能検証(PE = 8,手法OFF-Bottom-) . . . 77
5.25 Search Direction Decision機能検証(PE = 8,手法OFF-Top-) . . . 78
5.26 Search Direction Decision機能検証(PE = 10,手法OFF-Bottom-) . . 79
5.27 Search Direction Decision機能検証(PE = 10,手法OFF-Top-). . . 80
5.28 ALU数毎のマッピング解発見率 . . . 83
5.29 PE数毎のマッピング解発見率 . . . 84
5.30 PEC数毎のマッピング解発見率 . . . 85
5.31 複雑度検証 (ALU=2) . . . 87
5.32 複雑度検証 (ALU=4) . . . 88
5.33 複雑度検証 (ALU=8) . . . 89
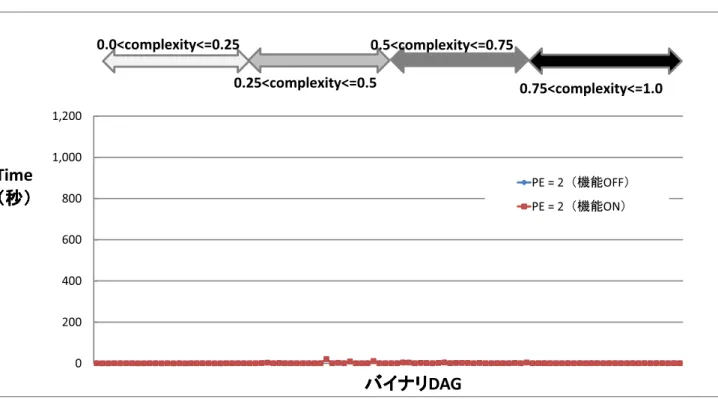
5.34 複雑度検証 (PE=2) . . . 90
5.35 複雑度検証 (PE=4) . . . 91
5.36 複雑度検証 (PE=6) . . . 92
5.37 複雑度検証 (PE=8) . . . 93
5.38 複雑度検証 (PE=10) . . . 94
5.39 複雑度検証 (PEC=2) . . . 95
5.40 複雑度検証 (PEC=4) . . . 96
5.41 複雑度検証 (PEC=8) . . . 97
5.42 複雑度検証 (PEC=16) . . . 98
5.43 複雑度指標を用いたフィードバック機構. . . 101
5.44 複雑度検証 (PE=6) . . . 104
5.45 実行時間(T)毎のP&R累計推定時間(シナリオ1). . . 106
5.46 実行時間(T)毎のP&R累計推定時間(シナリオ2). . . 107
5.47 Feedback Checker活用フロー . . . 108
表目次
5.1 ALU数毎のマッピング解発見率 . . . 50
5.2 PE数毎のマッピング解発見率 . . . 54
5.3 PEC数毎のマッピング解発見率 . . . 60
5.4 枝刈り手法評価 : Search Direction Decision . . . 81
5.5 Search Node SelectionによるPE削減数 . . . 99
5.6 フィードバックによるP&R推定実行時間 . . . 105
第 1 章
はじめに
1.1 本研究の背景と目的
本研究の目的は,近年需要が高まってきている携帯端末機の中心となるLSIの実現である.
携帯端末機ではメディア処理や無線などのアプリケーションが処理され,これはフィルタ処理 やバタフライ演算から成るループ処理形式により実現される.そこで,このような処理に適 合するLSIの開発が必要とされており,適応するLSIとして,Dynamically Reconfigurable
Architecture (DRA) が存在する.DRA を動作させるために実行コードが必要となるが,実
行コードを手動で生成することは困難であるため,DRA 向けのコンパイラが必要となる.コ ンパイラの主要処理の1つとして配置配線手法が必要とされているが,既存手法でのアプロー チが困難であるため,フィルタ処理やバタフライ演算に特化したDRA向けの配置配線につい て,新たな手法の提案が必要とされている.以上の内容について,次節より詳細を述べる.
1.1.1 LSI 市場の動向
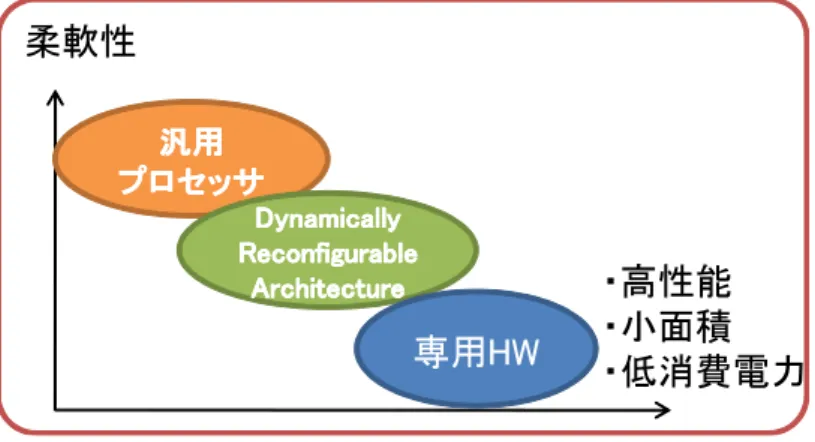
近年,携帯端末機等における高機能化に伴い,これらの機器向けのLSIに要求される処理能 力が増大し,高性能に加え,低消費電力,小面積なアーキテクチャへの要求が高まってきてい る.また,携帯端末機等においてメディア処理や無線などのアプリケーションが用いられてお り,これらのアプリケーションでは規格変更が多く行われるため,柔軟性を持ったアーキテク チャの開発も求められている.既存の汎用プロセッサのみを用いた場合,柔軟性の要求を満た すことができるが,高性能,低消費電力,小面積の要求を満たすことができなくなる.また,
専用ハードウェアを用いれば高性能,低消費電力の要求を満たすことは出来るが,一方で開発 コストの増大,アプリケーションの規格変更等に対する柔軟性に欠け,再利用性が低いという 欠点が浮上する [1].
1.1.2 Dynamically Reconfigurable Architecture (DRA)
これらの問題を解決する方法の1 つとして,図1.1に位置されるDynamically Reconfig- urable Architecture (DRA)が提案されている [2] [3].再構成可能なアーキテクチャとして
汎用 汎用 汎用 汎用 プロセッサ プロセッサ プロセッサ プロセッサ
Dynamically Dynamically Dynamically Dynamically Reconfigurable Reconfigurable Reconfigurable Reconfigurable Architecture ArchitectureArchitecture Architecture
専用HW
・高性能
・小面積
・低消費電力 柔軟性
図1.1 Dynamically Reconfigurable Architecture (DRA)
Field-Programmable Gate Arrays (FPGA) も存在しているが,構成情報のロードにはミリ 秒単位の時間を必要とするため,マイクロ秒単位で構成情報をロードするDRAはより動的な 切り替えに向いていることが分かる [4].さらに,粗粒度DRAの構成情報は,細粒度FPGA の構成情報よりも 1/10-1/100ほど小さいことが知られている [5].このことから,DRA は,
専用ハードウェアに近い演算能力と消費電力を持つ,小面積で柔軟性を持つプログラマブルな アーキテクチャだということがわかる.そこで,本論文では,アプリケーションの規格変更に 依存しにくく,アプリケーションのライフサイクルに依存しないDRAをターゲットとして採 用する.
1.1.3 パイプライン処理
メディア処理や無線等で扱われる処理,特に動画圧縮規格H.264や高速フーリエ変換FFT では,フィルタ処理やバタフライ演算に対する最適化が性能向上に重要であることが知られて
いる.フィルタ処理やバタフライ演算はデータが入力される度に決まった演算処理を行うた め,ループ実行される.同一処理をループ実行する場合,ソフトウェアパイプラインによる最 適化が有効となる.ソフトウェアパイプラインは,複数ステップで構成される処理を並行して 同時に行う処理であり,これにより命令を並列実行することが可能となり,高性能や低消費電 力が実現される.DRAで用いられる構造は,主にアレイ型とパイプライン型の2つが挙げら れる.これらについては後の節で詳細を述べるが,ソフトウェアパイプラインを最適化するに はパイプライン型が有用である.パイプライン型のユニットを保持するDRAの1つとして FlexSwordTM [6]のアーキテクチャを図1.2に示す.
Host Processor
データ用 メモリ
パイプライン型 パイプライン型パイプライン型 パイプライン型
ユニット ユニット ユニット ユニット-0 データ書き込み
データ書き込み データ書き込み データ書き込み
制御部 制御部制御部 制御部
接続インタフェース
ユニット間バッファ ユニット間バッファ ユニット間バッファ ユニット間バッファ 動的再構成可能なユニット
(ユニットごとに独立制御)
コード用 メモリ
パイプライン型 パイプライン型 パイプライン型 パイプライン型
ユニット ユニット ユニット ユニット-1 並列データ型
並列データ型並列データ型 並列データ型
ユニット ユニットユニット ユニット-0 並列データ型
並列データ型 並列データ型 並列データ型
ユニット ユニット ユニット ユニット-1 プログラムコードの流れ
データの流れ
FlexSword
図1.2 FlexSwordTMアーキテクチャ
FlexSwordTM は,Host Processorから接続インタフェースを通じてHost Processorから 処理を指示される.入力データはデータ用メモリから読み込まれ,ユニット間バッファを介し て5つのDRAユニットで処理を行い,再びデータ用メモリに書き戻される.ユニット間バッ ファにより,パイプライン型ユニットや並列データ型ユニットを任意の順序に実行可能になる ため,多くの処理を実行可能となる.また,コード用メモリに5つのDRAユニットの実行時 に必要な構成情報を保持している.
1.1.4 コンパイラ構成
FlexSwordTM などの DRA を動作させるためには実行コードが必要となるが,この実行
コードを手作業で生成することは一般に困難なため,通常コンパイラを用いて生成される.コ ンパイラは,ソースコードを入力として,いくつかのフェーズを経た後にオブジェクトコード
(実行コード)を出力する.フェーズは,「字句解析」,「構文解析」,「中間コード生成」,「コー ド最適化」,「コード生成」の5つのフェーズに分けられる.「字句解析」はプログラムをトー クンに分割するフェーズであり,「構文解析」はトークン間の関係を調べ,データフローグラ フなどの構文木を生成するフェーズである.「中間コード生成」フェーズでは,構文木の意味 を解析し内部的なコードである中間コードが生成される.「コード最適化」では,中間コード を変形することで,効率的なプログラムに変換を行う.最後に,「コード生成」フェーズで,
最適化された中間コードをターゲットアーキテクチャのアセンブリ言語などのオブジェクト コード(実行コード)に変換する.コンパイラの性能とは,効率的な実行コードを出力でき るかどうかであり,これは「コード最適化」での効率的な変換に依存している.「コード最適 化」で代表的な最適化アイテムとして,レジスタ割り当て,命令選択など命令スケジューリン グなどが挙げられる.本論文では,命令スケジューリングに含まれる,配置配線問題について 議論していくが,ここで,命令スケジューリングに関する関連研究について言及しておく.命 令スケジューリングの問題には,命令間に依存のない独立スケジューリングと,別の命令の結 果データを受信しなければ処理を実行できないDAGスケジューリングが存在する.さらに,
スケジューリングの前に全ての命令情報が得られているオフラインスケジューリングと,ス ケジュールをするにしたがって命令の情報が与えられるオンラインスケジューリングの違い が大きい.今回ターゲットアプリケーションとしているストリーミング処理は,命令間に依 存があるためDAG スケジューリングが該当する.また,ターゲットアーキテクチャである DRAは,DRAが事前に構成情報をメモリに保存しておき,実行時に構成情報を呼び出して 動的に構成を切り替えていく構造であるため,オフラインスケジューリングに分類される.オ フラインのDAGスケジューリングで多く用いられている手法はレベルスケジューリングであ り,Mapping Heuristic (MH) [7],Generalized Dynamic Level (GDL) [8],BestImaginary
Level (BIL) [9]の3つである.これらは同一のユニットで構成されるアーキテクチャに対し
て,レベルを定義した上でEarliest Completion Time (ECT) [10]の手法を用いてスケジュー
リングを行っている.ECTは処理が完了する時刻が最も早いユニットに命令を割り当てる 手法である.レベルスケジューリング以外にも多様な手法が提案されている.Clustering for Heterogeneous Processors (CHP) [11]は関連の強い命令同士をクラスタリングしてからクラ スタ単位でマシンに割り当てるが,同一のユニットのみを想定している.また,クリティカ ルパスをできるだけ 1台の速いユニットに割り当てる方針でスケジュールを構成する手法に は Heterogeneous Critical Path Fast Duplication (HCPFD) [12], Bubble Scheduling and Allocation (BSA) [13], Critical-Path-on-a-Processor (CPOP) [14]などがある.ユニットが すべて同一の場合にはクリティカルパスを1つの速いユニットに割り当てるのは自然である が,異種ユニットに対して適用するには限界がある.内部の配置配線も含めた命令スケジュー リングについては,Simulated Annealing (SA) [15]などの一般的な最適化手法を用いた例も あるが,計算量の観点から,ごく小規模な問題にしか適用できない.
1.1.5 DRA におけるアプリケーション実装
DRAでは,図1.3のように,実行コードに従って次々と構成情報を選択し,演算を行う演 算器や演算器間を接続する経路の構成を高速に変更することが可能である.
DRA
アプリケー ション プログラム アプリケー
ション プログラム アプリケー
ション プログラム
構成情報 構成情報 構成情報 構成情報 保存メモリ 保存メモリ 保存メモリ 保存メモリ
I/Oデータ データ データ データ 保存メモリ 保存メモリ 保存メモリ 保存メモリ
データーフローグラフ
(DAG)生成と分割
配置配線 実行順序
構成情報や 実行順序を メモリに保存
DRA構成を動的に 切り替えて実行
DAG
分割結果 構成情報
図1.3 DRAによるアプリケーション実装
アプリケーションプログラムをDRA上に実装する場合,まずアプリケーションプログラム をデーターフローグラフに変換し,これを元に,割り当てたいユニット毎にデーターフローグ ラフを分割する.分割したグラフの実行順序のスケジューリングと共に,分割グラフをDRA の持つユニットの構成に合わせて配置配線を行うことで構成情報が生成される.構成情報はメ モリ上に保存され,DRAの構成を動的に切り替える際に呼び出されることになる.また,入 出力データ(IOデータ)もまた,メモリ上に保存され,DRAの動的構成変換の際に,適宜呼 び出される.このような作業は一般にコンパイラによって行われる.これらステップを手作業 で行った場合,開発コストが増大してしまうため,DRA向けの構成情報を自動生成するコン パイラが必要となる [16].中でも命令スケジューリングに含まれる配置配線については,アー キテクチャ構成によっては手法が確立されていない場合も多い.本論文でターゲットとするス トリーミング処理を考えた場合,ストリーミング処理は一方向のみのデータ転送で実現できる ため,この処理を実現するためのアーキテクチャは,パイプライン型など必ずしも多くの配線 を必要としない.そのため,命令スケジューリングだけでなく配置配線においても配置配線制 約,命令間の依存関係やメモリ制約が厳しくなり,既存手法の適用は困難となる.
DRA向けのコンパイラを考えるにあたり,その探索空間の大きさが問題となる.大規模な 解空間に対して探索を行う場合,解空間を単純に探索した場合,現実的な時間での解取得は困 難となる.そこで,コンパイルの探索問題を分割することで,探索空間を分割し,実行時間の 短縮を図る必要がある.そのため,コンパイルフローを配置配線問題やスケジューリング問題 などに分割し,現実時間での実行コード生成を実現させる方法が考えられている.一般的に は,プログラム言語をコンパイラ中間言語へと変換するフロントエンド,ハードウェアとソフ トウェアの分割を行うミドルエンド,最後にスケジューリングやマッピングを行うバックエン ドに分割される [17].そこで,実際に設計されているアーキテクチャを用いて,コンパイル 分割の例を説明する.DRA向けのコンパイラでは,同種のユニット群から成る DRA向けの コンパイラと,異種のユニット群から成るDRA 向けのコンパイラが存在する [18].いずれ のコンパイラにおいても,実行コードを生成するためには,大規模な解空間に対して探索を 行う必要があるが,現実的な時間での解取得は困難である [19].特に,異種ユニットから成 るDRAでは,アーキテクチャ構造が異なるユニット内のマッピングやユニット単位でのクラ スタリングとスケジューリングにおいて,同種のユニットで構成されるDRA よりも問題が 複雑になる場合が多い [20].そこで,本論文で対象とするアーキテクチャは,一般的に複雑
とされる異種のユニット群から成る DRAを用いる.異種のユニット群から成るDRA には FlexSwordTM [6],ADRES [21]やMXP5800 [22]などが挙げられる. そこで,DRAで考慮 されるコンパイラの各分割問題について図1.4のコンパイルフロー図について見ていく.
データ依存解析 データ依存解析データ依存解析 データ依存解析 ソースプログラム ソースプログラム ソースプログラム ソースプログラム
データフローグラフ データフローグラフ データフローグラフ データフローグラフ
実行コード 実行コード 実行コード 実行コード クラスタリング クラスタリング クラスタリング クラスタリング
演算・ユニット対応情報 演算・ユニット対応情報演算・ユニット対応情報 演算・ユニット対応情報
配置・配線 配置・配線 配置・配線 配置・配線
構成情報 構成情報構成情報 構成情報
ユニットスケジューリング ユニットスケジューリング ユニットスケジューリング ユニットスケジューリング
add(+) sub(-) mul(*) div(/)
・・・
・・・
・・・
・・・
並列データ型 並列データ型並列データ型 並列データ型
ユニット ユニットユニット ユニット パイプライン型ユニット
パイプライン型ユニット パイプライン型ユニット パイプライン型ユニット
パイプライン型 パイプライン型 パイプライン型 パイプライン型
ユニットユニット ユニットユニット データ書き込み データ書き込み データ書き込み データ書き込み
制御部 制御部制御部 制御部
パイプライン型ユニット パイプライン型ユニットパイプライン型ユニット パイプライン型ユニット
並列データ型ユニット 並列データ型ユニット 並列データ型ユニット 並列データ型ユニット
図1.4 DRAコンパイラフロー
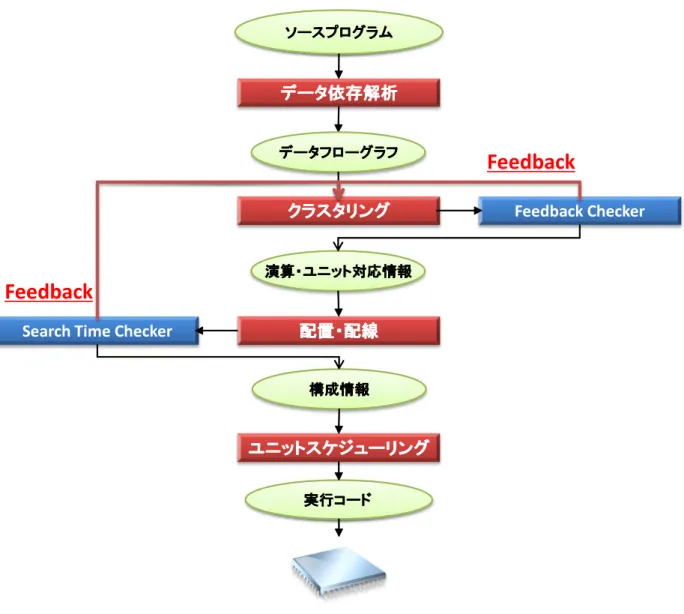
FlexSwordTM でのコンパイラ問題分割は, データ依存解析 , クラスタリング , 配
置・配線 , ユニットスケジューリング の4 つのフェーズから成る.以下で,各フェーズ についての説明を行う.
• データ依存解析
データ依存解析では, 高級プログラミング言語で記述されたソースプログラムを入力 としてデータ依存解析を行い, データフローグラフを生成し,出力する. データフロー グラフは有向グラフであり,ノードが演算を表し,エッジが演算の入出力データの流れ を表現している. データフローグラフの例は図1.4に示されている.
• クラスタリング
クラスタリングは,次に実行される配置・配線フェーズとセットで構成されており,
FlexSwordTM アーキテクチャ制約と性能を考慮し, データフローグラフを適切な演算
ユニットに割り当てるフェーズである. 演算ユニット単位のデータ依存グラフを命令・
ユニット対応情報と呼ぶ. 図1.4に命令・ユニット対応情報の例が示されている.
• 配置・配線
配置・配線では,各演算ユニット単位に分割されたデータフローグラフ内の演算をアー キテクチャ制約を考慮して配置・配線するフェーズである. そして,配置・配線可否判定 と,配置配線等のアーキテクチャ構成情報を生成する. アーキテクチャ構成情報は構成 情報と呼ばれ,図1.4に例が示されている.
• ユニットスケジューリング
ユニットスケジューリングでは,クラスタリングフェーズで生成される演算・ユニット 対応情報から得られたユニット単位でのデータフローグラフのスケジューリングを行 う. 最終的には,ユニットレベルのスケジューリング結果と配置・配線によって得られ た構成情報より,DRAの実行コードが生成される.
そこで,本論文では,性能や探索時間に大きく影響する配置・配線(Placement & Routing : P&R)について注目する.
1.2 関連手法
Placement & Routing (P&R) 手法における既存手法について述べる.代表的な既存手 法として,全探索アルゴリズムを用いた P&R 手法と Genetic Algorithm (GA) [23] [24], Simulated Annealing (SA) [15],タブーサーチ [25]やメトロポリス法[26]に代表されるメタ ヒューリスティクスアルゴリズムを用いたP&R手法が挙げられる.
全探索アルゴリズムを用いたP&R手法は,網羅的に全ての配置は全パターンを探索する手 法であり,探索解が存在する場合は必ず解を発見できるという特徴を持つ.しかし,配置配線 パターンが多い場合には,探索パターンが増大し,現実時間での解発見が困難となるという欠 点を持つ.
一方で,メタヒューリスティクスアルゴリズムにおけるP&R手法として最もよく用いられ るSAでは,ランダムに生成した配置配線パターンから近傍解を次々に探索していく手法であ る.メタヒューリスティクスアルゴリズムを用いたP&R手法では,配置配線制約が少ない場 合に,配置配線パターンが多い場合でも短時間で解を発見できる可能性を持つが,全探索と比 較すると,必ずしも解を発見できる保障が無いという欠点を持つ.
DRAユニットにおける配置配線を考える場合,DRAユニットの構造によって最適なP&R 手法というのは異なるため,次節にて良く用いられるDRA構造の考察と,本論文で対象とす るDRA構造の決定を行う.
1.3 DRA 構造
P&Rを解決するための新たなマッピング探索手法を提案するにあたり,ターゲットとする
アーキテクチャの構造を選定する.DRAが用いる構造は,主にアレイ型とパイプライン型の 2つが挙げられる [18].アレイ型DRA(以後,アレイ型アーキテクチャとする)は,図1.5 のように演算器がアレイ状に配置され,隣接する演算器が双方向に接続されている.パイプラ イン型DRA(以後,パイプライン型アーキテクチャとする)は,図1.6のように演算器が 1 方向に接続されている.一般的なDRAとしてはアレイ型アーキテクチャが多く用いられてお り,データが全てのノードに到達可能な配線構造であるため,マッピングの自由度が高いとい う特徴を持つ.一方,パイプラン型アーキテクチャはデータの流れが1方向であるパイプラ
イン処理に特化させるため,データが全てのノードに到達可能でない配線構造を持っており,
PipeRench [27], KC256 [28], SANYOアーキテクチャ [29], FlexSwordTM [6]などで採用さ れている.ただし,データが全てのノードに到達可能でないため,マッピングの自由度が低い という特徴を持つ.以上より,アレイ型アーキテクチャはマッピング自由度が高く多様なアプ リケーションに対応可能であるが配線数が多く面積が増大する傾向にあり,パイプライン型 アーキテクチャはマッピング自由度はやや下がり,対応可能なアプリケーションをストリーム 処理に限定する必要があるが,配線数を削減することが可能となることがわかる [28].このよ うなDRA構造の特徴を踏まえた上で,既存のP&R手法が適用可能かどうかを確認する.
図1.5 アレイ型アーキテクチャ 図1.6 パイプライン型アーキテクチャ
まず,アレイ型DRAにおいて全探索アルゴリズムを用いたP&R手法を適用した場合を考 える.この場合,配置配線制約を考えずに全ての配置配線パターンを探索してしまい,探索時 間が膨大となり現実時間内での探索終了は困難となる.そのため,アレイ型DRA において 全探索アルゴリズムを用いたP&R手法の適用は困難であることが分かる.アレイ型DRAに
SAを用いたP&R手法を適用した場合,アレイ型DRAのマッピング自由度の高さを利用し,
効率的に配置配線パターンを探索することが可能となる.そのため,アレイ型DRAにSAを
用いたP&R 手法の適用は可能であり,既にADRES向けコンパイラであるDRESCで適用
されている [30].
次に,パイプライン型 DRA における P&R 手法の適用について考える.PipeRench や
KC256などのパイプライン型DRA では,パイプライン間のフルクロスバーと呼ばれる全て
の演算器へのデータ転送が可能な配線構造を持ち,配線数を多く持つためパイプライン型アー キテクチャの中ではマッピング自由度が高いという特徴を持つ.この場合,配線制約が無い
ため,コンパイラは配置のみを考慮すれば良いので,マッピング問題は容易に解くことがで きる [31].一方で,配線制約が非常に厳しいSANYOアーキテクチャ [29]では,配置配線パ ターンが全探索で網羅できる範囲に収まっているため,全探索手法の適用が可能となる.しか
し, FlexSwordTM [6]などのフルクロスバーよりも配線が少ないが,全探索では現実時間内
で探索が完了しないようなパイプライン型DRAでは,配置配線制約が多いため,SA を用い
たP&R手法を単純に適用しただけでは機能しない事が分かる.
本論文では小面積なターゲットアーキテクチャを目標としていることから,パイプライン間 の配線がフルクロスバーでなく,配線が削減されているパイプライン型DRA が最適と考え る.また,配線が削減されているパイプライン型アーキテクチャでは,配線空間が削減できる とともに,構成情報を保持するメモリ面積の削減も可能となる.しかし,上記の考察より,パ イプライン型DRAに既存へのP&R手法の適用は困難であることが分かった.そこで本論文 では,ユニット数が多く,パイプライン型ユニットを持つFlexSwordTMを元に,パイプライ ン型DRAをターゲットとするマッピング探索問題を考える.
1.4 本研究のアプローチ
パイプラン型のマッピング探索問題では,有限パイプライン段数条件のもとで,目標とする 所定の演算を実現する必要から,マッピング探索を行う前にパイプラン段数に合わせて処理を 分割するクラスタリングを行う必要がある.性能向上のため,演算の充填率を上げたクラスタ リングを行う必要があるが,配線制約のあるパイプライン型アーキテクチャでは必ずしもマッ ピング可能性が上がらないという問題が生じる.そこで,マッピングに失敗した場合は,演算 の充填率を下げたクラスタリング結果を生成する必要がある.そこで,クラスタリングとマッ ピングを再試行するフィードバックが導入される [32] [33] [34].
これにより,クラスタリングは再度処理分割パターンを生成することができ,マッピング探 索解が得られた処理分割パターンの中から最も性能の良い結果を得ることになる.また,1回 のマッピング探索時間を短縮することができれば,試行できる分割処理のパターンが増えるた め,分割した処理を高速にマッピング探索する手法が必要とされている.しかし,マッピング 自由度の低いパイプライン型アーキテクチャにおいても,配線数が少なくマッピングが限定的 になる場合には探索は短時間で完了するが [35],配線が多く多様なマッピングが可能なパイプ
ラン型では探索が長時間となる傾向にある [36].そこで本論文では,アレイ型アーキテクチャ よりも小面積を実現し,配線を多くすることでマッピング可能性を向上させたパイプライン型 アーキテクチャに対しても,より短時間で解が発見可能となるマッピング探索手法を提案す る.このことにより,提案するマッピング探索手法では上記の配線数が少ないケースと多い ケースの両方に対応可能となる.
この新マッピング探索手法を提案するにあたり,ターゲットとするパイプライン型アーキテ クチャのモデルを定義した.モデル化では,様々なパイプライン型アーキテクチャの特徴を表 現可能とするために一般化を行った.また,マッピング探索の入力となるデータフローグラフ の定義も行った.様々なパイプライン型アーキテクチャモデルに対して提案マッピング探索手 法を評価するため,アーキテクチャサイズを基準としたデータフローグラフの複雑度指標を導 入し,コンパイラの高速化を実現するとともに,評価の正当性を示すことが可能となった.こ れらを定義することで,フィードバック機能を持つコンパイラ上で効率的に動作するマッピン グ探索手法を提案することが可能となった.
第2章ではターゲットとするパイプライン型アーキテクチャのモデル化と,マッピング探 索の入力となるデータフローグラフの定義を行う.第3章では関連手法に関する分析を行う.
第4章ではデーターフローグラフの複雑度指標とマッピング探索手法の提案を行う.第5章 では提案手法についてSAとの比較評価と,提案手法の有効性を評価する.さらに,提案手法 がパイプライン型アーキテクチャに汎用的に適用可能かどうかの検証を行い,その上でフィー ドバック機構を導入した新たなコンパイラフローを提案する.最後に第6章でまとめと今後の 課題を述べる.
第 2 章
パイプライン型アーキテクチャと データフローグラフのモデル化
本章では,本論文でターゲットとするパイプライン型アーキテクチャのモデリングを行い,
その後,提案マッピング手法の入力となるデータフローグラフの定義を行う.
2.1 パイプライン型アーキテクチャ
パイプライン型アーキテクチャのモデル化では,様々なタイプのパイプライン型アーキテク チャが実現できるような一般化を行う.そこでは,小面積を実現しながら多様なパイプライン 処理を実現可能なアーキテクチャであるFlexSwordTM をベースとして,様々なパラメータで ある演算器数,パイプラン段数,配線パターン数を設定可能なアーキテクチャを設計する [6].
パイプライン型アーキテクチャにおいて,多くのデータフローグラフを配置配線するために 用いられ,探索時間に影響を与える重要なパラメータとして配線パターン数が挙げられる.こ れは,配線パターン数を増やすことにより様々な位置の演算器にデータを転送することができ るが,一方で配線数が増えることで探索数が増大することを示している.そこで,配線パター ンが複数存在するようなパイプライン型アーキテクチャのモデリングを行う.
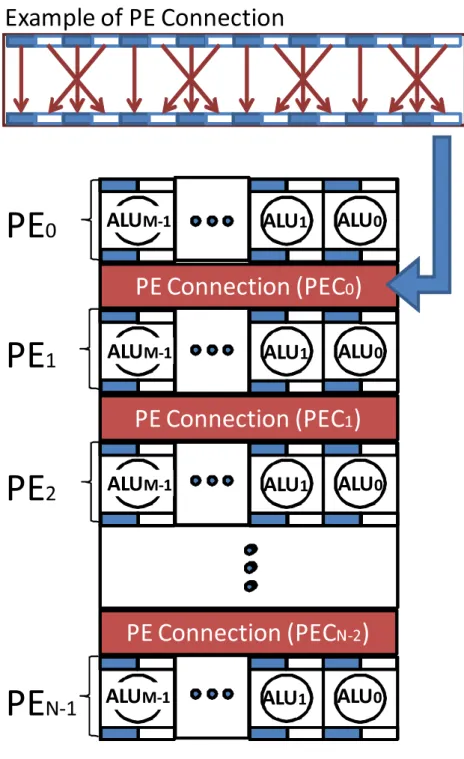
図2.1にモデル化したパイプライン型アーキテクチャの構成を示す.
PE Connection (PEC
0)
PE 0
PE 1
PE 2
PE N-1
ALU
M-1PE Connection (PEC
1)
PE Connection (PEC
N-2)
ALU
0ALU
1ALU
M-1ALU
1ALU
0ALU
M-1ALU
1ALU
0ALU
M-1ALU
1ALU
0Example of PE Connection
図2.1 パイプライン型アーキテクチャモデル
Connection Pattern 0 PE Connection
Connection Pattern 1
Connection Pattern 2
Connection Pattern 3
図2.2 PE間接続の配線パターンライブラリ
提案するパイプライン型アーキテクチャモデルは, N 個のProcessing Element (PE)とPE 間をデータ転送を行うN −1個のPE Connection (PEC) から成る. P E0 からデータを入 力し,最終的にP EN−1 から演算結果を出力する. 各PE はM個の ALUで構成されており, P Ei を構成する各ALUは,P ECi から2つのデータを入力し,同一の演算結果をP ECi+1
に2出力する.
以下で,各PEを構成してるALUとPECの詳細について述べる.
2.1.1 ALU
主な演算は2入力が多いことから,2入力の演算器でALUを図2.3のようにモデル化する.
さらに,出力結果も 2出力とすることで,全ての出力結果を次の段のいずれかの ALUの入 力とすることができる.また,各ALUは別に定義された演算集合の任意のものを実行可能で ある.
ALU
IN
AIN
BOUT
AOUT
B図2.3 ALU
2.1.2 PE Connection (PEC)
PE Connection (PEC)は隣接するPE間のデータ転送に用いられ, 各ALU出力データの 配置変更を行う機構である.PECはハードウェア設計時にあらかじめ決められた複数個の配 線パターンのセットを有し,実行時には必要に応じてどれか一つを動的に選択可能である.例 えば図2.2 のようにP Ei のALUからP Ei+1 のALUへとデータを転送する様々な配線パ
ターン (Connection Pattern)として,上下段のALUがそれぞれ2入力2出力でデータ入出
力可能な4種類の配線パターン (Connection Pattern)が用意されており,各PEC は独立に これらのパターンのうちの1つを動的に選択可能な構造をとる. なお,配線パターンの種類は 任意に決定可能である.種類を少なくすれば小面積となるが配置配線の自由度は下がる.一方 で,配線パターンの種類を多くした場合,面積は配線の分だけ大きくなるが,配置配線の自由 度は上がることになる.ただし,配線を選択可能とすることで配線制約が厳しくなり,配線不 可能となるケースも存在することに注意したい.なお,各配線パターンはALUが2入力2出 力の条件を満足していなければならない.つまり,全ての配線パターンはP Ei−1 のALU出 力が2出力となり,P EiにおけるALUが2入力2出力となり,P Ei+1のALUが2入力とな るような配線でなければならない.
2.2 データフローグラフ
本論文で提案する手法は,データフローグラフを入力とし,前節でモデル化したパイプライ ン型アーキテクチャにマッピングすることを目的としている. 最初に,提案手法で使用する データフローグラフの定義を行う.
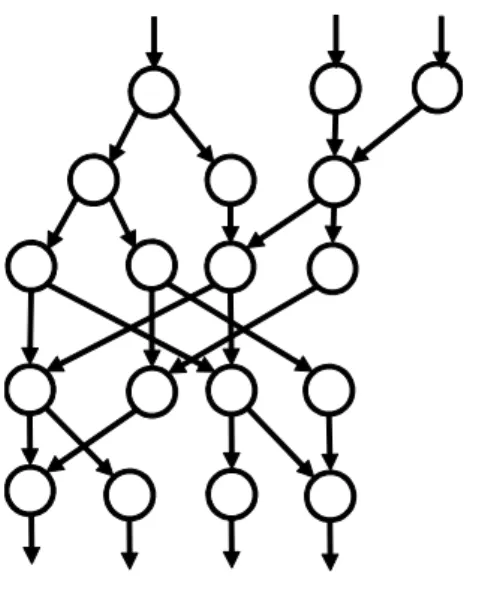
提案手法のターゲットであるパイプライン型アーキテクチャモデルのループを持たない構造 であることから,データフローグラフはDirected Acyclic Graph (DAG : ループなし有向グ ラフ)を採用した.DAGは,ノードが演算を表し,エッジがデータ依存関係を表現している. さらに,ALUが2入力2出力であることから,バイナリグラフを形成する.これらの条件を 満たすDAGを,提案手法の入力とする.
G はノードの集合 V とノードを接続しているエッジの集合 E の 2 つの要素で構成さ れるグラフを示している.ノードの集合 V は,P athi,vj で構成され,これは入力からの パス長が i の j 番目のノードを表している.そのため,i と j は,i ∈ {0,1, ..., N − 1}, j ∈ {0,1, ..., M −1}となる.また,エッジの集合Eは(P athk,vl, P athk+1,vm)で構成され,
これは P athk,vl が入力ノード,P athk+1,vm を出力ノードとしたエッジを示している.つま り,k は,k ∈ {0,1, ..., N −2},l, mは,l, m ∈ {0,1, ..., M −1}となる.さらに,ALUは 2入力2出力であるため,バイナリツリーを形成し,同一パス長のノードは各PEのALU数 であるM以下とし,クリティカルパス長はパイプライン段数であるN以下とする.これらの 条件を満たすDAGを提案アルゴリズムの入力とする.図2.4はPEの数がN = 5段,ALU
の数がM = 8の場合のDAGの例である.
図2.4 DAG
以上のように定義されたDAGのノードとエッジを,それぞれパイプライン型アーキテク チャの演算器(ALU)と配線へとマッピングされる.
第 3 章
関連手法の分析
本章では,DAGの特徴とパイプライン型アーキテクチャモデルの特徴を踏まえて,既存手 法である全探索アルゴリズム [37]とシミュレーテッドアニーリング(SA)に代表されるメタ ヒューリスティクスアルゴリズム [38] [39] [40] [41]のマッピング探索問題への適用可能性を 考える.
まず,従来手法をアレイ型アーキテクチャ向けのマッピングアルゴリズムとパイプライン型 アーキテクチャ向けのマッピングアルゴリズムに分けて考える.
アレイ型アーキテクチャは,そのマッピング自由度の高さから,SA などのメタヒューリス ティクスアルゴリムが良く用いられているが,探索空間が膨大なため,全探索手法などの網羅 的な手法は探索時間が長くなるために採用されない [21] [30].一方で,パイプライン型アーキ テクチャ向けのマッピングアルゴリズムには,全探索手法が用いられている [29].これは従来 提案されているパイプライン型アーキテクチャよりも配線数が非常に限られており,探索空間 が小さいためである.そこで,配線数の多いパイプライン型アーキテクチャに対して,全探索 によるマッピング探索手法や,アレイ型で用いられているSAによるマッピング探索手法が適 用可能かどうかの検討を行う.
3.1 全探索によるマッピング探索手法
全探索手法を用いてマッピングを行った場合,実装が容易であり,全てのマッピング探索解 を探索できるという利点があるが,探索範囲の広さはターゲットアーキテクチャに依存する.
配線数の少ないパイプライン型アーキテクチャに対しては全探索アルゴリズムが用いられてき たが,本論文で対象とするマッピング探索数の多いパイプライン型アーキテクチャでは,全探 索による現実的な時間内でのマッピング探索は困難となる [27] [42] [43] [44].
全探索手法をマッピング探索に適用したアルゴリズムを次に示す.
Full Search Algorithm
Begin
for N odeP lacementP attern= 1 to M∗NPVnum
if set N odeP lacement(N odeP lacementP attern) then for P EConnectionP attern= 1 to ST
if set P EConnection(P EConnectionP attern) then return P lacement
return false End
M は各PE 内のALU数,N はPE 数,Vnum はDAG におけるノード数,S は各PEC で実現可能な配線パターン数,T はPEC 数を示している.M∗NPVnum は,配置パターン数 の総数を表しており,set N odeP lacement(N odeP lacementP attern)ではパイプライン型 アーキテクチャにノード配置する関数である.ST は,配置パターン数の総数を表しており,
set P EConnection(P EConnectionP attern)ではパイプライン型アーキテクチャの配線を 決定する関数である.これにより,全ての配置配線の組み合わせをチェックすることができる.
さらに,式 (3.1) にパイプライン型アーキテクチャの規模を考慮したマッピング探索数 P attern numを示す.
P attern num=M∗N PVnum ∗ST (3.1) M は各PE内のALU数,N はPE数,VnumはDAGにおけるノード数,Sは各PECで実 現可能な配線パターン数,T はPEC数を示している.M∗NPVnum とST は,それぞれアーキ テクチャ全体における配置パターン数と配線パターン数を表している.これらをかけ合わせる ことにより,アークテクチャ全体でのマッピング探索数P attern numを得ることができる.
式(3.1)で算出されたマッピング探索数に対して,マッピング可能な解が非常に少ないことか ら,マッピング探索の時間は年単位となる可能性もある.これは,マッピング探索解の探索時
間が,M, N, Sなどの値が増えると,指数関数的に増大することからわかる.実際に,配線パ
ターン数がS = 1であるような配線パターン数の少ないパイプライン型アーキテクチャを考 えた場合,マッピング探索数P attern num=M∗N PVnum∗1となる.一方で,FlexSwordTM のような配線パターン数の多いパイプライン型アーキテクチャでは,S = 8,T = 4となり,
マッピング探索数P attern num=M∗N PVnum ∗4096より配線に関する要素のみでもマッピ ング探索数に大きな影響を与えることがわかる.
以上の分析により,配線数の多いパイプライン型アーキテクチャや規模の大きいパイプラン 型アーキテクチャでは,マッピング探索数が増大し現実時間内に探索が完了しないと考えられ る.そこで,アレイ型アーキテクチャでよく用いられているSAを用いたマッピング探索手法 についても分析を行う.
3.2 SA によるマッピング探索手法
SAに代表されるメタヒューリスティクスアルゴリズムは,ランダムに生成したマッピング 探索解とその近似解を繰り返し探索する事で,広い探索範囲に対しても適用可能な手法であ る.DRAとして一般的に用いられているアレイ型アーキテクチャでは,マッピングの自由度 の高さを利用し,SAを用いたマッピング探索が行われている [45] [21] [30].
しかし,本論文で対象とするパイプライン型アーキテクチャモデルでは,演算のマッピング の自由度が低いため,SAを用いた場合に探索時間が増大してしまう問題がある [43].これは 図1.5において任意の2つの演算器間のパスが多数あることと比較して,図1.6の任意の2つ の演算器間のパスはごく少ない,もしくは存在しないことからもわかる.つまり,アレイ型 アーキテクチャは配線がマッピング探索解を発見しやすいのに対して,パイプライン型アーキ テクチャは,マッピング探索解そのものがほとんど存在していない.
SAは,ランダムな解から出発し,より良い解を目指して,その状態の局所近傍を探索するア ルゴリズムである.局所近傍解が,元の解よりも改善されれば,局所近傍解を基本解として置 き換える.基本解とは,次の局所近傍探索のベースとなる解である.局所近傍解が,元の解よ りも改善されなくても,ある確率により,基本解として置き換えられる.この確率は,探索が
進むにつれて,徐々に下がっていく.これにより,探索初期における局所最適解への収束を防 ぐことが可能となる.配置配線アルゴリズムにおいては,DAGのノードの配置探索と,DAG のエッジと配線パターンの探索を同時に行うことは,解がより離散的となり,近傍解を探索し ていくSAアルゴリズムに適さないと判断した.そこで,対象とするパイプライン型アーキテ クチャの全ての PECにおいて,予め配線パターンを固定した上で,DAGの配置探索のみを SAによって行い,解が得られれば終結する.解が得られない場合には上記固定配線パターン を変更して配置配線を繰り返す.なお,パイプライン型アーキテクチャにおける配線パターン の組み合わせは,すべての組み合わせを順に実行していく.
基本となるSAの疑似コードを次に示す.
Simulated Annealing Algorithm
s :=s 0, e :=E(s), s b:=s, e b:=b, k := 0 Begin
while k < kmax and e > emax
s n:=neighbor(s), e n:=E(s n)
if random()< M etropolis(e, e n, temp(k/kmax)) then s:=s n, e:=e n
if e < e b then
s b:=s, e b:=e k :=k+ 1
return s b End
sは基本解である配置配線状態を表し,s 0はランダムに生成されたその初期基本解とする.
配置配線アルゴリズムにおける基本解とは,対象となるパイプライン型アーキテクチャの各演 算器とDAGにおけるノードの対応状態を示している.eはSA におけるエネルギーつまり評 価値を表し,E(s)は基本解sにおける評価値を表している.配置配線アルゴリズムにおける 評価値は,配置されたノード間の配線一致率である.これは,配置配線アルゴリズムが,あら かじめ与えられた配線に対して DAGの配置探索を行い,与えられた配線とDAG における エッジとの一致率によって解の良し悪しを判断しているためである.これにより,完全に一致
した場合は,評価値0とし,一致率が下がるにつれて評価値が増大するように評価関数を作 成した.s bとe bは,それぞれ得られた最良解とその評価値を表している.k はSAの終了 条件の一つであるステップ数を表しており,kmax が最大ステップ数となる.neighbour(s) は基本解 sの近傍解を返す関数である.配置配線アルゴリズムでは,基本解 sにおいてラン ダムに選択した演算器ノードと隣接する演算器のノードを交換することで近傍解を生成する.
temp(k/kmax)は局所解の置き換えの際に重要な温度パラメータである.配置配線アルゴリ
ズムでは,解のエネルギーが改善されれば1を返し,エネルギーが改善されなければk/kmax を返す.M etoropolis(e, e n, temp(k/kmax))は局所解の置き換えの際に,新しい状態を採用 するか棄却するかの判断基準を与える関数である.配置配線アルゴリズムでは,e < e nの場
合は 1を返し,e ≥ e nの場合はe(e−e n)/temp を返す.この値とランダムに生成した値を比
較することで,局所解の置き換え有無を判断する.
このようなSAによるマッピング探索手法を構築することにより,ベースとしたSAと比較 して高速にマッピング探索解を発見することが可能となる. ただし,SAを考える際に重要と なるパラメータである 総ステップ数kmaxについては,対象とする問題に応じて調整する必 要がある.なお,SAを用いた新たなマッピング探索手法が,パイプライン型アーキテクチャ に適用可能であるかどうかは,第5章実験評価における提案手法との比較によって確認する.
第 4 章
提案手法
本章では,DAGの複雑度指標と,パイプライン型アーキテクチャ向けのマッピング手法に ついての提案を行う.
まず,コンパイラにおけるフィードバック機構の可用性を向上させるための複雑度指標につ いて説明する.
4.1 複雑度指標
複雑度指標の提案では,DAGをパイプライン型アーキテクチャにマッピングするにあたり,
マッピング探索時間が問題となることに注目する.これは,コンパイラにおいてマッピングが 成功しなかった場合にクラスタリングを再実行するというフィードバック機構が含まれるため
である.FlexSwordTM におけるフィードバック機構を,図5.43に示す.クラスタリングで
は,演算・ユニット対応情報を生成することで,データフローグラフにおけるパイプライン型 アーキテクチャへの割当か所をクラスタリングするが,マッピング探索を行った結果,そのク ラスタリングが実現できないケースが発生する.その場合,フィードバック機構を利用して,
再度クラスタリングや配置配線を行う必要が生じる.そこで,事前に配置配線の実行時間を予 測することで,探索の短いクラスタリングを優先的に実行することが可能になると考えた.こ れにより,短い探索時間で多くのフィードバックを実行,もしくは少ないフィードバック回数 で良いマッピング解を得るという効果を得ることができる.以上を踏まえて,マッピング探索 時間がDAGのノード数やエッジ数によって変化することに注目した.これはDAGの規模や
複雑さによって,マッピング探索の困難さが変化する事を示している.DAGの複雑さと実行 時間の関係が明らかになった場合,マッピング時間が短いと予想されるクラスタリング結果か らマッピング探索を実行する事ができ,フィードバック機構を効率的に利用したコンパイラ提 案を行うことが可能となる.さらに,マッピング探索の上限時間設定を行うことでマッピング 時間そのものを短縮できる可能性がある.
以上のことから,DAGの規模や複雑さを,パイプラン型のALU数,配線数とDAGのエッ ジ数,ノード数を用いて表すComplexityという指標を導入した.Complexityの算出方法を 式(4.1)に示す.
Complexity(G) = (Vnum∗Enum)/(ALUSU M ∗EDGESU M) (4.1) Complexity(G)はDAGGのComplexityを表している.VnumはGのノード数,Enumは Gのエッジ数を表しており,図5.43のクラスタリング結果より算出できる.また,ALUSU M はアーキテクチャ全体における ALU 数,EDGESU M はエッジ数の総数を表しており,図 5.43のクラスタリングと配置配線によって算出できる,分子はDAGの規模を表しており,分 母はアーキテクチャの規模を表している.これにより,様々な規模のパイプラン型アーキテク チャのALUと配線に対して,DAG Gのノードとエッジの充填率を得ることができる.充填 率が高いほどマッピング探索領域が増えることから,これを複雑度指標とした.