移動付き編集距離に基づく曖昧検索が可能な圧縮索引
Approximate Query Search Algorithm for Edit Distance with
Moves on Grammar-Based Self Index
中島健太
1∗前田幸司
1高畠嘉将
1坂本比呂志
1Kenta Nakashima
1Koji Maeda
1Yoshimasa Takabatake
1Hiroshi Sakamoto
11
九州工業大学 情報工学府
1
Graduate School of Computer Science and Systems Engineering,
Kyushu Institute of Technology, Japan
Abstract: We propose an approximate query search algorithm for edit distance with moves on grammar compressed text. Edit distance with moves(EDM) is a distance between two strings. EDM is defined as a minimum number of edit operations, including insertion, deletion, replacement and substring moves, to turn one string to the other. It has many applications, for example, biological sequence, suggestion keyword and discovery of plagiarism. A online pattern search for EDM[1] and a query search algorithm for hamming distance[2] exist, but a search algorithm for EDM on grammer compressed text has not been proposed yet. Given a grammar compressed string S, a query Q, and k≥ 0, we consider the problem of finding occurrences of Q′ such that
d(Q, Q′) ≤ k and |Q′| = |Q| with respect to EDM. Our algorithm use ESP-index[7] which is a self-index based on edit-sensitive parsing.
1
はじめに
本稿では,文法圧縮によって圧縮されたデータ上で の移動付き編集距離に基づく曖昧検索を行う.移動付 き編集距離とは挿入・削除・置換・部分文字列移動の 4 つの操作を許した編集距離の一種である.移動付き編 集距離を用いることで aaabbb と bbbaaa のような通常 の編集距離では距離が離れている類似している文字列 同士を発見することができるようになる.これにより, DNA 配列同士の類似度判定やサジェスト,文書の剽窃 発見等に活用することができる.しかし今まで,オン ラインパターンマッチング [1] やハミング距離による検 索 [2],索引上で編集距離を用いた検索は存在したが, 索引上での移動付き編集距離を用いた検索手法は存在 しなかった.そこで今回,ESP の性質を用いて,領域 2n + n lg n + n lg N + n2lg N + o(n lg n)[bits],時間計 算量 O(q lg lg n(lg∗N + occk(q + lg N )) + nvq) での移 動付き編集距離に基づく曖昧検索手法の提案を行う. ∗連絡先: 九州工業大学大学院 情報工学府 〒 820-8502 福岡県飯塚市川津 680 番 4 E-mail: k [email protected]2
準備
文字列 S の長さを|S|,集合 C の基数を |C| と書く. 文字の有限集合を Σ とおき,Σ の要素からなる文字 列全体の集合を Σ∗と定義する.S[i],S[i,j] をそれぞ れ文字列 S の i 番目の文字と i から j 番目までの部分 文字列とする.本稿中では,対数の表記は lg = log2,lg(1)u = lg u,lg(i+1)u = lg lg(i)u と表記する.また,
lg∗u は lg∗u ={min{i| lg(i)u≤ 1}} を表す.
2.1
文法圧縮
文法圧縮とは,与えられた文字列 S を一意に導出する CFG を構築する圧縮手法である.ある生成規則 X→ α において左の X を変数と呼び,変数の集合を V A(G) と表す.生成規則の集合を辞書 D(G) と呼び,D(G) の 生成規則の数を n とする. このとき CFG G は admissible であり,一意に文字 列を導出することができる.つまり,任意の α∈ (Σ ∪ V A(G))∗において,X→ α ∈ D(G) は高々一つしかな い.また文法圧縮において CFG はチョムスキー標準形 の Straight line program(SLP) に制限するため,生成 規則は右が変数のみの X→ a(a ∈ Σ) もしくは 2 つの人工知能学会研究会資料 SIG-FPAI-B404-07
変数からなる Xk → XiXj (1≤ i, j < k ≤ |V A(G)|) のいずれかとなる.また,Xi, Xjを以下で述べる構文 木の左辺,右辺と呼ぶ. この生成規則の集合を木構造で表現したものを構文 木と呼ぶ.図 1 は文字列 aabbabab に対する CFG の一 例である. 構文木における展開長とは,そのノードから生成規則 を用いて復元できる文字列の長さのことである.図 1 では例えばノード A の展開長は 2,ノード D では 4 と なる.次に構文木における隣接関係について定義する. まず,最右先祖を以下のように定義する. 定義 2.1 ノード A から右辺を 0 回以上辿り,その後 左辺を 1 回だけ辿って到達できるノード中でもっとも A に近いノードを A の最右先祖とよぶ. 最右先祖を用いて木の隣接関係を次のように述べる ことが出来る. 定義 2.2 ノード A, B を根とする部分木が構文木中で AB の順で隣接するとは以下の 2 つの条件を満たす X が存在することである. • X は A の最右先祖である. • X の右の子から左辺だけを辿って B に到達可能 である. 図 1 を例にとると,ノード B の最右先祖は F であり 隣接関係にあるノードは C であると分かる. A→ aa B→ bb C→ ab D→ AB E→ CC F → DE 図 1: CFG の例 一般に生成規則数が少なくなるほど圧縮率は高くな るため,繰り返しの多いテキストに対しては効果的に 圧縮を行うことができる.しかし,生成規則数を最小 にする問題は N P− hard であることが証明されており [3],Repair[4] や LCA[5] などの文法圧縮アルゴリズム で近似解を求めるアルゴリズムが提案されている.
2.2
移動付き編集距離 (EDM)
移動付き編集距離とは,ある文字列 S から別の文字 列 T へ変換する際に以下の 4 つの編集操作の最小回数 として定義される文字列間の距離のことである. 1. 挿入操作 文字列の任意の場所に文字を挿入する操作. abcd→ abacd 2. 削除操作 文字列の任意の場所の文字を取り除く操作. abacd→ abad 3. 置換操作 文字列中の任意の場所の文字を別の文字に置き換 える操作. abad→ abcd 4. 部分文字列移動操作 文字列中の部分文字列を別の場所に移動させる操 作. aaaabbbb→ bbbbaaaa 一般に 2 つの文字列間の移動付き編集距離を求め ることは N P − hard であることが知られており [8],Edit senstive parsing(ESP) では移動付き編集距離の
O(lg N lg∗N ) の近似解を求めている.ここで N は文 字列の長さを表す.
2.3
問題定義
ここでは移動付き編集距離に基づく曖昧検索を以下 のように設定する. • 入力 文法圧縮されたテキスト T ,クエリ Q, パラメータ k • 出力 T 中の長さ|Q|,移動付き編集距離 k 以下の部分 文字列2.4
Edit Sensitive Parsing(ESP)
Edit Sensitive Parsing(ESP) とは 2 つの文字列 R,
S の近似移動付き編集距離 d(R, S) を計算するために
提案された文字列の parsing algorithm である. 2.2 で述べたように,文字列間の移動付き編集距離を求 めることは困難な為,ESP を用いた距離計算では近似 解を求めることで計算を行っている.
2.4.1 ESP algorithm ESP では長さ N の文字列 S から ESP 木と呼ばれる 構文木を構築する.[6] この木は全 2 分木として表現で きる.[7] S を以下の 3 つの Type の部分文字列の列と みなして長さ 2 または 3 文字毎に分割を行う. Type1 長さが 2 以上の同一文字による連続文字列. Type2 同一文字による連続文字列を含まない,長さ lg∗N を超える文字列. Type3 Type1,Type2 共に当てはまらない文字列.即 ち同一文字による連続文字列を含まない長さ lg∗N 以下の文字列である. Type1,Type3 に関しては左優先で 2 文字ずつをペ アにして置き換えを行っていく.長さが偶数の場合は, XY から ti → XY が,長さ奇数の場合は最後の 3 文字 を XY Z から ti→ Xt′,t′→ Y Z のように 2-2 木を構
築する.Type2 の文字列に関しては alphabet reduction という方法で分割を行っていく.
• alphabet reduction
alphabet reduction は Type2 の文字列を長さ 2 または 3 の部分文字列に分割するための手続き である.Type2 の文字列 S が与えられた時,S[i] ,S[i−1] を 2 進整数として考える.p を S[i],S[i−
1] の下位から見て最初にビットが違うポジション,
bit(p, S[i])∈ {0, 1} を S[i] の p 番目のビット値と
する.p は 0 から数える.
この時,ラベル L[i] を L[i] = 2p + bit(p, S[i]) と 定義する (∀i ≥ 2).S は Type2 の文字列なので 同じ文字の連続を含まない.そのため,S から計 算する新たなラベル列 L = L[2]L[3]…L[|S|] もま た同じラベルの連続は現れない. S に含まれる文字種類数を σ = [S] とおく.この 時,S に対して上の操作を行うと [L] = 2 lg σ に なる.この L に対して [L] ≤ lg∗|S| になるまで 操作を繰り返す. 最終ラベル L∗において下の式 を満たす S[i] を S の landmark と呼ぶ.
L∗[i] > max{L∗[i− 1],L∗[i + 1]} (local max-imum)
L∗[i] < min{L∗[i− 1],L∗[i + 1]} (local mini-mum)
local maximum による landmark の決定後に lo-cal minimum による landmark を決定する.全て の landmark を決定後,landmark となった文字 とその左の文字を優先的にペアにして変数への置 き換えを行う.landmark の決定に関して以下の 定理 2.3 が成り立つ.
補題 2.3 (Cormode and Muthukrishnan [6]) S[i] の最 近接 landmark の決定は左に lg∗|S| + 5 文字,右に 5 文字のみに依存する. この定理により Type2 の同一文字列は出現場所を問 わず,左に lg∗|S| + 5 文字,右に 5 文字を除いて分割 が一致することが言える. 以上の操作を文字列が長さ 1 になるまで繰り返す. ESP による分割の例として図 2 を載せる.図 2 は入力 テキストに対し 1 段 ESP を適用した状態である.文字 列 S = ababababbab に対して ACBDA という新たな 文字列が得られている. 図 2 のように葉を level0 として i 回 ESP を繰り返した 時のノードを level i のノードと呼ぶ.このアルゴリズ ムによって出来た ESP 木を用いることで移動付き編集 距離の近似解である L1距離を求める. L1距離とは以下の式によって定義される 2 つの文字列 R, S 間の距離である. ||V (S)−V (R)||1= ∑ x∈T (S)∪T (R) |V (S)[x]−V (R)[x]| ここで,T (S) を文字列 S から作られる ESP 木 TSの 全ノードの集合とする.V (S) は T (S) の各要素の ESP 木内での出現頻度を保存している特徴ベクトルである. V (S)[x] は V (S) 中の要素 x の ESP 木内での出現回数 を表している.L1距離と移動付き編集距離の関係につ いて,定理 2.4 が成り立つ.
定理 2.4 (Cormode and Muthukrishnan [6]) 文字列
R,S,m = M AX(|R|, |S|) が与えられた時,以下の 式が成り立つ. ||V (S) − V (R)||1= O(lg m lg∗m)d(S, R) 図 2: 文字列 S = ababababbab に対する ESP の分割例
2.5
ESP-index
ESP-index では ESP 木と等価な生成規則の集合を GMR[9] というデータ構造で符号化することで索引を 構築している.[7]ESP-index の索引サイズ,extraction time として定理 2.5,2.6 が成り立つ.extraction とは圧縮データ中の任 意の部分文字列を展開する操作である.
以下の定理では n は変数の数,N は入力テキストの長 さ ,m はパターン長を表している.
定理 2.5 (Yoshimasa Takabatake et al. [7])ESP-index で作られる索引のサイズは n lg N +n lg n+2n+o(n lg n) である.
定理 2.6 (Yoshimasa Takabatake et al. [7])ESP-index での extraction time は O(lg lg n(m + lg N )) である.
ESP-index では以下の操作を O(lg lg n) で行うこと ができる.[7] • parentTS(x) ノード x の親ノードを求める. • leftchildTS(x) ノード x の左の子を求める. • rightchildTS(x) ノード x の右の子を求める. • accessTS(x, j) i を 1≤ i ≤ numx(numxは TS上の x の数) とし た時,TS 上のノード x 全てにアクセスする. • reversesccess(xi, xj) 文字または非終端記号が 2 つ与えられた時,D(G) 内に xk → xixjがあると き xkを返す. よって,以降では圧縮したデータ上での木に対する 操作は全て O(lg lg n) で行っていると考えている.
3
提案手法
ここでは入力テキスト S 中に存在する移動付き編集 距離 k 以下の文字列を全て探す為のデータ構造とアル ゴリズムについて説明する.3.1
データ構造
ここでは提案手法のデータ構造について記述する.提 案手法では,入力テキストに対し ESP 木を ESP-index と同じ手法で符号化し,各ノードに自分以下の部分木 が持つノードの個数を配列として保存する.クエリに ついても同様に木を構築し,その木に出現するノード の個数を保存する.N は入力テキストの長さ,n は内 部変数の数である. 図 3: 提案手法のデータ構造イメージ 定理 3.1 この提案手法で作られるデータ構造のサイズ は 2n + n lg n + n lg N + n2lg N + o(n lg n) である. 証明. このデータ構造のサイズは,入力テキストの索 引構造に 2n + n lg n + n lg N + o(n lg n)[bits] だけの領 域が必要となる.(定理 2.5) これに加えて,各ノー ドに持たせる L1vector を保存する領域が必要になる. このサイズは各ノードに対してノードの個数分配列が 必要となるので領域は n2log N [bits] である. これらを合わせた,2n + n lg n + n lg N + n2lg N + o(n lg n)[bits] がデータ構造のサイズである.3.2
アルゴリズム
上記データ構造を用いて,以下の方法により移動付 き編集距離 k 以下の部分文字列検索を行う.Step1 入力テキスト S から ESP-index を用いて ESP
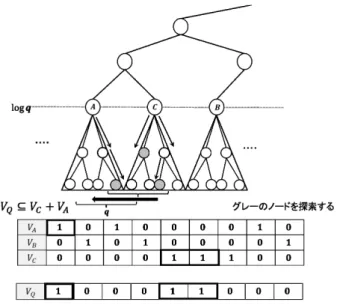
木 TS を構築してから 3.1 のデータ構造で表現 する. Step2 検索クエリ Q から ESP 木を作り, クエリの vector:VQ= (v1, v2, ..., v|VQ|) を計算す る. Step3 Ts内の高さ lg q にある各ノードの vector 中に {v1, v2, ..., v|VQ|} のいずれかが含まれるものを全 て列挙する.この時の列挙したノードの個数を occk Step4 Step3 で列挙したノードを中心として周辺を探 索する. 探索するノードを C,その両隣のノードを A, B とする.この時ノード A, C が,VQ ⊆ VA+ VC を満たす場合,そのノード以下を探索する.探索 は非終端記号が小さい順で行う.探索は図 4 のよ うに展開の合計長が q となるノードの組み合わせ を探していく.q =|Q| である.同じ動作をノー ド C, B に対しても行う.
図 4: Step4 における動作イメージ
Step5 Step4 を Step3 で列挙した全てのノードに対し
て行う.探索の際に,展開長が q かつ L1距離が k 以下のものを展開して解として出力する. 3.2.1 解析 ここでは提案アルゴリズムの計算量について解析を 行う. 定理 3.2 この手法にかかる時間計算量は O(q lg lg n(lg∗N + occk(q + lg N )) + nvq) である. 証明. まずクエリから ESP 木を構築し vector に保存す るのにかかる時間計算量が,O(q lg∗N lg lg n) である. 次にクエリの vectorVQ中の要素を含む Ts中のノード を列挙するためにかかる時間は,O(nvq) である.ただ し,ここでは vq =|VQ| としている. 列挙した各ノードから周辺の L1距離を計算していく ための時間計算量について考える.Step4 の動作にお いて S[i, i + q] の部分文字列は O(lg q) 個の非終端記号 で表現される.よって定理 2.6 から一個の extract に O(lg lg n(q + lg N )) かかる.これを探索するノードを ずらしながら合計 q 個の文字列に対して行う.すなわ ち,O(lg lg n(q(q + lg N ))) である. また,条件を満たしたノードを発見した際にはその 文字列を展開する必要がある.これにかかる時間は, O(q2lg lg n) であり occ k個に対して行われる可能性が ある.よって,O(occkq2lg lg n) である.これらから提 案手法にかかる時間計算量は, (q lg lg n(lg∗N + occk(q + lg N )) + nvq) となる. 定理 3.3 SQ を入力テキスト S 中の長さ q(= |Q|) の 部分文字列とする.この時,文字列 SQ,Q に対して, 提案手法による L1距離と移動付き編集距離との bound は, ||V (SQ)− V (Q)||1= O(lg q lg∗q)d(SQ, Q) である. 証明. 定理 2.4 より ESP から求められる L1距離と移 動付き編集距離との bound は ||V (SQ)− V (Q)||1= O(lg q lg∗q)d(SQ, Q) である. 提案手法では,ESP 木で求められるノードを全て使 って L1距離を求めてはいない.よって,ESP による L1距離の計算とずれが生じる場合がある.SQ, Q は SQ, Q 自身を表す部分木の列として vector で表されて いるとする.この時,Step4 の結果得られる部分木の vector と部分木を展開して得られた部分文字列からでき る ESP 木の vector の差は,ESP 木各 level で O(lg∗q)
個である.よって,最大でも O(lg∗q lg q) である.し たがって,bound は ESP と同じ||V (SQ)− V (Q)||1= O(lg q lg∗q)d(SQ, Q) となる.
4
おわりに
本稿では,ESP-index と ESP の性質を用い,圧縮索 引上で移動付き編集距離 k 以下の部分文字列を検索する アルゴリズムを提案した.時間計算量は (q lg lg n(lg∗N + occk(q + lg N )) + nvq) である.また,領域計算量は 2n + n lg n + n lg N + n2lg n + o(n lg n) である.提案 手法では,全ノードに L1距離を計算するための vector を持たせている為,索引サイズと比べて非常に大きな 領域を使用する必要がある.その為,提案手法では巨 大なテキストに対しては実行ができなくなる可能性が ある.今後は,提案アルゴリズムの実装と実験による 検証,さらに vector の保存方法を変えることで領域の 削減を行っていく.参考文献
[1] Y. Takabatake, Y. Tabei, H. Sakamoto: Online Pattern Matching for String Edit Distance with Moves. SPIRE Volume 8799, 2014, pp 203-214. [2] K. Maeda, Y. Takabatake, Y. Tabei, H.
Sakamoto: Finding Ambiguous Patterns on Grammar Compressed String. In GABA2014. [3] E. Lehman, A. Shelat: Approximation
al-gorithms for grammar-based compression. In
SODA pp. 205–212,(2002)
[4] N.J. Larsson and A. Moffat: Offline Dictionary-Based Compression. In DCC, pp. 296–305(1999)
[5] S. Maruyama, H. Sakamoto, and M. Takeda: An Online Algorithm for Lightweight Grammar-Based Compression. Algorithms Vol. 5,pp.213– 235(2012)
[6] G. Cormode, S. Muthukrishnan: The string edit distance matching problem with moves, ACM
Transactions on Algorithms,Vol. 3 (1) (2007)
[7] Y. Takabatake, Y. Tabei, and H. Sakamoto: Improved ESP-index: a practical self-index for highly repetitive texts, In SEA,pp. 338-350 Copenhagen (DENMARK)(2014)
[8] D. Shapira and J. A. Storer: Edit distance with move operations, In Proceeding of the 13th
Sym-posium on Combinatorial Pattern Matching.
Lec-ture Notes in Computer Science, vol. 2373. 85-98. [9] A. Golynski, J. I. Munro, and S. S. Rao: Rank/select operations on large alphabets:a tool for text indexing. In Proceedings of the 17th
An-nual ACM-SIAM Symposiumon Discrete Algo-rithms, pages 368-373, 2006.