マルチコア CPU 環境における低レイテンシデータストリーム処理 *
上田 高徳
†a)秋岡 明香
†山名 早人
†,††Low Latency Data Stream Processing on Multi-Core CPU Environments
∗Takanori UEDA
†a), Sayaka AKIOKA
†, and Hayato YAMANA
†,††あらまし データストリーム処理のアプリケーションには,アルゴリズム取引やネットワークパケット監視の ように,大容量データストリームを低レイテンシで処理することが必要なものがある.マルチコアCPUを用い た並列処理により大容量ストリームの処理が可能であるが,オペレータごとにスレッドを割り当てると,CPU コア間通信やスレッド待機のオーバヘッドによりレイテンシが増大する.逆にスレッド数が少なすぎては並列性 を生かせず,処理できるデータ量に限界が生じる.本論文では,CPUアーキテクチャやスレッド待機のオーバ ヘッドを考慮し,処理レイテンシを短縮するスレッド割当手法を提案する.マルチコア環境におけるデータスト リーム処理のレイテンシ定義を与え,モデル上で最適なスレッド割当が求まることを示す.更に,入力ストリー ムのデータレート変化に応じてオペレータを再配置する際,ストリーム処理を止めずにタプル適用順序を守って オペレータを再配置する方法を提案する.
キーワード レイテンシ,データストリーム,スケジューリング,マルチコア,ccNUMA
1.
ま え が きセンサ情報やネットワークトラフィックといった,
永続的かつ大量に生成されるデータストリームに対す るリアルタイム処理の需要が高まっている.リアルタ イム性の高いデータは処理結果を得るまでのレイテン シが短いほど情報を有効に活用できる.例えば,アル ゴリズム取引でのレイテンシ競争はマイクロ秒単位 になっており,東京証券取引所の
arrownet
では片道32 μs
程度のレイテンシでデータを提供できることを 謳っている[12]
.また,海外のアルゴリズム取引では5 μs
の差が勝敗を分けるともいわれている[10]
.こうしたデータストリームに対するリアルタイム処 理を実現するために
DSMS
(Data Stream Manage- ment System
)が発展してきた[1], [4]
.DSMS
はデー タが到着すると同時にオンメモリでクエリ処理を実行†早稲田大学,東京都
Waseda University, 3–4–1 Okubo, Shinjuku-ku, Tokyo, 169–
8555 Japan
††国立情報学研究所,東京都
National Institute of Informatics, 2–1–2 Hitotsubashi, Chiyoda-ku, Tokyo, 101–8430 Japan
a) E-mail: [email protected]
*本論文はデータ工学研究専門委員会推薦論文である.
し,リアルタイムに結果を生成する.データストリー ムは永続的に到着するが,演算の対象範囲をウィンド ウにより限定すれば,選択演算や結合演算といった関 係代数演算をサポートすることができ,
SQL
の拡張言 語によってクエリを表現することもできる.DSMS
は 与えられたクエリをプラン木に変換して実行する.プ ラン木の各ノードはオペレータを表し,入力キューと 出力キューをもつ.これらオペレータにどのように計 算リソースを割り当てて実行するかで,処理できるス トリーム量やレイテンシが決まる.冒頭に述べたような低レイテンシ処理の要求を考慮 すると,マイクロ秒単位の処理レイテンシ変化を考慮 して計算リソースを割り当てる必要がある.そして,
大量のデータストリームに対応するためには,マルチ コア
CPU
を活用することが必要になる.しかし,ス トリーム処理の並列化に関する既存研究は処理レイテ ンシの考慮が不十分であると考えられている[11]
.事 実,レイテンシ最小化手法として代表的なChain [3]
は単一コアによる処理を仮定しており,並列処理環境 を対象にしたものでない.マルチコア環境においては コア間通信やスレッド起床のオーバヘッドによるレイ テンシの考慮が必要である.
本論文はまず,
CPU
アーキテクチャやスレッド起床のオーバヘッドを考慮し,マルチコア環境における処 理レイテンシの発生原因について議論する.コア間通 信によって発生するレイテンシを削減するために,可 能な限り少数のコアで処理を実行し,通信経路を制御 すべきであることを示す.そして,データストリーム 処理のレイテンシ定義を与え,動的計画法によりモデ ル上の最適解が求まることを示す.更に,ストリーム の入力データレート変化に応じてオペレータを再配置 する際,ストリーム処理を停止せずに,オペレータへ のタプル適用順を守ってオペレータを再配置する方法 を提案する.
本論文は以下の構成をとる.
2.
で実機アーキテク チャをもとにレイテンシの発生原因を考察する.3.
に おいてデータストリーム処理のレイテンシモデルを与 え,モデル上の最適解が動的計画法で求まることを示 す.4.
においてデータレート変化に応じたオペレータ 再配置方法を述べる.5.
で実験結果を示し,6.
で本 手法が効果を得られる条件について議論する.7.
で関 連研究について述べ,8.
でまとめる.2.
処理レイテンシ発生原因の考察本章では処理レイテンシの発生原因について
CPU
コア間の通信と,処理スレッドのタプル到着待機方法 の二つの面から議論し,処理レイテンシを削減するた めに注意すべき点について述べる.そして,実機にお ける実験によって議論を検証する.2. 1
コア間通信を原因とするレイテンシマ ル チ プ ロ セッサ 環 境 で は
ccNUMA
(cache- coherent Non-Uniform Memory Access
)アーキテ クチャが一般的になっている.Intel Xeon 7500
シ リーズのアーキテクチャダイアグラムを図1
に示し た.CPU
一つはCPU
コアを8
個もち,HT
(Hyper- Threading
)により計16
論理コアとなる.CPU
コア のそれぞれは専用の一次,二次キャッシュをもつ.同 一CPU
内のコアは24 MByte
の三次キャッシュを共 有している.異なるCPU
間はマザーボード上を経由 するQPI
(QuickPath Interconnect
)で接続されて いる.したがって,同一CPU
内のコア間通信が三次 キャッシュ内で完結した場合の通信レイテンシは,異 なるCPU
間でQPI
を経由して通信した場合のレイ テンシより短い.データストリーム処理においてナノ秒やマイクロ秒 単位のレイテンシが問題となる場合,
1 CPU
内で通信 を完結させ,処理能力を超えない範囲で使用コア数を図1 Intel Xeon 7500シリーズダイアグラム[13]を参考 に作成
Fig. 1 Intel Xeon 7500 series diagram [13].
図2 1スレッドで1オペレータを実行 Fig. 2 A thread executes an operator.
図3 1スレッドで複数のオペレータを実行 Fig. 3 A thread executes multiple operators.
削減し,コア間の通信回数も抑えるべきと考えられる.
例えば,図
2
のように1
オペレータに1
スレッドを割 り当てて実行するとパイプライン効果により大きな入 力データレートに対応できると期待できるが,スレッ ドが別々のコアで動作した場合コア間通信の回数が増 え,コア間通信を原因とするレイテンシが多く発生す る.逆に図3
のように1
スレッドが多くのオペレータ を担当すると,コア間の通信回数が減少し,通信レイ テンシを削減できるものの,単位時間当りのストリー ムの入力量,すなわちデータレートが大きくなって計 算負荷が高まった際に,タプルが処理待ちになり,よ りレイテンシが大きくなる可能性がある.このトレー ドオフを鑑み,処理待ちタプルが発生しない範囲でコ ア間の通信レイテンシを最小化することが本論文の目 標の一つである.2. 2
スレッド待機を原因とするレイテンシ コア間通信に加えて,スレッド待機方法もレイテン シに大きな影響を与える.今,毎秒10
万タプルが等 間隔で到着する場合を考えると,10 μs
ごとに1
タプ ルが到着することになる.2 GHz
のCPU
では,10 μs
の間に
2
万クロックに相当する演算が可能であり,タ プルが到着してから次のタプルが到着するまでに処理 が完了した場合,処理スレッドはタプル到着を待たな ければならない.スレッドがタプル到着を待つ場合,スレッドを休止 する方法と,無限ループによりビジーウェイトする方 法がある.休止する場合,タプル到着後に処理を再開 できるよう
OS
のシステムコールを呼び出して待機す る.CPU
時間を節約できることが利点であるが,タ プルが到着した際のスレッド起床によるオーバヘッド でレイテンシが大きくなることが欠点である.一方,OS
に頼らずにソフトウェア側で無限ループによりビ ジーウェイトする方法は,スレッド再開のオーバヘッ ドがないためレイテンシを短縮できる.欠点としてはCPU
リソースを消費すること,消費電力が増加する ことが挙げられる.システムの要求に応じて,スレッ ド休止とビジーウェイトを使い分けることになる.ま た,ビジーウェイトであってもOS
のスケジューラに よりプリエンプションされ,他のプログラムが動作し てしまう可能性があるが本論文では考慮しない.なお
CPU
キャッシュのコヒーレンスプロトコルに より,ビジーウェイト中は読込み対象のメモリ領域が 更新されない限りバス帯域を消費しない.したがって,メモリ読込みのみを行うようにビジーウェイトを設計 すれば他
CPU
コアの処理に影響を与えない.2. 3
実機による検証ここで,実機での実験結果により,本節での議論を検 証する.
1
タプル当り単純な乗算・加算演算を計10
回 実行する仮想的なオペレータ12
個を連結し,タプルが 通過するまでに,120
回の計算を行う処理を表1
の環 境において実行した.オペレータを,図2
や図3
のよ うに各スレッドに割り当て,1
スレッドが担当するオペ レータ数を変化させた.図中のData Source
がタプル を生成してからSink
に到着するまでの時間をレイテ ンシとしてタプルごとに測定し,20
秒間の平均値を求表1 本論文での実験環境 Table 1 Experimental environment.
めた.
Data Source
が生成するタプル量は毎秒10
万 タプルであり,10 μs
ごとに図中のThread 1
へ送ら れ,順次スレッドを通過してSink
まで届く.CPU
速 度と入力データレートを考えると,各スレッドにタプ ルが到着してから,次のタプルが到着する前に演算が 完了すると期待でき,スレッド待機が多く発生する.ス レッド 間 通 信 に 用 い る
FIFO
キュー と し てJava
のjava.util.concurrent
パッケージで提供され るLinkedBlockingQueue
を用いた.ビジーウェイト にはpoll()
を用い,休止して待機する場合にはtake()
を用いた.poll()
はキューのサイズを確認して,空で あればnull
を返す実装となっており,他のコアに影 響を与えないビジーループを実現できる.なお,OS
はオペレータの接続関係を知らないので,単にスレッ ドを生成しただけでは,オペレータが動作するコア を制御できない.これは通信経路を制御できないこ とと同義である.そこで,Linux
のシステムコールで あるsched setaffinity
をJNI
により呼び出し,スレッ ドが動作するCPU
コアを固定して通信経路の制御を 行った.実験結果を図
4
に示した.図4
においてCPU
コ ア非固定の場合はOS
にスレッドスケジューリングを 完全に任せており,どのCPU
コアでスレッドを実行 するか制御していない.一方CPU
コア固定の場合はData Source
,Sink
,全スレッドを同一CPU
内で動 作させ,各スレッドが動作するコアを固定している.使用スレッド数が
6
スレッドまでは1
コアごとに1
ス レッドを動作させた.12
スレッドの場合はHT
機能 の動作に期待し,1
コアで2
スレッドずつを動作させ ている.また,全ての実験でData Source
とSink
は それぞれ単一のコア上で動作させている.図
4
から,最も安定的にレイテンシを短くするに図4 処理レイテンシ実験結果 Fig. 4 Processing latency evaluation.
はビジーウェイトを行った上で,スレッドが動作する
CPU
コアを固定して通信経路を制御するとよいこと が分かる.CPU
コアを固定せずに12
スレッド用いた 場合は処理あふれを起こした.消費電力削減や他のア プリケーションと共存する必要があり,ビジーウェイ トを許容できない場合でも通信経路の制御は必要とい える.また,通過するスレッド数が増えるほどレイテ ンシが延びていることが分かる.したがって,同じ処 理を適用するならば,使用するスレッド数は少ないほ ど低レイテンシで処理をすることができる.しかし,少なすぎると
1
プロセッサ当りの負荷が高まった際に 処理が間に合わずデータ損失が起きることになる.こ のトレードオフを調整してレイテンシを削減すること が本論文の目標である.3.
データストリーム処理におけるレイテ ンシ定義と平均レイテンシ最小化問題 本章では,ここまでの議論をもとにデータストリー ム処理のレイテンシを定義し,本論文の目標の一つで ある平均レイテンシ最小化問題を与える.本論文では 一つのCPU
内に存在するコアへのオペレータ割当と そのCPU
内での通信を議論の対象とし,複数のCPU
への割当やQPI
を経由した通信は対象としない.また コア数は十分に存在するものとする.なお,目標とす る問題は,Diwan
らの論文[6]
におけるAverage Path Length Minimization
を拡張した問題であり,NP
困 難であることが容易にいえる.Diwan
らの論文[6]
は,木構造インデックスのノードをディスクページに配置 する場合に,ディスク
I/O
回数を最小化する配置方法 について議論したものである.3. 1
処理レイテンシの定義と本論文の目標 クエリは図5
のようなプラン木G = (V, E)
で表現 されるとする.ノードv ∈ V
はオペレータを表し,エッジ
e ∈ E
はオペレータの接続関係を表す.各オペ レータは一つ以上の入力エッジとただ一つの出力エッ ジをもつ.オペレータv
はタプルを一つ受け取ると プロセッサリソースをc
v消費して確率θ
outv でタプル あるいはタプル集合を出力する.θ
vout はオペレータv
の選択率である.プラン木G
は一つ以上の入力オペ レータからなる集合V
in と,ただ一つの出力オペレー タv
out をもつ.入力オペレータとはデータソース集 合S
内のデータソース一つからタプルを受け取るオ ペレータであり,出力オペレータはクエリの出力タプ ルを生成するオペレータである.図5 プラン木と平均レイテンシの計算例 Fig. 5 A plan tree and an example of calculation of
average latency.
次に,
CPU
コア集合U
に対して,「各オペレータ をどのコアu ∈ U
で実行するか」を決定するコア割 当戦略π: v → u
を考える.CPU 1
コアがもつ単位 時間当りの処理能力をC
,単位時間当りにオペレー タv
が処理するタプル数をλ
v とすれば,CPU 1
コ アが単位時間当りに処理するタプル数と処理能力の必 要条件として∀ u ∈ U
,{v|π(v)=u}
c
vλ
v≤ C
が得 られる.また,異なるCPU
コアで動作するオペレー タに対してタプルを送信すると,コア間通信によるレ イテンシw
が等しくかかるとする.コア数は十分に あり,QPI
を経由したCPU
間の通信はしないとする.また,本論文ではデータ分割による並列化手法
[11]
は 扱わず,一つのオペレータは必ずただ一つのコアに配 置されるとする.ここで,出力タプルのレイテンシを定義する.今,
あるデータソース
s ∈ S
からの入力タプルα
が入力 オペレータに到着した時刻をt
in(α)
とする.また,出 力オペレータがクエリの出力タプルβ
を生成した時 刻をt
out(β)
とし,タプルβ
の生成に寄与した入力タ プルの集合をe(β)
と書く.ここで,タプルβ
の生成 レイテンシl(β)
を次の式で定義する.l(β) = t
out(β) − max
∀i∈e(β)
t
in(i) (1)
つまり式(1)
は,入力タプルが入力オペレータに到着した後,プラン木を伝搬し,出力オペレータから結 果が出力されるまでの時間を示す.言い換えると,タ プル出力に必要な全データがそろってからタプルを出 力するまでの時間ということになり,システムの即応 性を示す指標になる.同一の計算を行うシステムであ れば,式
(1)
の値が小さいほどレイテンシ性能が良い ことになる.ここで,入力タプルが入力オペレータ
v
in に到着し,出力オペレータ
v
outまでに通過する,L
個のオペレー タからなるパスP (v
in) = v
1, v
2, . . . , v
L,(
v
1= v
in,v
L= v
out)を考える.P (v
in)
は,プラン木が木構造 である限りただ一つに定まる.ここでオペレータは,タプルが到着するとすぐに動作を開始し,処理に専 念できるとする.また,二つ以上の入力キューをもつ オペレータは,それぞれの入力を独立に処理すると し,異なる入力キュー間の待合せはしないとすれば,
パス
P (v
in)
を通って出力されるタプルのレイテンシl(P (v
in))
は次のように書くことができる.l(P (v
in)) =w × { i | π(v
i) =π(v
i+1), 1 ≤ i ≤ L − 1 }
+
v∈P(vin)
c
vC (2)
また,
v
inにタプルが到着した際にP (v
in)
を通って出 力タプルが生成される確率はθ
Pout(vin)
=
v∈P(vin)
θ
outv で求まる.v
in に到着するタプルの全到着タプルに対 する割合をf (v
in)
として,クエリQ
の平均レイテン シl(Q)
を次のように定義する.l(Q) =
vin∈Vin
f(v
in)θ
Pout(vin)
v∈Vin
f(v
)θ
outP(v)l(P (v
in)) (3)
例 え ば 図5
に お い て 考 え る と ,l(Q) = (0.125 × 0.08 × 0.185 + 0.25 × 0.06 × 0.185 + 0.625 × 0.12 × 0.035)/0.1 = 0.0725
となる.以上の平均レイテンシ の定義を用いて本論文が扱う問題を定義できる.平均レイテンシ最小化
CPU
コア割当問題平均レイテンシ
l(Q)
が最小になるようなCPU
コア割当戦略π
OPT を求める.ただし,∀ u ∈ U
,{v|π(v)=u}
c
vλ
v≤ C
で,コア数は十分にあると する.[定理]
平均レイテンシ最小化
CPU
コア割当問題はNP
困 難である.図6 ナップザック問題からのリダクション Fig. 6 Reduction from knapsack problem.
(証明)
容量
C
のナップザック問題を考える.I
個のアイ テムがあり,大きさがS = {s
1, s
2, . . . , s
I}
で価値がL = { l
1, l
2, . . . , l
I}
で与えられるとき,図6
のようにc
vi= s
i/l
i,λ
vi= l
i,f(v
i) = l
ij
l
jであるI
個 の入力オペレータと,c
vout= 0
の仮想的な出力オペ レータを置いたプラン木を構成する.ここでCPU
の 処理能力をC
,∀v ∈ V
,θ
vout= 1
として,平均レイ テンシ最小化CPU
コア割当問題を解くと,出力オペ レータと同一コアに割り当てられた入力オペレータが 明らかにナップザック問題の解を求めている.NP
困 難であるナップザック問題からのリダクションが示せ たから本問題もNP
困難である. ■なお,
∀ v ∈ V (θ
outv= 1, c
vλ
v= 1)
及びw = 1
の場合,CPU
の処理能力C
をページサイズに置き換 えれば,木構造インデックスに対する平均I/O
回数 を最小化するノードマッピング方法を求めるAverage Path Length Minimization
問題[6]
と等価になる.3. 2
動的計画法による求解式
(3)
を最小化するためには式(2)
の第1
項を最小 化すればよい.Average Path Length Minimization
問 題[6]
を 解 く た め の 動 的 計 画 法 を ,∀u ∈ U
,{v|π(v)=u}
c
vλ
v≤ C
の制約を考慮するように初期 値を修正すればπ
OPTを効率良く求めることができる.あるオペレータ
v
にタプルを送信するn
個のオペ レータ(vp
1, vp
2, . . . , vp
n)
のうち,i
番目までのオペ レータを根とする部分木i
個を考える.この部分木i
個 までに含まれるオペレータを考えて,v
と同一のCPU
コアに割り当てられるオペレータが利用するCPU
リ ソースの合計がj
の場合に実現できる,v
を出力オ ペレータと仮定した場合の平均レイテンシの最小値 をS [v, i, j]
とする(図7
).またS
1[v, j] = S[v, n, j]
,S
2[v] = min
1≤j≤CS
1[v, j]
とおく.v
を根とする部分 木がもつ入力オペレータを通ってv
から出力される タプルを考えたとき,v
out からの全出力タプルに対図7 S[v, i, j]の定義 Fig. 7 Definition ofS[v, i, j].
するその割合を
F[v]
とする.入力オペレータ以外の オペレータV
mid= {v | v ∈ V, v / ∈ V
in}
に関してはF [v] =
1≤i≤n
F[vp
i]
と再帰的に計算できる.初期値として入力オペレータ
v ∈ V
in に対してS[v, 0, c
vλ
v] = S
1[v, c
vλ
v] = S
2[v] = F [v]
= f(v)θ
outP(v)v∈Vin
f(v
)θ
outP(v)S[v, 0, j] = S
1[v, j] = ∞ (j = c
vλ
v)
入力オペレータ以外のオペレータ
v ∈ V
mid に対してS[v, 0, c
vλ
v] = 0
S[v, 0, j] = ∞ (j = c
vλ
v)
として以下のように再帰的に定義する.
S[v, i, j] = min(A, B)
A = S
2[vp
i] + F [vp
i] + S [v, i − 1, j]
B = min
1≤m<j
(S
1[vp
i, m] + S [v, i − 1, j − m])
するとπ
OPT の平均レイテンシl(Q)
OPT は次の式で 計算できる.l(Q)
OPT= w × (S
2[v
out] − 1)
+
vin∈Vin
f(v
in)θ
outP(vin)
v∈Vin
f(v
)θ
outP(v)v∈P(vin)
c
vC
(4) c
vλ
v とC
を共に整数で扱うとし,オペレータ数をN
とすれば時間計算量はO(C
2N)
,空間計算量はO(CN)
となる.一般的な動的計画法と同様に,計算結果の表を逆にたどれば,最適なオペレータごとの
CPU
コア割当π
OPTを求めることができる[6]
.以上 で静的なオペレータ配置方法が分かった.次章で動的なオペレータ再配置方法について議論していく.
4.
オペレータ再配置方法と統計情報の取得 本章ではオペレータ再配置方法を検討する.3.
の 方法で静的な最適解が求まるが,実環境でデータスト リーム処理を行う場合には入力ストリームのデータ レート変化や,データ内容変化によってオペレータの 計算負荷が変化する.よって,計算負荷に応じて適応 的にCPU
コアへのオペレータ割当を調整する必要が ある.また,結合演算など内部状態をもつオペレータ においては,タプルの到着順にオペレータを適用する ことが求められる.いかにタプル順序を守りながら低 オーバヘッドでオペレータをCPU
コア間で移動する かが課題となる.なお本研究では,3.
でのコア割当問 題の定義のとおり,CPU
コア数は十分にあるとする.4. 1 Thread Unit
と統計情報の収集動的なオペレータ再配置を実現するためには,統計 情報の取得とオペレータの実行を担うスレッドの確 保が必要である.今,各
CPU
コアにオペレータ実行 用のスレッドを一つずつ固定で割り当てるとし,各ス レッドをThread Unit
と呼ぶ.以下,Thread Unit
をTU
と略す.TU
は通信用FIFO
キューをただ一つも ち,TU
間の通信はこの通信キューを介して行う.TU
が動作するコアは固定であり,キューの入出力のみで 通信すればタプルの通信経路を制御することができる.キューの入力待機にはビジーウェイトを用いる方がよ いが,本論文の手法はスレッドの待機方法によらない ため休止させてもよい.
また,
TU
へのオペレータ割当を決定するスケジュー ラをTU
とは別のコアで動作させる.各TU
はオペ レータを実行してタプルに適用するたびに,オペレー タが使用した合計CPU
時間,入出力タプル数を統計 情報として記録しておく(注1).入出力タプル数からオ ペレータごとの選択率も計算できる.各TU
は収集し た統計情報を一定時間ごとにスケジューラに送信する.送信間隔は,
3. 2
の動的計画法の計算時間の間隔で送 信すれば十分であり,タプルの到着に比べて低頻度で あるから,統計情報送信のオーバヘッドは小さい.動 的計画法の計算時間は5.
で示す.スケジューラは統 計情報に基づいて3. 2
の方法で各オペレータの割当を 計算する.配置が変わった場合には,TU
に指示を出(注1):rdtsc命令を用いることで現在のCPUクロックを低オーバヘッ ドで取得可能であり,オペレータ実行前後のクロック差から,オペレー タ適用に要したCPUクロック数が分かる.
図8 オペレータの移動操作 Fig. 8 Operator movement operation.
し再配置する.なお,クエリの実行初期は統計情報が ないため,十分な数の
TU
を用いて均等にオペレータ を割り当て,統計情報が集まってからオペレータを再 配置する.4. 2
オペレータ再配置方法結合演算など内部状態をもつオペレータにおいては,
タプルの到着順にオペレータを適用することが求めら れる.提案手法では,オペレータ移動の方向に制約を 設けることで,処理を止めずにタプル順序を守って低 オーバヘッドでの再割当を実現する.図
8
を例にTU1
に配置されているオペレータv
を右のTU2
で実行す るように移動する場合を考える.TU2
のキューの中に はv
が出力したタプルがオペレータd
の適用を待っ ている.今,TU1
においてv
の適用を止め,TU2
で 実行するようv
を移動する際に,提案手法ではv
の 移動命令をTU2
のキューに追加する.FIFO
キュー であるから,キューの中にあるタプルはv
が適用済 みで,移動命令以降に到着するタプルはv
が未適用 であることが保証される.一方,TU2
からTU1
にオ ペレータd
を移動する場合にはこのような保証がな く,TU2
のキュー内のタプル全てにd
を適用したあ とキューにタプルが追加されないようロックしてからd
を移動するといった,よりコストの高い同期手順を 実施する必要があり,レイテンシが大きくなる.この ため,提案手法では,オペレータ移動方向をデータ転 送方向に限定することで,オペレータ移動を簡単化し ている.なお,移動するオペレータの内部状態は,移 動先のThread Unit
から共有メモリを介して参照で きる.次に,
4.
のモデルのとおり,オペレータ間の通信回 数を1
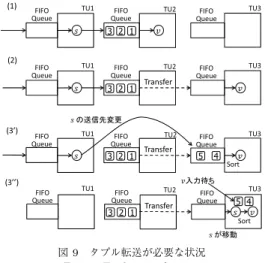
回に維持する場合のタプル適用順序の保持を考 える.図9
の(1)
の状態からオペレータv
をTU3
に 移動する場合を考える.1
ホップの通信を維持するた めには,(3
)
のようにs
の出力をTU3
に直接送る必図9 タプル転送が必要な状況 Fig. 9 Tuple transferring.
要がある.送信先を切り換えたとき,
TU2
のFIFO
キューにはs
の出力が残っているため,TU2
は(2)
の ようにこれらをTU3
に転送する必要がある.ここで,TU3
にはTU1
からとTU2
からのタプルが混在して 到着するため,タプル順序が入れ換わる可能性があ る.そこでTU3
はタプルID
をもとにタプルを並べ換 えて,v
を適用する必要がある.なお,図9
の(2)
や(3
)
の状態で,TU1
がs
の移動命令をTU2
のキュー に追加したとしても特別な操作は必要ない.なぜなら ば,TU2
がs
の移動命令を認識した段階で,TU2
は タプルの転送を終了していることが保証されるからで ある.また,図
9
の(2)
の状態で,更にs
がTU3
に移動 した(3
)
の場合を考える.この場合,s
の出力タプル がTU2
の入力キューに残っている.したがって,TU3
がs
への入力タプルを処理してs
がタプルを生成した としても,直ちにはv
に入力できない.TU2
に残っ ているタプルが転送されるのを待って,転送されたタ プルを先にv
に入力する必要がある.以上の議論は木構造の場合にも適用でき,操作のパ ターンを全て網羅すると,図
10
のような状態遷移図 が得られる.この状態遷移図は,あるTU
において,オペレータ
src
からオペレータdest
へ向かう通信路 がどのような状態にあるかを表している.初期状態はTU
がsrc
もdest
も動作させていないNONE
状態で あり,dest
をそのTU
が実行することになるとタプル 順序を並べ換えるSORT
状態になる.ソートが完了 すると受け取ったタプルにdest
を適用するRECV
状 態になり,src
がTU
に到着するとsrc
とdest
の両方図10 状態遷移図 Fig. 10 Sate transition diagram.
を一つの
TU
が実行するRUN
状態になる.続いて,dest
がTU
から去ると,他のTU
にタプルを転送す るSEND
状態になる.このほか,TRANSFER
はタ プルを転送する図9
の(2)
〜(3
)
におけるTU2
の状 態であり,RUN WAIT
は図9
の(3
)
におけるTU3
の状態であり,転送を待っている間,実行待機してい る状態である.以上のようにオペレータの移動方向を限定すること で,同期を排除したオペレータ移動と送信先変更を実 現することができる.
5.
評 価 実 験本章では提案手法の評価実験について述べる.評価 環境は既に示した表
1
のとおりである.5. 1
動的計画法の計算時間ここで
3. 2
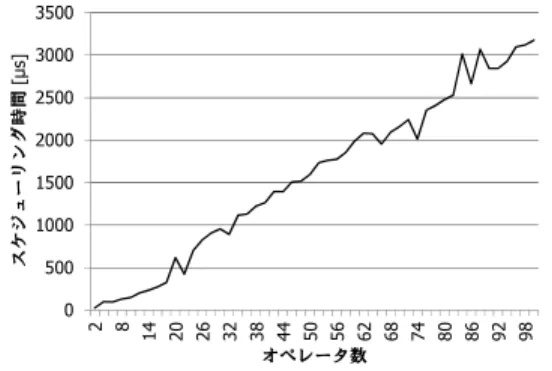
において与えたアルゴリズムの計算時間 について検証する.図11
はオペレータ数を変化させ たときに,4.
で説明した各Thread Unit
から統計情 報を取得し,3. 2
のアルゴリズムで最適配置の計算が 完了するまでに経過した時間である.図11
よりオペ レータ数に対して線形であることが分かる.100
オペ レータで3 ms
程度であり,1
秒間に300
回以上の計 算が可能である.この実験結果からThread Unit
の 統計情報の送信間隔を決定することができる.6.
で議 論するとおり,動的計画法の計算時間より短い間隔で のオペレータ再配置はできないことになるから,図11
をThread Unit
の統計情報送信間隔の目安とすれば よいことが分かる.5. 2
クエリプラン木次に,関係代数オペレータで構成されるプラン木を 用いて実験を行った.図
12
に実験に用いるクエリプ図11 オペレータ数とスケジューリング時間 Fig. 11 Scheduling time and the number of operators.
図12 実験用クエリプラン木とコアマッピング(図中の マッピングはパターンAの場合)
Fig. 12 A query plan tree and CPU core mapping.
ラン木を示す.八つのデータストリームから入力を受 け付け,結合結果を出力する.結合演算のウィンドウ サイズは
10
秒間である.タプルは整数四つの組から なり,それぞれ属性名をA
,B
,C
,D
とする.スト リームは毎秒5,000
タプルのデータソースが四つ,毎 秒1,250
タプルのデータソースが四つの計八つである.入力レートのパターン
A
とパターンB
を5
秒ごとに 入れ換えて,レイテンシの変化を確認した.また図12
にはパターンA
のときの最適割当を示している.こ のパターンA
のときのマッピングを変化させずに用 いた場合と提案手法の性能を比較した.レイテンシは100 ms
ごとの平均値を計測した.スレッド待機方法は ビジーウェイトとした.本実験では実験の5
秒〜10
秒 においてパターンA
とし,以降5
秒ごとにパターンA
とB
を変化させた.実験結果を図
13
に示した.10
秒までは定常状態に なく,ウィンドウも埋まっていないため省略している.図中の
Static
はパターンA
に適した状態のスレッド図13 平均レイテンシの変化(10秒〜15秒,20秒〜25 秒,30秒〜35秒はパターンB)
Fig. 13 Experimental result of average latency.
割当を実験中に変化させなかった場合であり,データ レートがパターン
B
になるとレイテンシ性能が悪化 していることが分かる.提案手法はパターンB
になる とオペレータを再配置するため,レイテンシを削減で きていることが分かる.10
秒から15
秒,20
秒から25
秒,30
秒から35
秒の間である.提案手法は入力 レートが変化してからオペレータを再配置するため,レイテンシ性能が一時的に悪化する.これは,図
13
においてもオペレータ再配置時の性能変化から確認で きる.しかし,再配置を行った場合でも,再配置しな い場合のレイテンシを超えていないことから,再配置 手法が有効に機能し,再配置のオーバヘッドが少ない ことを確認できる.なお,10
秒において提案手法のレ イテンシ性能が特に悪いのは,初回のオペレータ再配 置なため,JIT
コンパイラの影響によりレイテンシが 悪化していると考えられる.6.
本手法の適用条件に関する議論本章では本手法が有効になる,オペレータの計算時 間と通信レイテンシの関係やストリーム変化速度の 条件について議論する.まず,与えられたプラン木に おいて,通信レイテンシが最も多く発生する最悪の
CPU
コア割当を考える.最悪の割当は,各オペレー タに1
コアずつ割り当てた場合であることは明らかで あり,その際のレイテンシl(Q)
worst はl(Q)
worst=
vin∈Vin
f (v
in)θ
Pout(vin)
v∈Vin
f(v
)θ
Pout(v)w( | P (v
in) | − 1) +
v∈P(vin)
c
vC
となる.ここで,
A(g(v
in)) =
vin∈Vin
f (v
in)θ
Pout(vin)
v∈Vin
f(v
)θ
Pout(v)g(v
in)
とおき,本手法で得られる最適解l(Q)
OPT との比R
を考えると,R = l(Q)
OPTl(Q)
worst=
w(S
2[v
out] − 1) + A
v∈P(vin)
c
vC A(w( | P (v
in) | − 1)) + A
v∈P(vin)
c
vC
≥ A
v∈P(vin)
c
vC A(w( | P (v
in) | − 1)) + A
v∈P(vin)
c
vC
= 1
A(w( | P (v
in) | − 1)) A
v∈P(vin)
c
vC
+ 1
(5)
と で き る .こ こ で
R
は 本 手 法 に よ る 最 適 解 が ,l(Q)
worst に対してどの程度の割合になるか示している.上式最後の式
(5)
はR
の楽観的な見積り,つま り通信レイテンシが完全に排除され,最も性能が向上 した場合を表している.本手法がどの程度の貢献をし 得るかが,オペレータの計算時間c
vとコア間の通信 レイテンシw
の関係で表現されていることが分かる.c
v が小さくなるほど,クエリレイテンシl(Q)
のうち 通信レイテンシが占める割合が増し,本手法による通 信レイテンシ削減の効果が大きくなる.次に,再配置のコストについて,動的計画法の計算 時間から検討する.本手法では入力ストリームレート やオペレータの
CPU
使用量の統計に基づいて動的計 画法の計算を行い,最適配置が変わった場合は再配置 する.動的計画法の計算時間は図11
にあるとおりオ ペレータ数に対して線形である.このため,オペレー タ数が多くなるに従い,解を得るまでに時間が掛かる.計算時間が長くなると十分な頻度での再配置ができず,
頻繁な入力レートの変化に適応できなくなる.これは 本手法の弱点であることは事実であるが,最適解を求 めるという目標のもとではやむを得ないコストと考え られる.計算が間に合う限りで適応的な再配置をでき ると考えれば,入力レートの変化に伴う再配置の発生 間隔より動的計画法の計算時間の方が短いことが本手 法を適用する条件となる.
本研究の対象は関係代数演算で構成されたプラン木 であり,各オペレータはオンメモリで短時間な処理を 実行する.しかし,本手法の目標は
CPU
コア間の通 信レイテンシ削減であり,前式のw
は数マイクロ秒 単位の小さな値である.最も重要な基本演算である選 択演算や結合演算であっても,c
vの値によっては効果 が生まれるか明らかではない.前章の実験は,実際に選択演算や結合演算を用いた 場合に,通信レイテンシ削減の効果が発生することを 示している.更に,図
13
においての比較対象は,入 力レートがパターンA
のときの最適配置であり,前述 の楽観的な見積りで用いた1
オペレータに1
コアを割 り当てる方法よりはるかに厳しい比較対象である.そ の場合でも図13
の結果のように,レイテンシを10 μs
程度から8 μs
程度に削減できている.どの程度の入力レートの変化頻度に耐えられるか は,スケジューリング計算の間隔やタイミング,移動 すべきオペレータ数など様々な要素で決まってくると 考えられ,現時点では
Open Question
である.本論 文の実験の意義は,これまで議論されてこなかったオ ペレータ再配置によるレイテンシ短縮が可能であるこ とを示した点にある.7.
関 連 研 究これまで
DSMS
のオペレータスケジューリングに 関する研究は数多くされてきた.Chain [3]
はキュー に溜まったタプルサイズを抑えることでメモリ使用量 を最小化するとともに,レイテンシの最小化も目標に した手法であるが,単一コアによる処理を仮定してお り,マルチコア環境に適用できない.Eddies [2]
はオ ペレータのリオーダリングを許す手法で,データが準 備できておりかつ処理に余裕があるオペレータから適 用していくものである.複数のタプルをバッチ型にし てスケジューリングすることでオーバヘッドを抑えたTeddies [5]
がある.しかし,いずれも提案手法のよう なコア間通信のレイテンシを考慮したものではない.分散データストリーム処理のスケジューラも研究が 行われており,
IBM System S
のスケジューラであるCOLA [8]
は,計算機のCPU
リソースを超えないよ うにオペレータを配置した上で,通信に使用するCPU
時間を最小化する.スループットの向上に寄与するこ とは確認されているが,レイテンシに関する評価がさ れていない.RASC [7]
は,データの処理が間に合わ ず破棄されるデータ量を最小化するよう最小コスト流を用いてスケジューリングしている.しかし,データ の破棄が発生してから,発生した計算機に対する流量 を減らす戦略であるため,データの損失が発生する.
コンパイラや
HPC
の分野において,DAG
に対す るプロセッサの割付けが行われてきた[9]
.これらはDAG
の辺をデータ依存と考えて,全ノードの実行が 完了するまでの時間を最小化するものである.しかし,データストリーム処理では,タプルはプラン木に存在 するオペレータのうちの一部を通過して処理が行われ るため,問題の性質が異なる.
本論文では,単一計算機におけるストリーム処理の レイテンシ問題を扱った.
CPU
アーキテクチャやス レッド起床のオーバヘッドを考慮し,マルチコア環境 において処理レイテンシを短縮する.データ分割によ る並列化手法[11]
は扱っていないが,並列化後のプラ ン木を考えれば同じ議論が成り立つから,提案手法の 一般性を損なわないと考えられる.8.
む す び本論文では,マルチコア
CPU
を対象としたデータ ストリーム処理のレイテンシ問題を扱った.データス トリーム処理のレイテンシ定義を与え,動的計画法に より最適解が求まることを示し,計算リソースの統計 情報取得方法とデータストリーム処理を停止せずにオ ペレータ再配置を実現する方法について述べた.今後の課題として,高頻度なデータレート変化時に おける評価や,同一
CPU
内ではなくQPI
を経由し た,異なるCPU
間での通信を考慮することがある.QPI
を経由する場合,3.
でのコア間通信レイテンシw
が2
種類以上になり,より難しい問題となる.また,数百〜数千という多数のコアを考えた場合に,中央集 権的なスケジューラを用いるのではなく,各
CPU
が 自律的にスケジューリングすることも考えられる.ほ か,現実の環境に近づけるために,ネットワーク経由 でデータが到着した場合の評価も検討する必要がある.例えば,
InfiniBand
のRDMA
を用いれば数マイクロ 秒のレイテンシでのデータ送受信が可能になるため,本提案手法が有効に機能すると考えられる.本論文の アルゴリズムは我々が開発している分散型
DSMS
で あるQueueLinker
に実装した上で,オープンソース 化を予定している.謝辞 本研究に関して,筑波大学の北川博之先生,
川島英之先生より有益な御助言を頂いたことに感謝す る.本研究の一部は,文部科学省「
Web
社会分析基盤ソフトウェアの研究開発」及び科学研究費(挑戦的萌 芽研究
No.23650053
)によるものである.文 献
[1] D.J. Abadi, Y. Ahmad, M. Balazinska, U.
C¸ etintemel, M. Cherniack, J.H. Hwang, W. Lindner, A.S. Maskey, A. Rasin, E. Ryvkina, N. Tatbul, Y. Xing, and S. Zdonik, “The design of the Borealis stream processing engine,” Proc. CIDR 2005, pp.277–289, 2005.
[2] R. Avnur and J.M. Hellerstein, “Eddies: Contin- uously adaptive query processing,” Proc. SIGMOD 2000, pp.261–272, 2000.
[3] B. Babcock, S. Babu, M. Datar, R. Motwani, and D.
Thomas, “Operator scheduling in data stream sys- tems,” The VLDB Journal, vol.13, pp.333–353, 2004.
[4] D. Carney, U. C¸ etintemel, M. Cherniack, C. Convey, S. Lee, G. Seidman, M. Stonebraker, N. Tatbul, and S. Zdonik, “Monitoring streams - A new class of data management applications,” Proc. VLDB 2002, pp.215–226, 2002.
[5] K. Claypool and M. Claypool, “Teddies: Trained ed- dies for reactive stream processing,” Proc. DASFAA 2008, pp.220–234, 2008.
[6] A.A. Diwan, S. Rane, S. Seshadri, and S. Sudarshan,
“Clustering techniques for minimizing external path length,” Proc. VLDB 1996.
[7] Y. Drougas and V. Kalogeraki, “RASC: Dynamic rate allocation for distributed stream processing applica- tions,” Proc. IPDPS 2007, pp.1–10, 2007.
[8] R. Khandekar, K. Hildrum, S. Parekh, D. Rajan, J.
Wolf, K.-L. Wu, H. Andrade, and B. Gedik, “COLA:
Optimizing stream processing applications via graph partitioning,” Proc. Middleware 2009, pp.16:1–16:20, 2009.
[9] Y.-K. Kwok and I. Ahmad, “Static scheduling algo- rithms for allocating directed task graphs to mul- tiprocessors,” ACM Comput. Surv. (CSUR), vol.31, no.4, pp.406–471, Dec. 1999.
[10] K. Slavin, “How algorithms shape our world,”
http://www.ted.com/talks/lang/en/
kevin slavin how algorithms shape our world.html,
(2012/7/2訪問).
[11] 渡辺陽介,横田治夫,“マルチコア環境における可換演算 群の並列評価による低遅延ストリーム処理方式,” WebDB Forum 2011.
[12] 東京証券取引所:ネットワークサービス概要,
http://www.tse.or.jp/system/network/index.html,
(2012/7/2訪問).
[13] Intel Xeon Processor 7500 Series, Datasheet, Vol- ume 2: http://www.intel.com/Assets/PDF/
datasheet/323341.pdf,(2012/7/2訪問).
(平成24年7月3日受付,10月29日再受付)
上田 高徳 (学生員)
早稲田大学IT研究機構研究助手.同大 大学院基幹理工学研究科博士後期課程(在 学中).DSMS,並列分散処理,ストレー ジシステムに関する研究に従事.IEEE,
ACM,IPSJ,DBSJ各会員.
秋岡 明香 (正員)
2004博 士( 情 報 科 学 ,早 稲 田 大 学 ).
2004〜2005国立情報学研究所プロジェク
ト研究員.2005〜2007ペンシルバニア州 立大学ポスドク研究員.2007〜2010電気 通信大学大学院助教.2010〜早稲田大学IT 研究機構主任研究員.IEEE,ACM,IPSJ 各会員.
山名 早人 (正員:シニア会員)
1993早稲田大学大学院理工学研究科博士 後期課程了.博士(工学).1993〜2000電 子技術総合研究所.2000早稲田大学理工学 部助教授.2005同大理工学術院教授,NII 客員教授.IEEE,ACM,AAAI,IPSJ,
DBSJ各会員.
![Fig. 1 Intel Xeon 7500 series diagram [13].](https://thumb-ap.123doks.com/thumbv2/123deta/5629142.1500736/2.774.408.698.97.546/fig-intel-xeon-series-diagram.webp)

![図 7 S[v, i, j] の定義 Fig. 7 Definition of S[v, i, j]. するその割合を F[v] とする.入力オペレータ以外の オペレータ V mid = {v | v ∈ V, v / ∈ V in } に関しては F [v] = 1≤i≤n F[vp i ] と再帰的に計算できる.初期 値として入力オペレータ v ∈ V in に対して S[v, 0, c v λ v ] = S 1 [v, c v λ v ] = S 2 [v] = F [v] = f(v)θ out](https://thumb-ap.123doks.com/thumbv2/123deta/5629142.1500736/6.774.86.353.106.282/Sv定義オペレータオペレータに関しできるとしてオペレータに対し.webp)