名詞句の情報の状態と読み時間について
浅原 正幸
† 日本語は冠詞のない言語である.日本語名詞句の情報の状態は,テキストに陽に表 出せず,限られた文脈情報や世界知識のみに基づく手法では推定することは難しい. 情報の状態は情報の新旧や定・不定などの観点で分析される.しかしながら,日本 語の言語処理においては,この概念が適切に扱われていない.そこで,本稿では, まず,日本語名詞句の情報状態について解説する.次に,読み時間を手がかりとし て,名詞句の情報の状態(新旧・定不定)を推定することを検討する.具体的には 日本語名詞句の情報の状態が文の読み時間にどう影響するかについて調査する.結 果,名詞句の読み手の側の情報状態(情報)が読み時間に対して影響を与えること を明らかにしたので報告する. キーワード:情報状態,読み時間,アノテーション・ベイジアン線形混合モデルBetween Reading Time
and the Information Status of Noun Phrases
Masayuki Asahara†Japanese noun phrases are not marked by articles. The information status of Japanese noun phrases is not overt. Due to limited contextual information and world knowl-edge, it is difficult to estimate the information status, which is analyzed through the given/new status or indefinite/definite status. However, in Japanese language pro-cessing, the notion of the information status is yet to be understood. In this paper, we explain the information status of Japanese noun phrases. Then, we explore how the information status of Japanese noun phrases is estimated through the reading time. As a first step, we investigate the correlation between reading time and the information status of Japanese noun phrases. The statistical evaluation shows that readers’ information status affects reading time in Japanese.
Key Words: Information Status, Reading Time, Annotation, Bayesian Linear Mixed Model
1
はじめに
本稿では日本語名詞句の情報の状態を推定するために読み時間を用いることを目指して,情 報の状態と読み時間の関連性について検討する.名詞句の情報の状態は,情報の新旧に関する
だけでなく,定性・特定性など他言語の冠詞選択に与える性質や,有生性・有情性などの意味 属性に深く関連する.他言語では冠詞によって情報の性質が明確化されるが,日本語において は情報の性質の形態としての表出が少ないために推定することが難しい. 情報の状態は,書き手の立場のみで考える狭義の情報状態 (information status) と読み手の立 場も考慮する共有性 (commonness) の 2 つに分けられる.前者の情報状態は,先行文脈に出現 するか(既出:discourse-old)否か(未出:discourse-new)に分けられる.後者の共有性は,読 み手がその情報を既に知っていると書き手が仮定しているか(既知:hearer-old),読み手がそ の情報を文脈から推定可能であると書き手が仮定しているか(ブリッジング:bridging),読み 手がその情報を知らないと書き手が仮定しているか(未知:hearer-new)に分けられる.以後, 一般的な情報の新旧を表す場合に「情報の状態」と呼び,書き手の立場のみで考える狭義の情 報の新旧を表す場合に「情報状態」(information status)と呼ぶ. これらの情報の状態は,言語によって冠詞によって明示される定性 (definiteness) や特定性 (specificity) と深く関連する.また,情報の状態は,有生性 (animacy),有情性 (sentience),動作 主性 (agentivity) とも関連する.日本語のような冠詞がない言語においても,これらの「情報の 状態」は名詞句の性質として内在しており,ヒトの文処理や機械による文生成に影響を与える. 機械翻訳を含む言語処理における冠詞選択手法は,これらの名詞句にまつわる様々な特性を 区別せずに機械処理を行っているきらいがある.例えば,(乙武,永田 2016) は,本来,定・不 定により決定される英語の冠詞推定に情報の新旧の推定をもって解決することを主張している. 彼らの主張では,談話上の情報の新旧をもって定・不定が推定できると結論付けている. また,自動要約や情報抽出においても,既出・未出といった情報状態の観点,つまり書き手 側の認知状態が主に用いられ,既知・想定可能・未知といった共有性の観点,つまり読み手側 の認知状態が用いられることは少ない.これらを適切に区別して,識別することが重要である. 特に,読み手の側の情報状態は,自動要約や情報抽出の利用者の側の観点である.さらにその 推定には読み手の側の何らかの手がかりをモデルに考慮することが必要になると考える. 言語処理的な解決手法として,大規模テキストから世界知識を獲得して情報状態を推定する 方法が考えられる一方,読み手の反応を手がかりとして共有性を直接推定する方法が考えられ る.読み手の反応に基づいて,読み手側の解釈に基づく日本語の情報状態の分析は殆どない. そこで,本稿では,対象とする読み手に対する情報の状態が設定されているであろう新聞記 事に対する読み時間データが,名詞句の情報の状態とどのような関係があるのかを検討する. もし読み時間が名詞句の情報の状態と何らかの関係があるのであれば,視線走査装置などで計 測される眼球運動などから,情報の状態を推定することも可能であると考える.特に共有性は 読み手の側の情報状態であるにかかわらず,既存の日本語の言語処理では読み手の側の特徴量 を用いず推定する手法が大勢であった.なお,本研究の主目的は冠詞選択にはなく,日本語の 名詞句の情報状態を推定することにある.その傍論として既存の冠詞選択手法が定・不定など
の名詞句の特性と本稿で扱う書き手・読み手で異なる情報状態とで差異があり,言語処理の分 野において不適切に扱われてきた点について言及する. 以下,2 節では関連研究を紹介する.3 節に情報状態の概要について示す.4 節に読み時間の 収集方法について示す.5 節では今回利用する読み時間データおよび情報の状態アノテーショ ンデータと分析手法について示す.6 節で実験結果と考察について示す.7 節で結論と今後の方 向性について示す.
2
関連研究
情報状態に関するアノテーションについての関連研究を示す.G¨otze らは情報状態(既出 (given)/想定可能 (accessible)/未出 (new))や話題 (aboutness/frame setting) や焦点(新情報焦点 (new-information focus)/対照焦点 (contrastive focus))に関する言語非依存のアノテーション基準 を提案している (G¨otze, Weskott, Endriss, Fiedler, Hinterwimmer, Petrova, Schwarz, Skopeteas, and Stoel 2007).Prasad らは,Penn Discourse Treebank (Prasad, Dinesh, Lee, Miltsakaki, Robaldo, Joshi, and Webber 2008) および PropBank (Palmer, Gildea, and Kingsbury 2005) に対 するブリッジングアノテーションの基準について議論している (Prasad, Webber, Lee, Pradhan, and Joshi 2015). 次に,英語の冠詞推定に関連する研究について言及する.先に述べた (乙武,永田 2016) で は,情報の新旧と定・不定の近似による手法を提案している.(竹内,河合,細田,永田 2013) では,ブリッジング(想定可能)にも言及しているが,単語の共起をもってブリッジングとし ており,実際に読み手が想定可能かどうかについての言及はしていない.これらは,英語の冠 詞が表出する定・不定を誤って理解していることによるものだと考える.最後に,視線走査関連についての関連研究を示す.Dundee Eye Tracking Corpus (Kennedy and Pynte 2005) は英語とフランス語の新聞社説をそれぞれ 10 人の母語話者に呈示して視線走査 装置を用いて収集した読み時間データである.また,視線走査データを用いた言語学的な分析に ついて紹介する.Demberg らは Dundee Eye Tracking Corpus を用いて,Gibson の dependency locality theory (DLT)(Gibson 2008) や Hale の surprisal theory (Hale 2001) を検証した (Demberg and Keller 2008).Barret らは 視線走査データに基づいて品詞タグ付けを行う手法を提案して いる (Barrett, Bingel, Keller, and Søgaard 2016) .Klerke らは視線走査により,機械処理された テキストの文法性判断を行う手法を提案している (Klerke, Mart´ınez Alonso, and Søgaard 2015). このように視線走査を用いて,読み手側の要因をいれた研究が盛んに進められている.
3
名詞句の情報の状態について
本節では名詞句の情報の状態について概説する.なお,本節は (Miyauchi, Asahara, Nakagawa, and Kato 2018; 宮内,浅原,中川,加藤 2018) に記載されているものの一部であるが,査読者 の指示で掲載する. 本研究で利用するアノテーションデータ BCCWJ-Infostr では以下の 7 種類の情報の状態に まつわる属性について検討する. (1) a. 情報状態 (information status) 「新情報 (discourse-new)」「旧情報 (discourse-old)」 b. 共有性 (commonness) 「共有 (hearer-new)」「非共有 (hearer-old)」 c. 定性 (definiteness) 「定 (definite)」「不定 (indefinite)」 d. 特定性 (specificity) 「特定 (specific)」「不特定 (unspecific)」 e. 有生性 (animacy) 「有生 (animacy)」「無生 (inanimate)」 f. 有情性 (sentience) 「有情 (sentient)」「無生 (insentient)」 g. 動作主性 (agentivity) 「動作主 (agent)」「被動作主 (patient/theme)」 アノテーション対象とする『現代日本語書き言葉均衡コーパス』(BCCWJ) (Maekawa, Yamazaki, Ogiso, Maruyama, Ogura, Kashino, Koiso, Yamaguchi, Tanaka, and Den 2014) では,長単位と 短単位という 2 つの単位が採用されているが,本研究では,短単位の名詞をアノテーション対 象とする.アノテータは BCCWJ-DepParaPAS (植田,飯田,浅原,松本,徳永 2015; 浅原,大 村 2016) に付与された共参照情報を確認しながら,作業を行う.ただし,複合語については,前 部要素には指示性 (referentiality) がないこと等を考慮して,前部要素まで含めて一つの名詞と 捉えることにより,実質的に長単位名詞句へのアノテーションを行うことになる.この単位に 対する方針については,基本的には BCCWJ-DepParaPAS の作業方針と同じである.上記に示 したタグは言語学の専門的な知識を持つものでないとアノテーションができないために,1 人 の言語学博士課程の学生がアノテーションし,3 人がその結果を確認した. 定性・特定性・有生性・有情性・動作主性については,与えられた文脈から判断できない場
合に「どちらでもよい」というタグを認めた.特に動作主性については,ある名詞句が主節か ら見た場合と従属節から見た場合と異なる場合に付与した.なお,共有性・特定性・動作主性 については,その概念が認めがたい場合に「どちらでもない」というタグを認めた. 以下,実例と共にそれぞれのラベルのアノテーション基準を示す.
3.1
情報状態・共有性
(1a) の情報状態とは,いわゆる旧情報と新情報の区別である.ある談話において,新たな情 報は「新情報」となり,聞き手/読み手が知っている情報は「旧情報」となる.一つのテクス ト(BCCWJ 新聞サンプルにおける記事単位)全体を一つの談話とみなし,アノテーションを 行った. (2) a. 担任だった 池田弘子先生 は違った。 b. スクールカウンセラーでもあった 先生 の授業は 読売新聞 [BCCWJ:PN1c 00001] (2a) の下線部の名詞「池田弘子先生」はこのテクストで初出の実体であるために,末尾の短単位 名詞に新情報タグが付与される.一方,(2b) 下線部の名詞「先生」は (2a) の「池田弘子」を指示し ているため旧情報タグが付与される.これらの名詞は共参照関係にあり,BCCWJ-DepParaPAS のアノテーションから展開できるが,展開したのち,全数確認を行いラベル付与した. (1b) の共有性は,情報を聞き手が既に知っていると話し手が想定しているか否かを示す分類 である.聞き手が既に知っていると話し手が想定している情報は「共有 (hearer-old)」であり, 知らないと想定している情報は「非共有 (hearer-new)」である.なお,この判断の際はアノテー タの世界知識を使ってもよいこととし,「想定可能」というラベルも許す.このラベルは,ブ リッジング (bridging) を起こしている際に付与される. (3) aキャンティ街道 を抜け、bオリーブ畑 に囲まれた田園地帯のc レストラン で、 読売新聞 [BCCWJ:PN4c 00001] 3 の下線部 a. の名詞「キャンティ街道」は,世界遺産にも登録されている,ワインで有名な街 道であり,アノテータは既にこの街道について知っていたため,共有のタグが付与された.下 線部 b. の名詞「オリーブ畑」はこの記事からどんなオリーブ畑であるのか判断できないため, 非共有のタグが与えられる.下線部 c. の名詞「レストラン」はキャンティ街道のレストランを 指しており,ある種のブリッジングを起こしているため,想定可能のタグが付与される.3.2
定性・特定性
(1c) の定性とは,指示対象を聞き手が同定できるか否かを示す分類である.指示対象を聞き 手が同定できると話し手が想定していれば「定 (definite)」であり,同定できないと想定していれば「不定 (indefinite)」である.本研究では,判定する際に確認する文脈として前後 3 文を見 ることとする. (4) 高等部では自由な校風もあって、流行に乗ってかばんを薄くつぶしたり、ピアスを したり。呼び出して注意する先生もいたが、二、三年時に担任だった池田弘子先生 (七十五)は違った。「そんな薄いaかばん じゃb遊び道具 も入らないよ」 読売新聞 [BCCWJ:PN4c 00001] (4) の下線部 a. の名詞「かばん」はスコープである (4) の前 3 文以内に既出の名詞であり,こ こでは具体的に聞き手の持ち物のかばんを指示している.話し手はこの「かばん」は聞き手に より同定しうると想定していると考えられるため,定のタグが与えられる.(4) の下線部 b. の 名詞「遊び道具」は特に具体的な何か遊び道具を指示しているわけではないため,不定のタグ が付与される. (1d) の特定性は,定性と少々似た概念であるが,話し手が特定の事物を想定しているか否か を示す意味論的カテゴリーである.話し手が特定の事物を想定しているならば「特定 (specific)」 となり,想定していなければ「不特定 (unspecific)」となる.定性と同様,特定性に関しても文 脈として前後 3 文を見ることとする. (5) 米どころの同町では、降霜対策で農家による廃タイヤの野焼きが行われてきたが、ダ イオキシン問題や交通妨害が指摘され、行き場を失ったa廃タイヤ があぜ道やb納屋 の横に放置されてきた。同町が昨秋行った調査では、廃タイヤは農家が抱えるもの や不法投棄を含め約三万本に上るという。 読売新聞 [BCCWJ:PN4c 00001] 5 の下線部 a. の名詞「廃タイヤ」は,北海道鷹栖町に放置された約 30,000 本のタイヤを具体 的に指しており,これは 5 の前後 3 文から読み取ることが可能であるため特定のタグが付与さ れる.5 の下線部 b. の名詞「納屋」は特定の納屋が想定されているわけではなく,不特定のタ グが与えられる.
3.3
有生性・有情性
(1e) の有生性とは,生きているか否かを示すカテゴリーである.生物(人間,動物など)は 「有生 (animate)」であり,無生物(植物を含む)は「無生 (inanimate)」である.有生性は名詞 句レベルのみで判断し,付与されるものとする. 有生性と似た概念として (1f) の有情性がある.これは,情意があるか否かを示すパラメター である.自由意志による移動が可能な場合は「有情 (sentient)」となり,自由意志による移動が ないなら「非情 (insentient)」となる.日本語については,有生/無性の区別よりも有情/非情の区別が重要であるとする立場もあり,また,有生性と有情性の値が異なる場合もあり得るこ とから,このパラメターの設定が必要となる.情意の有無は名詞句単体では判定できない場合 があるため,有情性は述語-項レベルまで見た上で判断し,付与されるものとする. (6) オオクチバスなどのaブラックバス類 が、少なくとも四十三都道府県の七百六十一 のため池やb湖沼 に侵入し、 読売新聞 [BCCWJ:PN4c 00001] (6) の下線部 a. の名詞「ブラックバス」は生物であるため,有生のタグが付与される.また, ブラックバスに情意があるか否かは判断が難しいが,その述語は「侵入する」となっており,こ れは意志的な動作,行為を表しているため,ここでの「ブラックバス」は有情のタグが付与さ れることになる.(6) の下線部 b. の名詞「湖沼」は無生物であり,情意もないと判断されるた め,それぞれ,無生,非情のタグが与えられる.
3.4
動作主性
(1g) の動作主性は,事態に関わる事物や人物がその事態で果たしている役割を示す.行為を 意図的に実現するものは「動作主 (agent)」とし,行為によって変化を被るものを「被動作主 (patient/theme)」とする.このパラメターについては節レベルまで見て判断し,タグを付与す ることとする.その際,主節と従属節の両方を考慮する.また,「どちらでもよい」「どちらで もない」を許す. (7) a. 編み笠をかぶった人なつっこい 笑顔 を見るだけで、 b. もみじの木にとまって仲良く寄り添う二羽の キジバト。 c. 独特な雰囲気の 写真 になりました。 読売新聞 [BCCWJ:PN1d 00001] (7a) の下線部の名詞「笑顔」は,主節では被動作主であり従属節では動作主である.このよ うな場合に「どちらでもよい」というタグを付与する.(7b) の下線部の名詞「キジバト」は,そ れを含む文がこの名詞で終わる体言止めの文であるため主節では動作主性の判断ができないが, 従属節では動作主であるため,「動作主」というタグを付与する.(7c) の下線部の名詞「写真」 は動作主でも被動作主でもないため,「どちらでもない」となる.3.5
名詞句の情報の状態のまとめ
このように名詞句の情報の状態は,多様な観点が分析される.しかしながら,2 節で示した日 本人工学研究者による英語の冠詞推定手法のように,これらが混同されて扱われてきた. なお,我々の興味は,冠詞推定にはなく,情報の状態にある.情報の状態は 3.1 節に示した通り,書き手にとっての情報の新旧である情報状態と,読み手にとっての情報の新旧である共 有性の 2 つの観点がある.前者の情報状態については,談話の出現について言及する共参照解 析により言語処理に分野では扱われてきた.本稿では,後者の共有性を読み手の視線情報によ り捉えるかを検証する.一般に,情報抽出や自動要約のために必要なのは,アプリケーション を利用する受け手側から見た情報の新旧である共有性にある.
4
読み時間の収集方法
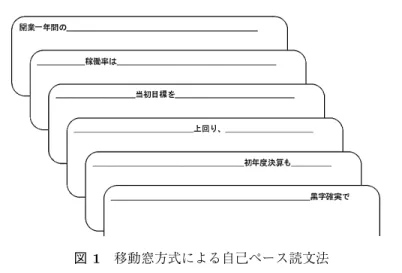
本節では読み時間の収集方法について説明する.なお,本節は言語学会論文誌『言語研究』に 投稿中のものの一部であるが,査読者の指示で掲載する. 読み時間を収集する対象は,BCCWJ(Maekawa et al. 2014) のコアデータの新聞記事データ (PN サンプル)の一部とした.コーパスアノテーションの分野では,できる限り同じテキストに 様々な情報を付与するという取組が進められている.対象の記事は,研究者コミュニティで共有 されているアノテーションの優先順位1に基づいて選択した.これにより,係り受け (Asahara and Matsumoto 2016)・節境界 (Matsumoto, Asahara, and Arita 2018)・分類語彙表番号 (加藤, 浅原,山崎 2017)・情報構造 (Miyauchi et al. 2018; 宮内 他 2018)・述語項構造および共参照 (植 田 他 2015)・否定の焦点 (松吉 2014) などのアノテーションとの重ね合わせに基づく分析が可能 になる.Dundee Eye Tracking Corpus においても Dundee Treebank (Kennedy, Hill, and Pynte 2003) など品詞・係り受け・共参照の整備が進んでいるが,本研究の BCCWJ-EyeTrack のよう にコーパス言語学的な統語・意味・談話レベルの情報が重畳的に付与されていない. 読み時間データの収集方法として,自己ペース読文法と視線走査法を用いた. 自己ペース読文法は,キーボード入力などに基づき,逐次的に文字列を表示し,実験協力者 のペースで文を読む課題である.図 1 に課題の画面例を示す.最初,コンピューター画面上に は,文の長さを表すアンダーバーが表示されている.被験者がスペースキーを押すごとに,刺 激文の始めから 1 文節(もしくは 1 単語)ずつ表示され,直前に表示されていた文節はアンダー バーに戻る.文節が表示されてから,次にボタンを押すまでの時間が,その文節の読解時間と してミリ秒単位で記録される.英語においては視線走査で得られる読み時間との高い相関があ ることが知られており (Just, Carpenter, and Woolley 1982),安価な機器で読み時間を取得する ことができる.刺激の呈示方法として移動窓方式を用いた.自己ペース読文法を実施するソフ トウェアとして Linger2を用いた.視線走査法は,実験協力者がディスプレイ画面上のどの文字を注視しているのかを取得する
1 https://github.com/masayu-a/BCCWJ-ANNOTATION-ORDER 2 http://tedlab.mit.edu/˜dr/Linger/
図 1 移動窓方式による自己ペース読文法 視線走査装置を用いて,視線注視箇所と注視時間を計測する手法である.自己ペース読文法と 異なり,読み戻しなどのより自然な読み時間を取得することができる.視線走査装置として SR Research 社の EyeLink 1000 シリーズ(タワーマウント)を用い,時間解像度は 1,000 Hz で, ミリ秒単位のデータが収集可能である. 視線走査法においては刺激となるテキストは等幅フォント(MS 明朝 24 ポイント)を用いて 横書きで 1 画面に最大 5 行を 21.5 インチのディスプレイに呈示した.横方向には全角で最大 53 文字を呈示し,後述のとおり文節境界に半角スペースを入れた場合には,最大全角 53 文字を超 えないようにした単位で折り返し,1 画面に 5 行まで表示した.文境界には必ず改行を入れた. 視線走査装置の上下方向の誤差を吸収するために,各行は 3 行空けて呈示した.実験協力者はあ ご台に顔を固定した状態で,ハーフミラー越しに画面を見るという姿勢で,課題に取り組んだ. 自己ペース読文法では,ハーフミラーつきのあご台を用いない以外は同条件で実験を行った. 文字列を呈示する基本単位として BCCWJ に付与されている国語研文節単位を用いた.自己 ペース読文法では,文節単位でテキストを表示した.また文節境界に半角スペースを空けた条 件と空けていない条件の 2 つの条件を用意し,読み時間を計測した.実験は新聞記事 20 件を A, B, C, D の 4 つのユニットに分割し,視線走査法による計測を 2 セッション実施したのちに, 自己ペース読文法による計測を 2 セッション実施した.実験協力者は各新聞記事 20 件を一度だ け読む.各ユニットの文節数,文数,画面数を表 1 に示す.1 件の新聞記事を読み終わり,次 の新聞記事が始まる際には,必ず画面を改めた.実験協力者は 3 人ずつ 8 つのグループに分け, 表 2 のように実験を行った.全実験協力者は視線走査法を行ったのちに,自己ペース読文法を 行った.
表 1 それぞれの記事ユニットに含まれる文節数,文数,画面数 ユニット 文節数 文数 画面数 A 470 66 19 B 455 67 21 C 355 44 16 D 363 41 15 表 2 実験計画:各被験者グループにおける記事ユニットと課題・文節境界の空白の有無の対応関係 グループ 視線走査法 自己ペース読文法 ア A (文節境界空白無) B (文節境界空白有) C (文節境界空白無) D (文節境界空白有) イ A (文節境界空白有) B (文節境界空白無) C (文節境界空白有) D (文節境界空白無) ウ C (文節境界空白無) D (文節境界空白有) A (文節境界空白無) B (文節境界空白有) エ C (文節境界空白有) D (文節境界空白無) A (文節境界空白有) B (文節境界空白無) オ B (文節境界空白無) A (文節境界空白有) D (文節境界空白無) C (文節境界空白有) カ B (文節境界空白有) A (文節境界空白無) D (文節境界空白有) C (文節境界空白無) キ D (文節境界空白無) C (文節境界空白有) B (文節境界空白無) A (文節境界空白有) ク D (文節境界空白有) C (文節境界空白無) B (文節境界空白有) A (文節境界空白無)
5
データと分析手法
本研究では『現代日本語書き言葉均衡コーパス』(Maekawa et al. 2014)(以下 BCCWJ)に対 する読み時間データ BCCWJ-EyeTrack (Asahara, Ono, and Miyamoto 2016) に,情報の状態ア ノテーション BCCWJ-Infostr (Miyauchi et al. 2018; 宮内 他 2018) を重ね合わせたもの(表 3) を用いる.これらをベイジアン線形混合モデル (Sorensen, Hohenstein, and Vasishth 2016) によ り回帰分析することにより,読み時間と情報の状態との関係を明らかにする.以下では,それぞれのデータについて概説する.
5.1
BCCWJ-EyeTrack: 読み時間のデータ
自己ペース読文法で取得したデータは,取得時に語句が文節単位に呈示され,読み戻しができ ないために,文節単位の読み時間がそのままデータとなる.視線走査法で取得したオリジナルの データは文字の半角単位に Start Fixation Time (注視開始時刻)と End Fixation Time (注視 終了時刻)と Fixation Time (注視時間)を得た.このデータを国語研文節単位でグループ化し なおしたものを注視順データと呼ぶ.この注視順データを,視線走査法を用いた読み時間計測 で標準的に用いられている,以下の 5 つの計測時間データ (measures) に加工した (Van Gompel, Fischer, Murray, and Hill 2007).これらは国語研文節単位を注視領域として作成した.
• First Fixation Time (FFT) • First-Pass Time (FPT)
• Second-Pass Time (SPT) • Regression Path Time (RPT) • Total Time (TOTAL)
説明のために図 2 の例を用いる.図中 1–12 の数字が視線走査順を表す.
First Fixation Time (FFT) はその注視領域に初めて視線が停留した際の注視時間である.例 中の「初年度決算も」の FFT は 5 の注視時間となる. 表 3 利用するデータの概要 読み時間データ (BCCWJ-EyeTrack) 列名 型 摘要 surface factor 表層形 time int 読み時間 (ミリ秒) measure factor 読み時間型 sample factor サンプル名 article factor 記事情報
metadata orig factor 文書構造タグ(原版)
metadata factor 文書構造タグ(修正版)
space factor 文節間空白の有無
length int 文字数
is first factor 最左文節
is last factor 最右文節
is second last factor 右から 2 番目の文節
sessionN int セッション順 articleN int 記事順 screenN int 画面順 lineN int 行順 segmentN int 文節順 subj factor 被験者識別子 dependent int 係り受けの数 情報の状態データ (BCCWJ-Infostr) 列名 型 摘要 infostatus factor 情報状態 definiteness factor 定性 animacy factor 有生性 commonness factor 共有性 specificity factor 特定性 sentience factor 有情性 agentivity factor 動作主性 図 2 視線走査順の例
First-Pass Time (FPT) は,注視領域に初めて視線が停留し,その後注視領域から出るまで の総注視時間である.出る方向は右方向でも左方向でも構わない.例中の「初年度決算も」の FPT は 5, 6 の注視時間の合計である. Second-Pass Time (SPT) は,注視領域に初めて視線が停留し,注視領域から出たあと,2 回 目以降に注視領域に停留する総注視時間である.例中の「初年度決算も」の SPT は 9, 11 の注 視時間の合計である.尚,FPT + SPT が後に説明する Total Time になる.
Regression Path Time (RPT) は,注視領域に初めて視線が停留し,その後領域の右側の境界 を超えて次の領域に出るまでの総注視時間である.視線が領域の左側の境界を超えて戻った場 合の注視時間も,元の注視領域の RPT として合算する.例中の「初年度決算も」の RPT は 5, 6, 7, 8, 9 の注視時間の合計である.左側に戻り再度注視領域に停留しない場合も合算する.つ まり,「初年度決算も」に対する 9 の視線停留がない場合の RPT は 5, 6, 7, 8 の注視時間の合 計となる.
Total Time (TOTAL) は注視領域に視線が停留する総注視時間である.例中「初年度決算も」 の TOTAL は 5, 6, 9, 11 の注視時間の合計である. テキスト生起順データにおいて,サッケード(跳躍眼球運動)の時間は集計しない.これら の時間情報を各種情報とともに CSV 形式に整形して公開する.公開データにおいては,平均 読み時間や標準偏差などを用いたトリミングなどの時間情報削除処理は実施していない. データは,時間情報を元テキストの情報・実験協力者の情報などとともに読み時間の種類ご との CSV 形式のデータである.表 3 左にデータ形式を示す. 出現書字形 (surface: factor) は実験協力者に呈示した文字列である.国語研文節単位にした もので全角空白は除去する. 読み時間 (time: int) は各実験で得た時間情報である.自己ペース読文法の場合は実験協力 者がその文節を見ていた時間である.視線走査法の場合は前小節で示した First Fixation Time (FFT), First-Pass Time (FPT), Second-Pass Time (SPT), Regression Path Time (RPT), Total Time (Total) の 5 種類のいずれかである.単位はミリ秒とする.読み時間の種類 (measure: factor) として{‘SelfPaced’, ‘EyeTrack:FFT’, ‘EyeTrack:FPT’, ‘EyeTrack:SPT’, ‘EyeTrack:RPT’, ‘EyeTrack:Total’} を定義する.尚,配布データは読み時間の種類ごとに 1 ファイル作成する. 対数読み時間 (logtime: num) は time の常用対数をとったものである.
文字数 (length: int) は,呈示した文節の出現書字形 surface を構成する文字の数である. 注視対象の面積に相当する.文節境界の有無 (space: factor) は呈示した画面に文節境界に半角 スペースがあるかないかを表す.係り受け関係 (dependent: int) は当該文節に係る文節数.文 節係り受けは人手で付与したもの (Asahara and Matsumoto 2016) を重ね合わせた.
記事に関するデータとして sample, article, metadata orig, metadata の 4 つを整備した. サンプル名 (sample: factor) は,各セッションごとに準備した記事ユニットで{A,B,C,D} から
なる.各ユニットは新聞記事 5–6 件から構成されている.記事情報 (article: factor) は,記事 単位の一意な識別子で,BCCWJ のアノテーション優先順位・BCCWJ 内サンプル ID・記事番 号をアンダースコアで連結したものとする.文書構造タグ (metadata orig: factor) は BCCWJ 内文書構造タグで,BCCWJ の XML の ancestor axis にあるタグ情報をスラッシュで連結した ものである.メタデータ (metadata: factor) は 前述の metadata orig から記事の特性のみを抽 出したものである.{authorsData (著者情報),caption (キャプション),listItem (リスト), profile (プロフィール),titleBlock (タイトル領域),未定義} のいずれかであり,BCCWJ 内 の文書構造タグの誤り・欠落を人手で修正したものである.
次に記事や画面の呈示順の情報について説明する.セッション順 (sessionN: int) は実験法ごと に文節境界空白有と文節境界空白無の 2 種類のセッションの順序を表す.記事呈示順 (articleN: int) はセッションごとの記事の呈示順 (1–5) を表す.画面呈示順 (screenN: int) は複数の画面 にわたる記事があり,記事ごとの画面呈示順を表す.行呈示順 (lineN: int) は画面ごとの行呈 示順 (1–5) であり,画面上の垂直方向の位置を表す.文節呈示順 (bunsetsuN: int) は行ごとの 文節呈示順である,画面上の水平方向の位置を表す.これらの呈示順情報により画面推移上の 一意な識別が可能である. また,文頭の文節は常に係り受けの数が 0 であり,文末の文節は係り受けの数が多い傾向にあ る.また,画面レイアウト上,最左要素・最右要素・右から 2 番目の要素は眼球運動中に「復帰改 行」の操作の影響がある.この問題を扱うために,レイアウト情報として,最左要素 (is first: bool)・最右要素 (is last: bool)・右から 2 番目の要素 (is second last: bool) を固定要因とす る.sample screen は,画面に対する一意な識別子である. 実験協力者 ID (subj: factor) は実験協力者を表示する一意な識別子である.実験協力者の特 性として 2 つの情報を持つ.1 つはリーディングスパンテスト得点 (rspan: num) であり,1.5–5.0 の 0.5 刻みの値を持つ.もう 1 つは語彙数テストの結果 (voc: num) であり,オリジナルの結果 を 1,000 語で割ったもの (37.1–61.8) である. 視線走査法の場合にはゼロ秒(注視されていない文節)は排除して集計した.
5.2
BCCWJ-Infostr: 『現代日本語書き言葉均衡コーパス』に対する情報の
状態アノテーション
本節では BCCWJ に対する情報の状態アノテーション BCCWJ-Infostr (Miyauchi et al. 2018; 宮内 他 2018) について概説する.同データでは名詞句(文節)に対して 3 節に示した 7 種類の 情報の状態を付与する.
• 情報状態 (infostatus:is) • 定性 (definiteness:def) • 特定性 (specificity:spec)
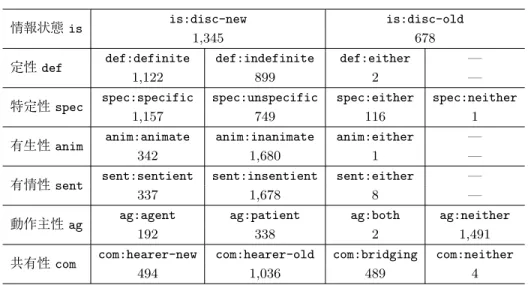
• 有生性 (animacy:ani) • 有情性 (sentience:sent) • 動作主性 (agentivity:ag) • 共有性 (commonnness:com) 情報状態は名詞句が談話文脈中で新情報か旧情報かの区別である.書き手が新しい情報とし て提示しているものを未出 is:disc-new と呼び,書き手が談話文脈中に既に情報として提示し ているものを既出 is:disc-old と呼ぶ.同情報は,BCCWJ に対する共参照情報アノテーショ ン (BCCWJ-PAS) などから展開することができる. 定性は,読み手が名詞句の参照対象が特定できるか否か (Lyons 1999; Heim 2011) を表す分 類である.ある名詞句の参照対象を読み手が特定可能であると書き手が想定している場合に定 def:definite とし,そうでない場合に不定 def:indefinite とする.特定性は,書き手が名詞 句の参照対象を特定しているか否か (von Heusinger 2011) を表す分類である.ある名詞句の参 照対象が唯一無二もしくは書き手が特定可能であるとみなしている場合に特定 spec:specific とし,そうでない場合に spec:unspecific とする.定性と特定性はアノテーション時には前後 3 文を読んだうえでタグ付けを行う. 有生性は名詞句の参照対象が生きているか否かの区別である.生物(ヒト,動物)は有生 ani:animate で,無生物(植物を含む)は無生 ani:inanimate とする.アノテーション時には 名詞句単体で評価する.似た分類で有情性がある.有情性は名詞句の参照対象が感情を持つか どうかを表し,他言語における有生性と対照して,日本語学で議論されている概念である.例 えば,動詞「ある」「いる」のどちらが利用できるかにより識別される.有生性と区別するため に名詞句とその係り先の述語の対をもって,有情 sent:sentient か無情 sent:insentient か を区別する. 動作主性は,名詞句がある状況でどのような役割を担うかを表す分類である.名詞句の参照 対象が意思をもって行動する場合に動作主 ag:agent とし,ある動作により変化を伴う場合に 被動作主 ag:patient とする.どちらでもないものを ag:neither とする.1 つの名詞句が主節 述語と従属節述語の両方と格関係を持つ場合がある.この場合に動作主であって被動作主でも あるもの ag:both を許す. 共有性は,聞き手が参照対象を既に知っていると書き手が仮定しているかを表す分類である. 聞き手が既に知っていると書き手が仮定している場合に既知 com:hearer-old とし,聞き手が 知らないと書き手が仮定している場合に未知 com:hearer-new とする.また,ブリッジングな どで聞き手が想定可能であると書き手が仮定している場合には想定可能 com:bridging とする. アノテーション時には,作業者は世界知識を用いながら判定する. 表 4 に,BCCWJ-EyeTrack と重ね合わせた情報の状態のラベルの基礎統計を示す.文脈 によって判断ができず,どちらでもよいことを表す *:either を定性 (def:either),特定性
表 4 情報の状態の基礎統計
情報状態 is is:disc-new is:disc-old
1,345 678
定性 def def:definite def:indefinite def:either —
1,122 899 2 —
特定性 spec spec:specific spec:unspecific spec:either spec:neither
1,157 749 116 1
有生性 anim anim:animate anim:inanimate anim:either —
342 1,680 1 —
有情性 sent sent:sentient sent:insentient sent:either —
337 1,678 8 —
動作主性 ag ag:agent ag:patient ag:both ag:neither
192 338 2 1,491
共有性 com com:hearer-new com:hearer-old com:bridging com:neither
494 1,036 489 4
(spec:either),有生性 (ani:either),有情性 (sent:either),動作主性 (ag:either) に対して 定義する.また,名詞句によっては定義することが不適切な場合に,どちらでもないことを表 す neither を特定性 (spec:neither),動作主性 (ag:neither),共有性 (com:neither) に対し て定義する.
表 3 右に統計分析に利用するデータについて示す.なお,分析対象は一般化線形混合モデル に基づく分析結果 (Asahara 2017) に基づき,各要因の相関関係をみながら,情報状態 (is:*)・ 定性 (def:*)・有生性 (ani:*)・共有性 (com:*) の 4 つに限定して行った.具体的には定性・特 定性間と有生性・有情性間に強い相関関係があり,モデル化において多重共線性の問題が発生 する.さらに動作主性については,ag:neither が多く,一般化線形混合モデルにおいて効果が 見られなかったために排除した.交互作用については一般化線形混合モデル構築時に収束した モデルが構築できなかったために今回も考慮しない.今回は,視線走査法の結果のみについて 検討する.統計分析においては,名詞句でない文節も検討し,それぞれ*:NIL とする.また,ラ ベルとして*:neither がついているものについては,統計処理においては*:neither のままと した.
5.3
Bayesian Linear Mixed Model: 統計分析手法
先に述べた読み時間データ BCCWJ-EyeTrack と情報の状態アノテーション BCCWJ-Infostr を重ね合わせたものを ベイジアン線形混合モデルにより分析を行う (Sorensen et al. 2016).帰 無仮説を立てた仮説論証的な分析においては一般化線形混合モデルのような頻度主義的な考え 方に基づき,有意差を検証する試みが一般的である.しかし本稿のような仮説探索的な分析に
おいては,ベイズ主義的な考え方に基づき,強い証拠を探索する試みが適切だと考え,ベイジア ン線形混合モデルを用いる.前処理として,手修正した metadata3が{authorsData, caption, listItem, profile, titleBlock} であるものを削除した.また読み時間データから全てのゼロ ミリ秒のデータポイントを排除した.統計分析は,読み時間 time を lognormal 関数により, レイアウト情報・提示順・係り受けの数・情報の状態などを固定要因とし,記事と被験者をラ ンダム要因として,ベイズ推定を行う.
具体的には次のような式を用いる: time∼ lognormal(µ, σ)
µ = α + βlength· length(x) + βspace· χspace(x) + βdependent· dependent(x) + βsessionN· sessionN(x) + βarticleN· articleN(x) + βscreenN· screenN(x) + βlineN· lineN(x) + βsegmentN· segmentN(x)
+ βis first· χ
is first(x) + βis last· χis last(x) + βis second last· χis second last(x) +∑ is:∗ βis:∗· χis:∗(x) + ∑ def:∗ βdef:∗· χdef:∗(x) + ∑ ani:∗ βani:∗· χani:∗(x) +∑ com:∗ βcom:∗· χcom:∗(x) + ∑ a(x)∈A γarticle=a(x)+ ∑ s(x)∈S γsubj=s(x).
ここで time は推定する読み時間である. lognormal は rstan の 対数正規分布関数である.σ は lognormal の標準偏差 µ は lognormal の平均で線形式で表される.α は線形式の切片を表す.
βlength は文節の長さ length(x) の傾きである.βspace は空白の有無 χ
space(x) 4 の傾きである.
βsessionN, βarticleN, βscreenN, βlineN, βsegmentNは,呈示順 sessionN(x), articleN(x), screenN(x), lineN(x), segmentN(x) に対する固定要因である.βis first, βis last, βis second last は,レイア ウト χis first(x), χis last(x), χis second last(x) に対する固定要因である.
∑
is:∗βis:∗· χis:∗(x) は 情報状態に対する固定要因,∑def:∗βdef:∗· χ
def:∗(x) は定性に対する固定要因,∑ani:∗βani:∗·
χani:∗(x) は有生性に対する固定要因, ∑ com:∗β com:∗· χ com:∗(x) は共有性に対する固定要因である. ∑
a(x)∈Aγarticle=a(x)は,x の記事を意味する a(x) に対するランダム要因である.
∑ s(x)∈Sγsubj=s(x) は, x の被験者識別子を意味する s(x) に対するランダム要因である.ベイズ推定はウォーム アップ(100 回)のあと,イテレーション 5,000 回を 4 chains 実施し,全てのモデルは収束した. なお,一般化線形混合モデルにおけるモデリングは (Asahara 2017) を参照されたい.一般化 3 BCCWJ の原版のメタデータ (metadata orig) が不完全であったために改めてタグ付けしたもの. 4 χ A は指示関数 χA(x) = { 1 if x∈ A, 0 if x̸∈ A.
線形混合モデルにおいては AIC による前進的選択法に基づき,6 種類の読み時間データ全てで 収束したものを報告している.その過程で各変数の交互作用についても検討したが,うまく収 束させたモデルが構築できなかった.今回のベイジアンモデルにおいては,既発表の読み時間 全体の傾向で用いた固定効果(レイアウト情報・呈示順・係り受けの数)に対して,情報の状 態として情報状態・共有性・定性・有生性の 4 種に限定して分析を行う.これは,一般化線形 混合モデルを構築する際に問題となった,定性と特定性の相関・有生性と有情性の相関に基づ く多重共線性の問題と,動作主性において効果が観察されなかったことに基づき,回帰式を構 成した.
6
結果と考察
6.1
結果
図 3(付録表 6)に Total Time の情報の状態以外の固定要因に対する係数を示す.グラフは, 中央のラインで事後平均値を,曲線でカーネル密度推定量を,色付きの背景で 50% 区間を表 す.βlengthが正であることから,文字数が増えるにつれて,視線が停留する面積が増えるため に停留時間が長くなる.βspaceが負であることから,文節間に空白を入れたほうが読み時間が 短くなる.βdependentが負であることから,修飾語をたくさん持つ文節が読み時間が短くなる.βsessionN, βscreenN, βlineN, βsegmentN が負であることから,実験が進むにつれて慣れていくことに より,読み時間が短くなる効果が見られる.なお,βarticleNに差が見られないのは,記事の順 をセットごとにある程度固定して行ったうえで,記事に対するランダム要因 γarticle=a(x)を入 れたために,これに吸収されたと考える.βis first, βis last, βis second last は,レイアウト要因 で先頭要素で読み時間を要し,末尾要素を読み飛ばしたうえで,末尾から 2 つ目の要素で読み 戻しの眼球運動の準備のために時間がかかる傾向がみられる.これらは,情報の状態要因なし の分析 (Asahara et al. 2016) と同様の結果である.
図 4(および付録表 7)に Total Time の情報の状態の固定要因に対する係数を示す. 名詞句以外である β∗:NILは読み時間が短い.別の調査において,名詞句以外と名詞句とを比 較すると名詞句のほうが読み時間が長くなる傾向がわかっており (Asahara and Kato 2017),そ れの追試となった.
情 報 の 新 旧 の 観 点 に お い て は ,情 報 状 態 と 共 有 性 の 双 方 ,新 情 報 βinfo:disc-new,
βcom:hearer-new のほうが旧情報 βinfo:disc-old, βcom:hearer-old よりも時間がかかるこ
とがわかった.旧情報は予測がつくため処理が早くなる一方,新情報は処理に時間がかかるため であろう.差異については情報状態よりも共有性のほうが明確な差がある.ブリッジング(想 定可能)βcom:bridgingも新情報より読み時間が短い傾向がある.
が長い傾向がある.また,有生性においては,有生 βani:animateのほうが,無生 βani:inanimateよ りも読み時間が短い傾向がある.
Total Time のみでは眼球運動の仔細について検討できないために,以下では First Fixation Time, First Path Time, Second Pass Time, Regression Path Time について検討する.
First Fixation Time (図 5・付録表 8)では,領域の最初の停留のみを評価する.有生性と無 生性の差が大きい傾向がある.また,情報の新旧において,情報状態では差がないが,共有性 においては差がみられることがわかる.First Pass Time (図 6・付録表 9)では,領域内の最初 の停留から,領域外に出るまでの停留時間の合計を評価する.ほぼ Total Time と同様な傾向が みられた.Second Pass Time (図 7・付録表 10)では,2 回目以降の視線停留の合計を評価す
図 3 Total Time: 情報の状態以外の固定要因 図 4 Total Time: 情報の状態の固定要因
る.定性,有生性,共有性で差がみられる.Regresion Path Time(図 8・付録表 11)では,領 域の最初の停留から,領域外を右に出るまでの停留時間の合計を評価する.有生性の差がもっ とも大きい.
6.2
考察
表 5 に読み時間型ごとの情報の状態の固定要因の事後平均の差分を事後標準偏差とともに
図 7 Second Pass Time: 情報の状態の固定要因 図 8 Regression Path Time: 情報の状態の固定
要因 表 5 情報の状態の固定要因の差分
Total First Fixation First Pass Second Pass Regression Path 情報状態 差−0.010 差 +0.001 差−0.010 差−0.007 差 +0.006 info:disc-new SD 0.036 SD 0.030 SD 0.029 SD 0.028 SD 0.029 info:disc-old SD 0.036 SD 0.030 SD 0.030 SD 0.029 SD 0.030 定性 差 +0.023 差 +0.005 差 +0.015 差−0.015 差 +0.006 def:definite SD 0.034 SD 0.061 SD 0.031 SD 0.029 SD 0.029 def:indefinite SD 0.034 SD 0.061 SD 0.031 SD 0.030 SD 0.030 有生性 差−0.031 差−0.031 差−0.034 差−0.027 差−0.038 ani:animate SD 0.033 SD 0.065 SD 0.030 SD 0.030 SD 0.030 ani:inanimate SD 0.033 SD 0.065 SD 0.030 SD 0.030 SD 0.030 共有性 差 +0.036 差−0.011 差 +0.031 差 +0.035 差 +0.026 com:hearer-new SD 0.031 SD 0.025 SD 0.028 SD 0.032 SD 0.028 com:hearer-old SD 0.033 SD 0.025 SD 0.028 SD 0.029 SD 0.030 共有性 差 +0.042 差 +0.007 差 +0.039 差 +0.025 差 +0.010 com:hearer-new SD 0.031 SD 0.025 SD 0.028 SD 0.032 SD 0.028 com:bridging SD 0.030 SD 0.025 SD 0.026 SD 0.027 SD 0.027
示す.
まず,共参照などに基づく情報状態は安定した差がどの読み時間型にも出ていないことがわ かる.冠詞推定に重要な定性についても,1 標準偏差を超える差は見られない.
有生性においては,すべての読み時間型において有生名詞句が無生名詞句より読み時間が短 い傾向があり,First Pass Time と Regression Path Time においては 1 標準偏差を超える差で あった.
共有性においては,情報の新旧の観点 (com:hearer-new, com:hearer-old) では,First Fixation を除く読み時間型で新情報のほうが時間がかかる傾向にあり,Total Time,First Pass Time,Second Pass Time において 1 標準偏差を超える差があった.ブリッジングの観点 (com:hearer-new, com:bridging) では, すべての読み時間型で新情報のほうが時間がかかる傾向にあり,Total Time,First Pass Time において 1 標準偏差を超える差があった.
有生性はシソーラスなど語彙言語資源からその情報の性質を推定できる一方,共有性は共参 照情報や世界知識を入れてもその性質を推定することは難しい.しかしながら,今回得られた 知見は読み時間などから読み手側の情報の新旧を読み手の反応である眼球運動から推定できる 可能性を示唆する.
7
おわりに
本稿では,明確に表出しない日本語の名詞句の情報の状態を推定することを目標として,読 み時間と日本語の名詞句の情報の状態について対照比較した.読み時間は視線走査装置を用い てミリ秒単位で計測を行ったデータを利用した.名詞句の情報の状態は,情報の新旧について 書き手の観点による情報状態と読み手の観点による共有性のほか,定性や有生性について検討 した.ベイジアン線形混合モデルによる分析の結果,共有性や有生性の特性の違いにより読み 時間に差があることがわかった.情報の状態のうち,残念ながら定性については読み時間に明 確な差が見られなかったが,表層の言語情報からはとらえにくい共有性に差があることが重要 である.読み時間の事後平均の差は事後標準偏差 1 程度のものであるが,周辺の言語情報とと もに機械学習モデルの特徴量として用いることにより共有性の違いを明らかにできる可能性が あることが示唆される. 本研究は,言語学・認知科学的な観点に基づく調査であるが,工学研究者に向けて 3 点言及 する.1 点目は,英語の冠詞推定においては,定・不定を同定する必要があり,多くの研究は情 報の新旧に基づいて処理されており,関連はするが,本質的には異なる名詞句の性質を用いて いる.2 点目は,情報の新旧には書き手視点と読み手視点の 2 つの考え方(情報状態・共有性) があり,本研究は読み手側の反応である読み時間を入れることで,既存の技術では適切に扱わ れてこなかった読み手視点の情報の新旧を得ようとするものである.3 点目は,情報抽出や自動要約などのアプリケーションにおいて本質的に重要なのは,書き手視点の談話上の情報の新 旧ではなく,アプリケーション利用者側の読み手視点の新旧である.読み手視点の新旧を,読 み手側の反応を取り入れながら適切にモデル化することが工学応用に求められている. 今後の研究の方向性として,共通の読み手を想定している新聞記事ではなく,共通の読み手 を想定していない読み手ごとに理解の差がある文書を用いて,読み時間に差があるかを検討し たい.これにより読み手ごとの情報抽出・自動要約が眼球運動計測により実現する可能性を調 査する. 他の研究の方向性として,文章の可読性評価が考えられる.文章の可読性は,文字(漢字)や 語彙の難易度および頻度に基づいて統制し,調査方法も評定評価等による研究が多かった.本 研究は可読性に対する反応である読み時間を直接評価するものであり,各文章の可読性は記事 のランダム要因として得ることができる.書誌情報と対照比較することにより可読性の傾向を 分析したい.
謝 辞
本研究の一部は,国立国語研究所基幹型共同研究プロジェクト「コーパスアノテーションの 基礎研究」,国立国語研究所コーパス開発センター共同研究プロジェクト「コーパスアノテー ションの拡張・統合・自動化に関する基礎研究」,国立国語研究所の所長裁量経費,および情 報・システム研究機構の機構間連携・文理融合プロジェクト「わかりやすい情報伝達の実現に向 けた言語認知機構の解明とその工学的応用」によるものです.本研究は JSPS 科研費 25284083, 17H00917, 18H05521 の助成を受けたものです.なお,本論文は The 31st Pacific Asia Conference on Language, Information and Computation PACLIC 31(2017) の発表 “Between Reading Time and Information Structure” をもとに,ベイ ジアン線形混合モデルにより統計分析をしなおしたものです.3 節は国立国語研究所論集 16 号 「『現代日本語書き言葉均衡コーパス』への情報構造アノテーションとその分析」,4 節は言語学 会論文誌『言語研究』に投稿中の内容を含みます.これは査読者の指示により内容に含めたも ので,著者には自己剽窃の意図はありません.
参考文献
Asahara, M. (2017). “Between Reading Time and Information Structure.” In Proceedings of the
31st Pacific Asia Conference on Language, Information and Computation, pp. 15–24. The
Asahara, M. and Kato, S. (2017). “Between Reading Time and Syntactic/Semantic Categories.” In Proceedings of the The 8th International Joint Conference on Natural Language
Process-ing, pp. 404–412.
Asahara, M. and Matsumoto, Y. (2016). “BCCWJ-DepPara: A Syntactic Annotation Treebank on the ‘Balanced Corpus of Contemporary Written Japanese’.” In Proceedings of the 12th
Workshop on Asian Langauge Resources (ALR12), pp. 49–58.
浅原正幸,大村舞 (2016). BCCWJ-DepParaPAS:『現代日本語書き言葉均衡コーパス』係り受 け・並列構造と述語項構造・共参照アノテーションの重ね合わせと可視化. 言語処理学会 第 22 回年次大会発表論文集, pp. 489–492.
Asahara, M., Ono, H., and Miyamoto, E. T. (2016). “Reading-Time Annotations for ‘Balanced Corpus of Contemporary Written Japanese’.” In Proceedings of COLING 2016, the 26th
International Conference on Computational Linguistics: Technical Papers, pp. 684–694.
Barrett, M., Bingel, J., Keller, F., and Søgaard, A. (2016). “Weakly Supervised Part-of-speech Tagging Using Eye-tracking Data.” In Proceedings of the 54th Annual Meeting of the
Asso-ciation for Computational Linguistics (Volume 2: Short Papers), pp. 579–584.
Demberg, V. and Keller, F. (2008). “Data from Eye-tracking Corpora as Evidence for Theories of Syntactic Processing Complexity.” Cognition, 109 (2), pp. 193–210.
Gibson, E. (2008). “Linguistic Complexity: Locality of Syntactic Dependencies.” Cognition, 68, pp. 1–76.
G¨otze, M., Weskott, T., Endriss, C., Fiedler, I., Hinterwimmer, S., Petrova, S., Schwarz, A., Skopeteas, S., and Stoel, R. (2007). “Information Structure.” In Dipper, S., G¨otze, M., and Skopeteas, S. (Eds.), Information Structure in Cross-linguistic Corpora: Annotation
Guidelines for Phonology, Morphology, Syntax, Semantics and Information Structure, Vol. 7,
pp. 147–187. Universit¨atsverlag Potsdam.
Hale, J. (2001). “A Probabilistic Earley Parser as a Psycholinguistic Model.” In Proceedings of
the 2nd Conference of the North American Chapter of the Association for Computational Linguistics, Vol. 2, pp. 159–166.
Heim, I. (2011). “Definiteness and Indefiniteness.” In von Heusinger, K., Maienborn, C., and Portner, P. (Eds.), Semantics: An International Handbook of Natural Language Meaning, Vol. 2, pp. 996–1025. Mouton de Gruyter.
Just, M. A., Carpenter, P. A., and Woolley, J. D. (1982). “Paradigms and Processes in Reading Comprehension.” Journal of Experimental Psychology: General, 3, pp. 228–238.
加藤祥,浅原正幸,山崎誠 (2017). 『現代日本語書き言葉均衡コーパス』に対する分類語彙表 番号アノテーション. 言語処理学会第 23 回年次大会発表論文集, pp. 306–309.
Kennedy, A., Hill, R., and Pynte, J. (2003). “The Dundee Corpus.” In Proceedings of the 12th
European Conference on Eye Movement.
Kennedy, A. and Pynte, J. (2005). “Parafoveal-on-foveal Effects in Normal Reading.” Vision
Research, 45, pp. 153–168.
Klerke, S., Mart´ınez Alonso, H., and Søgaard, A. (2015). “Looking Hard: Eye Tracking for Detecting Grammaticality of Automatically Compressed Sentences.” In Proceedings of the
20th Nordic Conference of Computational Linguistics (NODALIDA 2015), pp. 97–105.
Lyons, C. (1999). Definiteness. Cambridge University Press, Cambridge.
Maekawa, K., Yamazaki, M., Ogiso, T., Maruyama, T., Ogura, H., Kashino, W., Koiso, H., Yamaguchi, M., Tanaka, M., and Den, Y. (2014). “Balanced Corpus of Contemporary Written Japanese.” Language Resources and Evaluation, 48, pp. 345–371.
Matsumoto, S., Asahara, M., and Arita, S. (2018). “Japanese Clause Classification Annotation on the ‘Balanced Corpus of Contemporary Written Japanese’.” In Proceedings of Workshop
on Asian Language Resources 13 (ALR13), pp. 1–8.
松吉俊 (2014). 否定の焦点情報アノテーション. 自然言語処理, 21 (2), pp. 249–270.
宮内拓也,浅原正幸,中川奈津子,加藤祥 (2018). 『現代日本語書き言葉均衡コーパス』への 情報構造アノテーションとその分析. 国立国語研究所論集, 16.
Miyauchi, T., Asahara, M., Nakagawa, N., and Kato, S. (2018). “Annotation of Information Structure on “The Balanced Corpus of Contemporary Written Japanese.” In Computational
Linguistics: 15th International Conference of the Pacific Association for Computational Lin-guistics, PACLING 2017, Yangon, Myanmar, August 16–18, 2017, Revised Selected Papers,
pp. 155–165.
乙武北斗,永田亮 (2016). 冠詞推定のための情報構造仮説の検討. 言語処理学会第 22 回年次大 会発表論文集, pp. 493–496.
Palmer, M., Gildea, D., and Kingsbury, P. (2005). “The Proposition Bank: An Annotated Corpus of Semantic Roles.” Conputational Linguistics, 31 (1), pp. 71–105.
Prasad, R., Dinesh, N., Lee, A., Miltsakaki, E., Robaldo, L., Joshi, A., and Webber, B. (2008). “The Penn Discourse TreeBank 2.0.” In Proceedings of the 6th International Conference on
Language Resources and Evaluation (LREC’08), pp. 2961–2968.
Prasad, R., Webber, B., Lee, A., Pradhan, S., and Joshi, A. (2015). “Bridging Sentential and Discourse-level Semantics through Clausal Adjuncts.” In Proceedings of the 1st
Work-shop on Linking Computational Models of Lexical, Sentential and Discourse-level Semantics,
pp. 64–69.
A Tutorial for Psychologists, Linguists, and Cognitive Scientists.” Quantitative Methods for Psychology, 12, pp. 175–200. 竹内裕己,河合敦夫,細田直見,永田亮 (2013). 前方文脈を考慮した冠詞の推定. 言語処理学会 第 19 回年次大会発表論文集, pp. 717–720. 植田禎子,飯田龍,浅原正幸,松本裕治,徳永健伸 (2015). 『現代日本語書き言葉均衡コーパ ス』に対する述語項構造・共参照アノテーション. 第 8 回コーパス日本語学ワークショッ プ, pp. 205–214.
Van Gompel, R. P., Fischer, M. H., Murray, W. S., and Hill, R. L. (2007). “Eye-movement Research: An Overview of Current and Past Developments.” Eye Movements: A Window
on Mind and Brain, pp. 1–28.
von Heusinger, K. (2011). “Specificity.” In von Heusinger, K., Maienborn, C., and Portner, P. (Eds.), Semantics: An International Handbook of Natural Language Meaning, Vol. 2, pp. 1058–1087. Mouton de Gruyter.
付録
A
固定要因の詳細
表 6, 7, 8, 9, 10, 11 では固定要因の係数の推定値を示す.各列の意味は以下の通り: • Parameter: 推定する固定要因 • Rhat: 収束判定指標(1.1 以下を収束とみなす) • n eff: 有効サンプル数 • mean: 事後平均値 • sd: 事後標準偏差 • se mean: 事後平均の標準誤差 • 2.5%: 2.5%位値 • 50%: 中央値 • 97.5%: 97.5%位値表 6 Total Time の係数(情報の状態以外)
Parameter Rhat n eff mean sd se mean 2.5% 50% 97.5%
alpha 1.001 3,146 5.899 0.110 0.002 5.687 5.899 6.110 beta length 1.000 19,600 0.083 0.002 0.000 0.080 0.083 0.087 beta space 1.000 19,600 −0.066 0.012 0.000 −0.090 −0.066 −0.044 beta dependent 1.000 19,600 −0.068 0.007 0.000 −0.081 −0.068 −0.055 beta sessionN 1.000 19,600 −0.074 0.012 0.000 −0.097 −0.074 −0.051 beta articleN 1.001 6,813 −0.004 0.014 0.000 −0.033 −0.004 0.023 beta screenN 1.000 19,600 −0.043 0.006 0.000 −0.054 −0.043 −0.032 beta lineN 1.000 19,600 −0.032 0.004 0.000 −0.041 −0.032 −0.023 beta segmentN 1.000 19,600 −0.027 0.003 0.000 −0.033 −0.027 −0.021 beta is first 1.000 19,600 0.151 0.018 0.000 0.115 0.151 0.186 beta is last 1.000 19,600 −0.015 0.019 0.000 −0.053 −0.015 0.022
beta is second last 1.000 19,600 0.081 0.017 0.000 0.048 0.081 0.114
sigma 1.000 19,600 0.655 0.004 0.000 0.647 0.655 0.663 sigma article 1.001 2,616 0.088 0.019 0.000 0.058 0.085 0.133 sigma subj 1.001 3,830 0.298 0.047 0.001 0.221 0.292 0.407 sigma info 1.005 856 0.041 0.023 0.001 0.018 0.036 0.086 log-posterior 1.003 1,726 −922.740 7.377 0.178 −938.377 −922.286 −909.745 表 7 Total Time の係数(情報の状態のみ)
Parameter Rhat n eff mean sd se mean 2.5% 50% 97.5%
beta info:NIL 1.000 19,600 −0.021 0.042 0.000 −0.105 −0.021 0.061 beta info:disc-new 1.000 8,401 0.006 0.036 0.000 −0.059 0.006 0.068 beta info:disc-old 1.000 8,183 0.016 0.036 0.000 −0.046 0.015 0.082 beta def:NIL 1.000 18,658 −0.021 0.041 0.000 −0.105 −0.021 0.060 beta def:definite 1.000 17,256 0.022 0.034 0.000 −0.042 0.021 0.094 beta def:indefinite 1.000 17,655 −0.001 0.034 0.000 −0.072 0.000 0.063 beta ani:NIL 1.001 6,970 −0.021 0.046 0.001 −0.103 −0.021 0.060 beta ani:animate 1.000 16,120 −0.005 0.033 0.000 −0.072 −0.004 0.059 beta ani:inanimate 1.000 14,746 0.026 0.033 0.000 −0.037 0.025 0.092 beta com:NIL 1.000 9,276 −0.021 0.042 0.000 −0.104 −0.021 0.061 beta com:bridging 1.000 11,774 −0.011 0.030 0.000 −0.070 −0.010 0.044 beta com:hearer-new 1.000 8,762 0.031 0.031 0.000 −0.023 0.029 0.093 beta com:hearer-old 1.000 8,330 −0.005 0.033 0.000 −0.072 −0.002 0.051 beta com:neither 1.000 14,152 0.007 0.041 0.000 −0.069 0.006 0.089
表 8 First Fixation Time の係数(情報の状態のみ)
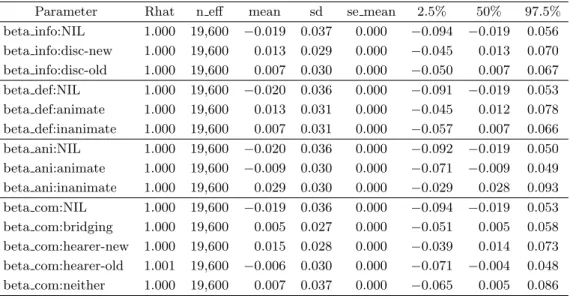
Parameter Rhat n eff mean sd se mean 2.5% 50% 97.5%
beta info:NIL 1.011 246 −0.001 0.085 0.005 −0.049 −0.006 0.041 beta info:disc-new 1.000 3,701 0.003 0.030 0.000 −0.033 0.003 0.040 beta info:disc-old 1.000 3,723 0.002 0.030 0.000 −0.035 0.002 0.039 beta def:NIL 1.012 230 −0.000 0.111 0.007 −0.051 −0.006 0.039 beta def:definite 1.010 282 0.008 0.061 0.004 −0.032 0.006 0.044 beta def:indefinite 1.009 285 0.003 0.061 0.004 −0.036 −0.000 0.039 beta ani:NIL 1.001 1,243 −0.005 0.053 0.002 −0.050 −0.006 0.039 beta ani:animate 1.008 513 −0.010 0.065 0.003 −0.053 −0.011 0.022 beta ani:inanimate 1.007 502 0.021 0.065 0.003 −0.015 0.017 0.060 beta com:NIL 1.010 375 −0.011 0.104 0.005 −0.051 −0.006 0.038 beta com:bridging 1.003 1,354 −0.007 0.025 0.001 −0.045 −0.007 0.024 beta com:hearer-new 1.002 1,377 −0.000 0.025 0.001 −0.037 −0.001 0.035 beta com:hearer-old 1.002 1,349 0.011 0.025 0.001 −0.024 0.010 0.048 beta com:neither 1.002 1,409 0.004 0.029 0.001 −0.039 0.003 0.053
表 9 First Pass Time の係数(情報の状態のみ)
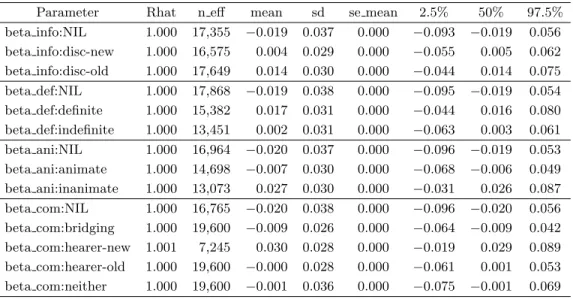
Parameter Rhat n eff mean sd se mean 2.5% 50% 97.5%
beta info:NIL 1.000 17,355 −0.019 0.037 0.000 −0.093 −0.019 0.056 beta info:disc-new 1.000 16,575 0.004 0.029 0.000 −0.055 0.005 0.062 beta info:disc-old 1.000 17,649 0.014 0.030 0.000 −0.044 0.014 0.075 beta def:NIL 1.000 17,868 −0.019 0.038 0.000 −0.095 −0.019 0.054 beta def:definite 1.000 15,382 0.017 0.031 0.000 −0.044 0.016 0.080 beta def:indefinite 1.000 13,451 0.002 0.031 0.000 −0.063 0.003 0.061 beta ani:NIL 1.000 16,964 −0.020 0.037 0.000 −0.096 −0.019 0.053 beta ani:animate 1.000 14,698 −0.007 0.030 0.000 −0.068 −0.006 0.049 beta ani:inanimate 1.000 13,073 0.027 0.030 0.000 −0.031 0.026 0.087 beta com:NIL 1.000 16,765 −0.020 0.038 0.000 −0.096 −0.020 0.056 beta com:bridging 1.000 19,600 −0.009 0.026 0.000 −0.064 −0.009 0.042 beta com:hearer-new 1.001 7,245 0.030 0.028 0.000 −0.019 0.029 0.089 beta com:hearer-old 1.000 19,600 −0.000 0.028 0.000 −0.061 0.001 0.053 beta com:neither 1.000 19,600 −0.001 0.036 0.000 −0.075 −0.001 0.069