DOI: http://doi.org/10.14947/psychono.38.2
多件法による上下法
岡 本 安 晴
日本女子大学
Up-down methods with more than two response categories
Yasuharu Okamoto
Japan Women s University
The up-down method of adaptive psychophysical measurement uses binary response categories, e.g., “stronger” and “weaker.” This study proposes that ratings using three response categories, e.g., “stronger,” “do not know,” and “weaker,” or four response categories, e.g., “stronger,” “probably stronger,” “probably weaker,” and “weaker,” should be used instead. Simulation experiments showed that the proposed methods were superior to the standard up-down method. Comparisons were made with respect to the root mean square error (RMSE). First, in the case of two re-sponse categories, the RMSEs of estimates made using a stochastic model were smaller than those derived using the standard arithmetic method based on simple averaging, except in one extreme case. Hence, comparison of two, three, and four response categories was made with respect to estimates made using stochastic models. The RMSEs of estimates of the point of subjective equality using three or four response categories were smaller than those using two response categories. The RMSEs of estimates of model slope parameters, where a just noticeable difference was calculated as a ratio of the parameter, were smaller with three or four response categories than with two response categories, except in two extreme cases.
Keywords: psychophysics, adaptive method, point of subjective equality, just noticeable difference, stochastic
model, Bayesian は じ め に 主観的等価点あるいは弁別閾を求める上下法におい て,2件法ではなく3件法あるいは4件法を用いることを 提案する。標準刺激に対して比較刺激の感覚の方が「強 い」か「弱い」かの判断が求められた場合に,観察者が 困難を訴える場合があることが指摘されている(池田, 2013; 神 作,1998)。Klein (2001) は,Kaernbach (2001) の「わからない/同じ」判断を許す3件法を評価すると ともに,彼自身は「わからない/同じ」判断を「多分よ り強い」判断と「多分より弱い」判断の 2つに分ける 4件法の方がよいとしている。 主観的等価点と弁別閾を与える心理測定関数(psycho-metric function: PF)を求める方法として高い評価を得て いる方法に恒常法がある(鳥居,2001)。この測定法は よく知られた方法であり,最も正確な方法であるとされ ている(Kingdom & Prins, 2010)。この恒常法において, 2件法より3件法あるいは4件法を用いる方が二乗平均 平方根誤差(root mean square error: RMSE)の観点から 望ましいことが報告されている(岡本,2017)。恒常法 では,PFの2つのパラメータの推定を行うのに必要な データの目安が400試行ぐらいとされている(Kingdom & Prins, 2010)。提示する比較刺激をパラメータの期待エ ントロピーを最小にするものとして選び,測定の効率を 図るものとしてPsi法(Kontsevich & Tyler, 1999)があり, 主観的等価点と弁別閾の2つのパラメータを同時に求め る方法として最も優れたもの(Kingdom & Prins, 2010) とされているが,比較刺激を選ぶために試行の度に毎回 期待エントロピーを計算する必要がある。 実験の実施が簡単であり,我が国の解説書で取り上げ られることが多く,近年優れた方法として用いられてい るものに上下法がある(相場・鳥居,2004; 大山・岩脇・ 宮埜,2005; 大山,2007; 繁桝,1998)。上下法では2件法 が用いられ,「強い」判断のときは次の比較刺激はより Copyright 2019. The Japanese Psychonomic Society. All rights reserved. Corresponding address. Professor Emeritus, Japan
Wom-en’s University, 2–8–1 Mejirodai, Bunkyo-ku, Tokyo 112– 8681, Japan. E-mail: [email protected]
弱い刺激が提示され,「弱い」判断のときは次の比較刺 激はより強い刺激が提示される。上下法において3件法 あるいは4件法(両者をまとめて多件法と呼ぶ)を用い た場合を2件法の場合と比較する。まず,3件法および 4件法を用いる上下法の手順と分析モデルについて説明 する。続いて,シミュレーション実験による比較を行 い,考察をまとめる。 手 順 本研究における上下法の手順を明記するために,2件 法の場合も含めて説明する。 第t試行における提示比較刺激値をXtで表し,標準刺 激値 Stdとの比較判断をRtで表す。比較判断は,2件法 の場合は比較刺激の感覚の方が「強い」あるいは「弱い」 であるが,それぞれ「+」あるいは「−」で表す。3件 法の場合の判断は,比較刺激の感覚の方が「強い」ある いは「弱い」に加えて「わからない/同じ」があるが, それぞれ「+」,「−」,「?」で表す。4件法の場合は, 比較刺激の感覚の方が「強い」あるいは「弱い」判断は 「+」あるいは「−」で表し,「多分強い」と「多分弱い」 の判断は「+?」と「−?」で表す。4件法は,観察者 の判断を2段に分けて求めることもできる。まず,提示 刺激が標準刺激より「強い」か「弱い」かの2件法で判 断を求め,続いてその判断についての確信度評定を「そ うである」あるいは「多分」と求める。この2件法判断 と確信度判断を組み合わせると,「強い」,「多分強い」, 「多分弱い」,「弱い」の4件法になる。 第t試行における刺激の変化量を∆tで表す。したがっ て,Xt+1=Xt±∆tである。刺激の変化量は,最初は大き くとり,試行が進むにつれて小さくとる(例えば,1/2 倍にする)が,ある値よりは小さくならないようにす る。すなわち, Δ Δ Δ ≥ Δ Δ Δ < Δ Δ Δ t t t t min t min t min 1 1 : , step size on t if , if rial t 1 1 2 2 1 2 + + = = である。 上下法は,次の刺激値が被験者に予測されやすいが, これを避けるための方法として2系列を用意して2つの 系列をランダムに混ぜて実施する二重上下法がある(大 山,2005)。本研究における上下法においても,二重上 下法を採用する。 二重上下法の各系列は,X1(1), X2(1), X3(1), . . . , および,X1(2), X2(2), X3(2), . . . , と上付き添え字を付けて表すことができる が,以下では2つの系列についての共通の説明において は上付き添え字を例えば(i)というように書き,X1(i), X2(i),
X3(i), . . . と記すことがある。このとき,提示刺激の決定手
続きは,以下のように記述できる。ここで,R(i)tおよび ∆t(i)は,刺激系列iの第t試行における比較判断および刺
激値の変化量を表す。
2件法(Up-down method with two response categories)
i
t response on trial t is stronger
R
response on trial t is weaker
“ ” + = “ ” - When R(i)t=+, X(i)t+1=Xt(i)−∆t(i)
when R(i)t=−, X(i)t+1=Xt(i)+∆t(i),
3件法(Up-down method with three response categories) i t
response on trial t is stronger
R response on trial t is equal or don t know response on trial t is weaker
? “ ” + “ ” “ ’ ” = “ ” - When R(i)t=+, X(i)t+1=Xt(i)−∆t(i),
When R(i)t=?, ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) Δ < Δ > i i i i t t t t i t i i i i t t t t X if X X X X if X X 1 1 1 , , , - + - - = + When R(i)t=−, X(i)t+1=Xt(i)+∆t(i)
4件法(Up-down method with four response categories) i t
response on trial t is stronger response on trial t is R
response on trial t is probably weaker response on trial t is weaker
? probably stronger ? “ ” + “ ” + = “ ” - “ ” - When R(i)t=+, X(i)t+1=Xt(i)−∆t(i)
When R(i)t=+? or −?, ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) Δ < Δ > i i i i t t t t i t i i i i t t t t X if X X X X if X X 1 1 1 , , - + - - = + When R(i)t=−, X(i)t+1=Xt(i)−∆t(i)
2 件法による上下法の場合,主観的等価点(point of subjective equality: PSE)は,提示刺激値の系列の方向の 変換点における平均値の平均で PSEが与えられる(大 山,1971, 2005; 鳥居,2001)。この方法は,容易に3件法 および4件法に拡張することができる。すなわち,
R(i)t−1≠+, Rt(i)=+ あるいは R(i)t−1≠−, Rt(i)=− のとき,平均値 ( )i ( )i t t X 1 X 2 -+ を算出し,これら平均値の平均を求めて PSEの値とす る。この推定値を,pseAで表す。 t i t i A X X pse average of 1 -+2 = (1) である。ここで,式(1)における平均は,2系列全体に わたってとる。 分析モデル 確率モデルに基づく分析では,以下のモデルを設定す る。これらは,岡本(2017)で用いられているものにお いて,3件法と4件法の場合に「?」あるいは「+?」お よび「−?」判断の境界点が主観的等価点に対応する感 覚量から等距離にあるとしたモデルである(Böckenholt, 2001; 岡本,1994; 大山,1971)。関数Φ(z)は,累積標準 正 規 分 布 関 数(cumulative stanndard normal distribution) であり,心理測定関数(psychometric function: PF)とし て累積正規分布関数は理論的に最も正当化される関数で あるとされ(Kingdom & Prins, 2010), PFが累積正規分布 関数で表されるという仮定はphi–gamma hypothesisと呼 ばれている(Guilford, 1954)。なお,3件法を用いる全系 列法において,弁別閾を算術計算によって求めた場合は 閾値の推定値が判断の基準の影響を受けるが,確率モデ ルによる分析を行えば閾値と判断の基準を分離して分析 できることが報告されている(岡本,1995)。 主観的等価点をμ,主観的等価点と判断の基準値との 距離をC,分散の平方根をσとおき,以下のモデルを設 定する。
Model of Two Response Categories: P(R(i)t=+|X(i)t)=Φ(X(i)t−μ)⁄σ) P(R(i)t=−|X(i)t)=1−Φ(Xt(i)−μ)⁄σ) Model of Three Response Categories: P(R(i)t=+|X(i)t)=Φ((X(i)t−μ−C)⁄σ)
P(R(i)t=?|X(i)t)=Φ((X(i)t−μ+C)⁄σ)−Φ((Xt(i)−μ−C)⁄σ) P(R(i)t=−|X(i)t)=1−Φ((Xt(i)−μ+C)⁄σ),
where
C>0
Model of Four Response Categories: P(R(i)t=+|X(i)t)=Φ((X(i)t−μ−C)⁄σ)
P(R(i)t=+?|X(i)t)=Φ((X(i)t−μ)⁄σ)−Φ((X(i)t−μ−C)⁄σ) P(R(i)t=−?|X(i)t)=Φ((X(i)t−μ+C)⁄σ)−Φ((Xt(i)−μ)⁄σ) P(R(i)t=−|X(i)t)=1−Φ((Xt(i)−μ+C)⁄σ),
where C>0
二重上下法の2系列を合わせた総試行数をNとおき, N個のデータをまとめて並べ,(R1, X1),. . . , (RN, XN)と
表 す。 こ の と き, 尤 度 L(θ|D) は 次 式 で 与 え ら れ る (Kingdom & Prins, 2010; 岡本,2017)。
(
θ)
(
θ)
∏
N(
i i)
i L D P D P R X 1 , = = = (2)where θ=(σ, μ) for two response categories, or θ=(σ, μ, C) for three or four response categories.
主観的等価点PSEはパラメータμで表される。すなわち, PSE=μ
である。
弁別閾(丁度可知差異; just noticeable difference: JND) は弁別確率75%の値として JND≈0.6745σ で与えられる。 パラメータの推定法としては,ベイズ分析(Gelman et al., 2014)を用いる。実験要因の影響を検討するよう な実験デザインにおいて上下法が用いられたとき,最尤 法に比べて現代ベイズ法では Markov chain Monte Carlo (MCMC)法の開発により柔軟な分析が可能である。ベ イズ法では,分析結果はパラメータの事後分布として得 られ,パラメータの点推定値は,この事後分布の代表値 として与えられる。事後分布は,次式(3)で与えられ る。 P(θ|D)∝P(θ) P(D|θ) 0 (3) ここで,P(θ)は事前分布である。ここでは事前分布と0 して,パラメータの値が実質的に取り得る有界な範囲で P(θ0)の値が一定である一様分布を設定する。一様分布 は,事後分布に実質的なバイアス効果を何ら与えない分
布である(Kruschke, 2015)。一様分布はパラメータσの 無 情 報 事 前 分 布 と し て(Carlin & Louis, 2009; Gelman, 2006),あるいはパラメータμの無情報事前分布として (Alcalá-Quintana & García-Pérez, 2004)勧められている。
Kingdom & Prins (2010)は,μとσの事前分布として一様 分布を設定している。ベイズ分析のソフトであるStanの デフォルト事前分布は一様分布であり,スクリプトにお いて事前分布が明記されないときは一様分布が設定され る。 一般に,分布の代表値としては平均値,中央値,最頻 値があるが,平均値はサンプルの外れ値の影響を受けや すいので,中央値と最頻値を点推定値とする。中央値 は,MCMC によるサンプルから推定するが,各パラ メータの最頻値は関数 (3)に対して極値探索法により 求めることができる 以上のモデルに基づく二重上下法における 2件法と3 件法および 4件法の比較をシミュレーションによって 行った。 シミュレーション 方 法 二重上下法のシミュレーションを以下の条件で行った。 パラメータμとσの値は,2件法,3件法および4件法とも μ=200, σ=15 とし,3件法および4件法におけるパラメータCの値は C=10 とした。このCの値は,ほぼJNDに等しい。すなわち, C≈JND≈0.6745σ≈10.1 である。 二重上下法における2つの提示刺激系列は,標準刺激 値に対して十分に強い比較刺激値から始まる系列 X1(1), X2(1), X3(1),. . . と,十分に弱い比較刺激値から始まる系列 X1(2), X2(2), X3(2),. . . を用意し,最初の刺激値を X1(1)≥250, X1(2)≤150 であるように設定した。具体的な値は,系列の2つの条 件,一致系列と中間系列,の説明のところで示す。 最初の刺激値X1(1)およびX1(2)の弁別確率は, Φ((X1(1)−μ)⁄σ)≥Φ((250−200)⁄15)≈0.9996 Φ((X1(2)−μ)⁄σ)≤Φ((150−200)⁄15)≈0.0004 であるので,X1(1)およびX1(2)は,それぞれほぼ確実に標 準刺激より「強い」あるいは「弱い」と判断される値で ある。 変化量の初期値∆1は ∆1=20 とした。変化量の最小値∆minは,次の4条件を設定した。 ∆min=5, 10, 15, 20 各変化量∆に対応する2件法における弁別確率を,次式 P(R=+|X=μ+Δ)=Φ(Δ⁄σ) (4) により算出したものをTable 1に示す。ただし,μ=200, σ=15の場合である。 変化量∆=5は,弁別確率約0.63で,ほとんど弁別で きない変化であり,変化量∆=20の弁別確率は約0.91で 弁別がかなり容易である。 二重上下法における2つの系列X(1)t とX(2)t は,ともに次 の一致系列であるか中間系列であるかの2条件を設定し た。 一致系列Seq.Coin: ある試行sおよび試行tにおいて X(1)s=Xt(2)=μ=200 中間系列Seq.Btwn: ある試行sおよび試行tにおいて (Xs(1)+X(1)s+1)⁄2 =(Xt(2)+X(2)t+1)⁄2=μ=200 すなわち,一致系列条件では主観的等価点と一致する刺 激値が提示されることがあり,中間系列条件では主観的 等価点を飛び越える形で提示刺激値が変化する。これら の系列条件は,以下のように∆minとの組み合わせで設定 された。 Table 1.
Discrimination Probabilities of Stimulus Differences. ∆ P (R=+|X=μ+Δ)=Φ (Δ⁄σ), where, μ=200, σ=15
5 0.631
10 0.748
15 0.841
In case of ∆min=5: Seq.Coin condition
X1(1)=250, X1(2)=150,
X(i)t=200=μ on some trial t Seq.Btwn condition
X1(1)=252.5, X1(2)=147.5,
i i s t
X X
on some adjacent trials s and t
200 . 2 + = = In case of ∆min=10: Seq.Coin condition X1(1)=250, X1(2)=150,
X(i)t=200=μ on some trial t Seq.Btwn condition
X1(1)=255, X1(2)=145,
i i s t
X X
on some adjacent trials s and t
200 . 2 + = = In case of ∆min=15: Seq.Coin condition X1(1)=250, X1(2)=150,
X(i)t=200=μ on some trial t Seq.Btwn condition
X1(1)=257.5, X1(2)=142.5,
( )i ( )i s t
X X
on some adjacent trials s and t
200 . 2 μ + = = In case of ∆min=20: Seq.Coin条件 X1(1)=260, X1(2)=140,
X(i)t=200=μ on some trial t Seq.Btwn条件
X1(1)=250, X1(2)=150,
i i s t
X X
on some adjacent trials s and t
200 . 2 + = = シミュレーションにおける各条件の組み合わせにおけ る実験数NExpは NExp=1000 であった。1つの実験における試行数NTrialは,二重上 下法であるので,1系列の長さLSeqの2倍であり,次の 3条件を設定した。 NTrial=40, 100, 400 (LSeq=20, 50, 200) パラメータθの点推定値 θ̂ は,事後分布の中央値(medi-an)と最頻値(mode; maximum a posteriori estimate: MAP estimate)を算出したが,PSEについては従来の算術平均
(式(1))による推定値も算出した。それぞれ θ̂ (Med), θ̂ (MAP)およびpseAで表す。これら点推定値の平均誤差
を次 式 の 二 乗 平 均 平 方 根 誤 差(root mean square error: RMSE; Lunneborg, 2000)として算出した。
(
θ θ)
NExp i T i RMSE NExp 1/2 2 1 1 ˆ = = - (4) ここでθ̂iは,i番目の実験におけるパラメータθの点推定 値であり,θTはパラメータθの真値である。 結 果 シミュレーションの結果をTable 2からTable 4に示す。 1実験当たりの総試行数別にTableにまとめ,判断の選択 肢数,提示刺激系列条件,提示刺激値の最小変化量別に 各パラメータの二乗平均平方根誤差RMSEが示されてい る。標準的な算術平均(式(1))による PSE 推定値を A pse で,ベイズ推定における中央値およびモード推定値 をそれぞれμ̂(Med)および μ̂(MAP)で表した。 まず,2件法におけるPSEの従来の推定値pseA (算術 平均)と確率モデルによる推定値,事後分布の中央値μ̂ (Med)および最頻値 μ̂(MAP),のRMSEを各シミュレー ション条件ごとに(従来推定値,中央値)および(従来 推定値,MAP)の形式で散布図を描いたものをFigure 1 に示す。点が,右上がりの直線 Y=Xより上にあれば, その点の表す確率モデルによる推定値のRMSEより2件 法による従来の推定値pseAのRMSE の方が小さい。従 来の推定値pseAのRMSEの方が小さいのは総試行数40,∆min=5,提示刺激系列条件Seq. Coinの中央値 μ̂(Med) に対するもの1例だけであり,この場合も推定値pseAの
RMSEが3.68,μ̂ (Med) のRMSEが3.72とほとんど同じ値 である。ちなみに,確率現象のシミュレーションにはラ ンダムな変動が伴うが,Figure 1に示されているpseAと
μ̂ (Med)のRMSEのペア24対の内1対がpseAのRMSEの
方が小さいという事象の p値は0.00001より小さい。す なわち,推定値 pseAのRMSE の方が有意に大きいとい える。これは,2件法の場合,標準的な算術平均による 推定値pseAよりも,確率モデルに基づいた推定値 μ̂ (Med)および μ̂ (MAP)の方が,RMSEが小さいという 意味で統計学的に優れているということであると考えら れる。以下の2件法と3件法および4件法との比較では, 確率モデルによる推定値のRMSEについて検討する。 主観的等価点 PSEの推定値の比較を,2件法と3件法 および4件法とで行ったものをFigure 2に示す。横座標 に2件法の中央値 μ̂ (Med)あるいは最頻値 μ̂ (MAP)の
RMSEの値をとり,縦座標に3件法および4件法におけ る中央値 μ̂ (Med)あるいは最頻値 μ̂ (MAP)のRMSEの 値をとり,シミュレーションの対応する条件における μ̂ (Med)の値同士,あるいは μ̂(MAP)の値同士を組み 合わせた点の散布図である。すべての点が直線Y=Xよ り下にあるので,中央値 μ̂ (Med)および μ̂ (MAP)とも 2件法より3件法,4件法の方がRMSEの値が小さい。 中央値による推定値 μ̂ (Med)とMAPによる推定値 μ̂ (MAP)のRMSEの比較を3件法および4件法に対して 行ったものをFigure 3に示す。散布図における点は,値 が1に近いもの,2に近いもの,3に近いもののグループ にまとまっているが,それぞれ総試行数が 400 試行, 100 試行,40 試行のものであることがTables 2–4からわ かる。すなわち,総試行数が多いほど RMSEは小さく なっている。また,総試行数が40試行と少ない場合は MAP推定値のRMSEが中央値(Med)によるものより小 さいが,総試行数が100試行あるいは400試行と多くな ると点はほぼ直線Y=X上に並んでおり,差がないこと がわかる。これは,データ数が多くなると事後分布が左 右対称の正規分布に近づいて(Gelman et al., 2014),中 央値とMAP値が同じ値に近づくためと考えられる。 次に弁別閾JNDの推定値について調べる。JNDは,弁 別確率75%の値としてJND≈0.6745σで与えられるので, σの推定値について比較する。2件法におけるσの事後分 布における中央値 σ̂ (Med)およびMAP値 σ̂ (MAP)の RMSE値を横軸の値として,対応する条件での3件法と 4 件 法 に お け るσ の 中 央 値 σ̂ (Med) お よ び MAP 値 σ̂ (MAP)のRMSE値を縦軸の値とした点をプロットし た散布図をFigure 4に示す。グラフの右上の2点を除い て散布図の点は直線 Y=X より下にある。すなわち, 3件法あるいは4件法における推定値の方がRMSEが小 さいと言える。右上の2点は,総試行数40試行,刺激値 の変化量 ∆min=5の場合の3件法における σ̂ (Med)の2つ の提示刺激系列条件のRMSE値である。総試行数が少な く,変化量も∆min⁄JND≈5⁄(0.6745×15)≈0.5と弁別閾に比 べて小さいので,PFの傾きのパラメータσの推定には条 Table 2.
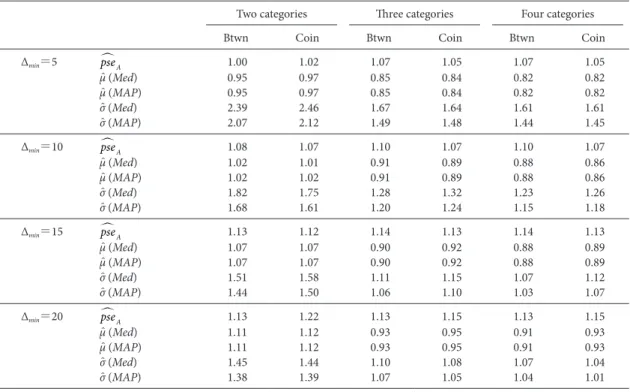
Root Mean Square Errors (RMSEs) in case of Total Number of Trials=40.
Two categories Three categories Four categories
Btwn Coin Btwn Coin Btwn Coin
∆min=5 pseA 3.77 3.68 3.72 3.61 3.72 3.61 μ̂ (Med) 3.73 3.72 3.27 3.33 3.21 3.25 μ̂ (MAP) 3.43 3.38 3.13 3.20 3.02 3.03 σ̂ (Med) 11.58 12.25 11.88 12.88 11.32 12.10 σ̂ (MAP) 5.44 5.23 4.41 4.57 4.20 4.27 ∆min=10 pseA 3.91 3.64 3.87 3.77 3.87 3.77 μ̂ (Med) 3.66 3.49 3.16 3.18 3.08 3.10 μ̂ (MAP) 3.58 3.37 3.05 3.08 2.96 2.98 σ̂ (Med) 9.40 10.11 8.03 8.35 7.44 7.76 σ̂ (MAP) 4.80 4.80 3.82 3.79 3.64 3.63 ∆min=15 pseA 3.85 3.88 3.97 3.99 3.97 3.99 μ̂ (Med) 3.71 3.66 3.18 3.23 3.11 3.22 μ̂ (MAP) 3.67 3.60 3.14 3.18 3.08 3.16 σ̂ (Med) 8.45 8.43 6.05 6.27 5.79 5.97 σ̂ (MAP) 4.62 4.70 3.58 3.56 3.43 3.42 ∆min=20 pseA 3.97 4.24 4.04 4.19 4.04 4.19 μ̂ (Med) 3.87 3.87 3.22 3.29 3.18 3.24 μ̂ (MAP) 3.97 3.79 3.19 3.27 3.16 3.22 σ̂ (Med) 7.15 7.28 5.18 5.22 4.87 4.99 σ̂ (MAP) 4.54 5.88 3.63 3.42 3.27 3.25
Note. Each RMSE was calculated from 1000 simulation experiments for each combination of conditions ∆min, number of response categories, and stimulus series condition (Ser. Btwn and Ser. Coin). Each experiment consists of two subsequences of stimuli; one starts with sufficiently stronger stimulus than the standard stimulus, and the other with sufficiently weaker than the stan-dard. Length of the two subsequences LSeq was half of the total number of trials NTrial, i.e., LSeq=NTrial/2. Estimates of , μ̂ (Med), μ̂ (MAP), σ̂ (Med), and σ̂ (MAP) were calculated from the same data of each experiment.
A
件が悪いと考えられる。 3 件 法 と 4 件 法 に お け るσ の 2 つ の 推 定 値, 中 央 値 σ̂ (Med)とMAP値 σ̂ (MAP),のRMSEの比較をFigure 5 に示す。横軸に中央値 σ̂ (Med)による推定値のRMSE, 縦軸にMAP値 σ̂ (MAP)のRMSEをとり,対応する条件 の中央値による推定値のRMSEとMAP値のRMSEを組み 合わせた点をプロットした。MAP値の方がRMSEが小 さいことがわかる。これは,σ の事後分布の裾が正の方 向に伸びているため,PSEの推定であるμの推定の場合 (Figure 3)と異なり,MAP 値と中央値でRMSE が異な り,MAP値の方がRMSEが小さいという結果になった と思われる。 刺激値の変化量∆minに対するRMSEの平均値をFigure 6 に示す。各変化量∆minにおける推定値のRMSEを総試行 数,選択肢数,提示刺激系列条件に亘って平均値を求め たものを縦軸の値として推定値ごとに表したものであ る。JND に 関 わ る パ ラ メ ー タσ の 推 定 値 は 中 央 値 σ̂ (Med),MAP 値 σ̂ (MAP)とも変化量∆minが大きくな るほどRMSEは小さくなっていて,特に中央値 σ̂ (Med) において大きく減少が見られる。主観的等価点の推定値 のRMSE は,中央値 μ̂ (Med)の RMSE において変化量
∆minが5から10に増加するときにわずかに減少している が,全体としては μ̂ (Med)および μ̂ (MAP)ともに変化 量∆minの増加とともにRMSEが大きくなっている。 考 察 標準的な2件法による上下法に比べて,3件法および 4件法を用いた上下法の方がRMSEが小さくなるという 意味で統計学的に優れていることが示唆されたと言え る。2件法は観察者が困難を覚えることがあり,3件法 あるいは4 件法の方が観察者には望ましいことが指摘 されているが(池田,2013; 神作,1998; Böckenholt, 2001; Kaernbach, 2001; Klein, 2001),本研究のシミュレーショ ンによって統計学的にも3件法あるいは4件法の方が望 ましいことが示唆されたと言える。恒常法において3件 法あるいは 4件法の方が望ましいことを示唆する報告 (岡本,2017)があるが,上下法においても積極的に 3件法あるいは4件法が用いられるべきだと言えよう。 シミュレーション結果(Tables 2–4)については,ま ず2件法において標準的な算術計算によって求められた PSEの推定値pseAと確率モデルに基づいて算出された推
定値 μ̂ (Med)および μ̂ (MAP)の RMSE が比較された Table 3.
Root Mean Square Errors (RMSEs) in case of Total Number of Trials=100.
Two categories Three categories Four categories
Btwn Coin Btwn Coin Btwn Coin
∆min=5 pseA 2.14 2.15 2.08 2.10 2.08 2.10 μ̂ (Med) 2.03 2.06 1.78 1.79 1.75 1.75 μ̂ (MAP) 2.00 2.02 1.76 1.75 1.72 1.72 σ̂ (Med) 6.46 6.74 4.48 4.58 4.29 4.41 σ̂ (MAP) 3.72 3.79 2.82 2.81 2.74 2.75 ∆min=10 pseA 2.18 2.25 2.27 2.23 2.27 2.23 μ̂ (Med) 2.05 2.13 1.86 1.82 1.82 1.77 μ̂ (MAP) 2.05 2.12 1.85 1.81 1.82 1.76 σ̂ (Med) 4.51 4.63 3.04 3.07 2.91 2.93 σ̂ (MAP) 3.19 3.21 2.38 2.36 2.29 2.28 ∆min=15 pseA 2.29 2.23 2.36 2.29 2.36 2.29 μ̂ (Med) 2.15 2.10 1.89 1.88 1.84 1.82 μ̂ (MAP) 2.15 2.10 1.89 1.88 1.84 1.82 σ̂ (Med) 3.81 3.69 2.58 2.61 2.49 2.53 σ̂ (MAP) 3.00 2.87 2.17 2.24 2.08 2.16 ∆min=20 pseA 2.38 2.40 2.28 2.38 2.28 2.38 μ̂ (Med) 2.32 2.23 1.89 1.97 1.86 1.92 μ̂ (MAP) 2.32 2.23 1.89 1.97 1.86 1.91 σ̂ (Med) 3.15 3.39 2.42 2.39 2.29 2.30 σ̂ (MAP) 2.66 2.91 2.10 2.10 1.99 2.02
(Figure 1)。標準的な従来の算術平均による推定値pseA
よりRMSEが大きかったのは総試行数40,∆min=5, 提示 刺激系列条件 Seq. Coinの中央値による推定値 μ̂ (Med) の1例だけであり,Figure 1に示されている散布図は推 定値pseAより推定値 μ̂ (Med)および μ̂ (MAP)の方が RMSEが小さいことを示すものと言える。確率モデルに
よる分析では提示された全刺激値に対する反応がデータ として使われるが,算術平均による推定値pseAでは提 示刺激値が上昇から下降,あるいは下降から上昇に転じ Table 4.
Root Mean Square Errors (RMSEs) in case of Total Number of Trials=400.
Two categories Three categories Four categories
Btwn Coin Btwn Coin Btwn Coin
∆min=5 pseA 1.00 1.02 1.07 1.05 1.07 1.05 μ̂ (Med) 0.95 0.97 0.85 0.84 0.82 0.82 μ̂ (MAP) 0.95 0.97 0.85 0.84 0.82 0.82 σ̂ (Med) 2.39 2.46 1.67 1.64 1.61 1.61 σ̂ (MAP) 2.07 2.12 1.49 1.48 1.44 1.45 ∆min=10 pseA 1.08 1.07 1.10 1.07 1.10 1.07 μ̂ (Med) 1.02 1.01 0.91 0.89 0.88 0.86 μ̂ (MAP) 1.02 1.02 0.91 0.89 0.88 0.86 σ̂ (Med) 1.82 1.75 1.28 1.32 1.23 1.26 σ̂ (MAP) 1.68 1.61 1.20 1.24 1.15 1.18 ∆min=15 pseA 1.13 1.12 1.14 1.13 1.14 1.13 μ̂ (Med) 1.07 1.07 0.90 0.92 0.88 0.89 μ̂ (MAP) 1.07 1.07 0.90 0.92 0.88 0.89 σ̂ (Med) 1.51 1.58 1.11 1.15 1.07 1.12 σ̂ (MAP) 1.44 1.50 1.06 1.10 1.03 1.07 ∆min=20 pseA 1.13 1.22 1.13 1.15 1.13 1.15 μ̂ (Med) 1.11 1.12 0.93 0.95 0.91 0.93 μ̂ (MAP) 1.11 1.12 0.93 0.95 0.91 0.93 σ̂ (Med) 1.45 1.44 1.10 1.08 1.07 1.04 σ̂ (MAP) 1.38 1.39 1.07 1.05 1.04 1.01
Note. See the note of Table 2.
Figure 1. Scatter diagram of (RMSE (pseA),RMSE
(μ̂ (Med)))s and (RMSE (pseA), RMSE (μ̂ (MAP)))s for
two response categories. These values are listed in Ta-bles 2 to 4, and paired with each other of the same sim-ulation condition.
Figure 2. Root mean square errors (RMSEs) of esti-mates μ̂s for two response categories on the abscissa and for three or four response categories on the ordi-nate. Estimates are the median (Med) or the maximum a posteriori (MAP) estimate, which are listed in Tables 2 to 4. RMSE values of two categories are paired with those of three or four categories of the same simulation conditions except the number of categories.
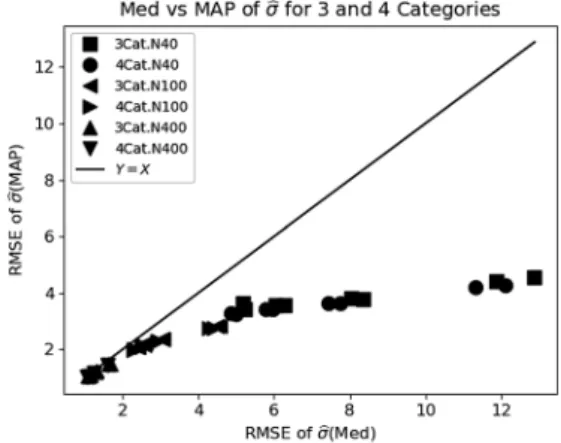
るところのデータのみが用いられる。この用いられる データ量の差が算術平均による推定値pseAのRMSEと 確率モデルによる推定値のRMSEとの差の原因の1つと 考えられる。 上下法を従来通り2件法によって行った場合も,点推 定値の RMSEの観点からはPSEの推定値は算術平均に よって求めるのではなく,確率モデルに基づいて推定さ れるべきであると言えるが,確率モデルを用いる利点は RMSEの観点からだけではない。近年は確率モデルがベ イズ統計学の手法で分析されるようになってきたが (Kruschke, 2015),これはベイズ分析用のStanなどのソ フトウェアの開発によることが大きい。本研究での弁別 データのベイズ分析もStanを利用している(弁別データ 分析用のStanスクリプト例は付記に示した)。確率モデ ルを用いると,パラメータμ, σ, Cなどの分析が実験デザ インを直接反映したモデルで行うことができる。例え ば,現在の分散分析は線形回帰モデルによって行われる が(Kutner et al., 2005; Myers & Well, 2003; Kirk, 1995; 岡本, 2014),この拡張モデルである一般化線形モデル(gener-alized linear model: GLM (Kruschke, 2015))を用いれば, Figure 3. Root mean square errors (RMSEs) of
μ̂ (Med) on the abscissa and μ̂ (MAP) on the ordinate for three and four response categories. RMSE values are listed in Tables 2 to 4, and RMSE values of μ̂ (Med) are paired with those of μ̂ (MAP) for the same simula-tion condisimula-tions.
Figure 4. Root mean square errors (RMSEs) of esti-mates σ̂s for two response categories on the abscissa and for three or four response categories on the ordi-nate. Estimates are the median (Med) or the maximum a posteriori (MAP) estimate, which are listed in Tables 2 to 4. RMSE values of two categories are paired with those of three or four categories of the same simulation conditions except the number of categories.
Figure 5. Root mean square errors (RMSEs) of σ̂ (Med) on the abscissa and σ̂ (MAP) on the ordinate for three and four response categories. RMSE values are listed in Tables 2 to 4, and RMSE values of σ̂ (Med) are paired with those of σ̂ (MAP) for the same simula-tion condisimula-tions.
Figure 6. Average RMSE and minimum step size ∆min. Values of RMSEs of μ̂ (Med), μ̂ (MAP), σ̂ (Med), and σ̂ (MAP) in Tables 2 to 4 were averaged for each ∆min.
パラメータμ, σ, Cに対する実験要因の影響を分散分析の デザインで直接分析することができる。 2件法において確率モデルによる分析の方が従来の標 準的な算術計算によって求められる PSEの推定値pseA よりRMSEが小さいという結果が得られたので,3件法 および4 件法との比較は確率モデルによる点推定値の RMSEの比較という観点から検討する。
まず,PSEの点推定値 μ̂ (Med)および μ̂ (MAP)につ いて2件法におけるものと3件法あるいは4件法におけ るものを反応選択肢数以外は同じである条件のものを対 にして散布図を描いたものが Figure 2に示された。2件 法より 3件法あるいは4件法の方がRMSEが小さく,こ の意味で統計学的に3件法あるいは4件法の方が2件法 よりよいことが示唆されていると言える。反応カテゴリ 数が多い方が PFに関する情報が詳しいからであろう。 統計学的観点とは別に,2件法は観察者が判断に困難を 覚えることがあると指摘されている。比較刺激の方が 「強い」か「弱い」か判断が難しいときは,例えば「ラ ンダムに反応を選ぶ」というような教示が行われると思 われるが,人はランダムな行動は難しい(Jokar & Mi-kaili, 2012)。判断が難しいときは「わからない」と答え ることは自然であり,人には難しいとされているランダ ム性を観察者に強いることを避けるためには,2件法の 使用は望ましくないと思われる。 3 件 法 お よ び 4 件 法 に お い て 点 推 定 値 μ̂ (Med) と μ̂ (MAP)の比較がFigure 3に示された。散布図の点は, 左下,中央,右上の3つのグループにまとまっている。 左下の総試行数400におけるもの,および中央の総試行 数 100におけるものでは,点は直線Y=X上に集まって いて差がないと言え,右上の総試行数40のものもほぼ 直線 Y=X上に集まっており大きな差はないと言える。 総試行数が増えるとデータ数も増え,事後分布が正規分 布に近づく(Gelman et al., 2014)ので,点推定値 μ̂ (Med)
とμ̂ (MAP)の差もなくなると考えられる。総試行数が 少ないときは,データ数が少なく実験ごとのランダムな 変動も大きくなるので,データの分析においては点推定 値だけではなく事後分布あるいは区間推定も示されるべ きである。上下法における標準的な従来の算術平均によ るPSEの推定では点推定値が示されるだけであるが,確 率モデルを設定してベイズ分析を行う場合は事後分布に 基づく点推定値のみだけではなく事後分布そのものある いは事後分布における区間推定を示すことができる。点 推定値 μ̂ (Med)あるいは μ̂ (MAP)は事後分布の代表値 であり,ベイズ分析ではデータの分析結果は事後分布で 与えられる。得られた事後分布あるいは区間推定の幅が 実験の目的と照らし合わせて不十分なものであれば,試 行数を増やした再実験が必要になる。単純な算術平均に よるPSEの点推定値のみでは,試行数が十分であったか どうかの判断は難しい。 弁別閾 JNDは,パラメータσからJND≈0.6745σで与え られる。このσの2件法における推定値と3件法あるいは 4件法における推定値を比較したものがFigure 4である。 総 試 行 数 40, 刺 激 変 化 量∆min=5 の 3 件 法 の 中 央 値 σ̂ (Med)を推定値とする2点を除いて直線Y=Xより下 にあり,全体として 2 件法より 3 件法,4 件法の方が RMSEが小さいと言えそうである。右上の4点は,刺激 値変化量が∆=5と小さく,総試行数が40と少ないので PFの傾きを表すパラメータσの推定が不安定になってい ると考えられる。3件法および4件法においてパラメー タσの点推定値 σ̂ (Med)と σ̂ (MAP)を比べたものがFig-ure 5である。同じ総試行数,刺激変化量および提示刺激 系列条件(Seq.Btwn および Seq.Coin)において σ̂ (Med) のRMSEを横軸の値に,σ̂ (MAP)のRMSEを縦軸の値と して散布図を描いたものである。点が,直線Y=Xの下 にあるので,σ̂ (MAP)の方がRMSEの値が小さいと言 えるが,特に総試行数がN=40と少ない条件で σ̂ (MAP) のRMSEの方が小さいという傾向が顕著である。データ 数が少ないと,事後分布の裾が正の方向へ伸びるという 分布の非対称性が強くなるためと考えられる。 刺激の変化量∆minに対して各推定値のRMSEの平均値 を表したものが Figure 6である。変化量∆minが大きくな るとパラメータσのRMSEは急激に減少しているが,パ ラメータμのRMSEは漸増傾向である。パラメータσの RMSEの減少は,∆minが20 (1.3σ)ぐらいまでであれば, 変化量∆minが大きい方が PFの傾きに関する情報が安定 しているからと考えられる。Figure 6に表されている変 化量∆minの大きさとパラメータ σ および μのRMSEの増 減の関係からは,刺激の変化量∆minは10 から 15 ぐらい がよいと考えられる。変化量∆min=10はほぼJNDに対応 する値で弁別確率は約0.75であり,変化量∆min=15は弁 別確率約0.84に対応している(Table 1)。すなわち,刺 激の変化が少しわかる程度がよいと思われる。刺激の変 化量を∆min=5と細かくしても,Figure 6に示されている RMSEのグラフからはあまり望ましいとは言えない。変 化量∆min=5に対応する弁別確率は約0.63であり,違い がほとんど分からない差であると思われ,このような感 覚量の変化がほとんどわからない刺激系列が提示され続 けると観察者の苦痛も大きいと思われる。逆に,主観的 等価点μの推定精度の多少の増加を問題にしないのであ れば,弁別確率が約 0.91 である変化量∆min=20 でもよ
い。弁別確率が約0.91の刺激値差は感覚量としてかなり わかりやすい差であると思われる。 総試行数として最小どれくらい必要であるかは,恒常 法ではなく上下法が選ばれる理由を考えるとき考慮すべ き問題の1つとなる。Tables 2–4, およびそれらを図示し たFigure 2, Figure 3を見るとき,総試行数が40試行,100 試行,400試行と増えるとPSEの推定値のRMSEは4ぐら いから2, さらに1ぐらいと明瞭に減少している。この総 試行数400のときの4件法におけるPSEの推定値のRMSE が1ぐらいという結果は,岡本(2017)の恒常法におけ る4件法400試行の値約1.4より小さい。シミュレーショ ンの条件はいずれも μ=200, σ=15, C=10で同じである が,パラメータ推定に用いられたモデルが岡本(2017) ではμから上下の判断の境界値がC1とC2というように異 なり得るものが設定されており,モデルのパラメータが 本研究におけるモデルより多いことがRMSEの増加の要 因の1つとして挙げられる。 本研究で比較の基準として用いたRMSEは,実験を多 数回実施したときの推定値の平均誤差(式(4))であり, 個々の実験結果の推定値の誤差を表すものではない。 個々の実験において試行数が十分であったかどうかの判 断は,パラメータの事後分布によって行うことができ る。目安として40試行から100試行ぐらい(二重上下法 であるので,一系列の長さは20試行から50試行ぐらい) で行い,事後分布の広がり,例えば95%確信区間の幅, が求めている精度と比べて著しく大きいときは,試行数 が不十分であったと考えられる。 なお,本シミュレーションでのRMSEの大きさの具体 的意味付けであるが,これを物理量に対応付けることは 心理学的には無意味である。例えば,長さはcmを単位と するかmmを単位とするかで数値は10倍の違いがある。 感覚の弁別においては,物理単位ではなく,JNDを単位 とすることが考えられる。JNDを単位とするとき,物理 単位がcmであるかmmであるかの影響を受けない。本シ ミ ュ レ ー シ ョ ン に お い て はσ=15 で あ る の で,JND= Φ−1(0.75) σ≈10.1である。したがって,RMSE=1あるい は4は,JNDを単位としたときRMSE≈(1⁄10.1) JNDある いは(4⁄10.1) JND, すなわち,RMSE≈0.1 JNDあるいは 0.4 JNDとなる。2件法と3件法および4件法との比較を 示した Figure 2において右上のクラスターは総試行数 N=40の場合であるが(Table 2参照),2件法と3件法お よび4 件法との RMSE の差は約 0.5 であるので,これは 0.05 JNDの差である。 心理物理学的測定の効率を考えて適応的方法が上下法 の他に種々提案されており,よく知られているものとし
てthe BestPEST (Pentland, 1980; Lieberman & Pentland, 1982), QUEST (Watson & Pelli, 1983)が挙げられるが,こ
れらではPFの傾きは実験者があらかじめ決めた値であ り,パラメータ値としてデータに応じて求められるのは 位置パラメータである。また,これらの手法では最尤法 あるいはベイズ統計に基づいて適応的に刺激提示が行わ れるため,実験中に最尤法あるいはベイズ統計の計算が オンラインで行われる。傾きと位置の2つのパラメータ
を同時に扱う適応的方法としてPsi法(Kontsevich & Ty-ler, 1999)があり,2つのパラメータを求める方法として 最 も 優 れ た 方 法 と さ れ て い る が(Kingdom & Prins, 2010),この方法ではオンラインで事後確率とエントロ ピーの計算が行われる。これら実験中にオンラインでの 統計計算が必要な手法に対して,上下法は現在の提示刺 激とそれに対する反応だけで次試行の提示刺激が決めら れるので実験手続きは簡単であり,この手続きの簡単さ が広く用いられている理由の一つであると思われる。上 下法によって得られたデータから PSEを算出する方法 も,提示刺激系列において反応が逆転した刺激の算術平 均を求めるという簡単な計算である。しかし,実験手続 きの簡単さは有用であるが,データ分析の計算が簡単で あることはPCによってデータ分析が行われる今日の状 況ではあまり意味がないといえよう。本研究のシミュ レーションにおいて2件法による上下法においても確率 モデルを設定したベイズ分析による推定値の方が単純な 算術平均による推定値よりRMSEが小さいことが示され た。分析に用いる確率モデルのプログラムは,例えば付 録に示すように簡単なStanスクリプトで記述できる。実 験手続きは上下法を用いた場合でも,分析は確率モデル に基づいた方法によるべきであろう。さらに,2件法よ り3件法あるいは4件法の方がRMSEが小さいことが示 されたので,上下法の実験は3件法あるいは4件法を用 いて行い,分析は確率モデルに基づいて行うのがよいと 思われる。確率モデルによる分析はベイズ法による豊か な分析(Martin, 2018)が可能であるが,算術計算によ る方法は単に推定値が得られるだけである。 最後に,本シミュレーションで採用したモデルについ て少し論じておきたい。本研究では,PSEおよびJNDは PF という理論(モデル)を設定して定義されている。 PSEあるいはJNDを実験操作によって定義する方法もあ るが,このときは実験操作の数だけPSEあるいはJNDが 存在することになり,理論なくしてはこれらを関係づけ ることはできない。感覚過程を正規分布で表すモデル構 成は,信号検出理論(Green & Swets, 1988)やThurstone のモデル(Thurstone, 1927)で採用されており,これら
から本研究におけるモデルを導くことができる。さら に,PFの累積正規分布による近似はよいとされている (Gescheider, 1997; Luce & Galanter, 1963; Stevens, 1975)。本 研究におけるモデルを分析モデルと位置づけたとき,そ のデータ記述の適合性は一般的には十分であると考えら れる。PFの記述モデルとしては,累積正規分布以外に Gumbel分布など代表的なものがいくつかあるが,いず れも位置に関するパラメータ(正規分布の場合はμ)と 傾きに関するパラメータ(正規分布の場合はσ)の2つ のパラメータをもち,横座標軸をともに物理量とする, あるいは対数値(デシベル値)とするもの同士ではパラ メータ値の調整によって極めてよく一致させることがで きる。したがって,累積正規分布モデルによる本シミュ レーションにおける結果は,他の2パラメータモデルの 場合にも同様の結果が得られるものと考えられる。 PFモデルの基本形は2パラメータモデルであるが,感 覚過程以外の推量パラメータγあるいは失策パラメータλ を加えたモデルもある(村上,2011)。2件法の場合は PF曲線が1本なので推量と失策が区別できるが,3件法 とか4件法の場合はPFが2本以上あり推量と失策を区別 するとモデルが複雑になる。いま,推量と失策をまとめ て非感覚判断として,その確率をδ=δ1+. . . +δKで表す。 δkは,反応が非感覚判断によって行われカテゴリkであ る確率を表し,各カテゴリは「−」判断から「+」判断 までの順に整数1からK (3件法のときはK=3, 4件法の ときはK=4)で表している。非感覚判断を考慮したモ デルでの刺激値Xに対する反応がカテゴリkである確率 P(R=k|X)は,非感覚判断過程を考えない本研究におδ けるモデルによる確率を P(R=k|X)で表すとき,次式 P(R=k|X)=δk+(1−δ) P(R=k|X) δ (5) で与えることができる。 また,上下法における算術平均(式(1))による値が PSEの推定値であると考えるためには理論的前提が必要 であることに注意しなければならない。PFをP(x)で表 したとき,PSEがP(PSE)=0.5を満たす値であると定義 されても,上下法ではP(x)の関数形を求めずに,実験 データからP(PSE)=0.5となるPSEを提示刺激系列の折 り返し点の平均値として推定している。これらの折り返 し点の平均が PSEに一致するという考え方には,関数 P(x)が点(PSE, P(PSE))に関して点対称であるという 了解があると思われる。さらに,折り返し点の平均値 (式(1))がPSEに一致するためには判断の反転(系列の 折り返し)についての理論(モデル)が必要である。単 純な算術平均(式(1))がPSEに一致すると考えてよい ことの理論的説明が必要である。これに対して,本研究 における確率モデルの場合はPFであるP(x)が求められ て,PSE と JND が P(PSE)=0.5, P(PSE+JND)=0.75 を 満 たす値として与えられ,データに対して求められた P(x)の適合性もチェックできる。また,Thurstone型の モデルと異なる「心理的」過程のモデルが提示されたと き,それとPFのパラメータがどのように対応するかは, 「心理的」過程モデルが具体的に提示されたときに議論 できることであろう。 引用文献 相場 覚・鳥居修晃(編著)(2004).改訂版知覚心理学 放送大学教育振興会
Alcalá-Quintana, R., & García-Pérez, M. A. (2004). The role of parametric assumptions in adaptive Bayesian estimation. Psychological Methods, 9, 250–271.
Böckenholt, U. (2001). Thresholds and intransitivities in pair-wise judgments: A multilevel analysis. Journal of Education-al and BehaviorEducation-al Statistics, 26, 269–282.
Carlin, B. P., & Louis, T. A. (2009). Bayesian methods for data analysis (3rd ed.). Boca Raton, FL: Chapman and Hall/CRC. Gelman, A. (2006). Prior distributions for variance parameters
in hierarchical models. Bayesian Analysis, 1, 515–533. Gelman, A., Carlin, J. B., Stern, H. S., Dunson, D. B., Vehtari,
A., & Rubin, D. B. (2014). Bayesian Data Analysis (3rd ed.). Boca Raton: CRC Press.
Gescheider, G. A. (1997). Psychophysics: The fundamentals. (3rd ed.). Mahwah, NJ: Lawrence Erlbaum Associates. Green, D. M., & Swets, J. A. (1988). Signal detection theory and
psychophysics (Revised edition (1st ed., 1966)). Los Altos, CA: Peninsula Publishing.
Guilford, J. P. (1954). Psychometric methods. New York: Mc-Graw-Hill Book Company.
池田まさみ(2013).精神物理学的測定法 藤永 保(監 修)最新心理学事典(pp. 428–431)平凡社
Jokar, E., & Mikaili, M. (2012). Assessment of human random number generation for biometric verification. Journal of Medical Signals and Sensors, 2, 82–87.
Kaernbach, C. (2001). Adaptive threshold estimation with un-forced-choice tasks. Perception & Psychophysics, 63, 1377– 1388.
神作 博(1998).閾値とその測定法 日本色彩学会 (編)新編色彩科学ハンドブック(第2版pp. 316–326)
東京大学出版会
Kingdom, F. A. A., & Prins, N. (2010). Psychophysics: A practi-cal introduction. Amsterdam: Elsevier.
Kirk, R. E. (1995). Experimental design: Procedures for the be-havioral sciences (3rd ed.). Pacific Grove: Brooks/Cole Pub-lishing Company.
Klein, S. A. (2001). Measuring, estimating, and understanding the psychometric function: A commentary. Perception & Psychophysics, 63, 1421–1455.
estimation of psychometric slope and threshold. Vision Research, 39, 2729–2737.
Kruschke, J. K. (2015). Doing Bayesian data analysis: A tutorial with R, JAGS, and Stan (2nd ed.). Amsterdam: Elsevier. Kutner, M. H., Nachtsheim, C. J, Neter, J. and Li, W. (2005).
Applied linear statistical methods (5th ed.). New York: Mc-Graw-Hill.
Lieberman, H. R. & Pentland, A. P. (1982). Microcomputer-based estimation of psychophysical threshold: The Best PEST. Behavior Research Methods & Instrumentation, 14, 21–25.
Luce, R. D., & Galanter, E. (1963). Discrimination. In P. Sup-pes, R. D. Luce, J. L. Zinnes, W. J. McGill, R. R. Bush, A. Newell, E. Galanter, & H. A. Simon (Eds.), Handbook of mathematical psychology, Vol. I. (pp. 191–243), New York: John Wiley & Sons.
Lunneborg, C. E. (2000). Data analysis by resampling: Concepts and applications. Pacific Grove: Brooks/Cole.
Martin, O. (2018). Bayesian analysis with Python (2nd ed.), Birmingham: Packt Publishing.
村上郁也(2011).第3章 心理物理学的測定法 大山 正(監修)村上郁也(編著) 心理学的研究法 1 感 覚・知覚 (pp. 41–69) 誠信書房
Myers, J. L., & Well, A. D. (2003). Research design and statisti-cal analysis (2nd ed.). Mahwah: Lawrence Erlbaum Associ-ates, Publishers. 岡本安晴(1994).全系列法データの最尤法による分析 例 金沢大学文学部論集行動科学科篇,14, 63–71. 岡本安晴(1995).全系列法データの最尤法による分析 について――シミュレーションによる検討―― 金沢 大学文学部論集行動科学科篇,15, 25–30. 岡本安晴(2014).心理学データ分析と測定――データ の見方と心の測り方―― 勁草書房 岡本安晴(2017).恒常法における反応カテゴリー数の 影響 基礎心理学研究,36, 85–91. 大山 正(1971).感覚・知覚測定法 和田陽平・大山 正・今井省吾(編著)感覚・知覚ハンドブック (pp. 32–55) 誠信書房 大山 正(2005).第7章 精神物理学的測定法 大山 正・岩脇三良・宮埜壽夫(共著)心理学研究法― デ ー タ収 集・ 分 析 か ら 論 文 作 成 ま で― (pp. 125–141)サイエンス社 大山 正(編著)(2007).実験心理学―こころと行動 の科学の基礎― サイエンス社 大山 正・岩脇三良・宮埜嘉夫(2005).心理学研究法 ――データ収集・分析から論文作成まで―― サイエ ンス社
Pentland, A. (1980). Maximum likelihood estimation: The best PEST. Perception & Psychophysics, 28, 377–379. 繁桝算男(1998).新版心理測定法 放送大学教育振興
会
Stevens, S. S. (1975). Psychophysics: Introduction to its percep-tual, neural, and social prospects. New York: John Wiley & Sons.
Thurstone, L. L. (1927). A law of comparative judgment. Psy-chological Review, 34, 273–286.
鳥居修晃(2001).知覚研究の方法 相場 覚・鳥居修 晃(編著)改訂版知覚心理学(pp. 24–39)放送大学教 育振興会
Watson, A. B., & Pelli, D. G. (1983). QUEST: A Bayesian adap-tive psychometric method. Perception & Psychophysics, 33, 113–120.
付録 弁別データ分析用Stanスクリプト 上下法データ分析用のStanスクリプトを以下に示す。これらのスクリプトの実行においては,パラメータpse (2件 法),mu (3件法,4件法),sgm, C (3件法,4件法)の初期値を設定した方がよい。初期値は,それぞれのパラメータ のおおよその見当で与えればよい。PFのパラメータσを表すsgmの最小値min_sgmは0を設定すればよいが,最大値 max_sgmはsgm (σ)の事後分布の変域が含まれるようにする。max_sgmが適切な値であるかどうかは,MCMCのサン プリング後,事後分布を描いてみるとわかる。事後分布の裾が切れておればmax_sgmの値が小さ過ぎたということで ある。max_sgmが大き過ぎると,サンプリングが不安定になる可能性がある。
Listing 1. Stan script for two response categories data {
int N; // The number of trials
int Res[N]; // Responses: 1 denotes -, 2 denotes + real X[N]; // Stimuli
real min_sgm; // The lower boundary of sgm real max_sgm; // The upper boundary of sgm } parameters { real<lower=0.0>sgm; real pse; } transformed parameters {
vector[2] p[N]; // Probabilities for X[N] for (i in 1:N){
p[i][1]=1 - Phi ((X[i] - pse) / sgm); p[i][2]=Phi ((X[i] - pse) / sgm); }
} model {
sgm~uniform (min_sgm, max_sgm); for (i in 1:N)
Res[i]~categorical (p[i]); }
Listing 2. Stan script for three response categories data {
int N; // The number of trials int Res[N]; // Responses:
// 1 denotes -, 2 denotes ?, 3 denotes + real X[N]; // Stimuli
real min_sgm; // The lower boundary of sgm real max_sgm; // The upper boundary of sgm }
parameters {
real<lower=0.0>sgm; real mu;
real<lower=0.0>C; }
transformed parameters {
vector[3] p[N]; // Probabilities for X[N] for (i in 1:N){
p[i][1]=1 - Phi ((X[i] - mu+C) / sgm);
p[i][2]=Phi ((X[i] - mu+C) / sgm) - Phi ((X[i] - mu - C) / sgm); p[i][3]=Phi ((X[i] - mu - C) / sgm);
} } model {
sgm~uniform (min_sgm, max_sgm); for (i in 1:N)
Res[i]~categorical (p[i]); }
Listing 3. Stan script for four response categories data {
int N; // The number of trials int Res[N]; // Responses: // 1: -, 2: -?, 3: +?, 4: + real X[N]; // Stimuli
real min_sgm; // The lower boundary of sgm real max_sgm; // The upper boundary of sgm } parameters { real<lower=0.0>sgm; real mu; real<lower=0.0>C; } transformed parameters {
vector[4] p[N]; // Probabilities for X[N] for (i in 1:N){
p[i][1]=1 - Phi ((X[i] - mu+C) / sgm);
p[i][2]=Phi ((X[i] - mu+C) / sgm) - Phi ((X[i] - mu) / sgm); p[i][3]=Phi ((X[i] - mu) / sgm) - Phi ((X[i] - mu - C) / sgm); p[i][4]=Phi ((X[i] - mu - C) / sgm);
} } model {
sgm~uniform (min_sgm, max_sgm); for (i in 1:N)
Res[i]~categorical (p[i]); }