DEIM Forum 2015 B2-5
閲覧・検索行動履歴に基づく情報再発見
武田
裕介
†大島
裕明
†田中
克己
††
京都大学大学院情報学研究科
〒 606–8501 京都府京都市左京区吉田本町
E-mail:
†{
takeda,ohshima,tanaka
}
@dl.kuis.kyoto-u.ac.jp
あらまし 本論文では,閲覧した複数の Web ページ間の関係から,あるページと共通の情報要求の元で閲覧したペー
ジ(同位ページ)を推定する手法を提案する.再発見を行っている際に閲覧しているページの同位ページを推薦するこ
とで再発見を支援する.再発見を行う際の情報要求と,再発見したいページを以前に閲覧していた際の情報要求は類
似していることが多いと考えられる.従って再発見を行うために閲覧しているページの同位ページの中に再発見した
いページが存在すると考えられる.同位ページの推定には,リンクやタブの切り替え,クエリの類似度といったユー
ザの閲覧・検索行動に関係する複数ページ間の関係を使用する.
キーワード 再発見,ブックマーク
1.
は じ め に
Webを利用して何らかの情報要求を満たすために複数のWeb ページを閲覧することがある.例えば三重旅行の計画を立てる とする.このとき,三重にはどのような観光名所があるかを調 べるという情報要求の元で複数の三重の観光情報サイトを閲覧 する.各観光名所について詳しく調べるという情報要求が生じ ることがある.このとき,伊勢神宮やなばなの里などの各観光 名所に関するページをタブ機能を用いて同時に開き,タブを切 り替えながらページを閲覧するといった閲覧行動が想定される. 一度閲覧したページを以前と似たような目的でもう一度閲覧 したいと思うことがある.訪問したページの内44%が再訪問で あったり[9],33%のクエリが再発見のためのもの[11]であると いう報告もある.このことからもページの再発見という行動を 普段から行っていることがわかる.先ほどの例でいうと以下の ような理由で再発見を行うことがある. • 観光名所一覧に関するページをもう一度見たい. • どの観光名所に行くか決め切ることが出来なかったので, 各観光名所についてもう一度調べたい 前者の場合,観光名所一覧に関するたった一つのページを再発 見すればよい.しかし,以前に発行したクエリと微妙に異なる クエリを発行してしまうことがある.その結果,目的のページ が検索結果に現れないことがある.このようにして再発見出来 なかったり,再発見に時間がかかってしまうこともある.後者 の場合,三重の観光名所に関する複数のページを開こうとする ことがある.複数のページを再発見しなくてはいけないので, 単純に前者の場合に比べて再発見に失敗することが多いと考え られる. 閲覧情報の再発見のためには,ブラウザのブックマーク機能 を利用するという方法がある.しかし,ブックマークしていな いWebページであってももう一度閲覧したいと思うページは 存在する.また,ページ単位のブックマークでは,作業中の文 脈や閲覧した複数のページ間の関係が失われるという問題点が ある.再発見のためには,閲覧履歴を参照するという方法も考 えられる.しかし,時系列順に並べられた大量の閲覧履歴情報 の中から目的のページを探しだすのは困難であると考えられる. 本研究では,再発見を行うために閲覧しているページの同位 ページを推薦することで再発見支援を行う手法を提案する.あ るページに対する同位ページとはあるページと共通の情報要求 の元で閲覧したページを意味する.三重観光の例で述べると以 下のページが同位関係にあると言える. • 三重の各観光情報サイト(「るるぶ」や「じゃらん」の 三重の観光スポット一覧に関するページなど) • 伊勢神宮に関するページとなばなの里に関するページ 前者は三重にはどのような観光名所があるかを調べるという情 報要求の元で開かれている.後者は三重の各観光名所について 詳しく調べるという情報要求の元で開かれている. ユーザは再発見を行うためにクエリを発行したり,リンクに よる遷移を行って以前にページを発見しようとする.しかし, クエリを正確に再現できなかったり,どのリンクによって遷移 を行えば良いかわからずにページを再発見出来ないことがある. しかし,再発見を行っている際の情報要求は再発見したいペー ジを以前に閲覧した際に情報要求と類似していることが多い. したがって,再発見を行うために閲覧しているページが再発見 したいページで無いならば,その同位ページの中に再発見した いページが存在すると考えた.例えば観光名所に関するページ をもう一度閲覧するためにクエリを発行したとする.そのクエ リが以前に目的のページを開くために開いたクエリと異なって おり目的のページが検索結果のページに表示されないというこ とはよくある.そこで,その検索結果ページの同位ページを推 薦する.ここでは同位ページの中に正しいクエリによる検索結 果ページが含まれる.これによって再発見したいページである 正しいクエリの検索結果ページを発見できるようになる.他に も各観光名所についてもう一度調べようと,伊勢神宮に関する ページを閲覧したとする.その際に,同位ページのなばなの里 などの他の各観光名所のページを推薦すれば,再発見したい複 数のページを容易に再発見できるようになると考えた. 同位ページの推定には閲覧したページの内容に加えて,ユーザの閲覧行動を利用する.利用するユーザの閲覧行動は,リン クによる遷移,フォーカスするタブの切り替え,使用したクエ リの類似度である. 本論文の構成は以下の通りとなっている.2章で関連研究に ついて紹介して本研究の位置づけを行う.3章で問題定義と同 位ページを推定するために考慮する閲覧行動を述べ,4章で同 位ページを発見する手法を提案する.5章で提案手法が有効で あるかを確かめるための実験について述べる.最後に6章で本 論文のまとめを述べる.
2.
関 連 研 究
関連する研究として,タブブラウザに関する研究や再発見, 再検索に関する研究がある. タブブラウザに関する研究としては以下のものが挙げられ る[4], [13].Dubroyら[4]はタブブラウザは複数のウィンドウ を開く必要のある昔のブラウザと比べて「戻る」機能の使用が 少なくなっていることを分析した.これは,タブ機能によって 複数ページを同時に閲覧することが可能になったことが原因の 一つであると考えられる.星加[13]は,タブブラウジングにお けるタブ操作の4つのパターンを分析し,オートマトンを用い て抽出する手法を提案した. 再発見・再検索時のユーザの行動の分析を行った研究は以下 のものが挙げられる[1], [2], [8], [10], [12].Nishimotoら[8]は, 再発見の際の以下の三つの問題点を挙げた. • 最初の検索の際には重要だと思わなかった情報を探さな くてはいけない時がある • 履歴情報は,文脈情報が失われている • 再発見時に必ずしも以前と同じ閲覧行動をとらない 本研究では,特に二つ目の問題にフォーカスしている.Capra [2]は,再発見の種類についてExact,Path,Subset,Moveの4
種類に分類した.Exactとは,以前に閲覧した情報と同じ情報 を再発見するものである.Pathとは,以前に閲覧した情報を 発見した際の閲覧行動と同様の閲覧行動を取ることで以前と少 し異なる情報を発見するものである.Subsetとは以前に閲覧 した情報の一部を再発見するものである.Moveとは,以前に 閲覧した情報を再発見するものであるが,その情報が置かれて いる場所が移動してしまっている場合である.Tylerら[12]は 再検索を行う際のクエリと元のクエリでは,再発見を行う際の クエリのほうが良いクエリとなっていることを分析した.Pu ら[10]は発見時と再発見時の検索の行動を比較をした.再発見 時にはより多くのクエリ,サーチエンジンを使用するという知 見を得ている.Adarら[1]は,ページが再訪問されるのが以前 の訪問からどれくらい時間が経ってからなのかによって,ペー ジが特徴付けられるということを分析した. 再発見のためのシステムに関する研究は以下のものがあ る[5], [6], [7], [14].内藤ら[14]は,Webページやオフィス文書 など,複数文書を同時に閲覧する際の文書間の関連について 6つの属性に分け,各文書間の関連を求め可視化した.Morris ら[7]は閲覧履歴をトピックとクエリによって階層化し,表示 するシステムを提案した.Kawaseら[6]は過去の閲覧ページ 以前に閲覧したページ 同位ページの推定 再発見を試みるユーザ 入力 出力 閲覧ページ 同位ページ 図 1 再発見支援の流れ と現在閲覧中のページが与えられた際に,次に再閲覧するペー ジを推定して表示するシステムを提案した.次に再閲覧する ページを予測するために,最近閲覧したということ,頻繁に閲 覧したということ,そしてページを閲覧した順序に注目した. Eirinakiら[5]はPageRankとマルコフモデルを用いてユーザ の行動を推定し,次あるいはその少し先に閲覧するであろう ページを推薦する手法を提案した.本研究では閲覧予測ではな く,その時に探しているページを推定するという点で異なる.
3.
閲覧行動と同位ページ
3. 1 問 題 定 義 すでに閲覧したページ(URLによって識別される)の集合 P ={p1, . . . , pn},再発見を行うために閲覧しているページ pnowがある,このとき,ページpnowの同位ページらしい順に pi∈ Pをランキングするという問題を解く. 図1のように,再発見を行うために閲覧しているページに対 してその同位ページを推定して推薦することで再発見支援を 行う. 3. 2 同位ページを推定するための閲覧行動 以下の閲覧行動とページ内容を考慮して同位ページを推定 する. • リンクによるページ遷移 • タブの切り替え • 検索クエリの発行 3. 2. 1 リンクによるページ遷移 あるページから複数のページをリンクによって開いたとする. このとき,開かれたページは共通の目的を達成するために開か れたと考えた.例えば,三重の観光名所についてまとめたペー ジから伊勢神宮に関するページとなばなの里に関するページへ リンクを行ったとする.このとき,伊勢神宮に関するページと なばなの里に関するページはどちらも,各観光名所について調 べるという目的を達成するために開かれた.したがって,伊勢 神宮に関するページに対して,なばなの里に関するページは同 位ページであると考えられる. 3. 2. 2 タブの切り替え タブのフォーカスを意図的に切り替えることによって表示し ているページを切り替えることがある.このようなタブの切り 替え行動は,異なるタブで開かれた複数のページを比較して閲覧するために行われることがあると考えた.例えば,三重で宿 泊する場所を決定するために複数の旅館に関するページを開い て,それらをタブで切り替えて比較しながら閲覧するという行 動が考えられる.このように,共通の目的を達成するためにで タブの切り替えが行われることがある.從って,タブの切り替 えがあったページは同位ページである可能性がある. 3. 2. 3 検索クエリの発行 2つの検索クエリによる検索結果が類似しているとする.ユー ザは情報要求を検索クエリという形で表現するので,この2つ のクエリを発行した際の情報要求は類似していると考えられる. また,検索結果からリンクをたどることによって閲覧したペー ジはクエリを発行した際の情報要求を達成するために閲覧さ れることが多いと考えられる.例えば,三重の観光名所を調べ ようと思った時に,「三重観光スポット」や「三重 観光 おすす め」といったクエリを発行してリンクを行うことによって様々 なページを閲覧する.このとき検索結果からリンクをたどるこ とによって閲覧したページは三重の観光名所を調べるためであ ることが多いと考えられる.このように,類似するクエリから リンクの遷移を行うことによって閲覧されたページ同士は共通 の情報要求があって開かれたと考えられるので同位ページであ る可能性が高いと考えられる.
4.
同位ページの推定
同位ページを発見するために,閲覧ページと情報要求をノー ド(それぞれページノード,目的ノードと呼ぶ)とする2部グ ラフを構築する,ページノードと目的ノードにエッジが張られ ているとき,目的ノードが表す情報要求の元でページが閲覧さ れたということを指す.あるページに対する同位ページらしさ を図るために,そのページから目的ノードを経由した際の他の ページへの辿りやすさを求める. リンクによるページ遷移,タブの切り替え,検索クエリの類 似性をそれぞれ用いて3つの2部グラフを構築する.作成され た2部グラフに対してGeneralized Co-HITSアルゴリズム[3] を適用することで同位ページを発見する. 4. 1 グラフ構築 全 て の グ ラ フ の ペ ー ジ ノ ー ド は 閲 覧 ペ ー ジ 集 合 P = {p1, . . . , pn}からなる.目的ノード集合とエッジ集合につい て,各グラフについて述べる.以下ではページノードxと目的 ノードノードy間のエッジを(x, y)と表す. 4. 1. 1 リンクに関するグラフ リンクに関するグラフでは同じページからリンクによる遷移 を行って閲覧したページは全て同じ情報要求の元で閲覧された と仮定して,グラフを構築する.従って,目的ノードはリンク 元のページ数だけ作成する.同じページからリンクされたペー ジに対して,同じ目的ノードとのエッジを張る.グラフは以下 のように表される. • GL= (P∪ NL, EL) • NL ={y|y = pi, lij∈ L} • EL ={(x, y)|x = pj, y = pi, lij∈ L} ページpi∈ P からページpj∈ P へのリンクをlij,このよう なリンク行動の集合をLとする. 4. 1. 2 タブの切り替えに関するグラフ タブの切り替えに関するグラフでは,タブの切り替えがあっ たページは全て共通の情報要求の元で閲覧されたという仮定 に基づいてグラフを構築する.タブの切り替えがあった2つの ページに対して,それらの2つのページのノードに対してエッ ジを張る目的ノードを作成する.グラフは以下のように表さ れる. • GT C = (P∪ NT C, ET C) • NT C ={y|y = nT Cij , tcij∈ T C} • ET C ={(x, y)|x∀∈ {pi, pj}, y = nT Cij ∈ NT C} nT C ij はpi ∈ P とpj ∈ P に対してエッジを張る目的ノード, tcijはi < jであり,pi∈ P とpj∈ P の間にタブの切り替え が生じたことを表す.TCはこのようなタブ切り替え情報集合 である. 4. 1. 3 検索クエリの類似性に関するグラフ 2組の検索クエリが類似しているとする.検索クエリの類似 性に関するグラフでは,それらのクエリからリンクによる遷移 を行って閲覧したページは全て共通の情報要求の元で閲覧され たという仮定に基いてグラフを構築する.検索クエリの類似度 は検索結果ページの類似度を用いて計算する.グラフは以下の ように表される. • GSQ = (P∪ NSQ, ESQ) • NSQ ={y|y = nSQij mn, pn∈ Ciq, pm∈ Cjq, simp(pqi, p q j) > θ, p q i ∈ P q , pqj∈ P q} • ESQ={(x, y)|x∀∈ {p m, pn}, y = nSQij mn∈ N SQ} nSQij mnは2つの検索結果ページpi∈ P とpj∈ P が類似して いることに対してpm∈ Pとpn∈ P に対してエッジを張る目 的ノード,pqi は検索結果ページを指す.Pqは検索結果ページ 集合であり,Pq⊂ P である.Cqi はページp q i ∈ P q からリンク の遷移によって訪問したページの集合を表す.simp(p i, pj)は ページpiとページpjとのページ類似度であり,θ∈ [0, 1]はど の程度類似度が高ければ類似していると判断するかを表す閾値 である.本研究ではページの類似度をページの特徴ベクトルの コサイン類似度を用いて計算した.ページの特徴ベクトルは, ページの内容を形態素解析し,N-Gram法を用いて出てきた語 の頻出度を用いた.本研究ではN=2とした.形態素解析には TinySegmenter(注 1) を用いた.この解析器は,Javascriptで作 成されており,ブラウザ上で動作するが,分かち書きのみで品 詞推定を行うことができない.そこで,ストップワードリスト を作成し精度を向上させた. 4. 2 Generalized Co-HITSアルゴリズムを用いた同位 ページの計算 上記で構築した各グラフG = (P∪ N, E)に,Generalized Co-HITSアルゴリズムを適用し,入力ページpinに対してペー ジp∈ P の同位ページらしさを求める.Generalized Co-HITS アルゴリズムは,ページノードpi ∈ P の値xiと目的ノード ni∈ N の値yiをエッジにそって伝播していくアルゴリズムで (注 1):http://chasen.org/ taku/software/TinySegmenter/ある.具体的に,以下の計算式によってxiとyiの値を更新す る.このアルゴリズムでは,xi∈ [0, 1],yi∈ [0, 1]となる. xi= (1− λp)x0i + λp
∑
nj∈N wjinpyj (1) yj= (1− λn)yj0+ λn∑
pi∈P wijpnxi (2) x0iはpiの初期値,y0jはnjの初期値であり,∑
x0i =∑
yj0= 1である.wnpji およびw pn ij は枝の重みであり,w np ji はnjから piへの枝の重みである.また,∑
pi∈Pw np ji =∑
nj∈Nw pn ij = 1 である.λp∈ [0, 1]およびλn∈ [0, 1]はx0i,y0jをどの程度重 視するかを表すパラメータであり,値が小さいほど,x0i,y 0 jを 重要であるとみなす. 上記のアルゴリズムは共通の目的ノードに対してエッジが張 られたページノードの値が近いものになる.したがってページ ノードの初期値として,ページpinと,同位ページらしいペー ジが高くなるようにすれば,ページpinとより同位ページらし いページが求まる.ここで類似するページは同位ページらしい という仮定を置く.ページの類似度を計算する際にはページの 中身だけでなく,タイトルも使用した.これは,Webページの 中には,中身が画像であったりして,ページの内容(HTML) がそのページの内容を正しく表していない場合があるからであ る.pi,niの初期値を以下のように設定する. x0i = (1− a)simp(pin, pi) + asimt(pin, pi)∑
pk∈P(
(1− a)simp(pin, pk) + asimt(pin, pk))
(3) y0i = 1/|N| (4) ここでa∈ [0, 1]は,タイトルの類似度をどれだけ重視するか を表す係数であり,|N|は目的ノード総数,simt(p i, pj)はタイ トルの類似度を指す.タイトルの類似度はタイトルをN-Gram 法によって特徴ベクトルに分割し(本研究ではN=2とした), その特徴ベクトルのコサイン類似度を用いて計算する. 枝の重みは,枝を張るような閲覧行動があった回数を用いて に計算する.リンクに関するグラフではは多くの回数リンクし ているほど,リンク元のページを閲覧した目的を達成するため にリンクによる遷移が行われた考えた.ページAからページB にリンクを5回,ページCにリンクを1回,ページDにリン クを4回行ったとする.この時,ページBに対してページD のほうがページCよりも同位ページらしいと考えられる.この ような理由から以下のように枝の重みを設定する. wjinp= count(lji)∑
pk∈P count(ljk) , wijpn= count(lji)∑
nk∈NL count(lki) (5) count(lij)は,ページpiからページpjへのリンクがあった回 数を指す. タブ切り替えに関しても,タブ切り替え回数が多いほど,共 通の目的を達成するためであると考えられるので以下のように 枝の重みを設定する.ただし,目的ノードからページノードへ は全て2つのエッジのみが張られるので,その重みは全て0.5 となる wjinp=1 2, w pn ij = count(tcij)∑
nk∈NL count(tcik) (6) count(tcij)は,ページpiとページpjの間でタブの切り替えが あった回数を指す. クエリの類似度に関しては,全てのエッジの重みを均等に扱 う.エッジを張る際にすでに閾値を用いて枝刈りをしているの で,全てのエッジの重みが等しいと考えた.したがって以下の ように計算される. wjinp=1 2, w pn ij = 1 EdgeNum(pi) (7) EdgeNum(pi)はpiに張られているエッジの本数を指す. 4. 3 各グラフによって得られた同位ページらしさの結合 各グラフに上記のGeneralized Co-HITSアルゴリズムを適 用すると,入力したページに対する各ページの同位ページらし さの値が求まる.リンクに関するグラフで求めたページpi∈ P の値をxLi,タブの切り替えに関するグラフで求めた値をxT Ci , 検索クエリの類似性に関するグラフで求めた値をxSQi とする. これらの値を合わせることで最終的な同位ページらしさの値を 決定する. xi= αxLi + βxT Ci + γxSQi (8) α,β,γはそれぞれのグラフをどの程度重視するかを表す係数 である.5.
ユーザ実験
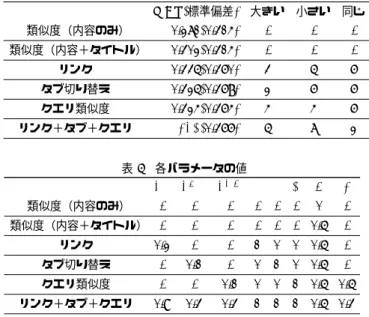
提案手法が有効であるかを検証する正解データを作成ために ユーザ実験を行った.ユーザ実験の目的は再発見を行っている 際に,どのページを推薦して欲しいかというデータを取得する ことである. 5. 1 実 験 内 容 実験は情報検索に慣れた20代の男性4人に行ってもらった. 実験の概要は以下の通りである. (1) 情報をまとめるようなタスクを20分間行ってもらう. まとめる際にはメモを作成してもらう.(タスク1) (2) 1週間後,メモを紛失したということでもう一度20分 間以内で同じメモを再現してもらう.(タスク2) (3) 再発見に関するアンケートに答えてもらう. 以下の状況を想定したタスクを行ってもらった. • 友達と温泉旅行へ行きたい.どこの温泉地へ行くかを決 めるために各温泉地の良いところと悪いところをまとめ ることになった. この状況を想定して各温泉地の良いところと悪いところをまと めたメモを作成してもらった.アンケートは,再発見時に閲覧 しているページに対して,どのページが推薦されれば嬉しいか という情報を得るために行った.アンケート内容は表1に示す. アンケートでは,タスク2を行っている際にいつ,どのページ を推薦して欲しかったかということを聞いた.表 1 アンケート内容 (1) 温泉地について詳しいですか(5 段階で評価) (2) タスク 2 を行っていた際にタスク 1 で閲覧したページを 推薦されると嬉しかったであろう場面を最低 3 つあげて 下さい.その時に閲覧していたページと推薦して欲しい ページをあげて下さい.なお,推薦して欲しいページは 1つでも複数でも構いません. 表 2 取得した情報 閲覧したページの情報 ページ ID URL タイトル 中身(html) 閲覧開始時間 閲覧終了時間 フォーカスしていた時間 開いているタブの ID セレクション文字列 タブの切り替え情報 切り替え元ページ ID 切り替え先ページ ID 切り替え元タブ ID 切り替え先タブ ID 切り替えた時間 表 3 被験者の閲覧行動の定量的情報 タスク 1 タスク 2 全体 閲覧ページ数 60.7 39.0 99.7 ユニークページ数 43.7 35.0 66.3 発行クエリ数 9.0 7.3 12.7 リンク数 33.3 24.3 57.7 タブの切り替え数 16.3 5.3 21.7 実験に使用したパソコンのOSはWindows8であり,ブラウ ザはFirefox(注 2) である.Firefoxの拡張機能と閲覧履歴を利用 して閲覧したページの情報とタブの切り替え情報を取得した. 取得した詳細な情報は表2のとおりである.ブラウザには,被 験者の閲覧行動を記録する拡張機能のみが入っており,その他 の拡張機能は入っていない.ブラウザには閲覧履歴が何も無い 状態で実験を行うので,閲覧履歴情報を用いると簡単に再発見 ができてしまう.そこで,閲覧履歴情報を閲覧することを禁止 した. 5. 2 実験のユーザの閲覧行動に関する結果 実験結果を以下に記す.実験で被験者の平均の閲覧したペー ジ数,ユニークページ数,タブの切り替え数,リンクを行った 回数,発行したユニーク検索クエリ数を表3に記す.閲覧ペー ジについては再訪問率が約50%となっており大変高いことが 分かる.また,タスク1に比べてタスク2の方が閲覧ページや 発行クエリ,タブの切り替え数が少なく,効率よく再発見がで きていることが分かる.また,全体の閲覧ページ数99.7ペー ジに対してリンク数が57.7回であり,ページ訪問の半分以上 がリンクによるものであるということが分かる. 温泉地の詳しさについては平均2.5点(どちらでもないが3 点,点数が大きいほど詳しい)であった.被験者は全員それほ ど温泉地について詳しく無いことが分かる.ユーザはタスク2 において,時間内に以前のメモをほぼ再現出来ていた.以前ま (注 2):http://www.mozilla.jp/firefox/ 表 4 各グラフの MAP と正解データの各組に対して初期値と各手法 を比べた際の平均適合率が大きい組、小さい組、同じ組の数 MAP(標準偏差) 大きい 小さい 同じ 類似度(内容のみ) 0.271(0.314) - - -類似度(内容+タイトル) 0.302(0.314) - - -リンク 0.335(0.360) 3 5 6 タブ切り替え 0.325(0.368) 2 6 6 クエリ類似度 0.324(0.364) 4 4 6 リンク+タブ+クエリ 0.341(0.366) 5 7 2 表 5 各パラメータの値 λL λT C λQS α β γ a θ 類似度(内容のみ) - - - 0 -類似度(内容+タイトル) - - - 0.5 -リンク 0.2 - - 1 0 0 0.5 -タブ切り替え - 0.1 - 0 1 0 0.5 -クエリ類似度 - - 0.1 0 0 1 0.5 0.5 リンク+タブ+クエリ 0.9 0.3 0.3 1 1 1 0.5 0.3 とめた温泉地の情報に加えて,更なる温泉地の情報をまとめて いる被験者もいた. 5. 3 評 価 方 法 実験で得られたデータを用いて提案手法の有効性を評価す る.タスク1で閲覧したページ集合をPt1,タスク2で閲覧し たページ集合をPt2とする.アンケートで得た推薦して欲しい 時に閲覧していたページpt2i ∈ P t2 とその時に推薦してもらう と嬉しい複数のページの集合Pit1′ ⊂ Pt1の組に対して評価を 行う.ユーザからのアンケートによってこのような組を14個 得られた.推薦してもらうと嬉しいページのページ数の平均は 2.00ページであった. タスク1で閲覧したページに対して4. 1節で示したように グラフを構築する.推薦して欲しい時に閲覧していたページ pt2 i を入力としてGeneralized Co-HITSアルゴリズムを適用 し,タスク1で閲覧したページpt1 j ∈ Pt1との同位ページらし さを計算してランキングをつける.このランキングに対して推 薦して欲しいページpt1j ∈ P t1′ i を正解として,平均適合率を求 めた.これを各組毎に求めその平均値を評価値とした.これは 一般にMAP(Mean Average Precision)と言われる評価値であ
る.MAPを用いる理由は,推薦して欲しいページ全てを発見 することを目的としているからである.ベースラインとして, pt1j′ ∈ P t1′ をページpt2i との類似度によってランキングしたも の(Generalized Co-HITSアルゴリズムの初期値)を用いた. 5. 4 評 価 結 果 結果を表4,各パラメタの値を5に示す.類似度に関して, タイトルを全く考慮しない場合に比べて,タイトルを考慮した 方が良いことが分かる.全ての場合においてMAPはベースラ インを上回った.単体のグラフを用いる場合,λの値が大きく なるに連れてMAPの値は下がった.リンクに関するグラフは 単体のグラフのMAPでは最も高い値をとっている.タブの切 り替えに関するグラフでは,MAPが上昇しているが,平均適 合率が下がっている組が6つもあり,有用でない場合も多いと
いうことが分かる.クエリの類似度に関するグラフでは,MAP は提案手法の中でもっとも低いが,4つの組で平均適合率が上 昇しており他の提案手法よりも多い. 正解データの各組について見る.現在見ているページから, リンクによってたどることはできないが,似たような目的で閲 覧されたページを推薦してほしいとなっている解答が多く見受 けられた.例えば「温泉 メリット デメリット」というクエリ の検索結果ページを閲覧している際に「温泉の特徴|メリット・ デメリット.com」というページを推薦してほしいとしている組 があった.この推薦して欲しいページは「温泉 メリット デメ リット」というクエリでは発見出来ない.以前は「日本 温泉 デメリット」というクエリを用いて発見したページである. 「温泉 メリット デメリット- Google検索」というページに 対しては「日本 温泉 デメリット- Google検索」のページの方 が「温泉の特徴|メリット・デメリット.com」というページに 比べて同位ページらしい.したがって,推薦して欲しいページ としては,同位ページらしさに加えてそのページがどれだけ目 的の達成に寄与したかということも考慮する必要があると考え られる.
6.
お わ り に
本論文では,再発見に有用なページとして同位ページを提案 し,同位ページを推定する手法を提案した.同位ページの推定 には以下の閲覧行動の特徴を利用した. • リンクによる遷移 • タブの切り替え • クエリの類似度 このような特徴を用いて 2部グラフを作成し,Generalized Co-HITSアルゴリズムを適用し同位ページを推定した.実験 の結果,提案手法がある程度有用であることがわかった. 今後の課題として,実験数が少ないので実験数を増やす必要 があると考えられる.また,本研究ではページとページの同位 関係のみを使用して再発見支援のための推薦を行う手法を提案 した.しかし,同位関係にあるページからリンクによって辿る ことができるページを推薦して欲しいという実験データも多 かった.従って同位関係だけでなく,再発見されやすいページ の性質も考慮する必要があると考えられる.今後の発展として, 現在は一人の閲覧ページ内で同位ページを発見することを目標 としているが,複数人の閲覧行動から同位ページを抽出して推 薦するということが考えられる.これによって,自分では発見 出来なかったが他の人が同じ情報要求の元で閲覧したページを 発見できるようになる.謝
辞
本研究の一部は,文部科学省科学研究費補助金(課題番号 24240013,24680008)によるものです.ここに記して謝意を表 します. 文 献[1] Eytan Adar, Jaime Teevan, and Susan T Dumais. Large scale analysis of web revisitation patterns. In Proceedings
of the SIGCHI conference on Human Factors in Computing Systems, pp. 1197–1206. ACM, 2008.
[2] Robert G Capra III. An investigation of finding and
refind-ing information on the web. PhD thesis, Virginia
Polytech-nic Institute and State University, 2006.
[3] Hongbo Deng, Michael R Lyu, and Irwin King. A gen-eralized co-hits algorithm and its application to bipartite graphs. In Proceedings of the 15th ACM SIGKDD
interna-tional conference on Knowledge discovery and data mining,
pp. 239–248. ACM, 2009.
[4] Patrick Dubroy and Ravin Balakrishnan. A study of tabbed browsing among mozilla firefox users. In Proceedings of the
SIGCHI Conference on Human Factors in Computing Sys-tems, pp. 673–682. ACM, 2010.
[5] Magdalini Eirinaki, Michalis Vazirgiannis, and Dimitris Ka-pogiannis. Web path recommendations based on page rank-ing and markov models. In Proceedrank-ings of the 7th annual
ACM international workshop on Web information and data management, pp. 2–9. ACM, 2005.
[6] Ricardo Kawase, George Papadakis, Eelco Herder, and Wolfgang Nejdl. Beyond the usual suspects: context-aware revisitation support. In Proceedings of the 22nd ACM
con-ference on Hypertext and hypermedia, pp. 27–36. ACM,
2011.
[7] Dan Morris, Meredith Ringel Morris, and Gina Venolia. Searchbar: a search-centric web history for task resumption and information re-finding. In Proceedings of the SIGCHI
Conference on Human Factors in Computing Systems, pp.
1207–1216. ACM, 2008.
[8] Ippei Nishimoto and Masashi Toda. Process-recollective refinding on the web. In Proceedings of the 2006
IEEE/WIC/ACM International Conference on Web Intel-ligence, pp. 883–892. IEEE Computer Society, 2006.
[9] Hartmut Obendorf, Harald Weinreich, Eelco Herder, and Matthias Mayer. Web page revisitation revisited: implica-tions of a long-term click-stream study of browser usage. In
Proceedings of the SIGCHI conference on Human factors in computing systems, pp. 597–606. ACM, 2007.
[10] Hsiao-Tieh Pu and Xin-Yu Jiang. A comparison of how users search on web finding and re-finding tasks. In
Pro-ceedings of the 2011 iConference, pp. 446–451. ACM, 2011.
[11] Jaime Teevan, Eytan Adar, Rosie Jones, and Michael AS Potts. Information re-retrieval: repeat queries in yahoo’s logs. In Proceedings of the 30th annual international ACM
SIGIR conference on Research and development in infor-mation retrieval, pp. 151–158. ACM, 2007.
[12] Sarah K Tyler and Jaime Teevan. Large scale query log analysis of re-finding. In Proceedings of the third ACM
in-ternational conference on Web search and data mining, pp.
191–200. ACM, 2010. [13] 星加拓人. タブブラウザ上のウェブアクセス履歴の分析. 修士論 文,法政大学, 2011. [14] 内藤稔, 大島裕明, 高橋亜希子, 田中克己. 複数文書閲覧時の文書 間の意味的関係の抽出と提示による文書ナビゲーション. 第9回 日本データベース学会年次大会,F8-4, 2011.