2020 年,161∼172
研究ノート
ポアソン潜在ブロックモデルによるドラッグストアにおける
購買データの解析
山
田 浩
喜,佐 藤
忠 彦
An Analysis of Purchase Data in Drugstore by Poisson Latent Block Model
Hiroki Yamada and Tadahiko Sato
In this paper, POS data with IDs of drugstores is applied to the analysis method proposed by Govaert & Nadif (2010). By using the Poisson latent block model with snacks purchase history data at drugstores located in the Gifu region, we cluster both the customers and the snacks brands simultaneously, and grasp the snack brand group that the customer group with a high purchase frequency choose. Furthermore, based on the model estimation, we discuss effective marketing measures in drugstores. Although we analyze only snack category, it can be extended to other product categories and is an effective way to summarize Big Data.
Key words: drugstore, poisson latent block model, mixture model, EM algorithm
キーワード:ドラッグストア,ポアソン潜在ブロックモデル,混合モデル,EMアルゴ リズム 1. は じ め に 小売業態の中で,ドラッグストアの成長が著しい. 日本チェーンドラッグストア協会によると,ドラッグ ストアとは医薬品と化粧品,そして,日用家庭用品, 文房具,食品等を取扱う店舗を指す.ただし,関係省 庁が定めた明確な業態定義はない.約30年前,米国 のドラッグストアを模倣した店舗が日本に進出してい る.その後,若年層や主婦を対象にした薬,化粧品そ して多様な雑貨(日用家庭用品,文房具等)を取扱っ た比較的規模の大きな店舗が都心や住宅地などに出店 している.現在では,少子高齢化時代を迎えて,地域 の人々の健康と美容を支える小売店舗としての役割が 期待されている(日本チェーンドラッグストア協会, 2020). 日本で最もドラッグストアの競争の激しい地区は岐 岐阜聖徳学園大学経済情報学部
(Faculty of Economics and Information, Gifu Shotoku Gakuen University) 連絡先:〒500–8288 岐阜県岐阜市中鶉 1 丁目 38 番地 E-mail:[email protected] 阜だといわれる(石橋, 2019).当該地区では,ゲン キー(本社:福井県坂井市),アオキ(同:石川県白 山市),コスモス(同:福岡県福岡市)の食品強化型 ドラッグストアが,激安価格を目玉に次々出店してお り,地場の中部薬品(同:岐阜県多治見市),スギ薬局 (同:愛知県大府市)も食品を強化し対抗している.ド ラッグストア各社が食品を強化する狙いは,言うまで もなく人口減少と競争激化によって狭小商圏化が進む 中で顧客の来店頻度を高めることである.そのため, 加工食品から日配品等を扱う店舗を増やす動きが急速 に強まってきた(石橋, 2019).厚生労働省の定義によ ると,加工食品とは食品になんらかの加工を施したも のであり,その種類は,水産練り製品・肉加工品・乳 加工品・嗜好食品・調味料・菓子類・レトルト食品・ 缶詰食品・インスタント食品等,多岐にわたる.加工 食品は,日配品と比べて鮮度管理にかかる費用や陳列 の手間があまりかからない.しかし,加工食品の多く はコモディティ商品であり,取り扱いブランドも多い ため,店舗にはきめの細かい管理が求められる.コン ビニエンスストアや食品スーパーといった小売業態で はPOSデータをもとに加工食品の緻密な商品管理や
売れ筋予測が行われているものの,ドラッグストアは 遅れている.日々蓄積される購買データの分析に着手 できていない店舗が多く,現状のままでは市場から取 り残される可能性があるとみるメーカーもある(石橋, 2020). 本研究では,ドラッグストアにおいてスナック菓子 を購入した顧客の購買履歴データをブロッククラス タリング手法に適用し分析する.分析にはBhatia & Iovleff(2019)で示された統計ソフトRパッケージ blockclusterを用いる.スナック菓子はブランド数が 多い.スナック菓子の分析手法を明示できれば,他の 加工食品の分析にも応用可能である.ブロッククラス タリングを用いれば,顧客クラスタとブランドクラス タから成る『顧客・ブランド』ブロックを定められる. 顧客のみをクラスタリングするアプローチと比べて, より粒度の細かい購買傾向に基づくクラスタリング結 果が得られるため,抽出された顧客・ブランドブロッ ク毎に購買傾向の特徴を把握することによって,購買 行動に関するより有用な情報を獲得することができる (桑田・山田・上田, 2008).なお,本研究はGovaert & Nadif(2010)で提案されたブロッククラスタリン グ手法にドラッグストアのID付POSデータを適用 させた応用研究として位置付けられる. 本稿の残りの部分は次のように構成する.第2章で はクラスタリングに関連する既存研究,第3章では分 析に用いるデータ及びモデルの詳細を示す.第4章で は第3章で示したモデルに実際のデータを適用した結 果を示し,第5章ではドラッグストアにおけるマーケ ティング高度化のための示唆を抽出する.第6章はま とめと今後の課題である. 2. 既存研究の概観 2.1. クラスタリングに関する研究 クラスタリングは,パターン認識,情報検索,マイク ロアレイ,データマイニングなど,さまざまな科学分 野において重要な分析ツールとなっている(Govaert
& Nadif, 2008).階層的クラスタリングやk-means
などの非階層的クラスタリングが代表的な手法であ り,それらの手法は顧客または商品などのオブジェク トを最適に分類することができる. マーケティング分野において消費者をセグメントす ることを考えた場合,外的要因の1つであるデモグラ フィック要因(年齢,所得及び教育水準等)を用いる ことが多い(清水, 1999).しかし,デモグラフィッ ク要因を基準に消費者を分類することは困難である. デモグラフィック要因と消費者行動との関係は必ずし も明確ではないためである(Levy, 1966;Mason & Himes, 1973;Crask & Reynolds, 1978;Lumpkin & Hawes, 1985;Roy, 1994).また,デモグラフィック 要因と同様に外的要因の1つであるライフスタイル要 因は,形成されたセグメントへのアクセス可能性の観 点で難があり,実際に用いられることは少ない(清水, 1999).一方,これらアプローチとは別に,POSデー タや購買履歴に基づきセグメンテーションを行う流れ がある.実際の購買履歴に基づいてなされるため,実 務的経験則と一致する結果になることが多く納得性が 高い. 本節では,ID付POSデータを用いたクラスタ分析 研究として中村・佐藤(2001),山田(2014)を取り上 げる.中村・佐藤(2001)は,期間併買と品 えをク ラスタ分析によって関連付けた研究である.具体的に は,スーパーマーケットのID付POSデータを用い てビールカテゴリーのサブ・カテゴリーを構成してい る.分析の手順は,はじめにアイテム数×アイテム数 の期間併買行列を形成し,それを因子分析にかけて傾 向軸を抽出する.次に因子得点を入力し,クラスタ分 析によって顧客の併買傾向を考慮した商品アイテムの 分類(サブカテゴリーの形成)を行い,最後には顧客 が(同時に)情報探索しやすいビールカテゴリーの棚 割を形成している.山田(2014)は,百貨店のID付 POSデータを用いて26商品カテゴリーの同時購買確 率行列を算定した上で因子分析を行い,そこから抽出 される因子得点をもとにクラスタ分析を行っている. 当該研究では,9つのサブ・カテゴリー(服飾品:6カ テゴリー,食品:3カテゴリー)が形成されている.さ らに,サブ・カテゴリーの購買金額比率行列をつかっ て因子分析を行い,そこから抽出された因子得点から クラスタ分析を行っている.このように顧客と商品カ テゴリーのクラスタ分析を個別に行うことによって, 同時に購買される商品グループ,および嗜好が類似し た顧客グループを抽出している.これら研究は,日々 膨大に蓄積されるID付POSデータを用いてカテゴ リー,顧客情報を縮約し,マーケティング施策構築に 資する重要な情報を抽出できた点では参考になる.し かし,同時購買(併買)行列を事前に作成し,カテゴ リーの因子分析およびクラスタ分析→顧客の因子分析 およびクラスタ分析を行っているため,分析が複雑で
計算に要する時間もかかる.
2.2. ブロッククラスタリング
Govaert & Nadif(2003)は,オブジェクト(行:観 測)と変数(列:属性)を同時に考慮したブロッククラ スタリング手法を示している.当該研究では,ブロッ ク混合モデルといわれる混合モデルを提案している. 混合モデルとは,複数の確率分布モデルによってクラ
スタリングを行うモデルを指す(Govaert & Nadif,
2003).当該研究では,オブジェクト(行)と変数(列)
の同時クラスタリングを混合アプローチによってモデ ル化している.Govaert & Nadif(2008)では,シミュ レートされたバイナリデータをブロック混合モデル, 行と列の個別クラスタリングモデルにそれぞれ適用 し,EMアルゴリズムによって処理能力の比較を行っ ている.その結果,ブロック混合モデルは,個別クラ スタリングモデルと比べて高速で,膨大なデータを処 理できることを示している.たとえば,(行)nのオ ブジェクト,(列)dの属性をもつデータを仮定する. クラスタリングの結果,(行)g,(列)mのデータに 再編成された場合,k-meansモデルであれば(n× m) と(g× d)の縮約途上行列に対してk-meansを交互に 適用しなければならない.それに比べて,同時にクラ スタリングを行うブロック混合モデルでは,構造が単 純であり,縮約途上行列が発生しないことが,高速で 効率的なデータ処理を可能にしている理由であるとし ている.Govaert & Nadif(2010)では,ブロック混 合モデルをポアソンモデルに拡張している.当該研究 では,ブロック混合モデルと個別クラスタリングモデ ルの精度比較,および処理速度の比較を行っている. 当該研究でもブロック混合モデルが優れていることを 示している.このように,ブロック混合モデルは,構 造が単純で精度が優れている点,高速および大規模な データを処理できる点が主な利点になる.
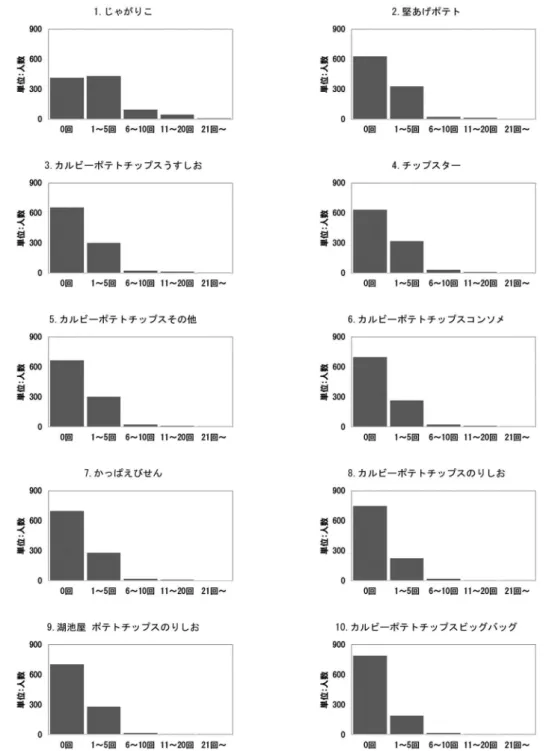
本研究では,Govaert & Nadif(2010)で提案され たブロッククラスタリング手法をドラッグストアの ID付POSデータの縮約に適用し,マーケティング施 策に貢献し得る情報を抽出する. 3. モ デ ル 3.1. データ 本研究では,岐阜地区に立地するドラッグストア (複数店舗)のID付POSデータ(期間:2017年10月 図 1. 曜日別購買客数 図 2. 時間帯別購買客数 1日∼2019年9月30日の3年間)を用いた.7,793 名分の購買履歴の内,それぞれの1年で2回以上ス ナック菓子を購買した経験のある顧客999名(構成比 12.8%)を抽出し,分析対象顧客とした.スナック菓 子のブランド数は80である.データには,顧客毎に, ブランド毎の購買回数,年齢(例. 30歳台,40歳台 等),性別が含まれている.ただし,内包されるデータ 元企業名,店舗名等の各企業を特定または識別できる 情報,および顧客個人を特定できる情報は含まれてい ない.対象期間(3年間)での購買回数は,平均60回, 最大495回,最小6回であった.また,対象期間での 購買金額合計は,平均117,305円,最大1,519,232円, 最小669円であった.図 1は曜日別の購買客数を表 したものである.月曜日から木曜日はほぼ横ばい,金 曜日は平日の中でも比較的購買客数が多く,土曜日と 日曜日の客数が突出して多くなる.図2は時間帯別の 購買客数を表したものである.分析対象のドラッグス トアのほとんどが9時から22時または23時までの 営業時間であるが,24時間営業の店舗も一店舗ある. 9時から23時までを見ると,16時から19時までが 最も多い.開店直後,閉店間際は客数が少なくなるも のの,16時∼19時以外の時間帯の客数にはあまり変
表 1. 分析対象顧客の性別 性別 人数 構成比 男性 244 24.4% 女性 755 75.6% 合計 999 100.0% 表 2. 分析対象顧客の年齢層 年代 人数 構成比 10 歳台 16 1.6% 20 歳台 90 9.0% 30 歳台 202 20.2% 40 歳台 348 34.8% 50 歳台 204 20.4% 60 歳台 95 9.5% 70 歳台 31 3.1% 80 歳台 12 1.2% 90 歳台 1 0.1% 合計 999 100.0% 化がない. 表1は分析対象顧客の性別,表2は年齢層を示した ものである.性別では女性(構成比75.6%)が多くを 占めている.年齢層では40歳台(構成比34.8%)が 最も多く,50歳台(同20.4%),30歳台(同20.2%) が続く. 図3は,スナック菓子の上位10ブランドの購買回 数に関する棒グラフである.縦軸は客数,横軸は対象 期間の購買回数を示している.それぞれのブランドに おいて購買回数0回の顧客が多い.特定のブランドに 購買が集中するのではなく,広範囲のブランドが購買 されていることを示唆している. 3.2. モデル 本研究では,ドラッグストアでスナック菓子を購買 する顧客の特性をブロッククラスタリングの手法を 用いて分析する.ブロッククラスタリングには,潜在 クラスモデルを組み込んだ混合モデルを用いる.これ を潜在ブロックモデルと呼ぶ.本節では,Govaert & Nadif(2010)で提案されたポアソン潜在ブロックモ デルおよび推定方法を示す. 以降,i(i = 1,· · · , n) ∈ I,j(j = 1,· · · , d) ∈ J, k(k = 1,· · · , g),l(l = 1,· · · , m)は,顧客,スナッ ク菓子のブランド,顧客のクラスタ(以降,顧客クラ スタ),ブランドのクラスタ(以降,ブランドクラス タ)をそれぞれ示す.データ行列およびベクトルは, X = (x1,· · · , xn),xi = (xi1,· · · , xid)とし,αは 対応するパラメータとする. 顧客が確率p = (p1,· · · , pg)のg個の顧客クラス タ,ブランドが確率q = (q1,· · · , qm)のm個のブ ランドクラスタによって構成されていると仮定する. はじめに顧客だけのモデルを考える.顧客iと顧客 クラスタkのもとでブランドjが独立であると仮定 すると,xiがクラスタkから発生したときの確率は φk(xi; αk) =
∏
dj=1φk(xij; αk)となり,Xの確率関 数は潜在クラスモデルを用いて(1)式のように表さ れる. f (X; αk, pk) = n∏
i=1 g∑
k=1 pk d∏
j=1 φk(xij; αk) (1) ここでブランドを含めたブロックモデルに拡張する ことを考える.z = (z1,· · · , zg)は,g個ある顧客ク ラスタの区分を示す.ここでziは顧客iの成分を指 す.顧客iが顧客クラスタkに含まれる場合,zik= 1 (それ以外は0)をもつzi= (zi1,· · · , zig)によって 表現される.Zは全顧客Iにおけるzの集合を表す. 同様に,w = (w1,· · · , wm)は,m個あるブランドク ラスタ区分を表す.wjはブランドjの成分である. ブランドjがブランドクラスタlに含まれる場合, wjl= 1(それ以外は0)をもつwj= (wj1,· · · , wjm) となる.W は全ブランドJにおけるwの集合であ る.仮にziやwjが固定された場合,xijは互いに 独立になる.そうすると,確率関数は(2)式の通りに なる. f (X|Z, W ; α) =∏
i,j φziwj(xij; αziwj) (2) φziwj(· ; αziwj)は,αziwjをパラメータにもつ確率関 数である.ziは顧客クラスタ番号,wjはブランドク ラスタ番号を表す.(1)式を潜在ブロックモデルに拡 張させたモデルは(3)式の通りになる. f (X; θ) =∑
(z,w)∈Z×W n∏
i=1 pz i d∏
j=1 qw j∏
i,j φziwj(xij; αziwj) (3) この場合,パラメータは,θ = (p, q, α)である.本研究では,(3)式の顧客iのブランドjの購買回 数xijの分布にポアソン分布を仮定する.xijはポア ソン分布P (µiνjαziwj)にしたがい,パラメータが顧 客iとブランドjのそれぞれ効果であるµiとνj,ブ ロックklの効果であるαklに分類されるとする.こ の場合,(3)式内の確率関数は,(4)式の通り表される. φziwj(xij; αziwj) = e−µiνjαziwj(µiν jαziwj) xij xij! (4) ポアソン潜在ブロックモデルにおけるパラメータ は,θ = (p, q, µ, ν, α)である.µ = (µ1,· · · , µn), ν = (ν1,· · · , vd),α = (α11,· · · , αgm)である. なお,本研究でのパラメータ推定には,EMアルゴ リズムを用いる.EMアルゴリズムとは,観測不可 能な潜在変数に確率モデルが依存する場合を想定し, 確率モデルのパラメータを最尤推定する手法である (Dempster, Laird, & Rubin, 1977).Z とW の条 件付きの対数尤度関数を,前回のパラメータの推定値 と観測データを用いて,θについて最大化する反復計 算を行う.行水準におけるEMアルゴリズム推定か ら,列水準におけるEMアルゴリズム推定の手順を それぞれ収束するまで繰り返す.データ分析には,統 計ソフトRパッケージblockclusterをつかって行う. 顧客とブランドのクラスタ数を設定,変更することに よって最適な共クラスタについて容易に考察すること ができる. 4. 分 析 結 果 本研究では,岐阜地区のドラッグストアにおいてス ナック菓子を購買した顧客のID付POSデータを用 いて,顧客とブランドの双方を同時に考慮したポアソ ン潜在ブロックモデルを推定した.顧客数は999名, ブランド数は80ブランドである. パラメータ推定では,アプリオリに顧客およびブラ ンドのクラスタ数をいくつか与え,データを組み合わ せて行う.顧客やブランドには,各クラスタに対する 所属確率が割り当てられ,最大の所属確率である顧客 クラスタ,ブランドクラスタに所属する.はじめに多 くのクラスタリングから推定し,顧客クラスタ,ブラ ンドクラスタに所属する顧客やブランドが構成比10 ∼50%台におさまるクラスタ数を選択する.基準に 10∼50%を用いた明確な根拠はない.しかし,クラス タ分析を行う場合,大規模データを縮約する反面,き めの細かい分析がもとめられるため目安として設定し ている.ただし,推定結果を精査し,少数割合のクラ スタであったとしても他のクラスタと明らかな違いが あれば,別のクラスタとして識別することにする.そ の結果,表3に示す通り,(顧客クラスタ6,ブランド クラスタ4)から(顧客4,ブランド3)までが選択で きた.ブランドクラスタの構成比を見ると,クラスタ が3つになると全てのクラスタで10%の構成比を超 える.顧客クラスタを見ると,最も小さなクラスタが いずれも3∼4%程度であり大きな変化は見られない. 他の顧客クラスタとは明らかに性質が異なることを示 唆している. また,石岡(2006)はクラスタ数の選択基準には以 下の4つがあることを示している. 1. クラスタ分析を何通りか行い,情報量規準等の 適当な基準を用いて最適なクラスタ数を決定す る方法 2. 最小体積楕円体推定量を用いる方法 3. 最適解と思うクラスタ数より多い数のクラスタ 分割からはじめ,近いクラスタ同士を併合する, または不要なクラスタを抹消することで適当な 数のクラスタを決定する方法 4. 最初にk-means法である十分小さい数のクラ スタに分類した後,各クラスタにおいて同様に k-means法による2分割を,その分割が適当で ないと判断するまで繰り返す方法 本研究では上記のうち1に基づき情報量規準の1
つであるICL (Integrated Complete Likelihood: 統合完全 尤 度)を ク ラス タ 数の 選 択 基 準に 用 いる (Biernacki, Cleleux, & Govaert, 2000).ICLは,十 分に分離したクラスタを提供することに焦点を当てた 尤度ベースの規準である.ICLは小さいほど当てはま りがよいとされるが,クラスタ数が少ないほどICLは 小さくなる特徴を持っている.表3のICLを見ると, (顧客クラスタ4,ブランドクラスタ3)が最も小さい ことがわかる.しかし,2番目にICLの小さい(顧客 クラスタ5,ブランドクラスタ3)と比べると,大きな 違いがない.また,ICLはクラスタ数によって大きさ に影響を受けることから(顧客クラスタ5,ブランド クラスタ3)が妥当なクラスタ数であると判断し,以 降の議論を進めることにする. 表 4には顧客クラスタ毎の人数と構成比を,表 5 にはブランドクラスタ毎のブランド数と構成比を示
表 3. ポアソン潜在ブロックモデルの推定結果 表 4. 顧客クラスタの人数 顧客クラスタ 人数 構成比 A 293 29.3% B 128 12.8% C 94 9.4% D 36 3.6% E 448 44.8% 合計 999 100.0% 表 5. ブランドクラスタのブランド数 ブランドクラスタ ブランド数 構成比 I 45 56.3% II 10 12.5% III 25 31.3% 合計 80 100.0% 表 6. 顧客クラスタ毎の性別 した. 以降では,顧客クラスタとブランドクラスタのそれ ぞれの推定結果を,続いて顧客クラスタとブランドク ラスタの双方を組み合わせたブロックの分析結果をそ れぞれ示す. 4.1. 顧客クラスタの推定結果 2.1節で示した通り,デモグラフィック要因を基準 に消費者を分類することは困難である.しかし,クラ スタリングを行った後,顧客クラスタの傾向を性別と 年齢で捉えられるかを本節では確認してみることにす る.表6は,顧客クラスタ毎の性別を示したものであ る.クラスタによって大きな性別の違いはないが,2 番目に人数の多いAクラスタでは女性の比率が高い 一方で3番目に人数の多いBクラスタでは男性の比 率が比較的高いことがわかる.表7は,顧客クラスタ 毎の年齢層を示している.最も人数の多いEクラス タ,2番目に多いAクラスタを見ると,全体傾向より も40歳台の構成比が低く,広い範囲に顧客が分散し ている. 一方,Cクラスタ(構成比50.0%),Dクラスタ(構 成比41.7%),Bクラスタ(構成比39.1%)は40歳台 の顧客が多いことがわかる. 表8は,顧客クラスタ毎のドラッグストアでの購買 回数を示している.購買回数の平均値を見ると,Dク ラスタ(164回)が最も高く,Cクラスタ(95回),B クラスタ(79回),Eクラスタ(50回),そしてAク ラスタ(42回)が続いている.Dクラスタ,Cクラス
表 7. 顧客クラスタ毎の年齢層
表 8. 顧客クラスタ毎のドラッグストア購買回数(単位:回)
表 9. ブランドクラスタによるブランドの分類 タは顧客クラスタの中で人数は少ないが,他のクラス タよりも突出して購買回数が多く,維持する優先度が 高いことを表している. 図4は表8で示した顧客クラスタ毎の購買回数の分 布を図示したものである.箱の枠は第1四分位点から 第3四分位点,箱の中央線は中央値,ひげの上端下端 はそれぞれ95%点,5%点を示している.ここでも同 様にDクラスタとCクラスタの購買回数が高い位置 で分布しており,ドラッグストアにとって重要な顧客 であることを示している. 4.2. ブランドクラスタの推定結果 表9は,ブランドクラスタの結果を示したものであ る.Iクラスタが45ブランド(構成比56.3%),IIIク ラスタが25ブランド(構成比31.3%),IIクラスタが 10ブランド(構成比12.5%)である.各ブランドを見 ると,IIIクラスタは聞いたことのある,または人気 の高いブランドが並んでいる.IIクラスタのブランド
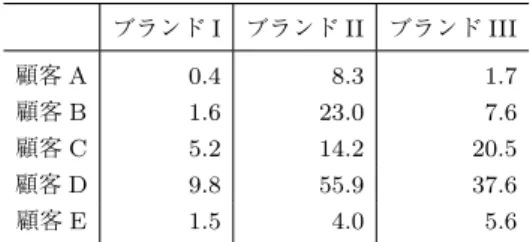
表 10. ブロック毎のスナック菓子平均購買回数 ブランド I ブランド II ブランド III 顧客 A 0.4 8.3 1.7 顧客 B 1.6 23.0 7.6 顧客 C 5.2 14.2 20.5 顧客 D 9.8 55.9 37.6 顧客 E 1.5 4.0 5.6 はスナック菓子といえばすぐ想起するような定番ブラ ンドである.一方,Iクラスタのブランドは定番ブラ ンドや人気ブランドと類似したもの,または一部消費 者に馴染みのあるブランドが多い.Kotler(1980)が 示した競争地位4類型(リーダー,チャレンジャー, フォロワー,ニッチャー)を援用して区分すると,ク ラスタIIIはチャレンジャー型ブランド,クラスタII はリーダー型ブランド,クラスタIはフォロワー/ ニッチャー型ブランドに位置づけられる. 4.3. ブロッククラスタの分析 表10は,顧客クラスタとブランドクラスタの双方 を組み合わせて形成したブロックにおける購買回数を 示している.顧客クラスタ毎にどのようなブランドク ラスタを購買する傾向にあるのかを把握することが可 能になる. 顧客クラスタD(36名・3.6%)のブランドクラス タIIの購買回数が,55.9回と突出して高く,同じく 顧客クラスタDのブランドクラスタIIIの購買回数が 37.6回で続いている. 続いて,顧客クラスタB(128名・12.8%)はブラ ンドクラスタIIの購買回数が23.0回,顧客クラスタ C(94名・9.4%)はブランドクラスタIIIの購買回数 が20.5回,ブランドクラスタIIの購買回数が14.2回 と高い.一方,最も人数の多い顧客クラスタE(448 名・44.8%)は,購買回数の多いブランドクラスタは みられなかった.また,次に人数の多い顧客クラスタ A(293名・29.3%)は,ブランドクラスタIIの購買 回数が8.3回と若干多い結果となった.なお,ブラン ドクラスタIはいずれの顧客クラスタにおいても購買 回数が低い. 5. マーケティング施策における示唆 本章では,これまでのポアソン潜在ブロックモデル の推定結果をもとに,ドラッグストアが取り得るマー ケティング施策について考察する.今回,分析に用い たデータはドラッグストア激戦区といわれる岐阜地 区のものである.ドラッグストアが次々と出店する中 で加工食品から日配品等を扱う店舗を増やす動きが 高まっている.その中でも加工食品は多くがコモディ ティ商品であり,取り扱いブランドが多いため,細か い管理が求められる.明確な戦略を打ち出せずに単な る価格競争に至れば,粗利益率の低下を起こし,経営 を圧迫することになりかねない. 表10をもとに有効なマーケティング施策を考察す る.マーケティング施策を店舗内と店舗外に分類した 場合,店舗内では品 えや陳列,店舗外では折込チラ シが有効な施策となり得る.購買回数の最も多い顧客 クラスタDが最も多く購買していたのが,リーダー型 ブランドであるブランドクラスタII,続いてチャレン ジャー型ブランドであるブランドクラスタIIIである. まずこれらブランドのスナック菓子は,品切れによる 機会ロスを起こさないことがもとめられる.また,値 頃感を強調するPOP等の店頭表示,商品を大量に積 み上げる大量陳列,エンド陳列といった店舗内マーケ ティング施策が効果をもつ(西道, 2003)と考えられ る.顧客クラスタCは,ドラッグストアの購買回数が 多いものの,それほどスナック菓子の購買回数は多く ない.その一方で,顧客クラスタBは,ドラッグスト アの購買回数がクラスタCよりも少ないが,リーダー 型ブランドであるブランドクラスタIIの購買回数は 相対的に多い.顧客クラスタBは男性が比較的多い. リーダー型ブランドとあわせて,男性化粧品などを折 込チラシに掲載し,来店喚起とともに関連購買を誘引 する取り組みが効果的であると考える.また,顧客ク ラスタB,C,Dは40歳台の顧客が多い.スナック菓 子に隣接する商品カテゴリーを40歳台に合わせるこ とによって,関連購買を促進することが期待できる. 顧客クラスタAと顧客クラスタEは人数が多いも のの,ドラッグストアの購買回数およびスナック菓子 の購買回数は少ない.現段階でのマーケティング施策 は店舗内,店舗外ともに有効な手段は見当たらない. ただし,女性の構成比が高いため,化粧品等の女性関 係商品に隣接して陳列する,折込チラシにスナック菓 子と女性関連商品をあわせて掲載する等が施策として 考え得る.また,フォロワー/ニッチャー型ブランド であるブランドクラスタIは,いずれの顧客クラスタ にもあまり購買されていない.商品が陳列されていな
いため購買されていないのかは現段階では確認できな いが,品 えや折込チラシ等のマーケティング施策の 優先度は低いといえる. 以上,表10をもとにマーケティング施策を考察し た.本研究ではスナック菓子以外の商品カテゴリーの 購買履歴は分析していない.そのため,前述で示した 他の商品カテゴリーとあわせた陳列や折込チラシ掲載 等の施策に関してはさらなる分析がもとめられる. 6. まとめと今後の課題 本研究では,ブロッククラスタリング手法をドラッ グストアのID付POSデータに適用し分析した.現 在,岐阜地区において,加工食品から日配品等を扱う 食品強化型ドラッグストアが次々と出店している.し かし,POSデータを有効に活用しているドラッグスト アは少なく,きめの細かい管理が必要とされる加工食 品の商品管理や売れ筋予測を行う上で課題であった. そこで,本研究では加工食品の1つであるスナック 菓子ブランドの購買履歴データをつかってマーケティ ング施策に資する情報を抽出した.顧客クラスタとブ ランドクラスタの双方を考慮したブロッククラスタリ ングの結果,顧客とスナック菓子ブランドを同時にク ラスタリングすることができ,購買回数の多い顧客グ ループがどのようなスナック菓子ブランドグループ を購買しているのかを把握できた.さらに,パラメー タ推定結果をもとに,店舗内,店舗外で有効なマーケ ティング施策を考察することが可能になった.本研究 では,スナック菓子に限定して分析を行ったが,それ 以外の商品カテゴリーにおいても拡張でき,ビッグ データを縮約する手法として有効である. ただし,課題も残されている.本研究では,スナッ ク菓子のブランド毎の購買実績をもとにクラスタリン グを行ったが,スナック菓子のサイズまでは考慮して いない.たとえば,『かっぱえびせん』は,一般的なサ イズもあれば小型サイズも販売しているが,サイズ毎 の購買実績までを踏まえた分析をしていない.また, 本研究では,顧客の特性を把握するデータとして,性 別と年齢層を用いた.しかし,消費者の多様性が進む 中で,性別と年齢層だけでは顧客の傾向を捉えるのに 不十分である.さらに,図3で示した通り,今回適用 したデータには0を多く含んでいる.0の多いデータ の場合,モデルの当てはまりがよくないことも多い. これらは今後の検討課題である. 謝 辞 本研究は,(株) True Data様から提供いただいた岐 阜地区のIDが付与されたPOSデータを用いており ます(当該データには,内包されるデータ元企業名, 店舗名等の各企業を特定または識別できる情報,およ び顧客個人を特定できる情報は含まれていません)。 また,本稿の改訂にあたり,編集長である慶応義塾大 学の星野崇宏先生および匿名の2名の査読者の先生方 から多くの有益なコメントをいただきました。この場 をかりてお礼申し上げます。なお,本研究は,文部科 学省科学研究費 「若手研究20k13626,研究代表者: 山田浩喜」の助成を受けたものです。 参 考 文 献
Bhatia, S., & Iovleff, S. (2019). A tutorial for blo-clcluster R package Version.4.
Biernacki, C., Cleleux, G., & Govaert, G. (2000). As-sessing a mixture model for clustering with the integrated completed likelihood, IEEE
Transac-tions on Pattern Analysis and Machine Intelli-gence, 22, 7, 719–725.
Crask, M., & Reynolds, F. (1978). An indepth pro-file of the department store shopper, Journal of
Retailing, 54, Summer, 23–32.
Dempster, A., Laird, N., & Rubin, D. (1977). Maxi-mum likelihood from incomplete data via the EM algorithm, Journal of the Royal Statistics Society
B, 39, 1, 1–38.
Govaert, G., & Nadif, M. (2003). Clustering with block mixture models, Pattern Recognition, 36, 2, 463–473.
Govaert, G., & Nadif, M. (2008). Block clustering with bernoulli mixture models: Comparison of different approaches, Computational Statistics &
Data Analysis, 52, 6, 3233–3245.
Govaert, G., & Nadif, M. (2010). Latent block model for contingency table, Communications in
Statistics—Theory and Methods, 39, 3, 416–425.
石橋忠子 (2019). 再成長三大要因の将来不安が示唆する 次の一手,ドラッグストア—食品偏重から独自性模 索に動く. 流通情報誌 激流. 国際商業出版, 44, 1, 22–27. 石橋忠子 (2020). 上位 10 社が入り乱れ一触即発の再編 模様. ドラッグストア—大型再編ドミノの幕開け. 流 通情報誌 激流. 国際商業出版, 45, 1, 22–27. 石岡恒憲 (2006). x-means 法改良の一提案—k-means 法 の逐次繰り返しとクラスターの再併合—. 計算機統 計学, 18, 1, 3–13.
Kotler, P. (1980). Marketing Management: Analysis,
Planning, Implementation and Control, Fourth Edition, Prentice-Hall Inc, 272–288.
桑田修平・山田武士・上田修功 (2008). ディリクレ過程 混合モデルに基づく離散データの共クラスタリン グ. 情報処理学会論文誌 数理モデル化と応用, 1, 1, 60–73.
Levy, S. I. (1966). Social class and consumer behavior, in On Knowing the Consumer, J. W. Newman ed. New York: John Wiley & Sons, 146–160. Lumpkin, J. R., & Hawes, J. M. (1985). Retailing
without stores: an examination of catalog shop-pers, Journal of Business Research, 13, 139–151. Mason, J. B., & Himes, S. H. (1973). An Exploratory Behavioral and Socioeconomic Profile of Con-sumer Action about Dissatisfaction with Selected Household Appliances, Journal of Consumer
Af-fairs, 7, Winter, 121–127.
中村博・佐藤忠彦 (2001). ID 付 POS データを用いた優
良顧客のためのグルーピング仮説抽出とその効果. 流通情報, 10 月号, 13–22.
Roy, A. (1994). Correlates of mall visit frequency,
Journal of Retailing, 70, 2, 139–161. 西道実 (2003). 3 章消費者の非計画購買過程. 竹村和久 (編)消費行動の社会心理学. 北大路書房, 40–51. 清水聰 (1999). 第 3 章消費者の外的要因に関する理論. 新しい消費者行動. 千倉書房, 33–71. 山田浩喜 (2014). 百貨店における個人別消費者行動モデ ルに関する研究, 筑波大学博士論文. 日本チェーンドラッグストア協会—ドラッグストア定義. http://www.jacds.gr.jp/outline/teigi.htm(2020/ 02/03 アクセス) (2020 年 4 月 11 日受理,2020 年 7 月 11 日採択) (この間審査 3 回・審査期間合計 64 日)